







总结
爬虫
1. 访问网站,保存图片的方法
# 法一
import requests
url = 'https://dss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=3566088443,3713209594&fm=26&gp=0.jpg'
response = requests.get(url)
f = open('pic.png', 'wb')
f.write(response.content)
f.close()
# 法二
import requests
url = 'https://dss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=3566088443,3713209594&fm=26&gp=0.jpg'
response = requests.get(url)
with open('pic.png', 'wb') as f:
f.write(response.content)
# 法三
import urllib
url = 'https://dss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=3566088443,3713209594&fm=26&gp=0.jpg'
urllib.request.urlretrieve(url, 'pic.png')
2. 访问网址的url被编码问题
被访问网址的url被编码后是不能直接进行访问的,需要将url进行解码,将其还原成本来面目后才能访问。
import urllib.parse
url = 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735041519%2F1618485629%5F84828260%5F22420%5FsProdImgNo%5F1%2Ejpg%2F200'
original_url = urllib.parse.unquote(url)
print(original_url)
# 结果
# http://shp.qpic.cn/ishow/2735041519/1618485629_84828260_22420_sProdImgNo_1.jpg/200
3. 爬取网站内容时的翻页处理
法一:总结每一页网址的区别,找出规律,利用for循环实现翻页处理
# 动态替换每一页url的pn值,向每一页的url发起请求
# https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=0 第一页
# https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=50 第二页
# https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=100 第三页
from urllib import parse
name = input('请输入需要搜索的内容:')
start, end = [int(i) for i in input('请输入起始页和终止页,以逗号隔开:').split(',')]
url0 = 'https://tieba.baidu.com/f?ie=utf-8&'
kw = {'kw': name}
for i in range(start, end+1):
pn = 50 * (i - 1)
url = url0 + parse.urlencode(kw) + f'&pn={pn}'
res = request.urlopen(url).read().decode('utf8')
# print(res)
f = open(f'第{i}页.html', 'w', encoding='utf-8')
f.write(res)
f.close()
print('保存成功')
数据分析
打开文件报错
pandas.read_csv() 报错 OSError: Initializing from file failed,报错原因分析和解决方法
Python版本:Python 3.6
pandas.read_csv() 报错 OSError: Initializing from file failed,一般由两种情况引起:一种是函数参数为路径而非文件名称,另一种是函数参数带有中文。
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 4 09:44:36 2018
@author: wfxu
"""
import pandas as pd
da1=pd.read_csv('F:\\数据源')
da2=pd.read_csv('F:\\2.0 数据源\\工程清单.csv')
这两种情况报错信息都是一样:
Traceback (most recent call last):
(报错细节不展示)
File "pandas/_libs/parsers.pyx", line 720, in pandas._libs.parsers.TextReader._setup_parser_source
OSError: Initializing from file failed
对于第一种情况很简单,原因就是没有把文件名称放到路径的后面,把文件名称添加到路径后面就可以了。还可以在代码中把文件夹切换到目标文件所在文件夹,过程太繁杂,不喜欢也不推荐,所以就不做展示了。
第二种情况,即使路径、文件名都完整,还是报错的原因是这个参数中有中文,但是Python3不是已经支持中文了吗?参考了错误原因和pandas的源码,发现调用pandas的read_csv()方法时,默认使用C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错。所以在调用read_csv()方法时指定engine为Python就可以解决问题了。
da4=pd.read_csv('F:\\数据源\\工程清单.csv',engine='python')
对于第二种情况还有另外一种解决方法,就是使用open函数打开文件,再取访问里面的数据:
da3=pd.read_csv(open('F:\\4.0 居配工程监测\\2.0 数据源\\02.南京新居配工程清单.csv'))
好了这个报错的原因都了解了,解决方法也很简单粗暴,是不是很简短简单!
声明:
————————————————
版权声明:本文为CSDN博主「飞羽喂马」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35318838/article/details/80564938
matplotlib中plt.bar()绘制图形时不按照大小高低顺序显示
plt.bar(x,height)方法中,x指的是横轴的刻度,是一个数值,它有大小,会按照x的数值由小到大排列,它决定了height的顺序。它不会根据height数值的先后顺序来排列。
如下所示:
import numpy as np
import matplotlib.pyplot as plt
plt.bar(np.arange(1,5),[4,6,2,8])
plt.show()
绘制条形图时,x的数据如果是字符串,那么它会将字符串根据ASCII表排序后再进行绘图。所以有时候我们把height的数据按照大小顺序排好后绘制出的图形仍然是乱的。
如下所示:
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure(figsize=(16,6)
ax1 = plt.subplot(111)
ax1.bar(x=df2.iloc[:20,0],df2.iloc[:20,-1])
ax1.set_xlabel('商品')
ax1.set_ylabel('打折率')
plt.show()
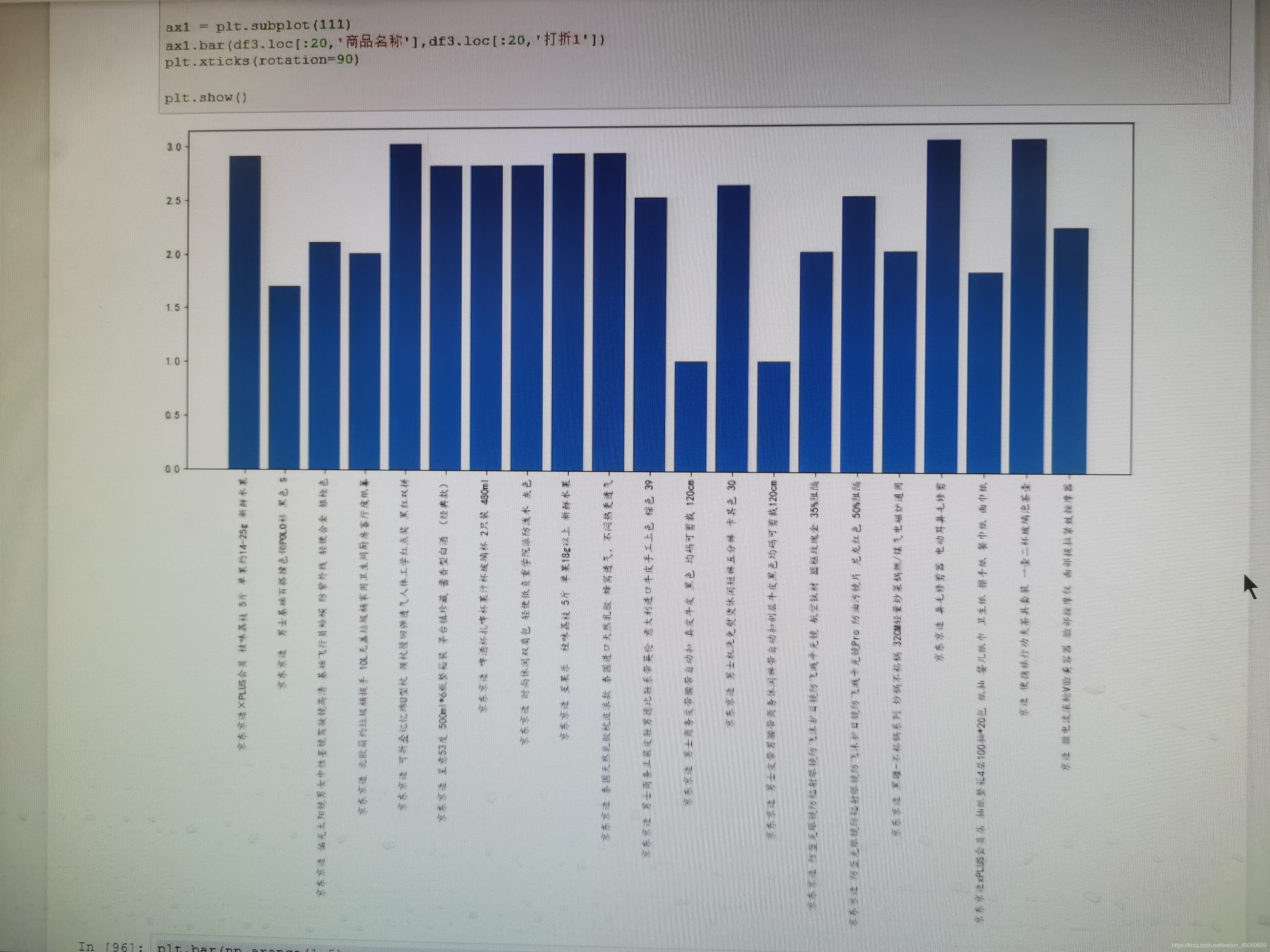
遇到这种情况的处理方法:
既然x指的是横轴的刻度,那么我们就得从刻度方面来考虑。首先我们将height的数据按照大小拍好顺序,用plt.bar()绘制图形,然后将横轴的数据用plt.xticks(loc,label)来对应就可以实现了。
如下所示:
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure(figsize=(16,6)
ax1 = plt.subplot(111)
ax1.bar(x=np.arange(20),df2.iloc[:20,-1])
plt.xticks(np.arange(20),df2.iloc[:20,0],rotation=90)
ax1.set_xlabel('商品')
ax1.set_ylabel('打折率')
ax2 = ax1.twinx()
ax2.plot(np.arange(20),df2.iloc[:20,-1])
plt.show()
注意:
- xticks是plt(pyplot)的方法,不是ax的方法,所以只能用plt.xticks(),不能用ax.ticks()
- plt.xticks(loc,label)这两个参数直接填入即可,不能使用loc=xxx, label=xxx,否则无法添加刻度标签。














 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









