






边缘计算与CDN的融合架构确实非常精妙,它通过将计算能力下沉到网络边缘,与传统的内容分发网络结合,显著提升了应用的响应速度、降低了带宽成本,并有效保障了系统的可靠性。
一、核心融合架构:“云-边-端”协同
边缘计算与CDN的融合本质上是构建了一个“云-边-端”三级协同的分布式系统。其整体运作流程和核心组件可以用下图来概括:
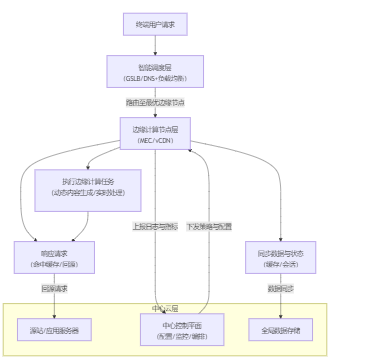
该架构的核心价值在于:
- 边缘侧:处理实时性、高并发请求,承担计算、缓存和加速职能。
- 云端:作为大脑,负责全局调度、状态同步、策略下发和数据持久化。
- 终端:获得低延迟、高可用的服务体验。
二、关键算法体系
融合架构的高效运行依赖于一系列核心算法。
-
智能调度与负载均衡
- 基于地理位置与网络状态的调度:通过解析用户IP获取其大致地理位置,并结合实时网络延迟(如RTT)、丢包率、节点负载(CPU、内存、带宽使用率)等指标,利用加权轮询或一致性哈希算法,将用户请求定向至最优的边缘节点。其目标函数可抽象为:寻找节点 i,使得 argmin( α·Distance(user, i) + β·Load(i) + γ·Latency(user, i) ),其中α, β, γ为权重系数。
- 任意播(Anycast):多个地理分布的边缘节点对外宣告相同的IP地址。BGP路由协议会根据网络拓扑,自动将用户的请求引导到“最近”的(跳数最少)节点。这天然实现了负载均衡和DDoS抵抗。
-
数据同步与一致性保障
- 缓存一致性:这是核心挑战。边缘节点缓存的数据可能与源站不同步。常用策略包括:
- TTL(生存时间):为每个缓存对象设置一个过期时间,到期后自动回源验证。简单但可能滞后。
- 主动失效(Purge):当源站数据更新时,主动向所有边缘节点发送缓存失效命令,或通过发布-订阅模型(如Redis Pub/Sub)通知节点更新。
- 分布式会话与状态同步:在边缘节点处理有状态请求(如购物车、用户会话)时,需在节点间同步状态。可采用一致性哈希将同一用户请求固定到特定节点,或在节点间使用低延迟的分布式缓存(如Redis Cluster)共享状态。
- 缓存一致性:这是核心挑战。边缘节点缓存的数据可能与源站不同步。常用策略包括:
-
边缘计算任务分发与管理
- 函数即服务(FaaS):将业务逻辑(如个性化推荐、A/B测试、数据过滤)封装为一个个无状态函数。通过事件驱动(如HTTP请求、消息队列)触发在边缘节点执行。关键在于冷启动优化和函数副本的智能放置,使函数更靠近需要它的事件源。
- 动态编排:中心控制器根据全局资源状态和请求预测,通过装箱算法(Bin Packing) 或基于机器学习的需求预测,动态决定将哪个函数副本部署到哪个边缘节点,以实现资源利用率和延迟的最优平衡。
三、代码体系与关键技术实现
下面是一些关键技术的简化代码示例,帮助你理解其实现思路。
-
智能调度算法(Nginx Lua示例)
智能调度是融合架构的“交通指挥官”,它通过综合决策,将用户请求引导至最合适的边缘节点。-- 基于地理位置和负载的调度策略 (Nginx Lua示例) -- 定义:使用Nginx的Lua模块,根据用户IP定位和边缘节点负载情况,智能选择最优节点 -- 输入:用户请求 -- 输出:定向至最优边缘节点 -- 关键函数:get_geo_info()获取地理位置,get_node_list()获取节点列表,select_node_by_load()基于负载选择节点 -- 参考:基于中智能调度算法思想 -- 在Nginx的access阶段执行 access_by_lua_block { -- 获取用户IP local user_ip = ngx.var.remote_addr -- 解析用户IP的地理位置(可集成第三方GeoIP库) local geo_info = get_geo_info(user_ip) -- 假设该函数返回用户所在区域,如"us-west" -- 获取该区域可用的边缘节点列表 local node_list = get_node_list(geo_info.region) -- 假设该函数从中心配置获取节点列表 -- 根据节点负载(如CPU、连接数)、健康状态等指标,选择最优节点 local target_node = select_node_by_load(node_list) -- 假设该函数返回负载最轻的节点地址 -- 执行内部重定向到选定的边缘节点 ngx.exec(target_node) }这只是一个概念性示例。在实际生产环境中,调度逻辑通常更复杂,并可能由专门的全局负载均衡器(GSLB)或DNS来完成。
-
边缘数据同步(Redis Pub/Sub示例)
保持边缘节点数据新鲜是核心挑战,发布-订阅模式是常见的解决方案。# 边缘数据同步策略 (Python Redis Pub/Sub示例) # 定义:利用Redis的发布订阅功能,在源站数据变更时通知所有边缘节点,确保缓存一致性 # 输入:源站数据更新事件 # 输出:边缘节点缓存失效或更新 # 关键方法:publish()发布消息,subscribe()订阅消息,set()更新缓存 # 参考:基于中数据同步机制 import redis # 中心云:当源站数据更新时 def publish_update(key, new_value): r_center = redis.Redis(host='center-redis', port=6379, db=0) # 1. 更新中心数据库 r_center.set(key, new_value) # 2. 发布变更消息到频道 'cache_invalidation' r_center.publish('cache_invalidation', f'{key}:{new_value}') # 边缘节点:订阅频道,监听变更 def subscribe_updates(): r_edge = redis.Redis(host='edge-redis', port=6379, db=0) p = r_edge.pubsub() p.subscribe('cache_invalidation') for message in p.listen(): if message['type'] == 'message': # 解析收到消息,格式为 "key:new_value" data = message['data'].decode().split(':') key, value = data[0], data[1] # 更新边缘节点的本地缓存 r_edge.set(key, value)此示例展示了最终一致性模型。对于需要强一致性的场景,请求需直接路由到中心或使用更复杂的分布式共识协议。
-
边缘函数处理(简化FaaS示例)
边缘函数处理是计算下沉的核心,允许在边缘节点动态执行业务逻辑。// 边缘函数处理 (JavaScript 简化示例) // 定义:在边缘节点执行轻量级函数,处理请求或数据,实现个性化逻辑 // 输入:用户请求或事件 // 输出:处理后的响应 // 关键步骤:接收请求、执行函数逻辑、返回结果 // 参考:基于中边缘计算逻辑动态部署思想 // 一个简单的边缘函数,用于个性化内容处理 async function handleEdgeRequest(request) { // 1. 尝试从边缘缓存获取用户信息或页面片段 const cachedData = await edgeCache.get(request.userId); if (cachedData) { // 缓存命中,直接返回个性化内容 return renderResponse(cachedData); } // 2. 缓存未命中,执行轻量级逻辑(如组装个性化页面) const userProfile = await fetchUserProfile(request.userId); // 可能从中心获取 const personalizedContent = generateContent(userProfile); // 本地生成内容 // 3. 将结果存入边缘缓存,并设置短期TTL(如10秒) await edgeCache.set(request.userId, personalizedContent, { ttl: 10 }); return renderResponse(personalizedContent); } // 边缘节点接收请求,调用函数处理 server.use(async (ctx, next) => { ctx.body = await handleEdgeRequest(ctx.request); });实际生产中,会使用专门的边缘计算平台(如AWS Lambda@Edge, OpenWhisk或者kubeEdge)来提供安全、隔离的函数运行环境。
四、典型应用场景
- 实时视频流与转码
视频流在边缘节点进行实时转码(如使用FFmpeg),适配不同设备(手机、PC)的码率和格式,极大减轻中心源站压力,降低端到端延迟。 - 物联网(IoT)数据处理
海量IoT设备产生的数据在边缘节点进行实时过滤、聚合和预处理(如计算平均值、判断阈值告警),仅将有价值的结果上传至云中心,节省大量带宽。 - 个性化与动态内容加速
边缘节点根据用户画像、地理位置等信息动态组装个性化页面(如新闻推荐、商品广告),并将结果缓存短暂时间,应对突发流量。 - API与数据库加速
将高频读写的API接口或数据库查询下沉至边缘,通过边缘节点缓存响应或直接部署只读副本,显著提升接口性能。
五、面临的核心挑战与应对策略
- 资源管理与调度:边缘节点资源(CPU、内存、带宽)有限。需通过容器化(Docker)和编排技术(Kubernetes Edge版)实现资源的精细化管理、隔离和弹性伸缩。
- 安全与隔离:边缘环境更开放,安全风险更高。需实施细粒度的访问控制、函数计算的安全沙箱、TLS加密通信以及边缘节点的安全加固。
- 开发与测试:分布式系统开发和调试复杂度高。需建立完善的CI/CD流水线,实现函数和配置的自动化部署、灰度发布和全链路监控与追踪。
- 成本与效益的平衡:需要在边缘计算的低延迟优势与其增加的开发复杂度和硬件成本之间找到最佳平衡点。

















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









