







目录
图的存储必须要完整、准确地反应顶点集和边集的信息。根据不同图的结构和算法,采用不同的存储方式将对程序的效率产生相当大的影响,因此所选的存储结构应适合于待求解的问题。下面介绍四种图的存储方式。
一、邻接矩阵法
1. 概念
邻接矩阵存储是指用一个一维数组存储图中顶点的信息,用一个二维数组存储图中边的信息(即各顶点之间的邻接关系),存储顶点之间邻接关系的二维数组称为邻接矩阵。
【在简单应用中,可直接用二维数组作为图的邻接矩阵(顶点信息等均可忽略)】
顶点数为 n 的图 G = (V, E) 的邻接矩阵 A 是 n × n 的,将 G 的顶点编号为 v1, v2,…, vn ,则:

对于带权图而言,若顶点 vi 和 vj 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值,若顶点 vi 和 vj 不相连,则通常用 0 或 ∞ 来代表这两个顶点之间不存在边:

有向图、无向图和网对应的邻接矩阵示例如下图所示:

2. 图的邻接矩阵存储结构定义
#define MaxVertexNum 100//顶点数目的最大值
typedef char VertexType;//顶点对应的数据类型
typedef int EdgeType;//边对应的数据类型
typedef struct{
VertexType vex[MaxVertexNum];//顶点表
EdgeType edge[MaxVertexNum][MaxVertexNum];//邻接矩阵(边表)
int vexnum, arcnum;//图当前的顶点数和边数
}MGraph;
【注】邻接矩阵表示法的空间复杂度为 O(n2) ,其中 n 为图的顶点数 |V| 。
3. 图的邻接矩阵存储表示法的特点
-
对于有 n 个顶点的无向图,有 A[i][i] = 0 ,其中 1 ≤ i ≤ n 。
-
无向图的邻接矩阵一定是一个对称矩阵(且唯一),即 A[i][j] = A[j][i](1 ≤ i ≤ n,1 ≤ j ≤ n),因此,在实际存储邻接矩阵时只需存储上(或下)三角矩阵的元素(压缩存储)。
-
对于无向图,邻接矩阵的第 i 行(或第 i 列)非零元素(或非 ∞ 元素)的个数正好是顶点 i 的度 TD(vi) 。
-
对于有向图,邻接矩阵的第 i 行非零元素(或非 ∞ 元素)的个数正好是顶点 i 的出度 OD(vi) ;邻接矩阵的第 i 列非零元素(或非 ∞ 元素)的个数正好是顶点 i 的入度 ID(vi) 。
-
用邻接矩阵存储图,很容易确定图中任意两个顶点之间是否有边相连,但是,要确定图中有多少条边,则必须按行、按列对每个元素进行检测,所花费的时间代价很大。
-
稠密图(即边数较多的图)适合采用邻接矩阵的存储方式。
-
(了解即可)设图 G 的邻接矩阵为 A ,Am 的元素 Am [i][j] 等于由顶点 i 到顶点 j 的长度为 m 的路径的数目。
4. 例题
① 若图的邻接矩阵中主对角线上的元素皆为 0 ,其余元素全为 1 ,则可以断定该图一定( C )。
A. 是无向图
B. 是有向图
C. 是完全图
D. 不是带权图
② 在含有 n 个顶点和 e 条边的无向图的邻接矩阵中,零元素的个数为( D ) 。
A. e
B. 2e
C. n2 - e
D. n2 - 2e
③ 带权有向图 G 用邻接矩阵存储,则 vi 的入度等于邻接矩阵中( D ) 。
A. 第 i 行非 ∞ 的元素个数
B. 第 i 列非 ∞ 的元素个数
C. 第 i 行非 ∞ 且非 0 的元素个数
D. 第 i 列非 ∞ 且非 0 的元素个数
④ 一个有 n 个顶点的图用邻接矩阵 A 表示,若图为有向图,顶点 vi 的入度是( B );若图为无向图,顶点 vi 的度是( D )。
A. Σi=1n A[i][j]
B. Σj=1n A[j][i]
C. Σi=1n A[j][i]
D. Σj=1n A[j][i] 或 Σj=1n A[i][j]
⑤ 【2013 统考真题】设图的邻接矩阵 A 如下图所示。各顶点的度依次是( C )。
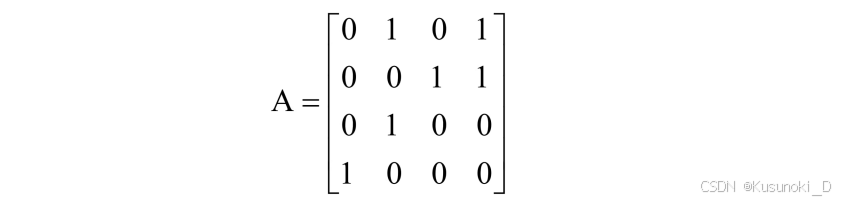
A. 1, 2, 1, 2
B. 2, 2, 1, 1
C. 3, 4, 2, 3
D. 4, 4, 2, 2
二、邻接表法
1. 概念
当一个图为稀疏图时,使用邻接矩阵法会浪费大量的存储空间,而图的邻接表法结合了顺序存储和链式存储的方法,大大减少了这种不必要的浪费。
邻接链表是指对图 G 中的每个顶点 vi 建立一个单链表,第 i 个单链表中的结点表示依附于顶点 vi 的边(对于有向图则是以顶点 vi 为尾的弧),这个单链表就称为顶点 vi 的边表(对于有向图则称为出边表)。边表的头指针和顶点的数据信息采用顺序存储,称为顶点表,所以在邻接表中存在两种结点:顶点表结点和边表结点,如下图所示:

顶点表结点由两个域组成:
- 顶点域(data)存储顶点 vi 的相关信息;
- 边表头指针域(firstarc)指向第一条边的边表结点。
边表结点至少由两个域组成:
- 邻接表域(adjvex)存储与头结点顶点 vi 邻接的顶点编号;
- 指针域(nextarc)指向下一条边的边表结点。
无向图、有向图对应的邻接表示例如下图所示:

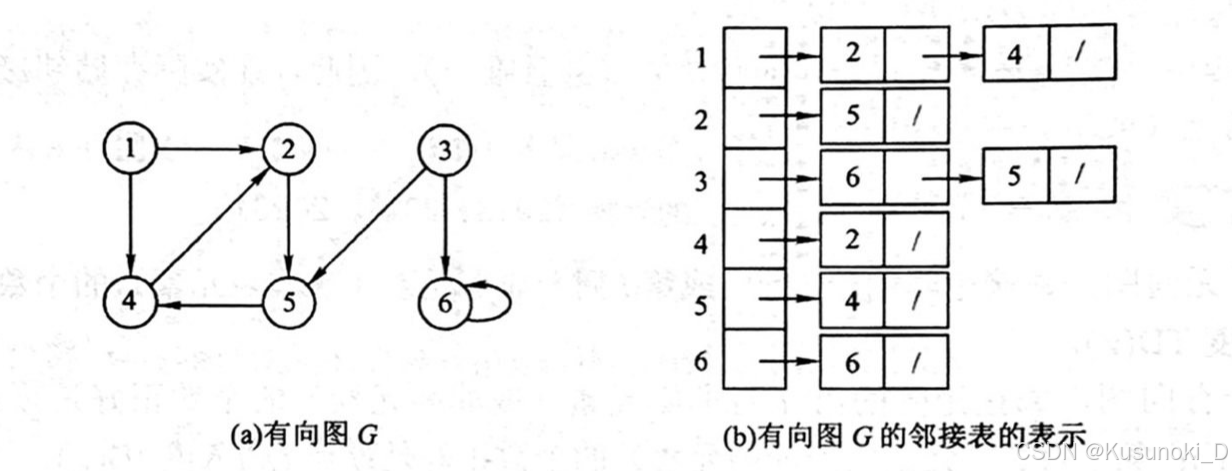
2. 图的邻接表存储结构定义
#define MaxVertexNum 100//图中顶点数目的最大值
typedef struct ArcNode{//边表结点
int adjvex;//该弧所指向的顶点的位置
struct ArcNode *nextarc;//指向下一条弧的指针
//InfoType info;//网的边权值
}ArcNode;
typedef struct VNode{//顶点表结点
VertexType data;//顶点信息
ArcNode *firstarc;//指向第一条依附该顶点的弧的指针
}VNode,AdjList[MaxVertexNum];
typedef struct{
AdjList vertices;//邻接表
int vexnum, arcnum;//图的顶点数和弧数
}ALGraph;//ALGraph是以邻接表存储的图类型
【注】若 G 为无向图,则图的邻接表存储方法所需的存储空间为 O(|V|+2|E|) ,若 G 为有向图,则所需的存储空间为 O(|V|+|E|) 。
3. 图的邻接表存储表示法的特点
-
对于稀疏图(即边数较少的图),采用邻接表表示将极大地节省存储空间。
-
在邻接表中,给定一个顶点,能很容易地找出它的所有邻边,因为只需要读取它的邻接表。在邻接矩阵中,相同的操作则需要扫描一行,花费的时间为 O(n) 。但是,若要确定给定的两个顶点间是否存在边,则在邻接矩阵中可以立刻查到,而在邻接表中则需要在相应结点对应的边表中查找另一结点,效率较低。
-
在无向表的邻接表中,求某个顶点的度只需计算其邻接表中的边表结点个数。在有向图的邻接表中,求某个顶点的出度只需计算其邻接表中的边表结点个数;但求某个顶点 x 的入度则需遍历全部的邻接表,统计邻接点(adjvex)域为 x 的边表结点个数。
-
图的邻接表表示并不唯一,因为在每个顶点对应的边表中,各边结点的链接次序可以是任意的,它取决于建立邻接表的算法及边的输入次序。
4. 例题
① 以下关于图的存储结构的叙述中,正确的是( B )。
A. 一个图的邻接矩阵表示唯一,邻接表表示唯一
B. 一个图的邻接矩阵表示唯一,邻接表表示不唯一
C. 一个图的邻接矩阵表示不唯一,邻接表表示唯一
D. 一个图的邻接矩阵表示不唯一,邻接表表示不唯一
② 用邻接表法存储图所用的空间大小( A )。
A. 与图的顶点数和边数有关
B. 只与图的边数有关
C. 只与图的顶点数有关
D. 与边数的平方有关
③ 若邻接表中有奇数个边表结点,则( D )。
A. 图中有奇数个结点
B. 图中有偶数个结点
C. 图为无向图
D. 图为有向图
④ 在有向图的邻接表存储结构中,顶点 v 在边表中出现的次数是( C )。
A. 顶点 v 的度
B. 顶点 v 的出度
C. 顶点 v 的入度
D. 依附于顶点 v 的边数
⑤ n 个顶点的无向图的邻接表最多有( B )个边表结点。
A. n2
B. n × (n - 1)
C. n × (n + 1)
D. n × (n - 1) / 2
⑥ 假设有 n 个顶点、e 条边的有向图用邻接表表示,则删除与某个顶点 v 相关的所有边的时间复杂度为( C )。
A. O(n)
B. O(e)
C. O(n + e)
D. O(n × e)
⑦ 对邻接表的叙述中,( D )是正确的。
A. 无向图的邻接表中,第 i 个顶点的度为第 i 个链表中结点数的两倍
B. 邻接表比邻接矩阵的操作更简便
C. 邻接矩阵比邻接表的操作更简便
D. 求有向图结点的度,必须遍历整个邻接表
三、十字链表法
1. 概念
十字链表是有向图的一种链式存储结构。在十字链表中,有向图的每条弧用一个结点(弧结点)来表示,每个顶点也用一个结点(顶点结点)来表示。如下图所示:

弧结点中有 5 个域:
- tailvex 域指示弧尾顶点的编号;
- headvex 域指示弧头顶点的编号;
- 头链域 hlink 指向弧头相同的下一个弧结点;
- 尾链域 tlink 指向弧尾相同的下一个弧结点;
- info 域存放该弧的相关信息。
这样,弧头相同的弧在同一个链表上,弧尾相同的弧也在同一个链表上。
顶点结点中有 3 个域:
- data 域存放该顶点的数据信息,如顶点名称;
- firstin 域指向以该顶点为弧头的第一个弧结点;
- firstout 域指向以该顶点为弧尾的第一个弧结点。
2. 有向图的十字链表表示示例

注意:顶点结点之间是顺序存储的,弧结点省略了 info 域。
在十字链表中,既容易找到 vi 为尾的弧,也容易找到 vi 为头的弧,因而容易求得顶点的出度和入度。图的十字链表表示是不唯一的,但一个十字链表表示唯一确定一个图。下面来详细分析一下上面的示例:
十字链表适用于有向图,它实际上是邻接表和逆邻接表的结合。邻接表的单链表指向的是顶点的出边表,与之相反,逆邻接表的单链表指向的是顶点的入边表。
我们先来看顶点的出边表部分:(进行水平方向的连接)
1)v1 指向 v2 、v3:

2)v3 指向 v1 、v4
v4 指向 v1 、v2 、v3:

再来看顶点的入边表部分:(进行垂直方向的连接)
3)v1 被 v3 、v4 指向:

4)v2 被 v1 、v4 指向
v3 被 v1 、v4 指向
v4 被 v3 指向:

再举一个例子:(自己练习一下吧)

3. 例题
十字链表是( B )的存储结构。
A. 无向图
B. 有向图
C. 无向图和有向图
D. 都不是
四、邻接多重表法
1. 概念
邻接多重表是无向图的一种链式存储结构。在邻接表中,容易求得顶点和边的各种信息,但在邻接表中求两个顶点之间是否存在边而对边执行删除等操作时,需要分别在两个顶点的边表中遍历,效率较低。与十字链表相似,在邻接多重表中,每个顶点、每条边用一个结点表示,其结构如下所示:

边结点中有 5 个域:
- ivex 域指示该边依附的其中一个顶点的编号;
- jvex 域指示该边依附的另一个顶点的编号;
- ilink 域指向下一条依附于顶点 ivex 的边;
- jlink 域指向下一条依附于顶点 jvex 的边;
- info 域存放该边的相关信息。

顶点结点中有 2 个域:
- data 域存放该顶点的相关信息;
- firstedge 域指向第一条依附于该顶点的边。
在邻接多重表中,所有依附于同一顶点的边串联在同一链表中,因为每条边依附于两个顶点,所以每个边结点同时链接在两个链表中。对无向图而言,其邻接多重表和邻接表的差别仅在于:同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。
2. 无向图的邻接多重表表示示例

注意:顶点结点之间是顺序存储的,弧结点省略了 info 域,邻接多重表的各种基本操作的实现和邻接表类似。下面来详细分析一下上面的示例:
1)图中顶点 b 和顶点 c 所连的边(3 条)最多,因此先画顶点 b 的边表:
b-a(1-0)、b-c(1-2)、b-e(1-4)

2)除去三条边后,顶点 c 和顶点 d 所连的边(2 条)最多,由于间隔一个顶点画出的图更好看,因此画顶点 d 的边表:
d-a(3-0)、d-c(3-2)

3)最后只剩 e-c(4-2)这条边了,把它加入顶点 e 的边表中:

4)连线,规则是与编号相同的就串联起来,比如顶点 a 的编号为 0 ,那么找到边表中有含 0 的结点,依次串联起来即可:

可以看出邻接多重表的表示方式不唯一。
再举两个例子:(自己练习一下吧)


3. 例题
邻接多重表是( A )的存储结构。
A. 无向图
B. 有向图
C. 无向图和有向图
D. 都不是
图的四种存储方式的总结
| 邻接矩阵 | 邻接表 | 十字链表 | 邻接多重表 | |
|---|---|---|---|---|
| 空间复杂度 | O(V2) | 无向图:O(V+2E) ,有向图:O(V+E) | O(V+E) | O(V+E) |
| 找相邻边 | 遍历对应行或列的时间复杂度为O(V) | 找有向图的入度必须遍历整个邻接表 | 很方便 | 很方便 |
| 删除边或顶点 | 删除边很方便,删除顶点需要大量移动数据 | 无向图中删除边或顶点都不方便 | 很方便 | 很方便 |
| 适用于 | 稠密图 | 稀疏图和其他 | 只能存有向图 | 只能存无向图 |
| 表示方式 | 唯一 | 不唯一 | 不唯一 | 不唯一 |



















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











