







我自己的原文哦~ https://blog.51cto.com/whaosoft/11556615
#MultiTrust
清华领衔发布多模态评估MultiTrust:GPT-4可信度有几何?
本工作由清华大学朱军教授领衔的基础理论创新团队发起。长期以来,团队着眼于目前人工智能发展的瓶颈问题,探索原创性人工智能理论和关键技术,在智能算法的对抗安全理论和方法研究中处于国际领先水平,深入研究深度学习的对抗鲁棒性和数据利用效率等基础共性问题。相关工作获吴文俊人工智能自然科学一等奖,发表CCF A类论文100余篇,研制开源的ARES对抗攻防算法平台(https://github.com/thu-ml/ares),并实现部分专利产学研转化落地应用。
以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。
然而,多模态大模型是否安全可靠呢?
图1 对抗攻击GPT-4o示例
如图1所示,通过对抗攻击修改图像像素,GPT-4o将新加坡的鱼尾狮雕像,错误识别为巴黎的埃菲尔铁塔或是伦敦的大本钟。这样的错误目标内容可以随意定制,甚至超出模型应用的安全界限。
图2 Claude3越狱示例
而在越狱攻击场景下,虽然Claude成功拒绝了文本形式下的恶意请求,但当用户额外输入一张纯色无关图片时,模型按照用户要求输出了虚假新闻。这意味着多模态大模型相比大语言模型,有着更多的风险挑战。
除了这两个例子以外,多模态大模型还存在幻觉、偏见、隐私泄漏等各类安全威胁或社会风险,会严重影响它们在实际应用中的可靠性和可信性。这些漏洞问题到底是偶然发生,还是普遍存在?不同多模态大模型的可信性又有何区别,来源何处?
近日,来自清华、北航、上交和瑞莱智慧的研究人员联合撰写百页长文,发布名为MultiTrust的综合基准,首次从多个维度和视角全面评估了主流多模态大模型的可信度,展示了其中多个潜在安全风险,启发多模态大模型的下一步发展。
- 论文标题:Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study
- 论文链接:https://arxiv.org/pdf/2406.07057
- 项目主页:https://multi-trust.github.io/
- 代码仓库:https://github.com/thu-ml/MMTrustEval
MultiTrust基准框架
从已有的大模型评估工作中,MultiTrust提炼出了五个可信评价维度——事实性(Truthfulness)、安全性(Safety)、鲁棒性(Robustness)、公平性(Fairness)、隐私保护(Privacy),并进行二级分类,有针对性地构建了任务、指标、数据集来提供全面的评估。

图4 MultiTrust框架图
围绕10个可信评价子维度,MultiTrust构建了32个多样的任务场景,覆盖了判别和生成任务,跨越了纯文本任务和多模态任务。任务对应的数据集不仅基于公开的文本或图像数据集进行改造和适配,还通过人工收集或算法合成构造了部分更为复杂和具有挑战性的数据。

图5 MultiTrust任务列表
与大语言模型(LLMs)的可信评价不同,MLLM的多模态特征带来了更多样、更复杂的风险场景和可能。为了更好地进行系统性评估,MultiTrust基准不仅从传统的行为评价维度出发,更创新地引入了多模态风险和跨模态影响这两个评价视角,全面覆盖新模态带来的新问题新挑战。

图6 多模态风险和跨模态影响的风险示意
具体地,多模态风险指的是多模态场景中带来的新风险,例如模型在处理视觉误导信息时可能出现的错误回答,以及在涉及安全问题的多模态推理中出现误判。尽管模型可以正确识别图中的酒水,但在进一步的推理中,部分模型并不能意识到其与头孢药物共用的潜在风险。

图7 模型在涉及安全问题的推理中出现误判
跨模态影响则指新模态的加入对原有模态可信度的影响,例如无关图像的输入可能会改变大语言模型骨干网络在纯文本场景中的可信行为,导致更多不可预测的安全风险。在大语言模型可信性评估常用的越狱攻击和上下文隐私泄漏任务中,如果提供给模型一张与文本无关的图片,原本的安全行为就可能被破坏(如图2)。
结果分析和关键结论

图8 实时更新的可信度榜单(部分)
研究人员维护了一个定期更新的多模态大模型可信度榜单,已经加入了GPT-4o、Claude3.5等最新的模型,整体来看,闭源商用模型相比主流开源模型更为安全可靠。其中,OpenAI的GPT-4和Anthropic的Claude的可信性排名最靠前,而加入安全对齐的Microsoft Phi-3则在开源模型中排名最高,但仍与闭源模型有一定的差距。
GPT-4、Claude、Gemini等商用模型针对安全可信已经做过许多加固技术,但仍然存在部分安全可信风险。例如,他们仍然对对抗攻击、多模态越狱攻击等展现出了脆弱性,极大地干扰了用户的使用体验和信任程度。

图9 Gemini在多模态越狱攻击下输出风险内容
尽管许多开源模型在主流通用榜单上的分数已经与GPT-4相当甚至更优,但在可信层面的测试中,这些模型还是展现出了不同方面的弱点和漏洞。例如在训练阶段对通用能力(如OCR)的重视,使得将越狱文本、敏感信息嵌入图像输入成为更具威胁的风险来源。
基于跨模态影响的实验结果,作者发现多模态训练和推理会削弱大语言模型的安全对齐机制。许多多模态大模型会采用对齐过的大语言模型作为骨干网络,并在多模态训练过程中进行微调。结果表明,这些模型依然展现出较大的安全漏洞和可信风险。同时,在多个纯文本的可信评估任务上,在推理时引入图像也会对模型的可信行为带去影响和干扰。

图10 引入图像后,模型更倾向于泄漏文本中的隐私内容
实验结果表明,多模态大模型的可信性与其通用能力存在一定的相关性,但在不同的可信评估维度上模型表现也依然存在差异。当前常见的多模态大模型相关算法,如GPT-4V辅助生成的微调数据集、针对幻觉的RLHF等,尚不足以全面增强模型的可信性。而现有的结论也表明,多模态大模型有着区别于大语言模型的独特挑战,需要创新高效的算法来进行进一步改进。
详细结果和分析参见论文。
未来方向
研究结果表明提升多模态大模型的可信度需要研究人员的特别注意。通过借鉴大语言模型对齐的方案,多元化的训练数据和场景,以及检索增强生成(RAG)和宪法AI(Constitutional AI)等范式可以一定程度上帮助改进。但多模态大模型的可信提升绝不止于此,模态间对齐、视觉编码器的鲁棒性等也是关键影响因素。此外,通过在动态环境中持续评估和优化,增强模型在实际应用中的表现,也是未来的重要方向。
伴随MultiTrust基准的发布,研究团队还公开了多模态大模型可信评价工具包MMTrustEval,其模型集成和评估模块化的特点为多模态大模型的可信度研究提供了重要工具。基于这一工作和工具包,团队组织了多模态大模型安全相关的数据和算法竞赛[1,2],推进大模型的可信研究。未来,随着技术的不断进步,多模态大模型将在更多领域展现其潜力,但其可信性的问题仍需持续关注和深入研究。
参考链接:
[1] CCDM2024多模态大语言模型红队安全挑战赛 http://116.112.3.114:8081/sfds-v1-html/main
[2] 第三届琶洲算法大赛--多模态大模型算法安全加固技术 https://iacc.pazhoulab-huangpu.com/contestdetail?id=668de7357ff47da8cc88c7b8&award=1,000,000
#从裸机到700亿参数大模型
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。
这篇文章来自于 AI 初创公司 Imbue,该公司致力于通过理解机器的思维方式来实现通用智能。
当然,将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群并不是一个轻松的过程,充满了探索和试错,但 Imbue 最终成功训练了一个 700 亿参数的 LLM,并在此过程中积累了许多有用的经验。
本文将深入介绍该团队构建自己的 LLM 训练基础设施的全过程,并会分享他们为方便监控、检查和纠错而编写的诸多工具和脚本。
如果你有心构建自己的 LLM 训练基础设施或好奇 LLM 是如何炼成的,那么这篇文章值得你阅读和收藏。
以下是 Imbue 团队文章原文。
引言
我们这个由研究者和工程师组成的小团队用了几个月时间在自己的基础设施上从头开始训练了一个 700 亿参数量的模型,并且该模型在推理相关的任务上胜过了零样本的 GPT-4o。
今天,我们要分享的是设置所需基础设施的过程:从组合初始集群和安装操作系统到设置在训练期间遭遇错误时自动恢复。我们会详细说明在每一步遭遇到的难题和解决方法。除了这些心得之外,我们还将发布我们一路上开发的许多脚本,以便其他团队能更轻松地为自己的模型训练创建稳定的基础设施。
在整个过程中,我们的工程师团队与 Voltage Park 一起准备好了计算机集群,构建了生产应用的基础。这整个过程包括:
1. 配置各台机器
2. 配置 InfiniBand
3. 确保机器完全健康
4. 诊断常见的训练问题
5. 改进基础设施工具
下面将详细描述每个步骤。
背景:这是如何炼成的
我们执行计算的目标是确保能快速实验大型语言模型。为此,我们需要大量高速 GPU,并且这些 GPU 之间也能高速通信。
本文将重点关注一个集群,其中包含分散在 511 台计算机中的 4088 台 H100 GPU,也就是每台计算机 8 台 GPU。之所以有 511 台带 GPU 的计算机,是因为需要保留一些连接给统一结构管理器(Unified Fabric Manager)节点,其作用是管理 InfiniBand 网络。在 511 台带 GPU 的主机上,每台 GPU 都直接与一块 ConnectX-7 网卡相连,其能以 400 Gbps 的速度与该 InfiniBand 网络中的任意 GPU 传输数据。
我们的 InfiniBand 网络拓扑结构的形式是「fully non-blocking」,即完全无阻塞;理论上讲,这能让 GPU 以最大速度互相通信。为此,我们使用了一种三层式 InfiniBand 网络架构:三层 InfiniBand 交换机。只要连接正确,便能让整个网络都获得这样高水平的吞吐量。下图展示了这个 InfiniBand 网络的概况:

请注意,训练网络时的通信发生在 InfiniBand 上,而不是以太网上。尽管这些机器也连接了以太网,但该网络的作用是传输数据集和检查点等数据。如果使用以太网来发送数据,速度会慢得多,因为数据会先从 GPU 传输到 CPU,然后再通过 100 Gbps 速度的以太网卡发出去。尽管也可以使用名为 RDMA over Converged Ethernet(RoCE)的技术基于以太网进行训练,但那需要在硬件和软件方面都做大量额外工作,并且可靠程度通常也不及 InfiniBand。详情可参阅这篇论文:https://arxiv.org/pdf/2402.15627
另外还有一个仅用于配置和管理的辅助以太网,从而可访问 BIOS(基本输入输出系统)、电源和其他低层机器接口的控制界面。如果没有这个管理网络,我们就必须通过 USB 驱动、键盘和显示器来手动设置每个节点。对于有几百台机器的情况,这并非一种可持续的方法。
要在这个集群上实现高性能训练,就需要每个组件(InfiniBand、以太网、GPU 和节点本身)都近乎完美地工作。如果这 12,000 多个连接中有任何一个有点不稳定,就会拖慢整体的训练运行速度。
本文接下来的内容就是介绍如何让这一切都完美且稳定地运行。
过程:如何将裸机变成完全可运行的集群
配置各台机器
在通过管理网络建立了与集群的初始以太网连接之后,就获得了基板管理控制器(BMC/baseboard management controller)的访问凭证。BMC 是一种远程监控主机系统的专用服务处理器,并且通常连接到一个分立的网络。它能让我们就像是亲身在现场一样操作机器,并还额外提供了硬件健康状况、BIOS 设置和电源管理的 API。
配备好这些组件后,我们就可以撸起袖子,开始设置集群了。
- 步骤 0:先配置好一台机器
我们首先使用 iDRAC(戴尔的基板管理控制器)在一台服务器上安装 Ubuntu 22.04,然后再基于这个操作系统设置其他一切。iDRAC 的一项能力是允许从本地计算机安装和启动 ISO 镜像,并通过浏览器提供一个虚拟控制台。理想情况下,这是该过程中唯一的手动安装步骤。
- 步骤 1:在每台机器上安装操作系统
在配置完第一台机器.之后,继续安装 Ubuntu 的 Metal-as-a-Service (MAAS) 软件以帮助配置剩余的服务器。使用预启动执行环境协议(PXE)启动和自动化 iDRAC 工具,可指示每台机器从网络启动并配置 MAAS 以响应 PXE 启动请求。在执行初始的网络启动时,服务器会通过动态 IP 分配协议 DHCP 从 MAAS 获得一个 IP 和一个初始内核,而无需在本地驱动器上安装任何东西。这是用于自动重复执行操作系统安装的基本环境。从理论上讲,我们只需等待第一次启动,然后一切都会被处理好。但实际上,MAAS 与 BMC 的整合并不可靠,因此我们使用 iDRAC API 来事先收集每台机器的 MAC 地址(一种唯一的物理硬件标识符)。
在这整个训练过程中,MAAS 通常是椎栈中比较可靠的组件。但是,我们在开始时遇到了一些我们的设置特有的问题。举个例子,在配置前几台机器时,由于时钟相差太大,HTTPS 证书验证问题导致无法通过 apt 安装任何东西。与此相关的是,由于 MAAS 服务器必须负责很多事情(DHCP 服务器、用于将主机名解析成 IP 的 DNS 服务器、主机和官方 Ubuntu 软件包服务器之间的 HTTP 代理、NTP 服务器、cloud-init 配置管理、用于将 MAC 地址连接到 IP 到主机名再到自定义元数据的 ground truth 数据库),因此我们很难从根源上解决这些问题。此外,还有 MAAS 配置生命周期的学习曲线问题,因为是设计目标是处理管理绿地部署(greenfield deployment)的复杂性以及节点的逐步迁移和各种调试 / 不健康的中间状态。
- 步骤 2:诊断损坏的机器
我们发现大约 10% 的机器都无法启动,主要原因是服务器的物理问题。这是设置大型 GPU 集群的常见情况。我们遇到的情况包括:没接网线或接错了网线、iDRAC 中的硬件问题、电源单元损坏、NVME(快速非易失性内存)驱动损坏、内部线路缺失、网卡或 GPU 无法显示。我们自动检查了这些问题,将一些机器退回给了戴尔以重新测试,并为数据中心工作人员提交相应的工单。我们自己上手配置集群的一个优势是:在等待维护某些机器的同时就能立即使用健康的机器。
- 步骤 3:最小可行可观察机器
我们继续在每台服务器上进行如下设置:
1.Docker(以便更轻松地运行服务和训练作业)
2. 数据中心 GPU 驱动
3.Prometheus 节点导出工具(用于导出稳定的硬件 / 操作系统指标数据流)
4.DCGM 导出工具(用于从英伟达 GPU 导出额外的指标数据,如 GPU 状态、时钟、利用率)
5. 所有非操作系统驱动的 RAIDZ ZFS 池,这让机器在某个驱动失效时也能继续工作,同时还能免费提供透明的压缩(这对纯文本数据集和重复性日志尤其有用 —— 相比于不使用该工具,使用该工具通常能将可使用的空间增大 10 倍)
然后我们运行基本的 GPU 诊断以确定 GPU 是否大体功能正常 —— 不正常的通常会在几个小时内出现硬件问题。
在此期间,当我们试图同时在全部 400 个节点上安装软件包时,我们遭遇了带宽瓶颈。这是我们第一次在数据中心部署的多个组件上收到高温过热警报。这首批发热问题基本上都通过固件更新得到了解决。
- 步骤 4:单节点的 GPU 训练
下一步是确保每台机器都能够单独处理真实的 GPU 工作负载。很多机器都无法做到这一点,问题包括:
- GPU 相关的错误,这类问题基本都可通过将 GPU 卡重新插入卡槽来解决:将 200 磅重的服务器从机架上滑出来,移除机盖和 GPU 之间的所有线缆,然后取出 GPU,再重新装上 GPU,之后再重新接上线缆并把服务器推回机架。
- 根据 Ubuntu 服务器日志,GPU 和 PCIe 总线或网卡之间的许多线缆都发出了这样的报错:「limited width: x4 < x16」。在更新 PCIe 交换机总线固件后,我们发现大约四分之一的主机需要重新安装内部 PCIe 线缆 —— 大概是因为外壳和 GPU 之间的线缆相当脆弱,这意味着每当对 GPU 进行维护时,这些线缆都会被推挤或拔掉。
- 还有一些杂项故障也影响了几台主机。戴尔通过固件升级帮助我们解决了一些问题:
- NVMe 驱动器没有显示故障,但触摸时会锁定整台机器。
- 硬盘驱动器在 Linux 下以随机顺序显示,这给 MAAS 造成了混乱,并会导致操作系统被安装在错误的驱动器上。
- 温度读数错误,这会导致风扇一直全速运转。其原因可能是英伟达驱动有问题,这通过降级驱动版本而得到了解决。
- CPU 的动态调频失控,将工作内核限制为 2 GHz。
- 直接的 GPU-GPU 通信(GDR 或 GPUDirect RDMA Peer Memory Client)无法成功应用。
配置 InfiniBand
- 步骤 0:安装 UFM
InfiniBand 的一个优势是其中心化的设计,这样一来整个网络就有了一个大脑。因此,对于整个网络结构中的 320 个网络交换机,我们只需处理其中一个实例。我们的首个任务是搞清楚哪台交换机连接了哪些机器,然后将其与接线图关联起来,并根据交换机的物理位置重新命名它们。
- 步骤 1:重新布线
一开始,UFM 无法检测到那 320 台交换机,更别说本应出现在网络结构中的主机了。在与我们的数据中心合作伙伴商讨之后,我们确认这些交换机已通电并接好了线,但依然无法检测到。在检查网络布线列表后,我们注意到该网络结构的顶层设计有误:这个结构不是统一的,而是分成了八个没有公共路由路径的互相脱离的网络。在重新接线之后,我们添加了检查步骤,以验证所有物理连接是否与新设计一致。
- 步骤 2:一万次温度告警(alert)
在解决了物理接线问题之后,InfiniBand 成功建立了与网络结构中所有 InfiniBand 交换机的联系。但是,几乎每个交换机端口都开始报告温度过高,有时候超过 70 ℃,即便它们还没有传输数据。我们发现这个问题源自同一机架中交换机之间的开放空间,这导致热空气回流到了前面。我们的数据中心合作伙伴帮助我们快速诊断出了该问题并制定了合适的解决方法。
- 步骤 3:1800 次告警
许多端口还有很高的错误率,或在正常和损坏状态之间来回变动,这被称为「抖动(flapping)」。这些问题只有在实际使用这些端口时才会出现,所以很难预先检测,因为我们的整个结构由 10,000 条高度冗余的链路组成。我们的数据中心合作伙伴帮助清洁和重新安装告警的端口,我们在等待替换时禁用了剩余的警报收发器。
尽管 InfiniBand 能弹性地应对硬件故障,但一旦大约 10% 的结构开始出现问题,自适应路由等功能就无法可靠地运行,无法解决偶尔丢失链路的问题。
在此期间,我们成功使用 100 到 200 台机器运行了多节点训练。我们的流程比较即兴:我们有时会随机启动一组节点,观察它们的性能,然后尽力让其中尽可能多的节点保持运行。该方法可让我们找到该 InfiniBand 网络结构中一组可靠的子集,但难度却很大,因为每次都需要改变用于训练的节点集合,由此改变默认的 InfiniBand 链路。
- 步骤 4:InfiniBand 疯狂燃烧
为了更高效地诊断 InfiniBand 问题,我们专门为整个集群设计了一个工作负载,其作用是同时将尽可能多的数据推送经过整个结构中的每个端口。这不同于在整个集群上运行一个大型的 all-reduce 工作负载,这需要使用 NCCL 来优化各个节点之中的通信,方法是使用 NVLink 经由 Server PCIe Module (SXM) 插槽来实现 GPU 通信。
相反,我们选择了一种蛮力方法,并轻松取得了成功。UFM 会在大多数端口的数据传输量超过理论容量的 97% 时开始发出警报,同时一些交换机会暂时宕机。我们认为能坚持到当天结束时的每个端口都是足够稳健的,其余的都被禁用或移除以待维修。
- 步骤 5:GPUDirect RDMA
要让 GPU 通信时不产生 CPU 计算开销,我们启用了一个名为 GPUDirect RDMA 的功能,其允许 InfiniBand 网卡之间直接通信。这涉及两个关键步骤:
1. 启动一个额外的核模块
2. 确保 PCIe Access Control Service (ACS) 被禁用,以防止 immediate hangs(立即挂起)
- 步骤 6:扩增「黄金」服务器
要使用最新硬件构建 GPU 集群,一个经验法则是:每周都有大约 3% 的机器出问题,要做好准备。
但是,需要说明一点:并不是每台机器都统一有 3% 的几率发生故障,而是少量不对付的机器反复出现各种不同问题,直到将它们妥善修复。这就凸显了在同一网络结构中配备大量机器的优势。因此,我们的做法不是随便找些机器来运行大规模训练,就像打地鼠一样看哪些出问题,而是专注于扩增已知可靠的服务器,也就是「黄金」服务器。
- 步骤 7:维护
InfiniBand 的维护主要涉及到响应 UFM 警报、更换故障线缆和收发器,以及偶尔诊断更困难的错误(比如交换机故障)。导致大规模维护的因素通常有两个:
1. 固件更新,尤其是集群中仅有一半完成更新时,这可能导致 UFM 状态损坏并必需重启所有 InfiniBand 交换机上的 UFM。
2.GPU 盒同时大规模重启,这可能会向 UFM 状态灌入大量更新,并同样需要重启 UFM 服务。
确保机器完全健康
在此过程中,我们发现了单台机器的多种故障或减慢训练速度的方式。其中许多故障模式并不会立即显现,因此我们编写了许多健康检查脚本,以检查主机是否足够健康。我们在这里发布了这些代码:https://github.com/imbue-ai/cluster-health
请注意,这些健康检查中的很多都特定于我们的运行时环境,并不一定与基础硬件相关,也不一定容易修复或自动化。这是设计决定的:为了实现让我们的机器准备好训练的总体目标,我们想要一个可以直接了当地回答「是」或「否」的单一入口点,并且可以概括总结任意数量的细微细节。
- GPU 健康检查
我们检查了 GPU 数量是否正确、ECC(错误更正代码)检查是否已启用以及是否存在 ECC 错误。我们还检查了 NVLink 拓扑(将 GPU 彼此连接起来)是否已启动且无错误。
- 磁盘空间健康检查
我们检查了主机的磁盘空间利用率是否超过 95%。
- Docker 健康检查
我们检查了 Docker 能否在连接了 GPU 的情况下运行容器(即 NVIDIA Container Runtime 是否正常工作),还检查了与监控 / 分析相关的 Docker 容器是否已激活并获得了正确的主机权限。
- Dmesg 健康检查
我们检查了 dmesg 中是否存在硬件 Xids 或 SXid 错误(由 NVIDIA GPU 或 GPU 间 NVIDIA 交换机引发的故障)。我们还读取了所有 dmesg 日志行,以验证它们是否都可以归类到「常见 / 预期日志行」列表中。
- iDRAC 健康检查
我们检查了机器上的 iDRAC 错误,其中忽略了非致命错误消息。这是戴尔计算机特有的检查,所以没有被包括在我们开源的代码中。
- 磁盘健康检查
我们检查了 zpool 是否已安装,Docker 是否已正确连接到它,以及它是否真的可以在不锁定 CPU 的情况下触及它。
- InfiniBand 健康检查
我们检查了 InfiniBand 的错误率是否会增加和 / 或驱动固件是否过时。
- Nvlink 健康检查
我们检查了机器上的 NVLink 错误。实践中看,这似乎不会导致训练失败,但可能会降低训练速度。
- GDR 健康检查
我们检查了机器上的 GDR 是否已启用。
- VBIOS 健康检查
我们检查了 GPU 的 VBIOS 版本以及 H100 基板固件是否是最新的。
- Flint 健康检查
我们使用 flint 和 hca_self_test 检查了 Mellanox OFED 驱动、网卡固件和收发器固件的版本是否正确,以及它们是否针对英伟达驱动进行了正确编译。
- PSB 健康检查
我们查询了 PCIe 设备,以检查 GPU、PSB(PCIe 交换机总线)和网卡之间的连接速度和宽度是否符合我们的预期。我们还检查了交换机固件是否为最新版本。该脚本由戴尔而非 Imbue 开发,所以我们目前无法共享它。
除了这些快速健康检查,我们还进行了一些更复杂的健康检查,包括:
- 通过 PyTorch 初始化矩阵计算,以及测量 NVLink 带宽和 GPU 计算速度和内存。我们设置了适当的 GDR 标志来测试 InfiniBand 和 NVLink。
- 使用 ib_write_bw 和 –use_cuda 通过 IB 卡发送数据并测量 PCIe 和 InfiniBand 卡带宽。这个过程持续了较长时间(约 15 分钟),以确保能找出抖动的 InfiniBand 链路。
- 运行多节点诊断运行以检查 NCCL 初始化能力以及它是否会随机停顿。如有停顿,则我们的分叉版 NCCL 代码会添加额外的日志记录。这需要 12 到 24 小时才能检测到问题,因此我们通常只对新节点或我们怀疑存在问题时运行此操作。
- 检查 DCGM 导出是否存在任何 GPU 时钟节流事件(不包括预期的 gpu_idle 和 power_cap)。为了检查这些电源事件,最好的方法是运行多节点训练,以同时检查所有 GPU、InfiniBand 卡以及 CPU 和磁盘。
诊断常见的训练问题
一旦硬件能正常工作,就可以开始训练了。
这一节将基于我们在我们的集群上运行大型语言模型训练的经验,分享一些具体的调试步骤和见解。
- 启动时崩溃
从某种程度上讲,这是所能遇到的最好的错误,因为其(理论上)很容易重现和迭代。
我们首先检查了我们的代码是否在正确的版本、配置和环境变量上运行。虽然很基础,但我们发现这一点至关重要:确保启动训练过程是可复现且容易检查的。一大原因是 Docker 镜像缓存或不透明秘密配置等中间抽象可能会造成混淆。
我们执行的另一个基础检查是确保所有机器都在线,并且可以轻松地聚合和检查所发出的栈跟踪记录或日志。我们使用了 Loki、Prometheus 和 Grafana 软件栈,但任何合适的日志聚合或跟踪 SaaS 的工具都可以。由于这些训练运行过程本质上是同步的和分布式的,因此第一个错误往往就会导致一连串的不相关错误。在这里,健康检查还可以帮助立马检测出硬盘驱动器损坏或 GPU 缺失或无效等错误。
我们构建了一个在发生故障时自动重启的系统,这使得日志和错误聚合变得更加重要,以避免混淆来自不同重启的错误。我们遇到的一些常见错误包括:
1.「Forward order differs across ranks: rank 0 is all-gathering 43 parameters while rank 1228 is all-gathering 1 parameters」这样的错误。我们发现这是 PyTorch 完全分片数据并行(FSDP)实现的一个奇怪特性,可通过重启解决。
2.GPU 内存不足(OOM)错误,看起来像这样:「CUDA out of memory. Tried to allocate …」通过多次检查我们的配置和代码并撤销近期的代码修改(由于启动期间 PyTorch 设备规格不正确而导致过多使用 GPU#0),我们解决了这些问题。
3.CPU/RAM 内存不足(OOM)错误,这些错误在错误日志中不太容易发现,并且通常能通过 Docker 容器外的主机的 dmesg 日志检测出来。当 OOM Killer 调用停止一个分叉进程或同级网络(network peer)时,我们可以看到它们主要表现为 CalledProcessError 或 ConnectionError。当从 dmesg 检测到了 OOM Killer 调用时,我们更倾向于直接放弃健康检查,并重启该机箱。我们还检查了我们的代码路径是否有足够的手动垃圾收集(下面有一部分介绍了如何禁用它),并还检查了是否有意外尝试进行计算或将张量移动到 CPU 上。
- 在训练过程中崩溃
首要任务是让系统能自动运行,让其能自动重新运行所有健康检查,然后在没发现不健康主机时重启运行。我们遇到了一些随机的硬件错误,包括 Xid 和 SXid 错误;这些错误可能会导致运行崩溃,却不会发出有意义的 Python 栈跟踪记录。行重映射等一些问题可通过重启恢复。不可纠正的 ECC 错误等另一些问题则往往需要硬件维护或更换零件。
此外,我们还观察到格式错误的训练数据也会导致崩溃。举个例子,如果语料库中有一个非常大的单个文档,就可能导致 GPU 或 CPU 出现内存不足错误。为了防止出现这个问题,我们采用了完全确定式的数据加载器 —— 通过与 epoch 或步数相关联,让每一次崩溃都可轻松复现。我们发现禁用数据加载或替换假数据(例如全零数据)有助于确认错误的根本原因是否是数据。
最后,通过指标聚合方法记录网络和一般节点的健康统计数据也很有帮助。以太网短暂断开或磁盘空间不足等问题可能不会显示为有用的错误消息,但却可以很轻松地与已收集的数据相关联。
- 没有栈跟踪信息的挂起(之后可能会有超时问题)
由于这些问题缺乏有帮助的信息,加上很难可靠地复现,因此这类错误的调试工作着实让人沮丧。
其中最令人难忘的错误类型伴随着这样的报错信息:
Watchdog caught collective operation timeout:WorkNCCL (SeqNum=408951, OpType=_ALLGATHER_BASE, … , Timeout (ms)=600000) ran for 600351 milliseconds before timing out并且训练运行中的所有 GPU 工作器都发出了这样的报错信息。
这意味着一台或多台主机未能完成 NCCL 操作或者 NCCL 和 InfiniBand 连接崩溃,导致其他所有主机同时卡在了某个张量运算上,直到达到 NCCL_TIMEOUT 超时时间。不幸的是,受 NCCL 软件库本质所限,我们很难找到究竟是哪台主机出了问题。
我们对 NCCL 软件库的日志记录做了一些修改,参见我们的分叉版:https://github.com/boweiliu/nccl 。从而在崩溃发生时可能更好地揭示正在执行的消息或操作,从而确定阻止运行的可能是哪台主机或 GPU。
请注意,为了识别行为不当的主机,我们通常需要搞清楚哪些主机没有生成某些日志消息。缺少此类消息表明该主机上的工作器已落后或已崩溃。
其他没有可用错误消息的无响应情况通常与硬件相关问题有关,比如之前提到的 Xid/SXid/ECC 错误会导致英伟达驱动或英伟达 Docker 通信驱动锁定。为了区分 NCCL 挂起与驱动挂起以及 Python 代码中的竞争条件或死锁,我们使用 Py-Spy 和 GNU Project Debugger(GDB)等工具来实时调试遇到的停滞进程。使用此方法可发现一个特定问题:由于 Python 线程设置中的配置错误,我们无法在某些主机上正确启动八个多线程 NCCL GPU 进程,这些进程在 PyTorch 之前的初始化代码阶段遇到了竞争条件。
- 训练减速(由 MFU 测量)
缺乏工具让这类问题比前一类更让人沮丧。除了使用 Py-Spy、栈跟踪检查和 GDB 之外,我们还采用了 NVIDIA Nsight 和 profiling 工具,其中一些工具在高度分布式的设置中很难使用。
遗憾的是,导致一般减速或让速度低于之前演示的模型浮点数利用率(MFU)的原因有很多。
首先,事实证明多次检查配置、代码和环境变量是有用的。我们经历过的错误包括:运行了错误的模型、批量大小错误、UFM 或 NCCL 设置出错、CUDA_DEVICE_MAX_CONNECTIONS 出错。这都会导致性能无法达到最优。
我们还发现测量瞬时(即每批次)MFU(而不是平滑或窗口平均值)很有用,因为未平滑处理的 MFU 曲线通常有助于诊断问题类别。导致训练速度下降的问题包括:
- 从非常低的 MFU(低于预期的十分之一)立即开始训练并保持稳定
这多半是 InfiniBand 网络连接的硬件问题,例如 T2 或 T3 层的交换机死机。GPU 和 NIC 之间的硬件问题也可能导致该情况,对此 dmesg 会这样报错:PCIe x16 lanes limited by …
- 从预期 MFU 的 30% 立即开始训练并保持稳定
其原因可能是一台主机的 GDR 设置不正确(NVIDIA 对等内存)或 GDR 环境变量不正确。
- 从预期 MFU 的约 60-80% 立即开始训练并保持稳定
最常见的原因是 InfiniBand 链路质量不行或故障,尤其是单台 GPU 出现了与 InfiniBand NIC 相关的故障,导致 NCCL 尝试经由本地 NVLink 路由流量并在同一主机上的另一台 GPU 上使用 NIC。CPU 节流也可能导致该问题,这需要调整某些主机的 BIOS 设置。
- 在处理某些数据批次时突然大幅减速(下降 10 倍),并且经常发生这种情况
这基本上都与检查点或评估有关 —— 可通过检查 epoch 数或步数来验证。恼火的是,如果设置了在 MFU 异常时自动告警,就会出现许多误报。
- 在处理某些数据批次时突然大幅减速(下降 10 倍)
这种情况是随机发生的并且相当罕见(大概每 15 分钟一次),并且之后马上就会完全恢复到良好的 MFU。
最常见的原因似乎是其他需要大量 CPU 计算的工作负载被调度到了一台运行中的主机上。我们发现,与其构建分析工具来识别特定的主机,通过 PID 来粗略地监控 CPU 会更容易。其原因可能是偶尔出现的网络连接问题,比如数据加载器遭遇瓶颈。我们监控了数据加载、检查点和任何非 NCCL 代码的指标数据并添加了 Python 代码计时日志,事实证明这非常可靠。
- MFU 在运行过程中逐渐减慢,但每次重启后又会回到 100%
理论上讲,其原因可能是交换机上的热量积累,但我们从未见过这种情况。不过,我们使用 Python 和 NVIDIA 分析器确定:性能下降的原因似乎是自动垃圾收集。

在调试解决这些减速问题时,我们发现吞吐量几乎必然会周期性地下降。随着训练地推进,这种下降会对分布式运算带来越来越多的影响。这让我们猜想下降的原因可能与自动垃圾收集有关 —— 我们通过分析和测试验证了这个猜想。当我们禁用了自动垃圾收集,并在所有主机上设定只在特定的间隔内收集垃圾,这种吞吐量「下降」就消失了。
我们使用了一种基于 ZeRO-3 的同步分布式训练算法 FSDP。在阻塞操作期间,运行垃圾收集的单个工作器进程可能会减慢其他所有工作器的速度。如果有数百个工作器进程,就可能导致速度大幅下降。
一开始性能良好,然后突然下降(达到预期的 70%),并且以高频持续(每 15 秒)
我们观察到这与英伟达 GPU 的「时钟节流原因」相关,这可通过对英伟达 DCGM 进行适当的设置来解决。发热问题(GPU 高温或主机冷却风扇故障 / 效果下降)或电源故障会导致该问题。另外,当我们同时最大化所有 8 台 GPU 利用率和 8x NIC InfiniBand 利用率以及 CPU/RAM/ 磁盘时,我们的一些具有特定电源硬件的主机会出现电压问题,但只有全部使用它们(通常只在实际训练运行期间)时才会出现这种情况。
- 性能优良但噪声比平常情况多(高频白噪声方差在预期 MFU 的 90% 和 100% 之间)
这也与 InfiniBand 硬件有关,但通常是由于网络中较高层的链路出现一定程度的性能下降或抖动,而不是冗余度较低的主机到 T2 层。
不幸的是,很多这类问题都难以定位到某台具体主机,而与 InfiniBand 相关的问题尤其难以定位,这是由于 InfiniBand 交换机技术的拓扑感知特性。InfiniBand 似乎更偏好 InfiniBand fat-tree 设计中的相邻主机,而 UFM 能以不对称的链路速度路由数据包。
以下是用于调试吞吐量问题的简单摘要 / 流程图 / 完备性检查表:
- 这套系统之前能正常工作吗?
- 你最近做了什么修改(比如合并代码、更新驱动)?
- 你运行的主机是否健康?你的所有依赖服务是否都运行正常,包括第三方的 SaaS,比如 Docker Hub、GitHub 等等?
- 你能确定现在运行的代码、环境、配置、版本、主机列表、排名顺序、随机种子与上次完全相同吗?(如果能实现这样的检查的话。)
- 问题可复现吗?
- 与其他事物有何关联?其他进程?每日 crontab 定时任务?主机或 DCGM 或 UFM 指标?
- 你的工具是否能正确度量这些指标?
- 在运行约简版的代码(使用更小的模型、假数据、不保存或加载检查点)时,问题是否依然存在?
改进基础设施工具
完成了以上步骤之后,就能在训练模型时实现优良性能了…… 至少在某个地方出故障之前是这样。
本节将介绍一些用于确保训练持续稳定的工具和系统,同时最好尽可能地少地需要人类干预。由于我们这个团队很小,因此我们没有足够的人手来进行人工维修,所以我们也希望能尽可能地自动化这个过程。
我们在训练过程中遇到的所有问题几乎都可归因于机器或网络组件故障。这类故障在大型集群中很常见,因此我们的做法是自动禁用出故障的机器和网络组件并发送维修请求。
- 机器故障
我们开发了一个系统,可在运行崩溃时自动从最近的检查点重启。在这个重启过程中,首先是对每台可用机器进行健康检查,然后基于其传递的健康检查结果对每台机器进行分类;然后尝试在最健康的机器上重启训练。
- 网络组件故障
我们观察到的所有网络故障都可通过 UFM 检测到,并会被记录到 UFM 事件日志中,因此响应方式也很简单:解析 UFM 日志并采取相应措施。
UFM 事件系统非常复杂,包含数十种事件类型。但在实践中,我们发现只有少数事件有问题,主要与链路故障或符号错误技术较高有关。在识别出这些事件后,我们可以编写脚本来解析 UFM 事件日志、禁用与最近事件相关的链路和端口、为这些网络组件申请维护工单、维护完成后重新启用这些组件。
- 本地镜像文件系统
对于这些大型分布式训练,人们很早就发现集群与以太网的数据交换速度是一大瓶颈。一条共享以太网连接的带宽大约为 10Gbit/s;如果有数百个工作器同时下载数据集和模型检查点,那么这点带宽会很快饱和。
为此,我们决定在我们集群内部构建一个本地文件系统,以作为云存储的镜像,其本质上就是一个缓存空间,可以减少从 S3 读取的文件量。为了解决集群流失问题(即因为维修原因而禁用或更换机器的情况),我们为每份文件都准备了三个副本,并使用了一致性哈希以均匀分配负载,从而在集群流失期间最大限度地减少文件移动。由于集群的磁盘空间有限,所以我们必须开发多种工具来跟踪文件的生命周期和清除不再有用的文件。
- 本地分布式 Docker 注册表
我们使用了 Kraken,这是一个可点对点传输 Docker 镜像的出色开源软件。这个软件几乎没出现过任何问题,我们还是挺惊讶的,毕竟我们的任务和实现都很复杂。工具地址:https://github.com/uber/kraken
- 各种性能监控工具
我们设置了默认的 Torch 分析器以及英伟达的 Nsight Systems。后者可帮助我们了解前向 / 反向通过以及 NCCL 通信所需的确切时间,并进一步帮助我们确定给定的模型大小和工作器数量是否会成为瓶颈。然而,Nsight Systems 有点难用,因为其需要在特权模式下运行 Docker,这需要禁用与性能监控事件相关的安全检查,并且保存其配置时往往需要停止整个训练进程。
此外,我们也编写了工具来检测训练速度慢的数据批次并理解其可能原因。我们发现这很有用。其中最有用的工具的作用是监控每一批次所需的时间并在某批次过于慢时丢弃该工作器的栈跟踪 —— 这让我们可以更轻松地找到硬件或软件有些小问题的主机。
- 将机器分成不同的组别以定位故障主机
在使用该集群的前几个月(那时候健康检查还不如现在这般透彻),我们经常遇到这种情况:在一组机器上训练时出现故障,但并不清楚究竟是哪台机器有问题。为了找到故障主机,我们开发了一些工具,可轻松地把一组机器分成不同的小组,然后在每个机器小组上运行更小的训练。
举个例子,如果一个在 48 台机器上运行的训练失败了,那么就在 6 组各 8 台机器上进行更小规模的训练,然后在 8 组各 6 台机器上运行更小规模的训练。通常情况下,这两个阶段中只有一次运行会失败,这让我们有信心得出结论:在两个阶段中都出问题的机器是有问题的。
反思和学习到的经验教训
在设置和维护基础设施的过程中,我们获得了一些有用的经验教训:
- 一种有用的做法是交换机器的位置。在运行时,使用多于所需机器数量 10-20% 的机器会很有帮助,这样就能在机器故障时轻松重启训练了。设置集群网络连接时让每台机器都与其他每台机器紧密相连,这样一来我们就能使用这些机器中任意可工作的子集。
- 对遇到的每一个硬件或软件故障,编写测试和自动化解决方案是值得的,因为训练中遇到的每一个问题都会再次出现。类似地,对于每一个含混不清的报错消息,都值得编写更能解释该错误的工具。
- 可重复性是优秀科研的关键。我们立马就采用的一大原则是:「一次只修改一个地方」,即便最简单的地方也是如此。
- 信任,但也要验证。每当我们引入外部工具或加入新人员(无论是来自公司内还是公司外)时,我们都会仔细检查他们声称的东西,尤其是当后续步骤依赖于这些声称的东西时。
总结
训练大型语言模型一开始就需要复杂的基础设施。我们之所以选择深入参与基础设施的设置细节,是因为我们相信完全理解我们操作的系统是非常重要的,也因为我们认为这样做的效率更高。
现在,经历过整个流程之后,我们很高兴我们采用了这样的方法 —— 事实证明,能完全控制我们的基础设施以及有能力轻松地在每个抽象层级上进行调试具有至关重要的价值。虽然这个过程需要大量的监督和迭代,但它让我们可以深入地理解其底层工作流程、构建一系列用于确保主机健康的工具、学习如何让系统自动运行以确保训练持续平滑,最终构建起一套让我们可以快速迭代训练前沿语言模型的基础设施。
这个基础设施构建流程体现了我们研究和构建 AI 智能体的基础方法论:探究细枝末节,不断改进现有流程,并构建有用的工具和系统使我们这个积极奋进的团队能够应对更大的挑战。
#大模型的能力边界
假如我们有无限的资源,比如有无穷多的数据,无穷大的算力,无穷大的模型,完美的优化算法与泛化表现,那么由此得到的预训练模型是否可以用来解决一切问题?本文从范畴论的角度给出一个答案。
假如我们有无限的资源,比如有无穷多的数据,无穷大的算力,无穷大的模型,完美的优化算法与泛化表现,请问由此得到的预训练模型是否可以用来解决一切问题?
这是一个大家都非常关心的问题,但已有的机器学习理论却无法回答。它与表达能力理论无关,因为模型无穷大,表达能力自然也无穷大。它与优化、泛化理论也无关,因为我们假设算法的优化、泛化表现完美。换句话说,之前理论研究的问题在这里不存在了!
今天,我给大家介绍一下我在ICML'2023发表的论文 On the Power of Foundation Models ,从范畴论的角度给出一个答案。
范畴论是什么?
倘若不是数学专业的同学,对范畴论可能比较陌生。范畴论被称为是数学的数学,为现代数学提供了一套基础语言。现代几乎所有的数学领域都是用范畴论的语言描述的,例如代数拓扑、代数几何、代数图论等等。范畴论是一门研究结构与关系的学问,它可以看作是集合论的一种自然延伸:在集合论中,一个集合包含了若干个不同的元素;在范畴论中,我们不仅记录了元素,还记录了元素与元素之间的关系。
Martin Kuppe曾经画了一幅数学地图,把范畴论放到了地图的顶端,照耀着数学各个领域:
关于范畴论的介绍网上有很多,我们这里简单讲几个基本概念:
- 范畴: 一个范畴 包含很多对象, 以及对象与对象之间的关系, 例如 表示两个 对象 之间的关系。
- 函子: 两个范畴 与 之间的函数被称为函子 . 它不仅把 中的对象映射到 , 同时还保持关系结构不变。
- 自然映射:函子之间也可以有关系,被称为自然映射。
监督学习的范畴论视角
我给本科生教了4年机器学习, 深刻感受到监督学习框架是其根本。这个框架极为优美: 我们假设存在一个真实分布 , 表示输入 和标签 的分布。训练数据集 和测试数据集 都是从 中均匀采样得到的。我们希望能够学习一个函数 , 使得 能够准确地计算出 的标签。为了达到这个目标, 我们需要定义一个损失函数 , 用来度量 和正确标签 的距离, 这个距离自然是越接近于0越好。
过去十多年,人们围绕着监督学习框架进行了大量的研究,得到了很多优美的结论。但是,这一框架也限制了人们对AI算法的认识,让理解预训练大模型变得极为困难。例如,已有的泛化理论很难用来解释模型的跨模态学习能力。
用范畤论来理解监督学习, 则会得到不一样的结果。我们可以把输入空间 与输出空间 当做两个不同的范畴, 把具体的数据点 和 当做范畴中的对象。在范畴论中我们经常用大写字母表示对象, 用花体字符表示范畴, 所以下面我们切换符号, 使用 和 表示数据点。同时, 我们也不再关心概率分布, 而使用从 到 的一个函子表示输入与输出的正确关系。
在新的视角下, 测试数据、训练数据就变成了从函子 中采样得到的输入输出数据。所以说, 监督学习在讨论如下问题:
我们能不能通过采样函子的输入输出数据,学到这个函子?
注意到, 在这个过程中我们没有考虑两个范畴 内部的结构。实际上, 监督学习没有对范畴内部的结构有任何假设, 所以可以认为在两个范畴内部, 任何两个对象之间都没有关系。因此, 我们完全可以把 和 看作是两个集合。这个时候, 泛化理论著名的no free lunch定理告诉我们, 假如没有额外假设, 那么学好从 到 的函子这件事情是不可能的(除非有海量样本)。
为了处理这个问题, 之前的泛化理论假设函子满足某些性质, 相当于加了一个比较强的约束, 就可以绕开no free lunch定理。但是, 从范畴论的角度看, 给函子加约束是一件很奇怪的事情: 函子并不是一个实体, 它只是描述了两个范畴之间的一些映射关系, 是伴随着带有内部结构的范畴的出现 而存在的一我们怎么可以说有些映射关系不能出现, 有些可以出现呢? 所以, 正确的做法应该是对范畴结构加约束。举个例子, 如果我们知道 有线性结构, 并且函子 保持了这个结构, 那么我们一样可以绕开no free lunch定理, 通过很少的样本学习 。
乍看之下,这个新视角毫无用处。给范畴加约束也好,给函子加约束也好,似乎没什么本质区别。实际上,新视角更像是传统框架的阉割版本:它甚至没有提及监督学习中极为重要的损失函数的概念,也就无法用于分析训练算法的收敛或泛化性质。那么我们应该如何理解这个新视角呢?
我想,范畴论提供了一种鸟瞰视角。它本身不会也不应该替代原有的更具体的监督学习框架,或者用来产生更好的监督学习算法。相反,监督学习框架是它的“子模块”,是解决具体问题时可以采用的工具。因此,范畴论不会在乎损失函数或者优化过程——这些更像是算法的实现细节。它更关注范畴与函子的结构,并且尝试理解某个函子是否可学习。这些问题在传统监督学习框架中极为困难,但是在范畴视角下变得简单。
自监督学习的范畴论视角
预训练任务与范畴
在自监督学习框架中, 数据集不再有标签。不过, 我们还是可以对数据集设置预训练任务, 学习数据集本身的信息。已有的预训练任务多种多样, 比如对比学习, 遮挡学习, 语言模型等等。我们在预训练模型中学习的目标是 , 即把每个数据点 映射到它的特征表示 , 使得这些特征表示可以用于解决预训练任务。
下面我们先明确在预训练任务下范畴的定义。实际上,倘若我们没有设计任何预训练任务,那么范畴中的对象之间就没有关系;但是设计了预训练任务之后,我们就将人类的先验知识以任务的方式,给范畴注入了结构。而这些结构就成为了大模型拥有的知识。
具体来说:
- 对比学习。 正如我在对比学习在学啥? 文章里介绍的, 对比学习构建了一个相似图, 使得任何两个对象之间的关系可以用一个相似度来表示, 而这个相似度恰好对应于正样本的采样概率, 即 被采样为一对正样本 。
- 遮挡学习。 遮挡学习的意思是把一个对象的一部分内容遮挡起来, 然后让模型预测遮挡的部分是什么。对于这个任务, 我们可以把遮挡之后的对象当做 , 把遮挡位置当做 , 然后将 定义为完整的对象本身。这样, 每一组关系都对应一个遮挡学习问题的解决方案。
- 语言模型。 对象 是一个句子, 对象 则是它的续写, 只有最后一个词不同。例如, “我今天很开”, “我今天很开心”。语言模型关心的是 , 我们把它定义为 。
换句话说,当我们在一个数据集上定义了预训练任务之后,我们就定义了一个包含对应关系结构的范畴。预训练任务的学习目标,就是让模型把这个范畴学好。具体来说,我们看一下理想模型的概念。
理想模型
给定一个预训练模型 ,它什么时候是比较理想的呢? 很简单, 当它计算出的特征可以用来很方便地刻画范畴 内部关系的时候。对于这个概念不太明白的朋友, 可以参见上一篇对比学习在学啥?, 里面有一些直观的例子。
严格来说, 给定由预训练任务定义的范畴 , 如果存在一个预定义的函数 Set, 使得对任意的 , 那么模型 就是理想的。
在这里, “数据无关"意味着 是在看到数据之前就预先定义的; 但下标 则表示 可以通过黑盒调用的方式使用 和 这两个函数。换句话说, 是一个“简单"的函数, 但可以借助模型 的能力来表示更复杂的关系。这一点可能不太好理解, 我们用压缩算法来打个比方。压缩算法本身可能是数据相关的, 比如它可能是针对数据分布进行了特殊优化。然而, 作为一个数据无关的函数 , 它无法访问数据分布, 但可以调用压缩算法来解压数据, 因为“调用压缩算法”这一操作是数据无关的。
针对不同的预训练任务, 我们可以定义不同的 :
- 对比学习。 在对比学习中, 任何两个对象之间的关系可以使用一个实数表示, 因此 可以被看作以 为核函数的空间。例如, 在SimCLR 和MoCo 中, 是一个简单的高斯核函数。
- 遮挡学习。就像之前说的, 我们用 表示可见部分, 表示遮蔽部分。在MAE 中, 我们用 和 计算这两个部分的表征。然后, 将 和 进行拼接, 并使用 恢复完整的对象。
- 语言模型。我们想要计算 , 其中 是 的续写, 只有最后一个词不同。 运行一个线性函数 (可以预先定义好, 不参与优化) 和一个Softmax函数来计算下一个词的概率分布。基于这个分布, 运行 来提取 , 并计算 。
因此,我们可以这么说:预训练学习的过程,就是在寻找理想模型 fff 的过程。
可是, 即使 是确定的, 根据定义, 理想模型也并不唯一。理论上说, 模型 可能具有超级智能, 即使在不学习 中数据的前提下也能做任何事情。在这种情况下, 我们无法对 的能力给出有意义的论断。因此, 我们应该看看问题的另一面:
给定由预训练任务定义的范畴 , 对于任何一个理想的 , 它能解决哪些任务?
这是我们在本文一开始就想回答的核心问题。我们先介绍一个重要概念。
米田嵌入
我们定义米田嵌入函子为 。针对任何 , 即可以接受输入 并输出 。
简单来说, 是一个专门存放各种函子的范畴(被称为预层范畴), 输入一个对象 , 输出一个集合。而 接受 并输出关于 的所有关系。如果 , 我们可以把 定义成先使用 计算出 , 再将 传给 , 得到 。所以我们知道 是理想的。
很容易证明, 是能力最弱的理想模型, 因为给定其他理想模型 中的所有关系也包含在 中。同时, 它也是没有其他额外假设前提之下, 预训练模型学习的最终目标。因此, 为了回答我们的核心问题, 我们下面专门考虑 。
提示调优(Prompt tuning): 见多才能识广
为了理解模型能够解决哪些任务, 我们需要先明确什么是任务。一个任务 可以看作是 中的函子。我们说模型解决了一个任务 , 如果对于任何输入 , 模型输出的答案与 是同构的。在范畴论中, 当两个对象 (或函子) 是同构的, 我们就将它们视为相等的。我们不去考虑如何让两个同构的对象变得完全一致, 因为这在现代神经网络中并不是问题。例如, 如果两个对象 和 之间存在一个同构映射, 使得 , 那么神经网络可以轻松地找到这个 。
能否解决某个任务 ? 要回答这个问题, 我们先介绍范畴论中最重要的一个定理。
米田引理
米田引理: 对于 和 , 有 。
给定任务 , 提示调优意味着我们需要冻结模型的参数, 并仅使用任务特定提示 (通常 为文本或图像) , 加上输入 , 得到输出 。因此, 提示 和输入 是模型的输入。由米田引理,如果我们直接将 和 作为 中的函子发送到 , 由于 是 函数的实现,我们有
即, 可以用这两种表征计算出 。然而, 注意到任务提示 必须通过 而非 发送, 这意味着我们会得到 而非 作为 的输入。这引出了范畴论中另一个重要的定义。
可表函子: 对于 ,如果存在某个 使得 , 则称 是可表的。 被称 为 的代表。
基于这个定义,我们可以得到如下定理(证明略去)。
定理1与推论
定理1. 可以通过提示调优解决任务 , 当且仅当任务 是可表的。当 可表时, 最优的提示是 的代表。
换句话说, 当我们设计一个提示词 , 发现它有比较好的效果的时候, 其实是因为它是(或者很接近)要解决的任务的一个代表。具体来说, 。
值得一提的是,有些提示调优算法的提示不一定是范畴 中的对象,可能是特征空间中的表征。这种方法有可能支持比可表任务更复杂的任务, 但增强效果取决于特征空间的表达能力。下面我们提供定理1的一个简单推论。
推论1. 对于预测图像旋转角度的预训练任务[4],提示调优不能解决分割或分类等复杂的下游任务。
证明:预测图像旋转角度的预训练任务会将给定图像旋转四个不同的角度:0°, 90°, 180°, 和 270°,并让模型进行预测。因此,这个预训练任务定义的范畴将每个对象都放入一个包含4个元素的群中。显然,像分割或分类这样的任务不能由这样简单的对象表出。
推论1有点反直觉,因为原论文提到[4],使用该方法得到的模型可以部分解决分类或分割等下游任务。然而,在我们的定义中,解决任务意味着模型应该为每个输入生成正确的输出,因此部分正确并不被视为成功。这也与我们文章开头提到的问题相符:在无限资源的支持下,预测图像旋转角度的预训练任务能否用于解决复杂的下游任务?推论1给出了否定的答案。
微调(Fine tuning): 表征不丢信息
提示调优的能力有限,那么微调算法呢?基于米田函子扩展定理(参见 [5]中的命题2.7.1),我们可以得到如下定理。
定理2. 给定足够的资源, 针对任何任务 Set, 的表征可以用于学习 Set, 使得 。
定理2考虑的下游任务是基于 的结构, 而不是数据集中的数据内容。因此, 之前提到的预测旋转图片角度的预训练任务定义的范畴仍然具有非常简单的群结构。但是根据定理 2 , 我们可以用它解决更多样化的任务。例如, 我们可以将所有对象映射到同一个输出, 这是无法通过提示调优来实现的。定理2明确了预训练任务的重要性, 因为更好的预训练任务将创建更强大的范畴 , 从而进一 步提高了模型的微调潜力。
对于定理2有两个常见的误解。首先, 即使范畴 包含了大量信息, 定理2只提供了一个粗糙的上界, 说 记录了 中所有的信息, 有潜力解决任何任务, 而并没有说任何微调算法都可以达到这 个目的。其次, 定理 2 乍看像是过参数化理论。然而, 它们分析的是自监督学习的不同步骤。过参数化分析的是预训练步骤, 说的是在某些假设下, 只要模型足够大且学习率足够小, 对于预训练任务, 优化和泛化误差将非常小。而定理2分析的则是预训练后的微调步骤, 说该步骤有很大潜力。
讨论与总结
监督学习与自监督学习。从机器学习的角度来看,自监督学习仍然是一种监督学习,只是获取标签的方式更巧妙一些而已。但是从范畴论的角度来看,自监督学习定义了范畴内部的结构,而监督学习定义了范畴之间的关系。因此,它们处于人工智能地图的不同板块,在做完全不一样的事情。
与ChatGPT的关系。 很多朋友可能会关心本文的结论应该如何应用到ChatGPT等聊天模型上去? 简单来说, ChatGPT等模型不光有预训练的过程, 还有RLHF等进一步微调部分, 所以定理1的结论没法直接应用。不过, 它也可以看作是对 进行微调的一种变体, 获得了强大的能力。这也符合数学家们使用 的感受:很多问题在原来的范畴 中很困难, 但是往往在 中就迎刃而解。
适用场景。 由于本文开头考虑了无限资源的假设, 导致很多朋友可能会认为, 这些理论只有在虚空之中才会真正成立。其实并非如此。在我们真正的推导过程中, 我们只是考虑了理想模型与 这 一预定义的函数。实际上, 只要 确定了之后, 任何一个预训练模型 (哪怕是在随机初始化阶 段)都可以针对输入 计算出 , 从而使用 计算出两个对象的关系。换句话说, 只要当 确定之后, 每个预训练模型都对应于一个范畴, 而预训练的目标不过是将这个范畴不断与由预训练任务定义的范畴对齐而已。因此, 我们的理论针对每一个预训练模型都成立。
核心公式。很多人说,如果AI真有一套理论支撑,那么它背后应该有一个或者几个简洁优美的公式。我想,如果需要用一个范畴论的公式来描绘大模型能力的话,它应该就是我们之前提到的:
对于大模型比较熟悉的朋友,在深入理解这个公式的含义之后,可能会觉得这个式子在说废话,不过是把现在大模型的工作模式用比较复杂的数学式子写出来了而已。
但事实并非如此。现代科学基于数学,现代数学基于范畴论,而范畴论中最重要的定理就是米田引理。我写的这个式子将米田引理的同构式拆开变成了不对称的版本,却正好和大模型的打开方式完全一致。
我认为这一定不是巧合。如果范畴论可以照耀现代数学的各个分支,它也一定可以照亮通用人工智能的前进之路。
#大模型训练的GPU联手CPU显存优化分析方法
只需要一行命令,即可实现GPU和CPU的混合训练。
随着深度学习模型复杂度和数据集规模的增大,计算效率成为了不可忽视的问题。GPU凭借强大的并行计算能力,成为深度学习加速的标配。然而,由于服务器的显存非常有限,随着训练样本越来越大,显存连一个样本都容不下的现象频频发生。除了升级硬件(烧钱)、使用分布式训练(费力),你知道还有哪些方法吗?即使显存充足,所有运算都在GPU上执行就是最高效吗?只要掌握以下小知识,模型训练的种种问题统统搞定,省时省力省钱,重点是高效!
其实CPU和GPU是协同工作的,如果能合理地利用它们各自的优势,就能够节省显存资源(显存不够内存来凑),甚至获得更好的训练性能。本文为您提供了device_guard接口,只需要一行命令,即可实现GPU和CPU的混合训练,不仅可以解决训练模型时通过调整批尺寸(batch size)显存依然超出的问题,让原本无法在单台服务器执行的模型可以训练,同时本文还给出了提高GPU和CPU混合训练效率的方法,将服务器资源利用到极致,帮助您提升模型的性能!
一、模型训练的特点
深度学习任务通常使用GPU进行模型训练。这是因为GPU相对于CPU具有更多的算术逻辑单元(ALU),可以发挥并行计算的优势,特别适合计算密集型任务,可以更高效地完成深度学习模型的训练。GPU模式下的模型训练如图1所示,总体可以分为4步:
第1步,将输入数据从系统内存拷贝到显存。
第2步,CPU指示GPU处理数据。
第3步,GPU并行地完成一系列的计算。
第4步,将计算结果从显存拷贝到内存。
从图中可以了解到,虽然GPU并行计算能力优异,但无法单独工作,必须由CPU进行控制调用;而且显存和内存之间的频繁数据拷贝也可能会带来较大的性能开销。CPU虽然计算能力不如GPU,但可以独立工作,可以直接访问内存数据完成计算。因此,想获得更好的训练性能,需要合理利用GPU和CPU的优势。
二、模型训练的常见问题
问题一:GPU显存爆满,资源不足
你建的模型不错,在这个简洁的任务中可能成为新的SOTA,但每次尝试批量处理更多样本时,你都会得到一个CUDA RuntimeError:out of memory。
这是因为GPU卡的显存是非常有限的,一般远低于系统内存。以V100为例,其显存最高也仅有32G,甚至有些显存仅12G左右。因此当模型的参数量较大时,在GPU模式下模型可能无法训练起来。
设置CPU模式进行模型训练,可以避免显存不足的问题,但是训练速度往往太慢。
那么有没有一种方法,可以在单机训练中充分地利用GPU和CPU资源,让部分层在CPU执行,部分层在GPU执行呢?
问题二:频繁数据拷贝,训练效率低
在显存足够的情况下,我们可以直接采用GPU模式去训练模型,但是让所有的网络层都运行在GPU上就一定最高效吗?其实GPU只对特定任务更快,而CPU擅长各种复杂的逻辑运算。框架中有一些OP会默认在CPU上执行,或者有一些OP的输出会被存储在CPU上,因为这些输出往往需要在CPU上访问。这就会导致训练过程中,CPU和GPU之间存在数据拷贝。
图2是CPU和GPU数据传输示意图。假设模型的中间层存在下图中的4个算子。其中算子A和算子B都在CPU执行,因此B可以直接使用A的输出。算子C和算子D都在GPU上执行,那么算子D也可以直接使用C的输出。但是算子B执行完,其输出在CPU上,在算子C执行时,就会将B的输出从CPU拷贝到GPU。
频繁的数据拷贝,也会影响模型的整体性能。如果能把算子A和B设置在GPU上执行,或者算子C和D设置在CPU上执行,避免数据传输,或许会提升模型性能。那么应该如何更加合理地为算子分配设备,使得训练过程更加高效呢?我们需要更综合地考虑,在发挥GPU和CPU各自计算优势的前提下,降低数据拷贝带来的时间消耗。
三、定义化GPU和CPU混合训练
上面两个场景都是希望为模型中的部分层指定运行设备。飞桨提供了fluid.CUDAPlace和fluid.CPUPlace用于指定运行设备,但这两个接口在指定设备时是二选一的,也就是说要么在GPU模式下训练,要么在CPU模式下训练。过去我们无法指定某一部分计算在GPU上执行还是在CPU上执行。飞桨开源框架从1.8版本开始提供了device_guard接口,使用该接口可以为网络中的计算层指定设备为CPU或者GPU,实现更灵活的异构计算调度。
如何使用device_guard接口解决上面两个场景中提到的问题呢?接下来,我们看看具体的例子。
好处一:充分利用CPU资源,避免显存超出
如果使用fluid.CUDAPlace指定了全局的运行设备,飞桨将会自动把支持GPU计算的OP分配在GPU上执行,然而当模型参数量过大并且显存有限时,很可能会遇到显存超出的情况。如下面的示例代码,embedding层的参数size包含两个元素,第一个元素为vocab_size(词表大小),第二个为emb_size(embedding层维度)。实际场景中,词表可能会非常大。示例代码中,词表大小被设置为10,000,000,该层创建的权重矩阵的大小为(10000000, 150),仅这一层就需要占用5.59G的显存。如果再加上其他的网络层,在这种大词表场景下,很有可能会显存超出。
import paddle.fluid as fluid
data = fluid.layers.fill_constant(shape=[1], value=128, dtype='int64')
label = fluid.layers.fill_constant(shape=[1, 150], value=0.5, dtype='float32')
emb = fluid.embedding(input=data, size=(10000000, 150), dtype='float32')
out = fluid.layers.l2_normalize(x=emb, axis=-1)
cost = fluid.layers.square_error_cost(input=out, label=label)
avg_cost = fluid.layers.mean(cost)
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_cost)
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
result = exe.run(fluid.default_main_program(), fetch_list=[avg_cost])embedding是根据input中的id信息从embedding矩阵中查询对应embedding信息,它并不是一个计算密度非常高的OP,因此在CPU上进行计算,其速度也是可接受的。如果将embedding层设置在CPU上运行,就能够充分利用CPU大内存的优势,避免显存超出。可以参考如下代码,使用device_guard将embedding层设置在CPU上。那么,除了embedding层,其他各层都会在GPU上运行。
import paddle.fluid as fluid
data = fluid.layers.fill_constant(shape=[1], value=128, dtype='int64')
label = fluid.layers.fill_constant(shape=[1, 150], value=0.5, dtype='float32')
with fluid.device_guard("cpu"): #一行命令,指定该网络层运行设备为CPU
emb = fluid.embedding(input=data, size=(10000000, 150), dtype='float32')
out = fluid.layers.l2_normalize(x=emb, axis=-1)
cost = fluid.layers.square_error_cost(input=out, label=label)
avg_cost = fluid.layers.mean(cost)
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_cost)
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
result = exe.run(fluid.default_main_program(), fetch_list=[avg_cost])因此,在显存有限时你可以参考上面的示例将一些计算密度不高的网络层设置在CPU上避免显存超出。
好处二:合理设置运行设备,减少数据传输
如果你在GPU模式下训练模型,希望提升训练速度,那么可以看看模型中是否存在一些不必要的数据传输。在文章开头我们提到CPU和GPU之间的数据拷贝是耗时的,因此如果能够避免这样的情况,就有可能提升模型的性能。
在下面的内容中,我们将教你如何通过profile工具分析数据传输开销,以及如何使用device_guard避免不必要的数据传输,从而提升模型性能。大致流程如下:
- 首先使用profile工具对模型进行分析,查看是否存在GpuMemcpySync的调用耗时。若存在,则进一步分析发生数据传输的原因。
- 通过Profiling Report找到发生GpuMemcpySync的OP。如果需要,可以通过打印log,找到GpuMemcpySync发生的具体位置。
- 尝试使用device_guard设置部分OP的运行设备,来减少GpuMemcpySync的调用。
- 最后比较修改前后模型的Profiling Report,或者其他用来衡量性能的指标,确认修改后是否带来了性能提升。
步骤1、使用profile工具确认是否发生了数据传输
首先我们需要分析模型中是否存在CPU和GPU之间的数据传输。在OP执行过程中,如果输入Tensor所在的设备与OP执行的设备不同,就会自动将输入Tensor从CPU拷贝到GPU,或者从GPU拷贝到CPU,这个过程是同步的数据拷贝,通常比较耗时。下列示例代码的14行设置了profile,利用profile工具我们可以看到模型的性能数据。
import paddle.fluid as fluid
import paddle.fluid.compiler as compiler
import paddle.fluid.profiler as profiler
data1 = fluid.layers.fill_constant(shape=[1, 3, 8, 8], value=0.5, dtype='float32')
data2 = fluid.layers.fill_constant(shape=[1, 3, 5, 5], value=0.5, dtype='float32')
shape = fluid.layers.shape(data2)
shape = fluid.layers.slice(shape, axes=[0], starts=[0], ends=[4])
out = fluid.layers.crop_tensor(data1, shape=shape)
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
compiled_prog = compiler.CompiledProgram(fluid.default_main_program())
with profiler.profiler('All', 'total') as prof:
for i in range(10):
result = exe.run(program=compiled_prog, fetch_list=[out])在上述程序运行结束后,将会自动地打印出下面的Profiling Report,可以看到GpuMemCpy Summary中给出了2项数据传输的调用耗时。如果GpuMemCpy Summary中存在GpuMemcpySync,那么就说明你的模型中存在同步的数据拷贝。
进一步分析,可以看到slice和crop_tensor执行中都发生了GpuMemcpySync。我们通过查看网络的定义,就会发现尽管我们在程序中设置了GPU模式运行,但是shape这个OP将输出结果存放在CPU上,导致后面在GPU上执行的slice使用这个结果时发生了从CPU到GPU的数据拷贝。slice的输出结果存放在GPU上,而crop_tensor用到这个结果的参数默认是从CPU上取数据,因此又发生了一次数据拷贝。
-------------------------> Profiling Report <-------------------------
Note! This Report merge all thread info into one.
Place: All
Time unit: ms
Sorted by total time in descending order in the same thread
Total time: 26.6328
Computation time Total: 13.3133 Ratio: 49.9884%
Framework overhead Total: 13.3195 Ratio: 50.0116%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 30 Total: 1.47508 Ratio: 5.5386%
GpuMemcpyAsync Calls: 10 Total: 0.443514 Ratio: 1.66529%
GpuMemcpySync Calls: 20 Total: 1.03157 Ratio: 3.87331%
------------------------- Event Summary -------------------------
Event Calls Total CPU Time (Ratio) GPU Time (Ratio) Min. Max. Ave. Ratio.
FastThreadedSSAGraphExecutorPrepare 10 9.16493 9.152509 (0.998645) 0.012417 (0.001355) 0.025192 8.85968 0.916493 0.344122
shape 10 8.33057 8.330568 (1.000000) 0.000000 (0.000000) 0.030711 7.99849 0.833057 0.312793
fill_constant 20 4.06097 4.024522 (0.991025) 0.036449 (0.008975) 0.075087 0.888959 0.203049 0.15248
slice 10 1.78033 1.750439 (0.983212) 0.029888 (0.016788) 0.148503 0.290851 0.178033 0.0668471
GpuMemcpySync:CPU->GPU 10 0.45524 0.446312 (0.980388) 0.008928 (0.019612) 0.039089 0.060694 0.045524 0.0170932
crop_tensor 10 1.67658 1.620542 (0.966578) 0.056034 (0.033422) 0.143906 0.258776 0.167658 0.0629515
GpuMemcpySync:GPU->CPU 10 0.57633 0.552906 (0.959357) 0.023424 (0.040643) 0.050657 0.076322 0.057633 0.0216398
Fetch 10 0.919361 0.895201 (0.973721) 0.024160 (0.026279) 0.082935 0.138122 0.0919361 0.0345199
GpuMemcpyAsync:GPU->CPU 10 0.443514 0.419354 (0.945526) 0.024160 (0.054474) 0.040639 0.059673 0.0443514 0.0166529
ScopeBufferedMonitor::post_local_exec_scopes_process 10 0.341999 0.341999 (1.000000) 0.000000 (0.000000) 0.028436 0.057134 0.0341999 0.0128413
eager_deletion 30 0.287236 0.287236 (1.000000) 0.000000 (0.000000) 0.005452 0.022696 0.00957453 0.010785
ScopeBufferedMonitor::pre_local_exec_scopes_process 10 0.047864 0.047864 (1.000000) 0.000000 (0.000000) 0.003668 0.011592 0.0047864 0.00179718
InitLocalVars 1 0.022981 0.022981 (1.000000) 0.000000 (0.000000) 0.022981 0.022981 0.022981 0.000862883步骤2、通过log查看发生数据传输的具体位置
有时同一个OP会在模型中被用到很多次,例如可能我们会在网络的几个不同位置,都定义了slice层。这时候想要确认究竟是在哪个位置发生了数据传输,就需要去查看更加详细的调试信息,那么可以打印出运行时的log。依然以上述程序为例,执行GLOG_vmodule=operator=3 python test_case.py,会得到如下log信息,可以看到这两次数据传输:
- 第3~7行log显示:shape输出的结果在CPU上,在slice运行时,shape的输出被拷贝到GPU上
- 第9~10行log显示:slice执行完的结果在GPU上,当crop_tensor执行时,它会被拷贝到CPU上。
I0406 14:56:23.286592 17516 operator.cc:180] CUDAPlace(0) Op(shape), inputs:{Input[fill_constant_1.tmp_0:float[1, 3, 5, 5]({})]}, outputs:{Out[shape_0.tmp_0:int[4]({})]}.
I0406 14:56:23.286628 17516 eager_deletion_op_handle.cc:107] Erase variable fill_constant_1.tmp_0 on CUDAPlace(0)
I0406 14:56:23.286725 17516 operator.cc:1210] Transform Variable shape_0.tmp_0 from data_type[int]:data_layout[NCHW]:place[CPUPlace]:library_type[PLAIN] to data_type[int]:data_layout[ANY_LAYOUT]:place[CUDAPlace(0)]:library_type[PLAIN]
I0406 14:56:23.286763 17516 scope.cc:169] Create variable shape_0.tmp_0
I0406 14:56:23.286784 17516 data_device_transform.cc:21] DeviceTransform in, src_place CPUPlace dst_place: CUDAPlace(0)
I0406 14:56:23.286867 17516 tensor_util.cu:129] TensorCopySync 4 from CPUPlace to CUDAPlace(0)
I0406 14:56:23.287099 17516 operator.cc:180] CUDAPlace(0) Op(slice), inputs:{EndsTensor[], EndsTensorList[], Input[shape_0.tmp_0:int[4]({})], StartsTensor[], StartsTensorList[]}, outputs:{Out[slice_0.tmp_0:int[4]({})]}.
I0406 14:56:23.287140 17516 eager_deletion_op_handle.cc:107] Erase variable shape_0.tmp_0 on CUDAPlace(0)
I0406 14:56:23.287220 17516 tensor_util.cu:129] TensorCopySync 4 from CUDAPlace(0) to CPUPlace
I0406 14:56:23.287473 17516 operator.cc:180] CUDAPlace(0) Op(crop_tensor), inputs:{Offsets[], OffsetsTensor[], Shape[slice_0.tmp_0:int[4]({})], ShapeTensor[], X[fill_constant_0.tmp_0:float[1, 3, 8, 8]({})]}, outputs:{Out[crop_tensor_0.tmp_0:float[1, 3, 5, 5]({})]}.步骤3、使用device_guard避免不必要的数据传输
在上面的例子中,shape输出的是一个1-D的Tensor,因此在slice执行时,计算代价相对于数据传输代价或许是更小的。如果将slice设置在CPU上运行,就可以避免2次数据传输,那么是不是有可能提升模型速度呢?我们尝试修改程序,将slice层设置在CPU上执行:
import paddle.fluid as fluid
import paddle.fluid.compiler as compiler
import paddle.fluid.profiler as profiler
data1 = fluid.layers.fill_constant(shape=[1, 3, 8, 8], value=0.5, dtype='float32')
data2 = fluid.layers.fill_constant(shape=[1, 3, 5, 5], value=0.5, dtype='float32')
shape = fluid.layers.shape(data2)
with fluid.device_guard("cpu"): # 一行命令,指定该网络层运行设备为CPU
shape = fluid.layers.slice(shape, axes=[0], starts=[0], ends=[4])
out = fluid.layers.crop_tensor(data1, shape=shape)
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
compiled_prog = compiler.CompiledProgram(fluid.default_main_program())
with profiler.profiler('All', 'total') as prof:
for i in range(10):
result = exe.run(program=compiled_prog, fetch_list=[out])步骤4、比较修改前后模型,确认是否带来性能提升
再次观察Profiling Report 中GpuMemCpy Summary的内容,可以看到GpuMemCpySync 这一项已经被消除了。同时注意到,下面的Total time为 14.5345 ms,而修改前是26.6328 ms,速度提升一倍! 此实验说明使用device_guard避免数据传输后,示例模型的性能有了明显的提升。
在实际的模型中,若GpuMemCpySync调用耗时占比较大,并且可以通过设置device_guard避免,那么就能够带来一定的性能提升。
-------------------------> Profiling Report <-------------------------
Note! This Report merge all thread info into one.
Place: All
Time unit: ms
Sorted by total time in descending order in the same thread
Total time: 14.5345
Computation time Total: 4.47587 Ratio: 30.7948%
Framework overhead Total: 10.0586 Ratio: 69.2052%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 10 Total: 0.457033 Ratio: 3.14447%
GpuMemcpyAsync Calls: 10 Total: 0.457033 Ratio: 3.14447%
------------------------- Event Summary -------------------------
Event Calls Total CPU Time (Ratio) GPU Time (Ratio) Min. Max. Ave. Ratio.
FastThreadedSSAGraphExecutorPrepare 10 7.70113 7.689066 (0.998433) 0.012064 (0.001567) 0.032657 7.39363 0.770113 0.529852
fill_constant 20 2.62299 2.587022 (0.986287) 0.035968 (0.013713) 0.071097 0.342082 0.13115 0.180466
shape 10 1.93504 1.935040 (1.000000) 0.000000 (0.000000) 0.026774 1.6016 0.193504 0.133134
Fetch 10 0.880496 0.858512 (0.975032) 0.021984 (0.024968) 0.07392 0.140896 0.0880496 0.0605797
GpuMemcpyAsync:GPU->CPU 10 0.457033 0.435049 (0.951898) 0.021984 (0.048102) 0.037836 0.071424 0.0457033 0.0314447
crop_tensor 10 0.705426 0.671506 (0.951916) 0.033920 (0.048084) 0.05841 0.123901 0.0705426 0.0485346
slice 10 0.324241 0.324241 (1.000000) 0.000000 (0.000000) 0.024299 0.07213 0.0324241 0.0223084
eager_deletion 30 0.250524 0.250524 (1.000000) 0.000000 (0.000000) 0.004171 0.016235 0.0083508 0.0172365
ScopeBufferedMonitor::post_local_exec_scopes_process 10 0.047794 0.047794 (1.000000) 0.000000 (0.000000) 0.003344 0.014131 0.0047794 0.00328831
InitLocalVars 1 0.034629 0.034629 (1.000000) 0.000000 (0.000000) 0.034629 0.034629 0.034629 0.00238254
ScopeBufferedMonitor::pre_local_exec_scopes_process 10 0.032231 0.032231 (1.000000) 0.000000 (0.000000) 0.002952 0.004076 0.0032231 0.00221755总结
通过以上实验对比可以发现,device_guard接口能够做到一条命令即可合理设置模型网络层的运行设备,对模型进行GPU和CPU计算的更灵活调度,将服务器的资源利用到极致,解决显存容量捉襟见肘导致模型无法训练的问题。怎么样,这个功能是不是相当实用!心动不如心动,快快参考本文的方法,尽情训练自己的模型吧!
#Reward Centering
强化学习之父Richard Sutton给出一个简单思路,大幅增强所有RL算法
在奖励中减去平均奖励
在当今的大模型时代,以 RLHF 为代表的强化学习方法具有无可替代的重要性,甚至成为了 OpenAI ο1 等模型实现强大推理能力的关键。但这些强化学习方法仍有改进空间。近日,强化学习之父、阿尔伯塔大学教授 Richard Sutton 的团队低调更新了一篇论文,其中提出了一种新的通用思想 Reward Centering,并称该思想适用于几乎所有强化学习算法。这里我们将其译为「奖励聚中」。该论文是首届强化学习会议(RLC 2024)的入选论文之一。一作 Abhishek Naik 刚刚从阿尔伯塔大学获得博士学位,他是 Sutton 教授的第 12 位博士毕业生。

下面我们简要看看 Reward Centering 有何创新之处。
- 论文标题:Reward Centering
- 论文地址:https://arxiv.org/pdf/2405.09999
奖励聚中理论
智能体和环境之间的交互可以表述为一个有限马尔可夫决策过程(MDP)(S, A, R, p),其中 S 表示状态集,A 表示动作集,R 表示奖励集,p : S × R × S × A → [0, 1] 表示转换的动态。在时间步骤 t,智能体处于状态 S_t,使用行为策略 b : A × S → [0, 1] 采取行动 A_t,然后根据转换动态:

观察下一个状态 S_{t+1} 和奖励 R_{t+1}。这里研究的问题是持续性问题,即智能体和环境的交互会无限地进行。智能体的目标是最大化长期获得的平均奖励。为此,该团队考虑了估计每个状态的预期折扣奖励总和的方法:

这里,折扣因子不是问题的一部分,而是一个算法参数。奖励聚中思想很简单:从奖励中减去实际观察到的奖励的平均值。这样做会让修改后的奖励看起来以均值为中心。这种以均值为中心的奖励在 bandit 设置中很常见。举个例子,Sutton 和 Barto 在 2018 年的一篇论文中表明,根据观察到的奖励估计和减去平均奖励可以显着提高学习速度。而这里,该团队证明所有强化学习算法都能享受到这种好处,并且当折现因子 γ 接近 1 时,好处会更大。奖励聚中之所以这么好,一个底层原因可通过折现价值函数的罗朗级数(Laurent Series)分解来揭示。折现价值函数可被分解成两部分。其中一部分是一个常数,并不依赖状态或动作,因此并不参与动作选取。
用数学表示的话,对于与折现因子 γ 对应的策略 π 的表格折现价值函数

:

其中 r(π) 是策略 π 获得的独立于状态的平均奖励,

是状态 s 的微分值。它们各自对于遍历 MDP 的定义为:


则是一个误差项,当折现因子变为 1 时变为零。状态值的这种分解也意味着状态-动作值有类似的分解。
这种 Laurent 级数分解能解释奖励聚中为何有助于解决 bandit 问题。在完整的强化学习问题中,与状态无关的偏移可能会相当大。举个例子,图 2 中展示的三状态马尔科夫奖励过程。如果状态从 A 变成 B,则奖励是 +3,否则都是 0。平均奖励为 r(π) = 1。右侧表中给出了三个折现因子的折现状态值。

现在,从每个状态中减去常数偏移的折现值

,也被称为聚中折现值。
可以看到,这个已经聚中的值在幅度上要小得多,并且当折现因子增大时,也只会发生轻微变化。这里还给出了微分值以供参考。这些趋势普遍成立:对于任意问题,折现值的幅度都会随着折现因子接近 1 而急剧增加,而聚中折现值则变化不大,并接近微分值。从数学上看,聚中折现值是平均聚中奖励的预期折现和:

其中 γ ∈ [0, 1]。当 γ = 1 时,聚中折现值与微分值相同。更一般地说,聚中折现值是微分值加上来自罗朗级数分解的误差项,如上图右侧所示。因此,奖励聚中能够通过两个组件(恒定平均奖励和聚中折现值函数)捕获折现值函数中的所有信息。这种分解非常有价值:
- 当γ→1时,折现值趋于爆炸,但聚中折现值仍然很小且易于处理。
- 如果问题的奖励偏移了一个常数 c,那么折现值的幅度就会增加 c/(1 − γ),但聚中折现值会保持不变,因为平均奖励也会增加 c。
使用奖励聚中时,还可以设计出在智能体的生命周期内可以改变折现因子(算法参数)的算法。对于标准折现算法来说,这通常是低效或无效的,因为它们的非聚中值可能会发生巨大变化。相比之下,聚中值可能变化不大,当折现因子接近 1 时,变化会变得微不足道。
当然,为了获得这些潜在好处,首先需要基于数据估计出平均奖励。
简单奖励聚中以及基于价值的奖励聚中
估计平均奖励最简单的方法是根据之前已经观察到的奖励估计平均值。也就是说,如果

表示 t 个时间步骤后的平均奖励估计,则

。更一般地,可以使用步长参数 βt 来更新该估计:

该团队表示,这种简单的聚中方法适用于几乎任何强化学习算法。举个例子,奖励聚中可以与传统的时间差分(TD)学习组合起来学习一个状态-价值函数估计:

此外,他们还提出了基于价值的奖励聚中。这种方法的灵感来自强化学习的平均奖励公式。Wan et al. (2021) 表明,使用时间差分(TD)误差(而不是 (4) 中的传统误差)可以对表格离策略设置中的奖励率进行无偏估计。事实证明,平均奖励公式中的这个思路在折扣奖励公式中也非常有效。该团队表明,如果行为策略采取目标策略所做的所有操作,那么可以使用 TD 误差很好地近似目标策略的平均奖励:

由于这种聚中方法除了奖励之外还涉及价值,因此他们将其称为基于价值的聚中。不同于简单的奖励聚中,现在平均奖励估计和价值估计的收敛是相互依赖的。
实验
该团队实验了 (5) 式的四种算法变体版本,并测试了不同的折现因子。详细过程请阅读原论文,这里我们简单看看结果。

如图 3 所示,当奖励由一个 oracle 进行聚中处理时,学习曲线的起点会低得多。对于其它算法,第一个误差都在 r(π)/(1 − γ) 量级。无聚中的 TD 学习(蓝色)最终达到了与 oracle 聚中算法(橙色)相同的误差率,这符合预期。简单聚中方法(绿色)确实有助于更快地降低 RMSVE,但其最终误差率会稍微高一点。这也符合预期,因为平均奖励估计会随时间而变化,导致与非聚中或 oracle 聚中版本相比,更新的变数更大。当 γ 更大时也有类似的趋势。这些实验表明,简单的奖励聚中技术在在策略设置中非常有效,并且对于较大的折扣因子,效果更为明显。在学习率和渐近误差方面,基于价值的奖励聚中(红色)在在策略问题上与简单聚中差不多。但在离策略问题上,基于价值的聚中能以更快的速度得到更低的 RMSVE,同时最终误差率也差不多。总体而言,可以观察到奖励聚中可以提高折现奖励预测算法(如 TD 学习)的学习率,尤其是对于较大的折扣因子。虽然简单奖励聚中方法已经相当有效,但基于价值的奖励聚中更适合一般的离策略问题。此外,该团队还研究了奖励聚中对 Q 学习的影响。具体的理论描述和实验过程请访问原论文。


总之,实验表明,奖励聚中可以提高 Q 学习算法的表格、线性和非线性变体在多种问题上的性能。当折现因子接近 1 时,学习率的提升会更大。此外,该算法对问题奖励变化的稳健性也有所提升。看起来,奖励聚中这个看起来非常简单的方法确实可以显著提升强化学习算法。你怎么看待这一方法,会在你的研究和应用中尝试它吗?
#Data Scaling Laws in Imitation Learning for Robotic Manipulation
机器人迈向ChatGPT时刻!清华团队首次发现xxx智能Scaling Laws
想象这样一个场景:你正在火锅店和朋友畅聊,一个机器人熟练地为你倒饮料、端菜,完全不需要你分心招呼服务员。这个听起来像科幻的场景,已经被清华大学交叉信息院的研究者们变成了现实!他们发现了xxx智能领域的 “圣杯”——data scaling laws,让机器人实现了真正的零样本泛化,可以无需任何微调就能泛化到全新的场景和物体。这一突破性发现,很可能成为机器人领域的 “ChatGPT 时刻”,彻底改变我们开发通用机器人的方式!
,时长00:29
从火锅店到电梯,机器人展现惊人泛化力
研究团队可不是只在实验室里玩玩具。他们把机器人带到了各种真实场景:火锅店、咖啡厅、公园、喷泉旁,甚至是电梯里。更令人震惊的是,机器人在这些前所未见的环境中都展现出了超强的适应能力!
,时长00:31
为了确保研究的可复现性,团队慷慨地开源了所有资源,包括耗时半年收集的海量人类演示数据:
论文标题:Data Scaling Laws in Imitation Learning for Robotic Manipulation
论文链接:https://arxiv.org/abs/2410.18647
项目主页:https://data-scaling-laws.github.io/
连 Google DeepMind 的机器人专家 Ted Xiao 都忍不住为这项研究点赞,称其对机器人大模型时代具有里程碑意义!

Scaling Laws:从 ChatGPT 到机器人的制胜法则
还记得 ChatGPT 为什么能横空出世吗?答案就是 scaling laws!现在,清华团队首次证明:这个法则在机器人领域同样适用。事实上,真正的 scaling laws 包含数据、模型和算力三个维度,而本研究重点突破了最基础也最关键的数据维度。
,时长00:05
研究团队使用便携式手持夹爪 UMI,在真实环境中收集了超过 4 万条人类演示数据。他们采用最新的 Diffusion Policy 方法从这些数据中学习机器人控制模型,并通过惊人的 15000 + 次实机测试进行严谨评估,最终发现了三个革命性的幂律关系:
- 模型对新物体的泛化能力与训练「物体」数量呈幂律关系。
- 模型对新环境的泛化能力与训练「环境」数量呈幂律关系。
- 模型对环境 - 物体组合的泛化能力与训练「环境 - 物体对」的数量呈幂律关系。

这意味着什么?简单说:只要有足够的数据,机器人就能像 ChatGPT 理解语言一样,自然地理解和适应物理世界!这一发现不仅证实了机器人领域与语言模型存在惊人的相似性,更为预测数据规模与模型性能的关系提供了坚实的理论基础。
颠覆性发现:数据收集原来要这么做!
研究团队还破解了一个困扰业界的难题:对于给定的操作任务,如何优化选择环境数量、物体数量和每个物体的演示次数?
经过大量实验,他们得出了两个出人意料的结论:
1. 当环境数量足够多时,在单一环境中收集多个不同的操作物体的数据收益极其有限 —— 换句话说,每个环境只需要一个操作物体的数据就够了。

2. 单个物体的演示数据很容易达到饱和 —— 在倒水和摆放鼠标等任务中,总演示数据达到 800 次时,性能就开始趋于稳定。因此,每个物体 50 次示范基本就能搞定。

为验证这个策略,团队找来 4 个人,只花了一个下午就收集到了训练数据。结果令人震惊:在 8 个全新场景中,机器人成功率高达 90%!这意味着,原本可能需要几个月的数据收集工作,现在可能只需要几天就能完成!

模型规模化探索的意外发现
除了数据规模,研究团队还在模型规模化方面有三个重要发现:
- 视觉编码器必须经过预训练和完整的微调,缺一不可
- 扩大视觉编码器的规模能显著提升性能
- 最令人意外的是:扩大扩散模型的规模却没能带来明显的性能提升,这一现象还值得深入研究

未来展望
数据规模化正在推动机器人技术走向新纪元。但研究团队提醒:比起盲目增加数据量,提升数据质量可能更为重要。关键问题在于:
- 如何确定真正需要扩展的数据类型?
- 如何最高效地获取这些高质量数据?
这些都是 Data Scaling Laws 研究正在积极探索的方向。相信在不久的将来,具有超强适应力的机器人将走进千家万户,让科幻电影中的场景变为现实!而这一切,都将从清华团队发现的这个基础性规律开始!
#PIVOT-R
机器人操纵世界模型来了,成功率超过谷歌RT-1 26.6%
对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。
针对该问题,来自中山大学和华为诺亚等单位的研究团队提出了一种全新的原语驱动的路径点感知世界模型,借助 VLMs 作为机器人的大脑,理解任务之间的动作关联性,并通过 “世界模型” 获取对未来动作的表征,从而更好地帮助机器人学习和决策。该方法显著提升了机器人的学习能力,并保持良好的泛化性。
- 论文地址:https://arxiv.org/abs/2410.10394
- 项目主页:https://abliao.github.io/PIVOT-R/
研究动机

当前,现有机器人操作任务有两个关键问题:
- 机器人模型在开放世界中表现差且不稳定:许多机器人操作模型虽然能够处理复杂任务,但往往直接将用户指令和视觉感知映射到低层次的可执行动作上,而忽略了操作任务中关键状态(路径点)的建模。这种方式容易使模型记住表面数据模式,导致模型在开放环境中表现脆弱。模型缺乏对关键路径点的预测,使得每个动作的随机性可能逐步放大,降低了任务的执行成功率。
- 计算效率低:随着模型的增大(例如 RT-2, RT-H),运行速率随之降低,无法满足机器人任务实时性的需求。
为了解决上述问题,研究团队提出了 PIVOT-R,一种原语驱动的路径点感知世界模型。如上图所示,对比左图现有的方法,右图展示了 PIVOT-R 通过关注与任务相关的路径点预测,提升机器人操作的准确性,并设计了一个异步分层执行器,降低计算冗余,提升模型的执行效率。
这样做有几个好处:
- 它使得模型可以更好的学习任务与动作之间的内在关联性,减少其他干扰因素的影响,并更好地捕捉不同任务之间的相似性(例如,拧瓶盖和拧螺丝的动作是相似的,拿杯子和搭积木都有一个抓住物体的过程),从而使得模型可以在多任务数据下学习到可迁移的知识。
- 通过世界模型建模的方式获得对未来关键动作的表征,避免了文本语言带来的模糊性、不确定性。
- 通过异步执行的方式,确保各模块独立运行、互不阻塞,从而有效避免了大模型导致的低速率问题。
研究方法

原语动作解析
PIVOT-R 的第一个核心步骤是原语动作解析,这一步通过预训练的视觉 - 语言模型(VLM)来解析用户的语言指令。VLM 可以将复杂的自然语言指令转换为一组简单的原语动作,例如 “靠近”、“抓取”、“移动” 等。这些原语动作为机器人提供了操作任务的粗略路径。
具体流程如下:
- 用户输入的语言指令(例如 “请给我那个杯子”)首先被输入到 VLM 中,VLM 会将其解析为与任务相关的原语动作(如 “靠近杯子”、“抓取杯子”)。
- 原语动作作为提示,指导机器人在接下来的步骤中专注于特定的操作轨迹点。这种方式确保机器人不会被复杂的环境因素干扰,而是明确知道每个动作的目的。
路径点预测
在原语动作解析后,PIVOT-R 的下一步是路径点预测。路径点代表了机器人操控过程中一些关键的中间状态,例如靠近物体、抓取物体、移动物体等。通过预测路径点,PIVOT-R 能够在机器人执行任务时提供明确的操作指导。具体来说,通过一个 Transformer 架构的模型,预测路径点对应的视觉特征,为后续的动作预测模块提供指引。
动作预测模块
动作预测模块负责根据预测的路径点生成具体的低层次机器人动作。它以路径点为提示,结合机器人历史状态(如位置、姿态等),计算下一步应该执行的动作。该模块使用轻量级的 Transformer 架构进行动作预测,确保计算效率和性能的平衡。这一模块的设计重点在于低延迟和高精度执行操控任务。
异步分层执行器
此外,PIVOT-R 还引入了一个关键的执行机制,即异步分层执行器。与以往的机器人模型不同,PIVOT-R 并不对所有模块在每一步都进行同步更新,而是为不同模块设置了不同的执行频率,以多线程的方式进行异步更新,从而提升执行速度。
实验
作者在具有复杂指令的 SeaWave 仿真环境和真实环境下进行实验。


如 Table 1 和 Table 2 所示,PIVOT-R 在仿真环境和真实环境都取得了最优的效果,同时,模型的速度和 RT-1 等方法速度相近,没有因为使用大模型而导致速度变慢。

作者也在 SeaWave 上做了泛化性测试,在三种泛化性测试场景下,PIVOT-R 仍保持远高于其他模型的成功率。
研究总结
PIVOT-R 通过引入原语动作驱动的路径点感知,显著提升了机器人在复杂操控任务中的性能。该模型不仅在执行效率上具备优势,还能够更好地应对复杂、多变的环境。该方法在仿真环境和真实环境操纵下表现优异,为机器人学习提供了一个新范式。
#全球首款AI游戏问世了
欢迎来到 Transformer 的世界。

两个月前,我们对 AI 游戏的认知刚刚被谷歌 GameNGen 颠覆。他们实现了历史性的突破,从此不再需要游戏引擎,AI 能基于扩散模型,为玩家生成实时可玩的游戏。
GameNGen 一出,从此,开发者不必再手动编程,价值 2000 亿美元的全球游戏产业,都将被彻底颠覆。无论什么类型的游戏,都可以想你所想、懂你所懂,幻化出只属于你的独享世界。这样的论调瞬间铺满了 AI 圈。
当时,游戏界最热的除了《黑神话:悟空》,就是米哈游创始人蔡浩宇的犀利发言:「AI 颠覆游戏开发,建议大部分游戏开发者赶快转行。」
没想到,只过了两个月,新的里程碑就来了,AI 实时生成游戏不再只是「只可远观不可亵玩」的 demo,直接就能上手体验。
,时长00:51
昨天,两家初创公司 Etched、 Decart AI 联手,带来了世界上首个实时生成的 AI 游戏 Oasis,你在其中体验到的每一帧都来自扩散模型的实时预测,游戏画面持续以 20 帧每秒的速度实时渲染,零延迟。
更重要的是,所有代码和模型权重均已开源。
- 试玩链接:https://oasis.decart.ai/overview
- 项目链接:https://github.com/etched-ai/open-oasis
- 模型权重:https://huggingface.co/Etched/oasis-500m/blob/main/media/thumb.png
AI 能够精确模拟出高质量的图形和复杂的实时交互,这一切的到来快得令人措手不及,看到的网友都有点错愕:难道我们没穿越到《黑客帝国》中的矩阵世界吗?
AI 领域的专家而言也都在关注 Oasis。FlashAttention 作者,普林斯顿助理教授 Tri Dao 等诸多大佬纷纷点赞:「很快模型推理就会变得非常便宜,我们的许多娱乐内容都将由人工智能生成」。
不过既然是游戏,我们就要以游戏的要求来对它进行评价。
一流的意义,摸不着头脑的体验
话不多说,我们立马上手试玩了一下。果然,重要的事情起码要说三遍 —— 这是世界上第一款 AI 实时生成的游戏。这刚进入界面,就收到了 Oasis 的提醒:「请注意,你做出的每一步都将决定整个世界的走向」。

这可一下子把期待值拉满了。游戏的内容能够实时自我塑造,这意味着这个世界里的一举一动都完全以你为主,与你有关,玩家不需要再遵循固定的模式和任务,因为每一秒都是 AI 为你量身定制的惊喜。
从海岸、村庄、森林、沙漠等地形中选择一个,就能正式开启体验了。(由于 Oasis 太过火爆,想真玩上还要排一会儿队,算力有限,每位使用者限时体验五分钟。)

终于挤进去之后,Oasis 这个游戏却让人有点看不懂了,这不就是《我的世界》吗?

比《幻兽帕鲁》还有既视感。
「这样做真的没有版权问题吗?」
很多试玩的人也有同感:「告诉 AI:参考《我的世界》做一个游戏,把 UI 改改就行。」
AI:下载《我的世界》,启动!
不过照《我的世界》的玩法继续搭房子,Oasis 帮忙生成出来的牛棚倒是可圈可点。毕竟,这次驱动游戏的不是设定好的逻辑和程序,只有一个 AI 模型。
把栅栏放在另一个栅栏旁边的动作,看起来只需要一步,但模型其实悄咪咪地完成了识别你点击的是栅栏,它要和其他物体放在一起应该如何排列,这个画面要如何呈现等等的复杂转化。

不过相比它的预测能力,记忆应该是 Oasis 的短板,比如画面左边原来有座山,但是再把视线转回去,就会发现山已经消失了。

我那么大一座山呢?
而像 Sora,或者同样都旨在模拟物理世界的其他视频模型,在把「镜头」平移回来之后就没有这种明显的记忆损失。对此,有网友猜测是牺牲了参数数量来换取实时的推理速度。
虽然官方声称游戏的操作是 0 延迟的,但是使用鼠标操控起来有点困难,就像有一股神秘的力量在影响鼠标和电脑之间的连接。想要点击背包中某一格的物品,总会识别到其他格中。并且游戏中的文字,有一种梦核的意味,好像有点轮廓,却怎么也看不清楚。

这位网友的形容很贴切:「开始的时候,我以为是《我的世界》,后来亲自尝试过之后,这是吃了菌子再玩的《我的世界》。」
Oasis 的技术:Transformer 中的宇宙
作为 Oasis 的技术支持,Etched、 Decart AI 都发布了技术博客,其中 Decart AI 主要负责训练模型,Etched 提供算力。
架构
模型由两部分组成:一个空间自编码器和一个潜在扩散模型结构。这两部分都基于 Transformer 模型:自编码器基于 ViT,而主干则基于 DiT。与最近的基于动作的世界模型如 GameNGen 和 DIAMOND 不同,Oasis 的研究团队选择了 Transformer 来确保稳定、可预测的扩展。

与 Sora 这样的双向模型不同,Oasis 是自回归地生成帧的,它能够根据游戏输入调节每一帧,这构成了 AI 生成的游戏实时与世界互动的基础。
该模型采用了 Diffusion Forcing 训练方法,能够独立对每个 token 进行去噪。它通过在空间注意力层之间加入额外的时间注意力层,来利用前几帧的上下文。此外,扩散过程在 ViT VAE 生成的潜在维度中进行,这一维度不仅压缩了图像大小,还使得扩散能够专注于更高层次的特征。
时间的稳定性是 DecartAI 关注的问题 —— 需要确保模型的输出在长时间跨度内是有意义的。在自回归模型中,错误会累积,小瑕疵很快就会累积成错误的帧。
为了解决这个问题,该团队在长上下文生成中进行了创新。他们选择的方法是动态调整噪声。模型推理时将对噪声实施这样的计划,初期,通过扩散前向传播注入噪声以减少错误积累,在后期逐渐去除噪声,使模型能够发现并保持之前帧中的高频细节。

性能
Oasis 游戏以每秒 20 帧的速度生成实时输出。目前最先进的具有类似 DiT 架构的文本转视频模型(例如 Sora、Mochi-1 和 Runway)可能需要 10-20 秒才能创建一秒钟的视频,即使在多个 GPU 上也是如此。然而,为了匹配玩游戏的体验,Oasis 的模型必须最多花每 0.04 秒生成一个新帧,速度快了 100 倍以上。

借助 Decart 推理堆栈的优化设置,开发者大幅提升了 GPU 的运行、互联效率,让该模型最终能以可播放的帧速率运行,首次解锁了实时交互性。
但是,为了使模型速度再快一个数量级,并使其大规模运行更具成本效益,就需要新的硬件。Oasis 针对 Etched 构建的 Transformer ASIC Sohu 进行了优化。Sohu 可以扩展到 4K 分辨率的 100B+ 大规模下一代模型。
此外,Oasis 的端到端 Transformer 架构使其在 Sohu 上运行非常高效,即使在 100B+ 参数模型上也可以为 10 倍以上的用户提供服务。对于像 Oasis 这样的生成任务来说,价格显然是可运作的隐藏瓶颈。

来势汹汹的 Etched 与 Decart AI
Etched,这个名字可能有点陌生,但它算得上是硅谷又一个 AI 融资神话。两位 00 后创始人 Chris Zhu 和 Gavin Uberti,把宝押在了基于 Transformer 架构的大模型上,选择 all in Transformer。于是 2022 年,他们双双从哈佛大学退学联手创业,专门开发用于 Transformer 模型的专用芯片(ASIC)
Etched 的两位创始人 Gavin Uberti(图左)、Chris Zhu(图右)。
今年 7 月,Etched 发布了首款 AI 芯片 Sohu,宣称:「就 Transformer 而言,Sohu 是有史以来最快的芯片,没有任何芯片能与之匹敌。」当天,Etched 完成了 1.2 亿美元 (约人民币 8 亿元) 的 A 轮融资,投资阵容集结了一众硅谷大佬,向英伟达发起了挑战。

与英伟达相比,一台集成了 8 块 Sohu 的服务器,性能超过 160 块 H100,Sohu 的速度比 H100 快 20 倍;与英伟达最强的新一代 B200 相比,Sohu 的速度要快 10 倍以上,而且价格更便宜。
Decart 则是一家来自以色列人工智能公司,直到今天才正式露面。伴随 Oasis 发布的还有 Decart 获得红杉资本和奥伦・泽夫 2100 万美元(约等于 1.5 亿人民币)融资的消息。在推出 Oasis 之前,Decart 提供的主要服务为构建更高效的平台,提升大模型的速度和可靠性。
Oasis 或许会是一个好的开始,或许在此基础之上,不久以后我们就可以玩到全新形态的 AI 游戏?
参考内容:
https://www.etched.com/blog-posts/oasis
https://www.decart.ai/articles/oasis-interactive-ai-video-game-model
#「上下铺猜想」被证伪
理所当然也能错,数学界震动
现代数学,开始对你的直觉开刀了。
数学的很大一部分是由直觉驱动的,但有时想当然会让人误入歧途。早期的证据可能并不代表大局,一个陈述可能看起来很明显,但一些隐藏的微妙之处会自行显露出来。
三位数学家现在已经证明,概率论中一个著名的假设,即双层床猜想(bunkbed conjecture)就属于这一类。这个猜想 —— 关于当数学迷宫(称为图、graphs)像双层床一样堆叠在一起时,你可以用不同的方式导航 —— 这似乎是自然的,甚至是不言而喻的。
「我们的大脑告诉我们的任何事情都表明,这个猜想应该是正确的,」普林斯顿大学图论学家 Maria Chudnovsky 说道。
- 论文链接:https://arxiv.org/abs/2410.02545
但这就是错误的。上个月,三位数学家宣布了一个反例,反驳了这一猜想。这一结果为解决固体材料性质相关物理问题提供了新的指导。但它也涉及了关于数学如何运作的更深层次的问题。大量的数学努力都花在试图证明猜想是正确的上。这项新工作的团队在最终找到反例之前失败了很多次。他们的故事表明,数学家可能需要更频繁地质疑他们的假设。
图中之图
在 1985 年,一位名叫 Pieter Kasteleyn 的荷兰物理学家想要用数学方法证明液体如何在多孔固体中流动。他的工作使他提出了双层床猜想。
要理解这个理论,我们先从一张图开始:一组由线或边连接的点或顶点。

现在复制一份该图并将其直接放在原图上方。在它们之间画一些垂直柱子 —— 将底部图上的一些顶点与顶部图上的孪生顶点连接起来的附加边。最终得到的结构类似于双层床。

接下来,我们考虑底部图中的一条边,开始抛硬币。如果硬币正面朝上,则擦除边。如果硬币反面朝上,则保留边。对两个图中的每条边重复此过程。你的下铺和上铺最终看起来会有所不同,但它们仍将通过垂直柱子连接起来。

最后,在下部图中选取两个顶点。你能沿着图的边缘从一个顶点到达另一个顶点吗?还是说这两个顶点现在断开了?
对于任何图,你都可以计算出存在路径的概率。现在看看同样的两个顶点,但对于其中一个顶点,跳转到顶部图中它正上方的顶点。是否有一条路径可以带你从底部图上的起始顶点到达顶部图上的终止顶点?

双层床猜想认为,找到下铺路径的概率总是大于或等于找到跳到上铺路径的概率。无论你从哪个图开始,在双层床之间画多少个垂直柱子,或者选择哪个起始和结束顶点,都无关紧要。
看起来很合理是吧,这难道还能证伪吗?
几十年来,数学家们一直认为这是成立的。直觉告诉我们,在一个铺位上寻路应该比去另一个铺位的路径更简单 —— 从下铺到上铺所需的额外垂直跳跃应该会大大限制可用路径的数量。
数学家们希望双层床猜想是真的。它属于渗透理论领域的一类陈述,该理论处理在随机删除图的边后存在的路径和簇。这些图可以被认为是流体如何移动或渗透通过多孔材料的简化模型,就像水通过海绵一样。双层床猜想则暗示了物理学中一个被广泛接受的假设,即流体穿过固体的可能性。它还暗示了如何解决渗透物理学的相关问题。
但只有当有人能证明双层床猜想是正确的时候,这种情况才会发生。没有人能证明这一点是有原因的。
问题显现
加州大学洛杉矶分校(UCLA)数学家 Igor Pak 一直怀疑双层床猜想是否正确。「他从一开始就持怀疑态度,」他的一名研究生 Nikita Gladkov 说道。「他非常不相信旧猜想。」Pak 一直直言不讳地批评数学家们倾向于集中精力证明这些猜想。同样重要的进步也可以来自设问「如果它们全都错了怎么办?」
Igor Pak 怀疑双层床猜想还有一个特别的理由:它似乎是一个过于宽泛的说法。他怀疑这个猜想是否真的适用于所有可以想象的图。有些猜想是由实质驱动的,有些则是由一厢情愿的想法驱动的,双层床猜想似乎是后者。

Nikita Gladkov 对每个图表进行了详尽的强力搜索,以寻找反例。
2022 年,他开始寻求反驳这一理论。他花了一年时间尝试,但都以失败告终。然后,他指示 Gladkov 使用计算机对他能找到的每一张图进行详尽的强力搜索。Gladkov 意识到这项任务需要一些复杂的编程,于是请来了高中时就认识的朋友 Aleksandr Zimin(现在他是麻省理工学院的在读博士)。「我们实际上是大学时的室友 —— 我们的宿舍里有一张真正的双层床,」Gladkov 说道。
Gladkov、Pak 和 Zimin 能够手动挨个检查每个少于九个顶点的可能图。在这些情况下,他们可以验证上下铺猜想成立。但对于更大的图,可能情况的数量将会急剧增加,以至于他们无法穷尽所有可能的边删除方式或路径形成方式。
团队随后转向 AI 领域,使用机器学习方法。他们训练了一个神经网络来生成可能偏好向上跳跃的曲折路径图。在模型生成的许多示例中,他们发现下铺路径仅比上铺路径的概率略高一点。但模型未能找到任何反过来的例子。
还有另一个问题出现了:神经网络生成的每个图仍然很大,以至于数学家们无法逐一调查掷硬币步骤的所有可能结果。团队不得不计算在这些结果的子集上找到上下路径的概率,就像民意调查通过抽样部分选民来预测选举结果一样。
数学家们意识到,他们可以对神经网络提供的任何反例有超过 99.99% 的信心确认其是正确的,但却无法达到 100%。他们开始怀疑这种方法是否值得继续追求。这样的证明方式不太可能说服数学界,更不用说任何权威期刊会将其视为严谨的证明了。
「博士生在现实中需要找工作,而不是理论上,」Pak 在他的博客上写道,而 Gladkov 和 Zimin 很快也将开始找工作。「这才是我们停下来的真正原因,」他接着说道。「当你可以尝试做别的事情时,为什么还要坚持并制造争议呢?」
他们放弃了他们的计算方法,但并未停止对这个问题的思考。在接下来的几个月里,他们专注于制定一个不需要计算机的理论论证。但他们仍然缺少完成它所需的所有拼图。
然后,一个来自国外的突破性研究出现了。
计算机?不用了
今年六月,剑桥大学的 Lawrence Hollom 在不同的背景下推翻了上下铺问题的一个变体版本。这个版本的猜想不是关于图,而是关于一种称为「超图」(hypergraphs)的对象。在超图中,「边」不再被定义为两个顶点之间的连接线,而是可以任意数量的顶点间的连接线。
Hollom 成功找到了这个猜想的反例。他创建了一个小型超图,每条边都连接三个顶点:

Gladkov 偶然发现了这篇论文,意识到它正是他们三人所需要的。「我是在晚上发现的,读到凌晨三点。我心想,『哇,这太疯狂了,简直令人难以置信,』」他说。他在睡前给 Zimin 发了短信,第二天两人便通了电话。
这时候考验来了:他们是否可以将 Hollom 找到的反例重新构造成一个普通图,从而推翻原来的上下铺猜想?
这其实并不是这对老朋友第一次考虑如何将超图转化为图。去年年初,他们在一起参加演唱会前的不久就曾讨论过这个问题。「当时红辣椒乐队(The Red Hot Chili Peppers)在台上唱歌,而我却在想着这个问题,」Gladkov 说。「我完全没心思听音乐。」
后来,他们就开发出了在特定情况下将超图转化为图的方法。
他们意识到,现在他们终于可以使用这些技术来转换 Hollom 的超图。Gladkov、Pak 和 Zimin 将超图中每条具有三顶点的边替换为由大量点和普通边组成的集群。这使他们得到了一张巨大的图,包含 7222 个顶点和 14422 条边。
然后,他们放弃了使用人工智能的方法后,利用所构建的理论进行论证。在他们的这张图中,找到上路径的概率比找到下路径高出

% ,这是一个极小但不为零的数值。
至此,上下铺猜想终于被他们证明是错误的。
普林斯顿大学数学家 Noga Alon 对此表示,他们的研究结果显示了不应把任何事情视为理所当然的重要性。「我们必须保持怀疑,即便是那些直观上看起来很可能为真的事情。」
Gladkov、Pak 和 Zimin 在之后, 找到了许多满足该猜想的小图示例,但最终,这些示例并未反映在具有足够多顶点和边时他们能构建出的更复杂、更不直观的图中。
正如 Hollom 所说:「我们真的像我们认为的那样理解这些内容了吗?」
数学家们仍然相信激发了上下铺猜想的关于固体内连接位置的物理陈述。但他们需要找到另一种方法来证明它。

Aleksandr Zimin 在大学期间与 Gladkov 同住一间宿舍,宿舍里还有一张真正的上下铺。
与此同时,Pak 表示,很明显,数学家需要更积极地讨论数学证明的本质。他和同事最终并未依赖有争议的计算方法,而是以完全确定的方式推翻了该猜想。但随着计算机和 AI 方法在数学研究中的使用日益普及,一些数学家开始争论该领域的规范是否需要改变。
「这是一个哲学问题,」Alon 说道。「我们应如何看待那些仅在高概率下才能成立的证明?」
「我认为未来的数学界会接受这样的概率证明,」罗格斯大学的数学家 Doron Zeilberger 说道(这位数学家因在他本人许多的论文中将计算机列为合著者而闻名),「在 50 年内,或许更短,人们将有新的态度。」

Doron Zeilberger 常将他的计算机 Shalosh B. Ekhad 列为合著者,成为一桩趣事。
其他人则担心这样的未来会威胁到某种重要的东西。「也许概率证明会让你对事情的真实本质缺乏理解或直觉,」Alon 说道。
Pak 建议随着此类结果变得更加常见,应创建专门的期刊来发表这些研究结果,以免它们的价值被数学家们忽视。但他的主要目的是为了在数学界引发大讨论。
「没有正确答案,」他说。「我希望数学界思考,下一次此类结果是否应该被视为有效。」随着技术不断渗透和改变数学领域,这个问题将变得更加紧迫。
参考内容:
https://www.quantamagazine.org/maths-bunkbed-conjecture-has-been-debunked-20241101/
https://www.reddit.com/r/math/comments/1fulfpu/the_bunkbed_conjecture_is_false/
#安克深耕前沿技术的另一面藏在这里
前段时间,幻方科技、DeepSeek 创始人梁文锋亲自挂名的一篇论文传遍了全球互联网。
论文地址:https://arxiv.org/pdf/2502.11089
从论文的署名信息来看,十五位作者分属三家机构,大部分来自 DeepSeek,也有几位是在读博士生、以实习生的身份参与研究:一位来自华盛顿大学,一作和另外两位作者来自国内的「北大 - 安克大模型联合实验室」。
这引起了我们的关注:原来在 DeepSeek 之外,北京大学与安克创新这家消费电子巨头也有校企合作关系。
那么,双方究竟在大模型领域合作什么内容?跟安克创新的消费电子本业又有什么联系呢?带着这些问题,我们专访了安克创新高级副总裁 & 智能家庭业务总裁 Frank Zhu,对安克创新的大模型和机器人业务策略有了更为深入的了解。
「看十年,想三年,做一年」
安克创新对机器人的战略布局
Frank 表示:“前一段安克有几个火出圈的新闻,首先需打破一个误区,安克创新绝非是一家‘充电宝公司’,而是一家致力于拥有硬核技术实力的智能硬件公司。”
据悉,安克旗下的智能家庭品牌 eufy 已跻身欧美高端智能家居领域的领导品牌之列,在美、欧、日、澳等海外发达市场积累了近 1000 万中高端家庭用户。在安防领域,eufy Security 基于家庭本地基站构建的 “AI 大模型 + 本地化部署” 智能模式,能够有效识别人员危险等级并迅速响应,在高端安防领域占据市场份额首位。在清洁机器人领域,eufy 拥有数百人的研发团队,专注于 Deep Cleaning 定位,使清洁机器人精准理解需求,高效规划路径,实现家庭地面的深度清洁。该品类去年业绩良好,全球月活用户已突破百万。
尽管已实现高端引领,安克并未满足于渐进式创新。去年,安克更新了使命愿景,在「极致创新,激发可能」的新使命指引下,公司决意打造顶尖技术团队,实现极致技术创新,开启未来生活的多种新可能。
从宏观角度来看,家庭安防和清洁皆为机器人自动化领域的延伸,均共享机器人的底层能力:任务理解 + 感知、规划、控制。安克的战略方法论为:「看十年,想三年,做一年」。未来十年必定是机器人走进家庭、显著改善生活的十年。为给全球家庭用户缔造更美好的生活,安克决心打造支撑未来十年的机器人技术栈,并借助安克成熟的产品化和市场化能力,达成商业闭环。
Frank Zhu 指出,安克的机器人技术栈和产品将围绕三个本体进行布局:
- 本体一「二维基础型」:以扫地机器人、割草机器人为典型的平面作业机器人,是当下商业化的主力,支撑着基础业务规模。
- 本体二「三维移动型」:包含机器狗、无人机等具有三维空间移动能力的机器人,作为安防和清洁领域的补充。
- 本体三「三维交互型」:通过机械臂来实现复杂操作的人形/类人形机器人,代表着未来家庭智能服务的最终形态。

安克相信,在未来,家庭机器人将由少量通用类人形机器人以及众多专用领域机器人共同构成:例如在用户外出时,机器狗或无人机可以在家中巡逻,利用其三维移动能力灵活穿梭,支持 eufy Security 的智能模式,实时监控家中情况并快速响应威胁。当用户回到家,扫地机器人等已保持家中环境整洁。对于清洁前的整理物品等环节,具有机械臂的“三维交互型”人形/类人形机器人便会登场。这些不同类型的机器人各司其职、相互配合,共同为用户带来极致体验和美好生活。
安克主张,三类本体并非依序展开,而是凭借一组通用机器人能力共同演进,最终实现xxx智能。具体来说,安克认为需构建三组技术栈:机器人本体能力、大小脑能力,以及连接本体与大小脑、支撑快速强化的系统化平台能力。
安克在现有研发团队持续深耕本体一,在创造业务规模与现金流的同时,亦在大力布局底层技术栈团队以及本体二、本体三团队,以达成从二维至三维场景的跃迁,实现从单一智能体向多智能体协同的技术升级。
技术创新、产品化、商业化的飞轮
与所有科技领域相同,机器人领域的发展本质上是围绕 “技术创新 - 场景化产品 - 商业化成功” 的飞轮。在机器人领域获取成功,需要具备三种能力:其一,在技术研究阶段构建领先技术栈,突破传统技术瓶颈;其二,在产品化阶段基于对场景的充分理解,构建出有真正客户价值的产品形态,并打磨好极致体验;其三,在商业化阶段,构建产品、供应链、市场的协同网络,快速实现全球化规模销售,形成商业壁垒。只有拥有了完整的三种能力,才能实现商业成功。

安克正凭借其成熟的场景化产品能力与全球商业化能力,为其xxx智能的三本体战略赋予场景耕耘及商业规模优势,实现技术创新的真正突破。
安克在全球美、欧、日、澳等海外发达地区,不但积累了近千万中高端家庭用户,而且其用户复购率更是超过 30%。这意味着安克推出的任何新家庭机器人产品,都能够迅速进入全球家庭,在真实环境中积累场景和使用数据,进而实现快速强化闭环。同时,安克对用户家庭场景的深入理解和大量实践,也将有助于精准地实现技术的产品化,未来无论是安防机器狗还是人形机器人,融入现有的 eufy 智能家庭场景,都将更为容易。
如果我们对比探讨:一家技术实力领先的公司实现场景产品化和全球商业化所需的年数,以及一家在产品化和商业化方面占据优势的公司弥补技术短板所需要的年数,相信每个人都会有自己的看法。从过往的历史经验来看,倘若后者公司能够充分认识到技术人才的意义,吸引到一流的技术人才,并为他们营造优越的创新环境,那么实现技术突破所需的时间并不会太久。
安克在找“第一性、求极致、共成长”的创造者
在这场xxx智能的创新革命中,安克正在努力招兵买马。经历了挫折成长的安克深知,找到正确的人是成功最关键的要素。在分析了大量成功的创新者之后,安克把创新需要的特质归纳为三个方面,分别是第一性、求极致、共成长。安克内部把拥有这样特质的人叫「创造者」。
- 创造者们坚持第一性,敢于抛开表面事实,回归基础原理,抓出突破关键。
- 创造者们敢于求极致,能够顶着巨大风险,想尽一切办法,追求长期全局最优。
- 创造者们相信共成长,坚持长期主义、学以致用、以及持续的自我觉察与自我进化。
以时代最为杰出的创造者之一马斯克为例:在业界普遍认为锂电池成本过高的情况下,马斯克通过对电池成本结构的剖析,提出了垂直整合供应链、制造出低价锂电池的 “第一性方向”。面对巨大的困境,他坚定不移地付诸努力,最终引领全球步入电动车时代,这是真创造者的 “求极致精神”。在长达十年的进程中,马斯克坚守长期信念,持续自我进化,最终成为时代典范,这是真创造者的 “共成长主义”。
安克坚信创造者能够改变世界,致力于吸引和培育卓越的创造者:他们未必具备丰富的行业经验,或许是刚毕业甚至仍在校的硕士博士。跟大模型领域一样,xxx智能领域不存在成熟稳定的技术路线。在这场技术无人区的探索中,缺乏行业经验、较少受到思维定式的影响,甚至可能成为一种优势。安克的人才观与梁文锋组建 DeepSeek 团队的理念是一致的。DeepSeek 这支由 “并非高深莫测的奇才,而是一些顶尖高校的应届毕业生、未毕业的博四、博五实习生,以及一些毕业仅数年的年轻人” 构成的团队,也是安克在xxx智能领域搭建团队的目标模式。安克将为这些创造者搭建平等、透明且开放的环境,并提供充足的资源与激励,期望他们所创造的极致技术能为全球家庭用户带来全新的生活体验。这也是安克致力于为创造者构建的 “有机会、有成长、有回报、有意义” 的四有平台。
安克创新高级副总裁兼智能家庭业务总裁 Frank Zhu 指出,在机器人领域中,“二维基础型、三维移动型、三维交互型” 这三种本体,“机器人本体、大小脑以及系统化机器人平台” 这三组技术,以及 “技术创新、场景化产品、商业化成功” 这三种能力,是安克重点投入的公司战略,期待创造者们的加入并携手共创。
#使用DeepSeek的GRPO,7B模型只需强化学习就能拿下数独
没有任何冷启动数据,7B 参数模型能单纯通过强化学习学会玩数独吗?
近日,技术博主 Hrishbh Dalal 的实践表明,这个问题的答案是肯定的。并且他在这个过程中用到了 DeepSeek 开发的 GRPO 算法,最终他「成功在一个小型数独数据集上实现了高奖励和解答」。

下面我们就来具体看看他的博客文章,了解一番他的开发思路。
原文地址:https://hrishbh.com/teaching-language-models-to-solve-sudoku-through-reinforcement-learning/
现在的语言模型已经能完成很多任务了,包括写论文、生成代码和解答复杂问题。但是,如何让它们学会解答需要结构化思维、空间推理和逻辑推理的难题呢?这就是我最近的实验的切入点 —— 通过强化学习教语言模型解决数独问题。
教语言模型玩数独的难点
对语言模型来说,数独有自己独特的难点。不同于开放式的文本生成,玩数独需要:
- 遵循严格的规则(每行、每列和每框必须包含数字 1-9,且不能重复)
- 保持一致的网格格式
- 应用逐步的逻辑推理
- 理解网格元素之间的空间关系
- 得出一个正确的解答
有趣的是,语言模型并不是为结构化问题设计的。它们的训练目标是预测文本,而不是遵循逻辑规则或维持网格结构。然而,通过正确的方法,它们可以学会这些技能。
准备数据:从数值到网格
本实验使用了来自 Kaggle 的包含 400 万数独的数据集,其中有非常简单的,也有非常困难的。准备数据集的过程包含几大关键步骤:
1、加载和过滤:使用 kagglehub 库下载数据集并根据难度级别过滤数独。
2、难度分类:根据线索数量,将数独分为四个难度级别:
- Level 1(非常简单):50-81 条线索
- Level 2(简单):40-49 条线索
- Level 3(中等):30-39 条线索
- Level 4(困难):17-29 条线索
3、每个数独一开始都被表示成了 81 个字符的字符串。这里将其转换为具有适当行、列和框分隔符的网格格式:

4、提示词工程:每个数独都会被封装在一个精心设计的提示词中,而该提示词的作用是指示模型:
- 在 <think> 标签中逐步思考解决方案
- 在 <answer> 标签中提供具有适当网格格式的最终答案
对于初始实验,我创建了一个包含 400 个训练样本的聚焦数据集,这主要是使用更简单的数独来为学习构建一个基线。这个数据集被刻意选得较小,目的是测试模型使用有限样本学习的效率。加上我的资源有限:如果使用 unsloth grpo 训练,24GB RTX 4090 大约最多只能放入 3000 上下文长度。因此我只能选择更简单的问题以避免内存溢出(OOM),因为困难的问题及其推理链更长。
实验方法
我决定探索强化学习(尤其是 GRPO)能否让语言模型变成数独求解器。我实验了两种不同的模型大小:
- Qwen 2.5 7B Instruct:使用了秩为 16 的 LoRA 进行微调
- Qwen 2.5 3B Instruct:使用了秩为 32 的 LoRA 进行微调
重要的是,我没有使用冷启动数据或从 DeepSeek R1 等较大模型中蒸馏的数据。这里会从基础指令微调版模型开始,单纯使用强化学习。训练配置包括:
- 批量大小:1
- 梯度累积步骤:8
- 学习率:3e-4(Karpathy 常数)
- 最大部署:500
- 每 10 步评估一次
- 最大序列长度:3000 token

Andrej Karpathy 曾表示 3e-4 是 Adam 的最佳学习率
奖励系统:通过反馈进行教学
强化学习的核心是奖励函数 —— 可以告诉模型它何时表现良好。我设计了一个多分量奖励系统,它具有几个专门的功能:
1. 格式合规性奖励
为了实现良好的解析,模型应该始终记得使用正确的思考和答案标签(分别是 <think></think> 和 <answer></answer> 标签)。这些标签有两个关键目的:
- 将推理过程与最终答案分开
- 使提取与评估模型的解答变得容易
为了强制实施这种结构,我实现了两个互补的奖励函数:

第一个函数(tags_presence_reward_func)为出现的每个标签提供部分 credit,其作用是鼓励模型包含所有必需的标签。第二个函数(tags_order_reward_func)则用于确保这些标签以正确的顺序出现 —— 先思考再回答。它们一起可教会模型保持将推理与解答分开的一致结构。
2. 网格架构奖励
为了让我们读懂数独的解答,必须以特定的网格格式呈现它。该奖励函数的作用便是评估模型维持正确网格结构的能力:

该函数会将网格格式分解为多个部分 —— 正确的行数、正确的分隔符位置、适当使用分隔符。模型每个方面正确了都会获得一些奖励。这种细粒度的方法有助于模型学习数独网格的特定空间结构。
3. 解答准确度奖励
当然,最终目标是让模型正确解答数独。这里使用了两个奖励函数来评估解答的准确度:

第一个函数 (exact_answer_reward_func) 会为完全正确的解答提供大奖励 (5.0),从而为模型提供正确解答数独的强大动力。
第二个函数 (simple_robust_partial_reward_function) 会更微妙一些,会为部分正确的解答提供部分 credit。它有两个关键特性:
- 严格强制模型保留原始线索(如果任何线索发生变化,则给予零奖励);
- 对于模型正确填充的每个空单元格,都按比例给予奖励。
这种部分奖励对于学习至关重要,因为它能为模型在训练期间提供更平滑的梯度。
4. 规则合规奖励
最后,数独解答必须遵守游戏规则 —— 任何行、列或 3×3 框中都没有重复数字:

该函数会检查每行、每列和每 3×3 框是否有重复项,模型满足每个约束时都能获得一些奖励。这能让模型学会数独的基本规则,鼓励它生成有效的解答,即使它们与预期答案不完全匹配。
出人意料的结果:尺寸很重要
实际训练结果揭示了一些有趣的事情:模型大小对学习稳定性和性能具有巨大的影响。
7B 模型(使用了秩为 16 的 LoRA)结果优良:
- 保持了稳定的完成长度,约为 1000 token
- 能生成格式一致的解答
- 奖励指标稳步提升
- 在整个训练过程中保持了策略稳定性
与之形成鲜明对比的是,3B 模型(使用了秩为 32 的 LoRA )表现不佳:
- 训练期间出现灾难性的不稳定性
- 出现巨大的策略分歧(KL 飙升至 80!)
- 未能保持一致的性能
- 最终崩溃,无法恢复
图表清楚地说明了这一点:7B 模型(粉色线)保持了稳定的性能,而 3B 模型(绿色线)则出现了剧烈波动,并且最终完全失败。
训练和测试的完成长度情况:

训练和测试的净奖励:

答案格式奖励:

最重要的:最终答案奖励(模型生成完全正确的响应网格并完全匹配):

对于 7B 模型,精确答案奖励增长意味着模型能给出完全匹配的答案,但 3B 则出现崩溃情况。这证明 7B 模型学会了用很少的数据解决数独问题,并且学习速度很快!
部分奖励:

我们得到的启发
这个实验揭示了关于复杂推理任务的语言模型教学的几个重要启示:
1、Deepseek R1 论文中提到,在没有冷启动数据的情况下,复杂推理存在一个最小规模阈值。
有些任务需要一定的模型能力才能稳定学习。3B 模型的失败表明,数独解题可能就是这样一种任务。
2、稳定是学习的前提
在模型学会正确解题之前,它需要保持稳定的训练动态。7B 模型始终如一的指标使其能够取得稳步进展。
3、多成分奖励提供更好的指导
与单一的通过 / 失败信号相比,将奖励细分为格式合规性、规则遵守性和解题准确性有助于更有效地指导学习过程。
4、强化学习可以教授结构化思维
尽管困难重重,GRPO 还是成功地教会了 7B 模型保持正确的格式并开始解题,这些技能并不是语言模型所固有的。
下一步:扩大实验范围
这在很大程度上是一个持续进行的项目,计划下一步采取几个步骤:
- 增加难度:引入更具挑战性的谜题来测试模型的推理能力
- 扩大计算规模:使用更多计算资源,进行更长时间和更大批次的训练
- 探索模型架构:测试 7B 模型的 LoRA rank 32,看更高的 rank 是否能提高性能
- 蒸馏法:从 DeepSeek R1 等大型模型中提炼出冷启动数据集,然后在此基础上应用 GRPO
- 高级奖励函数:实施我已经设计好但尚未在训练中部署的更细致入微的奖励机制
- 评估框架:开发更复杂的评估指标,以评估推理质量,而不仅仅是解决方案的准确性
增强的奖励函数的重要性
我未来工作中最重要的一个方面就是实现我已经设计好的更复杂的奖励函数。目前的简单奖励函数是有效的,但增强版包含了几项关键改进,可以显著提高学习效率。
以下是我设计的增强奖励函数,但尚未在训练中实施:

这些奖励函数背后的思维过程
我的奖励函数设计理念围绕几个关键原则:
- 渐进式奖励优于二元反馈:我不会简单地将答案标记为正确或错误,而是为部分解答提供部分奖励。这能创造一个更平滑的学习梯度,有助于模型渐进式改进。
- 难度感知型扩展:这些增强过的函数会将问题难度作为一个乘数,这能为解决更难的问题提供更高的奖励。这能鼓励模型解决更难的问题,而不仅仅是优化简单的问题。
- 严格的线索保存:所有奖励函数都执行了一条不可协商的规则,即必须保留原始问题线索。这可以防止模型通过更改问题本身来「作弊」。
- 额外奖励阈值:这些经过增强的函数包括当模型超过某些性能阈值(75%、85%、95% 正确)时的额外奖励。当模型走上正轨时,这些作为激励里程碑,可以加速学习。
- 最低奖励底线(我最关注的一点):即使是部分正确的解答也会获得较小的最低奖励(0.05),确保模型即使进展很小,也能获得一些反馈。
当前的简单函数侧重于最关键的方面(线索保存和部分 credit),而这里增强后的版本则通过难度调整和渐进奖励增加了复杂性。在未来的训练中,我计划实现这些更微妙的奖励函数,看看它们能否进一步提高学习效率和解答质量。
我设计奖励函数的关键见解是:基于过程的奖励(奖励旅程,而不仅仅是目的)对于模型学习复杂的推理任务至关重要。通过提供中间步骤和部分解答的反馈,可创建一个比二元成功 / 失败信号更有效的学习环境。
这很重要,并且不仅是数独
让语言模型学会玩数独不仅仅是为了解谜娱乐,还为了开发能够完成以下任务的 AI 系统:
- 遵从结构化流程
- 逐步应用逻辑推理
- 保持格式一致性
- 根据已知规则验证自己的成果
- 理解空间关系
这些功能的应用场景远不止于游戏:
- 编程:教模型编写遵循严格语法和逻辑约束的代码
- 数学问题求解:实现复杂数学问题的分步解答
- 科学推理:帮助模型理解和应用科学方法和原理
- 形式验证:训练模型根据既定规则检查自己的成果
总结:未尽的旅程
这个实验只是我通过强化学习让语言模型学习结构化推理的探索的开始。虽然 7B 模型的初步结果很有希望,但仍有许多需要学习和改进的地方。
3B 和 7B 模型性能之间的明显差异凸显了一个重要的教训:对于某些任务,要实现稳定学习,对基础模型有最低的尺寸要求。随着我继续使用更多数据、更好的奖励函数和更大的模型来改进方法,我期望看到更出色的结果。
随着新发现的出现,我将定期更新这个项目。教机器逻辑思考和解决结构化问题的旅程充满挑战但又令人着迷 —— 我很期待其未来走向。
#12万级标配激光雷达
零跑把高阶智驾做到了极致
12.98 万元标配激光雷达 + 端到端智驾,通义千问 + DeepSeek 双模型智能座舱。
进入 2025 年,「智能化」成为了各家车企的主要竞争方向,不论是高阶智能驾驶还是 AI 智能座舱,都呈现出全面铺开、价格下调的趋势。
昨天,有智能电动车普惠者之称的零跑,又为行业立下了新的标杆。
3 月 10 日,零跑在杭州宣布旗下全新 B 系列首款全球化车型 —— 零跑 B10 正式开启预售, 预售价仅为 10.98-13.98 万元。零跑还展示了自研的 LEAP3.5 技术架构。
这只是预售价格。零跑表示,人们还可以持续保持关注。
此前在 2024 巴黎车展上首秀时,零跑 B10 就已经引发了人们的关注。昨天的发布会上零跑公布了更多配置细节:这款车搭载了高通最新旗舰智驾芯片 SA8650,算力等效达到 200TOPS,搭载的激光雷达为禾赛科技的最新型号。
作为同级唯一搭载激光雷达的车型,B10 在智能驾驶领域展现了出绝对优势。据官方介绍,发布会结束的 1 小时内,B10 的订单就突破了 1.5 万台,其中有 70% 的人都选择了激光雷达智驾版车型。
零跑表示,B10 的硬件储备可以对标 50 万元级豪华车型,基于端到端大模型智驾支持高速、城区通勤智能领航辅助等高阶功能,未来可通过 OTA 持续升级,且所有智驾系统的升级都全部免费。
零跑 B10 激光雷达版本的车型上将搭载高速智能领航辅助 NAP、城区通勤智能领航辅助 CNAP 等能力。在一次学习识别你的通勤路线之后,上下班的行程就可以完全交给 B10 来完成了。
在部分媒体的试驾体验过程中可以观察到,零跑 B10 的智能驾驶在城市道路行驶中可以实现全程零接管、无违章,很多场景开起来就像一个老司机。
相较于部分纯视觉智能驾驶方案,加入激光雷达的端到端智能驾驶从原理上看更加安全 —— 激光雷达的视野超越人眼,可以在雨天、大雾等极端天气条件下获取更多信息,大幅提升系统的稳定性。
在智能座舱方面,B10 搭载了行业顶尖的高通 8295 芯片,配合 Leapmotor OS 4.0 Plus 交互系统和 AI 语音大模型,为用户带来了极致的智能交互体验。零跑的智能车机允许用户自由选择通义千问和 DeepSeek 大模型,人们向语音助手询问,可以获得立刻的解答,大幅提升了互动的效率。
零跑 B10 在 15 万以内的价格上,做到了智能驾驶和智能座舱的技术领先,这背后是其智驾体系上感知、算法、执行全链路全自研的闭环。
零跑科技创始人、董事长兼 CEO 朱江明表示,目前零跑智驾团队仅算法部分就已有 500 余人,已有足够的规模和能力向智驾技术第一梯队发起冲击,「我们自去年起,只用五六个月时间就构建起了端到端的智能驾驶系统。在 B10 产品交付后,我们希望在第三季度推送城市 NOA,明年实现车位到车位的点对点智能驾驶。」
零跑今年发布的 LEAP 3.5 技术架构是其十年全域自研积累的最新成果,在去年 LEAP3.0 技术架构基础上,实现了软硬件的超级集成和超级智能。
该架构在控制体系集成、AI 交互智能座舱、高阶智驾技术、安全架构、电驱系统、底盘一体化等方面均展现出了行业的最高水平。

基于一系列新技术,零跑 B10 搭载的自研 LMC 一体化运动融合控制技术能够在高速爆胎、湿滑路面等极端情况下保持车身稳定,提升驾驶安全性。
「前两天其他车企在百万级豪车上实现的主动稳定控制能力,零跑在 15 万级的车辆上也实现了,」朱江明表示。「零跑真正实现了科技平权,这样的能力将会标配在零跑未来的所有车型上。」
除此之外,零跑 B10 的设计和其他配置也很吸引人。
这款车的长宽高分别为 4515/1885/1655 毫米,轴距 2735 毫米,属于小型 SUV 范畴。
基础配置上,B10 全系标配后置单电机,分为 132kW 和 160kW 两个版本。电池容量为 56.2kWh,CLTC 工况续航里程为 510 公里 / 600 公里,最快支持 19 分钟 30%-80% 的快充能力。B10 搭载了七合一油冷电驱总成,百公里加速时间为 6.8 秒,配合 50:50 前后轴荷比和前窄后宽胎设计,可为用户带来灵动且精准的驾驶体验。
B10 标配了 14.6 英寸 2.5K 高清中控屏、Leap Sound 12 扬声器等配置,副驾空间还支持 DIY 拓展,用户可以根据自己的需求,通过「魔术拓展坞」自由搭配折叠桌板、手机支架等配件,打造出个性化的多功能空间。
目前,零跑 B10 的实车已经在全国门店就位,人们可以通过零跑官方 APP、小程序及官网支付 99 元预订金预订,新车将于 4 月正式上市并启动大规模交付。
昨日,零跑也发布了 2024 年业绩报告。2024 年零跑在全球共交付 29.4 万台车,数量翻倍,位列全球 11 位,成为了全球第三家(仅次于特斯拉、理想)实现盈利的造车新势力。与此同时,零跑也与 Stellantis、中国一汽达成了战略合作,未来会共同开发新能源车型与零部件。
#GaussianAnything
原生3D+流匹配,现有SOTA被GaussianAnything超越
兰宇时,MMLab@NTU博士生,导师为 Chen Change Loy。本科毕业于北京邮电大学,目前主要研究兴趣为基于神经渲染的 3D 生成模型、3D 重建与编辑。
尽管 3D 内容生成技术取得了显著进展,现有方法仍在输入格式、潜空间设计和输出表示上面临挑战。
在 ICLR 2025 中,来自南洋理工大学 S-Lab、上海 AI Lab、北京大学以及香港大学的研究者提出的基于 Flow Matching 技术的全新 3D 生成框架 GaussianAnything,针对现有问题引入了一种交互式的点云结构化潜空间,实现了可扩展的、高质量的 3D 生成,并支持几何-纹理解耦生成与可控编辑能力。
该方法在 Objaverse 数据集上进行了大规模训练,并在文本、图像、点云引导的 3D 生成任务中超越了现有的原生 3D 生成方法。
目前,项目所有模型和测试/训练代码均已全面开源至 Github/Huggingface, 并支持多卡、自动混合精度 (AMP) 训练、flash-attention 以及 BF16 等加速技巧。
- 论文项目主页: https://nirvanalan.github.io/projects/GA/
- 论文代码: https://github.com/NIRVANALAN/GaussianAnything
- Gradio demo 地址: https://huggingface.co/spaces/yslan/GaussianAnything-AIGC3D
- 个人主页: https://nirvanalan.github.io/
- 论文标题:GaussianAnything: Interactive Point Cloud Latent Diffusion for 3D Generation

研究背景
近年来,以可微渲染和生成模型为核心的神经渲染技术 (Neural Rendering) 取得了快速的进展,在新视角合成、3D 物体生成和编辑上取得了令人满意的效果。在统一图片/视频生成的 LDM 框架的基础上,近期关于原生 (native) 3D diffusion model 的研究也展现了更优的泛化性,更快的生成速度与更好的可编辑性。
然而,一些关于原生 3D diffusion 模型的设计挑战仍然存在: (1) 3D VAE 输入格式,(2) 3D 隐空间结构设计,(3) 3D 输出表征选择。
为了解决上述问题,研究者提出基于 Flow Matching 的可控点云结构化隐空间 3D 生成模型 GaussianAnything,支持多模态可控的高效、高质量的 3D 资产生成。
方法
方法概览图 (3D VAE 部分):

研究者提出的 3D-aware flow matching 模型主要包含以下三个部分:
- 利用编码器 (3D VAE Encoder) 将 3D 物体的 RGB-D (epth)-N (ormal) 多视图渲染图压缩到点云结构的 3D 隐空间。
- 在 3D 隐空间中训练几何 + 纹理的级联流匹配模型 (Flow Matching model), 支持图片、文字、和稀疏点云引导的 3D 物体生成。
- 使用 3D VAE Decoder 上采样生成的点云隐变量,并解码为稠密的表面高斯 (Surfel Gaussian)。
Point-cloud structured 3D VAE
结构化的高效、高质量 3D 压缩
高效的 3D 物体编码
首先,和图片/视频 LDM 模型类似,3D 隐空间生成模型也同样需要与之适配的 3D VAE 模型,且该模型的效果决定了 3D 生成模型的上限。因此,研究者采取了以下设计来提升原生 3D VAE 的性能:
在 3D 编码器端,相较于目前普遍使用的基于稠密点云 (dense point cloud) 的方法 (CLAY [1], Craftsman [2]), 研究者选择使用多视图 RGB-D (epth)-N (ormal) 渲染图来作为输入 3D 物体的等效表达,并联合 Plucker 相机编码一起共 15 维信息

作为多视图编码器的输入。
为了更好地编码多视图输入,相较于直接使用图像/视频领域常见的 U-Net 模型,研究者使用基于 3D-attention 的 Transformer [3] 结构来处理多视图输入

。相较于使用稠密点云作为输入的方法,本文的 3D VAE Encoder 更高效自然地拥有来自多种输入格式的丰富的 3D 信息,并能够同时压缩颜色与几何信息。
基于 3D 点云结构化隐空间表达
虽然上述过程已经将 3D 物体压缩为 multi-view latent

, 本文中研究者认为该隐空间并不适合直接用于 3D diffusion 的训练。首先,

的维度

较高,在高分辨率下训练开销巨大。其次,multi-view latent

并非原生的 3D 表达,无法直观灵活地用于 3D 编辑任务.
为了解决上述缺陷,研究者提出在点云结构的 3D 隐空间表达进行 3D diffusion 的学习。具体地,他们使用 Cross Attention 操作

将特征

投影到从输入物体表面采样得到的稀疏的 3D 点云 上。最终的点云结构化隐变量

被用于 diffusion 生成模型的训练。
高质量 3D 高斯上采样/解码
在得到点云结构化隐变量后,研究者首先使用 3D Transformer 结构对其进一步解码

,得到深层次特征。
在此基础上,他们通过 K 个上采样模块将低分辨率点云逐步上采样至高分辨率高斯点云,其中每一个模块都由 transformer 实现:

。该设计同时支持不同细节层次 (Level of Details) 的 3D 资产输出,提升了本文方法的实用性。
与此同时,该上采样设计能够有效保证较高的高斯利用率 (98% 以上),而传统多视图方法 (LGM) 由于视角重叠问题仅有 50% 的高斯利用率。
VAE 模型训练
本文的 3D VAE 模型可端到端学习,并同时使用 2D Rendering loss 和几何 loss 共同监督:

其中

为多视图重建损失,

为 VAE KL 约束,

约束物体表面几何,

用于提升 3D 材质真实性。在实验数据上,研究者使用目前最大规模的开源 3D 数据集 Objaverse 来进行 VAE 训练,并公布了 DiT-L/2 尺寸的 VAE 预训练模型供用户使用。
Cascaded 3D Generation with Flow Matching
级联 3D 生成框架

在第二阶段,研究者在训练完成的 3D VAE space 上进行 Flow Matching 训练。在使用文本/单目图像作为输入条件时,他们均使用 Cross Attention 进行条件信息编码并送入 DiT 框架中进行训练。同时分为两个阶段单独学习几何 (稀疏点云) 和纹理 (点云结构的低维特征)。
具体而言,研究者首先训练一个稀疏点云上的 Flow Matching 模型:

在此基础上,研究者将点云输出作为条件信息进一步输出细节纹理特征:

该生成范式有效的支持了几何 - 纹理解耦的生成与编辑。
实验结果
Image-conditioned 3D Generation | 图生 3D
考虑到 3D 内容创作更多采用图片作为参考,本文方法同样支持在给定单目图像条件下实现高质量 3D 生成。相比于多视图生成 + 重建的两阶段方法,本文方案在 3D 生成效果、多样性以及 3D 一致性上有更稳定的表现:
数值结果:

可视化结果:

Text-conditioned 3D Generation | 文生 3D
在大规模 3D 数据集 Objaverse 上,研究者基于 Flow Matching 的 3D 生成模型支持从文本描述直接生成丰富,带有细节纹理的高质量 3D 资产,并支持 textured-mesh 的导出。生成过程仅需数秒即可完成。可视化对比结果如下:

在数值指标上,GaussianAnything 同样优于投稿时最优的原生 text-conditioned 3D 生成方法。

更多内容请参考原论文与项目主页。
Reference
[1] CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets. TOG 2024.
[2] CraftsMan: High-fidelity Mesh Generation with 3D Native Generation and Interactive Geometry Refiner. arXiv 2024.
[3] Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations. CVPR 2022.
#SeedFoley
字节音效生成模型来了,一键生成大片感音效!已上线即梦
在 AIGC 持续突破视频生成边界的当下,音效制作仍是制约行业发展的瓶颈。字节跳动豆包大模型语音团队最新提出的 SeedFoley 模型,通过端到端架构实现了视频音效的智能生成,将 AI 视频创作带入「有声时代」。相关功能「AI 音效」已在即梦上线,用户使用即梦生成视频后,选择「AI 音效」功能,即可生成 3 个专业级音效方案。

App 端

Web 端
效果展示
先「听」为快,这里展示了一些 SeedFoley 生成的视频音效效果。
,时长00:05
,时长00:05
,时长00:05
,时长00:05
技术方案
SeedFoley 是一种端到端的视频音效生成架构,通过融合时空视频特征与扩散生成模型,实现了音效和视频的高度同步。首先,用固定的视频帧率对视频序列进行抽帧提取,然后使用一个视频编码器提取视频的表征信息,并通过多层线形变换将视频表征投射到条件空间,在改进的扩散模型框架中构建音效生成路径。
在训练过程,提取语音和音乐相关标签,作为 multi conditions 的形式输入,可以将音效和非音效进行解耦。SeedFoley 能支持可变长度的视频输入,并且在音效准确性,音效同步性和音效匹配度等指标上都取得了领先水平。

图 1:SeedFoley 的模型架构
视频编码器
SeedFoley 的视频编码器,采用了快慢特征组合的方式,在高帧率上提取帧间的局部运动信息,在低帧率上提取视频的语义信息。通过将快慢特征组合,既保留了运动特征,有效降低计算成本。通过这种方式,能在低计算资源性实现 8fps 的帧级别视频特征提取,实现精细动作定位。最后利用 Transformer 结构融合快慢特征,实现视频的时空特征提取。在提升训练效果和训练效率上,SeedFoley 通过在一个批次中引入多个困难样本,显著提升了语义对齐效果,同时使用了 sigmoid loss 而非 softmax loss,能在更低的资源上实现媲美大批次训练的效果。

图 2:SeedFoley 的视频编码器
音频表征模型
对于扩散模型而言,通常采用 VAE 生成的潜在表征(latent representation)作为音频特征编码。与基于梅尔频谱(mel-spectrum)的 VAE 模型不同,SeedFoley 采用原始波形(raw waveform)作为输入,经过编码后得到 1D 的表征,比传统 mel-VAE 模型在重构和生成建模上更有优势。这里,音频采用了 32k 的采样率,以确保高频信息的保留。每秒钟的音频提取到 32 个音频潜在表征,可以有效提升音频在时序上的分辨率,提升音效的细腻程度。
SeedFoley 的音频表征模型采用了两阶段联合训练策略:在第一阶段使用掩码策略,将音频表征中的相位信息进行剥离,将去相位后的潜在表征作为扩散模型的优化目标;在第二阶段则使用音频解码器从去相位表征中重建相位信息。这个做法可以有效降低扩散模型对表征的预测难度,最终实现音频潜在表征的高质量生成和还原。
扩散模型
SeedFoley 采用 Diffusion Transformer 框架,通过优化概率路径上的连续映射关系,实现了从高斯噪声分布到目标音频表征空间的概率匹配。相较于传统扩散模型依赖马尔可夫链式采样的特性,SeedFoley 通过构建连续变换路径,有效减少推理步数,降低推理成本。
在训练阶段,将视频特征与音频语义标签分别编码为隐空间向量;通过通道维度拼接(Channel-wise Concatenation)将二者与时间编码(Time Embedding)及噪声信号进行混合,形成联合条件输入。该设计通过显式建模跨模态时序相关性,有效提升了音效和视频画面在时序上的一致性以及内容的理解能力。
在推理阶段,通过调整 CFG 系数可调整视觉信息的控制强度以及生成质量之间的关系。通过迭代式优化噪声分布,将噪声逐步转换为目标数据分布。通过将人声以及音乐标签进行强行设定,可以有效避免音效中夹杂人声或者背景音乐的可能性,提升音效的清晰度和质感。最后将音频表征输入到音频解码中,得到音效音频。
结语
SeedFoley 实现了视频内容与音频生成的深度融合,能够精确提取视频帧级视觉信息,通过分析多帧画面信息,精准识别视频中的发声主体及动作场景。无论是节奏感强烈的音乐瞬间,还是电影中的紧张情节,都能精准卡点,营造出身临其境的逼真体验;另外,SeedFoley 可智能区分动作音效和环境音效,显著提升视频的叙事张力和情感传递效率。
「AI 音效」功能已上线即梦,用户使用即梦生成视频后,选择「AI 音效」功能,即可生成 3 个专业级音效方案。在 AI 视频,生活 Vlog、短片制作和游戏制作等高频场景中,能有效摆脱 AI 视频的「无声尴尬」,便捷地制作出配有专业音效的高质量视频。
团队介绍
豆包大模型语音团队的使命是利用多模态语音技术丰富交互和创作方式。团队专注于语音和音频、音乐、自然语言理解和多模态深度学习等领域的前沿研究和产品创新。
#机器人接手所有家务
李飞飞团队「具身智能」最新研究
李飞飞「具身智能」又出新研究了。
「机器人学习领域中的一个『圣杯』级挑战是执行通用的日常家庭移动操作任务。借助一款新型双臂移动机器人,我们的最新成果 ——BEHAVIOR Robot Suite(简称 BRS)正在尝试攻克这一极为困难且尚未解决的难题!」

,时长01:09
在日常生活中,你有没有想过这样一个问题,即机器人究竟需要具备哪些能力才能真正帮助人类完成家务任务?BRS 就是为了解决这项任务而诞生的 —— 简单来讲,BRS 就是一个综合性框架,用于掌握机器人多样化家庭任务中移动全身操作。无论是倒垃圾、摆放衣物还是清洁马桶,BRS 都能让机器人应对这些日常实用活动。
例如,基于 BRS 的机器人可以帮助用户捡垃圾:

将扔在地上的物体重新放在架子上:

还能帮你清洁马桶,看起来是一个任劳任怨的机器人:

Party 过后帮你收拾桌子:

还能帮你去衣柜拿衣服:

这么全能的机器人是如何实现的呢?我们接着往下看。
方法介绍

论文主页:https://behavior-robot-suite.github.io/
机器人需要具备哪些关键能力才能有效执行日常家务?
通过分析,研究团队确定了成功执行这些任务所必需的三项全身控制能力:双手协调、稳定精确的导航以及广泛的末端执行器可达性。
例如,搬运大型重物需要双手操作,而在房屋中检索工具则依赖于稳定精确的导航。复杂任务 —— 如一边拿着杂货一边开门,需要协调运用这两种能力。此外,日常物品分布在不同位置和高度,这要求机器人能够相应地调整其触及范围。

经过精心设计的机器人硬件,配备双臂、移动底座和灵活躯干,是实现全身操作的关键。
然而,这类复杂设计给策略学习方法带来了重大挑战,尤其是在数据采集规模化和全身协调动作方面。
为应对这些挑战,研究团队推出了 BRS,旨在通过全身操作技术解决各种真实家庭任务。
BRS 有两项关键创新,两者协同解决机器人硬件和学习方面的挑战。
JoyLo(Joy-Con on Low-Cost Kinematic-Twin Arms);
WB-VIMA(Whole-Body VisuoMotor Attention)。

JoyLo
,时长01:01
为实现对高自由度移动机械臂的流畅控制,同时便于为后续策略学习收集数据,研究团队推出了 JoyLo —— 一种构建经济实惠的全身远程操作界面的通用框架。

研究团队在 R1 机器人上实现了 JoyLo,设计目标如下:
- 高效的全身协调控制系统,实现复杂动作的流畅衔接;
- 丰富的用户反馈机制,带来直观的远程操作体验;
- 确保高质量的示范动作,提升策略学习效果;
- 低成本实现方案,大幅提高系统可及性;
- 实时、便捷的控制器设计,确保操作无缝顺畅。
项目还提到,JoyLo 的成本总共不到 500 美元,团队还贡献了物料清单和组装说明。
- 物料清单地址:https://behavior-robot-suite.github.io/docs/sections/joylo/overview.html#bill-of-materials-bom
- 组装说明:https://behavior-robot-suite.github.io/docs/sections/joylo/step_by_step_assembly_guidance.html
WB-VIMA 策略
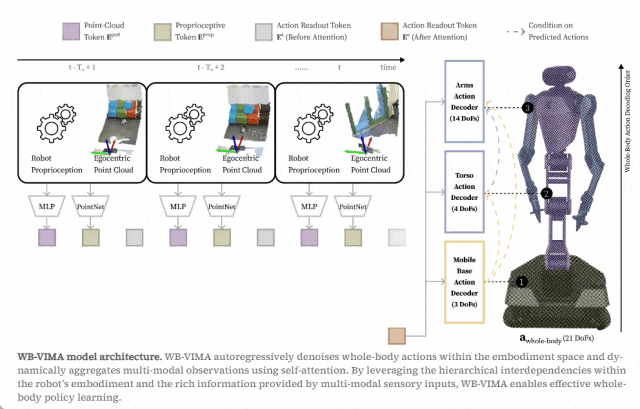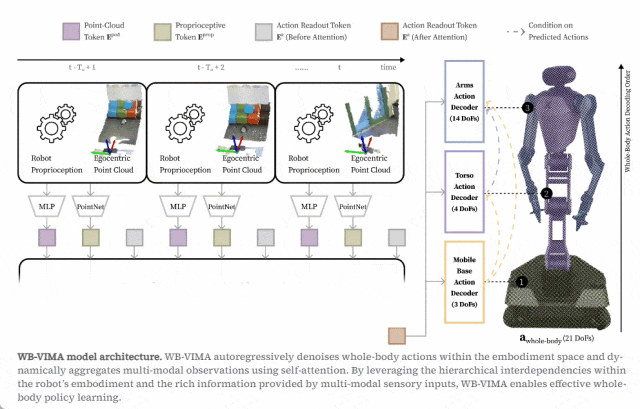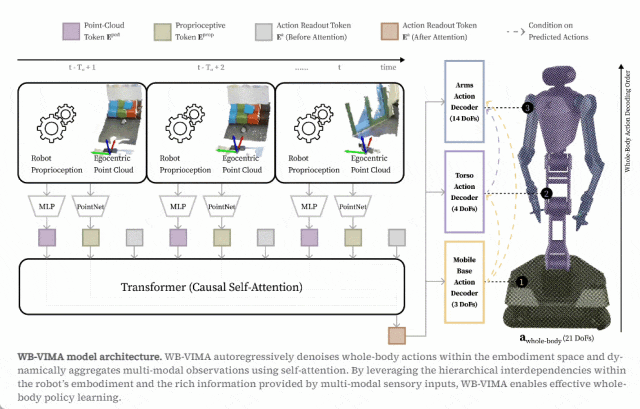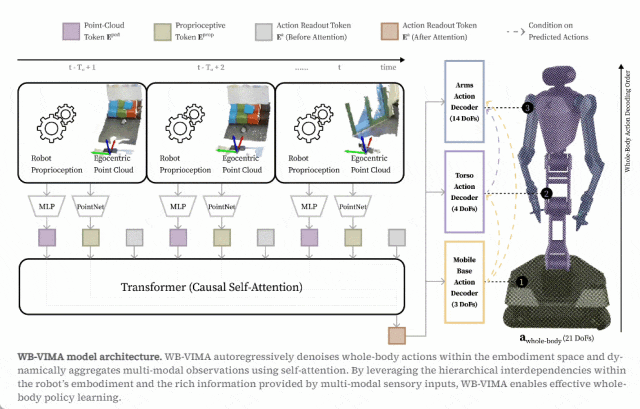
WB-VIMA 是一种模仿学习算法,旨在通过利用机器人的固有运动学层次结构来建模全身动作。
WB-VIMA 的一个关键见解是,机器人关节之间存在强烈的相互依赖关系 —— 上游链接(例如躯干)的小幅移动可能会导致下游链接(例如末端执行器)的大幅位移。为了确保所有关节之间的精确协调,WB-VIMA 将下游组件的动作预测条件化于上游组件的预测,从而实现更同步的全身运动。
此外,WB-VIMA 通过自注意力动态聚合多模态观察,使其能够学习表现力强的策略,同时减轻对本体感知输入的过拟合。
实验
实验探讨了以下问题:
- Q1:BRS 支持哪些类型的家庭任务?
- Q2:JoyLo 与其他方法相比表现如何?
- Q3:WB-VIMA 是否优于基线方法?
- Q4:哪些组件促成了 WB-VIMA 的有效性?
对于问题 1:BRS 适用于各种家庭任务,比如扔垃圾:
机器人先是导航到客厅中的垃圾袋旁边,将其捡起(子任务 1),然后将垃圾携带到一扇关闭的门前(子任务 2),打开门(子任务 3),移动到室外,并将垃圾袋放入垃圾桶(子任务 4)。
,时长00:48
又比如,机器人打扫餐桌。机器人从客厅出发,导航到厨房的洗碗机(子任务 1)并打开洗碗机(子任务 2)。然后,它移动到游戏桌(子任务 3)收集碗(子任务 4)。最后,机器人返回洗碗机(子任务 5),将碗放入洗碗机内并关闭洗碗机(子任务 6)。稳定且精确的导航是完成这一任务的最关键能力。
,时长01:06
对于问题 2:JoyLo 能够为策略学习提供高质量的数据
研究团队对 10 名参与者进行了全面的用户研究,以评估 JoyLo 的效果及其收集数据对策略学习的适用性。下图为将 JoyLo 与 VR 控制器和 Apple Vision Pro 进行比较。

效率优势:
- JoyLo 整体任务成功率是 VR 控制器的 5 倍(Apple Vision Pro 无人完成全任务);
- 中位完成时间较 VR 控制器缩短 23%;
- 在铰接物体操作等精细任务中表现突出。

用户研究结果(10 名参与者)。
用户体验:
- 所有参与者最终评价 JoyLo 为最友好交互;
- 70% 用户最初认为 IK 更直观,但实操后偏好逆转;
- 用户反馈 IK 方法在移动底座 / 躯干控制上存在显著困难。

用户研究参与者的人口统计数据和调查结果。
对于问题 3:WB-VIMA 始终优于基线方法
实验显示,WB-VIMA 在所有任务中全面超越基准方法:端到端任务成功率比 DP3 高 13 倍,比 RGB-DP 高 21 倍;平均子任务表现分别优于 DP3(1.6 倍)和 RGB-DP(3.4 倍)。

五项代表性家庭活动的成功率。「ET」表示整个任务,「ST」表示子任务。

评估期间的安全违规情况。WB-VIMA 与环境物体的碰撞极少,且几乎不会因施加过度力量而导致电机失去动力。
对于问题 4:WB-VIMA 组件对任务性能的影响
研究团队针对 WB-VIMA 展开消融实验,分别移除自回归全身动作去噪和多模态观察注意力机制模块。实验表明,任一组件缺失均导致性能显著下降:在「将物品放上架子」及「整理衣物」任务的「打开衣柜」子任务中,移除自回归去噪模块使成功率骤降 53%;而多模态注意力机制缺失则全面削弱各任务表现。

「放置物品到架子上」和「铺展衣物」任务的消融实验结果。
最后,研究团队还展示了几个失败案例。包括:
1) 尽管机器人已经抓住把手,但未能完全打开洗碗机;
2) 未能按下冲水按钮;
3) 未能从地板上拾起垃圾袋;
4) 未能抬起地上的箱子;
5) 未能关闭衣柜门。

#1000 token/s的「扩散LLM」凭什么倒逼AI走出舒适区?
在 NVIDIA H100 GPU 实现高达 1000 tokens/秒的输出速度。
ChatGPT 平地一声雷,打乱了很多人、很多行业的轨迹和节奏。这两年模型发布的数量更是数不胜数,其中文本大模型就占据了 AIGC 赛道的半壁江山。关注我的家人们永远都是抢占 AI 高地的冲锋者。
所以,今天我准备用一个小调查开头——
【当前你对大模型最不满的点是什么?】
(我尽可能整理的全一点儿,但也不可避免地会有遗漏,家人们可以在评论区讨论 ~)
- 逻辑混乱的"幻觉式回答"
- 上下文理解和长对话记忆能力有限 or 过度记忆(混入了之前出现的不相关的内容)
- 知识库更新滞后
- 生成速度影响交互流畅度
- 指令跟随的精确度不够高
- 在特定专业领域的回答深度不够
- 缺乏创意,创造性、想象力不够
- 道德护栏过严(拒绝合理请求)
- 价值观/偏见:产生一些带有偏见或不符合伦理道德的回答
- 个性化缺失(回答太“通用”,不够贴合个人需求)
- 多模态输出粗糙(图文/视频生成不达标)
- 数据隐私问题
幻觉、知识滞后是一个老生常谈的话题,现在模型基本上都已经具备 RAG 联网能力,或者通过人类反馈强化学习(RLHF)优化生成逻辑来缓解;为了让模型多记住点东西,增大上下文长度也是这两年各大厂商卷的方向,硬是被谷歌卷到了 2M 的天花板。
关于「在特定专业领域的回答深度不够」,现在特别火的 Manus 虽然它想做成通用型 Agent,但我觉得也能解决一部分专业度问题,像秘塔的研究模式、Deep Research、百度的深度搜索,有不少解决方案都在做了。
这里我想提一下第 4 点——
「生成速度」
因为这两天对这个感触比较深。
先是看到群里有小伙伴吐槽阿里千问的新推理模型 QwQ-32B 的速度,我也深有体会,等半天没有结果,心急火燎的。所以我干脆本地部署了一个(看上次的推文);
然后是 Manus,虽然视频 demo 里面,处理速度快到飞起。但是现实总是有骨感的。
不少拿到邀请码的朋友和我吐槽“1 小时才做一半”,速度慢到怀疑人生,一个任务动辄需要几十分钟。
虽然知道它是一个级联、多模块调度的复杂系统,但是也能真实的反映当下现在 AI 的响应速度,有时候真的跟不上我们心里的速度了。
尤其在高峰期或复杂任务中,等待时间,简直让人抓狂。
这种心急如焚的等待,经历过的都懂!
正好这两天看到 family 群里小伙伴在讨论——Mercury Coder
是一个扩散语言模型,2 月底才出来,生成速度快到要起飞,直接秒杀现在所有的大模型。
当时并没有多少人关注它,但是怎么逃得过我这个老技术人的嗅觉。
先感受下它的速度,这是我在官网跑的一个 case(无加速版):
官网地址:
,时长00:07
除了 first token 之前有 3、4 秒的等待,中间几乎是一口气儿 print 出来的。
再看个和 Claude、chatgpt 的对比视频——
,时长00:22
Mercury 最先出结果,全程只用了 6 秒,Claude 用了 28 秒生成完毕,chatgpt 则用了 36 秒。
生成速度整整快了 5-6 倍。
来自官方的一组更直观的数字——
“在 NVIDIA H100 GPU 实现高达 1000 tokens/秒的输出速度,在此之前只能在定制芯片能够实现这个速度。 ”
而且,不是通过定制芯片、框架适配、加速计算库这些硬件和工程化手段做到的,而且引入了一种全新的语言模型——
扩散语言模型,diffusion LLM,简称成 dLLM。
扩散模型,听过,语言模型,也听过。两个都不陌生。
那扩散 + 语言模型,听过吗?大部分人到这里可能还没意识到事情的严重性。
这个新结合体,极有可能会终结掉现在所有的大模型。
Deepseek 封了 ChatGPT 的成神之路,diffusion LLM,未来可能封了 Transformer 的进化之路。
理解这个之前,你得先知道,现在绝大部分主流 LLM 都是基于 Transformer 架构。
AI 模型的演进史,从 ngram 到 RNN,再到 LSTM,最后到 Transformer,每一代都是以「前一代」的局限性为靶心。
ngram → RNN:解决了上下文长度限制。
和我一样学过宗成庆老师的《自然语言处理》的一定知道,ngram 是统计语言模型的奠基者。
RNN → LSTM:解决了梯度爆炸/消失问题。
我刚工作那会儿还在大学特学卷积神经网络和 LSTM 呢,天天研究卷积的复杂度是咋算的、输入门、遗忘门是怎么控制的数据的。
LSTM → Transformer:解决了并行化问题。
Transformer → ???
diffusion LLM 可能就是这里的???。
你看这个图——
在其他模型的输出速度只有百级别的时候,Mercury 实测速度已突破每秒 1000 Token 大关。
而且,性能表现可以与 GPT-4o-mini 和 Claude 3.5 Haiku 这种各家兼顾效果和速度的模型相提并论。
自回归与扩散之争
目前为止,你们见到的大部分大语言模型,在核心建模方法上都大同小异,都是“自回归”式的。简单理解——
从左到右,依次预测下一个词(token)。
就像写作文,从第一个字开始,根据上下文逐字逐句地写下去,就跟挤牙膏一样。
缺点就是速度慢,因为必须一个字一个字地生成。
更重要的是,生成每个 token 都需经过一次对神经网络的正向计算(推理),带来了巨大的计算负担。
而大多数图像和视频生成 AI 都是用扩散模型,而不是自回归模型。举个恰当的例子:
就像雕塑,先有一块粗糙的石头,逐步去除多余部分,最终呈现出精美的雕像。
优点是并行生成: 理论上可以一次性生成所有 token,速度更快。
比如 DALL-E 2、Stable Diffusion、Sora 都是扩散的代表。
所以你好不好奇,为什么文本生成偏爱自回归,而图像/视频生成偏爱扩散模型?
这背后原因很复杂,涉及到信息和噪声在不同领域的分布,以及我们人类对它们的感知。
- 文本是离散的 token 序列,每个词汇的选择都强烈依赖于前面的上下文。自回归模型(如 Transformer)天然地契合了文本的序列依赖性。
- 图像和视频是由连续的像素值组成的,扩散模型最初是为连续数据设计的。
扩散模型的核心在于模拟两个互逆的过程完成“由混沌至有序” 的生成策略:
- 前向扩散,如同逐渐向清晰照片注入噪声,使其最终变为完全随机的噪点。
- 反向扩散 则相反,模型学习从纯噪声中逐步去除噪声,最终还原出清晰图像。 反向扩散过程是扩散模型生成数据的关键。
扩散模型不是从左到右,而是一次性生成(这个“一次性”也是通过逐步去噪实现的)。
从纯噪声开始,逐步去除噪声,最终形成一个 token 序列。
去噪的过程,看这个视频很直观——
,时长00:13
不是一字一字按顺序生成,像随意蹦出来的字符,最后竟然是连贯的。
这是一篇我前段时间刷到过,来自人大高瓴和蚂蚁集团合作的一篇论文 LLaDA。
论文链接:
再看一个例子——
,时长00:17
扩散大语言模型 LLaDA 的核心在于其参数化的模型 𝑝(𝜃)(⋅|𝑥(𝑡))。这个模型接收序列输入,并能同时预测所有被mask的 token (用 M 表示)。 在训练过程中使用交叉熵损失函数,但仅在被掩盖的 token 上计算损失,以优化模型预测掩码 token 的能力, 训练的目标函数如下图所示:
训练完成后,LLaDA 即可用于文本生成。
它通过模拟一个反向扩散过程来实现,这个反向过程由训练好的掩码预测器 𝑝(𝜃) 参数化。 模型的分布被定义为反向过程在时间步 t=0 时所诱导的边缘分布。 这种设计使得 LLaDA 成为一种有原则的生成建模方法。
LLaDA 的架构与目前主流的自回归大语言模型架构相似,仍是基于 Transformer 架构。 然而,LLaDA 并不使用因果掩码。 这是因为 LLaDA 的设计允许模型在进行预测时看到完整的输入序列,而无需像自回归模型那样只能依赖于之前的 token。
回到 Mercury 的性能——
在执行 LLM 推理函数编写任务时,传统自回归模型需迭代 75 次方可完成,而 Mercury Coder 仅需 14 次迭代,速度提升幅度显著:
,时长00:19
在代码补全能力上,Mercury Coder Mini 在 Copilot Arena 基准测试中取得了卓越成绩,位列第二,不仅超越了 GPT-4o Mini 和 Gemini-1.5-Flash 等模型,甚至能与更大型的 GPT-4o 模型相提并论:
Andrej Karpathy 对这个工作都表示了认可和期待。
吴恩达老师也翻牌了,称这是一次很酷的尝试:
团队介绍
Mercury 的研究团队来自一家名为 Inception Labs 的创业公司, 其联合创始人 Stefano Ermon 不仅是扩散模型技术的核心发明人之一,也是 FlashAttention 原始论文的主要作者之一。
Aditya Grover 和 Volodymyr Kuleshov 毕业于斯坦福大学,并分别执教于加州大学洛杉矶分校和康奈尔大学的计算机科学教授,也共同参与了 Inception Labs 的创立。
Mercury 以及 LLaDA 的出现,标志着基于扩散模型的 dLLM 已经崭露头角。
扩散 LLM 如果要封喉 Transformer,还需要在生成速度(并行去噪)、多样性(摆脱自回归的单调性)和可控性(更精准的输出)上全面胜出。
但眼下,它更像是个有潜力的“后浪”。
但是技术演进往往是融合而非完全替代,未来也有可能是两者的融合,例如先用扩散模型生成草稿,再用自回归模型进行润色。
毕竟在这个信息过载的时代,0.5 秒的加载时长就足以让用户流失。
当「生成速度」成为制约创造力的瓶颈,就要倒逼 AI 走出舒适区。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









