







“损失函数”是如何设计出来的?直观理解“最小二乘法”和“极大似然估计法”
所谓的极大使然估计,是用于已知某种情况(事件)发生,去推测影响该事件发生的概率情况。
在图像识别的二分类问题中,使用w,b表示所谓的θ,也就是某些事件发生的概率。
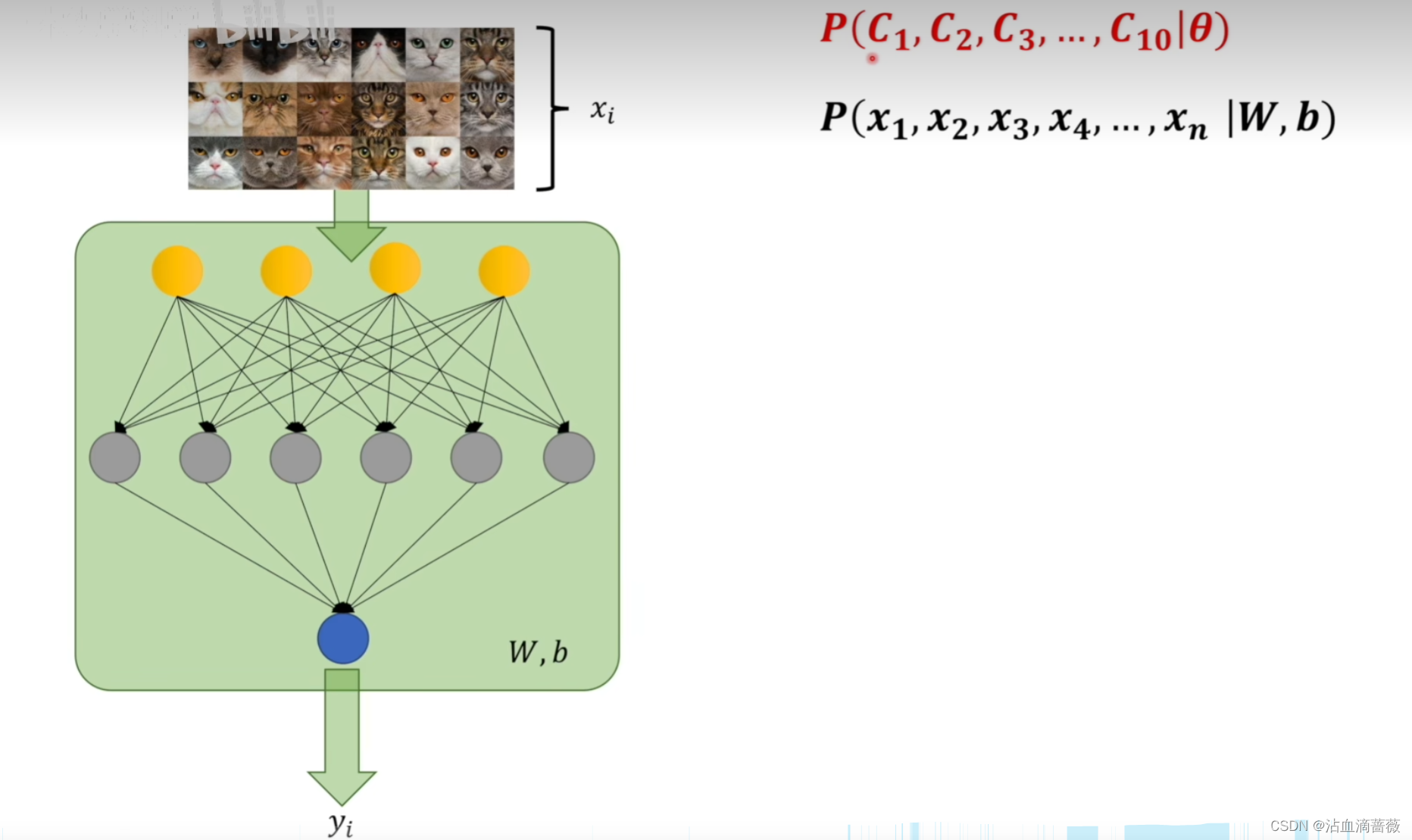
其中,x1,x2,x3,代表输入的照片是猫 还是狗,也就是目标值(正确值)。P(xi|w,b)表示输出xi的概率是多少,二分类中可以理解为w,b下输出猫的概率为P(xi|w,b)。由此可以求出针对输入数据的这组数据的可能性为p(x1,x2,…|W,b),也称为似然函数。极大使然估计就是求该函数的最大值,可以理解为使该函数最大时,猫狗的概率分布最符合要求,也就是w,b最符合要求。

然而,在训练的时候W,b是一个确定的值,无论输入是什么,训练时他都是确定的。在神经网络中,w,b可以根据输入数据,结合w,b,算出估计的概率,yi(此处用yi表示)。yi包含了w,b信息。所以可以用yi代替w,b。式子变为(连乘符号P(xi,yi))。只需要求该函数最大即可,求得最符合需要概率分布信息,也就是w,b值。
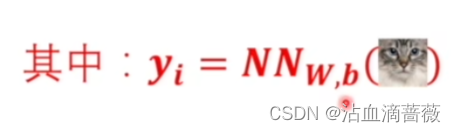
其中P(xi|yi)在二分类中就是表示是猫的概率,或是狗的概率。所以可以视为服从伯努利分布,可以写出分布函数如下。则上面的似然函数可以直接通过p进行表示。

f(x)表示概率密度函数,然后求其最大值。
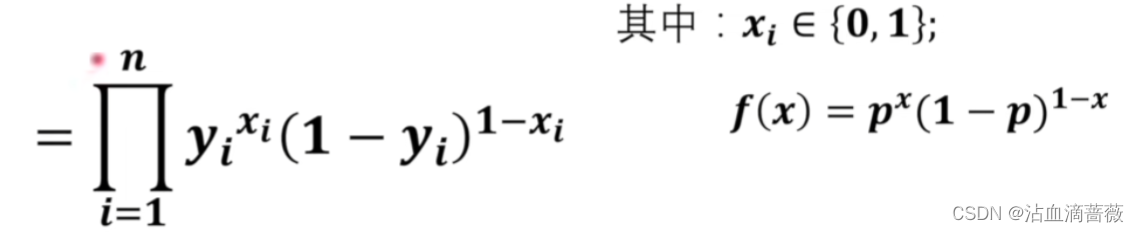
对于连乘的情况,我们使用对数进行处理,改写为连加的形式,
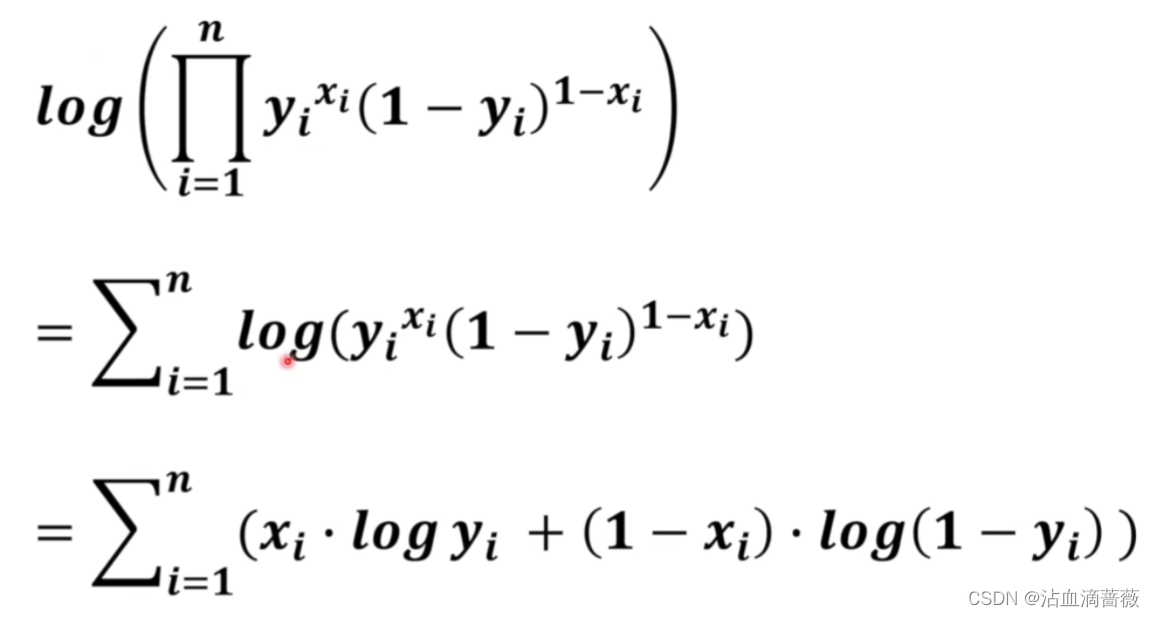
求该函数的最大值,可以通过负号转为求他的最小值。而吴恩达所写的公式中没有求和负号是因为:在训练中是迭代的过程,一次一次走的,所以公式中去掉了叠加。

最终问题是需要找到一组W,b的值,使得似然函数具有最大值。















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









