







文章目录
EMRA-Net:利用混合优化多尺度残差注意力网络在社交媒体中进行高效的多模态情感分析
总结:提出一种使用 AOA-HGS 优化的集成多尺度残差注意力网络 EMRA-Net,来探索文本、语音、和视觉模态之间的相关性,从而进行了更有效的多模态情感分析。优点:在提出的模型中,对三种模态(文本、语音和视频)给予同等重视。缺点:将特征融合起来输入,得到的三种模态特征是否具备足够的特性。
文章信息
作者:Bairavel Subbaiah,Kanipriya Murugesan
单位:KCG技术学院(印度)
会议/期刊:Artificial Intelligence Review(IF:11.6)
年份:2024-02-05
代码:暂未公开
数据集:MELD ,EmoryNLP (MATLAB下进行实验的)
算力要求:Intel ® Core i5
研究目的
以前的研究主要集中在单一模态上,例如对视觉信息的文字描述。与标准图像数据库相比,社交图像之间频繁地连接在一起,使得情感分析具有挑战性。现在使用的大多数方法都是单独考虑不同的图像,使得它们对相关的图像无用。(模型泛化能力差)
研究内容
提出一种混合了算术优化算法-饥饿游戏搜索(AOA-HGS) 优化的集成多尺度残差注意力网络 EMRA-Net,来探索包括文本、音频、和视觉在内的模态相关性,从而进行更有效的多模态情感分析。EMRANet 使用两个片段,集合注意力卷积神经网络(Ensemble Attention CNN,EA-CNN) 和 三尺度残差注意力卷积神经网络(Three-scale Residual Attention Convolutional Neural Network ,TRA-CNN) 来分析多模态情感。在 TRA-CNN 中加入小波变换来减少空间域图像纹理特征的损失。EA-CNN 的特征级融合技术可用于结合视觉、音频和文本信息。
- 本文提出了基于音频、视频和文本的混合 AOAHGS 优化 EMRA-Net 技术,用于预测社交媒体中的多模态情感。
- 该模型通过对现有技术往往无法完成的模态间和模态内表示进行建模,来单独分析每个模态(文字、声音、视觉)中存在的情感。
- 为了获得准确率最高的最佳特征集,作者开发了算术优化算法和饥饿游戏搜索相结合的方法。通过 AOA-HGS 对 EMRA-Net 的超参数进行优化。
- 为了分析多模态情感,EMRA-Net 利用了两个部分,如 EA-CNN 和 TRA-CNN。TRA-CNN 中引入了小波变换,以减少空间域中图像和纹理特征的损失。
- 通过使用 MELD 和 EmoryNLP 数据集进行实验,评估所提出的混合 AOAHGS 优化 EMRA-Net 技术的效率。
研究方法

首先,对音频、文本和视频输入进行预处理,以获得无噪声数据。然后,从文本、音频和视频中提取重要特征来分析情感。为了分析多模态情感,EMRA-Net 使用了两个分段,如 EA-CNN 和 TRA-CNN。使用 TRA-CNN 对音频特征、视觉特征和文本特征进行分类。随后,EA-CNN 被用于多模态情感融合。在此过程中,使用 AOA-HGS 对 EMRA-Net 的超参数进行了优化。为了获得准确率最高的最佳特征集,算术优化算法与饥饿游戏搜索算法相结合。最后,预测情绪的极性(正面、负面和中性)。
1.预处理
为实现有效分类,在将文本输入分类器之前,需要对文本进行初步预处理。预处理是必要的,原因如下。(1) 从社交媒体中获取的文本类型各不相同,可能包含噪音,而且由于其大小、俚语和打字速度等原因,包含许多语义和语法错误。(2)数据标准化使分类器更容易学习模式。(3) 文本将遵守词嵌入层和其他分类器的输入规范。以下是预处理阶段:(1)将超文本标记语言(HTML)代码更改为符号和单词;(2)使用自然语言工具包(NTLK)功能去除停顿词;(3)将所有单词改为小写;(4)减少相同字符出现的次数,最多不超过两次(例如,将 "Sooohappy "更改为 “so happy”);(5)去除用户在社交媒体上的提及(例如,Twitter 上的 "RT "一词);(6)去除标点符号。
使用调整大小程序将不同尺寸的输入图像调整为 224 * 224 的标准尺寸。随后,应用平均值和标准偏差对图像进行归一化处理。具体方法是减去平均值,然后除以每个通道中所有图像的标准偏差。
I
c
=
(
r
c
−
α
c
)
/
σ
c
,
c
=
1...
,
n
I_c=(r_c-\alpha_c)/\sigma_c,\quad c=1...,n
Ic=(rc−αc)/σc,c=1...,n
r 表示输入图像,α 表示数据集的平均值,c 表示通道,σ 表示标准偏差。
2.特征提取
使用COVREP工具提取音频特征,利用FACET提取视频中的面部特征。
3.Three‑scale residual attention convolutional neural network (TRA‑CNN)
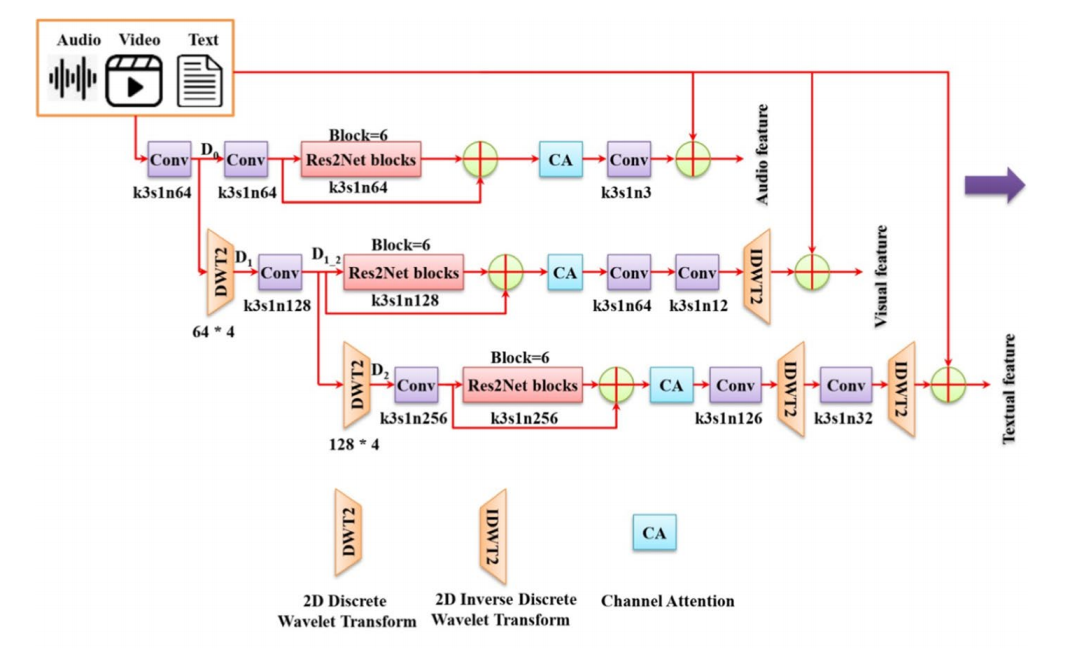
3.1多尺度小波变换
多尺度网络结构对提高复原图像质量至关重要。为了从输入图像中生成各种尺寸的图像,所以使用图像金字塔化。然而,图像金字塔化会在空间域损失图像纹理特征。因此,无法将低分辨率图像升采样为高分辨率图像。但是,在进行图像降采样时,小波变换能保留高频子带信息,所以采用小波变换来实现图像金字塔化的构建。
为了创建四个子带图像,在二维离散小波变换(DWT2)中使用了四个滤波器。由于二维离散小波变换具有可分离的特性,因此小波函数和尺度函数相乘就能产生四个滤波器。
{
γ
(
a
,
b
)
=
γ
(
a
)
γ
(
b
)
χ
H
o
r
i
z
(
a
,
b
)
=
χ
(
a
)
γ
(
b
)
χ
V
e
r
t
(
a
,
b
)
=
γ
(
a
)
χ
(
b
)
χ
D
i
a
g
(
a
,
b
)
=
χ
(
a
)
χ
(
b
)
\begin{cases}\gamma(a,b)=\gamma(a)\gamma(b)\\\chi^{Horiz}(a,b)=\chi(a)\gamma(b)\\\chi^{Vert}(a,b)=\gamma(a)\chi(b)\\\chi^{Diag}(a,b)=\chi(a)\chi(b)\end{cases}
⎩
⎨
⎧γ(a,b)=γ(a)γ(b)χHoriz(a,b)=χ(a)γ(b)χVert(a,b)=γ(a)χ(b)χDiag(a,b)=χ(a)χ(b)
对于大小为p×q的输入g(a , b),创建四个子带图像。

| 符号 | 含义 |
|---|---|
| χ ( ⋅ ) \chi(\cdot) χ(⋅) | 一维小波函数 |
| γ ( ⋅ ) \gamma(\cdot) γ(⋅) | 一维尺度函数 |
| χ j = { H o r i z , V e r t , D i a g } ( a , b ) \chi^{j=\{Horiz,Vert,Diag\}}(a,b) χj={Horiz,Vert,Diag}(a,b) | 二维小波函数 |
| γ ( a , b ) \gamma(a,b) γ(a,b) | 滤波器,低频信息的二维尺度函数 |
| χ D i a g \chi^{Diag} χDiag | 滤波器,评估对角线上的偏差(斜对角线上的高频信息) |
| χ H o r i z \chi^{Horiz} χHoriz | 滤波器,评估列方向上的偏差(水平方向上的高频信息) |
| χ V e r t \chi^{Vert} χVert | 滤波器,评估行方向上的偏差(垂直方向上的高频信息) |
| R χ t = { H o r i z , V e r t , D i a g } R_{\chi}^{t=\{Horiz,Vert,Diag\}} Rχt={Horiz,Vert,Diag} | 表示三个不同方向下的高频子带图像 |
| R γ R_{\gamma} Rγ | 低频输入的合适图像,低频子带图像 |
首先,将输入图像通过3x3的卷积,进行批次归一化以及使用ReLU激活函数后,得到输入图像的浅层特征图
D
0
D_0
D0 。
D
0
=
β
(
E
(
H
(
i
n
p
u
t
)
)
D_0=\beta(E(H(input))
D0=β(E(H(input))
然后,利用二维离散小波变换对
D
0
D_0
D0 进行分解,得到输入图像的 1/2 尺度
D
1
D_1
D1(降采样后的特征图)。接着将
D
1
D_1
D1 通过后面的卷积操作来最小化整个网络的冗余和参数,得到
D
1
_
2
D_{1\_2}
D1_2 。
D
1
_
2
=
β
(
E
(
H
(
D
1
)
)
)
D_{1\_2}=\beta(E(H(D_1)))
D1_2=β(E(H(D1)))
最后,同样利用二维离散小波变换对
D
1
_
2
D_{1\_2}
D1_2 进行分解,得到输入图像的1/4尺度
D
2
D_2
D2,同样通过卷积,得到
D
1
_
4
D_{1\_4}
D1_4 。
| 符号 | 含义 |
|---|---|
| E E E | 批次归一化,batch normalization |
| β ( ⋅ ) \beta(\cdot) β(⋅) | ReLU激活函数 |
| H ( ⋅ ) H(\cdot) H(⋅) | 3x3的卷积 |
3.2深度残差学习模块

为了改进稀疏学习,在 TRA-CNN 中部署了 Res2Net 模块。Res2Net 模块将初始 1 × 1 卷积的特征图分为 q 个特征图子集,即
a
j
(
j
∈
{
1
,
2
,
.
.
.
,
q
}
)
a_j(j\in\{1,2,...,q\})
aj(j∈{1,2,...,q})。在 TRA-CNN 的每个尺度分支中都有六个 Res2Net 模块,每个模块中又有四个子集。
b
j
=
{
a
j
j
=
1
T
j
j
=
2
T
j
(
a
j
+
b
j
−
1
)
2
<
j
≤
q
b_j=\begin{cases}a_j&j=1\\T_j&j=2\\T_j(a_j+b_{j-1})&2<j\leq q\end{cases}
bj=⎩
⎨
⎧ajTjTj(aj+bj−1)j=1j=22<j≤q
3.3通道注意力模块
多个通道的高层特征图提供了精细的特征信息,通道信息加权对于多模态情感分析至关重要。在TRA - CNN的每个尺度分支内部构建通道注意力组件,以保持Res2Net块底层通道之间的相互依赖性。
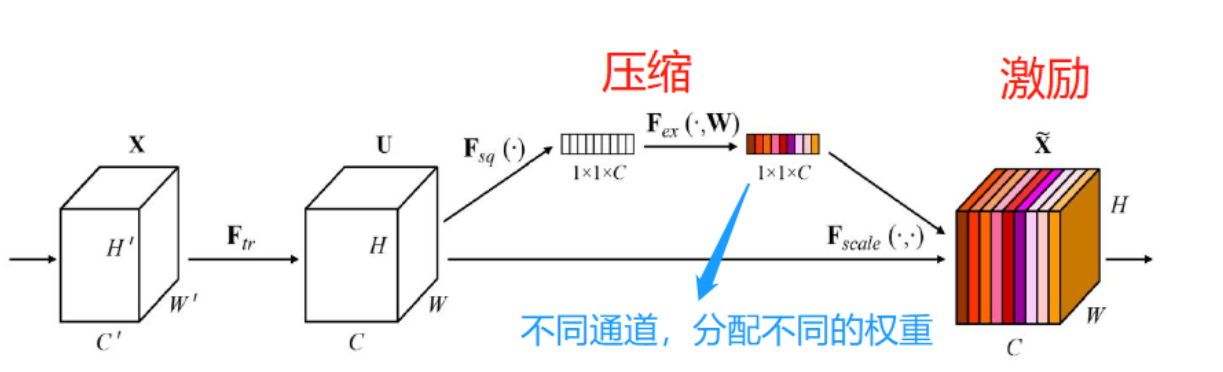
通道注意力机制是在Squeeze-and-Excitation Networks中提出的。SENet分为压缩和激励两个部分,压缩是对特征图的全局空间信息进行压缩,然后在通道维度进行特征学习。激励是对各个通道分配不同的权重。
在压缩部分,输入的元素特征图的维度是 HxWxC,H、W、C分别代表高度、宽度和通道数。压缩部分的功能是将维数从HxWxC压缩至1x1xC。该过程由平均池化实现。
在激励部分,将压缩部分得到的1x1xC的维度融入全连接层,预测各个通道的重要程度,然后再激励到原始特征图的对应通道上。该过程由门控机制与sigmoid激活函数实现。
3.4生成模态特征
在每个尺度分支中预测多模态输入和输入中存在的情感之间的残差。在通道注意力之后,在第一个尺度分支中使用残差连接和3 × 3卷积来生成音频特征。然后,在第二和第三个尺度分支中使用二维离散小波逆变换和卷积操作来创建视觉和文本特征。
4.Ensemble Attention CNN (EA‑CNN)
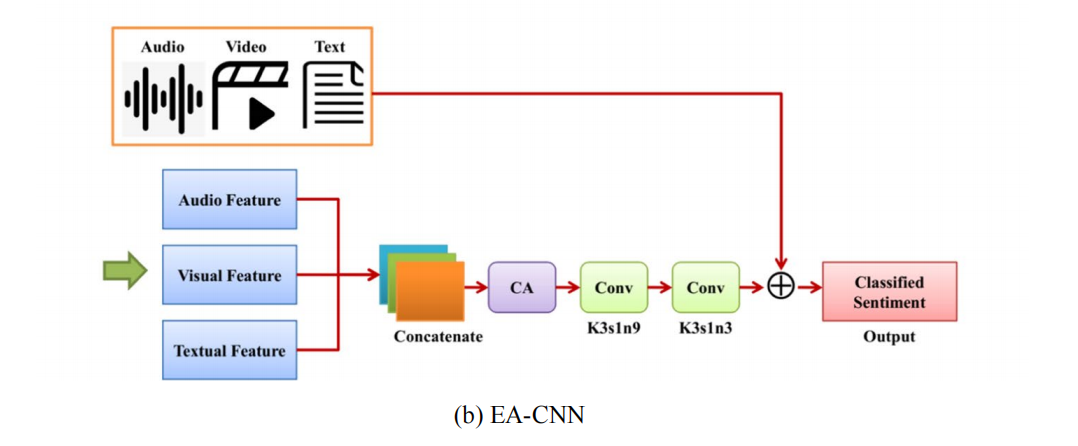
对三种模态特征首先进行线性组合,然后使用一个通道注意力模块,接着使用两个卷积,使用残差连接形成多模态特征,最后送入分类器进行预测。
通过TRA-CNN得到的音频、视频和文本特征表示为:
Y
A
U
D
I
O
、
Y
V
I
D
E
O
、
Y
T
E
X
T
Y_{AUDIO}、Y_{VIDEO}、Y_{TEXT}
YAUDIO、YVIDEO、YTEXT
A
u
d
i
o
M
o
d
a
l
i
t
y
:
Y
A
U
D
I
O
=
{
Y
1
,
Y
2
,
Y
3
,
.
.
.
Y
L
}
V
e
d
i
o
M
o
d
a
l
i
t
y
:
Y
V
I
D
E
O
=
{
Y
1
′
,
Y
2
′
,
Y
3
′
,
.
.
.
Y
L
′
}
T
e
x
t
u
a
l
M
o
d
a
l
i
t
y
:
Y
T
E
X
T
=
{
Y
1
′
′
,
Y
2
′
′
,
Y
3
′
′
.
.
.
Y
L
′
′
}
AudioModality:Y_{AUDIO}=\begin{Bmatrix}Y_1,Y_2,Y_3,...Y_L\end{Bmatrix} \\ VedioModality:Y_{VIDEO}=\{Y_{1}^{\prime},Y_{2}^{\prime},Y_{3}^{\prime},...Y_{L}^{\prime}\} \\ TextualModality:Y_{TEXT}=\{Y_1^{\prime\prime},Y_2^{\prime\prime},Y_3^{\prime\prime}...Y_L^{\prime\prime}\}
AudioModality:YAUDIO={Y1,Y2,Y3,...YL}VedioModality:YVIDEO={Y1′,Y2′,Y3′,...YL′}TextualModality:YTEXT={Y1′′,Y2′′,Y3′′...YL′′}
然后,将得到的三种模态特征,两两融合。融合矩阵为:(τ和σ的值分别为τ = 1和σ = - 1?为什么?)
G
1
=
{
u
1
,
u
2
,
u
3
,
.
.
.
u
m
}
G
2
=
{
v
1
,
v
2
,
v
3
,
.
.
.
v
m
}
G
3
=
{
w
1
,
w
2
,
w
3
,
.
.
.
w
m
}
\begin{gathered} G_1=\begin{Bmatrix}u_1,u_2,u_3,...u_m\end{Bmatrix} \\ G_{2}=\begin{Bmatrix}v_{1},v_{2},v_{3},...v_{m}\end{Bmatrix} \\ G_3=\begin{Bmatrix}w_1,w_2,w_3,...w_m\end{Bmatrix} \end{gathered}
G1={u1,u2,u3,...um}G2={v1,v2,v3,...vm}G3={w1,w2,w3,...wm}
G 1 = τ Y A U D I O + σ Y V I D E O G 2 = τ Y A U D I O + σ Y T E X T G 3 = τ Y V I D E O + σ Y T E X T G_{1}=\tau Y_{AUDIO}+\sigma Y_{VIDEO}\\G_{2}=\tau Y_{AUDIO}+\sigma Y_{TEXT}\\G_{3}=\tau Y_{VIDEO}+\sigma Y_{TEXT} G1=τYAUDIO+σYVIDEOG2=τYAUDIO+σYTEXTG3=τYVIDEO+σYTEXT
u i = τ Y i + σ Y i ′ ′ ν i = τ Y i + σ Y i ′ w i = τ Y i ′ ′ + σ Y i ′ ′ u_{i}=\tau Y_{i}+\sigma Y_{i}^{\prime\prime}\\\nu_{i}=\tau Y_{i}+\sigma Y_{i}^{\prime}\\w_i=\tau Y_i''+\sigma Y_i'' ui=τYi+σYi′′νi=τYi+σYi′wi=τYi′′+σYi′′
实验分析
- 与现有方法相比,该方法在准确性、精度、召回率和F-measure等方面均优于其他方法。
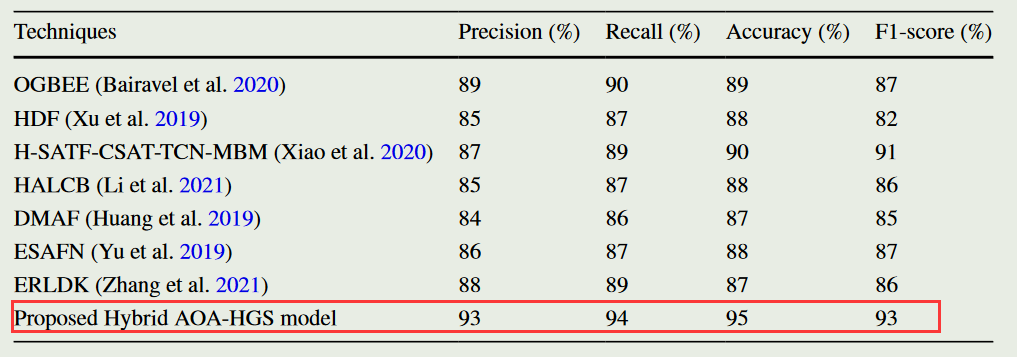
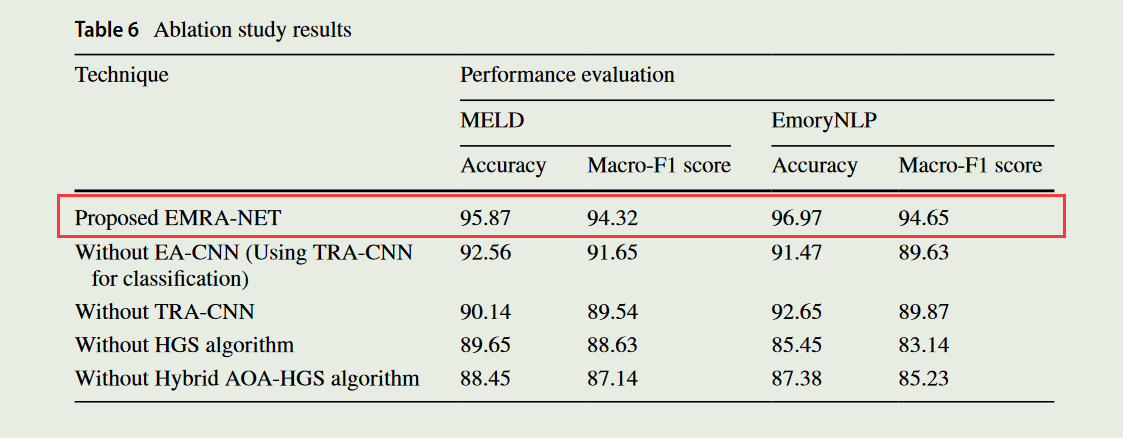
- 消融实验,测试了所提出模型的不同组成部分的有效性,包括Hybrid AOA-HGS、EA-CNN、HGS算法和TRA-CNN。结果表明,EA-CNN在预测最终结果方面起着主要作用,而去除EA-CNN部分会影响多模态情感分析结果并降低准确率。去除TRA-CNN会导致空间域特征丢失,从而降低准确率。去除HGS算法与混合AOA-HGS算法会显著影响性能并降低准确率。
补充知识
1.什么是多尺度?
多尺度,就是对信号的不同粒度的采样,通常在不同的尺度下可以观察到不同的特征,从而完成不同的任务。
如上两个图是同样的一维信号在不同采样频率下的结果,这是一条精度曲线。通常来说粒度更小/更密集的采样可以看到更多的细节,粒度更大/更稀疏的采样可以看到整体的趋势。

如上展示了3个尺度的图像,如果要完成的任务只是判断图中是否有前景,那么12×8的图像尺度就足够了。如果要完成的任务是识别图中的水果种类,那么64×48的尺度也能勉强完成。如果要完成的任务是后期合成该图像的景深,则需要更高分辨率的图像,比如640×480。
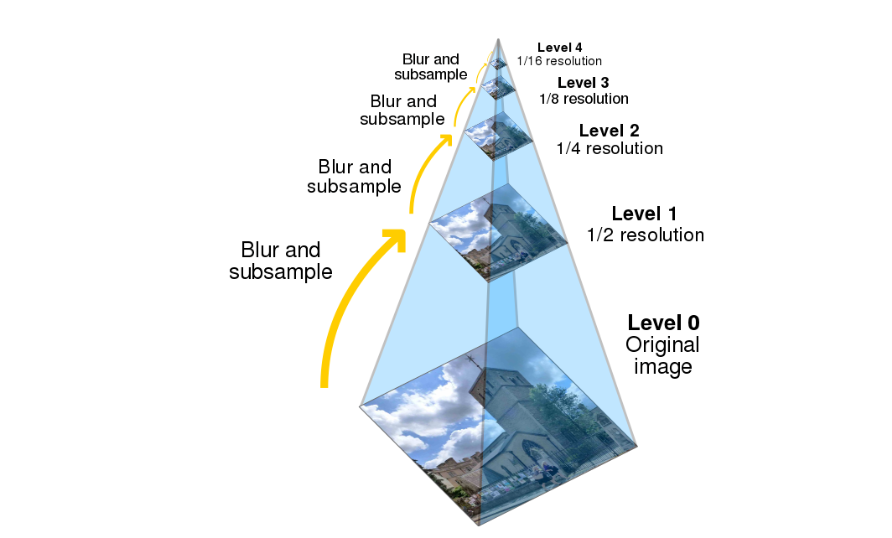
2.图像金字塔
金字塔是一种图像多尺度信号表示法,其中信号或图像要经过反复的平滑和二次采样。通过对原始图像进行多尺度像素采样的方式,生成N个不同分辨率的图像。把具有最高级别分辨率的图像放在底部,以金字塔形状排列。
两种采样方式:
- 升采样:分辨率逐渐升高,图像变大
- 降采样:分辨率逐渐下降,图像变小
3.小波金字塔
二维离散小波变换将二维图像分解为多尺度表达, 原图像可以由多尺度小波系数精确重建。
频域告诉我们场景里有什么东西,空域告诉在什么位置。高频往往对应的是边缘,所以相对于图像的低频成分来说,图像的高频成分的空间定位需求很高,不应该损失空间表达能力。对于低频的部分则要求频域的分辨能力更强。即,高频要求空域上的高分辨率,低频要求频域上的高分辨率。
4.子带编码
在子带编码中,一幅图像被分解成为一系列频带受限的分量,称为子带。子带可以重组在一起无失真地重建原始图像。每个子带通过对输入图像进行带通滤波而得到。

5.Res2Net 模块与ResNet区别

通俗的理解,就是将原来的resnet中间的3x3卷积换成了右侧红色部分,该部分最少是不经过3x3卷积,直接连接。最多会经过3个3x3的卷积,这样就能理解感受野比原结构多的原因了。再来讲一下里面的结构,经过1x1卷积之后,将特征图分成4部分。第一部分线路很简单,x1不做处理,直接传到y1;第二部分线路,x2经过3x3卷积之后分为两条线路,一条继续向前传播给y2,另一条传到x3,这样第三条线路就获得了第二条线路的信息;第三条线路、第四条线路,以此类推。
参考
- 【AI不惑境】深度学习中的多尺度模型设计
- 图像金字塔
- 形象易懂讲解算法I——小波变换
- 小波变化和多分辨率处理
- 图像处理的两种变换:2D-DWT和Gabor变换
- Res2Net:新型backbone网络,超越ResNet
😃😃😃



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









