










神经网络搭建六步法
1.keras介绍
tf.keras 是 tensorflow2 引入的高封装度的框架,可以用于快速搭建神经网络模型,keras 为支持快速实验而生,能够把想法迅速转换为结果,是深度学习 框架之中最终易上手的一个,它提供了一致而简洁的API,能够极大地减少一般 应用下的工作量,提高代码地封装程度和复用性。
2.tf.keras 搭建神经网络六部法
第一步:import 相关模块,如 import tensorflow as tf。
第二步:指定输入网络的训练集和测试集,如指定训练集的输入 x_train 和标签 y_train,测试集的输入 x_test 和标签 y_test。
第三步:逐层搭建网络结构,model = tf.keras.models.Sequential()。
第四步:在 model.compile()中配置训练方法,选择训练时使用的优化器、损失 函数和最终评价指标。
第五步:在 model.fit()中执行训练过程,告知训练集和测试集的输入值和标签、 每个 batch 的大小(batchsize)和数据集的迭代次数(epoch)。
第六步:使用 model.summary()打印网络结构,统计参数数目。
下面对“六步法”中出现的函数做一些介绍
tf.keras.models.Sequential()
Sequential 函数是一个容器,描述了神经网络的网络结构,在Sequential函数的输入参数中描述从输入层到输出层的网络结构。
例如
model=tf.keras.Sequential(layers=[tf.keras.layers.Dense(3,activation="relu"), tf.keras.layers.Dense(3,activation="softmax")])
常用的层有:
- 拉直层 tf.keras.layers.Flatten():拉直层可以变换张量的尺寸,把输入特征拉直为一维数组,是不含计算参数的层。
- 全连接层 tf.keras.layers.Dense(神经元个数,activation=”激活函数”, kernel_regularizer=”正则化方式”)。
- 卷积层 tf.keras.layers.Conv2D(filter=卷积核个数,kernel_size = 卷积核尺寸, strides = 卷积步长, padding = “valid” or “same”)
- LSTM 层 tf.keras.layers.LSTM()。
其中activation(字符串给出)可选 relu、softmax、sigmoid、tanh等
kernel_regularizer 可选 tf.keras.regularizers.l1()、 tf.keras.regularizers.l2()
Model.compile()
Compile用于配置神经网络的训练方法,告知训练时使用的优化器、损失函数和准确率评测标准。
Model.compile(optimizer = 优化器,loss = 损失函数,metrics = [“准确率”])
其中:
- optimizer可以是字符串形式给出的优化器名字,也可以是函数形式,使用函数 形式可以设置学习率、动量和超参数。
| 优化器名字 | 函数形式 |
|---|---|
| ‘sgd’ | tf.optimizers.SGD(lr=学习率,decay=学习率衰减率, momentum=动量参数) |
| ‘adagrad’ | tf.keras.optimizers.Adagrad(lr=学习率, decay=学习率衰减率) |
| ‘adadelta’ | tf.keras.optimizers.Adadelta(lr=学习率, decay=学习率衰减率) |
| ‘adam’ | tf.keras.optimizers.Adam (lr=学习率, decay=学习率衰减率) |
- Loss可以是字符串形式给出的损失函数的名字,也可以是函数形式。
| 损失函数名字 | 函数形式 | 备注 |
|---|---|---|
| ‘mse’ | tf.keras.losses.MeanSquaredError() | |
| ‘sparse_categorical_crossentropy‘ | tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False) | 如果输出经过了softmax转化为概率,那么这选择False,如果没有选择为True |
- Metrics标注网络评测指标。
| 网络评测指标名字 | 备注 |
|---|---|
| ‘accuracy’ | y_和 y 都是数值(标签类型),如 y_=[1] y=[1]。 |
| ‘categorical_accuracy’ | y_和 y 是以独热码和概率分布表示。如 y_=[0, 1, 0], y=[0.256, 0.695, 0.048]。 |
| ‘sparse_ categorical_accuracy’ | y_是以数值形式给出,y是以概率分布表示。如 y_=[1],y=[0.256, 0.695, 0.048]。 |
eg.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy']
)
model.fit()
model.fit的参数有:
- 训练集的输入特征x_train,
- 训练集的标签y_train,
- batch_size,
- epochs,
- validation_data = (测试集的输入特征,测试集的标签),
- validataion_split = 从测试集划分多少比例给训练集,
- validation_freq = 测试的 epoch 间隔次数)
validation_data和validataion_split 两者选择一个使用即可。使用validation_data需要传递测试数据,而使用validataion_split不需要传递测试数据,测试数据从训练数据中划分出一部分。
eg.
# 将训练数据的20%划分出来用于测试
model.fit(x_train,y_train,batch_size=32,epochs=500,validation_split=0.2,validation_freq=20)
# 或
# 指定测试数据
model.fit(x_train,y_train,batch_size=32,epochs=500,validation_data=(x_test,y_test),validation_freq=20)
model.summary()
summary 函数用于打印网络结构和参数统计。
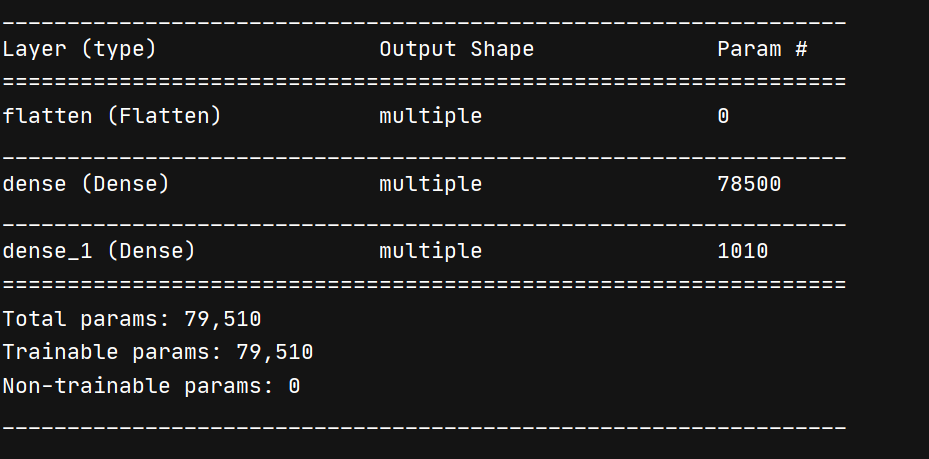
3.MNIST数据集手写数字识别复现
# 1.import 相关模块
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
# 2.指定输入网络的训练集和测试集
mnist=tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)=mnist.load_data()
x_train,x_test=x_train/255.0,x_test/255.0
# 3.逐层搭建网络结构
# 两个全连接层
model=tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100,activation="relu"),
tf.keras.layers.Dense(10,activation="softmax")
])
# 4.在 model.compile()中配置训练方法
model.compile(optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 5.在 model.fit()中执行训练过程
model.fit(x_train,y_train,batch_size=100,epochs=5,validation_data=(x_test,y_test),validation_freq=1)
# 6.使用 model.summary()打印网络结构
model.summary()
使用 class 来声明网络结构
在“六步法”的第三步 搭建网络结构 中,使用Sequential可以快速搭建网络结构,但是如果网络包含跳连等其他复杂网络结构,Sequential 就无法表示了。
这就需要使用class来声明网络结构。
简单来说就是我们需要声明一个类,这个类继承自tensorflow.keras.Model,把我们要搭建的网络结构和正向传播过程写在这个类里。看下面代码会很好理解:
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
self.flatten=Flatten()
self.d1=Dense(100,activation="relu")
self.d2=Dense(10,activation="softmax")
def call(self,x):
y=self.flatten(x)
y=self.d1(y)
y=self.d2(y)
return y
model=MyModel()
"__init__”方法中设置网络的结构。
“call”方法接受输入的特征数据,然后数据逐层正向计算,返回输出。
使用class来声明网络结构只是改变了“六步法”中的第三步的具体操作,其他的步骤完全不会受到干扰。
eg.
# 1.import 相关模块
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
# 2.指定输入网络的训练集和测试集
mnist=tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)=mnist.load_data()
x_train,x_test=x_train/255.0,x_test/255.0
# model=tf.keras.Sequential([
# tf.keras.layers.Flatten(),
# tf.keras.layers.Dense(100,activation="relu"),
# tf.keras.layers.Dense(10,activation="softmax")
# ])
# 3.逐层搭建网络结构
# 两个全连接层
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
self.flatten=Flatten()
self.d1=Dense(100,activation="relu")
self.d2=Dense(10,activation="softmax")
def call(self,x):
y=self.flatten(x)
y=self.d1(y)
y=self.d2(y)
return y
model=MyModel()
# 4.在 model.compile()中配置训练方法
model.compile(optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 5.在 model.fit()中执行训练过程
model.fit(x_train,y_train,batch_size=100,epochs=5,validation_data=(x_test,y_test),validation_freq=1)
# 6.使用 model.summary()打印网络结构
model.summary()














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









