






时间序列数据预测
什么是时序数据
时序数据,即时间序列数据,按时间维度顺序记录且索引的数据。像智慧城市、物联网、车联网、工业互联网等领域各种类型的设备都会产生海量的时序数据。这些数据将占世界数据总量的 90%以上。便于我们根据时间变化对数据进行分析。
时序数据,总的来说就是时间为x轴,y轴为观测数据变量。例如:股市价格走势、气温变化曲线。时序数据集各式各样,但基本上符合以下三点:
- 写入的数据是最新时间的数据
- 数据按照时间顺序排版
- 时间为X轴
在时序数据预测任务中,单单给出气温变化曲线,然后预测未来具体气温是非常困难且不准确的,往往需要多个时序数据共同计算,从而预测未来气温。例如:气温、气压、风向、湿度等,这样的多种数据集,称为多元时序数据,实际处理中也往往要处理多元时序数据。
基本预测方法
周期因子法
周期因子法,适合一些具备周期性的数据,例如:羽绒服购买数据、交通数据、客流量数据。这些数据周期性是非常明显的,根据周期性就可以预测未来数据。

根据每一周给出的过去数据,算出平均值,再除平均值得到每一周所有值的比例。
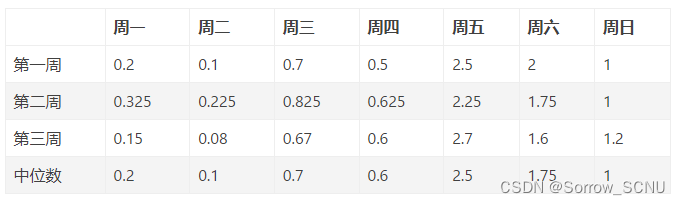
再根据每一天的比例,选择中位数的数值,例如,周一选择0.2、周二选择0.1。再乘以一周的评价值Base,得到未来一天预测的数值。

总的来说,周期因子法步骤如下:
- 计算周期因子factors
- 计算平均值base
- result = base * factors
线性回归
线性回归中,最经典的案例就是预测房价,给出不同房子的面积area、年龄age和价格price,同时给出一个新房子的area、age,预测这套新房子的price。
p r i c e = W a r e a ⋅ a r e a + W a g e ⋅ a g e + b price = W_{area} · area + W_{age} · age + b price=Warea⋅area+Wage⋅age+b
公式如上,不同的W表示 area 和 age 的权重,b为偏置项,权重表示每个特征值对结果的影响,在实际项目中,偏置项可为0可不为0,用于调整结果。在实际项目中,多个影响特征需要多个W权重,往往十分麻烦。我们需要利用矩阵来表示数据,将(x1, x2, , xn)表示为 X1
(w1, w2, ,wn)表示为W1。将两个向量相乘便可简化算出一条数据的结果。再将多个X向量组合成矩阵,同理操作W组成矩阵。
p
r
i
n
c
e
=
W
T
X
+
b
prince = W^TX + b
prince=WTX+b
基于此,线性回归的核心在于如何算出合适的W和b,这时需要利用损失函数进行计算。损失函数表示通过模型算出的预测值和真实值的差距,差距越小表示模型越精准。回归问题中,有许多常用的损失函数,最常用的是平方误差函数:
L
(
W
,
b
)
=
1
2
(
y
p
r
e
−
y
t
r
u
e
)
2
L(W,b)=\frac{1}{2}(y_{pre} - y_{true}) ^2
L(W,b)=21(ypre−ytrue)2
得到损失函数后,如何调整W和b呢?
W
1
=
W
0
−
α
J
(
W
0
)
W^1 = W^0 - αJ(W^0)
W1=W0−αJ(W0)
当W和b过大时,loss值也会很高,那么权重调整需要不能再往上涨,需要往相反方向移动,即梯度的反方向。同理,当W和b过小时,也要往相反方向移动。在逐步调整权重时,需要α限制移动步伐,步伐不能过大也不能过小,取值往往会采取前人经验提供值。
多次循环调整后,模型成功训练好,此时传入新的数据信息,我们便可预测需要的值。
传统时序建模
在传统时序建模方法中,常用的时AR、MA、ARIMA模型。
- AR(Autoregressive model),自回归模型,利用之前的一些数据,推测未来的数据,其核心思想公式如下:
X n = w 1 x 1 + w 2 x 2 + . . . . + w n − 1 x n − 1 + n o i s e X_n = w_1x_1 + w_2x_2+ ....+w_{n-1}x_{n-1} + noise Xn=w1x1+w2x2+....+wn−1xn−1+noise
实际项目中,很可能是最近几天的数据影响因子较大,因此不同的x会有不同的权重,同时会添加噪音noise,作用与偏置差不多,用于调整输出值。
AR的方式较为简易,只能预测简单模型,同时对数据集会有一些限制条件:
必须具有自相关,如果自相关系数®小于0.5,则不宜采用,否则预测结果极不准确。
只适用于预测与自身前期相关的现象,即受自身历史因素影响较大的现象,如矿的开采量,各种自然资源产量等;对于受外因影响较大的现象,不宜采用自回归,而应改采可纳入其他变数的向量自回归模型。
适用于宽平稳数据,其特性是序列的统计特性不随时间的平移而变化,即均值和协方差不随时间的平移而变化。
AR需要的数据是平衡的,最好是一条水平线上的轻微波动的数据,然而现实情况很少这类数据,大部分数据会上下波动,或是在一定区间内上涨或下降。明明符合逐步上升规律的简单数据,却无法利用AR模型,显然是值得优化的。对于这些数据,就需要进行差分处理。
差分:即差值,一阶差分是指当前数值减去前一个数值,得到的插值为一阶差分。二阶差分是指在一阶差分基础上,再进行相减差值操作。将简单的上涨数据,进行一阶差分处理后,便能得到一段平稳的数据。值得注意的一点是,每一次差分之后,都会少一个序列值
同时我们如何判断数据到底有没有平稳呢,目视是最简单但不靠谱的,我们需要一个合理的数学方法进行判定 ,即ADF检验平稳性。我们可以调用Python中tseries库引入ADF函数,我们认为,当输出的p-value值 > 0.05时,序列数据是不平稳的,需要进行进一步差分操作。直到p-value < 0.05,数据区域平稳。
-
MA(Moving average),移动平均模型,是算出近期一组数据的平均值,反映这组数据的趋势,用于预测未来数据。
当数据变动不规则,波动较大,可以用MA模型预测趋势。因此也可以理解为,MA模型是用来求数据的趋势曲线的。
我们知道,在实际数据处理中,往往会获得多元数据序列,同时一元数据序列也需要拆分提取。将一维数据分解成多维数据,毕竟不是所有数据都是有意义的,这就是MA和AR的区别。在AR模型中,我们是用前段时间的实际观察值进行拟合求解,得到预测值。而MA模型是用拆分后的白噪声数据进行拟合求解,来观察噪声值的振动,预测趋势。
y n = ω n + β n − 1 ω n − 1 + . . . + β 1 ω 1 y_n = ω_n +β_{n-1} ω_{n-1} + ... + β_1 ω_1 yn=ωn+βn−1ωn−1+...+β1ω1 -
ARIMA,差分整合移动平均自回归模型,该模型是将AR和MA的整合,根据不同数据类型,使用不同的模型。同时需要考虑数据的平稳性和价值,只有数据处理成平稳且非白噪声,才能调用模型,更好地预测结果。
在使用ARIMA模型前,我们需要判断数据地自相关性ACF和偏自相关性PACF,ACF更关注当前值与过去值的相关程度,PACF更关注残差的相关程度。
针对ACF和PACF的评价指标,分别有截尾和拖尾两种:截尾,在一个横轴位置后快速趋于0,呈现截断式;拖尾,慢慢趋向于0,同时会在0值附近随机波动。


数据处理的重点不是在于区分数据集呈现截尾还是拖尾,而是重点观测,在第几阶差分后,ACF和PACF呈现出尾巴。在实际处理中,观测是无法确定到底从第几阶差分就能视为出现尾巴了,我们需要进行单位根检测。与平衡性检测一样,调用函数取得结果,当d阶查分的p值小于0.05时,视为出现尾巴,再基于此根据不同尾巴类型进行下一步模型选择操作。
通过上述平稳性检测、白噪声检测、尾巴检测后,模型需要的参数还是不够的。因为ACF和PACF分别具体取哪一阶差分的值作为参数,对模型的结果是有很大差别的。我们需要找到一组**(p,q)**值,使得模型预测结果最好,该方法就是BIC\AIC指标法。
同样是根据封装好的函数,便可以获得不同p q的组合,导致模型的不同预测结果。我们在其中取得最小值的pq组合,就是我们需要的pq值。到此为止,ARIMI(p,d,q)模型便可以进行拟合,之后用于预测。
总的来说,ARIMA模型的基本流程如下:
- 数据预处理,包括处理多余数据,空白数据,拆分数据等。
- 差分操作,不断进行查分,直到数据符合平稳且具备价值,确定参数d。
- BIC\AIC准则,确定参数p,q。
- 拟合模型,预测结果。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









