










经典CNN的实现 LeNet AlexNet VGGNet
在卷积神经网络的发展历程中,出现过许多经典的网络结构,这些CNN经典网络的提出都曾极大地促进了领域的发展,在这里,我们会使用TensorFlow搭建这些经典的CNN,并且使用它们训练cifar10数据集。

因为InceptionNet和ResNet相对复杂很多,我们这篇文章先实现结构较为简单的前三个CNN:LeNet AlexNet VGGNet
我们各种经典的CNN都是只改变上一篇文章中的自定义model class部分(也就是“六步法”中的第三步) 和 模型保存地址 需要修改,其他代码都不用改变。
LeNet
LeNet 即 LeNet5,由 Yann LeCun 在 1998 年提出,做为最早的卷积神经网络之一,是许多神经网络架构的起点。
论文出处:Yann Lecun, Leon Bottou, Y. Bengio, Patrick Haffner. Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 1998.
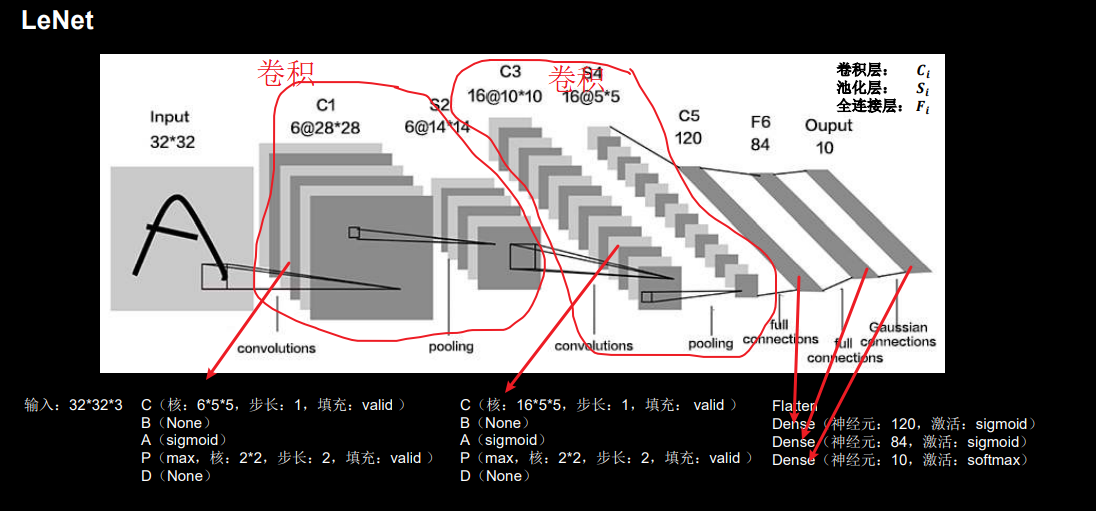
LeNet提出的时候,还没有批标准化和Dropout,激活函数也是sigmoid占据主流,所有它的卷积(CBAPD)非常的简单。
图中第一个卷积(CBAPD)使用的卷积核数量是6,因此第一层卷积输出的深度是6。同理,第二个卷积使用的卷积核个数是16,因此第二层卷积输出的深度是16。
通过下面的CBAPD对照图可以轻松地将网络结构转换为代码:
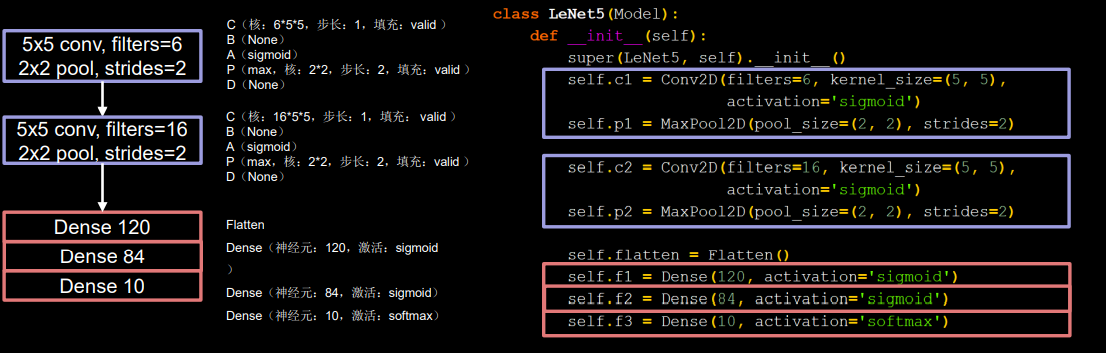
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
############################################### LeNet5 ###############################################
class MyLenet5(Model):
def __init__(self):
super(MyLenet5, self).__init__()
#CBAPD_1
self.c1=Conv2D(filters=6,kernel_size=(5,5),strides=1,padding='valid',activation='sigmoid')
# 没有BN,激活函数可以直接写在Conv2D()中
self.p1=MaxPooling2D(pool_size=(2,2),strides=2,padding='valid')
# CBAPD_2
self.c2=Conv2D(filters=16,kernel_size=(5,5),strides=1,padding='valid',activation='sigmoid')
# 没有BN,激活函数可以直接写在Conv2D()中
self.p1=MaxPooling2D(pool_size=(2,2),strides=2,padding='valid')
# 拉直
self.flatten=Flatten()
# 三个全连接层
self.f1=Dense(120,activation='sigmoid')
self.f2=Dense(84,activation='sigmoid')
self.f3=Dense(10,activation='softmax')
def call(self,x):
x=self.c1(x)
x=self.p1(x)
x=self.c2(x)
x=self.p2(x)
x=self.flatten(x)
x=self.f1(x)
x=self.f2(x)
y=self.f3(x)
return y
model = MyLenet5()
############################################### LeNet5 ###############################################
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 注意这里模型保存的地址也要修改一下
checkpoint_save_path = "./checkpoint/MyLenet5.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
AlexNet
AlexNet网络诞生于2012年,当年ImageNet竞赛的冠军,Top5错误率为16.4%
论文出处:Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. In NIPS, 2012.
可以说AlexNet的出现使得已经沉寂多年的深度学习领域开启了黄金时代。
AlexNet 的总体结构和 LeNet5 有相似之处,但是有一些很重要的改进:
- 由五层卷积、三层全连接组成,输入图像尺寸为 224 * 224 * 3,网络规模远大于 LeNet5;
- 使用了 Relu 激活函数;
- 进行了舍弃(Dropout)操作,以防止模型过拟合,提升鲁棒性;
- 增加了一些训练上的技巧,包括数据增强、学习率衰减、权重衰减(L2 正则化)等。
在具体实现中,我们对AlexNet做了一些调整:
- 将输入图像尺寸改为 32 * 32 * 3 以适应cifar10数据集
- 将原始的 AlexNet 模型中的 11 * 11、7 * 7、 5 * 5 等大尺寸卷积核均替换成了 3 * 3 的小卷积核
- alexnet原文使用的是用LRN(local response normalization)局部响应标准化,这里采用了BN(Batch Normalization)这一更主流的方法进行替代。
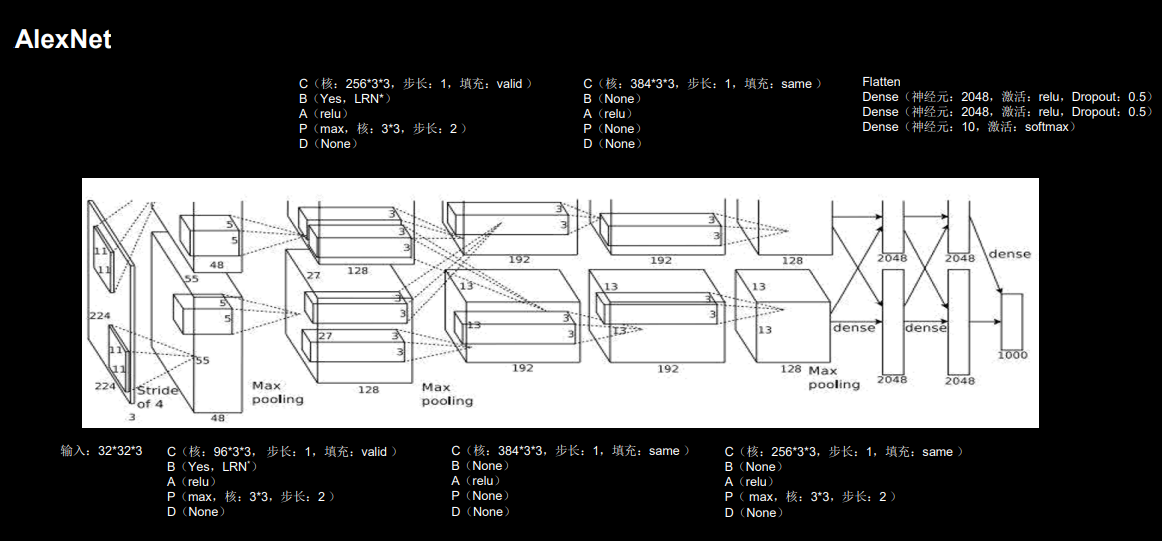
通过下面的CBAPD对照图可以轻松地将网络结构转换为代码:
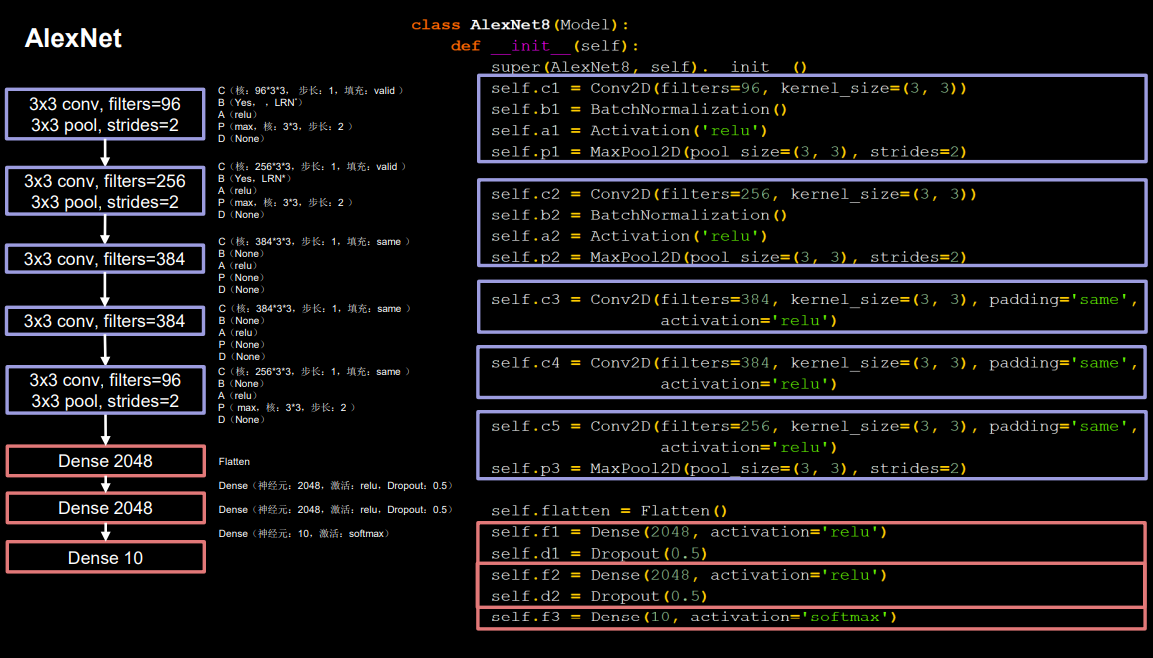
class MyAlexnet(Model):
def __init__(self):
super(MyAlexnet, self).__init__()
#CBAPD_1
self.c1=Conv2D(filters=96,kernel_size=(3,3),strides=1,padding='valid')
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.p1=MaxPooling2D(pool_size=(3,3),strides=2)
# CBAPD_2
self.c2 = Conv2D(filters=256, kernel_size=(3, 3), strides=1, padding='valid')
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPooling2D(pool_size=(3, 3), strides=2)
# CBAPD_3
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), strides=1, padding='same')
self.a3 = Activation('relu')
# CBAPD_4
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), strides=1, padding='same')
self.a4 = Activation('relu')
# CBAPD_5
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), strides=1, padding='same')
self.a5 = Activation('relu')
self.p5 = MaxPooling2D(pool_size=(3, 3), strides=2)
# 拉直
self.flatten=Flatten()
# 三个全连接层 以及两个Dropout
self.f1=Dense(2048,activation='relu')
self.d_1=Dropout(0.5)
self.f2=Dense(2048,activation='relu')
self.d_2=Dropout(0.5)
self.f3=Dense(10,activation='softmax')
def call(self,x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.a3(x)
x = self.c4(x)
x = self.a4(x)
x = self.c5(x)
x = self.a5(x)
x = self.p5(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d_1(x)
x = self.f2(x)
x = self.d_2(x)
y = self.f3(x)
return y
与结构类似的 LeNet5 相比,AlexNet模型的参数量有了非常明显的提升,卷积运算的层数也更多了,这有利于更好地提取特征;Relu 激活函数的使用加快了模型的训练速度;Dropout 的使用提升了模型的鲁棒性,这些优势使得 AlexNet 的性能大大提升。
VGGNet
VGGNet诞生于2014年,当年ImageNet竞赛的亚军,Top5错误率减小到7.3%
论文出处:K. Simonyan, A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.In ICLR, 2015
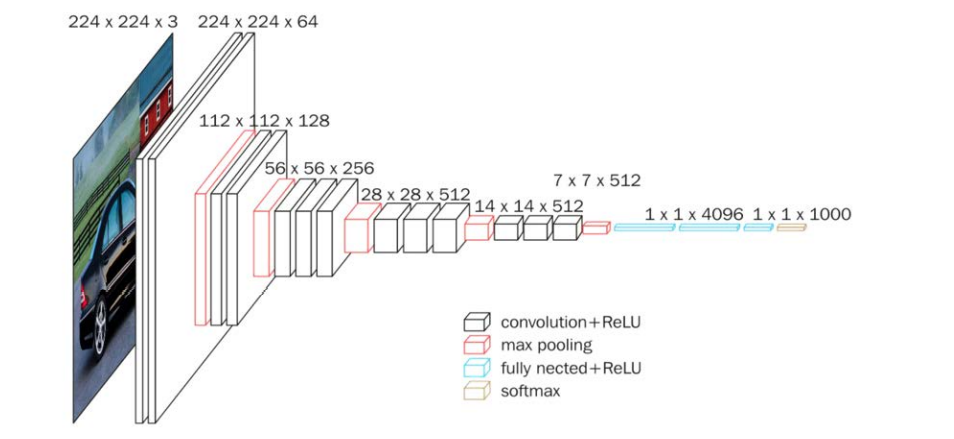
通过下面的CBAPD对照图可以轻松地将网络结构转换为代码:
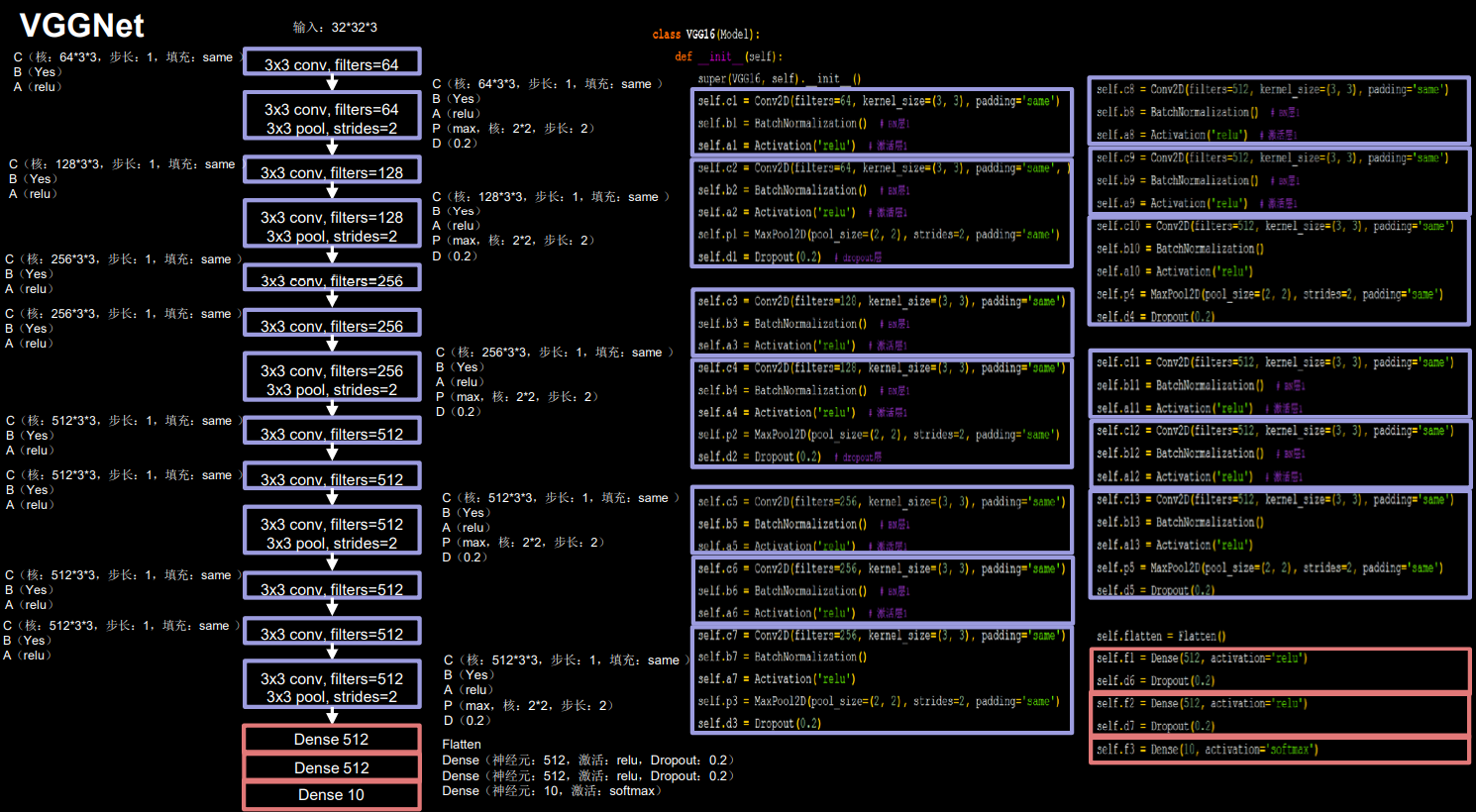
class MyVggnet16(Model):
def __init__(self):
super(MyVggnet16, self).__init__()
# CBA ABAPD ABA CBAPD CBA CBA CBAPD CBA CBA CBAPD CBA CBA CBAPD flatten dense dense dense
######################
# CBA ABAPD
self.c1=Conv2D(filters=64,kernel_size=(3,3),padding='same')
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.c2=Conv2D(filters=64,kernel_size=(3,3),padding='same')
self.b2=BatchNormalization()
self.a2=Activation('relu')
self.p2=MaxPooling2D(pool_size=(2,2),strides=2,padding='same')
self.d2=Dropout(0.2)
# CBA ABAPD
self.c3=Conv2D(filters=128,kernel_size=(3,3),padding='same')
self.b3=BatchNormalization()
self.a3=Activation('relu')
self.c4=Conv2D(filters=128,kernel_size=(3,3),padding='same')
self.b4=BatchNormalization()
self.a4=Activation('relu')
self.p4=MaxPooling2D(pool_size=(2,2),strides=2)
self.d4=Dropout(0.2)
# CBA CBA ABAPD
self.c5=Conv2D(filters=256,kernel_size=(3,3),padding='same')
self.b5=BatchNormalization()
self.a5=Activation('relu')
self.c6=Conv2D(filters=256,kernel_size=(3,3),padding='same')
self.b6=BatchNormalization()
self.a6=Activation('relu')
self.c7=Conv2D(filters=256,kernel_size=(3,3),padding='same')
self.b7=BatchNormalization()
self.a7=Activation('relu')
self.p7=MaxPooling2D(pool_size=(2,2),strides=2)
self.d7=Dropout(0.2)
# CBA CBA ABAPD
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization()
self.a8 = Activation('relu')
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization()
self.a9 = Activation('relu')
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p10 = MaxPooling2D(pool_size=(2, 2), strides=2)
self.d10 = Dropout(0.2)
# CBA CBA ABAPD
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization()
self.a11 = Activation('relu')
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization()
self.a12 = Activation('relu')
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p13 = MaxPooling2D(pool_size=(2, 2), strides=2)
self.d13 = Dropout(0.2)
# flatten dense dense dense
self.flatten=Flatten()
self.f1=Dense(512,activation='relu')
self.d_1=Dropout(0.2)
self.f1=Dense(512,activation='relu')
self.d_2=Dropout(0.2)
self.f1=Dense(10,activation='softmax')
def call(self,x):
####################
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.d2(x)
#####################
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p4(x)
x = self.d4(x)
####################
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p7(x)
x = self.d7(x)
####################
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p10(x)
x = self.d10(x)
####################
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p13(x)
x = self.d13(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d_1(x)
x = self.f2(x)
x = self.d_2(x)
y = self.f3(x)
return y
我这里代码和上面图片中的代码在每一层的命名上稍有不同,不过它们都是描述的同一个网络结构。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









