






多进程是什么?
进程:系统中正在运行的一个应用程序。
它有什么特点?
1个CPU核心职能执行1个进程,其它进程就处于阻塞状态 。多个CPU核心就可以同时执行N个任务。
线程是什么?
进程中包含的执行单元
它有什么特点?
1个进程可包含多个线程
1次只能执行1个线程
线程锁(资源竞争问题)
有很多的场景中的事情是同时进行的,比如开车的时候 手和脚共同来驾驶汽车,再比如唱歌跳舞也是同时进行的
(凡是程序一上线程,那么复杂度就提升了,出BUG的频率也就提升了)

一、线程的创建,有2种方式:
import threading
(1)通过函数:threading.Thread(函数对象)
使用threading模块当中的一个Thread类,调用 threading.Thread 之后,会创建一个新的线程,参数 target 指定线程将要运行的函数function,args 和 kwargs 则指定function函数的参数。
import threading
import time
def demo():
# 子线程
print('hello 我是子线程')
if __name__ == '__main__':
for i in range(5):
t = threading.Thread(target=demo)
time.sleep(1)
t.start()
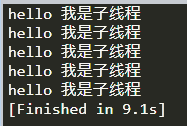
结果:
(2)通过类;
自定义一个类,并继承父类 threading.Thread ,再重新run()方法
import threading
import time
class A(threading.Thread):
def run(self):
for i in range(5):
print('hello 我是子线程')
if __name__ == '__main__':
a = A()
a.start()
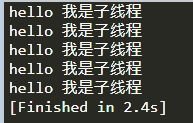
结果:
1、主线程会等待子线程结束之后再结束
import time
import threading
def demo1():
for i in range(5):
print('hello everybody')
time.sleep(1)
if __name__ == '__main__':
t = threading.Thread(target=demo1)
t.start()
print(1)
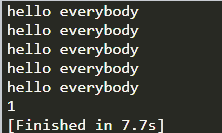
结果:(主线程在打印1后应该结束,但没有结束)

2、join():等待子线程执行结束之后,主线程再继续执行
import time
import threading
def demo1():
for i in range(5):
print('hello everybody')
time.sleep(1)
if __name__ == '__main__':
t = threading.Thread(target=demo1)
t.start()
t.join() # 等待子线程执行结束之后再执行
print(1)
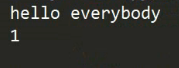
结果:
3、setDaemon(True) : 守护进程,即主线程不会等待子线程结束
import time
import threading
def demo1():
for i in range(5):
print('hello everybody')
time.sleep(1)
if __name__ == '__main__':
t = threading.Thread(target=demo1)
t.setDaemon(True) # 守护进程
t.start()
print(1)
结果:
4、enumerate()查看线程的数量
enumerate()的一般应用:
enumerate()在线程中的使用:threading.enumerate()

第1个print(threading.enumerate()),当前只有一个主线程;
第2个print(threading.enumerate()),仍然只有一个主线程;(因为t.start() 才是表示线程demo1创建并执行)
第3个print(threading.enumerate()),有2个线程,一个是主线程,一个是线程demo1
5、线程中的全局变量
(1)在函数内部修改全局变量
a = 20
def fn():
a = 10
print('函数内部:','a =',a)
fn()
print('函数外部: a =',a)

‘’
(2)线程中的全局变量:线程之间共享全局变量
import threading
import time
num = 100
def demo1():
global num
num += 1
print('demo1-num-%d' % num)
def demo2():
print('demo2-num-%d' % num)
def main():
t1 = threading.Thread(target=demo1,name='demo1')
t2 = threading.Thread(target=demo2,name='demo2')
t1.start()
t2.start()
print('main-num-%d' % num)
if __name__ == '__main__':
main()
结果:(线程demo1执行后,全局变量num的值是101)

二、线程间的资源竞争
使用threading模块当中的一个Thread类,调用 threading.Thread 之后,会创建一个新的线程,参数 target 指定线程将要运行的函数function,args 和 kwargs 则指定function函数的参数。
一个线程写入,一个线程读取,没问题,如果两个线程都写入呢?

当argv设置大值时,

解决方法:有2种
(1)sleep强制性的等线程1完全结束后,再执行线程2

或者用join(),会比sleep()更快;

(2)线程锁:threading.Lock()
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为"锁定",其他线程不能改变,直到该线程释放资源,将资源的状态变成"非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
第一步:创建一个线程锁,lock = threading.Lock()
第二步:上锁,lock.acquire()
第三步:解锁,lock.release()

三、线程队列
from queue import Queue #从库里导入类
q=Queue() #实例化对象,既然是对象,那就有方法。
队列的特点:先进先出
常见的队列方法:
empty() 判断队列是否为空,True代表是空的
full() 判断队列是否满了,True代表队列满了
get() 从队列当中取出数据
put() 将一个数据添加到队列当中

为了防止程序长时间的没有反应,

我们设置一个超时时间timeout,

或者用put_nowait()

四、案例应用对比
1、普通方式爬取小米应用信息
需求:爬取 小米应用商城中聊天社交应用的信息 应用的名称 应用的类别 应用的详情页的url 并且 翻页爬取


第一步 页面分析
我们发现数据不在网页的源码当中 证明数据是动态加载的 ajax加载的数据

解决方案: 1 、分析真正的数据接口 2 、通过selenium来爬取数据
(我们用的第1种)
我们右键检查-network-刷新-并翻页后,发现requests的数量在增加;

并在XHR中,发现有几个是很相似的,如下图:

我们点开第一个,可以发现有displayName:LOFTER,预示着我们可能找对方向了。
在Preview中data下,有更全的信息:

由此,我们复制Headers中的url地址(之后我们确定了这就是目标url),新页面中打开(需要提前加载好扩展程序jsonview,方法后面补充),得到:

由此,我们可以得到每个应用的目标信息;我们打开一个应用的下载地址,可以看到:

再打开另一个应用的下载地址,可以确定,就是后缀的不同。
以上,我们就确定了目标url是:https://app.mi.com/categotyAllListApi?page=0&categoryId=2&pageSize=30(相应的要将其中的page=0,一直替换到66)
import requests
import time
import random
from fake_useragent import UserAgent
class XiaomiSpider():
def __init__(self):
self.url = 'https://app.mi.com/categotyAllListApi?page={}&categoryId=2&pageSize=30 '
# self.headers = {
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
# }
# 获取响应内容
def get_html(self,url):
headers = {'User-Agent':UserAgent().random}
html = requests.get(url,headers=headers).json()
#print(html)
self.parse_html(html)
# 解析响应内容
def parse_html(self,html):
item = {}
for app_dict in html['data']:
item['app_name'] = app_dict['displayName']
item['app_type'] = app_dict['level1CategoryName']
item['app_link'] = 'https://app.mi.com/details?id=' + app_dict['packageName']
print(item)
def main(self):
for page in range(67):
url = self.url.format(page)
self.get_html(url=url)
# 控制一下抓取的频率
time.sleep(random.randint(1,2)) # n = random.randint(1,2) 1 <= n <= 2
if __name__ == '__main__':
x = XiaomiSpider()
x.main()
结果:

2、多线程爬取
知识点:

import threading
from queue import Queue
import time
q=Queue()
q.put(1)
q.put(2)
q.put(3)
q.put(4)
q.put(5)
def parse_html():
a=q.get()
print(a)
for i in range(4): #创建了4个线程,每个线程轮流启动
t=threading.Thread(target=parse_html) #每个线程的作用是,从q中取出一个数并打印,该线程便结束。
t.start()
print(t)
问题:如何取出第5个数?
答案是在target=parse_html函数中,无限循环。

程序没有finish提示结束的原因是,主线程在等待子线程结束后再结束,而子线程无限循环地在空队列中取数,将一直挂着,不结束。所以要注意防范当队列被取空以后,再向该空队列取数时,被一直挂着的情况。

可以在get中添加一个参数:timeout=3(即3秒取不到数,将报错)
那么要怎样才出现finish呢?有2种方式,如下图:
(1)当线程中的目标函数不是无限循环模式时:

(2)当线程中的目标函数是无限循环模式时:t.setDaemon(True),也可以解决上述(1)的问题。

或者:

补充:
(1)

也就是说,上图中,for循环没有循环下去,只有子线程1成功创建并启动。
那么要如何修改呢?

(2)

解决办法:

原因:如果线程里每从队列里取一次,但没有执行task_done(),则join无法判断队列到底有没有结束,在最后执行join()是等不到结果的,会一直挂起。
可以理解为,每task_done一次 就从队列里删掉一个元素,这样在最后join的时候根据队列长度是否为零来判断队列是否结束,从而执行主线程。

又见下面的案例。
import requests
import time
import random
import threading
from queue import Queue
from fake_useragent import UserAgent
class XiaomiSpider():
def __init__(self):
self.url = 'https://app.mi.com/categotyAllListApi?page={}&categoryId=2&pageSize=30'
#创建队列
self.q = Queue()
#创建线程锁
self.lock = threading.Lock()
def url_in(self):
#将目标url放到队列当中
for page in range(67):
url = self.url.format(page)
self.q.put(url)
#线程的事件函数 获取url 请求 解析 处理
def parse_html(self):
while True: #无限循环,是为了让线程循环下去
# 上锁
self.lock.acquire()#线程间有竞争,假设最后一个url,一下个线程已进行到28行,而下一个线程又判断不是空,就会堵塞
if not self.q.empty():
url = self.q.get()
# 解锁
self.lock.release()
headers = {'User-Agent': UserAgent().random}
html = requests.get(url, headers=headers).json()
item = {}
for app_dict in html['data']:
item['app_name'] = app_dict['displayName']
item['app_type'] = app_dict['level1CategoryName']
item['app_link'] = 'https://app.mi.com/details?id=' + app_dict['packageName']
print(item)
else:
self.lock.release()
break
def run(self):
self.url_in()
t_lst = []
for i in range(5):
t = threading.Thread(target=self.parse_html)
t_lst.append(t)
t.start()
if __name__ == '__main__':
spider = XiaomiSpider()
spider.run()
# JSONDecodeError 抓取频率太快了 页面没有及时返回
补充:
1、chrome浏览器扩展程序
第一步,下载好程序包,永久的放在桌面;
第二步,加载已解压的扩展程序。

2、import json 和 requests模块当中的 response.json(),效果是一样的。
(1)import json是python内置的json模块提供的,和requests库没关系。
import json
import requests
response = requests.get(url)
data1 = json.loads(response.text)
(2)requests库提供的
import requests
response = requests.get(url)
data2 = response.json()














 4857
4857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









