







问题描述:
在使用yolov5训练自己制作的数据集时出现报错
背景:
数据集是自己制作的yolo格式数据集,图片较大,没有做resize处理,分辨率为4000*3000,猜测可能是数据集出现问题
在网上搜索报错信息:
解决方案一:
img = Image.open(image_path) 改为
img = Image.open(image_path).convert(‘RGB’)。
解决方案二:
问题1::RuntimeError: DataLoader worker (pid XXX) is killed by signal: Bus error
问题原因:
一般这种问题发生在docker中,由于docker默认的共享内存为64M,导致工人数量多时空间不够用,发生错误。
解决方案:
1.自废武功
- 将
num_workers设置为0
2.解决问题
在创建docker时配置较大的共享内存,加入参数--shm-size="15g",设置15g(根据实际情况酌量设置)的共享内存:
nvidia-docker run -it --name [container_name] --shm-size="15g" ...
- 通过
df -h查看
df -h
# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 3.6T 3.1T 317G 91% /
tmpfs 64M 0 64M 0% /dev
tmpfs 63G 0 63G 0% /sys/fs/cgroup
/dev/sdb1 3.6T 3.1T 317G 91% /workspace/tmp
shm 15G 8.1G 7.0G 54% /dev/shm
tmpfs 63G 12K 63G 1% /proc/driver/nvidia
/dev/sda1 219G 170G 39G 82% /usr/bin/nvidia-smi
udev 63G 0 63G 0% /dev/nvidia3
tmpfs 63G 0 63G 0% /proc/acpi
tmpfs 63G 0 63G 0% /proc/scsi
tmpfs 63G 0 63G 0% /sys/firmware
- 其中shm即为共享内存空间
问题2 RuntimeError: DataLoader worker (pid(s) ****) exited unexpectedly
问题原因:
由于dataloader使用了多线程操作,如果程序中存在其他有些问题的多线程操作时就有可能导致线程套线程,容易出现死锁的情况
解决方案:
1.自废武功
将num_workers设置为0
2.解决问题
- 在dataloader 的
__getitem__方法中禁用opencv的多线程:
def __getitem__(self, idx):
import cv2
cv2.setNumThreads(0)
解决方案三:
封装dataloader的时候,最后剩下的不足一个batchsize! 自带的dataloader就会有这个现象
改正:
batch_size_s = len(targets) #不足一个batch_size直接停止训练
if batch_size_s < BATCH_SIZE:
break
解决方案四:
向上追溯原因,我的原因在于:
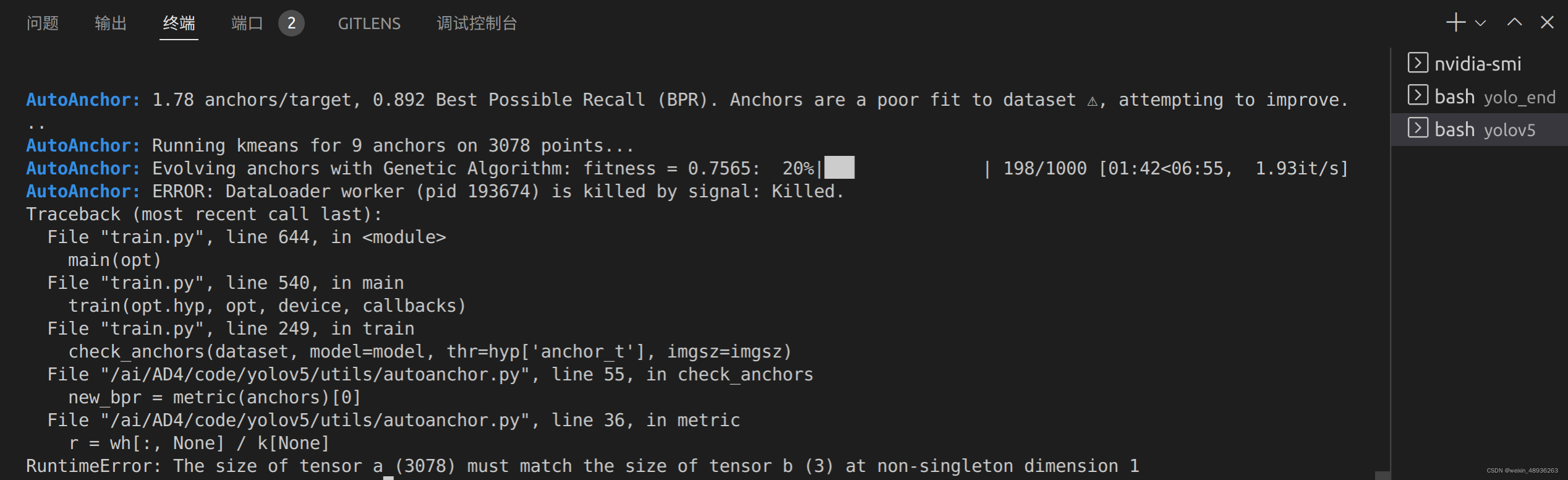
AutoAnchor: Running kmeans for 9 anchors on 3078 points...
AutoAnchor: Evolving anchors with Genetic Algorithm: fitness = 0.7565: 20%|██▉ | 198/1000 [01:42<06:55, 1.93it/s]
AutoAnchor: ERROR: DataLoader worker (pid 193674) is killed by signal: Killed.
于是直接减小batch为32,训练参数如下:
python train.py --img 640 \
--batch 32 \
--epochs 300 \
--data /ai/AD4/code/yolov5/data/waterpipewire_yolo.yaml \
--weights /ai/AD4/code/yolov5/models/model/yolov5s.pt
开始训练!
参考资料:
1.Pytorch dataloader 错误 “DataLoader worker (pid xxx) is killed by signal” 解决方法
2. RuntimeError: The size of tensor a (128) must match the size of tensor b (16) at non-singleton dimen















 6879
6879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









