









Dom4j的基本使用
一、下载对应的jar包
进入官网dom4j ->`地址,下载对应jdk版本的dom4j。

二、常用类的基本了解
| 对象 | 说明 |
|---|---|
| Document | 表示整个xml文档 |
| Element | 标签 |
| Attribute | 属性 |
| Text | 文本内容 |
三、解析xml文件
3.1 准备一个Contact.xml
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1" vip="true">
<name> 潘金莲 </name>
<gender>女</gender>
<email>panpan@itcast.cn</email>
</contact>
<contact id="2" vip="false">
<name>武松</name>
<gender>男</gender>
<email>wusong@itcast.cn</email>
</contact>
<contact id="3" vip="false">
<name>武大狼</name>
<gender>男</gender>
<email>wuda@itcast.cn</email>
</contact>
<user>
<contact>
<info>
<name>我是西门庆</name>
</info>
</contact>
</user>
</contactList>
3.2 创建测试类进行解析
测试使用的是junit包,如果没有导入包,直接在main里面执行此方法也行
首先把contact.xml放入src目录下,然后自己在src目录创建一个包,里面创建一个测试类,代码如下
package com.itheima.d1.dom4j;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
public class Dom4jDemo2 {
@Test
public void parseToList() throws Exception {
//1.创建解析器对象,解析xml.获取document
SAXReader saxReader=new SAXReader();
//加载xml 使用类加载资源的/可用直接定位到src
InputStream is=Dom4jDemo2.class.getResourceAsStream("/Contacts2.xml");
Document document = saxReader.read(is);
//2.获取根元素
Element rootElement = document.getRootElement();
//3.获取所有的concat子元素
List<Element> contactList = rootElement.elements("contact");
//4.遍历子元素获取属性和值
List<Contact> list=new ArrayList();
for (Element element : contactList) {
//不直接强转 直接解析成相关类型
Integer id =Integer.valueOf( element.attributeValue("id"));
Boolean vip =Boolean.valueOf( element.attributeValue("vip"));
//再回去子元素的文本内容
String name = element.elementTextTrim("name");
String gender = element.elementTextTrim("gender");
String email = element.elementTextTrim("email");
Contact contact=new Contact(id,name,vip,gender,email);
list.add(contact);
}
//5.输出 查看效果
for (Contact contact : list) {
System.out.println(contact);
}
}
}
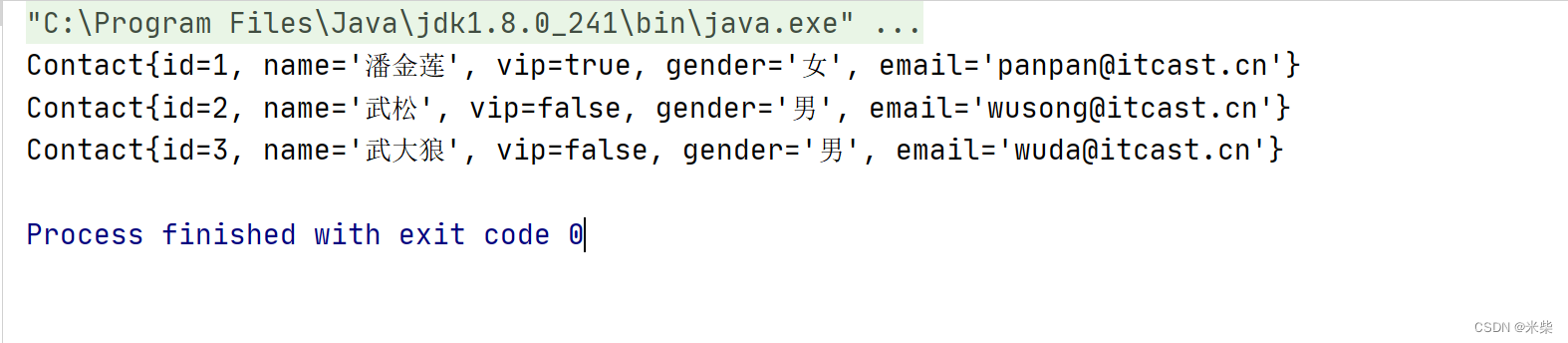
3.3 输出 查看效果
四、总结
SAXReader saxReader=new SAXReader(),这个类属于dom4j里面的,用于解析xml文件。- 使用方法说明
| 方法 | 属于类 | 说明 |
|---|---|---|
Element getRootElement() | Document | 获取根元素 |
List<Element> elements(标签名) | Element | 获取所有指定的子元素 |
List<Element> elements() | Element | 获取所有的子元素 |
Element element(标签名) | Element | 获取指定的第一个子元素 |
String elementText(标签名) | Element | 获取当前元素指定子元素的内容 |
String getName() | Element | 获取标签名 |
String getText() | Element | 获取元素的内容 |
String attributeValue(String name) | Element | 获取元素指定属性名 |
子元素都是指一级子元素















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









