









文章目录
基本信息:
论文标题:
作者:
机构:
论文链接:
URLs:
论文概述
本文提出了一种显式利用文本信息的方法,通过结合对比学习机制和文本编码器特征来学习更加鲁棒的特征表示。该方法通过文本引导的对比特征对齐技术,在跨模态、跨序列和跨站点等多种场景中评估了其有效性,并与现有文献中的方法进行了性能比较。
背景与动机
论文背景:
深度学习在医学图像分割中的应用受到训练和测试数据集之间领域偏移的影响,这限制了模型在不同临床环境中的可靠性和一致性。为了解决这一问题,研究者们探索了单源领域泛化(SDG)的方法,旨在训练能够在单一源域数据上泛化到未见过的目标域的网络。
过去方案
以往的SDG方法主要依赖于数据增强和特征适应技术来提高模型的泛化能力。然而,这些方法依赖于源域特定的视觉特征,可能导致过拟合,限制了模型泛化到新领域能力。
论文的Motivation
在医学图像分割领域,深度学习模型的泛化能力常常受到训练和测试数据集之间领域偏移的影响。这种偏移通常是由于成像方式、设备特性和扫描协议等数据采集过程的差异造成的,这被认为是将这些模型临床部署的主要障碍。为了克服这些挑战,研究者们提出了单源领域泛化(SDG),这是一种实用的方法,旨在训练能够在单一源域数据上训练并有效泛化到未见过的目标域的网络。
核心方法:
a. 理论背景:
该方法基于对比学习理论,通过文本编码器特征引导的对比学习机制来学习更加鲁棒的特征表示。
b. 技术路线:
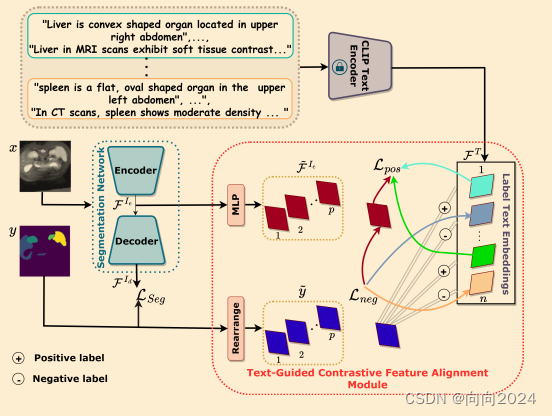
研究者们首先使用预训练的CLIP文本编码器将来自ChatGPT的标签描述转换为文本特征表示。然后,通过文本引导的对比特征对齐(TGCFA)模块,将这些文本特征与图像特征进行对齐,以增强模型的泛化能力
1、文本引导的对比特征对齐(Text-Guided Contrastive Feature Alignment):该方法通过使用预训练的CLIP文本编码器将标签描述映射到文本特征表示,并通过对比学习机制来增强图像和文本编码器表示之间的对齐。这种方法不仅能够减少对领域偏移和虚假相关性的敏感性,而且能够通过文本信息来增强视觉特征。
2、模型结构:该方法采用了一个编码器-解码器网络作为分割的主干网络,并引入了TGCFA模块来提取来自真实标签的类级信息,以指导图像表示学习,使得学习到的视觉特征更接近于正类文本嵌入。
3、多模态对比学习:该方法通过结合文本特征和图像特征,使得模型能够优先考虑临床上下文而非误导性的视觉相关性。这有助于将特定的文本特征映射到相应的视觉模式。
c.核心贡献:
1、提出了一种通过集成文本引导的对比特征对齐模块来增强SDG方法的新方法,该方法提供了一种与领域无关的视角,通过将视觉特征与文本信息结合起来,减少了对领域偏移和虚假相关性的敏感性。
2、方法是一种补充性方法,可以无缝集成到任何分割网络中,无需架构修改。
3、在包括跨模态、跨序列和跨站点设置在内的多种挑战性场景中评估了文本引导的对比特征对齐方法,并在分割不同解剖结构方面取得了有利的性能。
实验结果
a. 详细的实验设置
实验在跨模态腹部、跨序列心脏和跨站点眼底数据集上进行。使用了U-Net和EfficientNet-b2作为分割网络的主干网络,并在不同的分辨率和学习率下进行了训练。
b. 详细的实验结果
实验结果表明,与现有的SDG方法相比,本文提出的方法在所有三个问题设置中均取得了一致的性能提升。特别是在MRI-CT泛化任务中,该方法显著提高了器官边界的精确定位和划分。
总结
本文通过结合文本信息和视觉特征,有效地解决了医学图像分割中的单源领域泛化问题,提高了分割的鲁棒性。文本引导的对比特征对齐方法在包括跨模态、跨序列和跨站点设置在内的具有挑战性的临床场景中表现出显著的改进。
缺陷和不足
尽管该方法取得了显著的改进,但仍可能存在一些局限性。例如,该方法可能依赖于高质量的文本描述和预训练的文本编码器。此外,对于没有足够文本描述的解剖结构或疾病状态,该方法可能需要进一步的调整和优化。
可以进一步改进的点:
1、探索更多的文本信息来源和生成方法,以提高模型对不同医学图像的理解。
2、研究如何减少对预训练文本编码器的依赖,可能通过自监督学习方法来提高模型的泛化能力。
3、在更多的临床数据集上验证该方法的有效性,并探索其在实际临床环境中的应用潜力。
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











