







模型介绍
目前基于Transformer的预训练模型在各项NLP任务纷纷取得更好的效果,这些成功的部分原因在于Self-Attention机制,它运行模型能够快速便捷地从整个文本序列中捕获重要信息。然而传统的Self-Attention机制的时空复杂度与文本的序列长度呈平方的关系,这在很大程度上限制了模型的输入不能太长,因此需要将过长的文档进行截断传入模型进行处理,例如BERT中能够接受的最大序列长度为512。
基于这些考虑,Longformer被提出来拓展模型在长序列建模的能力,它提出了一种时空复杂度同文本序列长度呈线性关系的Self-Attention,用以保证模型使用更低的时空复杂度建模长文档。
这里需要注意的是Longformer是Transformer的Encoder端。
模型改进
Longformer对长文档建模主要的改进是提出了新的Self-Attention模式,如图1所示,下面我们来详细讨论一下。
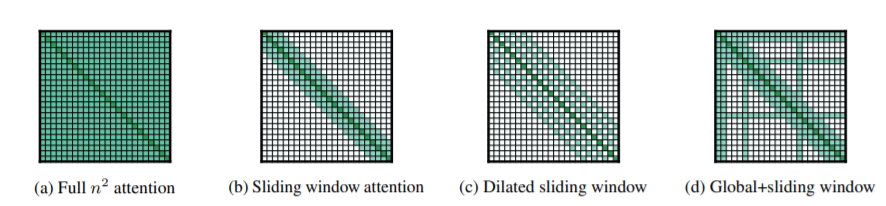
图1展示了经典的Self-Attention和Longformer提出的Self-Attention,其中图1a是经典的Self-Attention,它是一种”全看型”的Self-Attention,即每个token都要和序列中的其他所有token进行交互,因此它的时空复杂度均是O(n2)。右边的三种模式是Longformer提出来的Self-Attention模式,分别是Sliding Window Attention(滑窗机制)、Dilated Sliding Window(空洞滑窗机制)和Global+Sliding Window(融合全局信息的滑窗机制)。
Sliding Window Attention
如图1b所示,对于某个token,经典的Self-Attention能够看到并融合所有其他的token,但Sliding window attention设定了一个窗口w,它规定序列中的每个token只能看到w个token,其左右两侧能看到12w个token,因此它的时间复杂度是O(n×w)。
你不需要担心这种设定无法建立整个序列的语义信息,因为transformer模型结构本身是层层叠加的结构,模型高层相比底层具有更宽广的感受野,自然能够能够看到更多的信息,因此它有能力去建模融合全部序列信息的全局表示,就行CNN那样。一个拥有m层的transformer,它在最上层的感受野尺寸为m×w。
通过这种设定Longformer能够在建模质量和效率之间进行一个比较好的折中。
Dilated Sliding Window Attention
在对一个token进行Self-Attention操作时,普通的Sliding Window Attention只能考虑到长度为w的上下文,在不增加计算量的情况下,Longformer提出了Dilated Sliding Window,如图1c所示。在进行Self-Attention的两个相邻token之间会存在大小为d的间隙,这样序列中的每个token的感受野范围可扩展到d×w。在第m层,感受野的范围将是m×d×w。
作者在文中提到,在进行Multi-Head Self-Attention时,在某些Head上不设置Dilated Sliding Window以让模型聚焦在局部上下文,在某些Head上设置Dilated Sliding Window以让模型聚焦在更长的上下文序列,这样能够提高模型表现。
Global Attention
以上两种Attention机制还不能完全适应task-specific的任务,因此Global+Sliding Window的Attention机制被提出来,如图1d所示。它设定某些位置的token能够看见全部的token,同时其他的所有token也能看见这些位置的token,相当于是将这些位置的token”暴露”在最外面。
这些位置的确定和具体的任务有关。例如对于分类任务,这个带有全局视角的token是”CLS”;对于QA任务,这些带有全局视角的token是Question对应的这些token。
那么这种融合全局信息的滑窗Attention具体如何实现呢,我们先来回顾一下经典的Self-Attention,公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) ⋅ V Attention(Q,K,V)=softmax(\frac {QK^T} {\sqrt{d_k}})·V Attention(Q,K,V)=softmax(dkQKT)⋅V
即将原始的输入分别映射到了Q,K,V三个空间后进行Attention计算,Global+Sliding Window这里涉及到两种Attention,Longformer中分别将这两种Attention映射到了两个独立的空间,即使用Qs,Ks,Vs来计算Sliding Window Attention,使用Qg,Kg,Vg来计算Global Attention。

















 2221
2221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











