






摘 要
穷游网酒店数据采集与可视化分析大屏的背景是为了满足用户对酒店数据的需求以及提供数据洞察和决策支持。随着旅游业的快速发展,人们对酒店信息的需求日益增加,而穷游网作为一家专注于旅游信息的网站,拥有丰富的酒店数据资源。
这个大屏的目的是通过数据采集和可视化分析,为用户提供全面、实时的酒店信息。它可以帮助用户快速了解酒店的位置、价格、评分、评论等细节信息,从而辅助用户做出更明智的预订决策。
通过Python Flask框架进行开发,实现以下功能:
数据采集:使用网络爬虫技术从穷游网等相关网站抓取酒店数据,并存储到数据库中,确保数据的实时性和准确性。
数据清洗和处理:对采集到的原始数据进行清洗和处理,去除重复、缺失或不准确的数据,以提高数据质量。
数据可视化:利用数据可视化技术,将酒店数据转化为直观、易于理解的图表、地图等形式,以便用户更好地理解和分析数据。
实时更新:数据采集和数据可视化都要保持实时性,确保用户获取的是最新的酒店信息。
这个大屏的用处在于为用户提供一个集中的、直观的酒店信息展示平台,帮助用户快速了解和比较不同酒店的特点和性价比,提供决策支持。同时,它也可以为酒店经营者和市场分析人员提供数据洞察,了解市场需求和竞争情况,从而做出优化和调整策略。
关键词:可视化大屏,酒店数据,Python,信息展示平台
引 言
在旅游业快速发展的背景下,人们对酒店信息的需求不断增加。为了满足用户的需求并提供数据洞察和决策支持,穷游网酒店数据采集与可视化分析大屏应运而生。通过数据采集和可视化分析,这个大屏能够为用户提供全面、实时的酒店信息,并帮助他们做出明智的预订决策。同时,大屏也为酒店经营者和市场分析人员提供了数据洞察和决策支持,帮助他们了解市场需求和竞争情况,从而做出优化和调整策略。总之,这个基于Python Flask的大屏为用户和酒店经营者提供了一个集中的、直观的酒店信息展示平台,具有重要的实用价值和商业意义。
1. 绪论
1.1 背景
在旅游业蓬勃发展的背景下,酒店成为旅行者重要的住宿选择之一。然而,由于酒店数量庞大、信息分散且更新频繁,用户往往难以快速准确地获取到满足自己需求的酒店信息。因此,建立一个穷游网酒店数据采集与可视化分析大屏具有重要的研究背景和意义。
首先,随着互联网技术的迅猛发展,用户对酒店信息的需求呈现出爆发式增长。用户希望能够通过一站式平台获取到全面、准确、实时的酒店信息,以便做出更明智的预订决策。而传统的酒店信息搜索方式存在信息分散、更新滞后等问题,无法满足用户的需求。
其次,数据采集和可视化分析技术的不断发展为酒店信息的获取和分析提供了新的解决方案。通过网络爬虫技术,可以从穷游网等相关网站实时抓取酒店数据,确保数据的准确性和实时性。同时,利用Python Flask框架进行开发,可以实现数据的清洗、处理和存储,为后续的可视化分析提供数据基础。
最后,数据可视化分析能够以图表、地图等形式将酒店数据直观地展示出来,帮助用户更好地理解和分析数据。同时,酒店经营者和市场分析人员也可以通过大屏获取数据洞察,了解市场需求和竞争情况,为优化经营策略提供依据。
1.2 系统功能和特点
基于Python Flask的穷游网酒店数据采集与可视化分析大屏具有以下系统功能特点:
数据采集:通过网络爬虫技术实时抓取穷游网等相关网站的酒店数据,确保数据的准确性和实时性。
数据清洗和处理:利用Python pandas库进行数据的清洗、处理和存储,确保数据的质量和可用性。
数据可视化:将酒店数据以图表、地图等形式直观地展示出来,帮助用户更好地理解和分析数据。
数据洞察和决策支持:为酒店经营者和市场分析人员提供数据洞察和决策支持,帮助他们了解市场需求和竞争情况,优化经营策略。
实时更新和监控:系统能够实时更新酒店数据,并提供监控功能,及时发现和处理数据异常和错误。
1.3 系统设计目的
通过此次设计设计目的是提供便捷的酒店信息获取途径,通过数据采集和整合,将穷游网等相关网站的酒店数据集中展示,为用户提供一站式的酒店信息获取途径,减少用户的搜索时间和精力。通过实时抓取和数据更新机制,保证酒店数据的准确性和实时性,帮助用户获取最新的酒店信息,做出更明智的预订决策。通过图表、地图等形式将酒店数据直观地展示出来,帮助用户更好地理解和分析数据,从而做出更准确的决策。提供数据洞察和决策支持,为酒店经营者和市场分析人员提供数据洞察和决策支持,帮助他们了解市场需求和竞争情况,优化经营策略,提升竞争力。
1.4 系统开发步骤
穷游网酒店数据采集与可视化分析大屏的系统开发步骤主要包括以下几个阶段:
数据采集与清洗:使用Python的爬虫技术,抓取穷游网等相关网站的酒店数据,并进行清洗和整理,确保数据的准确性和一致性。
数据存储与管理:选择合适的数据库,如MySQL,将清洗后的酒店数据存储起来,并建立相应的数据管理系统,方便后续数据的查询和更新。
可视化分析模块开发:利用Python的数据可视化库,如echarts等,开发数据可视化模块,将酒店数据以图表、地图等形式展示出来,提供直观的分析结果。
系统测试与优化:对系统进行全面的功能测试和性能测试,发现并解决存在的问题和bug,优化系统的响应速度和用户体验。
2. 需求说明
2.1 需求分析
基于Python Flask的穷游网酒店数据采集与可视化分析大屏的系统需求分析如下:
数据采集:系统需要使用爬虫技术,从穷游网等相关网站抓取酒店数据,并进行清洗和整理,确保数据的准确性和一致性。
数据存储与管理:系统需要选择合适的数据库,如MySQL,将清洗后的酒店数据存储起来,并建立相应的数据管理系统,方便后续数据的查询和更新。
数据可视化:系统需要使用Python的数据可视化库,如echarts等,将酒店数据以图表、地图等形式展示在大屏上,提供直观的分析结果。
实时更新:系统需要实现数据的实时更新功能,确保展示的酒店信息是最新的,可以通过定时任务或事件触发等方式来实现。
自动化展示:系统应该能够自动展示酒店数据的可视化结果,无需人工干预,以保证大屏的实时性和稳定性。
响应式设计:系统需要针对大屏的分辨率和显示效果进行适配,确保在不同分辨率下都能够正常显示数据可视化结果。
2.2 可行性分析
2.2.1 技术可行性
数据采集:Python有强大的爬虫库,如BeautifulSoup和Scrapy,可以用于抓取穷游网等相关网站的酒店数据。
数据清洗与整理:Python的数据处理库,如Pandas和Numpy,提供了丰富的功能和方法,可以对采集到的数据进行清洗和整理。
数据可视化:Python的数据可视化库,如echarts,可以将酒店数据以图表、地图等形式展示出来。
Web开发:Python的Flask框架能够快速构建Web应用程序,提供了路由、模板引擎和数据库等功能,方便开发大屏界面和数据管理系统。
2.2.2 经济可行性
Python是一种免费开源的编程语言,不需要额外购买昂贵的开发工具和库,降低了开发成本。
Flask框架简单易用,开发效率高,能够快速构建功能完善的Web应用程序。
使用开源库进行数据采集、清洗和可视化,避免了自行开发的繁琐和耗时,进一步降低了开发成本。
2.2.3 数据可行性
穷游网等相关网站提供了酒店数据的公开接口或网页,可以通过爬虫技术获取数据。
酒店数据通常包括酒店名称、地理位置、价格、评分等基本信息,这些信息可以满足数据可视化和分析的需求。
穷游网等相关网站的酒店数据通常会定期更新,能够保证数据的实时性和准确性。
3. 系统构架及开发工具简介
3.1 应用架构方式
3.1.1 Flask框架概述
Flask是一个基于Python的轻量级Web应用框架,具有简单、灵活和易用的特点。它提供了路由、模板引擎、数据库支持等功能,可以帮助开发者快速构建Web应用程序。
Flask的核心思想是"micro",即追求简洁和精简。它的设计哲学是让开发者能够自由选择和组合各种插件和库,以满足不同的需求。Flask本身只提供了最基本的功能,其他功能可以通过插件和扩展来实现。
在穷游网酒店数据采集与可视化分析大屏的项目中,Flask可以用于搭建Web界面,提供数据的展示和交互功能。通过Flask的路由功能,可以定义URL与视图函数的映射关系,实现页面的跳转和数据的加载。通过Flask的模板引擎,可以方便地渲染动态页面,将数据可视化结果呈现给用户。同时,Flask还提供了数据库支持,可以与MySQL或MongoDB等数据库进行交互,实现数据的存储和管理。
在穷游网酒店数据采集与可视化分析大屏的项目中,Flask框架扮演着重要的角色,能够帮助开发者快速搭建Web应用程序,并提供丰富的功能和扩展性,满足项目的需求。
3.1.2 系统体系结构
基于Python Flask的穷游网酒店数据采集与可视化分析大屏的系统体系结构主要包括数据层、数据处理层和应用层,如图1所示。
数据层:
数据采集:使用Python的爬虫库,如BeautifulSoup和Scrapy,从穷游网等相关网站获取酒店数据。
数据存储:将采集到的数据存储到数据库中,如MySQL,方便后续的数据处理和查询。
数据处理层:
数据清洗与整理:使用Python的数据处理库,如Pandas和Numpy,对采集到的酒店数据进行清洗、去重和整理,保证数据的准确性和一致性。
数据分析与计算:利用Python的数据分析库,如Pandas和Scikit-learn,对清洗后的数据进行统计和分析,提取有价值的信息和特征。
应用层:
Web开发:使用Python的Flask框架搭建Web应用程序,提供用户界面和数据的展示功能。
数据可视化:利用Python的数据可视化库,如echarts,将酒店数据以图表、地图等形式展示给用户。
整个系统的体系结构是一个典型的三层架构,数据层负责数据的采集和存储,数据处理层负责数据的清洗和分析,应用层负责Web开发和数据可视化。这种体系结构将系统的功能划分清晰,使得各个层次的功能能够独立进行开发和维护,并且能够灵活地进行扩展和优化。同时,通过Flask框架的支持,实现了数据的可视化展示,提高了用户体验和系统的实用性。
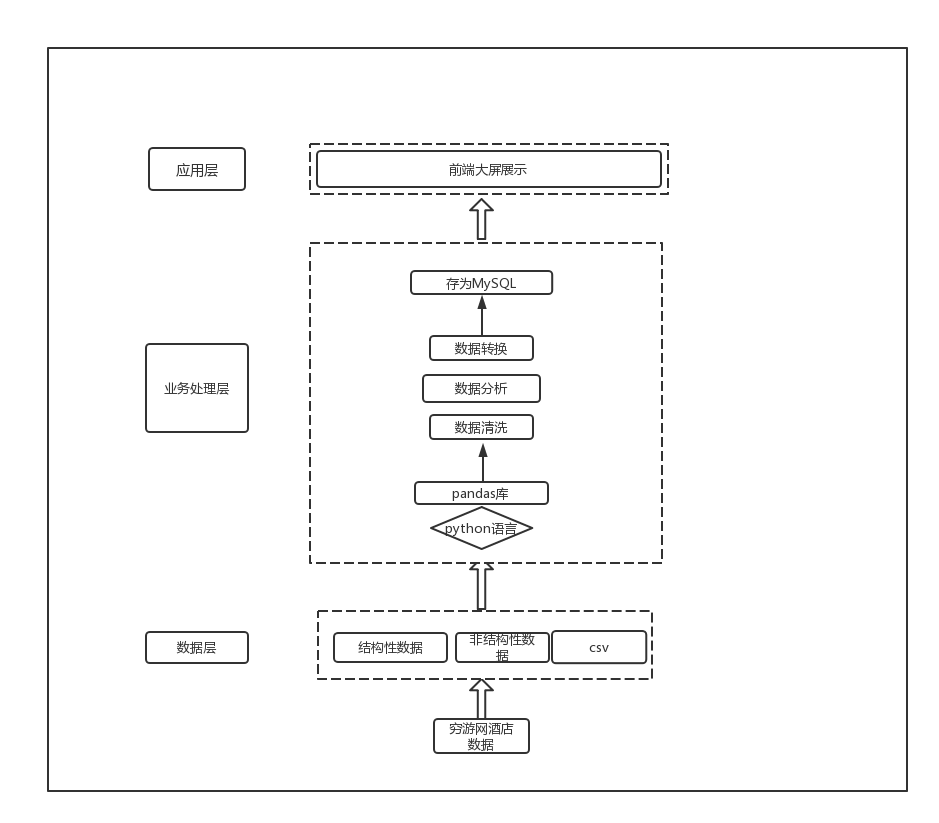
图1 系统体系结构
3.2 开发技术简介
3.2.1 Python简介
Python是一种高级编程语言,具有简洁、易读、易学的特点。它被广泛应用于数据分析、人工智能、Web开发等领域。在穷游网酒店数据采集与可视化分析大屏的开发中,Python提供了丰富的工具和库,使开发变得高效和便捷。
首先,Python拥有强大的数据处理和分析库,如Pandas和Numpy,可以对采集到的酒店数据进行清洗、整理和统计分析。同时,Python还拥有Scikit-learn等机器学习库,可以进行数据挖掘和预测建模,提取酒店数据的有价值信息。
其次,Python的爬虫库,如BeautifulSoup和Scrapy,可以方便地从穷游网等相关网站上采集酒店数据。这些库提供了强大的网页解析和数据提取功能,能够自动化地获取大量的酒店信息。
此外,Python的Web框架Flask提供了简洁而灵活的开发环境,可以快速搭建Web应用程序。Flask具有路由、模板引擎和数据库支持等功能,使开发者能够方便地实现页面的跳转、数据的加载和展示,并与用户进行交互。
3.2.2 MySQL简介
MySQL是一种常用的关系型数据库管理系统(RDBMS),被广泛应用于Web开发和数据存储领域。在穷游网酒店数据采集与可视化分析大屏的开发中,MySQL提供了可靠的数据存储和查询功能。
首先,MySQL具有良好的性能和稳定性,可以处理大规模数据的存储和管理。它支持高并发访问和事务处理,能够保证数据的一致性和完整性。
其次,MySQL提供了丰富的SQL语法和功能,方便数据的查询和操作。通过使用Python的MySQL库,可以在Python代码中直接执行SQL语句,实现对酒店数据的增删改查操作。
此外,MySQL还支持数据的备份和恢复,可以有效地保护数据的安全性。同时,它提供了多种存储引擎,如InnoDB和MyISAM,可以根据具体需求选择适合的存储引擎,提高数据的存储和查询效率。
4. 概要设计
4.1 系统具体功能
4.1.1 系统的整体功能模块
-
数据采集模块:使用Python的爬虫库进行网页数据的抓取和解析,从穷游网等相关网站上获取酒店的基本信息、价格、评分等数据,并将其存储到数据库中。
-
数据清洗与整理模块:使用Python的数据处理和分析库,如Pandas和Numpy,对采集到的酒店数据进行清洗、去重、缺失值处理等操作,保证数据的质量和准确性。
-
数据存储模块:使用MySQL等关系型数据库管理系统,将清洗后的酒店数据存储到数据库中,以便后续的查询和分析。
-
数据分析模块:使用Python的数据分析和可视化库,如echarts,对酒店数据进行统计分析和可视化展示,包括酒店价格的趋势分析、酒店评分的分布情况等。
-
大屏模块:使用Python Flask框架搭建Web应用程序,实现可视化展示。
4.1.2 系统整体界面设计
系统的大屏页面设计将酒店数据以图表、表格或地图等形式展示,使用户能够直观地了解酒店数据的分布和趋势。例如,设计一幅柱状图来展示各个城市的酒店数量,使用颜色深浅表示不同价位的酒店数量,以便用户可以快速了解各个城市的酒店分布情况。另外,设计一个折线图展示酒店价格的趋势,用户可以通过观察图表来了解酒店价格的变化。
页面设计还包括一些统计数据和关键指标的展示,例如酒店的平均评分、最低价格和最高价格等。这些指标以表格的形式呈现,方便用户快速查看。同时,设计一个地图来表示酒店评分的分布情况,用户通过颜色的深浅来了解评分的高低。
因此穷游网酒店数据采集与可视化分析大屏的系统页面设计主要以数据可视化为主,通过图表、表格和热力图等形式展示酒店数据的分布和趋势,让用户能够直观地了解酒店数据的情况。
4.2流程设计
4.2.1 数据采集流程
数据采集流程如图2所示。通过遍历城市列表,构建不同城市的URL,并发送请求获取响应数据。然后,从响应数据中解析出每个酒店的名称、城市、地址、评论数、价格、评分等信息,并将其存储在一个列表中。接着,调用存储函数将列表中的数据插入到数据库的表格中。
首先,在数据库中创建了一个名为"穷游网"的数据库,并在该数据库中创建了一个名为"酒店数据"的表格。然后,通过爬虫从指定的URL获取数据,根据城市和页数构建URL,并发送HTTP请求获取响应。接着,解析响应数据,提取出需要的酒店信息,并将其存储在一个列表中。最后,将列表中的数据逐条插入到数据库的"酒店数据"表格中。
整体流程是: 构建不同城市的URL-> 发送请求 -> 解析响应 -> 提取字段 -> 写入列表->存入MySQL数据库。通过这个流程,可以实现对穷游网酒店数据的采集与存储。
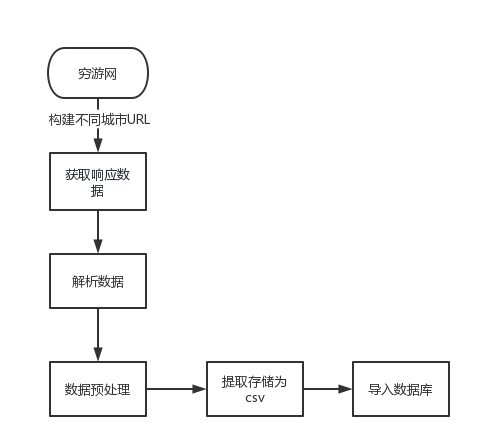
图2 数据采集流程
数据代码如下:
def chuangku():
# 连接数据库
conn = pymysql.connect(host="localhost", user="root", password="root",
port=3306,charset='utf8mb4')
try:
# 创建游标
cur = conn.cursor()
# 执行sql查询语句
cur.execute("drop database if exists 穷游网")
cur.execute("create database 穷游网")
print('数据库创建成功')
# 关闭游标
cur.close()
# 关闭数据库连接
conn.close()
except:
print('创建失败')
return True
def chuangbiao():
# 连接数据库
conn = pymysql.connect(host="localhost", user="root", password="root",
port=3306,db="穷游网")
try:
# 创建游标
cur = conn.cursor()
# 执行sql查询语句
cur.execute("drop table if exists 酒店数据")
cur.execute("create table if not exists 酒店数据 (酒店名 VARCHAR(255),城市 VARCHAR(255),地址 VARCHAR(255),评论数 int(11),价格 int(5),评分 float(5),评分等级 VARCHAR(25),穷游用户 int(5),星级 VARCHAR(25))")
# 关闭游标
print('数据表创建成功')
cur.close()
# 关闭数据库连接
conn.close()
except:
print('创建失败')
return True
def cun(list):
conn = pymysql.connect(host="localhost", user="root", password="root",
port=3306, db="穷游网")
# 创建游标
cur = conn.cursor()
# try:
# 执行sql查询语句
sql = '''insert into 酒店数据 (酒店名,城市,地址,评论数,价格,评分,评分等级,穷游用户,星级) values (%s, %s, %s, %s,%s, %s, %s, %s, %s)'''
cur.execute(sql, (list[0], list[1], list[2], list[3], list[4], list[5], list[6], list[7],list[8]))
conn.commit()
print('存入成功')
# except:
# print('存入失败')
return True
def pachong(url,city_0,ye):
for a in range(ye):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res=requests.get(url.format(city_0,a),headers=headers).json()
soup=res['data']['hotel']['data']['list']
for i in soup:
list_1=[]
name=i['cn_name']
city=i['address']
dizhi=i['around']
pls=i['comment_num']
price=i['price']
pf=i['score']
pldj=i['score_comment']
user=i['user_num']
star=i['star']
list_1.append(name)
list_1.append(city)
list_1.append(dizhi)
list_1.append(pls)
list_1.append(price)
list_1.append(pf)
list_1.append(pldj)
list_1.append(user)
list_1.append(star)
print(list_1)
4.2.2 数据处理流程
数据处理流程如图3所示。实现了简单的数据处理和清洗功能,并通过Flask框架提供了Web接口,方便用户访问和查看处理后的数据。
首先,使用Flask框架搭建了一个Web应用,并定义了多个路由函数。这些路由函数通过调用数据库工具类、SQLAlchemy等库来获取数据,并进行数据处理和清洗。
路由函数通过数据库查询语句从数据库中获取原始数据。然后,使用pandas库将查询结果转换为DataFrame对象,方便进行数据处理和清洗操作。接着,根据需要,对数据进行一系列的处理和清洗操作,如数据类型转换、数据筛选、缺失值处理等。
例如,在函数getjiaotong()中,首先读取数据库中的酒店数据并创建一个DataFrame对象。然后,根据需求,提取字符串中的数值,将其存储在新的列中。接下来,对新的列进行数据类型转换和处理,如将字符串转换为浮点数类型,并处理异常值。最后,根据指定的区间范围,将数据进行分组,并统计每个分组内的数量。最终,将统计结果转换为列表形式,并返回给前端页面。
整体数据处理流程:读取MySQL数据 -> 将数据转换为列表 -> 数据清洗和格式转换 -> 数据筛选 -> 统计结果转换为列表形式 -> 返回给前端页面 。
通过这个数据处理流程,实现了简单的数据处理和清洗功能,以便后续的可视化展示。
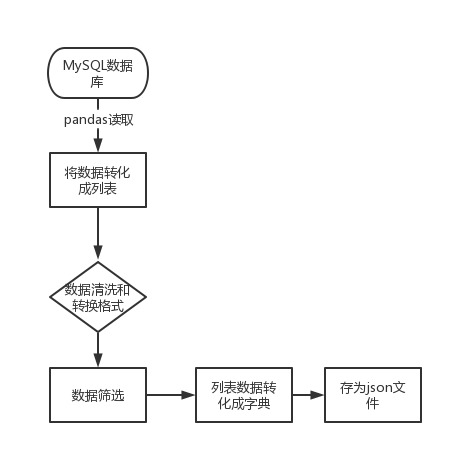
图 3 数据处理流程
数据处理代码如下:
def removenone(mylist):#移除参数中空值的函数
while '' in mylist:
mylist.remove('')
return mylist
def regnum(s):#提取爬取到的字符串中的数值
mylist = re.findall(r'[\d+\.\d]*', s)
mylist = removenone(mylist)
return mylist
def get_db_conn():
"""
获取数据库连接
:return: db_conn 数据库连接对象
"""
return DBUtils(host='localhost', user='root', password='root', db='穷游网')
def msg(status, data='未加载到数据'):
"""
:param status: 状态码 200成功,201未找到数据
:param data: 响应数据
:return: 字典 如{'status': 201, 'data': ‘未加载到数据’}
"""
return json.dumps({'status': status, 'data': data})
@app.route('/')
def index():
"""
首页
:return: index.html 跳转到首页
"""
return render_template('index.html')
@app.route('/getjobnum')
def get_job_num():
"""
获取个城市酒店数量
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(sql_str="SELECT 城市,COUNT(1) num FROM 酒店数据 GROUP BY 城市 ORDER BY COUNT(1) DESC LIMIT 10")
if results is None or len(results) == 0:
return msg(201)
if results is None or len(results) == 0:
return msg(201)
data = []
data1=[]
for r in results:
data.append(r[0])
data1.append(r[1])
data2 = {'name':data,'value':data1}
return msg(200, data2)
@app.route('/xingji')
def get_xing():
"""
获取个城市星级数量
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(sql_str="SELECT 星级,城市, COUNT(1) AS num FROM 酒店数据 WHERE (城市='上海' OR 城市='北京' OR 城市='广州' OR 城市='深圳' OR 城市='天津') AND 星级 IS NOT NULL AND 星级 > 2 GROUP BY 星级,城市 ORDER BY 星级,城市")
if results is None or len(results) == 0:
return msg(201)
if results is None or len(results) == 0:
return msg(201)
data1=[]
data0 = []
for r in results:
data1.append(r[1])
data0.append(r[2])
data2 = {'name':'三星','data':data0[:5]}
data3= {'name':'四星','data':data0[5:10]}
data4 = {'name': '五星', 'data': data0[10:15]}
data5=[]
data5.append(data2)
data5.append(data3)
data5.append(data4)
# data={'data':data5}
# print(data)
return msg(200, data5)
#
@app.route('/price')
def get_price():
"""
获取个城市星级价格
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(sql_str="SELECT 星级,城市, max(价格) AS num FROM 酒店数据 WHERE (城市='上海' OR 城市='北京' OR 城市='广州' OR 城市='深圳' OR 城市='天津') AND 星级 IS NOT NULL AND 星级 > 2 GROUP BY 星级,城市 ORDER BY 星级,城市")
if results is None or len(results) == 0:
return msg(201)
if results is None or len(results) == 0:
return msg(201)
data1=[]
data0 = []
for r in results:
data1.append(r[1])
data0.append(r[2])
data2 = {'name':'三星','data':data0[:5]}
data3= {'name':'四星','data':data0[5:10]}
data4 = {'name': '五星', 'data': data0[10:15]}
data5=[]
data5.append(data2)
data5.append(data3)
data5.append(data4)
# data={'data':data5}
# print(data)
return msg(200, data5)
@app.route('/getbing')
def get_com_bing():
"""
获取评分占比
:return:
"""
# engine = create_engine("mysql+pymysql://用户名:密码@127.0.0.1:3306/数据库名")
engine = create_engine('mysql+pymysql://root:root@localhost:3306/穷游网', encoding='utf8')
# 写一条sql
sql = 'select * from 酒店数据'
# 建立dataframe
df = pd.read_sql_query(sql, engine)
print(df)
df['评分']=df['评分'].astype('float')
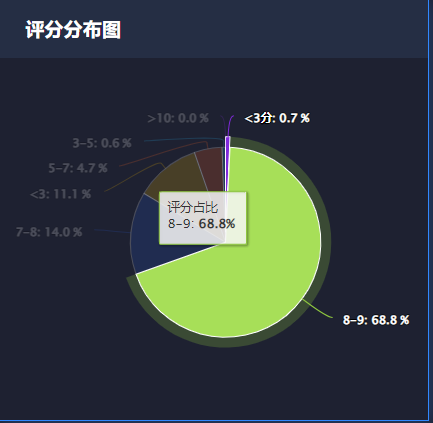
price_bin = pd.cut(df['评分'], bins=[0, 3, 5, 7, 8,9,10,15], include_lowest=True, right=False,
labels=['<3', '3-5', '5-7', '7-8', '8-9','9-10','>10'])
df_price = pd.value_counts(price_bin)
data_pair = [list(z) for z in zip(df_price.index.tolist(), df_price.values.tolist())]
data_pair[0]={'name': '<3分','y': 10,'sliced': True,'selected': True},
print(data_pair)
return msg(200, data_pair)
# return data_pair
@app.route('/getjiaotong')
def getjiaotong():
# engine = create_engine("mysql+pymysql://用户名:密码@127.0.0.1:3306/数据库名")
engine = create_engine('mysql+pymysql://root:root@localhost:3306/穷游网', encoding='utf8')
# 写一条sql
sql = 'select * from 酒店数据'
# 建立dataframe
df = pd.read_sql_query(sql, engine)
print(df)
df['最大距离'] = None
df['最小距离'] = None
for j in range(df.shape[0]):
try:
df.iloc[j, 9] = max(regnum(df.iloc[j, 2]))
df.iloc[j, 10] = min(regnum(df.iloc[j, 2]))
except:
df.iloc[j, 9] = 0.0
df.iloc[j, 10] = 0.0
print(df['最大距离'])
print(df.info())
df = df[~df['最小距离'].isin(["."])]
df['最大距离'] = df['最大距离'].astype('float')
price_bin = pd.cut(df['最大距离'], bins=[0, 2, 100], include_lowest=True, right=False,
labels=['<2', '>2'])
df_price = pd.value_counts(price_bin)
data_pair = [list(z) for z in zip(df_price.index.tolist(), df_price.values.tolist())]
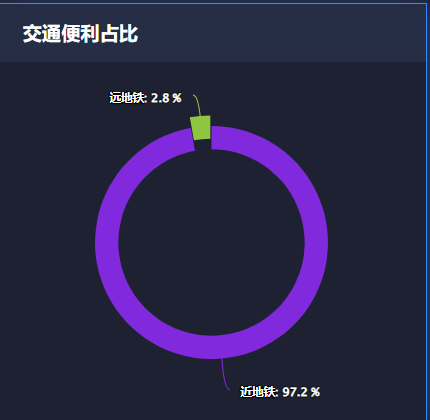
data_pair[0] = {'name': '近地铁','y':data_pair[0][1]}
data_pair[1] = {'name': '远地铁', 'y': data_pair[1][1],'sliced': True,'selected':True}
return msg(200, data_pair)
4.3 数据库库设计
数据库在整个管理系统中占有非常重要的地位 , 数据库结构设计的好坏将直接对系统的效率以及实现的效果产生影响。合理的数据库结构可以提高数据存储的效率 , 保证数据的完整和一致。在数据库建立时 , 大体上选建立一个总体的数据库存文件 , 以便统一调用数据库连接语句 。
4.3.1 穷游网酒店数据表设计
表1 酒店数据表表设计
| 字段名 | 类型 | 长度 | 注释 |
|---|---|---|---|
| 酒店名 | varchar | 255 | |
| 城市 | varchar | 255 | |
| 地址 | varchar | 255 | |
| 评论数 | int | 0 | |
| 价格 | int | 0 | |
| 评分 | float | 0 | |
| 评分等级 | varchar | 25 | |
| 穷游用户 | int | 0 | |
| 星级 | varchar | 25 |
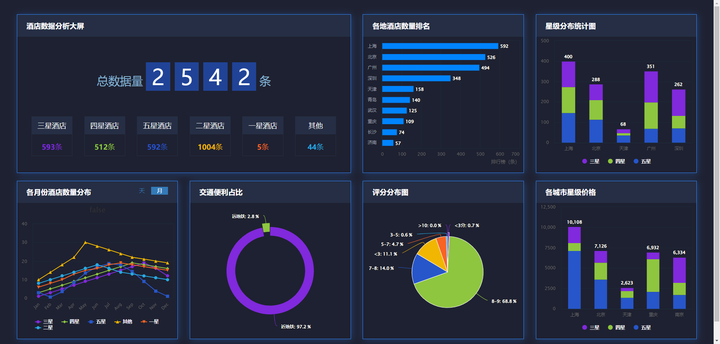
5. 详细设计
5.1 数据汇总
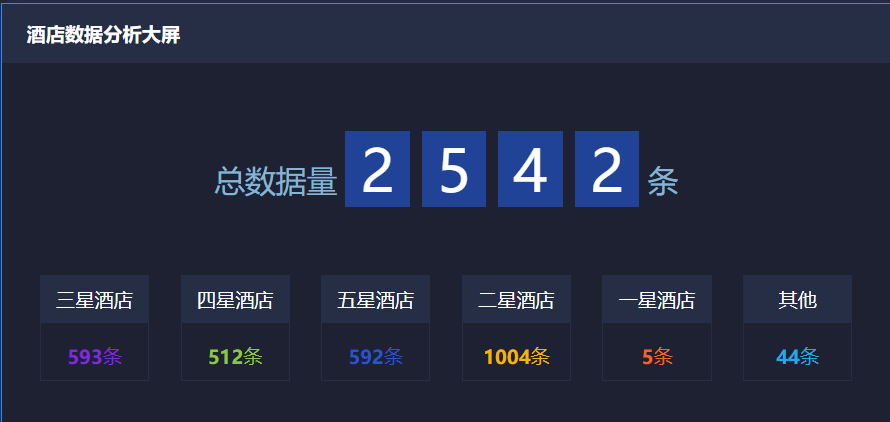
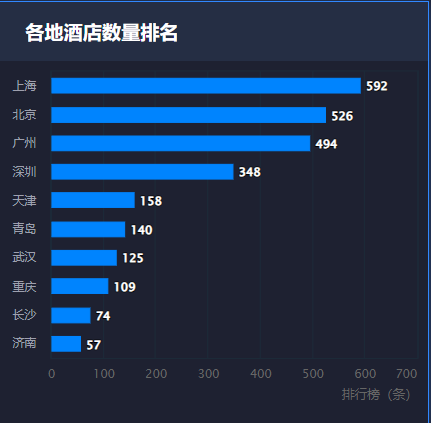
5.2 各地酒店数量排行
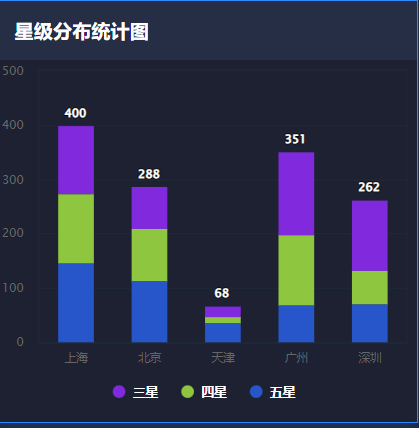
5.3 星级数量分析
5.4 交通便利占比
5.5 评分分布分析
5.6 完整大屏效果
6.总结
穷游网酒店数据采集与可视化分析大屏系统实现了酒店数据的采集、存储、处理和可视化展示功能,为用户提供了直观的酒店数据分析工具。通过该系统,用户可以快速了解酒店数据的分布情况、价格趋势和评分情况,帮助他们做出更好的旅行决策。
在实现过程中,我使用了Python Flask框架搭建了系统的后端,并结合数据库技术(如MySQL)进行数据的存储与查询。通过爬虫技术,我成功地从穷游网等网站上采集了大量的酒店数据,并将其存储到数据库中。同时,我运用数据分析和可视化工具(如Matplotlib、Seaborn等)对数据进行处理和可视化,通过图表、表格和热力图等形式直观地展示了酒店数据的分布和趋势。
在实践过程中,我深刻体会到了数据的重要性和数据分析的价值。通过对大量的酒店数据进行采集和分析,我们可以发现隐藏在数据中的规律和趋势,为用户提供有针对性的旅行建议。同时,数据可视化的技术也极大地提升了用户对数据的理解和使用效果,使其更加直观地了解酒店数据的情况。
然而,这个系统还存在一些不足之处。首先,系统的数据采集过程还需要进一步优化,以提高数据的准确性和完整性。其次,系统的可视化展示目前还偏向静态,缺乏用户交互的功能,例如用户无法根据自己的需求进行筛选和排序。此外,系统的性能和稳定性也需要进一步优化,以支持更大规模的数据处理和更高的并发访问。
展望未来,我希望进一步完善系统的功能和性能。首先,可以引入更多的数据源,并通过数据清洗和整合,提供更全面和准确的酒店数据。其次,可以增加用户交互功能,例如搜索、筛选和排序等,提升用户体验。另外,可以引入机器学习和预测模型,对酒店数据进行更深入的分析和预测,为用户提供更精准的旅行建议。最后,可以将系统部署到云端,实现分布式架构和高可用性,以应对更大规模的数据处理和更高的并发访问。
参考文献
[1] 牛作东,李捍东.基于Python与flask工具搭建可高效开发的实用型MVC框架[J].计算机应用与软件,2019,36(7):21-25.
[2]叶锋.Python最新Web编程框架Flask研究[J].电脑编程技巧与维护,2015(15):27-28.
[3] 钱志远.基于Web的Python编程环境研究[J].数字技术与应用,2016,34(10):54-54.
[4]谢韵佳.面向ECharts的高校学籍信息可视化研究[J].软件导刊,2019,18(12):271-276.
[5]管小卫.网络爬虫探讨及应用[J].科技创新与应用,2020(27):178-179.
[6] 赵文杰,古荣龙.基于Python的网络爬虫技术[J].河北农机,2020(8):65-66.
[7] 李相霏,韩珂.基于Flask框架的疫情数据可视化分析[J].计算机时代,2021(12):60-63.
[8] 李莉,杨旭.基于Python的Web开发框架研究[J].数码世界,2019,0(12):36-37.
[9] 燕妮,李岳松,郭史进,刘浩宇.基于Flask和爬虫的书籍循环平台的设计与实现[J].科技与创新,2021(17):1-3.
[10] 余晓帆,朱丽青.基于Flask框架的社交网站数据爬取及分析[J].微型电脑应用,2022,38(3):9-12.
[11] 于路遥,宋瑾钰.基于Python的天气信息可视化分析系统的设计与实现[J].软件工程与应用,2022,11(6):1394-1403.

















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









