







六、TensorBoard的使用
探究模型在不同阶段是如何输出的
不同步数可以看到不同的结果
安装tensorboard
在pytorch环境里安装:
pip install tensorboard
安装成功!

1、SummaryWriter 类使用
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") #创建实例
2、writer.add_scalar() 方法的使用
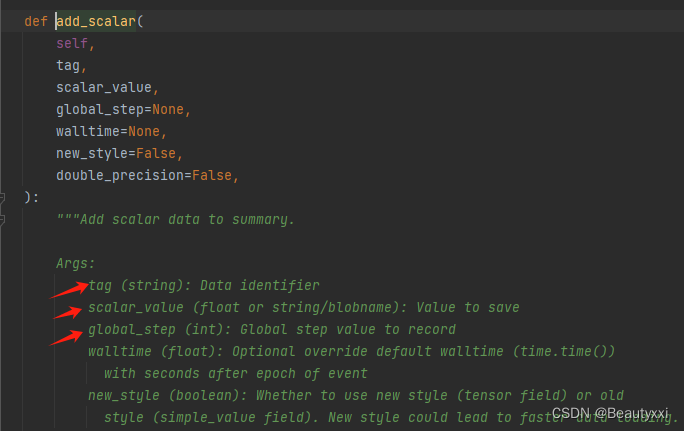
箭头分别对应:
图表标题
y轴
x轴
3、创建
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") #创建实例,名为logs
# writer.add_image()
# y = x
for i in range(100):
writer.add_scalar("y=x", i, i)
writer.close()
运行后多出一个 logs 的文件夹(tensorboard的一些事件文件)
4、如何打开事件文件
方法一:
在项目文件夹的地址下,输命令行:
tensorboard --logdir=logs #logdir=事件文件所在文件夹名

✳ 为了防止和别人冲突,可以指定端口
tensorboard --logdir=logs --port=6008

进入浏览器:
问题一: 点击进入后出现报错:

由于版本太高,减低版本
pip install tensorboard==2.12.0
问题二: 出现的不是直线,是一个类似三角形
生成了多次,还记录了上次的内容,
!把多余的文件删掉,或者把文件夹删掉重新运行
问题三: 出现两条直线
调节 smoothing 可以解决
5、writer.add_image() 方法的使用
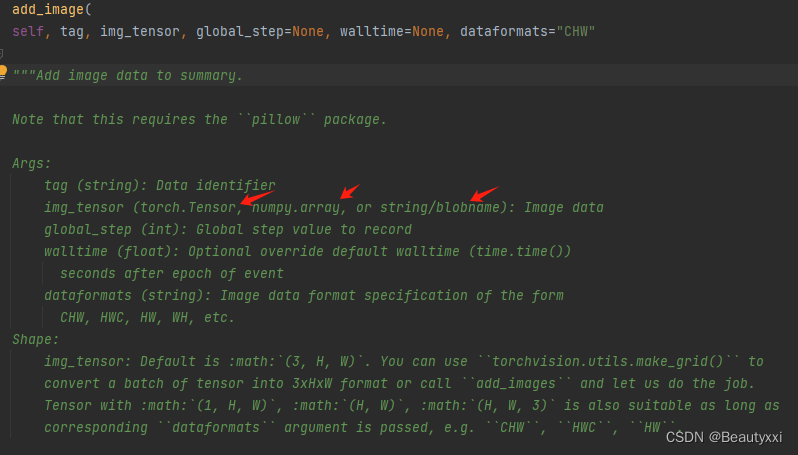
读取图片时:
image_path = "data/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(image_path)
print(type(img))
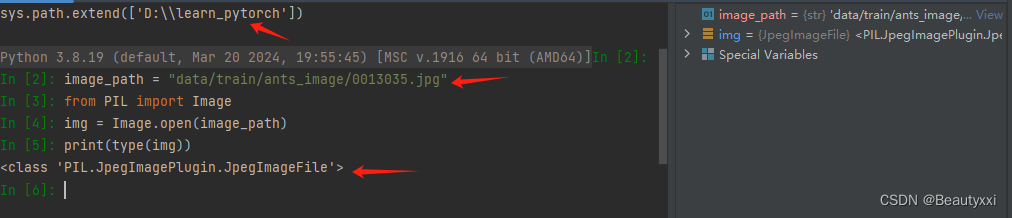
(1)由于在文件夹下打开,所以使用相对路径即可
(2)img 的类型不符合 add_image ,还需转换
关于第三个参数步数的解释,可以参考:https://blog.csdn.net/qq_38737428/article/details/121720853
6、利用opencv读取图片,获得numpy型图片数据
(1)安装 Opencv,读取图片
import cv2
cv_img = cv2.imread(img_path)
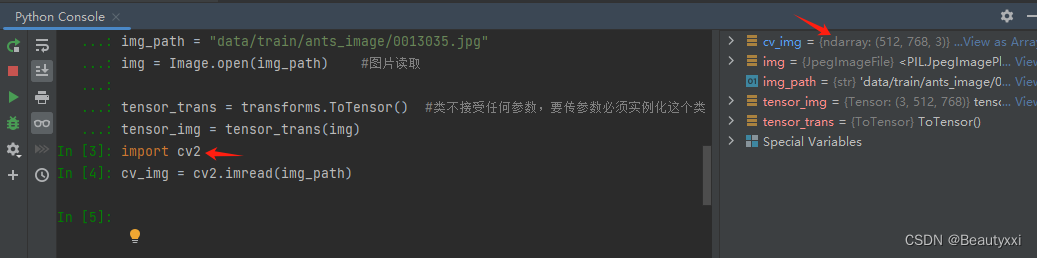
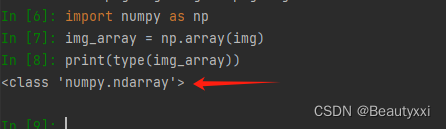
(2)将 PIL 类型转化为 numpy 类型
import numpy as np
img_array = np.array(img)
print(type(img_array))
⭐完整代码
如下:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs") #创建实例
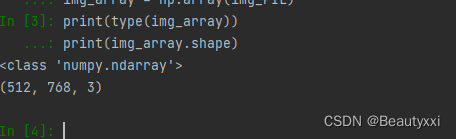
image_path = "data/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("test", img_array, 1, dataformats='HWC')
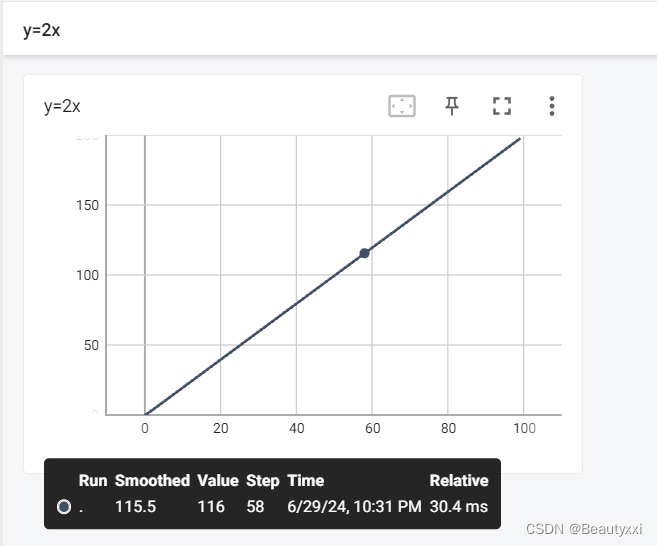
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
运行结果可视化:

❗出现报错,格式不符合,修改
通道在后面,粘贴dataformats='HWC'
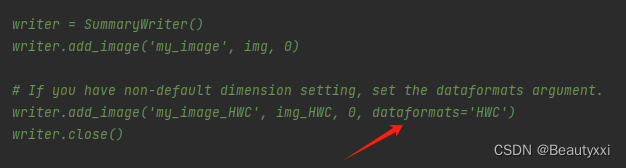
❗又出现报错:

是在pillow的10.0.0版本中,ANTIALIAS方法被删除了,降低版本
在命令行中依次输入:
pip uninstall -y Pillow
pip install Pillow==9.5.0
七、Transforms的使用(图像变换)
transforms.py工具箱
工具(class)
totensor
resize
特定格式的图片 经过处理 得到结果图片
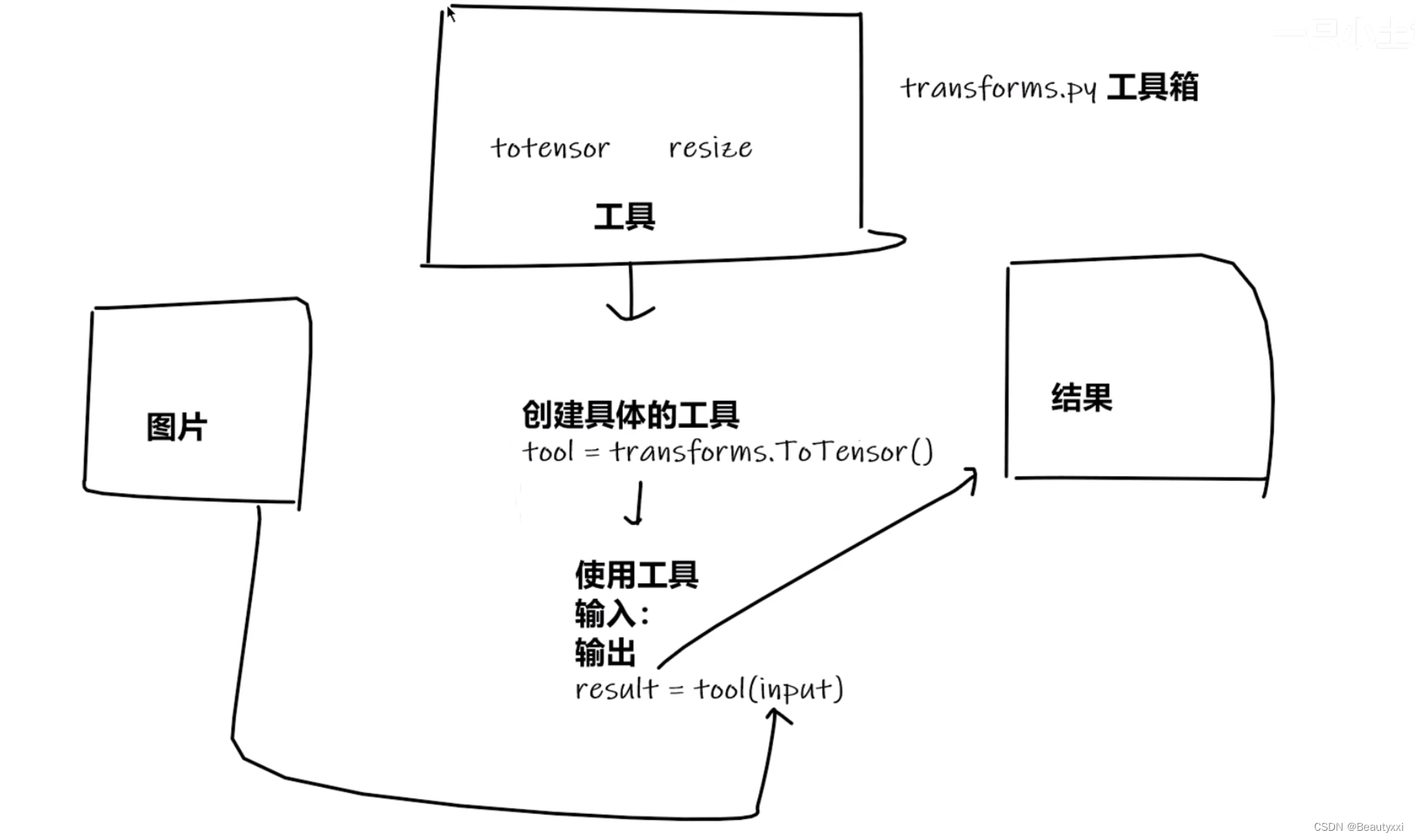
借助 structure 查看结构
⭐完整代码
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python的用法 ——> tensor数据类型
# 通过 transforms.ToTensor 来看两个问题
# 1、transforms 该如何使用(python)
# 2、为什么我们需要Tensor数据类型
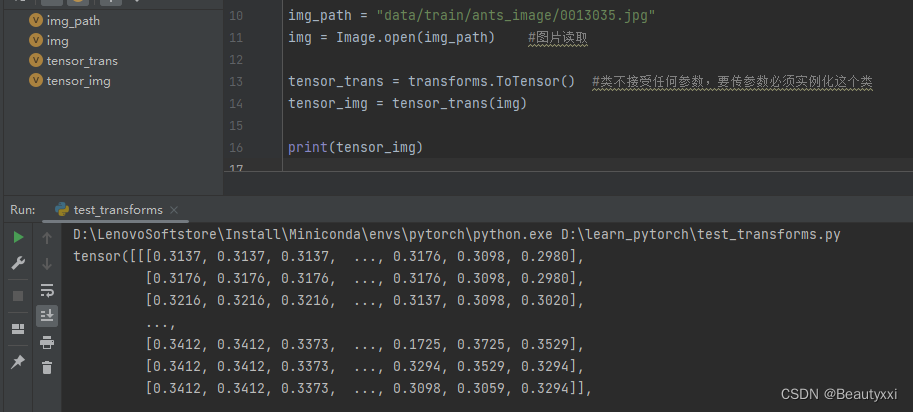
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path) #图片读取
writer = SummaryWriter("logs") #创建实例
tensor_trans = transforms.ToTensor() #类不接受任何参数,要传参数必须实例化这个类
tensor_img = tensor_trans(img)
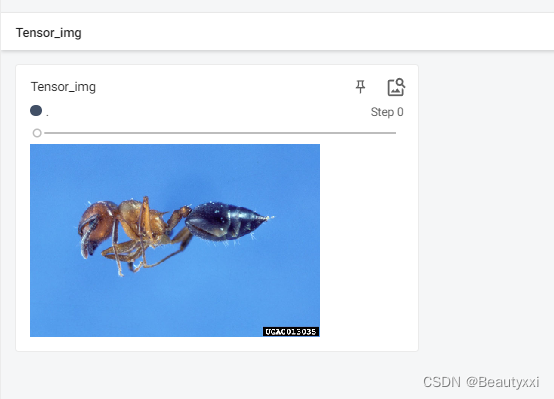
writer.add_image("Tensor_img", tensor_img)
writer.close()
成功显示图片:
python的用法 ——> tensor数据类型
通过 transforms.ToTensor 来看两个问题
⭐1、transforms 该如何使用(python)
tensor_trans = transforms.ToTensor() #类不接受任何参数,要传参数必须实例化这个类(创建的工具)
tensor_img = tensor_trans(img)
2、为什么我们需要Tensor数据类型
包装了神经网络的反向传播所需要的理论基础的参数
在神经网络中转化成 tensor 型,进行训练
注:
(1)出现波浪线即有错误,点小灯泡(Alt+回车)
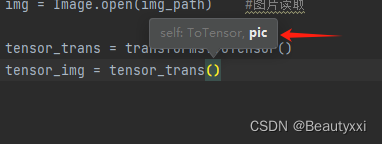
(2)CTRL + p ——>出现需要什么参数
(3)类不接受任何参数,要传参数必须实例化这个类
tensor_trans = transforms.ToTensor() #类不接受任何参数,要传参数必须实例化这个类
tensor_img = tensor_trans(img)
(4)没有实例化,报错
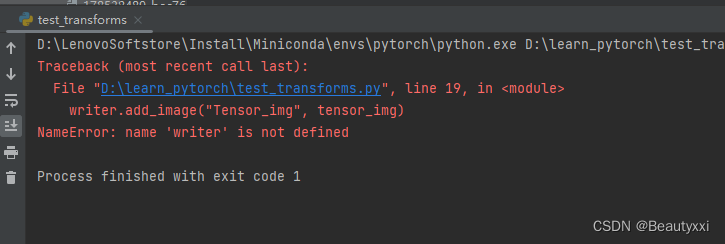
#错
SummaryWriter(“logs”)
#对
writer = SummaryWriter(“logs”)
3、常见的 Transforms
使用python文件中的不同的类,有不同的作用

内置__call__
内置__call__,可以不用点调用,直接对象名 + 括号参数调用
class Person:
def __call__(self, name):
print("__call__" + " hello " + name)
def hello(self, name):
print("hello " + name)
person = Person()
person("zhangsan")
person.hello("lisi")

忽略大小写,进行提示匹配
在设置中修改

图片的数组表示
PIL图片是(h, w, c)布局
进行tensor转化后,默认进行归一化处理,布局转化为(c, h, w)
np处理展示出图片数组,图片分为三通道,每一个通道为一个 h × w 的矩阵,图片像素点根据三通道计算得到。

(1)ToTensor
Convert a PIL Image or numpy.ndarray to tensor
#ToTensor 的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("totensor", img_tensor)
writer.close()
tensorboard显示:

(2)Normalize(归一化)
Normalize a tensor image with mean and standard deviation.
This transform does not support PIL Image.
Given mean: (mean[1],...,mean[n]) and std: (std[1],..,std[n]) for n
channels, this transform will normalize each channel of the input
torch.*Tensor i.e.,
output[channel] = (input[channel] - mean[channel]) / std[channel]
一般用于预处理:增加稳定性,防止溢出
#Normalize 的使用
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
writer.close()
公式:( input - 0.5 )/ 0.5 = 2 * input - 1
input [0,1]
output [-1, 1]
tensorboard显示:

print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1, 3, 5], [3, 2, 1])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 1)

(3)Resize
对图片进行缩放
Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have […, H, W] shape, where … means an arbitrary number of leading dimensions
Args:
size (sequence or int): Desired output size.
If size is a sequence like (h, w), output size will be matched to this.
If size is an int, smaller edge of the image will be matched to this number.
i.e, if height > width, then image will be rescaled to
(size * height / width, size).
1、按给定比例缩放
#Resize 的使用
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img是PIL数据类型,resize后还是PIL类型
img_resize = trans_resize(img)
# img_resize是PIL类型,ToTensor处理后,tensor数据类型
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize)
对图片进行压缩:

2、进行一个等比缩放,不改变高和宽的比例
#Compose resize --2
trans_resize_2 = transforms.Resize(512)
#PIL -> PIL ->tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img) #PIL类型
writer.add_image("Resize", img_resize_2, 1)

(4)Compose
Composes several transforms together. This transform does not support torchscript.
Please, see the note below.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
第一个的输出是第二个的输入,注意类型匹配
#Compose resize --2
trans_resize_2 = transforms.Resize(512)
#PIL -> PIL ->tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img) #PIL类型
writer.add_image("Resize", img_resize_2, 1)
(5)RandomCrop (随机裁剪)
Crop the given image at a random location.
按照指定规格随机裁剪
#RandomCrop
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)

总结使用方法
(1)关注输入输出类型
(2)看官方文档
(3)关注方法需要什么参数
输出数据类型:print(img) 或者 print(type(img))
⭐学习完整代码
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import numpy as np
writer = SummaryWriter("logs") #配置一下tensorboard
img = Image.open("images\lazysheep.jpg")
print(img)
img_np = np.array(img)
print(img_np[0][0][0])
#ToTensor 的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("totensor", img_tensor)
#Normalize 的使用
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1, 3, 5], [3, 2, 1])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
#Resize 的使用
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img是PIL数据类型,resize后还是PIL类型
img_resize = trans_resize(img)
# img_resize是PIL类型,ToTensor处理后,tensor数据类型
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize)
print(img_resize)
#Compose resize --2
trans_resize_2 = transforms.Resize(512)
#PIL -> PIL ->tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img) #PIL类型
writer.add_image("Resize", img_resize_2, 1)
#RandomCrop
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
八、torchvision 中的数据集使用(Dataset)
将 数据集 和 transforms 结合在一起
标准数据集的下载、组织 和 查看
数据集:
torchvision.datasets
COCO数据集:目标检测,语义分割
MNIST数据集:手写文字
CIFAR10:物体识别
CIFAR10 的使用(torchvision.datasets.XXX)

root:数据集位置
train:训练集
transform:想进行的变化
download:下载
数据集中返回的形式:

(1)下载数据集:
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
注:速度太慢的话,可以在迅雷中下载,复制链接就直接跳出了
如果没有显示链接,CTRL + 数据集 跳转到相应文件位置,复制 url 到迅雷下载。

查看测试集中的第一个:print(test_set[0])
输出(PIL文件):(<PIL.Image.Image image mode=RGB size=32x32 at 0x1AC5A7F94C0>, 3)
第一部分是 PIL 图片,第二部分是 target
(2)输出数据集图片
debug 显示信息
(打断点,点小虫)

测试代码
如下:
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
print(test_set[0]) #查看测试集中的第一个
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
效果如下:

(3)与 transforms 联动使用
将 ToTensor 应用到数据集中的每一张图片
1 将数据集中的图片转化为 tensor 类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
2 使用 TensorBoard 显示
writer = SummaryWriter("d_t")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
效果如下:

⭐完整代码
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
print(test_set[0])
writer = SummaryWriter("d_t")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
九、DataLoader 的使用
DataLoader:加载器,将数据加载到神经网络中。
从 dataset 中取数据,取多少数据,怎么取
1、DataLoader的一些参数:

dataset:告诉程序,数据集在什么地方,第一张数据、第二张数据在什么地方,数据集有多少数据。
自定义的 dataset 实例化放在DataLoader中即可。
batch_size:每次抓牌抓两张
shuffle:打乱
num_workers:多进程 or 单进程 加载
出现 错误 BrokenPipError:[Errno32] Broken pipe
可以将 num_workers 设置为 0
num_workers = 0
drop_last:数据集除不尽的时候 ,要不要舍去余下的图片
2、DataLoader的使用示例
(1)准备测试数据集
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
(2)建立Loader
test_Loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
(3)测试数据集中的第一张 图片 及 target
# 测试数据集中第一张 图片 及 target
img, target = test_data[0]
print(img.shape)
print(target)
结果如下:

(4)取出 test_Loader 中的每一个返回
# 取出 test_Loader 中的每一个返回
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)

四张融合在一起
采样器随机采样:

(5)查看 batch_size、drop_last 的效果
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("test_data", imgs, step)
step = step + 1
注:如果报错了,检查是否 add_images()函数 书写错误,写成add_image()会报错!!!
batch_size=64,drop_last=False 时:


batch_size=64,drop_last=True 时:
最后剩16张不足64张,所以会舍去

(6)查看 shuffle 的效果
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step = step + 1
writer.close()
shuffle=False时
进行两轮,图片取的顺序相同。

shuffle=True时
进行两轮,图片取的顺序会被打乱。

⭐完整代码
如下:
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张 图片 及 target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step = step + 1
writer.close()
# 取出 test_Loader 中的每一个返回
# print(targets)
# print(imgs.shape)















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









