






jdk的下载 oracle官网地址:
Java Downloads | Oracle![]() https://www.oracle.com/java/technologies/javase-downloads.html
https://www.oracle.com/java/technologies/javase-downloads.html
hadoop的下载 官网地址:http://hadoop.apache.org/releases.html![]() http://hadoop.apache.org/releases.htmlzookeeper的下载 Zookeeper镜像地址:Index of /apache/zookeeper
http://hadoop.apache.org/releases.htmlzookeeper的下载 Zookeeper镜像地址:Index of /apache/zookeeper![]() https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/hbase的下载 hbase的镜像地址:Index of /apache/hbase
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/hbase的下载 hbase的镜像地址:Index of /apache/hbase![]() https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/
本文安装版本如右图所示:
版本冲突问题请参考:Centos Linux 单机安装 HBase 、使用 HBase - 寒水馨 - 博客园 (cnblogs.com)
一、JDK的安装
1.文件夹创建
进入到自己的系统指定一个安装目录 cd /opt/software/java,将下载好的jdk的包放到/opt/software/java 路径下并解压

![]()
文件夹创建命令 mkdir 要创建的文件名
解压命令 tar -xvf jdk-8u144-linux-x64.tar.gz
2.配置环境变量
vim /etc/profile #如果没有安装vim命令请先输入 sudo apt install vim
在文件末尾添加以下配置 注:JAVA_HOME=安装的jdk的目录
export JAVA_HOME=/opt/software/java/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export JRE_HOME=$JAVA_HOME/jre
export PATH=${JAVA_HOME}/bin:$PATH
最后使配置文件生效
source /etc/profile
3.检验是否安装成功
输入java -version 检查是否配置成功 出现如下信息则为配置成功

二、Hadoop的伪分布式安装配置
1.配置SSH免密登录
sudo apt-get install openssh-server
2.登录在退出ssh localhost
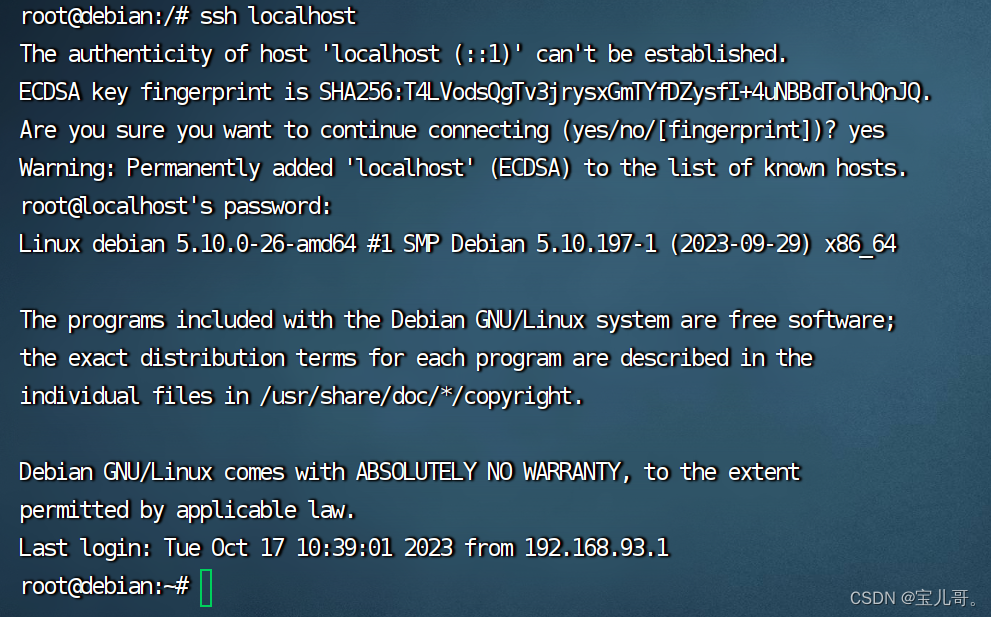

3.配置无密码登录
cd ~/.ssh/ #若没有该目录,请执行一次ssh localhost
ssh-keygen -t rsa #使用rsa算法生成密钥和公钥对,按三次Enter就可以了
cat ./id_rsa.pub >> ./authorized_keys #把公钥加入到授权中
ssh localhost #重新登录,此时就不需要密码了
参考如下图所示:

4.解压文件
解压到/opt/software/hadoop/
tar -xvf hadoop-3.3.6.tar.gz
5.检查是否安装成功
安装目录下执行 bin/hadoop version 出现以下如图所示:表示安装成功

6.修改配置文件
由于Hadoop默认模式为非分布式模式(本地模式 ),无需进行其他配置即可运行,这里只介绍伪分布式配置方法。
进入此目录 cd /opt/software/hadoop/hadoop-3.3.6/etc/hadoop
a.打开core-site.xml
vim core-site.xml
将<configuration></configuration>修改如下配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/software/hadoop/hadoop-3.3.6/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
b.打开hdfs-site.xml
vim hdfs-site.xml
将<configuration></configuration>修改如下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop/hadoop-3.3.6/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop/hadoop-3.3.6/tmp/dfs/data</value>
</property>
</configuration>
c.打开hadoop-env.sh
vim hadoop-env.sh
找到#export JAVA_HOME= 语句修改或直接在空白处添加为如下
![]()
返回Hadoop主目录格式化NameNode
cd /opt/software/hadoop/hadoop-3.3.6
./bin/hdfs namenode -format
7.以上成功配置hadoop伪分布式后
a.在/opt/software/hadoop/hadoop-3.3.6/sbin路径下的start-dfs.sh,stop-dfs.sh两个文件顶部添加参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
b.在start-yarn.sh,stop-yarn.sh两个文件顶部添加参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
8.启动hadoop
启动命令 ./sbin/start-dfs.sh 注:如需start-all.sh启动,请参考别的配置方法。启动不一样,配置方法也不一样。

使用jps查看进程,出现:DataNode、NameNode、SecondaryNameNode表示启动成功

在虚拟机的浏览器输入localhost:50070出现以下界面
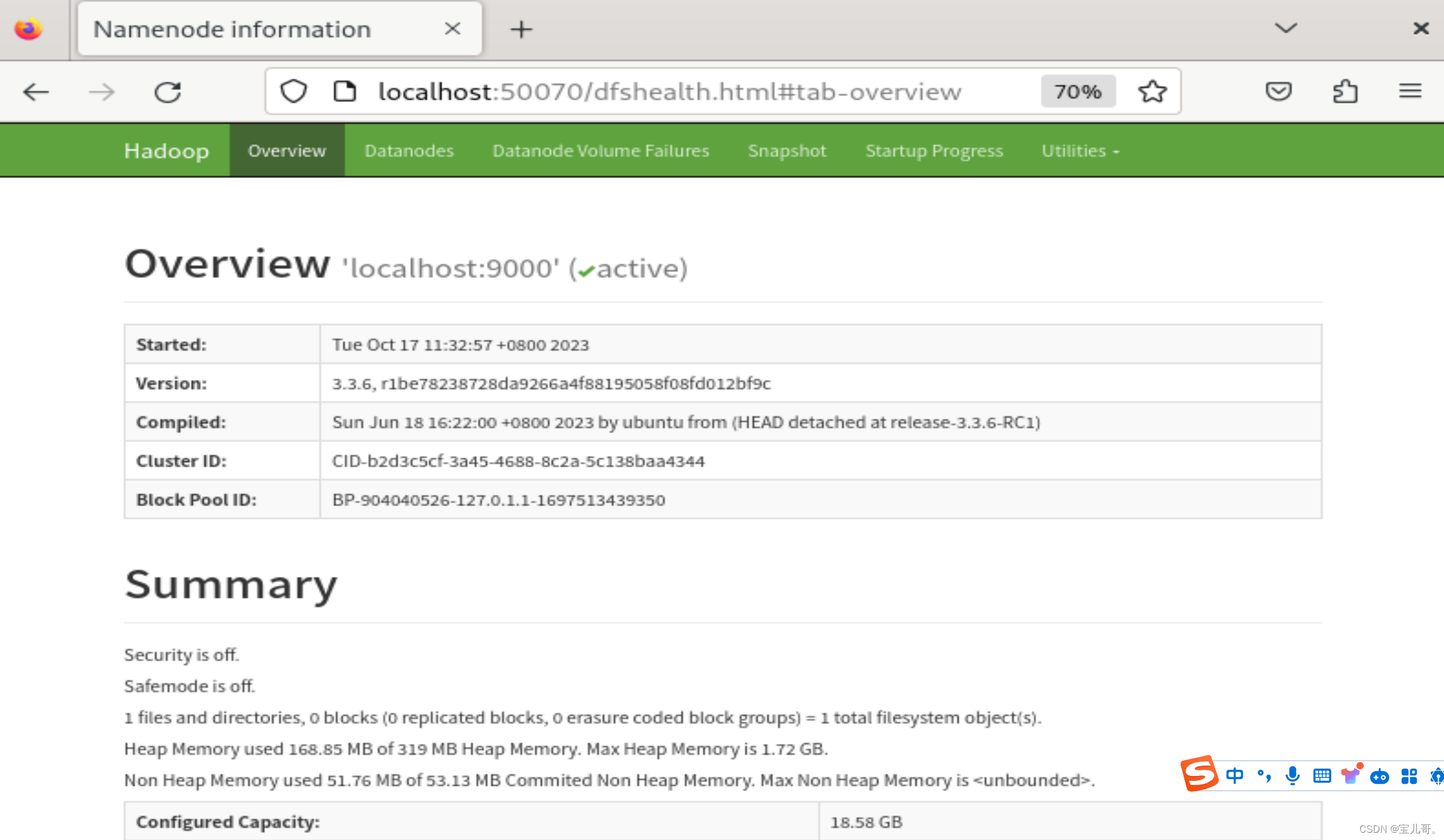
建议只格式化一次,否则namenode和datanode的clusterID会不一致报错。无奈只能重新安装,如有好方法,评论区推荐。
三、Zookeeper的单体安装
1.解压文件
tar -xvf apache-zookeeper-3.7.2-bin.tar.gz
2.配置环境变量
vim /etc/profile 文件最底下添加 之后输入 source /etc/profile使其生效
export ZOOKEEPER_HOME=/opt/software/zookeeper/apache-zookeeper-3.7.2-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
3.创建文件夹
在zookeeper下创建文件夹zkData mkdir zkData
4.修改配置文件
进入 cd /opt/software/zookeeper/apache-zookeeper-3.7.2-bin/conf 目录
执行cp zoo_sample.cfg zoo.cfg 命令并编辑 vim zoo.cfg 只需要将dataDir后面换成上一步创建的目录即可,其他可以不用修改,如需要修改,根据个人情况修改。
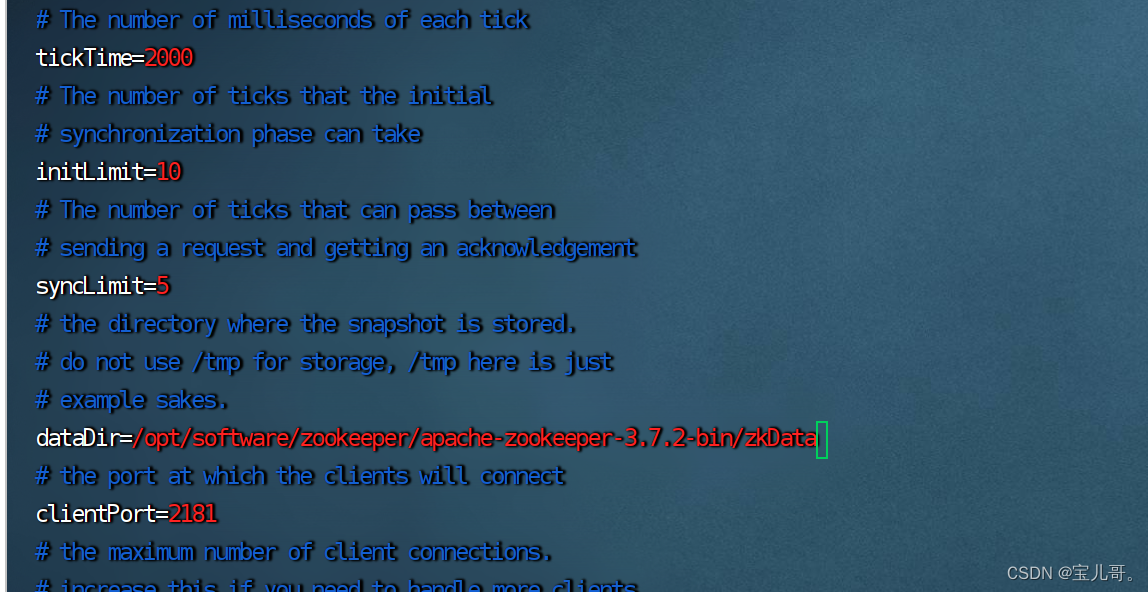
5.启动zookeeper
cd /opt/software/zookeeper/apache-zookeeper-3.7.2-bin
bin/zkServer.sh start 启动命令
bin/zkServer.sh stop 关闭命令

6.验证是否连接成功
输入 bin/zkCli.sh -server localhost:2181 验证是否连接成功,如图所示表示成功

四、Hbase的伪集群安装
1.解压文件
tar -xvf hbase-2.4.17-bin.tar.gz
2.配置hbase环境变量(同上Zookeeper一样)
export HBASE_HOME=/opt/software/hbase/hbase-2.4.17
export PATH=/$PATH:/$HBASE_HOME/bin
3.修改hbase的配置文件
a.打开hbase-site.xml
将<configuration></configuration>修改如下配置
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.master</name>
<value>master:16000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost:2181</value>
</property>
</configuration>
b.打开hbase-evn.sh vim hbase-env.sh 什么都别管,直接在空白处添加
export JAVA_HOME=/opt/software/java/jdk1.8.0_144
export HBASE_MANAGES_ZK=false
4.接着就到了最最最重要的。
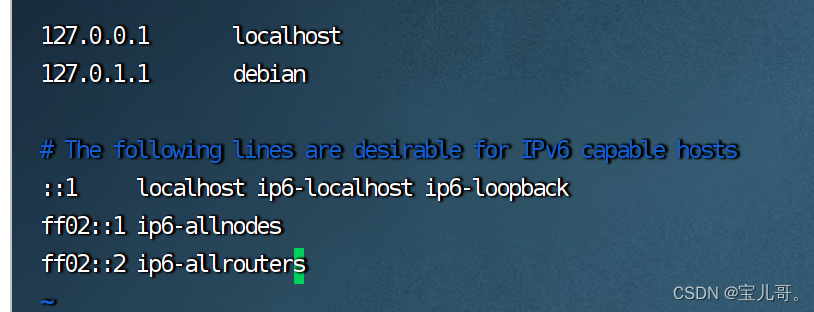
设置hosts文件。 vim /etc/hosts
添加master的ip地址 127.0.0.1 master
并且将把127.0.1.1 debian 替换 192.168.93.128 debian
由左图变右图:

保存退出后执行 /etc/init.d/networking restart 出现以下提示则成功

5.启动hbase
注:启动前先启动hadoop-zookeeper-hbase
cd /opt/software/hbase/hbase-2.4.17
bin/start-hbase.sh
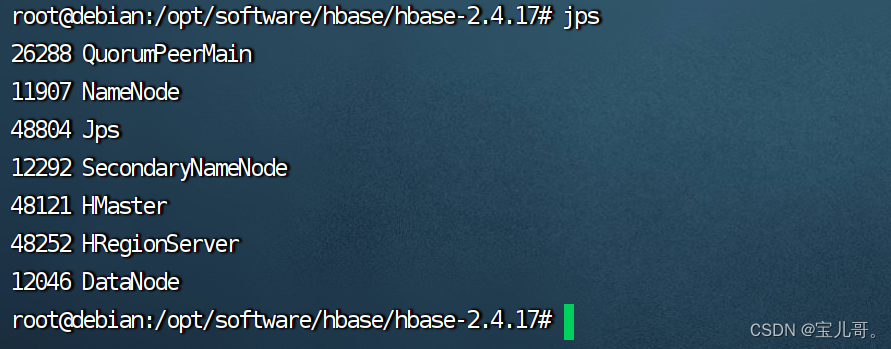
6.jps查看全部进程
HMaster HRegionServer 如有此两项代表启动成功
接着在虚拟机的浏览器输入master:16010出现以下页面表示cg

扩展:
windows连接虚拟hbase时需要操作两步
1.配置hadoop的环境变量(hadoop可以下载人家处理过的,如何下载请自行查询喽)
2.在hosts里添加 跟虚拟机hosts添加的一样的配置 192.168.93.128 debian
后续在将扩展编写成java api连接hbase 以及springboot连接hbase 相关文章,拜拜!
















 6698
6698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









