









mysql笔记
目录
文章目录
前言
基础的sql知识在sql笔记中已经整理。这里主要是针对mysql的一些特殊操作的整理。
mysql的特点
mysql
mysql是一种数据库软件(DBMS)。
开源、性能高、简单、可信赖。
DBMS分为两种:
- 基于共享文件。
- 客户端-服务机模式(主要、包括mysql、Oracle、sql server等)
服务器部分是一个负责所有数据访问和处理的软件。
而客户机则是与用户打交道的软件(广义上的软件)。
目的:所有的数据操作活动岁用户来说都是透明的。用户不需要关心数据(物理上)存放在什么地方,或本地、或其他主机上。
那就mysql而言,什么是“服务器,什么又是”客户端“呢?
- 服务器软件就是 mysql DBMS,它可以装在本机是哪个,也可以装在一个具有访问权限的远程服务器上。
- 客户机可以使mysql提供的工具、脚本语言、或其他可以连接操作数据库的开发语言。(php、c、java等)
mysql版本
mysql4.1 和mysql5增加了重要的功能。
mysql工具
这个工具也就是客户机。
命令行工具:
例如用户名是123、密码是234,则输入:
mysql -u123 -p234
mysql Administrator:
mysql Administrator(mysql管理器)是一个图形交互客户机,用来简化MySQL服务器的管理。
使用mysql
选择数据库
例如要是用数据库 bookstore
use bookstore
IN操作符
in操作符用来指定条件范围,范围中的没给我条件都可以匹配。
in的操作可以和or替换例如下面两个语句等价
select bookname
from book
where id in (2,3);
select bookname
from book
where id=2 or id=3;
为什么使用IN操作符:
- 如果满足条件较多时,用in比较清晰。
- 计算次序更容易管理。(因为操作符上,看起来清晰)
- in操作符比or一般要快。
- in可以包含其他select语句,嵌套查询。
用正则表达式进行搜索
正则表达式是用来匹配文本的特殊的字符串。(正则表达式也叫模式)
mysql仅支持部分正则表达式。
regexp
regexp告诉mysql,regexp后面的跟着的是正则表达式。
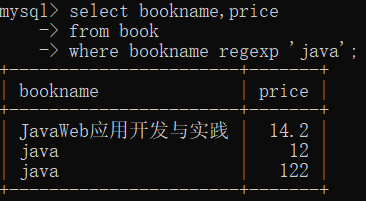
--这两个例子可以看出regexp和like的差别。
select bookname,price
from book
where bookname regexp 'java';
--可以看出mysql中的正则表达式不区分大小写。
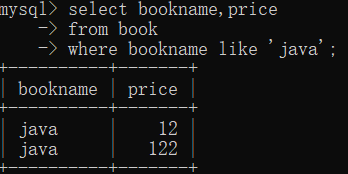
--like匹配整个列,而regexp在列值内进行匹配。
--当然是用^和$定位符可以使得正则表达式也匹配整个列。
select bookname,price
from book
where bookname like 'java';
“.”匹配单一字符
select bookname,price
from book
where bookname regexp '.ava';
"[]"匹配单一字符之一
select bookname,price
from book
where bookname regexp 'c[+#]';
结果:
| C#程序设计及应用编程 | 40.1 |
| C++程序设计 | 54.5 |
| C#网络应用编程 | 24.5 |
匹配范围
[123456789]可以匹配1到9,可以简化[1-9]。
不只是数字也可以匹配字符,[a-c],匹配a或b或c。
select bookname,price
from book
where price regexp '3[0-9]';
匹配特殊字符
. 、 [] 、| 和 - 等,还有其他一些字符具有特殊的意义,如果要匹配这些字符本身,需要用到装一字符 “\ \”(注意这里是两个\连在一起)。
select bookname,price
from book
where price regexp '\\.';
--匹配所有价格中带有小数点的行。
匹配字符类
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意的字母和数字(同[a-zA-Z0-9]) |
| [:alpha:] | 任意字符 |
| [:blank:] | 空格和制表 |
| [:cntrl:] | ASCII控制字符 |
| [:digit:] | 任意数字 |
| [:grahp:] | 与[:print:]相同,但不包含空格 |
| [:lower:] | 任意小写字母 |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]也不在[:cntrl:]中任意字符 |
| [:space:] | 包括空格在内的任意空白字符 |
| [:upper:] | 任意大写字母 |
| [:xdigit:] | 任意十六进制数字 |
select bookname
from book
where bookname regexp '[:lower:]';
匹配多个实例
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配 |
| + | 1个或多个匹配 |
| ? | 0个或1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
定位符
为了匹配特殊位置的文本。
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结束 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结束 |
select bookname
from book
where bookname regexp '^java$';
--只能匹配到"java",而不能匹配到"JavaWeb应用开发与实践"。
计算字段
拼接
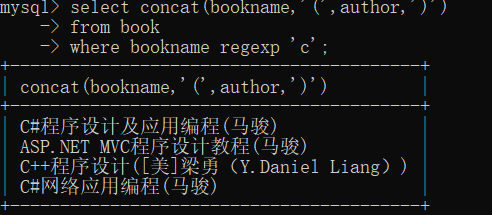
mysql使用concat()函数实现两个的值的拼接。
select concat(bookname,'(',author,')')
from book
where bookname regexp 'c';
RTrim()和LTRim()实现去掉右边/左边的空格。
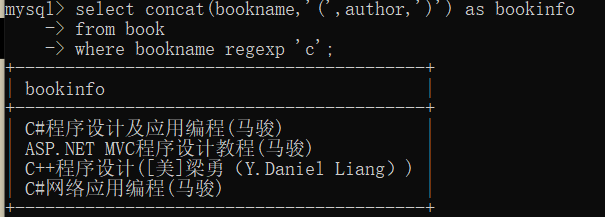
一般给新拼接的列起一个别名。
select concat(bookname,'(',author,')') as bookinfo
from book
where bookname regexp 'c';
执行算数运算
select price*number as allprice
from book
where bookname regexp 'c';
使用函数
文本处理函数
| 函数 | 说明 |
|---|---|
| RTrim() | 去掉串右边的空格 |
| Soundex() | 返回串的SOUNDEX值 |
| SubString() | 返回子串的字符 |
| Upper() | 将串转换为大写 |
其中Soundex()可以查找读音相似的匹配数据。(具体例子见《sql笔记》)。
日期和时间处理函数
| 函数 | 说明 |
|---|---|
| AddDate() | 增加一个日期(天、周等) |
| AddTime() | )增加一个时间(时、分等) |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前时间 |
| Date() | 返回日期时间的日期部分 |
| DateDiff() | 计算两个日期之差 |
| Date_Add() | 高度灵活的日期运算函数 |
| Date_Format() | 返回一个格式化的日期或时间串 |
| Day() | 返回一个日期的天数部分 |
| DayOfWeek() | 对于一个日期,返回对应的星期几 |
| Hour() | 返回一个时间的小时部分 |
| Minute() | 返回一个时间的分钟部分 |
| Month() | 返回一个日期的月份部分 |
| Now() | 返回当前日期和时间 |
| Second() | 返回一个时间的秒部分 |
| Time() | 返回一个日期时间的时间部分 |
| Year() | 返回一个日期的年份部分 |
不管是插入或更新表值还是用 WHERE 子句进行过滤,日期必须为格式yyyy-mm-dd。
select bookname,price
from book
where Date(date)='2021-02-02';
--date列存放日期时间
数值处理函数
| 函数 | 说明 |
|---|---|
| Abs() | 返回一个数的绝对值 |
| Cos() | 返回一个角度的余弦 |
| Exp() | 返回一个数的指数值 |
| Mod() | 返回除操作的余数 |
| Pi() | 返回圆周率 |
| Rand() | 返回一个随机数 |
| Sin() | 返回一个角度的正弦 |
| Sqrt() | 返回一个数的平方根 |
| Tan() | 返回一个角度的正切 |
汇总数据
聚集函数
有些时候我们需要汇总数据而不是将它们实际检索出来。
聚集函数运行在行组上,计算并返回单个值的函数。
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值(忽略null值) |
| COUNT() | 返回某列的行数(如果指定列名则忽略控制,如果使用*则不忽略)(也没办法忽略) |
| MAX() | 返回某列的最大值(忽略null值) |
| MIN() | 返回某列的最小值(忽略null值) |
| SUM() | 返回某列值之和(忽略null值) |
select count(date)
from book;
--只有date不为空的才被计数,也就是说有多少行daye不为空,则返回多少。
--如果指定count(*)或者count(date)与count(*)同时指定,则返回总行数。
select子句顺序
select
from
where
group by
having
order by
limit
联结
在一条 SELECT 语句中联结几个表时,相应的关系是在运行中构造的。
联结需要两个条件 一是from子句列出两个表,二是where中的过滤条件。
select bookname,price
from book,user
where book.sellerid=user.id;
全文本搜索
全文本搜索
mysql支持多种数据库殷勤,并非所有的殷勤都支持全文本搜索。
MyISAM支持,InnoDB不支持。
之前介绍的like和正则表达式存在问题:
- 通常会尝试匹配所有的行,性能不高。
- 控制不明确。
- 不能提供智能化的选择结果的方法。
全文本搜索时,MySQL不需要分别查看每个行,不需要分别分析和处理每个词。MySQL创建指定列中各词的一个索引,搜索可以针对这些词进行。这样,MySQL可以快速有效地决定哪些词匹配(哪些行包含它们),哪些词不匹配。
因此,必须先索引被搜索的列。
--在创建表时启用全文本搜索
create table booknotes
{
note_id integer(10) not null auto_increment,--auto_increment 设置自增一
book_id integer(10) not null,
note_text text null,
primary kry(note_id),
fulltext(note_text) --这里
}engin=MyISAM;
--代码无法执行,不知道问题在哪儿。
进行全文本搜索
select note_text
from booknotes
where match(note_text) against('rabbit');
--传递给match()的值必须与fulltext()定义中的相同。如果指定多个列,则必须列出它们(而且次序
--正确)。
match(note_text) against(‘rabbit’)产生一个匹配等级。且根据等级进行排序。
等级由MySQL根据行中词的数目、唯一词的数目、整个索引中词的总数以及包含该词的行的数目计算出来。
查询扩展
- 进行一次全文本搜索,找到匹配行。
- mysql检查这些匹配行并选择有用的词。
- mysql再次进行全文本搜索,不仅使用原来的条件还是用所有用的词。
查询扩展查找结果不精确。
布尔文本搜索
根据要匹配的词、要排斥的词、排列提示、表达式分组等内容进行搜索。
布尔方式不需要定义fulltext索引。
select note_text
from booknotes
where match(booknotes) against('数据' in BOOLEAN MODE)
--其中使用了关键字 IN BOOLEAN MODE ,但实际上没有指定布尔操作符。
--因此,其结果与没有指定布尔方式的结果相同。
select note_text
from booknotes
where match(booknotes) against('数据 -计算*' in BOOLEAN MODE)
--匹配"数据",但是明确指出要排除包含以"计算"开头的行。
| 布尔操作符 | 说明 |
|---|---|
| + | 包含,词必须存在 |
| - | 排除,词必须不出现 |
| > | 包含,而且增加等级值 |
| < | 包含,且减少等级值 |
| () | 把词组成子表达式(允许这些子表达式作为一个组被包含、排除、排列等) |
| ~ | 取消一个词的排序值 |
| * | 词尾的通配符 |
| “” | 定义一个短语(与单个词的列表不一样,它匹配整个短语以便包含或排除这个短语) |
在布尔方式中,不按等级值降序排序返回的行。
全文本搜索的使用说明
- 短词被忽略且从索引中删除。(三个或三个一下字符的词,可以修改)
- mysql自带一个内建的非用词表,这些词在索引是被忽略。(可以覆盖这个表)
- 频率很高的词,搜索他们没有用处,mysql规定如果一个词出现在50%以上的行中,则它作为一个非用词忽略。上上个例子中的in BOOLEAN MODE使得这个规则无效。
- 如果表中的行数少于3行,则全文本搜索不返回结果。
- 忽略词中的单引号。例如, don’t 索引为 dont 。
创建表时的操作
AUTO_INCREMENT --设置自增一
default 1 --指定默认值为1
--MySQL不允许使用函数作为默认值,它只支持常量。
关于引擎
CREATE TABLE 语句的结束为止的ENGINE=InnoDB指明使用的引擎。(可不指定)
mysql具有多种引擎。
- InnoDB可靠的事务处理引擎。
- MyISAM 是一个性能极高的引擎,它支持全文本搜索但不支持事务处理。
- MEMORY 在功能等同于 MyISAM ,数据存储在内存,速度很快。
视图更新
如果视图定义中有以下操作,则不能进行视图的更新:
- 分组
- 联结
- 子查询
- 并
- 聚集函数
- didstinct
- 导出(计算)列
存储过程
存储过程
create procedure productpricing()
begin
select avg(price) as priceavg
from book;
end;
delimiter //
create procedure productpricing()
begin
select avg(price) as priceavg
from book;
end//
delimiter ;
--注意,如果使用命令行需要这样写,在开始设置"//为结束标志,然后再结尾处再修改为;
--这样做的目的是为了"保住"语句中间的"from book;这里有一个分号,如果不把结束符设置为"//"
--程序会认为整个语句到这里就结束了。
通过call使用存储过程
call productpricing();
通过drop删除存储过程
drop procedure productpricing;
drop procedure productpricing if exists;--有问题。
使用参数
变量:内存中临时存储数据。
--删除后重新建立
delimiter //
create procedure productpricing(
out pl decimal(8,2),
out ph decimal(8,2),
out pa decimal(8,2)
)
begin
select min(price) into pl
from book;
select max(price) into ph
from book;
select avg(price) into pa
from book;
end//
delimiter ;
--此存储过程接受3个参数,decimal指明十进制值。
--MySQL支持 IN (传递给存储过程)、 OUT (从存储过程传出,如这里所用)和 INOUT (对存储
--过程传入和传出)类型的参数。
--不能通过一个参数返回多个行和列
call productpricing(@pricelow,
@pricehigh,
@priceaverage);
--调用存储过程。
select @pricelow, @pricehigh, @priceaverage;
--得到数据。
--使用in的例子。
delimiter //
create procedure productpricing2(
in num decimal(8,2),
out allprice decimal(8,2)
)
begin
select sum(price*num) into allprice
from book;
end//
delimiter ;
call productpricing2(5,@allprice);
select @allprice;
智能存储过程
我们需要获得总的价格,散失有些时候可能会需要考虑是加上额外费用之后的总价。最终返回总价。
#命令行中用这个注释
delimiter //
create procedure ordertotal(
in oid int,
in myadd boolean,
out ototal decimal(8,2)
)
begin
DECLARE total decimal(8,2);
declare addmoney int dafault 6;
select sum(price*number)
from book
where id=oid
into total;
if myadd then
select total+addmoney into total;
end if;
select total into ototal;
end//
delimiter ;
--有问题
--用 DECLARE 语句定义了两个局部变量。
--IF 语句检查 taxable 是否为真,如果为真,则用另SELECT 语句增加营业税到局部变量 total。
--最后,用另一 SELECT 语句将total (它增加或许不增加额外费用)保存到 ototal 。
检查存储过程
show create procedure productpricing2;
--显示 用来创建一个存储过程的 CREATE 语句。
游标
mysql游标只能用于存储过程(和函数)。
游标用 DECLARE 语句创建。
存储过程处理完成后,游标就消失(因为它局限于存储过程)。
OPEN CURSOR 语句来打开;CLOSE 释放游标使用的所有内部内存和资源。如果你不明确关闭游标,MySQL将会在到达 END 语句时自动关闭它。
简单来说,一般情况下我们使用select语句,返回的值是一组行(结果集)
我们现在想要找到这个结果集的某一行并且可以找到它的上一行或下一行,就可以使用游标。
游标是一个存储在mysql服务器上的数据库查询,它不是select语句,而是被该语句检索出来的结果集。
对于mysql来说,游标只能用在存储过程或函数中。
使用declare声明一个游标,同时需要定义一个select语句。
使用open打开,使用close关闭。(当然,如果你忘记关闭的话,mysql会在执行到end时自动关闭)
delimiter //
create procedure processorders_cursor()
begin
#1
declare done boolean default 0;
declare o int;
#2
declare ordernumbers cursor
for
select number from book;
#3
declare continue handler for sqlstate '02000' set done=1;
#4
open ordernumbers;
#5
repeat
fetch ordernumbers into o;
until done end repeat;
#6
close ordernumbers;
end //
delimiter ;
--1. 声明局部变量。
--2. 声明游标 定义select语句。
--3. 定义了一个continue handler,它是在条件出现时被执行的代码。
--它指定当“sqlstate '02000'”出现时,set done=1。
--“sqlstate '02000'”是一个未找到条件,当repeat由于没有更多的行供循环
--而不能继续时,出现这个条件。
--4. 打开游标。
--5. 一个循环(重复执行) “fetch ordernumbers into o;”指的是使用
--fetch检索当前number到标量o中。
--6. 关闭游标。
--注意,这个整体依然是一个存储过程,对于存储过程而言,游标只是其中一个
--配件,可以有也可以没有,也不会影响存储过程中的其他部分(存储过程中依
--然可以执行除上述这些以外的代码,包括条用其它的存储过程。
delimiter //
create procedure processorders_cursor2()
begin
declare done boolean default 0;
declare o int;
declare ordernumbers cursor
for
select number from book;
declare continue handler for sqlstate '02000' set done=1;
create table if not exists onlynumbers
(number int);
open ordernumbers;
repeat
fetch ordernumbers into o;
insert into onlynumbers
values(o);
until done end repeat;
close ordernumbers;
end //
delimiter ;
--游标所进行的工作就是在酶促循环时,把当前行的数据插入到表onlynumbers中。
--调用这个存储过程
call processorders_cursor2();
--现在表onlynumbers中已经有数据
select *
from onlynumbers;
触发器
触发器
在有些情况下,我们需要在某个表发生变动时自动处理。
对于mysql,delete语句、insert语句、update语句都可以在其前或后设置触发器。(所以对于一个数据库,最多只有6个触发器)可以在执行某个操作前后去执行依据代码(begin end代码块)
只有表支持触发器,视图不支持。
注意:如果before触发器失败,则mysql将不执行请求的操作。此外,如果 before触发器或语句本身失败,mysql将不执行after触发器(如果有的话)。
使用create trigger创建触发器。
after insert,此触发器将在 INSERT 语句成功执行后执行。同理还有before insert。
insert触发器:
在insert触发器内可以引用一个名为NEW的虚拟表,这个虚拟表中存放的是(将要)被插入的行。
在before insert中,这个表的值可以被更新。
对于 auto_increment列, NEW 在insert执行之前包含 0 ,在 insert执行之后包含新的自动生成值。
create trigger newuser after insert on user
for each row select NEW.name;
--MYSQL5以后,不允许触发器返回任何结果,上面这个代码需要修改,使用变量。
create trigger newuser after insert on user
FOR EACH ROW SELECT NEW.name INTO @asd;
--这里只是定义了一个触发器,还没有使用。
insert into user(name,password)
values("hhh","1234");
select @asd;
--查看触发器的结果结果。
delete触发器
在delete触发器中可以引用一个名为OLD的虚拟表(只读)。
create table if not exists oldusers
(oldusername varchar(255));
delimiter //
create trigger olduser after delete on user
for each row
begin
insert into oldusers(oldusername)
values(OLD.name);
end//
delimiter ;
--将将要删除的数据插入到olduser表中(可以用在卖出书籍中)。
delete from user
where name='hhh';
select *
from oldusers;
--查看数据。
使用 BEFORE DELETE 触发器的优点(相对于 AFTER DELETE 触发器来说)为,如果由于某种原因,订单不能存档, DELETE 本身将被放弃。
uodate触发器
在 update触发器代码中,你可以引用一个名为 OLD 的只读虚拟表访问以前( update语句前)的值,引用一个名为 NEW 的虚拟表访问新更新的值。
在 before uodate触发器中, NEW 中的值可能也被更新(允许更改将要用于 update语句中的值)。
create trigger updatename before update on user
for each row set NEW.name=upper(NEW.name);
update user
set name='ch'
where name='chh';
select name
from user;
--查看到原来name是'chh'的位置现在变为'CH'。
一般将before用于数据验证和净化(目的是保证插入表中的数据确实是需要的数据)。
事务处理
对于mysql来说,MyISAM不支持明确的事务处理。InnoDB支持事物处理。
事务处理(transaction processing)用来维护数据库的完整性,它保证成批的mysql操作要么完全执行,要么完全不执行。
标志事务的开始
start transation;
select * from admin;
start transation;
delete from admin;
select * from admin;
rollback
select * from admin;
--rollback回退(回退delete语句)。
--然后再用select检查结果,是否成功回退。
回退rollback
rollback 只能在一个事务处理内使用。
insert update delete可以回退。create drop和selete不可以回退。
提交commit
一般来说数据库会进行自动提交(隐含提交)。
但是在事务处理块中,提交不会隐含进行。
start transation
delete from user where id=10;
delete from book where sellerid=10;
commit;
当 commit或 rollback语句执行后,事务会自动关闭。
使用保留点
savepoint delete1;
--设置一个名为delete1的保留点。
release savepoint;
--明确释放保留点。
更改默认的提交行为
set autocommit=0;
--设置不再自动提交(针对这个链接不再自动提交,一个数据库可以连接多个连接)。
全球化和本地化
字符集:字母和符号的集合。
编码:某个字符集成员的内部表示。
校对:规定字符如何比较的指令。
show character set;
--显示所有可用的字符集以及每个字符集的描述和默认校对。
show collation;
--显示所有可用的校对,以及它们适用的字符集。
show variables like 'character%';
show variables like 'collation%';
--确定所用的字符集和校对
--不同的表,甚至不同的列都可能需要不同的字符集,而且两者都可以在创建表时指定。
create table table1
(
col_1 int,
col_2 varchar(10)
) default character set hebrew
collate hebrew_general_ci;
--对表设置字符集和校对。
create table table2
(
col_1 int,
col_2 varchar(10) character set gbk collate gbk_chinese_ci
) default character set hebrew
collate hebrew_general_ci;
--对整个表以及一个列指定了字符集和校对。
校对在对用 order by子句检索出来的数据排序时起重要的作用。
select * from table1
order by col_1 collate collate gbk_chinese_ci;
--可以在select中使用collate指定一个备用的校对顺序。也可以用在 group by、having、聚集
--函数、别名等。
savepoint;
–明确释放保留点。
#### 更改默认的提交行为
```sql
set autocommit=0;
--设置不再自动提交(针对这个链接不再自动提交,一个数据库可以连接多个连接)。
全球化和本地化
字符集:字母和符号的集合。
编码:某个字符集成员的内部表示。
校对:规定字符如何比较的指令。
show character set;
--显示所有可用的字符集以及每个字符集的描述和默认校对。
show collation;
--显示所有可用的校对,以及它们适用的字符集。
show variables like 'character%';
show variables like 'collation%';
--确定所用的字符集和校对
--不同的表,甚至不同的列都可能需要不同的字符集,而且两者都可以在创建表时指定。
create table table1
(
col_1 int,
col_2 varchar(10)
) default character set hebrew
collate hebrew_general_ci;
--对表设置字符集和校对。
create table table2
(
col_1 int,
col_2 varchar(10) character set gbk collate gbk_chinese_ci
) default character set hebrew
collate hebrew_general_ci;
--对整个表以及一个列指定了字符集和校对。
校对在对用 order by子句检索出来的数据排序时起重要的作用。
select * from table1
order by col_1 collate collate gbk_chinese_ci;
--可以在select中使用collate指定一个备用的校对顺序。也可以用在 group by、having、聚集
--函数、别名等。
关于性能、维护、安全管理等之后再单独整理。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









