






总结如下:
1.order by 不管reduces设置成几个,都只会执行一个
2.sorte by 只能在一个reduces内排序,并且只对第一列排序
每个Reducer内部进行排序,对全局结果集来说不是排序。可以看到每个reduce task (分区)内部是有序排列的。
3.distributre by 分区排序
Distribute By在全排序是没有意义的,因为都是一个分区;所以才结合sort by来使用
分区和排序都是在shuffle阶段完成,分区是在map task阶段的shuffle完成,排序是在map task 和reduce task里完成;
例子:
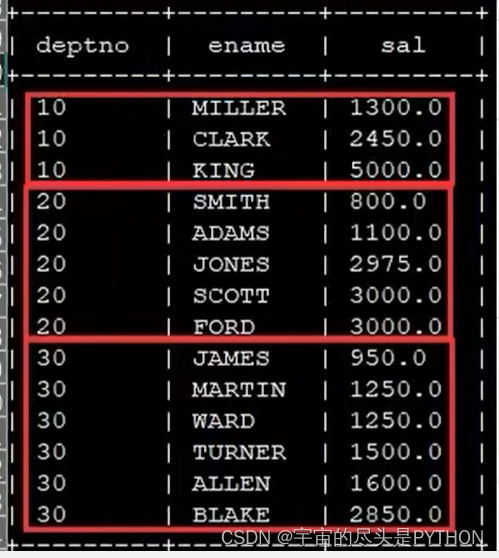
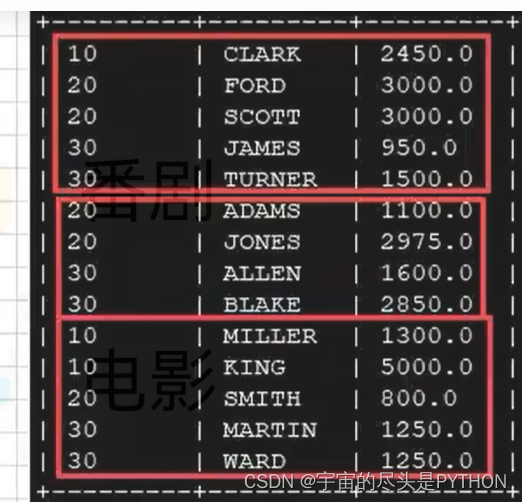
先按照部门编号分区,再按照员工编号降序排序。
set mapreduce.job.reduces=3
insert into overwrite local directory '/root/soft/sortby-result'
row format delimited fields
terminated by '\t'
select * from emp distribute by deptno -- 部门编号
sorte by empno desc;
注意:overwrite 这个自动删除指定的目录:
执行完了之后会生成三个文件,因为是三个reduce task
4 cluster by
当 distribute by 和 sorte by 是同一个字段的时候就等价于 cluster by
cluster by = distribute by + sort by 只能默认升序
即
```sql
select * from emp custer by deptno ;
select * from emp distribute by deptno sort by deptno ;
展开说明:
order by 有案例如下:
select deptno
,ename
,sal
from emp
order by
deptno
,sal
;
-- (不管reduces设置成几个,都只会执行一个)
set mapreduce.jobs.reduces;
set mapreduce.jobs.reduces = 3;
-- 等价于
select deptno
,ename
,sal
from emp
distribute by
deptno
sorte by
sal;
reduces可以设置成多个,效率有提升
sorte by 只能跟一个列,跟两个列是没有效果的。
select deptno ,ename, sal
from emp
sorte by deptno, sal;
加的第二列是没有效果的 。
只能在一个reduces内排序,并且只对第一列排序。
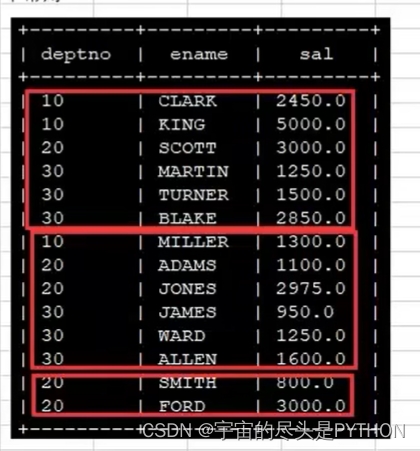
来源材料2:
使用sorte by 的话,需要将reduce task 设置大于1 , 一个reduce task 就是一个分区,每个reduce内部排序,对全局结果集来说不排序。
1 设置reduce个数
set mapreduce.job.reduces=3;
2.根据部门编号降序查看员工信息
select *
from emp
sort by empno desc ;
这样执行完了你会发现数据都是乱的,没有什么效果…
需要将数据导出到文件里面才能看到效果
-- 将查询的语句导入到指定文件里面
insert overwrite local directory '/root/soft/sortby-result' row format delimited fields terminated by '\t'
select * from emp sort by sal desc;
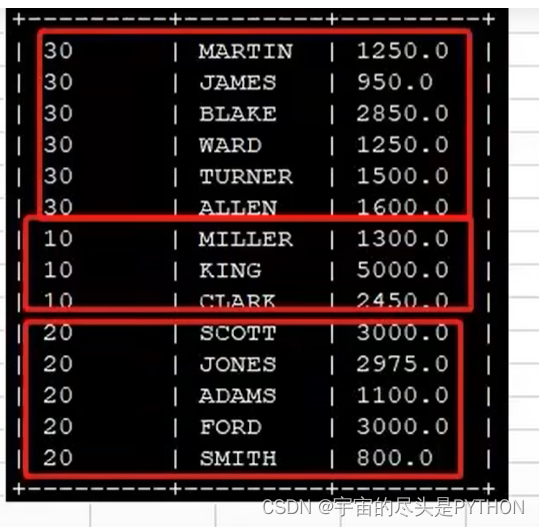
此时linux的/root/soft下会生成一个sortby-result文件夹,因为启动了三个reduce task任务,依次查看这三个文件里的内容,可以看到每个reduce task (分区)内部是有序排列的。
[root@zjj101 soft]# cd sortby-result/
[root@zjj101 sortby-result]# ls
000000_0 000001_0 000002_0
[root@zjj101 sortby-result]# pwd
/root/soft/sortby-result
[root@zjj101 sortby-result]#
[root@zjj101 sortby-result]# ls
000000_0 000001_0 000002_0
[root@zjj101 sortby-result]# cat 000000_0
7839 KING PRESIDENT \N 1981-11-17 5000.0 \N 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 \N 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 \N 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 \N 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
[root@zjj101 sortby-result]# cat 000001_0
7566 JONES MANAGER 7839 1981-4-2 2975.0 \N 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 \N 10
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 \N 20
7900 JAMES CLERK 7698 1981-12-3 950.0 \N 30
[root@zjj101 sortby-result]# cat 000002_0
7902 FORD ANALYST 7566 1981-12-3 3000.0 \N 20
7369 SMITH CLERK 7902 1980-12-17 800.0 \N 20
[root@zjj101 sortby-result]#
第4种 cluster by
当 distribute by 和 sorte by 是同一个字段的时候 ,
select deptno ,ename, sal
from emp distribute by deptno sorte by deptno ;
就等价于 cluster by
select deptno ,ename, sal from emp cluster by deptno ;
cluster by 后面可以接2个参数,但是意义不大。
select deptno ,ename, sal from emp cluster by deptno ,sal;
sotre by 和 cluster by 在后面的over()窗口函数中有真正的涉及。














 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









