







我自己的原文哦~ https://blog.51cto.com/whaosoft/13759961
#exo
电脑平板组AI集群,在家就能跑400B大模型
不用H100,三台苹果电脑就能带动400B大模型。
背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。
利用这个框架,几分钟就能用iPhone、iPad等日常设备构建出自己的AI算力集群。
这个框架名叫exo,不同于其他的分布式推理框架,它采用了p2p的连接方式,将设备接入网络即可自动加入集群。
开发者使用exo框架连接了两台MacBook Pro和一台Mac Studio,运算速度达到了110TFLOPS。
同时这位开发者表示,已经准备好迎接即将到来的Llama3-405B了。
exo官方也放话称,将在第一时间(day 0)提供对Llama3-405B的支持。
而且不只是电脑,exo可以让iPhone、iPad等设备也加入本地算力网络,甚至Apple Watch也同样能够吸纳。
随着版本的迭代,exo框架也不再是苹果限定(起初只支持MLX),有人把安卓手机和4090显卡也拉进了集群。
最快60秒完成配置
与其他分布式推理框架不同,exo不使用master-worker架构,而是点对点(p2p)地将设备进行连接。
只要设备连接到相同的局域网,就可以自动加入exo的算力网络,从而运行模型。
在对模型进行跨设备分割时,exo支持不同的分区策略,默认是环内存加权分区。
这会在环中运行推理,每个设备分别运行多个模型层,具体数量与设备内存成比例。
而且整个过程几乎无需任何手动配置,安装并启动之后系统就会自动连接局域网内运行的设备,未来还会支持蓝牙连接。
在作者的一段视频当中,只用了60秒左右就在两台新的MacBook上完成了配置。
可以看到,在60秒左右时,程序已然开始在后台运行。
另外从上面这张图中还能看出,exo还支持tiny chat图形化界面,同时还有兼容OpenAI的API。
不过,这样的操作只能在集群中的尾节点(tail node)上实现。
目前,exo支持苹果MLX框架和开源机器学习框架tinygrad,对llama.cpp的适配工作也正在进行。
美中不足的是,由于iOS实现更新跟不上Python,导致程序出现很多问题,作者把exo的手机和iPad端进行了暂时下线,如果确实想尝试,可以给作者发邮件索取。
网友:真有那么好用?
这种利用本地设备运行大模型的方式,在HakerNews上也引发了广泛的讨论。
本地化运行的优点,一方面是隐私更有保障,另一方面是模型可以离线访问,同时还支持个性化定制。
也有人指出,利用现有设备搭建集群进行大模型运算,长期的使用成本要低于云端服务。
但针对exo这个具体的项目,也有不少人表达了心中的疑问。
首先有网友指出,现有的旧设备算力水平无法与专业的服务商之间差了数量级,如果是出于好奇玩一玩还可以,但想达到尖端性能,成本与大型平台根本无法比较。
而且还有人表示,作者演示用的设备都是高端硬件,一个32GB内存的Mac设备可能要价超过2000美元,这个价格还不如买两块3090。
他甚至认为,既然涉及到了苹果,那可以说是和“便宜”基本上不怎么沾边了。
这就引出了另一个问题——exo框架都兼容哪些设备?难道只支持苹果吗?
网友的提问则更加直接,开门见山地问支不支持树莓派。
作者回复说,理论上可以,不过还没测试,下一步会进行尝试。
除了设备自身的算力,有人还补充说,网络传输的速度瓶颈,也会限制集群的性能。
对此,框架作者亲自下场进行了解释:
exo当中需要传输的是小型激活向量,而非整个模型权重。
对于Llama-3-8B模型,激活向量约为10KB;Llama-3-70B约为32KB。
本地网络延迟通常很低(<5ms),不会显著影响性能。
作者表示,目前该框架已经支持tinygrad,因此虽然测试主要在Mac设备上展开,(理论上)支持能运行tinygrad的所有设备。
目前该框架仍处于实验阶段,未来的目标是把这个框架变得像Dropbox(一款网盘)一样简单。
BTW,exo官方也列出了一些目前计划解决的缺点,并进行了公开悬赏,解决这些问题的人将获得100-500美元不等的奖金。
GitHub:https://github.com/exo-explore/exo
参考链接:https://x.com/ac_crypto/status/1814912615946330473
#Llama 3.1泄密
首个超越GPT4o级开源模型!Llama 3.1泄密:4050亿参数,下载链接、模型卡都有了
快准备好你的 GPU!
Llama 3.1 终于现身了,不过出处却不是 Meta 官方。
今日,Reddit 上新版 Llama 大模型泄露的消息遭到了疯传,除了基础模型,还包括 8B、70B 和最大参数的 405B 的基准测试结果。
下图为 Llama 3.1 各版本与 OpenAI GPT-4o、Llama 3 8B/70B 的比较结果。可以看到,即使是 70B 的版本,也在多项基准上超过了 GPT-4o。
图源:https://x.com/mattshumer_/status/1815444612414087294
显然,3.1 版本的 8B 和 70B 模型是由 405B 蒸馏得来的,因此相比上一代有着明显的性能提升。
有网友表示,这是首次开源模型超越了 GPT4o 和 Claude Sonnet 3.5 等闭源模型,在多个 benchmark 上达到 SOTA。
与此同时,Llama 3.1 的模型卡流出,细节也泄露了(从模型卡中标注的日期看出基于 7 月 23 日发布)。
有人总结了以下几个亮点:
- 模型使用了公开来源的 15T+ tokens 进行训练,预训练数据截止日期为 2023 年 12 月;
- 微调数据包括公开可用的指令微调数据集(与 Llama 3 不同)和 1500 万个合成样本;
- 模型支持多语言,包括英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。
图源:https://x.com/iScienceLuvr/status/1815519917715730702
虽然泄露的 Github 链接目前 404 了,但有网友给出了下载链接(不过为了安全,建议还是等今晚的官方渠道公布):
不过这毕竟是个千亿级大模型,下载之前请准备好足够的硬盘空间:
以下是 Llama 3.1 模型卡中的重要内容:
模型基本信息
Meta Llama 3.1 多语言大型语言模型 (LLM) 集合是一组经过预训练和指令微调的生成模型,大小分别为 8B、70B 和 405B(文本输入 / 文本输出)。Llama 3.1 指令微调的纯文本模型(8B、70B、405B)针对多语言对话用例进行了优化,在常见的行业基准上优于许多可用的开源和闭源聊天模型。
模型架构:Llama 3.1 是优化了的 Transformer 架构自回归语言模型。微调后的版本使用 SFT 和 RLHF 来对齐可用性与安全偏好。
支持语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
从模型卡信息可以推断,Llama 3.1 系列模型的上下文长度为 128k。所有模型版本都使用分组查询注意力(GQA)来提高推理可扩展性。
预期用途
预期用例。Llama 3.1 旨在用于多语言的商业应用及研究。指令调整的纯文本模型适用于类助理聊天,而预训练模型可以适应各种自然语言生成任务。
Llama 3.1 模型集还支持利用其模型输出来改进其他模型(包括合成数据生成和蒸馏)的能力。Llama 3.1 社区许可协议允许这些用例。
Llama 3.1 在比 8 种受支持语言更广泛的语言集合上进行训练。开发人员可以针对 8 种受支持语言以外的语言对 Llama 3.1 模型进行微调,前提是遵守 Llama 3.1 社区许可协议和可接受使用策略, 并且在这种情况下负责确保以安全和负责任的方式使用其他语言的 Llama 3.1。
软硬件基础设施
首先是训练要素,Llama 3.1 使用自定义训练库、Meta 定制的 GPU 集群和生产基础设施进行预训练,还在生产基础设施上进行了微调、注释和评估。
其次是训练能耗,Llama 3.1 训练在 H100-80GB(TDP 为 700W)类型硬件上累计使用了 39.3 M GPU 小时的计算。这里训练时间是训练每个模型所需的总 GPU 时间,功耗是每个 GPU 设备的峰值功率容量,根据用电效率进行了调整。
训练温室气体排放。Llama 3.1 训练期间基于地域基准的温室气体总排放量预估为 11,390 吨二氧化碳当量。自 2020 年以来,Meta 在全球运营中一直保持净零温室气体排放,并将其 100% 的电力使用与可再生能源相匹配,因此训练期间基于市场基准的温室气体总排放量为 0 吨二氧化碳当量。
用于确定训练能源使用和温室气体排放的方法可以在以下论文中找到。由于 Meta 公开发布了这些模型,因此其他人不需要承担训练能源使用和温室气体排放。
论文地址:https://arxiv.org/pdf/2204.05149
训练数据
概述:Llama 3.1 使用来自公开来源的约 15 万亿个 token 数据进行了预训练。微调数据包括公开可用的指令数据集,以及超过 2500 万个综合生成的示例。
数据新鲜度:预训练数据的截止日期为 2023 年 12 月。
Benchmark 评分
在这一部分,Meta 报告了 Llama 3.1 模型在标注 benchmark 上的评分结果。所有的评估,Meta 都是使用内部的评估库。
安全风险考量
Llama 研究团队致力于为研究界提供宝贵的资源来研究安全微调的稳健性,并为开发人员提供适用于各种应用的安全且强大的现成模型,以减少部署安全人工智能系统的开发人员的工作量。
研究团队采用多方面数据收集方法,将供应商的人工生成数据与合成数据相结合,以减轻潜在的安全风险。研究团队开发了许多基于大型语言模型 (LLM) 的分类器,以深思熟虑地选择高质量的 prompt 和响应,从而增强数据质量控制。
值得一提的是,Llama 3.1 非常重视模型拒绝良性 prompt 以及拒绝语气。研究团队在安全数据策略中引入了边界 prompt 和对抗性 prompt,并修改了安全数据响应以遵循语气指南。
Llama 3.1 模型并非设计为单独部署,而是应作为整个人工智能系统的一部分进行部署,并根据需要提供额外的「安全护栏」。开发人员在构建智能体系统时应部署系统安全措施。
请注意,该版本引入了新功能,包括更长的上下文窗口、多语言输入和输出,以及开发人员与第三方工具的可能集成。使用这些新功能进行构建时,除了需要考虑一般适用于所有生成式人工智能用例的最佳实践外,还需要特别注意以下问题:
工具使用:与标准软件开发一样,开发人员负责将 LLM 与他们所选择的工具和服务集成。他们应为自己的使用案例制定明确的政策,并评估所使用的第三方服务的完整性,以了解使用此功能时的安全和安保限制。
多语言:Lama 3.1 除英语外还支持 7 种语言:法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。Llama 可能可以输出其他语言的文本,但这些文本可能不符合安全性和帮助性性能阈值。
Llama 3.1 的核心价值观是开放、包容和乐于助人。它旨在服务于每个人,并适用于各种使用情况。因此,Llama 3.1 的设计宗旨是让不同背景、经历和观点的人都能使用。Llama 3.1 以用户及其需求为本,没有插入不必要的评判或规范,同时也反映了这样一种认识,即即使在某些情况下看似有问题的内容,在其他情况下也能达到有价值的目的。Llama 3.1 尊重所有用户的尊严和自主权,尤其是尊重为创新和进步提供动力的自由思想和表达价值观。
但 Llama 3.1 是一项新技术,与任何新技术一样,其使用也存在风险。迄今为止进行的测试尚未涵盖也不可能涵盖所有情况。因此,与所有 LLM 一样,Llama 3.1 的潜在输出无法事先预测,在某些情况下,该模型可能会对用户提示做出不准确、有偏差或其他令人反感的反应。因此,在部署 Llama 3.1 模型的任何应用之前,开发人员应针对模型的具体应用进行安全测试和微调。
模型卡来源:https://pastebin.com/9jGkYbXY
参考信息:https://x.com/op7418/status/1815340034717069728
https://x.com/iScienceLuvr/status/1815519917715730702
https://x.com/mattshumer_/status/1815444612414087294
#神经网络也有空间意识
学会在Minecraft创建地图,登上Nature子刊
这是人类首次证明神经网络可以创建自己的地图。
想象一下,你身处一个陌生的小镇,即使一开始周围的环境并不熟悉,你也可以四处探索,并最终在大脑中绘制出一张环境地图,里面包含建筑物、街道、标志等相互之间的位置关系。这种在大脑中构建空间地图的能力是人类更高级认知类型的基础:例如,有理论认为,语言是由大脑中类似地图的结构编码的。
然而, 即使是最先进的人工智能和神经网络,也无法凭空构建这样的地图。
计算生物学助理教授、Heritage Medical 研究所研究员 Matt Thomson 说:「有一种感觉是,即使是最先进的人工智能模型,也不是真正的智能。它们不能像我们一样解决问题;不能证明未经证实的数学结果,也不能产生新的想法。」
「我们认为,这是因为它们无法在概念空间中导航;解决复杂问题就像在概念空间中移动,就像导航一样。人工智能做的更像是死记硬背 —— 你给它一个输入,它给你一个回应。但它无法综合不同的想法。」
最近,Thomson 实验室的一篇新论文发现,神经网络可以使用一种叫做「预测编码」的算法来构建空间地图 。该论文于 7 月 18 日发表在《自然 - 机器智能》(Nature Machine Intelligence)杂志上。
- 论文地址:https://www.nature.com/articles/s42256-024-00863-1
- 代码地址:https://github.com/jgornet/predictive-coding-recovers-maps
在研究生 James Gornet 的带领下,两人在游戏《我的世界》(Minecraft)中构建了环境,将树木、河流和洞穴等复杂元素融入其中。他们录制了玩家随机穿越该区域的视频,并利用视频训练了一个配备预测编码算法的神经网络。
他们发现,神经网络能够学习 Minecraft 世界中的物体彼此之间是如何组织的,并且能够「预测」在空间中移动时会遇到的环境。

预测编码算法与 Minecraft 游戏的结合成功地「教会」了神经网络如何创建空间地图,并随后使用这些空间地图来预测视频的后续帧,结果预测图像与最终图像之间的均方误差仅为 0.094%。
更重要的是,研究小组「打开」了神经网络(相当于检查内部结构),发现各种物体的表征是相对于彼此进行空间存储的。换句话说,他们看到了存储在神经网络中的 Minecraft 环境地图。
神经网络可以导航人类设计者提供给它们的地图,例如使用 GPS 的自动驾驶汽车,但这是人类首次证明神经网络可以创建自己的地图。这种在空间上存储和组织信息的能力最终将帮助神经网络变得更加「聪明」,使它们能够像人类一样解决真正复杂的问题。
这个项目展示了人工智能真正的空间感知能力,而这在 OpenAI 的 Sora 等技术中仍然看不到,后者存在一些奇怪的故障。
James Gornet 是加州理工学院计算与神经系统(CNS)系的学生,该系涵盖神经科学、机器学习、数学、统计学和生物学。
「CNS 项目确实为 James 提供了一个地方,让他从事其他地方不可能完成的独特工作,」Thomson 说。「我们正在采用一种生物启发的机器学习方法,让我们能够在人工神经网络中反向设计大脑的特性,我们希望反过来了解大脑。在加州理工学院,我们有一个非常容易接受这类工作的社区。」
执行预测编码的神经网络
受预测编码推理问题中隐式空间表示的启发,研究者开发了一个预测编码智能体的计算实现,并研究了该智能体在探索虚拟环境时学习到的空间表示。
他们首先使用 Minecraft 中的 Malmo 环境创建了一个环境。物理环境的尺寸为 40 × 65 格单位,囊括了视觉场景的三个方面:一个山洞提供了一个全局视觉地标,一片森林使得视觉场景之间具有相似性,而一条带有桥梁的河流则限制了智能体如何穿越环境(图 1a)。

智能体遵循路径,路径由 A* 搜索确定,以找到随机取样位置之间的最短路径,并接收每条路径上的视觉图像。
为了进行预测编码,作者构建了一个编码器 - 解码器卷积神经网络,编码器采用 ResNet-18 架构,解码器采用转置卷积的 ResNet-18 架构(图 1b)。编码器 - 解码器架构使用 U-Net 架构将编码的潜在单元传递到解码器中。多头注意力处理编码潜在单元序列,以编码过去的视觉观察历史。多头注意力有 h = 8 个头。对于维度为 D = C × H × W 的编码潜在单元,在高度 H、宽度 W 和通道 C 的情况下,单个头部的维度为 d = C × H × W/h。

预测编码器通过最小化实际观测值与预测观测值之间的均方误差来近似预测编码。预测编码器在 82,630 个样本上进行了 200 个 epoch 训练,使用了具有 Nesterov 动量的梯度下降优化,权重衰减为 5 × 10^(-6),学习率为 10^(-1),并通过 OneCycle 学习率调度进行调整。优化后的预测编码器预测图像与实际图像之间的均方误差为 0.094,具有良好的视觉保真度(图 1c)。

参考链接:
https://techxplore.com/news/2024-07-neural-network-minecraft.html
#WE-MATH
真相了!大模型解数学题和人类真不一样:死记硬背、知识欠缺明显,GPT-4o表现最佳
本文作者来自北京邮电大学、腾讯微信、华中科技大学、北京理工大学。作者列表:乔润祺,谭秋纳,董冠霆,伍敏慧,孙冲,宋晓帅,公却卓玛,雷尚霖,卫喆,张淼萱,乔润枫,张一凡,纵晓,徐一达,刁沐熙,包志敏,李琛,张洪刚。其中,共同第一作者乔润祺是北京邮电大学博士生,谭秋纳是北京邮电大学硕士生,通讯作者是北京邮电大学张洪刚副教授,该文章为乔润祺在微信实习期间完成。
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。这种多模态能力使得 LMMs 在各类复杂场景中的应用潜力巨大,而为了严谨科学地检验 AI 是否具备较强的推理能力,数学问答已成为衡量模型推理能力的重要基准。
回顾 AI 的发展历程,我们发现人类的认知和思考问题的方式对 AI 的发展产生了深远的影响。诸如神经网络、注意力机制等突破均与人类的思维模式息息相关。想象一下,人类在解答一个数学问题时,首先需要熟知题目所考察的知识点,而后利用相关知识进行逐步推理从而得出答案。但模型在作答时,其推理过程是否与人类一致呢?
聚焦于数学问题,我们发现模型可以回答出复杂问题,但在一些简单问题面前却捉襟见肘。为探究这一现象的原因,受人类解题思维模式的启发,我们首先对先掌握知识点,再运用其进行逻辑推理的解题过程建模如下:

其中 (X, Y) 和 (x_i, y_i) 分别表示数学问题和每个子问题中的问题与答案,P_reason 代表 LMMs 的综合运用能力 (知识泛化)。基于此,We-Math 首先基于 67 个原子知识点构建了一个多层级树状知识体系,紧接着以原子知识及推理答案为依据,通过将多知识点的复杂问题拆解为多个原子知识点对应的子问题来探究模型的作答机制。
- 题目:WE-MATH: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
- 论文:https://arxiv.org/pdf/2407.01284
- 主页:https://we-math.github.io/
- 代码:https://github.com/We-Math/We-Math
- 数据集:https://huggingface.co/datasets/We-Math/We-Math
目前 We-Math 在当日的 HuggingFace Daily Paper 中排名第一,并在推特上的浏览量达到 10K+!
We-Math Benchmark
1. 数据构成
We-Math 测评数据集共包含 6.5k 个多模态小学数学问题和一个多层级知识架构,每一个数学问题均有对应的知识点(1-3 个)。其中所有问题的知识点均被 5 层 99 个节点(最后一层包含 67 个知识点)的知识架构所涵盖。并且如下图所示,为了缓解模型在解决问题过程中固有的问题,我们参考教材与维基百科,启发式的引入了 67 个知识点的描述,从而为 LMMs 的推理过程提供必要的知识提示。
2. 题目拆解
为了合理的评估模型的作答机制,我们严格以人类作答的标准答案为依据,按照复杂问题所包含的知识点,将其拆解成了 n 个子问题,其中 n 表示复杂问题包含的知识点数量。
如下图所示,对于一道复杂问题:Mary 从一个圆形花坛的最北端点沿花坛边缘走到最东端点,走过的距离是 50.24 米,求解圆形花坛的面积。在解题过程中,首先需要根据 “东南西北方向” 知识点,通过 “最北” 和 “最东” 两个方向的条件,求得 Mary 走过路径所对应的圆心角大小(“最北” 和 “最东” 的夹角为 90 度)。接着,根据 “圆的周长” 知识点,通过圆心角的大小为 90 度和 Mary 走过的路径长度的条件,计算出圆形花坛的周长,并求得圆形花坛的半径。最后,根据 “圆的面积” 知识点,通过求得的半径的条件,计算出圆形花坛的面积,至此完成题目的求解。
分析上述解题过程,为了探究模型的答题机制以及模型的细粒度推理表现,可以将原题按照其对应的知识点拆解成三个子问题,具体而言,第一问:Mary 从一个圆形花坛的最北端点沿花坛边缘走到最东端点,求她走过路径的圆弧所对应的圆心角的度数;第二问:圆形花坛中,90 度圆心角所对应的圆弧弧长为 59.24m,求解圆形花坛的半径;第三问:求半径为 32m 的圆形花坛的面积。
3. 度量标准
在此基础上,如下图所示,我们引入一种新的四维度量标准,即知识掌握不足 (IK)、泛化能力不足 (IG)、完全掌握 (CM) 和死记硬背 (RM)。
- 知识掌握不足 (IK): 模型无法作答出复杂问题,并在子问题中出现错误,我们推测模型无法作答出复杂问题的原因是因为对知识点掌握不足所导致的。
- 泛化能力不足 (IG): 模型无法作答出复杂问题,但是所有的子问题中均回答正确,我们推测模型无法作答出复杂问题的原因是因为缺少综合运用能力(泛化能力)。
- 完全掌握 (CM): 模型可以作答出复杂问题,并且可以作答出所有的子问题,这种现象是合理且被期望得到的。
- 死记硬背 (RM): 模型可以作答出复杂问题,但在子问题中出现错误,这与人类的逻辑思维相悖,如果一个模型可以解决复杂的多步问题,但无法作答出解答过程中所需的单步问题,我们认为这种情况是不合理的,考虑模型存在机械记忆的情况。
其中 IK、IG、CM 之间存在 IK<IG<CM 的层次关系,即模型需要先掌握知识,才可以讨论综合运用的能力,而 RM 我们认为是一种不合理的现象。此外,考虑到模型的不稳定性,当前判定结果是否属于 RM 的标准较为严格。因此,我们提出了一种更灵活的宽松标准。如上图所示,在包含两个知识点的问题中,TFT 和 FTT 情况根据宽松标准(Loose Metric)被视为 CM(而非 RM)。我们在文章的附录中同样讨论了四维度指标在三步问题中的情况。因此,结合上述情况我们最终提出了一个综合打分度量标准,以此评估 LMM 推理过程中的固有问题。
实验与结论
We-Math 目前在 17 个大模型中完成了评测,共包含 4 个闭源模型与 13 个开源模型。其中表 1 与图 6 展示了 LMMs 在不同知识点数量下的结果与模型在第二层级知识点下的表现;表 2 与图 7、图 8、图 9 展示了 LMMs 在四维指标下的结果以及在严格和宽松标准下的综合打分结果;图 10 展示了 KCA 策略对模型在 IK 问题中的缓解结果。
LMMs 在不同知识点数量下的表现及其在第二层级知识点下的表现
- 模型作答情况与题目所包含的知识点数量呈现较明显的负相关关系,即题目包含的知识点越多,模型作答情况越不理想。我们也提议可以通过题目包含的知识点数量对题目的难易度进行建模。
- 模型在与计算相关的知识点下表现较好,在细粒度视觉问题上表现欠佳。也进一步表明 LMMs 在应用公式上较为擅长,但在理解和综合应用知识方面仍有局限。
- GPT-4o 表现最佳,在包含不同知识点数量的题目中均保持领先,并在不同的知识点下基本保持领先。
- LMMs 展现了一定的参数压缩潜力。在不同的 LMMs 中,LLaVA-NeXT-110B 的表现最接近 GPT-4。而令人惊喜的是,尽管参数规模较小,InternVL-Chat-V1.5, GLM-4V-9B, InternLM-XC2 等模型的表现也展现出了较好的表现。
LMMs 在四维指标下的表现及其在严格和宽松标准下的综合评分结果
- 多数模型存在 “知识掌握不足” 和 “死记硬背” 的问题,尤其是在较小的模型中更加明显。并且,“知识掌握不足” 仍是大多数模型的主要问题。
- GPT-4o 在 “死记硬背” 的衡量维度上大幅领先于其他模型,进一步说明 GPT-4o 更贴近于人类的解题方式,其所呈现的结果更加可靠,意味着模型真正的学到了知识,而不是 “死记硬背”。
- GPT-4o 在 “知识掌握不足” 这个衡量维度上大幅领先于其他模型,已经逐渐迈向下一阶段,需要进一步提升 “知识泛化能力”。
LMMs 在 KCA 策略下的表现
- 模型在 KCA 策略下整体表现有所提升。如上图所示,不同参数规模的 LMMs 在引入 KCA 策略后,在严格和宽松指标上均表现出一致的性能提升。
- KCA 策略显著缓解了 IK 问题,但对 IG 问题的改善并不明显。这与人类直觉一致,因为知识描述主要解决的是推理知识的缺口。然而,要解决 IG 问题,需要全面提升 LMMs 的知识泛化能力,这也为未来研究指明了方向。
总结
在本文中,我们提出了 WE-MATH,一个用于细粒度评测 LMMs 在视觉数学推理任务中作答机制的综合基准。WE-MATH 共包含 6.5k 个视觉数学问题,涵盖 5 层 67 个知识点的多级知识架构。我们开创性地根据题目所需的知识点将其拆解为多个子问题,并引入了一种新的四维度指标用于细粒度的推理评估。通过 WE-MATH,我们对现有的 LMMs 在视觉数学推理中的表现进行了全面评估,并揭示了模型作答情况与题目所包含的知识点数量呈现较明显的负相关关系。
此外,我们发现多数模型存在死记硬背的问题 (RM),并且知识掌握不足(IK)是 LMMs 最大的缺陷。然而,GPT-4o 的主要挑战已从 IK 逐渐转向 IG,这表明它是第一个迈向下一个阶段的模型。最后,我们对 KCA 策略和错误案例的分析进一步启发性地引导现有的 LMMs 向人类般的视觉数学推理发展。
#MaskGCT
国产最强语音大模型诞生,MaskGCT宣布开源,声音效果媲美人类
近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。
论文链接:https://arxiv.org/abs/2409.00750
样例展示:https://maskgct.github.io
模型下载:https://huggingface.co/amphion/maskgct
Demo 展示:https://huggingface.co/spaces/amphion/maskgct
项目地址:https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
公测应用:voice.funnycp.com
本文介绍了一种名为 Masked Generative Codec Transformer(MaskGCT)的全非自回归 TTS 模型。
现有大规模文本到语音(TTS)系统通常分为自回归和非自回归系统。自回归系统隐式地建模持续时间,但在鲁棒性和持续时间可控性方面存在一定缺陷。非自回归系统在训练过程中需要显式的文本与语音对齐信息,并预测语言单元(如音素)的持续时间,这可能会影响其自然度。
该模型消除了文本与语音监督之间的显式对齐需求,以及音素级持续时间预测。MaskGCT 是一个两阶段模型:在第一阶段,模型使用文本预测从语音自监督学习(SSL)模型中提取的语义标记;在第二阶段,模型基于这些语义标记预测声学标记。MaskGCT 遵循掩码预测学习范式。在训练过程中,MaskGCT 学习根据给定的条件和提示预测掩码的语义或声学标记。在推理过程中,模型以并行方式生成指定长度的标记。通过对 10 万小时的自然语音进行实验,结果表明 MaskGCT 在质量、相似度和可理解性方面优于当前最先进的零样本 TTS 系统。
一、方法
MaskGCT 模型由四个主要组件组成:
1. 语音语义表示编解码器:将语音转换为语义标记。
2. 语音声学编解码器:从声学标记重建波形。
3. 文本到语义模型:使用文本和提示语义标记预测语义标记。
4. 语义到声学模型:基于语义标记预测声学标记。

语音语义表示编解码器用于将语音转换为离散的语义标记,这些标记通常通过离散化来自语音自监督学习(SSL)模型的特征获得。与以往使用 k-means 方法离散化语义特征相比,这种方法可能导致信息损失,从而影响高质量语音的重建或声学标记的精确预测,尤其是在音调丰富的语言中。为了最小化信息损失,本文训练了一个 VQ-VAE 模型来学习一个向量量化码本,该码本能够从语音 SSL 模型中重建语音语义表示。具体来说,使用 W2v-BERT 2.0 模型的第 17 层隐藏状态作为语音编码器的语义特征,编码器和解码器由多个 ConvNext 块组成。通过改进的 VQ-GAN 和 DAC 方法,使用因子分解码将编码器输出投影到低维潜在变量空间。
语音声学编解码器旨在将语音波形量化为多层离散标记,同时尽可能保留语音的所有信息。本文采用残差向量量化(Residual Vector Quantization, RVQ)方法,将 24K 采样率的语音波形压缩为 12 层的离散标记。此外,模型使用 Vocos 架构作为解码器,以提高训练和推理效率。

文本到语义模型采用非自回归掩码生成 Transformer,而不使用自回归模型或任何文本到语音的对齐信息。在训练过程中,我们随机提取语义标记序列的前缀部分作为提示,以利用语言模型的上下文学习能力。我们使用 Llama 风格的 Transformer 作为模型的主干,结合门控线性单元(GLU)和 GELU 激活函数、旋转位置编码等,但将因果注意力替换为双向注意力。还使用了接受时间步 t 作为条件的自适应 RMSNorm。在推理过程中,我们生成任意指定长度的目标语义标记序列,条件是文本和提示语义标记序列。本文还训练了一个基于流匹配的持续时间预测模型,以预测基于文本和提示语音持续时间的总持续时间,利用上下文学习。
语义到声学模型同样采用非自回归掩码生成 Transformer,该模型以语义标记为条件,生成多层声学标记序列以重建高质量语音波形。

二、样例展示
MaskGCT 能超自然地模拟参考音频音色与风格,并跨语言生成音频:
参考音频:
中文克隆效果:
英文克隆效果:
MaskGCT 还能够模仿动画人物和名人的声音,猜猜下面的音频都是谁?
以下是一个展示 MaskGCT 翻译《黑神话:悟空》的实例:
参考音频:
,时长03:16
翻译效果:
,时长03:16
四、实验结果
SOTA 的语音合成效果:MaskGCT 在三个 TTS 基准数据集上都达到了 SOTA 效果,在某些指标上甚至超过了人类水平。

此外,MaskGCT 在风格迁移(口音、情感)也达到了 SOTA 的水准:

我们还研究了 MaskGCT 在中、英外其它语言的能力:

五、应用场景
目前,MaskGCT 在短剧出海、智能助手、有声读物、辅助教育等领域拥有丰富的应用场景。为了加快落地应用,在安全合规下,趣丸科技打造了多语种速译智能视听平台 “趣丸千音”。一键上传视频即可快速翻译成多语种版本,并实现音话同步、口型同步、去字幕等功能。该产品进一步革新视频翻译制作流程,大幅降低过往昂贵的人工翻译成本和冗长的制作周期,成为影视、游戏、短剧等内容出海的理想选择平台。
《2024 年短剧出海白皮书》显示,短剧出海成为蓝海新赛道,2023 年海外市场规模高达 650 亿美元,约为国内市场的 12 倍,短剧出海成为蓝海新赛道。以 “趣丸千音” 为代表的产品的出现,将加速国产短剧 “走出去”,进一步推动中华文化在全球不同语境下的传播。
六、总结
MaskGCT 是一个大规模的零样本 TTS 系统,利用全非自回归掩码生成编解码器 Transformer,无需文本与语音的对齐监督和音素级持续时间预测。MaskGCT 通过文本预测从语音自监督学习(SSL)模型中提取的语义标记,然后基于这些语义标记预测声学标记,实现了高质量的文本到语音合成。实验表明,MaskGCT 在语音质量、相似度和可理解性方面优于最先进的 TTS 系统,并且在模型规模和训练数据量增加时表现更佳,同时能够控制生成语音的总时长。此外,我们还探索了 MaskGCT 在语音翻译、语音转换、情感控制和语音内容编辑等任务中的可扩展性,展示了 MaskGCT 作为语音生成基础模型的潜力。
七、团队介绍
- 王远程:香港中文大学(深圳)计算机科学专业的二年级博士生,研究聚焦语音合成与表征领域,曾作为共同第一作者,研发新一代语音合成系统 NaturalSpeech 3。
- 武执政:香港中文大学(深圳)副教授、博导,港中大深圳 - 趣丸科技联合实验室主任。入选国家级青年人才,连续多次入选斯坦福大学 “全球前 2%顶尖科学家”、爱思唯尔 “中国高被引学者” 榜单。
- 曾锐鸿:趣丸科技资深语音算法工程师,研究聚焦跨语言零样本语音合成。曾在顶级期刊 ACM TWEB 发表论文,以及多篇语音识别和语音合成相关发明专利。
- 詹皓粤:趣丸科技资深语音算法工程师,研究聚焦跨语言零样本语音合成,曾发表多篇领域顶会论文及发明专利。
- 张强:趣丸科技人工智能研究中心副主任,人工智能高级工程师,专注研究人工智能算法,目前主持语音大模型、2D 和 3D 数字人等技术的研发。
- 张顺四:趣丸科技副总裁兼人工智能研究中心主任,人工智能高级工程师,粤港澳人工智能产业智库专家,长期从事低延迟音视频通讯技术和人工智能技术的研究,主导过千万级日活产品。发表技术发明专利 30 余篇,发表 EI 3 篇,SCI 3 篇。
#Anthropic挖走DeepMind强化学习大牛
AlphaGo核心作者Julian Schrittwieser
从 AlphaGo、AlphaZero 、MuZero 到 AlphaCode、AlphaTensor,再到最近的 Gemini 和 AlphaProof,Julian Schrittwieser 的工作成果似乎比他的名字更广为人知。
今天的 AI 社区,再次被一则大佬转会消息吸引了目光。
在谷歌工作十年后,大名鼎鼎的谷歌 DeepMind Alpha 系列核心作者 Julian Schrittwieser,宣布加入 Anthropic。
我很高兴地宣布,将从本周起加入 Anthropic!Claude 是我发现自己一直在使用的第一个 LLM。最近,我被《Artifacts》和《Computer Use》以及 Claude 不断提高的技能深深震撼了。
我非常幸运地参与了谷歌 DeepMind 过去 10 年的奇妙旅程,在那里我参与了很多令人兴奋的项目,这是我做梦都想不到的:从 AlphaGo 到 AlphaZero 和 MuZero 的传奇;还有很多的应用研究,如 AlphaCode 和 AlphaTensor,以及最近的 Gemini 和 AlphaProof。我相信,那里的团队也将继续创造惊人的成就,我迫不及待地想一探究竟!
Julian Schrittwieser 的跳槽,可以说是近期领域内最为惊人的一则消息,因为 Julian Schrittwieser 在 DeepMind 内部的地位非同寻常。更令人好奇的是,Anthropic 是如何招揽到这样一位顶尖人才:
不管过程如何,这一定是 Anthropic 最「超值」的一次招聘:
在 DeepMind 诞生以来的数年中,「Alpha 系列成果」一直是该团队最闪耀的前沿成果。而 Julian Schrittwieser 是这些伟大成就中不可忽视的贡献者。
2016 年,DeepMind 开发的 AlphaGo 以 4:1 击败世界顶级围棋棋手李世石(Lee Se-dol),成为轰动全球的人工智能里程碑事件。Julian Schrittwieser 参与撰写了第一篇关于 AlphaGo 的里程碑式论文。
- 《AlphaGo 4:1 战胜李世石,我们需要更好的理解人工智能》
2017 年,在 AlphaGo 与柯洁的比赛之后,DeepMind 宣布退役 AlphaGo,自学成才的 AlphaGo Zero 以 100:0 击败了早期的竞技版 AlphaGo,Julian Schrittwieser 是 AlphaGo Zero 论文的第二作者,也负责了从主搜索算法、训练框架到对新硬件的支持等工作。
- 《无需人类知识,DeepMind 新一代围棋程序 AlphaGo Zero 再次登上 Nature》
- 《DeepMind AlphaGo Zero 引爆业内,创造者现身 Reddit 问答》
而 AlphaGo Zero 随后被拓展为一个名为 AlphaZero 的程序。2017 年底,DeepMind 正式发表了 AlphaZero,这是一种可以从零开始通过 Self-Play 强化学习在多种任务上达到超越人类水平的算法。该算法经过不到 24 小时的训练后,即可在国际象棋和日本将棋上击败此前业内顶尖的计算机程序(这些程序早已超越人类世界冠军水平),也轻松击败了训练 3 天时间的 AlphaGo Zero。
- 《不只是围棋!AlphaGo Zero 之后 DeepMind 推出泛化强化学习算法 AlphaZero》
2020 年,DeepMind 发表了 MuZero。在不具备任何底层动态知识的情况下,该算法通过结合基于树的搜索和学得模型,不仅在国际象棋、日本将棋和围棋的精确规划任务中匹敌 AlphaZero,还在 30 多款雅达利游戏中展示出了超越人类的表现。Julian Schrittwieser 是 MuZero 论文《Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model》的核心作者之一。
- 《通用 AlphaGo 诞生?DeepMind 的 MuZero 在多种棋类游戏中超越人类》
2022 年 2 月,DeepMind 发布了基于 Transformer 模型的 AlphaCode,可以编写与人类相媲美的计算机程序。包括 Julian Schrittwieser 在内的多位作者后续又在《Science》上发表了论文。
- 《卷起来了!DeepMind 发布媲美普通程序员的 AlphaCode,同日 OpenAI 神经数学证明器拿下奥数题》
- 《DeepMind 携 AlphaCode 登 Science 封面,写代码能力不输程序员》
2022 年 10 月,DeepMind 提出了 AlphaTensor,第一个可用于为矩阵乘法等基本任务发现新颖、高效且可证明正确的算法的人工智能系统,并揭示了 50 年来在数学领域一个悬而未决的问题,即找到两个矩阵相乘最快方法。AlphaTensor 建立在 AlphaZero 的基础上,展示了 AlphaZero 从用于游戏到首次用于解决未解决的数学问题的一次转变。
- 《强化学习发现矩阵乘法算法,DeepMind 再登 Nature 封面推出 AlphaTensor》
2023 年 6 月,谷歌 DeepMind 发布了 AlphaDev,这种全新的强化学习系统发现了一种比以往更快的哈希算法。Julian Schrittwieser 也是 AlphaDev 项目的核心参与者之一。
- 《AI 重写排序算法,速度快 70%:DeepMind AlphaDev 革新计算基础,每天调用万亿次的库更新了》
2024 年 7 月,谷歌 DeepMind 团队研发的 AlphaProof 和 AlphaGeometry 2 在 IMO 竞赛上共同实现了里程碑式的突破。AlphaProof 是一种用于形式化数学推理的强化学习系统,而 AlphaGeometry 2 是 DeepMind 几何求解系统 AlphaGeometry 的改进版本。正式比赛中,AlphaProof+AlphaGeometry 2 组合成的 AI 系统在几分钟内就解决了人类参赛选手需要几个小时才能解决的问题。
- 《谷歌 AI 拿下 IMO 奥数银牌,数学推理模型 AlphaProof 面世,强化学习 is so back》
8 年前,基于强化学习的 AlphaGo 声名大噪;8 年后,强化学习在 AlphaProof 中再次大放异彩。2016 年 AlphaGo 论文的核心成员 Julian Schrittwieser、Aja Huang、Yannick Schroecker,如今也是 AlphaProof 的核心贡献者。有人在朋友圈感叹说:RL is so back!
业内普遍认为,OpenAI o1 运用的技术关键也在于强化学习的搜索与学习机制,这标志着 RL 下 Post-Training Scaling Law 的时代正式到来。正如《The Bitter Lesson》所说,只有搜索和学习这两种学习范式能够随着计算能力的增长无限扩展。强化学习作为这两种学习范式的载体,如何能够在实现可扩展的 RL 学习(Scalable RL Learning)和强化学习扩展法则(RL Scaling Law),将成为进一步突破大模型性能上限的关键途径。
这或许就是 Calude 团队招揽 Julian Schrittwieser 的出发点。o1 研发团队在采访中也谈到过,OpenAI 很早就受到 AlphaGo 的启发,意识到了深度强化学习的巨大潜力,并在相关方向投入了大量研究力量。
作为 RL 领域的深耕者,Julian Schrittwieser 又会带领 Claude 团队做出怎样的成果呢?让我们拭目以待。
参考链接:https://www.furidamu.org/blog/2024/10/28/joining-anthropic/
#Max Tegmark团队又出神作了
AI「长脑子」了?LLM惊现「人类脑叶」结构并有数学代码分区,MIT大牛新作震惊学界!
Max Tegmark团队又出神作了!他们发现,LLM中居然存在人类大脑结构一样的脑叶分区,分为数学/代码、短文本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非人类独有,硅基生命也从属这一法则。
LLM居然长「脑子」了?
就在刚刚,MIT传奇大牛Max Tegmark团队的新作,再次炸翻AI圈。
论文地址:https://arxiv.org/abs/2410.19750
他们发现,LLM学习的概念中,居然显示出令人惊讶的几何结构——
首先,它们形成一种类似人类大脑的「脑叶」;其次,它们形成了一种「语义晶体」,比初看起来更精确;并且,LLM的概念云更具分形特征,而非圆形。
具体而言,这篇论文探讨了LLM中稀疏自编码器(SAE)的特征向量表示的。
Max Tegmark团队的研究结果表明,SAE特征所代表的概念宇宙在多个空间尺度上展现出有趣的结构,从语义关系的原子层面到整个特征空间的大规模组织。
这就为我们理解LLM的内部表征和处理机制,提供了全新的见解。
总之,这个研究实在太过震撼!网友直言:如果LLM和人脑相似,这实在是给人一种不好的预感……
所以,美丽的自然法则并不独属于人类,硅基也从属于这一法则。
这个发现证明了:数学才是一切的基础,而非人类构造。
LLM的三个层面:原子,大脑和星系
团队发现,SAE特征的概念宇宙在三个层面上都具有有趣的结构:
- 小尺度「原子」
- 中尺度「大脑」
- 大尺度「星系」
原子级的微观结构,包含面为平行四边形或梯形的「晶体」,这是对经典案例的推广(比如「男人-女人-国王-王后」的关系)。
他们发现,当使用线性判别分析(LDA)高效地投影出诸如词长等全局干扰方向时,这些平行四边形和相关函数向量的质量会显著提升。
而类似「大脑」的中间尺度结构,则展现出了明显的空间模块化特征,团队将其描述为空间集群和共现集群之间的对齐。
比如,数学和代码特征形成了一个「脑叶」,跟神经功能磁共振图像中观察到的人类大脑功能分区相似。
团队运用多个指标,对这些功能区的空间局部性进行了量化分析,发现在足够粗略的尺度上,共同出现的特征簇在空间上的聚集程度远超过特征几何随机分布情况下的预期值。
而在「星系」的大尺度结构上,特征点云并非呈各向同性(各个方向性质相同),而是表现出特征值幂律分布,中间层的斜率最抖。
而聚类熵也在中间层周围达到峰值!
看完这个研究,有网友给出了这样的评价——
「如果这项研究出自Max Tegmark之外的任何人,我都会觉得他是疯子。但Tegmark是我们这个时代最优秀的科学家之一。当我说意识是一种数学模式、一种物质状态时,我引用的是他。」
LLM学习概念中,惊人的三层几何结构
去年,AI圈在理解LLM如何工作上取得了突破,稀疏自编码器在其激活空间中,发现了大量可以解释为概念的点(「特征」)。
稀疏自编码器作为在无监督情况下发现可解释语言模型特征的方法,受到了很多关注,而检查SAE特征结构的工作则较少。
这类SAE点云最近已经公开,MIT团队认为,是时候研究它们在不同尺度上的结构了。
「原子」尺度:晶体结构
在SAE特征的点云中,研究者试图寻找一种称之为「晶体结构」的东西。
这是指反映概念之间语义关系的几何结构,一个经典的例子就是(a, b, c, d)=(男人,女人,国王,女王)。
它们形成了一个近似的平行四边形,其中b−a≈d−c。
这可以解释为,两个函数向量b−a和c−a分别将男性实体变为女性,将实体变为皇室。
研究者还搜索了只有一对平行边b−a ∝ d−c的梯形(对应于仅一个函数向量)。
图1(右)即为这样的一个例子:(a, b, c, d)=(奥地利,维也纳,瑞士,伯尔尼),其中函数向量可以解释为将国家映射到其首都。
研究者通过计算所有成对的差向量并对其进行聚类来搜索晶体,这应该会产生与每个函数向量相对应的一个簇。
簇中的任何一对差向量,应该构成梯形或平行四边形,这取决于在聚类之前差向量是否被归一化(或者可以等效于,是否通过欧几里得距离或余弦相似度,来量化了两个差向量之间的相似性)。
最初搜索SAE晶体时,研究者发现的大多是噪声。
为什么会出现这种情况?
为了调查原因,研究者将注意力集中在了在第0层(token嵌入)和第1层,在这些层中,许多SAE特征与单个词相对应。
然后,他们研究了Gemma2 2B模型中来自数据集的残差流激活,这些激活对应于先前报告的词->词函数向量,于是搞明白了这个问题。
如图1所示,晶体四重向量通常远非平行四边形或梯形。
这与多篇论文指出的情况一致,即(男,女,国王,王后)并不是一个准确的平行四边形。
之所以会有这种现象,是因为存在一种所谓的「干扰特征」。
比如,图1(右)中的横轴主要对应于单词长度。
这在语义上是不相关的,并且对梯形(左)造成了严重破坏,因为「Switzerland」要比其他的词长很多。
为了消除这些语义上无关的干扰向量,研究者希望将数据投影到与这些干扰向量正交的低维子空间上。
对于数据集,他们使用了线性判别分析(LDA)来实现这一点。LDA将数据投影到信号噪声比特征模式上,其中「信号」和「噪声」分别定义为簇间变化和簇内变化的协方差矩阵。
这种仿佛显著改善了簇和梯形/平行四边形的质量,突显出干扰特征可能掩盖了现有的晶体结构。
「大脑」尺度:中等尺度的模块结构
接下来,我们到了论文最精彩的地方。
在这一部分,研究者们缩小了视角,试图寻找更大规模的结构。
他们研究了功能相似的SAE特征组(这些特征组倾向于一起激活),想看看它们是否在几何上也是相似的,是否会在激活空间中形成「脑叶」。
在动物的大脑中,这种功能组就是众所周知的神经元所在的三维空间中的簇。
例如,布罗卡区涉及语言生成,听觉皮层处理声音,杏仁核主要处理情绪。
研究者非常好奇,是否可以在SAE特征空间中找到类似的功能模块呢?
他们测试了多种方法,来自动发现这类功能性「脑叶」,并量化它们是否是空间模块化的。
他们将脑叶分区定义为点云的一个k子集的划分,这种分区的计算不使用位置信息,相反,他们是基于它们在功能上的关联性来识别这些脑叶分区的。
具体来说,这些脑叶在同一文档内倾向于一起激活。
为了自动识别功能脑叶,研究者首先计算了SAE特征共现的直方图。
他们使用Gemma2 2B模型处理了来自The Pile的文档。
研究者发现,在第12层的残差流SAE具有16k个特征,平均L0为41。
他们记录了这个SAE被激活的特征(如果某特征的隐藏激活值> 1,则将其视为被激活)。
如果两个特征在同一个256个token的块内同时激活,则它们被视为共现。
此长度提供了一种粗略的「时间分辨率」,使他们能够发现倾向于在同一文档中共同激活的token,而不仅限于同一token。
研究者使用了最大长度为1024的上下文,并且每个文档只使用一个这样的上下文,这就使他们在The Pile的每个文档中最多有4个块(和直方图更新)。
他们在5万个文档中计算了直方图。
基于此直方图,他们根据SAE特征的共现统计,计算了每对特征之间的亲和分数,并对得到的亲和矩阵进行了谱聚类。
研究者尝试了以下基于共现的亲和度计算方法:简单匹配系数、Jaccard相似度、Dice系数、重叠系数和Phi系数,这些都可以仅通过共现直方图计算得出。
研究者们原本假设,功能上相似的点(即常见的共现SAE特征)在激活空间中应该是均匀分布的,不会表现出空间模块性。
然而,出乎他们意料,图2显示出:脑叶在视觉上呈现出相当集中的空间分布!
在SAE点云中识别出的特征倾向于在文档中一起激活,同时也在几何上共同定位于功能「脑叶」中,左侧的2脑叶划分将点云大致分为两部分,分别在代码/数学文档和英文文档上激活。右侧的3脑叶划分主要将英文脑叶细分为一个包含简短消息和对话的部分,以及一个主要包含长篇科学论文的部分
为了量化其统计显著性,研究者使用了两种方法来排除原假设:
1. 虽然可以基于特征是否同时出现进行聚类,但也可以基于SAE特征解码向量的余弦相似度来进行谱聚类。
他们首先使用了余弦相似度对SAE特征进行聚类,然后使用共现对特征进行聚类,之后计算这两组标签之间的相互信息。
在某种意义上,这直接衡量了通过了解功能结构可以获得多少关于几何结构的信息。
2. 另一个方法就是训练模型,通过几何信息预测特征所属的功能脑叶。
为此,研究者将基于共现聚类得到的脑叶标签集作为目标,使用逻辑回归模型直接根据点的位置预测这些标签,并使用80-20的训练-测试集划分,报告该分类器的平衡测试准确率。
左上:空间聚类与功能聚类之间的调整互信息。右上:逻辑回归的平衡测试准确率,用位置预测基于共现的聚类标签。左下:随机置换余弦相似度聚类标签后的调整互信息。右下:随机单位范数特征向量的平衡测试准确率。报告的统计显著性基于Phi系数的脑叶聚类
图3显示,对于两种度量方法,Phi系数效果最佳,提供了功能脑叶与特征几何形状之间的最佳对应关系。
为了证明其统计显著性,研究者随机打乱了基于余弦相似度聚类的簇标签,并测量了调整后的相互信息。
同时,他们使用随机高斯分布,对SAE特征解码方向重新初始化并归一化,然后训练逻辑回归模型从这些特征方向预测功能脑叶。
图3(下)显示,两项测试都以极高的显著性排除了零假设,分别达到了954和74个标准差,这就明确表明:研究者所观察到的脑叶是真实的,而非统计偶然!
为了评估每个脑叶的专长,他们将The Pile数据集中的1万份文档输入了Gemma2 2B模型,并再次记录了第12层中每256个token块内触发的SAE特征。
对于每个token块,他们都记录了具有最高特征触发比例的脑叶。
The Pile中的每个文档都带有名称,指定该文档属于语料库的哪个子集。对于每种文档类型,针对该类型文档中每个256 token块,他们都会记录哪一个脑叶具有最高的SAE特征触发比例。
跨越数千份文档后,可以查看每种文档类型中,哪个脑叶的激活比例最高的直方图。
在图4中,研究者展示了使用Phi系数作为共现度量计算的三个脑叶结果,这构成了图2中脑叶标记的基础。
每个脑叶都具有最高比例的激活特征上下文分数。脑叶2通常在代码和数学文档上不成比例地被激活,脑叶0在包含文本(聊天记录、会议记录)的文档上激活更多,脑叶1在科学论文上激活更多
图5对比了五种不同共现度量的效果。尽管Phi系数最佳,但五种度量方法均能够识别出「代码/数学脑叶」。
「星系」尺度:「大规模」点云结构
最后一种,让我们进一步拉远视角,看看大模型在「星系」尺度结构中,点云的样子。
主要是研究其整体形状、聚类,类似于天文学家研究硬核系形状和子结构的方式。
接下来,研究人员试图去排除一个简单的零假设(null hypothesis):点云只是从各向同性多元高斯分布中采样的。
如图6直观地表明,即使在其前三个主要成分中,点云分布也不完全是圆形的,某些主轴略宽于其他轴,类似人脑的形状。
形状分析
图7(左)通过点云协方差矩阵的特征值排序,来量化这一现象。
它揭示出,这些特征值并非是恒定的,而是呈现出幂律衰减。
为了检验这个令人惊讶的幂律是否显著,图中将其与从各向同性高斯分布中抽取的点云的相应特征值谱进行比较。
结果显示,后者更加平摊,并且与分析预测一致:
从多元高斯分布中抽取的N个随机向量的协方差矩阵遵循Wishart分布
这一点,已经在随机矩阵理论中,得到了充分的研究。
由于,最小特征值的急剧下降是由有限数据引起的,并在N趋于无穷大时消失,研究人员在后续分析中,将点云降维到其100个主成分。
换句话说,点云的形状像一个「分形黄瓜」,其在连续维度上的宽度像幂律一样下降。
研究人员发现,与SAE特征相比,激活值的幂律特征明显较弱。未来,进一步研究其成因,也将是一个有趣的方向。
图7(右)显示了,上述幂律的斜率如何随LLM层数变化,这是通过对100个最大特征进行线性回归计算得到的。
研究人员观察到一个清晰的模式:
中间层具有最陡的幂律斜率(第12层的斜率为-0.47),而早期和后期层(如第0层和第24层)的斜率较为平缓(分别为-0.24和-0.25)。
这可能暗示了,中间层充当了一个瓶颈,将信息压缩到更少的主成分中,或许是为了更有效表示高层抽象概念。
图7(右)还在对数尺度上,展示了有效云体积(协方差矩阵的行列式)如何随层数变化。
聚类分析
一般来说,星系或微观粒子的聚类,通常通过幂谱或相关函数来量化。
对于研究中高维数据来说,这种量化变得很复杂。
因为底层密度会随着半径变化,而对于高维高斯分布,密度强烈集中在相对较薄的球壳周围。
由此,研究人员选择通过估计点云,假定采样的分布的「熵」来量化聚类。
他们使用k-NN方法来估计熵H,计算如下:

其中ri是点i到第k个最近邻的距离,d是点云的维度;n是点的数量;
常数Ψ是k-NN估计中的digamma项。作为基线,高斯熵代表了给定协方差矩阵的最大可能熵。
对于具有相同协方差矩阵的高斯分布,熵的计算方法如下:

其中λi是协方差矩阵的特征值。
研究人员定义聚类熵,或「负熵」,为Hgauss − H,即熵比其最大允许值低多少。
图8显示了不同层的估计聚类熵。可以看到,SAE点云在中间层强烈聚集。
在未来研究中,研究这些变化是否主要取决于不同层中晶体或叶状结构的显著性,或者是否有完全不同的起源,将会是一个有趣的方向。
破解LLM运作机制黑箱,人类再近一步
总而言之,MIT团队这项最新研究中,揭示了SAE点云概念空间具有三层有趣的结构:
原子尺度的晶体结构;大脑尺度的模块结构;星系尺度的点云结构。
正如网友所言,亲眼目睹了人类硅基孩子在我面前成长,既令人敬畏又令人恐惧。
Max Tegmark出品,必属精品。
此前就有人发现,仅在下一个token预测上训练的序列模型中,存在线性表征的类似证据。
23年2月,哈佛、MIT的研究人员发表了一项新研究Othello-GPT,在简单的棋盘游戏中验证了内部表征的有效性。
在没有任何奥赛罗规则先验知识的情况下,研究人员发现模型能够以非常高的准确率预测出合法的移动操作,捕捉棋盘的状态。他们认为语言模型的内部确实建立了一个世界模型,而不只是单纯的记忆或是统计,不过其能力来源还不清楚。
吴恩达对该研究表示了高度认可。
受此启发,Max Tegmark团队发现,Llama-2-70B竟然能够描绘出研究人员真实世界的文字地图,还能预测每个地方真实的纬度和经度;而在时间表征上,模型成功预测了名人的死亡年份、歌曲电影书籍的发布日期和新闻的出版日期。
总之,这项研究在LLM中发现了「经度神经元」,在学界引起了巨大反响。
如今,Tegmark团队又再进一步,帮我们从更微观的角度剖析LLM的大脑。人类离解释LLM运作机制的黑箱,又近了一步。
参考资料:
https://arxiv.org/abs/2410.19750
#全球最大AI超算内部首次曝光
马斯克19天神速组装10万块H100,未来规模还将扩大一倍
一文揭秘全球最大AI超算,解析液冷机架和网络系统的创新设计。这台全球最大AI超算Colossus由xAI和英伟达联手建造,耗资数十亿,10万块H100仅半个多月搭建完成,未来规模还将扩大一倍!
两个月前,马斯克才刚刚自曝了xAI的Colossus超算,称其是世界上最强大的AI训练系统。
最近,马斯克又宣布了一条振奋人心的消息——集群即将扩展到20万张H100/H200显卡!
同时,ServeTheHome也发布了一条15分钟的视频,公布了这台超算的详情!
来自ServeTheHome的Patrick Kennedy带着摄影机探访了这台超级计算机
这台全球最大的AI超级计算机Colossus位于美国田纳西州孟菲斯,配备了10万个英伟达Hopper GPU,并由英伟达Spectrum-X以太网提供网络传输支持。
目前,Colossus的第一阶段建设已完成,集群全面上线,但这并不是终点。它将很快迎来升级,GPU容量将翻倍,新增5万块H100 GPU和5万块下一代H200 GPU。
Colossus正在用于训练xAI的Grok,并为X Premium订阅用户提供聊天机器人功能。
在训练超大规模的Grok时,Colossus展现了前所未有的网络性能。在网络结构的所有层级中,系统在流量冲突的情况下没有经历任何应用延迟降级或数据包丢失。
通过Spectrum-X拥塞控制,它保持了95%的数据吞吐量。这种性能水平无法通过标准以太网实现,标准以太网在传输中会产生数千次流量冲突,数据吞吐量仅能达到60%。
由于保密协议的限制,这台超级计算机的一些细节并没有透露。不过,像Supermicro GPU服务器等关键部件的介绍在视频中都有所涉及。
液冷机架
Colossus集群的基本构建单元是Supermicro液冷机架。
每个机架包含八台4U服务器,每台服务器配备八个英伟达H100,共计64个GPU。
八台此类GPU服务器再加上一个Supermicro冷却分配单元(CDU)及相关硬件,构成了一个GPU计算机架。
这些机架以八台为一组排列,共512个GPU,并通过网络连接,形成更大系统中的小型集群。
xAI使用的是Supermicro 4U通用GPU系统。
这是目前市面上最先进的AI服务器,有2个原因:其一是它的液冷程度;其二是设备的可维护性。
该系统被放置在托盘上,无需将系统从机架中移出即可维护。1U机架分流器可为每个系统引入冷却液并排出温热液体。快速断开装置让液冷系统可以迅速移除,甚至可以人工单手拆装;移除后,托盘即可拉出以便维护。
下图是一张该服务器原型的照片,展示了这些系统的内部构造。
SC23展示的Supermicro 4U通用GPU系统:支持液冷英伟达HGX H100和HGX 200
上图SC23原型中的两个x86 CPU液冷模块相对常见。
特别之处在于右侧:Supermicro的主板集成了几乎所有HGX AI服务器中使用的四个Broadcom PCIe交换机,而非将其单独安装在另一块板上。Supermicro为这四个PCIe交换机设计了定制液冷模块。
其他AI服务器通常是在风冷设计的基础上加装液冷,而Supermicro的设计则完全从零开始,为液冷而打造,且所有组件均来自同一供应商。
打个通俗的比方,这类似于汽车——有些车型先设计为燃油车,之后再安装电动动力系统,而有些车型从一开始就是为电动车设计的。这款Supermicro系统就属于后者,而其他HGX H100系统则属于前者。
Patrick怒赞道:测评了各种各样的液冷系统设计,这款Supermicro系统遥遥领先于其他系统!
网络系统
这里的每条光纤连接速率为400GbE,是常见1GbE网络速率的400倍。此外,每个系统拥有9条这样的连接,意味着每台GPU计算服务器的带宽达到约3.6Tbps。
打个比方,如果1GbE的普通家庭网络好比是一条单车道公路,那这个400GbE就像是一条拥有400车道的高速公路。而每个系统有9条这样的「高速公路」,相当于每台GPU计算服务器拥有9条这样的超宽带公路,总带宽达到3.6Tbps。
这个带宽甚至超过了2021年初顶级Intel Xeon服务器处理器在所有PCIe通道上所能处理的连接总量。
GPU的RDMA网络构成了该带宽的大部分。每个GPU都有自己的NIC。
在这里,xAI使用英伟达BlueField-3 SuperNIC和Spectrum-X网络。英伟达的网络堆栈中加入了一些独特技术,可以帮助数据绕过集群中的瓶颈,确保数据准确地传输到指定位置。
这是一个重大突破!许多超级计算机网络使用的是InfiniBand或其他技术,而这里采用的是以太网。
以太网是互联网的骨干,因此它具有极强的扩展性。这些庞大的AI集群已扩展到一些更小众技术未能触及的规模。对于xAI团队而言,这确实是一个大胆的举措。
除了GPU的RDMA网络外,CPU也配备了400GbE连接,但使用完全不同的交换结构。xAI为其GPU和集群的其余部分分别配置了独立的网络,这在高性能计算集群中是非常常见的设计。
除了高速集群网络外,还有低速网络用于管理接口和环境设备,这些都是此类集群的重要组成部分。
参考资料:
#全自动打工「人」
波士顿动力Atlas进厂视频火了,不断电不下班
波士顿动力Atlas进厂打工,不靠远程操控,转身动作像惊悚电影。
波士顿动力的人形机器人,进厂了。
本周三,波士顿动力发来一条喜讯。其最新披露的视频展示了机器人在工厂环境中的任务完成能力。机器人现在已经可以全自动干活了,它可以在储物柜之间搬动汽车发动机零件:

搬运的这个东西是汽车的发动机盖。视频里可见新版 Atlas 机器人是在寻找零件并挑选位置放置,还附带识别过程的展示:

搬着搬着 Atlas 看到有人拍摄,突然虎躯一震(其实是东西没放对位置)。没关系,我很稳:

我们注意到,在拿到东西和放好东西后需要转身的瞬间,Atlas 并没有像人类一样转过来,而是以腰部为中心进行旋转,该动作最大限度地减少了移动,从而节省了过程中宝贵的几秒钟。不过,这也让人联想到一些惊悚电影里,主人公身子不动,头直接转过来的画面。

一通操作看下来,机器人在工厂完成一些简单工作看起来是游刃有余了。
在社交网络上,网友们纷纷表示:太强了,看起来已经可以商业化了。

但众所周知,实现这样的愿景还有很长一段路要走。
波士顿动力指出,目前该公司的人形机器人已经能够通过视觉、受力和本体感受传感器的组合来检测环境变化(例如移动固定装置)和动作故障(例如无法插入盖子、绊倒、环境碰撞)并做出反应。
,时长02:52
需要注意的是:波士顿动力这次强调了演示视频中的机器人是完全自主运行的,没有「预设程序或遥控动作」,它可以使用机器学习算法理解并适应真实世界的环境。这一声明似乎是在 cue 谁,但就是没有明说。
最近一段时间,哪家的人形机器人上过头条?应该是在特斯拉「We, Robot」活动中大放异彩的擎天柱 Optimus。马斯克还说,人形机器人的数量将在不到 20 年内超过人类,「这工作要由我来干」。
特斯拉的 Optimus 机器人展示了与观众互动,玩游戏、跳舞,甚至进行简单对话的能力,好不先进。

然而,很多人指出,Optimus 在展示过程中实际上部分依赖于人类的远程操控,这引发了外界对于其自主能力的质疑。由于种种原因,特斯拉的股价当时还瞬间跌了 10%。
与 Figure、Tesla 和 Apptronik 等竞争对手一样,波士顿动力公司人形机器人的首次应用包括在汽车工厂的工作。考虑到该公司现在属于现代汽车公司,而现代汽车公司刚刚选择与丰田汽车的研究部门达成协议,关注 Atlas 这一应用是很有意义的。几十年来,汽车行业在自动化领域也一直遥遥领先。或许有一天,Atlas 真的会变身一名「汽车工人」。
波士顿动力也玩转型:Atlas 电动化之后
今年 4 月,波士顿动力曾跟全世界开了一个玩笑,先是官宣人形机器人 Atlas 退役,狠狠来了一波回忆杀。

紧接着,就在第二天,他们又放出了一个新的人形机器人视频。新机器人也叫 Atlas,不过由原来的液压改为了电动,身材更为小巧、灵活。

此时,外界才反应过来,原来波士顿动力并不是要放弃人形机器人,而是转变了研发方向,让机器人更加适应工业环境。当时,该公司表示,这个电动版的 Atlas 将于明年初在韩国现代汽车工厂里开始进行试点测试,并会在几年后全面投产。看来,试点的时间可能提前了一些。
和之前的液压版 Atlas 一样,电动版的 Atlas 也是有一些绝活在身上的,比如随手就来一个俯卧撑:


做完俯卧撑后,Atlas 还能自己站起来。
倒立行走:

这些「绝活」是怎么做到的呢?前段时间,在机器人顶会 RSS 的一场技术分享中,MIT 博士、波士顿动力机器人工程师 Robin Deits 介绍了 Atlas 机器人过去几年的研发历程,以及从中学到的经验、教训。

具体来说,Robin Deits 主要介绍了 Atlas 控制器的核心 ——MPC(模型预测控制)。他表示,波士顿动力从 2019 年以来实现的所有机器人动作都是依靠 MPC 来完成的,包括跑酷、体操、跳舞、后空翻等等。最近,他们还展示了 MPC 用于操纵物体的效果。2024 款纯电驱动的 Atlas 新版本也是由 MPC 驱动的。
对于这场技术分享,也做了详细报道,感兴趣的读者可以抽时间详细阅读(参见《波士顿动力技术揭秘:后空翻、俯卧撑与翻车,6 年经验、教训总结》)。
其实,除了内部研发,波士顿动力也在加强与外部的基础研究合作。就在两周前,波士顿动力和丰田研究院(TRI)官宣建立新的合作伙伴关系,以「利用 TRI 的大型行为模型和波士顿动力的 Atlas 机器人,加速通用人形机器人的开发」。
根据 IEEE Spectrum 的报道,TRI 的大型行为模型(LBM)其实类似于大型语言模型(LLM),只不过它的应用场景是在物理世界中工作的机器人。TRI 长期以来一直致力于开发基于人工智能的学习技术,以应对各种复杂的操作挑战。在与波士顿动力合作后,他们将通过 Atlas 获取更多物理世界的数据,这些数据将反过来用于支持高级 LBM 的训练。双方合作有一定的互补作用。
在基础研究层面,人工智能能否给 Atlas 带来新的突破,欢迎在评论区讨论。
参考内容:
https://x.com/BostonDynamics/status/1851624026424197434
https://spectrum.ieee.org/boston-dynamics-toyota-research
#登上生图排行榜第一的red_panda
是家创业公司,不是国产模型
大家别猜了,「red_panda」(小熊猫)模型有主了。
谜底解开了。
前几天在 Hugging Face 文本转图像排行榜上排名第一的 red_panda,是一个名为 Recraft V3 的模型,由 AI 初创公司 Recraft 提供。
Recraft V3 以 1172 的 ELO 评分位居第一,超越了 Midjourney、OpenAI 和其他公司的模型。

榜单地址:https://huggingface.co/spaces/ArtificialAnalysis/Text-to-Image-Leaderboard

试用地址:https://fal.ai/models/fal-ai/recraft-v3
当时这个神秘模型一夜爆火,但迟迟没有机构认领,于是大家纷纷玩起了猜谜游戏,网友们否定了包括 Stability AI、OpenAI 在内的几乎所有能想到的机构。

还有人猜测这个模型来自中国一家实验室。

让大家意外的是,这是一家刚成立两年的公司,总部设在英国伦敦。
Recraft 发布的 Recraft V3 模型在文本生成方面提供了前所未有的质量,他们还推出了几项重要的新功能,让用户可以更好地控制 AI 生成,比如可以指定图像中的文本大小和位置、精确的样式控制及新的修复功能。

文本生成无限制:Recraft V3 是图像生成领域唯一可以生成带有长文本(而不是只有一个或几个单词)的图像的模型。

专为设计打造:Recraft V3 允许用户控制文本的大小和位置,以创建详细、专业品质的视觉效果,非常适合品牌推广、营销和复杂的图形布局。


精确的风格控制:Recraft V3 接受风格作为模型输入,并且不需要重新训练来捕获细节。只需选择一组图像来代表品牌的审美,并完善候选风格,直到生成图像完全符合所需的外观和感觉。

此外,Recraft 还提供了第一个支持矢量艺术和风格一致性的 API,为开发人员提供无缝集成,支持可缩放矢量图形(SVG),以实现品牌一致性。
初创公司 Recraft
Recraft 于 2022 年成立,致力于帮助设计师创造和完善视觉效果,更好地控制整个设计过程,确保创作者能够通过人工智能完全控制他们的创作过程,将想法变成现实。

#ExFM
GPT4规模大模型落地,Meta提ExFM框架:万亿参数基础大模型的工业级落地成为可能
如何让万亿级基础大模型能够高效、低成本地服务于大规模工业级应用,并且让能够随着模型规模的提升(Scaling)而得到持续的性能增长?这一直是众多企业困扰良久的难题。
在线广告推荐系统是互联网平台的核心服务之一,其模型性能直接影响用户体验与商业价值。近年来,随着 GPT-4、 DeepSeek、 Llama 等万亿参数基础模型的成功,工业界和学术界开始探索通过模型规模化(Scaling)的方式建立基础大模型来提升推荐效果。
然而,受限于其巨额训练以及计算成本,以及工业级广告实时推荐对延时性以及部署计算资源的严格要求,基础大模型几乎很难被直接地应用于实时广告排序以及推荐系统,尤其是考虑到很多公司无法负担大规模的 GPU 来服务巨量用户群体。
因此,目前工业界广泛考虑让基础大模型(Foundation Model)的能力迁移到线上小模型(Vertical Model)当中以提高在线模型的能力,且主要采用教师-学生蒸馏(teacher-student distillation)。不过,此类解决方案在广告工业中的应用依旧面临着两大长期被忽视的挑战:受限的训练/推理预算,与动态变化的流式数据分布。这些挑战的存在使得大模型对线上模型的帮助受限,且无法规模化提升线上模型的性能。
本周,在 Meta AI 研究团队提交的一篇论文中,研究团队提出 External Large Foundation Model(ExFM)框架,首次系统性地解决了上述问题,成功支持万亿参数大模型在广告推荐中的高效服务。据文章描述,ExFM 框架实现了以下 SOTA 成果:
- 规模化大模型及线上模型的迭代部署:ExFM 解耦了教师模型和学生模型的迭代和部署,在接近于 0 服务成本的情况下成功部署万亿级别参数的工业级大模型(类 GPT-4 规模),显著降低了工业界受益于大模型的门槛和成本。ExFM 创新的提出数据增强系统(DAS),使得模型在等待线上用户的真实训练标签(ground-truth label, 如用户最终的点击或购买行为)的时间里完成教师模型的参数更新与相应的伪标签预测,达到对服务延迟没有额外要求。
- 高效的知识迁移转化率:ExFM 创新地提出了辅助头(Auxiliary Head)以及学生适配器(Student Adapter)来解耦教师与学生模型,减少流式数据分布变化对教师模型与学生模型训练过程中引入的偏置对知识迁移的影响,从而提高教师模型到学生模型的知识迁移转化率,并对此进行了相应的理论分析。经验结果表明,这两项新技术在内部以及公开数据上皆取得了 SOTA 的结果。
- 实现 1 到 N 的知识迁移转化:在 ExFM 的赋能下,不同领域、任务、阶段里负责广告排序的线上模型均实现了 SOTA 表现。
- 新型的 Transfer Scaling Law:在 ExFM 的赋能下,当不断迭代和提升基础大模型的模型规模时,其高效的知识转化率使得线上的广告排序模型的性能呈现出连续数年的持续提升(图 1),且增速在不断扩大,展示了一种新型的 Transfer Scaling Law。

图 1:内部数据上基于不同规模的 FM 对 VM 进行迭代下取得的 NE 增益(时间跨度从 2023 年至 2024 年)。1X 等于 60 Million training FLOPs,1T 指 1 Trillion。
目前该论文已被 WWW 2025 Industrial Track 录用为口头报告 (Oral Presentation,根据往年数据一般为 top 10% 的论文)。本文将深入解析这一技术突破的核心思想与创新实践。
- 论文标题:External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
- 论文链接:https://arxiv.org/abs/2502.17494
规模化的隐形门槛
工业级推荐的两大挑战
现有广告推荐方面的研究多聚焦于模型架构创新与参数规模扩展,但工业场景的特殊性导致线上部署的模型会面临以下两个主要挑战:
1. (C-1) 大流量下严格的延迟限制
- 广告推荐需在毫秒级响应中从海量候选广告(O (100K))中实时筛选,模型推理延迟将直接影响用户体验。
- 传统知识蒸馏(KD)需联合训练师生模型,显著增加计算成本和线上模型更新迭代的延迟,无法满足工业级模型实时更新的需求。
2. (C-2) 流式数据的动态漂移
- 用户与广告数量会出现大规模的实时增减,这导致数据分布持续变化。传统多轮训练易出现过时,具体指的是线上模型更新完成的时间点落后于即时数据到达的时间点而使得大量实时数据无法被纳入训练,导致模型训练后性能不足。并且多轮训练的计算代价高昂,这是因为实时数据的规模异常庞大且与日俱增。
- 教师模型,如基础模型(FM),与垂直模型(VM)间的跨域偏差与新鲜度差异进一步加剧性能衰减。

图 2:(a)联合蒸馏(Co-Distillation)与外部蒸馏(External Distillation);(b)流式数据下的模型迭代更新示意图;(c)ExFM 框架,以一次模型迭代为例的示意图。
对于解决挑战 C-1,常见的解决手段基于知识蒸馏,如果图 2(a)所示,即把一个参数量大的教师模型与一个参数量小的学生模型进行联合训练,而学生模型会用于在线广告推荐。然而在现实场景中,联合训练将增加学生模型的训练复杂度以至于无法满足工业级应用对在线模型进行更新训练的延时要求。另一方面,广告推荐往往涉及多个在线服务模型,每一个模型需要负责特定的阶段的广告排序任务。若对每个服务模型都建立对应的教师模型将非常低效且无法规模化。
因此,本文认为一个理想的教师模型应该满足以下两点需求:
- 教师模型应该独立于学生模型,即进行外部整理,如图 2(a)所示。
- 教师模型应该像一个基础模型一样满足 1-to-N,即一个教师模型可以帮助多个不同方向的学生模型的性能提升。
然而在线广告工业中的流式及动态变化的数据分布(挑战 C-2)使得实现理想的教师模型变得相当困难。如图 2(b)所示,模型需要持续训练以应对不断出现的分布漂移。对此 Meta 内部数据显示,若模型停止更新,其归一化熵损失(NE)随延迟时间呈指数级上升(如图 3 所示)。这迫使工业系统必须在「模型规模」与「服务效率」间寻求平衡。

图 3:点击率预测(CTR)随着模型更新延迟而出现严重的下滑。
为了解决上述的挑战,本文提出 ExFM 框架。ExFM的核心思想是通过外部蒸馏将基础模型(FM)的知识高效迁移至多个垂直模型(VM),并结合动态适配机制应对数据漂移。该框架的核心优势包括:
- 零额外推理延迟:通过外部蒸馏与数据增强系统(DAS),万亿 FM 的预测离线生成,VM 服务延迟与基线持平。
- 动态适应能力:流式训练与适配器设计使模型持续适应数据分布变化,NE 增益能够随着时间推移以更大增速进行扩大。
ExFM 框架
外部蒸馏与动态适应的双重革新
具体而言,ExFM 的技术架构如图 2 (c) 所示,包含四大创新模块:
1. 外部蒸馏与数据增强系统(DAS, 见图 4)
- 解耦师生训练:FM 独立于 VM 训练,通过离线生成预测标签作为监督信号,避免联合训练的计算开销。
- 1:N 资源共享:FM 聚合多个 VM 的数据进行训练,以「基础模型」形式服务多个垂直场景,显著摊薄构建成本。
- DAS 系统设计:通过分布式快照管理(Zeus)与数据流水线优化,实现 FM 预测的实时记录与高效分发,确保 VM 训练数据始终包含最新 FM 知识。

图 4:数据增强系统(Data Augmentation Service,DAS)
2. 辅助头
传统蒸馏将 FM 预测与真实标签通过同一头部融合,导致偏差传递。ExFM 创新性引入独立辅助头(图 5a):
- 解耦监督信号:真实标签由服务头处理,FM 预测由辅助头处理,阻断偏差传播路径。
- 梯度/标签缩放技术:通过放大 FM 预测的梯度影响与标签幅值,解决广告点击数据的长尾分布难题。
文中对此进行理论分析显示,辅助头可确保 VM 在真实标签任务上收敛至最优解,而传统单头架构因偏差传递无法实现。

图 5:(a)辅助头(Auxiliary Head)(b)学生适配器(Student Adapter)
3. 学生适配器(Student Adapter)
针对 FM 与 VM 间的新鲜度差异,ExFM 提出轻量级适配模块(图 5b):
- 动态校正机制:通过小型 MLP 网络实时调整 FM 预测,使其适配 VM 的当前数据分布。
- 理论保障:文中给出理论分析表明,适配器可将模型偏差降低,显著优于传统方法。
4. 流式训练范式
- FM 与 VM 均采用单轮流式训练,每日处理超 3000 亿样本,模型参数逐日迭代更新。
- 系统支持分钟级快照切换,确保服务高可用性。
实验结果
性能飞跃与工业验证
ExFM 在 Meta 内部数据集与公开数据集(TaobaoAd、Amazon 等)上均取得显著效果:
1. 单 VM 性能提升
- 内部场景中,3.2 万亿参数的 FM 使 VM 的归一化熵(NE)持续降低,性能增益随训练数据量增长呈类指数上升(图 1)。
- 公开数据集上(表 1),ExFM 在不同 FM-VM 组合均取得性能的提升。

表 1:公开数据集上的表现
2. 跨场景泛化能力
- 单一 FM 可同时服务广告系统的召回、粗排、精排多阶段 VM(图 6),NE 增益达 0.11%-0.25%。
- 在跨域(表 4)与多任务(表 5)场景中,ExFM 均显著优于无 FM 基线,验证其通用性。

图 6:内部数据上 1000X,3.2T FM 对 跨阶段(cross-stage) VM 的 NE 增益

表 4(左)及 表 5(右):公开数据集上 FM 对跨域以及跨任务的 VM 的性能提升
3. 模块消融实验
- 辅助头(AH)贡献主要性能增益,使学生模型 NE 降低 4%(图 7)。
- 学生适配器(SA)在 FM 更新延迟时仍能维持 0.08% 的 NE 增益(图 8),但其效果依赖 FM 的持续迭代(图 9)。

图 7(左):对 1000X 3.2T 的 FM 增加辅助头(AH)后的 NE 变化; 图 8(右):对 1800X,2.2T 的 FM 增加学生适配器(SA)后的 NE 变化

图 9:公开数据集上,当 FM 的更新出现延迟的时,学生适配器的性能变化
结论
在本论文中,Meta AI 研究团队提出了 ExFM 框架以实现万亿参数量的基础大模型对实时广告推荐模型进行持续、规模化的性能提升。降低了LLM规模的大模型在 recsys domain 的门槛,开启了「foundation model for RecSys 」领域的时代。
#灵犀X2
稚晖君发布灵犀X2,上演“自行车杂技”+“葡萄缝针”神技,比人还会演
jrm!稚晖君这次真的放大招了!
稚晖君所在的智元 X-Lab 正式上线了史上最复杂的具身智能项目——灵犀 X2!
发布前,官方先是放出“烟雾弹”,预告将发布三款机器人,分别拥有以下能力:
- 双足人形机器人:运动能力超强,能骑自行车能跳舞!
- 智能交互机器人:搭载情感计算引擎,更有人情味!
- 具身机器人:初步具备通用任务执行能力,保姆、保安、保洁、三保合一时代来临!
今早早上稚晖君揭晓真相: 一款机器人-灵犀 X2,它集齐了上述所有机器人的能力!
正式介绍之前,先给大家来几个机器人震惊小鹿的精彩瞬间:
超轻盈骑自行车:

用针缝葡萄:

稚晖君介绍,这次机器人的硬件系统像飞控去攒一套无人机航模一样,抽象出了一系列可复用的核心组件:
(1)小脑控制器 Xyber-Edge
(2)域控制器 Xyber-DCU
(3)智能电源管理系统 Xyber-B
(4)核心关键模组 PowerFlow 等
在运动控制算法方面,灵犀 X2 机器人摒弃了传统的基于模型的控制方法,转而采用学习驱动的强化学习策略。通过深度融合强化学习与模仿学习算法的优势,机器人可以掌握复杂运动技能,例如驾驶滑板车和平衡车。
此外,该系统还采用了智能体学习驱动的范式。
从每秒数万次的环境交互和动作数据中自主学习,并优化运动控制策略,突破运动性能瓶颈。
在交互智能方面,灵犀 X2 机器人搭载了基于 Diffusion (扩散模型)的生成式动作引擎,使其不仅具备强大的运动能力,更拥有高度智能化的交互能力。
研发团队坚持以理解人性为核心的交互设计理念,为 X2 训练了多模态交互大模型——硅光动语 ,这使得灵犀 X2 成为一台真正具备复杂交互能力,感知理解和认知世界的能力的灵动机器人。此外,得益于边缘侧大脑的端到端模型架构以及大量的工程优化,X2 实现了毫秒级的交互响应速度。
在视频展示中,能够 0 帧起手快速读取药品说明书,充分体现了其在复杂视觉信息处理和实时交互响应方面的强大性能!
除了功能上的显著提升,为了赋予灵犀 X2 更富人性化的特质,让它更有“人情味儿”,研究团队还在动作模态方面进行了精细的设计,为机器人融入了呼吸的韵律、人类的注意力机制等细节,使其行为举止更加自然生动:

稚晖君指出,人类对于理想机械伙伴的憧憬从未止步。 他强调,情感交互能力对于具身机器人至关重要。 因此,智元 X-Lab 将 Reaction-Agent 作为情感计算引擎,赋予了灵犀 X2 情感感知能力。
例如视频里,在问它:“与狗落水先救谁” 的伦理问题时,机器人能回答出符合人类价值观的回答。
除灵犀 X2 机器人本体外,智元 X-Lab 在本次发布中还宣布 开源具身智能仿真数据集,并同步发布了 RoboDual 大小脑系统架构 以及 最新 ViLLA 架构具身基座大模型 “启元” (GO-1)。 灵犀 X2 的核心能力其实就是源于 “启元” (GO-1) 基座大模型,通过 融合多模态大模型 (VLM) 与混合专家系统 (MoE),有效突破了传统具身智能的四大瓶颈。
- 泛化性不足
- 跨本体适配性差
- 数据利用率低
- 缺乏持续进化机制
(1) 感知层:实现多维信号整合与毫秒级场景理解
采用 InternVL-2B 模型整合多视角视觉、力觉反馈及语音输入,实现 毫秒级场景理解。 这种多模态感知能力赋予机器人 全面、精准的环境感知,为后续规划和决策提供 可靠依据。
例如,在复杂工业生产线上,灵犀 X2 能够 快速识别零件、设备位置与状态,以及工人操作意图,实现高效协同作业。
(2)规划层:Latent Planner 生成任务链优化任务执行流程
规划层搭载 GO-1 大模型的 Latent Planner 组件,通过 隐式动作标记 (Latent Action Tokens) 生成任务链,将复杂任务 分解为可执行的子任务。
例如, “叠衣服” 系统可将其细化为感知形状、调整角度等步骤,动态调整执行顺序和参数。
(3)执行层:Action Expert 生成精细动作序列
执行层由 Action Expert 组件 驱动,该组件基于百万级真机数据训练,能够生成 精细动作序列,
例如:在 “倒水” 任务中,其误差可控制在 ±3ml 以内,满足日常生活及工业生产的 高精度操作需求。
通过性能表现:GO-1 平均成功率提升 32%,生活场景任务成功率高达 78%
在五项标准任务测试中,GO-1 平均成功率较行业最优模型提升 32%。 其中,“倒水”、“清理桌面” 等生活场景任务成功率高达 78%,展现出 强大的通用性和实用性,
结语
总有人说人形机器人是浪漫主义陷阱,仿佛是对技术进步方向的误判。 然而,历史的车轮滚滚向前,总是在质疑声中碾压出新的道路。
莱特兄弟的飞机曾被嘲笑为异想天开,图灵的计算机也一度被视为庞大而无用的怪物。
如今看来,那些看似遥不可及的梦想,都成为了划时代的现实。
具身智能的发展亦是如此,它并非空中楼阁,而是技术演进的必然方向。 它承载着人类对自身能力延伸的渴望,对更智能、更人性化工具的追求。 与其说是浪漫主义的陷阱,不如说是人类理性与想象力交织的必然产物~
它预示着一个全新的智能时代即将到来,一个机器与人更紧密协作、共同进化的未来正在展开。
#Open-Sora 2.0
20万美元商业级视频生成大模型来了,权重、推理代码及训练流程全开源!
潞晨科技正式推出 Open-Sora 2.0 —— 一款全新开源的 SOTA 视频生成模型,仅 20 万美元(224 张 GPU)成功训练商业级 11B 参数视频生成大模型。开发高性能的视频生成模型通常耗资高昂:Meta 的视频模型训练需要 6000 多张 GPU 卡片,投入数百万美元。在多项关键指标上,它与动辄百万美元训练成本的模型分庭抗礼,全面提升视频生成的可及性与可拓展性。
今天,视频生成领域迎来开源革命!Open-Sora 2.0—— 全新开源的 SOTA(State-of-the-Art)视频生成模型正式发布,仅用 20 万美元(224 张 GPU)成功训练出商业级 11B 参数视频生成大模型,性能直追 HunyuanVideo 和 30B 参数的 Step-Video。权威评测 VBench 及用户偏好测试均证实其卓越表现,在多项关键指标上媲美动辄数百万美元训练成本的闭源模型。此次发布全面开源模型权重、推理代码及分布式训练全流程,让高质量视频生成真正触手可及,进一步提升视频生成的可及性与可拓展性。
- GitHub 开源仓库:https://github.com/hpcaitech/Open-Sora

1. 体验与指标双在线
1.1 震撼视觉:Open-Sora 2.0 Demo 先行
观看宣传片,体验 Open-Sora 2.0 的强大生成能力
,时长00:54
动作幅度可控:可根据需求设定运动幅度,以更好地展现人物或场景的细腻动作。
,时长00:05
,时长00:05
画质与流畅度:提供 720p 高分辨率和 24 FPS 流畅视频,让最终视频拥有稳定帧率与细节表现。
,时长00:05
,时长00:05
支持丰富的场景:从乡村景色到自然风光场景,Open-Sora 2.0生成的画面细节与相机运镜都有出色的表现。
,时长00:05
,时长00:05
1.2 11B 参数规模媲美主流闭源大模型
- 媲美 HunyuanVideo 和 30B Step-Video:Open-Sora 2.0 采用 11B 参数规模,训练后在 VBench 和人工偏好(Human Preference) 评测上都取得与用高昂成本开发的主流闭源大模型同等水平。
- 用户偏好评测:在视觉表现、文本一致性和动作表现三个评估维度上,Open Sora 在至少两个指标上超越了开源 SOTA HunyuanVideo,以及商业模型 Runway Gen-3 Alpha 等。以小成本获取了好性能。


- VBench 指标表现强势:根据视频生成权威榜单 VBench 的评测结果,Open-Sora 模型的性能进步显著。从 Open-Sora 1.2 升级到 2.0 版本后,与行业领先的 OpenAI Sora 闭源模型之间的性能差距大幅缩小,从之前的 4.52% 缩减至仅 0.69%,几乎实现了性能的全面追平。此外,Open-Sora 2.0 在 VBench 评测中取得的分数已超过腾讯的 HunyuanVideo,以更低的成本实现了更高的性能,为开源视频生成技术树立了全新标杆!
2. 实现突破:低成本训练与高效能优化
Open Sora 自开源以来,凭借其在视频生成领域的高效与优质表现,吸引了众多开发者的关注与参与。然而,随着项目的深入推进,也面临着高质量视频生成成本居高不下的问题。为解决这些挑战,Open Sora 团队展开了一系列卓有成效的技术探索,显著降低了模型训练成本。根据估算,市面上 10B 以上的开源视频模型,动辄需要上百万美元的单次训练成本,而 Open Sora 2.0 将该成本降低了 5-10 倍。

作为开源视频生成领域的领导者,Open-Sora 不仅继续开源了模型代码和权重,更开源了全流程训练代码,成功打造了强大的开源生态圈。据第三方技术平台统计,Open-Sora 的学术论文引用量半年内获得近百引用,在全球开源影响力排名中稳居首位,领先所有开源的 I2V/T2V 视频生成项目,成为全球影响力最大的开源视频生成项目之一。

2.1 模型架构
Open-Sora 2.0 延续 Open-Sora 1.2 的设计思路,继续采用 3D 自编码器和 Flow Matching 训练框架,并通过多桶训练机制,实现对不同视频长度和分辨率的同时训练。在模型架构上,引入 3D 全注意力机制,进一步提升视频生成质量。同时,采用最新的 MMDiT 架构,更精准地捕捉文本信息与视频内容的关系,并将模型规模从 1B 扩展至 11B。此外,借助开源图生视频模型 FLUX 进行初始化,大幅降低训练成本,实现更高效的视频生成优化。
2.2 高效训练方法和并行方案全开源
为了追求极致的成本优化,Open-Sora 2.0 从四个方面着手削减训练开销。首先,通过严格的数据筛选,确保高质量数据输入,从源头提升模型训练效率。采用多阶段、多层次的筛选机制,结合多种过滤器,有效提升视频质量,为模型提供更精准、可靠的训练数据。

其次,高分辨率训练的成本远超低分辨率,达到相同数据量时,计算开销可能高达 40 倍。以 256px、5 秒的视频为例,其 tokens 数量约 8 千,而 768px 的视频 tokens 数量接近 8 万,相差 10 倍,再加上注意力机制的平方级计算复杂度,高分辨率训练的代价极其昂贵。因此,Open-Sora 优先将算力投入到低分辨率训练,以高效学习运动信息,在降低成本的同时确保模型能够捕捉关键的动态特征。

与此同时,Open-Sora 优先训练图生视频任务,以加速模型收敛。相比直接训练高分辨率视频,图生视频模型在提升分辨率时具备更快的收敛速度,从而进一步降低训练成本。在推理阶段,除了直接进行文本生视频(T2V),还可以结合开源图像模型,通过文本生图再生视频(T2I2V),以获得更精细的视觉效果。
最后,Open-Sora 采用高效的并行训练方案,结合 ColossalAI 和系统级优化,大幅提升计算资源利用率,实现更高效的视频生成训练。为了最大化训练效率,我们引入了一系列关键技术,包括:
- 高效的序列并行和 ZeroDP,优化大规模模型的分布式计算效率。
- 细粒度控制的 Gradient Checkpointing,在降低显存占用的同时保持计算效率。
- 训练自动恢复机制,确保 99% 以上的有效训练时间,减少计算资源浪费。
- 高效数据加载与内存管理,优化 I/O,防止训练阻塞,加速训练流程。
- 高效异步模型保存,减少模型存储对训练流程的干扰,提高 GPU 利用率。
- 算子优化,针对关键计算模块进行深度优化,加速训练过程。
这些优化措施协同作用,使 Open-Sora 2.0 在高性能与低成本之间取得最佳平衡,大大降低了高质量视频生成模型的训练。
2.3 高压缩比 AE 带来更高速度
在训练完成后,Open-Sora 面向未来,进一步探索高压缩比视频自编码器的应用,以大幅降低推理成本。目前,大多数视频模型仍采用 4×8×8 的自编码器,导致单卡生成 768px、5 秒视频耗时近 30 分钟。为解决这一瓶颈,Open-Sora 训练了一款高压缩比(4×32×32)的视频自编码器,将推理时间缩短至单卡 3 分钟以内,推理速度提升 10 倍。

要实现高压缩比编码器,需要解决两个核心挑战:如何训练高压缩但仍具备优秀重建效果的自编码器,以及如何利用该编码器训练视频生成模型。针对前者,Open-Sora 团队在视频升降采样模块中引入残差连接,成功训练出一款重建质量媲美当前开源 SoTA 视频压缩模型,且具备更高压缩比的 VAE,自此奠定了高效推理的基础。

高压缩自编码器在训练视频生成模型时面临更高的数据需求和收敛难度,通常需要更多训练数据才能达到理想效果。为解决这一问题,Open-Sora 提出了基于蒸馏的优化策略,以提升 AE(自编码器)特征空间的表达能力,并利用已经训练好的高质量模型作为初始化,减少训练所需的数据量和时间。此外,Open-Sora 还重点训练图生视频任务,利用图像特征引导视频生成,进一步提升高压缩自编码器的收敛速度,使其在更短时间内达到一定生成效果。
Open-Sora 认为,高压缩比视频自编码器将成为未来降低视频生成成本的关键方向。目前的初步实验结果已展现出显著的推理加速效果,希望能进一步激发社区对这一技术的关注与探索,共同推动高效、低成本的视频生成发展。
3. 加入 Open-Sora 2.0,共同推动 AI 视频革命
今天,Open-Sora 2.0 正式开源!
- GitHub 开源仓库:https://github.com/hpcaitech/Open-Sora
- 技术报告:https://github.com/hpcaitech/Open-Sora-Demo/blob/main/paper/Open_Sora_2_tech_report.pdf
欢迎加入 Open-Sora 社区,探索 AI 视频的未来!
Open-Sora 2.0,未来已来。让我们用更少的资源、更开放的生态,创造属于下一代的数字影像世界!
#Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
通常来说,这些方法在训练模型时可以产生比典型正确解决方案更长的轨迹,并包含了试图实现某些「算法」的 token:例如反思前一个答案、规划或实现某种形式的线性搜索。这些方法包括显式地微调预训练 LLM 以适应算法行为,例如对搜索数据进行监督微调(SFT)或针对 0/1 正确性奖励运行结果奖励(outcome-reward,OR)RL。
虽然通过「结果奖励 RL 生成长推理链」的方式来训练模型消耗测试时计算的前景看好,但为了继续从扩展测试时计算中获得收益,我们最终需要回答一些关键的理解和方法设计问题。
第一个问题:当前的 LLM 是否高效使用了测试时间计算?也就是说,它们是否消耗了与典型解决方案长度大致相当的 token,或者它们是否在简单的问题上使用了太多 token?
第二个问题:当运行测试时 token 预算远大于用于训练的 token 预算时,LLM 是否能够「发现」用于更难问题的解决方案?最终,我们希望模型能够从它们生成的每个 token(或任何语义上有意义的片段)中获得足够的效用,这不仅是为了提高效率,还因为这样做可以形成一个系统化的流程来发现更难、分布外问题的解决方案。
在本文中,CMU、HuggingFace 的研究者提出从元强化学习(RL)的视角来形式化上述优化测试时计算的挑战。
- 论文标题:Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
- 论文地址:https://arxiv.org/pdf/2503.07572
- 项目主页:https://cohenqu.github.io/mrt.github.io/
在构建方法的过程中,研究者在给定问题上将 LLM 的输出流分割成多个片段(图 2)。如果我们只关心效率,那么 LLM 应该只学习利用并直接输出最终答案,而无需耗费太多片段。另一方面,如果 LLM 仅专注于发现(discovery),那么探索就更可取,这样 LLM 就可以耗费几个片段来尝试不同的方法,并进行验证和修改,然后得出最终答案。
从根本上说,这与传统的 RL 不同,这里的目标是学习一个可以在每个测试问题上实现探索 - 利用算法的 LLM。换句话说,本文的目标是从训练数据中学习这样的算法,使其成为一个「元」RL 学习问题。

理想的「元」行为是在过早采用一种方法(即「利用」片段)和尝试过多高风险策略(即「探索」片段)之间取得平衡的行为。从元 RL 文献中,我们知道探索和利用的最佳权衡相当于最小化输出 token 预算的累积悔值。这种悔值衡量了 LLM 与一个 oracle 比较器成功可能性之间的累积差异,如图 1 (b) 中的红色阴影区域所示。

通过训练 LLM 来最小化每个查询的累积悔值,本文学习了一种在某种程度上与测试时预算无关的策略,即在部署时 LLM 仅耗费必要数量的 token,同时在更大的 token 预算下运行时仍会取得进展。
具体地,研究者利用一类新的微调方法来优化测试时计算,通过最小化累积悔值的概念产生了一种被称为元强化微调(Meta Reinforcement Fine-Tuning,MRT)的解决方案(或范式),从而为评估现有推理模型(如 Deepseek-R1)在使用测试时计算的有效性提供了一个指标。
研究者发现,使用结果奖励 RL 进行微调的 SOTA LLM 无法通过更多片段来提高发现正确答案的概率,即它们没有取得稳定的「进展」(如上图 1 (a) 所示),即使这种行为对于发现未见过难题的解决方案至关重要。事实上,在 FLOPs 匹配的评估中,运行更少片段并结合多数投票的更简单方法通常对较难的问题更有效(下图 3)。
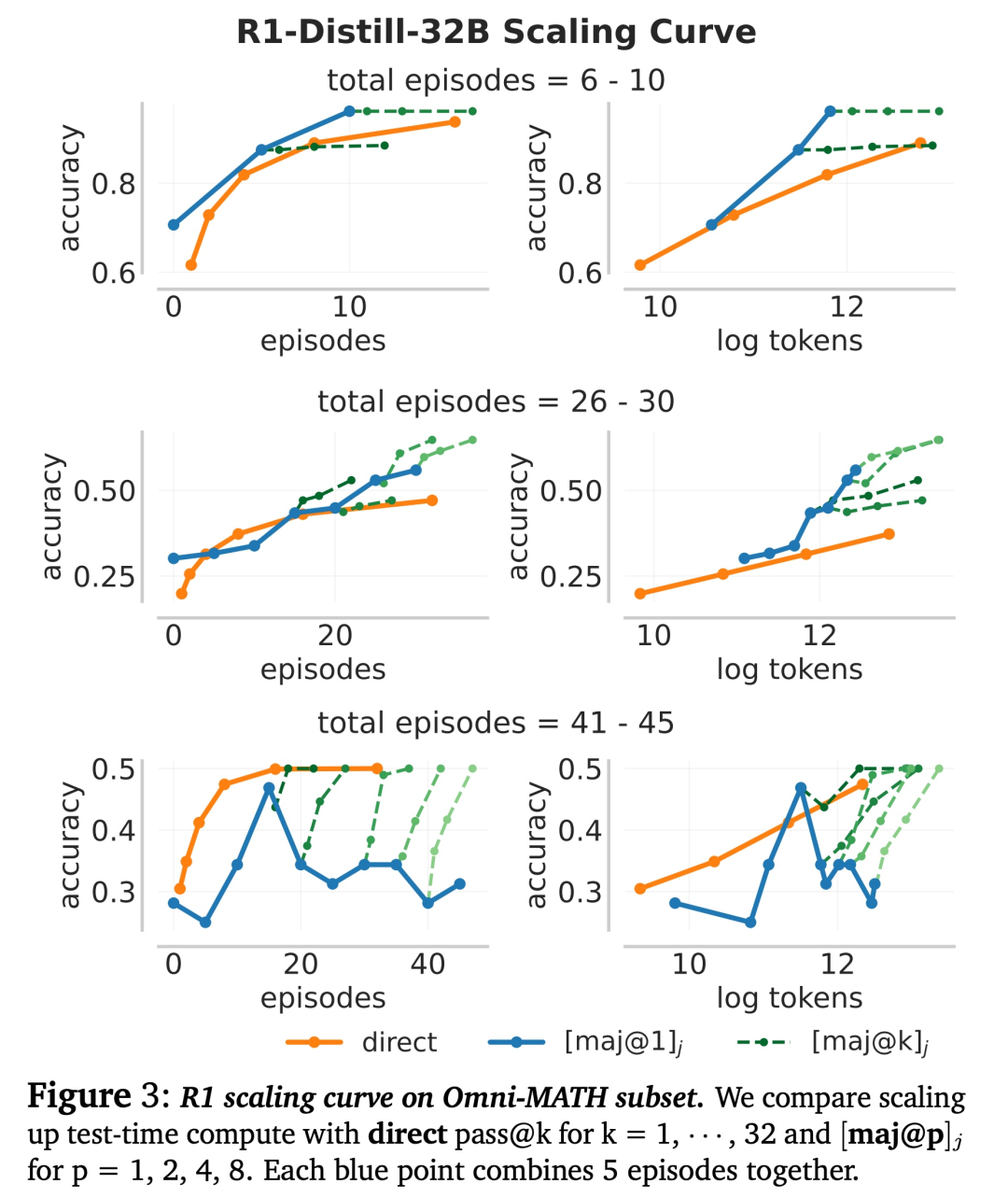
相反,研究者表明,当目标是最小化悔值时,除了结果奖励之外,对进展的优化也会自然而然出现。本文的微调范式 MRT 为 RL 训练规定了密集的奖励(reward bonus)。直观地说,这一进展奖励衡量了在生成给定片段之前和之后获得正确答案的似然的变化。
在实验部分,研究者在两种设置下对 MRT 进行了评估,二者的不同之处在于它们对片段进行参数化的方式。对于第一种设置,他们对基础模型进行微调,包括 DeepScaleR-1.5B-Preview、DeepSeek-R1-Distill-Qwen-1.5B 和 DeepSeekR1-Distill-Qwen-7B,并采用了数学推理问题数据集。
结果发现,MRT 的表现始终优于结果奖励强化学习,在多个基准测试(AIME 2024、AIME 2025、AMC 2023 等)上取得了 15 亿参数规模的 SOTA 结果,其相较于基础模型的准确率提升是标准结果奖励 RL(GRPO)的约 2-3 倍,而 token 效率是 GRPO 的 1.5 倍、是基础模型的 5 倍。GRPO 是 DeepSeek-R1 的关键强化学习算法。
对于第二种设置,研究者对 Llama 3.1 进行微调以实现回溯,结果表明,MRT 相较于 STaR 和 GRPO 均实现了 1.6-1.7 倍的 token 效率提升。
元强化微调(MRT)范式
MRT 的目标是直接学习一种与预算无关(budget-agnostic)的 LLM,使其能够稳步取得进展。

该研究使用在线强化学习方法(如 GRPO)实现元强化学习范式。下面是它的工作原理:
该研究定义了一个元证明器策略(Meta-Prover Policy)μ,用于评估一个片段对解决问题的贡献程度。该策略的工作方式如下:
- 强制终止当前的思考块(thought block),使用「time is up」提示(prompt);
- 让模型根据当前的推理前缀(reasoning prefix)生成其最佳猜测的解决方案。
对于推理过程中的每一个片段,需要这样操作:
- 使用元证明器策略 μ 计算思维前缀的奖励;
- 基于这个前缀采样多个策略内的轨迹(rollouts),这些轨迹被均匀分配为:继续进一步推理;终止思考轨迹并生成最佳猜测的解决方案;
- 根据对进展(progress)的奖励,然后计算进展奖励。
在训练过程中,该研究优化了包含标准结果奖励和基于进展的密集奖励奖励的 MRT 目标函数:

实验结果
实验评估了 MRT 在优化「测试时计算」资源方面的有效性。
如表 1 所示,MRT 的表现优于在相同数据集上未使用密集奖励训练的模型。

此外,该研究还得出了以下结论:
- 基于 DeepScaleR-1.5B-Preview 基础模型微调的模型达到了其规模下 SOTA 水平。由于模型在经过蒸馏或已经经过强化学习(RL)训练的基础模型上进行了训练,因此绝对性能提升较小。然而,与基于结果奖励的 RL 方法(如 GRPO)相比,使用 MRT 的相对性能提升约为 2-3 倍。
- 当使用 DeepScaleR-1.5B 模型在 AIME 问题数据集上进行微调时,MRT 不仅在 AIME 2024 和 AIME 2025 评估集上取得了更好的性能(这或许在意料之中),而且在相对于结果奖励强化学习(RL)分布外的 AMC 2023 数据集上也保持了较好的性能。
MRT 对 token 的处理效率
前文我们已经看到 MRT 可以在 pass@1 准确率上超越标准的结果奖励强化学习(RL)。接下来,作者尝试评估 MRT(RL)在 token 效率上是否可以带来提升。
如图 7 所示,MRT 在 AIME 2024 数据集上,在相同 token 数量的情况下,平均准确率比基础模型高出 5%。此外,MRT(RL)在 AIME 2024 上所需的 token 数量比基础模型少 5 倍,在 MATH 500 上少 4 倍,就能达到相同的性能(本例中使用的是 DeepSeek-R1 蒸馏的 Qwen-1.5B 模型)。
同样地,MRT 在 token 效率上比结果奖励 RL 提高了 1.2-1.6 倍。这些结果表明,MRT 在保持或提升准确率的同时,显著提高了 token 效率。

回溯搜索设置中的线性化评估
在这种设置中,模型被限制为先生成一个解决方案,接着进行错误检测,最后在进行修正(如图 5 所示)。

该研究首先对基于 Llama-3.1-8B 模型微调的 MRT 的 STaR 变体进行评估。如图 8(左)所示,MRT 在两种评估模式下(并行模式为实线;线性化模式为虚线)均实现了最高的测试效率,并在线性化评估模式下将效率提高了 30% 以上。
图 8(右)显示,与结果奖励 GRPO 相比,MRT(RL)通过减少 1.6 倍的 token 来提升线性化效率。

#长链推理表象下,大模型精细表征张冠李戴的本质
些年,大模型的发展可谓是繁花似锦、烈火烹油。从 2018 年 OpenAI 公司提出了 GPT-1 开始,到 2022 年底的 GPT-3,再到现在国内外大模型的「百模争锋」,DeepSeek 异军突起,各类大模型应用层出不穷。
然而,无论在学术界还是在工业界,目前对大模型应用的评测都是单纯在模型输出层面判断结果的准确性,而没有从大模型内在精细决策逻辑的角度来分析模型的可靠性。类比到人类社会,「实现内在精细逻辑对齐」才是实现人与人互信的基础。
- 论文标题:Alignment Between the Decision-Making Logic of LLMs and Human Cognition: A Case Study on Legal LLMs
- Arxiv 地址:https://arxiv.org/abs/2410.09083
无法在内在逻辑上与人类认知沟通,也恰恰是黑盒智能模型无法取得信任的本质——在可信问题上的「人」「机」有别,其主要问题并不在哲学、社会学方面,而是一个数学问题:能否严格地证明神经网络在单个样本上输出背后的千万种不同变换,都可以在数值上严格表示为一个简单的逻辑图模型。
但是,因为神经网络的复杂结构与所需要的清晰逻辑解释是天然冲突的,所以「从数学上严格地解释大模型内在的精细决策逻辑」长期以来被认为是一个不可能完成的问题。好在沉舟侧畔千帆过,柳暗花明又一村。我们构建了等效交互理论体系,发表了几十篇论文,在一定程度上证明并成功实现了对大部分神经网络的符号化解释。
相关链接:
https://zhuanlan.zhihu.com/p/693747946
https://mp.weixin.qq.com/s/MEzYIk2Ztll6fr1gyZUQXg
大模型金玉其外,败絮其中
一旦有了严谨的解释性理论工具,当我们可以清晰地解构出大模型的内在决策逻辑时,我们惊讶地发现,哪怕大模型在特定任务上展现出再高的准确率,其内在的决策逻辑表征可谓是一塌糊涂,甚至一半以上都是混乱的、完全与正常推理逻辑不沾边的。
很多应用需求是创造出来的。比如,在新的研究 [3] 中,我们以法律大模型为例,目前几乎所有的法律大模型应用仅仅关注判案结果的正确性,而忽视了法律推理过程中可能潜在的不公平和伦理风险。
然而,当你第一次确切地解构出一个法律大模型所使用的大量复杂、却又一塌糊涂的决策逻辑时,当你在各种情景中验证了这些错误逻辑的客观存在及其数值严谨性时,很多认知就回不去了,就像见过元素周期表以后,五行炼丹也就回不去了。
我们发现,法律大模型经常错误地将与案件无关的时间、位置信息视为法律判决的理由,或者「张冠李戴」地将一个被告的行为引为其他被告的判案依据。
时代洪流滚滚向前,让我们看看都发生了什么。

图 1. 对 SaulLM-7B-Instruct 在案例 1 的解释
让我们考虑一个输入案例

,它包含
![]()
个输入变量(这里可以是案例中的各个短语),我们用集合

表示这些输入变量的全集。由大模型生成的一个包含
![]()
个 tokens 的自然语言序列,

。这样,大模型输出结果的置信度得分

可以定义为:

其中,

表示在生成第
![]()
个 token 之前的前

个tokens 组成的序列。

表示给定输入句子
![]()
和前

个tokens 的条件下生成第
![]()
个token的概率。
这样,我们可以构造出一个「与或交互逻辑模型」。

这个逻辑模型中包含「与交互」和「或交互」两类操作。触发函数

表示一个「与交互」,当且仅当集合

中全部输入变量都被包含(没有被遮挡)在样本

时,函数

被激活,并返回 1;否则返回 0。
类似地,触发函数

表示一个「或交互」,当集合

中任一输入变量被包含(没有被遮挡)在样本

时,函数

被激活,并返回 1;否则返回 0。
无限拟合性:我们证明,无论我们如何随机遮挡
![]()
个输入单元,得到
![]()
个不同的遮挡输入,构造出的与或交互模型总可以精确近似出神经网络在这所有
![]()
个遮挡状态下对生成目标的输出置信度得分。

这里
![]()
表示遮挡输入样本
![]()
中属于集合

中的输入单元,仅保留属于集合

中的输入单元的遮挡样本。

图 2. 与或交互的无限拟合性
需要注意的是,与或交互解释显示,不同于惊艳的应用性能所展示的对大模型推理能力的想象,大模型的大部分决策逻辑并不是严密的、清晰的、层次化的逻辑链条,大部分交互概念仅仅表示词汇之间的统计关联性。类似于「词袋」模型,当大模型基于输入 prompt 生成下一个单词或 token 时,其所依赖的交互效用大部分并没有利用输入上下文之间的逻辑关系,大部分决策依赖于词汇间最浅表的统计关联性来「盲猜」目标单词。
比如,在上文案例中,大模型仅仅根据「chased」为生成的判决结果「Assault」给出了 0.3811 的置信度,而单独一个「with an axe」短语也会为「Assault」判决增加 0.4632 的置信度。
固然这些单词与判决结果有统计意义的强相关性,但是大模型的决策依据并没有试图建模这些单词与犯罪嫌疑人之间的切实关系,并没有理解哪些犯罪嫌疑人做了什么事儿,也就导致了大模型可能产生一些看似正确的结果,但是其推理过程中可能潜在巨大的伦理风险。
例如,在下面的案例中我们将展示大模型常常将不同犯罪嫌疑人的行为进行张冠李戴,使其他犯罪嫌疑人的行为影响到目标犯罪嫌疑人的判罚。
案例:张冠李戴,根据其他犯罪嫌疑人的行为做出判决
模型:BAI-Law-13B [1]
输入:On the morning of December 22, 2013, the defendants Andy and Bob deceived Charlie and the three of them had an argument. Andy chased Charlie with an axe and bit Charlie, causing Charlie to be slightly injured. Bob hit Charlie with a shovel, injuring Charlie and shovel causing Charlie's death.
输出:Intentional Injury,输出置信度数值 2.3792

图 3. 对 BAI-Law-13B 模型和 SaulLM-7B-Instruct 模型在案例 1 上的解释
法律 LLM 很大一部分交互模式错误地使用了犯罪嫌疑人的行为来对另一个无关的犯罪嫌疑人做出判决,显示出大模型存在的一种典型缺陷——张冠李戴。
大模型倾向于记忆敏感词语(如武器)与输出结果之间的相关性,而不是理解输入 prompt 中真正的逻辑,例如识别谁做了哪些行为。
案例显示,Andy 咬伤 Charlie,构成伤害罪,随后 Bob 用铁锹击打 Charlie,导致 Charlie 死亡。案例经由法律专家将与判决相关的实体行为标记为相关词语,与判决不相关的词语标记为不相关词语,以及将不应影响判决的不正确的实体行为标记为禁止词语。
在这起案件中,当法律大模型判决 Andy 行为的后果时,「hit」「with a shovel」「injuring」和「death」等描述 Bob 的行为和后果的词语应被标记为禁止词语,与Andy没有直接关系。
在英文法律大模型 SaulLM-7B-Instruct 前 50 个最突出的 AND-OR 交互模式中,有 26 个 AND 交互模式和 24 个 OR 交互模式。如图 1,可以看出 AND 交互模式

,AND 交互模式

,OR 交互模式

分别对 Andy 的判决贡献了显著的可靠交互效应 = 0.47、= 0.33、= 0.09。然而,大模型也使用了描述 Bob 的行为和后果的禁止词语得出对 Andy 的判决,例如,AND 交互模式

,

,

等对 Andy 的判决产生不可靠的交互效应 = -1.04、= 0.93、= 0.19。
在中文法律大模型 BAI-Law-13B 前 50 个最突出的 AND-OR 交互模式中,有 17 个 AND 交互模式和 33 个 OR 交互模式。如图 3,可以看出 AND 交互模式

,AND 交互模式

,OR 交互模式

分别对 Andy 的判决贡献了显著的可靠交互效应 = 0.33、= 0.17、= 0.06。然而,大模型也使用了描述 Bob 的行为和后果的禁止词语得出对 Andy 的判决,例如,AND 交互模式
![]()
,OR 交互模式

,
![]()
等对 Andy 的判决产生不可靠的交互效应 = -0.43、= -0.09、= -0.04。
这里大模型用的不可靠交互比例为 55.5%-58.5%。

图 4.交互概念解释率先揭示了大模型精细表征逻辑的隐患。大模型没有建模「长链推理」逻辑,而使用大量「张冠李戴」的局部信息来生成判决结果,引起了不容忽视的伦理问
图 4 展示了 BAI-Law-13B 模型在中文案例上的解释,判案所依据的大部分交互概念都是与目标犯罪嫌疑人无关的张冠李戴的交互概念。
参考文献
[1] Baiyulan Open AI Research Institute. 2023. Baiyulan Open AI. (2023). https://baiyulan.org.cn
[2] Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, and Michael Desa. SaulLM-7B: A pioneering Large Language Model for Law. arXiv preprint arXiv:2403.03883 (2024)
[3] Lu Chen, Yuxuan Huang, Yixing Li, Yaohui Jin, Shuai Zhao, Zilong Zheng, Quanshi Zhang, "Alignment Between the Decision-Making Logic of LLMs and Human Cognition: A Case Study on Legal LLMs" in arXiv:2410.09083, 2024.
#阿里妈妈搜索广告2024大模型思考与实践
一、概览
随着大模型时代的到来,搜推广模型是否具备新的进化空间?能否像深度学习时期那样迸发出旺盛的迭代生命力?带着这样的期待,阿里妈妈搜索广告在过去两年的持续探索中,逐步厘清了一些关键问题,成功落地了多个优化方向。如今,我们更加坚定地认为,搜推广模型与大模型的结合蕴藏着巨大的想象空间和业务价值。本文将从以下几个方面分享和交流 2024 年的思考与实践:
- 在这场变革性的技术交替之际,回顾搜推广模型的历史演进,抓住三条关键路径(明线、暗线和辅助线)有助于更清晰地理解技术升级的内在逻辑。同时,明确如何在新时期系统性发挥算力优势,深度挖掘搜推广领域的 Scaling Law,已成为推动技术进步的核心路线。
- 作为新技术探索的前哨站,预估模型通过与大模型的深度结合,全面提升感知与推理能力。在感知层面,专注于解决内容语义信息与行为协同信息的融合问题,持续优化多模态表征的质量,突破传统 ID 表征体系的局限,逐步实现对客观世界更丰富的感知建模;在推理层面,构建用户行为序列大模型,将生成式方法与判别式方法有机结合,探索推理能力的持续进化之路。
- 大模型正在全面重塑搜索广告系统。依托预训练(pre-train)与后训练(post-train)的模型迭代新范式,阿里妈妈自主研发了广告领域专属大模型 LMA(Large Models for Advertising),并于 2024 年 4 月随业务宣推。LMA 是电商基座大模型衍生出来的广告模型集合,迭代分支包括认知、推理和决策。新财年以来,LMA 持续优化,认知分支聚焦多模态表征,推理分支聚焦搜推广领域的用户行为大模型等。这些技术进展不仅推动预估环节实现多个版本迭代上线,还深度改造了召回、改写、相关性和创意等核心技术模块,推动技术体系全面升级。
二、模型演进规律和大模型迭代趋势
和深度学习时期相比,大模型时期的搜推广模型既有一脉相承之处,也有推陈出新的地方。回顾过往,模型能力的突破主要沿三条路径演进:
- 明线,归纳偏置(Inductive Bias)的合理设计,是模型能力提升的核心驱动力。
- 暗线,硬件算力的指数级提升,为模型的规模化提供了强力支撑。
- 辅助线,CV 和 NLP 领域的代际性技术升级,给搜推广领域带来重要启发。

2.1. 明线 - 归纳偏置
所谓明线,即大家表面能够看到的模型结构的演变,其本质是对归纳偏置的合理设计与实现。归纳偏置体现了模型在学习过程中对特定假设和结构的先验偏好,它在数据有限的情况下能够有效约束参数搜索空间,提升模型的泛化能力。例如 CV 领域广泛应用的模型结构 CNN,背后的归纳偏置就是图像在局部空间的平移不变性。
类似地,搜推广模型在用户行为预测建模上也有自己的归纳偏置。例如,如何设计模型结构以充分捕捉用户行为的多样性、动态演化、局部敏感性及时序依赖关系等;如何优化 Embedding 结构及训练范式,使其能够有效适配 ID 特征的高维稀疏和幂律分布等统计特性。所以,每一次看得见的模型结构升级,都是对归纳偏置的更深层次理解与实现。
2.2. 暗线 - 算力
所谓暗线,即模型能力升级的内在演进逻辑,就是借助算力的东风不断提升模型规模化的能力。若明线似看得见的招式,则暗线似看不见的内功。如何修炼内功,优化底层训练和推理架构,充分利用摩尔定律与黄氏定律带来的算力提升,使得模型参数规模持续增长。这正是近年来模型演进的核心旋律。
然而,算力的指数级增长主要体现在计算能力上,“内存墙” 依然高筑,存储与带宽仍是系统的瓶颈。对于搜推广模型而言,其训练的主要挑战在于稀疏 Embedding 的访问与计算,如何进行算法与工程的深度联合优化,提升计算与通信的占比,最大化 GPU 计算利用率,成为释放算力潜能和推动模型规模化的关键。
某种程度上,搜推广模型比其他领域更早认识到 Scaling Law(缩放定律)的重要性。与 CV 和 NLP 领域不同,搜推广模型依赖于高维稀疏的 ID 特征体系,因此其规模化方向并非向 Deeper 方向生长,而是朝着 Wider 方向扩展。如果以 LLM 常用的 Token 规模作为对比,我们的场景中一天的样本所对应的 Token 规模已达到 T 级别,与 GPT-3 公开的数据相当,且模型的训练还需涵盖多年样本,数据量远超一般 LLM 训练范畴。
因此,长期以来,增加样本规模、特征个数和 Embedding 维度等共同支撑了 Wider 方向 Scaling Law 的第一增长曲线。然而,随着时间推移,这一增长曲线的边际效益正逐渐递减,促使我们重新思考:搜索推广模型是否也有向 Deeper 方向扩展的机会?接下来,我们将重点探讨这一可能性。
2.3. 辅助线 - CV&NLP 领域
搜推广模型作为 AI 应用领域的重要分支,深受整个 AI 技术的发展影响。纵观整个 AI 发展史,CV 和 NLP 领域的技术相互借鉴、交相辉映,每一轮技术革新都推动着 AI 迈向新的高度,起到了引领和破圈的效应。对应地,搜推广模型在发展过程中既面临 AI 领域的共性问题,也有自身业务属性的特色问题。其中关于共性问题,CV 和 NLP 的技术突破就是很好的辅助线,给到搜推广模型重要启发,加速创新。
搜推广模型经历的几次重大技术变革,和 CV 和 NLP 领域的创新息息相关,沿着时间线:
- AlexNet 在 ImageNet 竞赛中的突破性成功表明了 DNN 巨大潜力,搜推广开启 DNN 时代;
- Word2Vec 奠定了表征基础,启发了 Embedding 技术在搜推广的广泛应用;
- Attention 机制对翻译任务的大幅提升,深刻影响用户行为兴趣建模;
- 基于 Transformer 结构的训练范式的普及,推动了对比学习、掩码学习、预训练 & 迁移学习等各种迭代模式的兴起。
当然了,搜推广模型的实践也会反哺 AI 领域的发展,例如基于用户反馈的强化学习和出于性能敏感的蒸馏、剪枝、低秩和量化等技术。如今,LLM 又开启了大模型的新时代。
2.4. 大模型时期的迭代主线
综上,新的辅助线看来会延伸更远,LLM 已彻底重塑 NLP,搜推广模型的演进思路也会随之发生深刻变化。
- 一方面,从算力(暗线)角度来看,Scaling Law 在稀疏的 Wider 方向已经清晰呈现出第一增长曲线,新时期需要探索稀疏往稠密的转变,走出 Deeper 的新增长;
- 另一方面,从归纳偏置(明线)角度来说,人工先验的归纳偏置由精细化设计往朴素化范式转变。正如《The Bitter Lesson》所言:“AI 发展史最苦涩的教训是:试图将我们认为的思维方式硬编码进 AI,长期来看是无效的。唯一重要的,是那些能够随着计算能力增长而扩展的通用方法”。这一点尤为感同身受,过去依赖精巧结构设计的短期收益,往往在算力提升的长期趋势下变得微不足道,甚至某些复杂结构反而成为算力扩展的障碍。真正支撑生产服务的模型,最终仍会朝着紧凑、简约、高效的方向收敛,以适应计算资源的可扩展性和实际业务需求。
所以,大模型时期的迭代主线:弱化归纳偏置,强化数据驱动,设计通用且高效的模型结构,让模型从数据中自动学习复杂模式,充分挖掘算力潜能,探索出稀疏 Wider 方向往稠密 Deeper 方向扩展的新路径。这就是我们研发 LMA 系列模型的核心认知。
三、预估模型与大模型结合
LLM 的横空出世让各领域纷纷探索其应用潜力,搜推广系统也不例外。关于 LLM 在搜索和推荐系统中的原生应用,业界已有诸多优秀综述,技术分类体系阐述非常完善,很有启发,本文不再赘述。鉴于算力现实和性能约束,我们更关注短期内的落地可行性,所以本文将从渐进式优化的视角,回顾并整理 CTR 预估模型与大模型结合的思考与实践。
前文已经论述了大模型时期我们认为的迭代主线,即弱化归纳偏置,强化数据驱动,探索搜推广模型的稠密 Deeper 方向的规模化之路。CTR 模型经过多年的迭代积累,形成最具迭代生命力的两个提效方向 ——Embedding 建模和用户行为兴趣建模。两者均遵循 Wider 的规模化思路,不断增加特征个数、不断扩长用户行为规模、不断延展 Embedding 的维度等,取得持续不断的收益。但是 Deeper 的规模化始终没有像 CV 和 NLP 模型那么顺利,CTR 模型似乎搞到几十层没有意义,反而会适得其反。
最关键的认知破局点在于,CTR 任务的判别式模式太简单了,让模型判别是否点击这类的 1bit 信息量的答案,相较于 Next Token Prediction 的生成式而言,求解空间过小。如此,在不改变判别式任务的情况下,模型仅依靠强能力的高维稀疏 ID Embedding 就能做好大部分的记忆工作,浅层的 Dense 参数只需要承担部分的泛化能力就好,这样模型始终有 Deeper 方向规模化的瓶颈。所以,我们认为三阶段的迭代范式 ——“Pre-train + Post-train + CTR” 可以破局,Deeper 方向规模化的重任交由 Pre-train 和 Post-train 完成。下面分别介绍新范式下我们对 Embedding 建模和用户行为兴趣建模的改造,对应两个关键词 ——“多模态” 和 “生成式”。
3.1. 感知 - 多模态表征模型
深度学习时期的 CTR 模型以 ID 特征体系为基石,ID Embedding 的参数规模占据整个模型的 90% 以上,其表征质量决定了模型预估能力的基础。然而,ID Embedding 体系长期面临一个核心挑战,就是其过度依赖历史统计数据,对长尾和冷启数据极为不友好,且这类数据是搜推广业务的核心问题。随着 Embedding 参数规模化的收益边际增长速率逐渐放缓,和关于数据稀疏的瓶颈问题日益凸显,我们需要探索新的 Embedding 技术体系。
我们开始重新审视 ID 形式的特征表达,认为 ID 仅仅是客观世界的代理表达,但是模型对世界的感知应该更加原生和直接。常理思考,用户对于一个 item 是否感兴趣、是否会发生点击行为,本质是 item 的内容视觉表达是否吸引到用户,所以直接建模原生视觉表达会更为本质。于是,过去两年我们重点建设多模态 MM Embedding 技术体系,并将其应用到用户行为兴趣建模中,打造朴素但强大的视觉兴趣模型(MIM:Multi-modal content Interest Modeling)。
视觉兴趣模型 MIM 采用 “Pre-train + Post-train + CTR” 的迭代范式,核心考虑就是将 Deeper 方向的参数规模化交由 Pre-train 和 Post-train 来实现,前序阶段的训练目标就是产出高质量的 MM Embedding,然后基于 MM Embedding 的视觉兴趣建模由 CTR 任务来高性价比地完成。该范式有诸多优势,包括多模态能力可以及时追踪前沿开源技术、CTR 任务能够保持性能和迭代的高效、Deeper 方向的规模化可以有规划性的持续迭代、生产关系可以解耦并各司其职地有序开展等。这些优势在过去两年的模型升级中体现得淋漓尽致,这也是我们没有采用端到端建模路线的原因。
高质量 MM Embedding 生成的核心是承载语义信息的内容空间与承载协同信息的兴趣空间如何有效对齐,模型架构就是多模态领域的稠密模型。稠密模型和 CTR 任务的稀疏模型相比,语义理解比统计判别任务相对更难,几十层的模型架构更为主流,给 Deeper 方向规模化带来空间。Pre-train 职责是 Encode,负责内容空间的理解与迁移,关注图文是什么,多模态对齐能力的持续优化是基础,将开源世界知识往电商知识迁移是关键;Post-train 职责是 Align,负责内容空间与兴趣空间的对齐,关注用户行为反馈、凸显图文吸引要素,高质量的训练样本和找到与下游 CTR 任务正相关的中间指标是关键。另外,这两个阶段也有着共同的优化主线:
- 训练模式,包括分类、对比学习、掩码学习、自回归学习等,且 backbone 紧随主流更迭,包括 BEiT3、BGE、BLIP2、EVA2 等。
- 数据质量,图文质量包括视觉强相关的主体和关键词识别,难正负样本挖掘,结合行业特色挖掘兴趣样本例如拍立淘的图搜场景等。
- 规模效应,包括图片尺寸、训练样本和模型参数,模型尺寸经历了 0.1B、1B 和 10B 的升级过程,是 Deeper 方向规模化的主要路径。
有了高质量的 MM Embedding,CTR 阶段的兴趣建模就回归传统、轻车熟路,基于 Target-Attention 机制将 ID Embedding 升级为 MM Embedding 就可以灵活高效地建模用户视觉偏好。整个算法框架就如此运作,三个阶段既是互相解耦又是相互联系。同时,关于 Pre-train 和 Post-train 的稠密模型框架和 CTR 的稀疏模型框架的有机结合,工程侧在离线和在线环节都做了相应的架构升级和性能优化。至今,MIM 模型共上线 4 期,分别在过去两年的大促(2023&2024-618 & 双 11)全量上线,每期都有大约整体 CTR+5%、长尾 CTR+10% 的显著提效。

欢迎探讨,【MIM】MIM: Multi-modal Content Interest Modeling Paradigm for User Behavior Modeling
论文链接:https://arxiv.org/abs/2502.00321
3.2. 推理 - 用户行为大模型
随着用户行为序列特征的规模不断扩大,包括长周期行为的不断加长、多类型行为和多场域行为的不断扩充等,这类特征的重要性逐渐在整个特征体系中占据主导地位。过去,单值特征类型的特征交互建模曾是模型迭代的主线,而如今,实际业务提效的研究焦点早已转向多值 / 序列特征类型的用户行为建模。研究焦点的转向和该方向的 Scaling Law 密不可分,例如针对行为周期的不断拉长,设计高性能的 Target-Attention 结构能够带来持续性收益。但是传统 Scale up 依然仅在 Wider 方向有效,我们多次试图加深行为兴趣网络结构的层数,却提效甚微且很快就遇到瓶颈,我们开始意识到 CTR 任务的端到端建模会限制模型的复杂度,Deeper 方向的规模化红利需要用新思路来解决。
为此,我们提出 LUM(Large User Model)模型,同样采用 “Pre-train + Post-train + CTR” 的迭代范式,考虑点和 MIM 模型类似,Deeper 方向规模化由 Pre-train 和 Post-train 来承担,同时系统架构、迭代效率、推理性能和生产关系等对实际落地和长远发展均有益处。前序阶段参考 LLM 模型架构设计自回归生成式任务 ——Next Item Prediction,旨在从用户行为序列中以数据驱动的方式学习协同过滤模式,该阶段专注下游行为预测类模型的可迁移性。CTR 模型则依赖 LUM 的推理结果,进行 Target-Attention,除了传统的从历史行为中提取兴趣以外,还将从推理的未来信息中挖掘潜在兴趣,该方式高效融合了生成式与判别式任务的各自特点。
其实类似的范式并不新鲜,但之前可能大家对该范式的 Scale up 能力估计不足,在 LLM 盛行之前并没有成为持续迭代的主流,这次我们以全新的认知重新做系统性建设。LUM 模型的规模化潜力主要源自 Next Item Prediction 的任务设计,因为 Item 集合非常大,模型学习空间相较只有 1bit 信息量的是否点击的 CTR 任务更大,可以容纳更多的样本与模型参数。实践表明,确实该模式下模型层数可以加深到几十层,与之对应的该阶段设立的一些技术指标如 recall 等均能持续提升,并与下游 CTR 任务结合,可以体现推理能力不断提升。
LUM 模型的优化核心要解决两个问题,Item 如何高效 Token 化和语义信息与协同信息如何高效融合。前者,一方面 Item 规模相较 LLM 的 Token 词表过于庞大,另一方面如果参考初期文献直接文本化的做法对于长序列表达是个灾难,所以将语义信息压缩至小规模的 Token 非常有必要。目前 Token 化方法处于百花齐放中,包括语义 ID、LLM 总结、多模态表征等;后者,虽然协同信息和语义信息的建模思路大同小异,都是在时序维度刻画 Token 之间的 “共现” 概率,但是背后的 Pattern 还是有很大差异。为了求解解耦可以各司其职,分层架构是理想方案,底层 Token 化聚焦语义信息的编码,上层 Transformer 结构聚焦协同信息的挖掘。如上,用户行为建模可以增强兴趣推理能力,并开启新的规模化路径。

欢迎探讨:
- 【LUM】Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model
- 论文链接:https://arxiv.org/abs/2502.08309
- 【UQABench】UQABench: Evaluating User Embedding for Prompting LLMs in Personalized Question Answering
- 论文链接:https://arxiv.org/abs/2502.19178
四、大模型重塑搜索广告系统
大模型的出现对搜推广业务影响深远,短期来看可以通过 AI 能力升级重构现有系统,长期来看必将孕育出新的产品形态和商业模式。本章重点介绍一下我们如何利用大模型的能力全链路重塑现有的搜索广告系统。主要体现在两方面的优势:1)传统搜索系统过于依赖 ID 特征体系,大模型在语义理解和逻辑推理上的惊人能力可以真正读懂用户的搜索需求,各环节的匹配效率都会大幅提升;2)大模型沉淀下来的 Pre-train 和 Post-train 的迭代范式,能够更加一体化地优化全链路,并进一步打开 Scale up 的空间。继 2023 年的效果初探,2024 年我们在全链路上有更加全面的落地,包括改写、召回、相关性和创意等模块,累计提效约 CTR+10%、RPM+5%,下文选取几个代表性工作做介绍。

4.1. 改写
改写是搜索广告场景极具业务特色的技术模块,用户输入搜索词 Query 表达搜索需求,广告主通过广告平台设置和自己产品有关的竞买词 Bidword 表达想要触达的流量,改写的目标是对 Query 和 Bidword 做高效匹配。匹配效率体现在两方面,分别是相关性和流量价值,前者是基础,后者是在前者的基础上挑选流量变现价值更高的 Bidword。核心挑战主要有两个:1)精准理解 Query 背后的真实购物需求,尤其是手机文本输入成本高,用户和广告主的表达习惯千差万别,Query 和 Bidword 之间的语义鸿沟对于相关性挑战很大;2)相关性和高价值的平衡。
经典方案需要有两类模型相配合,深度语义模型解决相关性问题,基于协同过滤的深度价值模型解决流量价值问题。该方案有两方面问题,一方面存在老生常谈的问题即对长尾 Query 理解和改写能力不足,另一方面两段式目标融合往往会顾此失彼。大模型 LLM 的出现可以极大改善前者长尾流量上的相关性问题,LLM 蕴含的世界知识对于文本理解和推理能力非常强大,我们在 2023 年初就开始推进 LLM 在改写方向的落地,探索生成式改写的提效潜力。电商广告领域知识的 SFT 和在线动态 RAG 是迭代初期的常规优化手段,效果不错。生成式改写也是 LLM 在搜索广告业务中第一个上线项目。
但是简单将 LLM 适配成改写任务仍然会存在两个问题,一个是 LLM 的生成结果无法保证一定是在竞买词库中,导致生成结果不可用;另一个是生成结果虽然能够极大保证相关性但是无法提供流量价值的判断。所以系统往往需要有一个第二段改写的模块,给上述两个问题兜底或者改善。为了进一步优化改写效果,我们提出基于带权 Trie 树的 LLM 生成式改写技术(VALUE)。一方面通过将全库竞买词构建成 Trie 树,使得 LLM 生成过程在 Trie 树约束搜索下进行,确保生成结果一定是在竞买词库中;另一方面离线环节构建高低价值的反馈判断(哪个词的变现效率更高)进行 DPO 训练,在线环节将 Trie 树升级为带权(权重即变现效率的层层汇聚)且实时更新的模式,两相结合使得一段式生成过程兼顾了高价值判定。如上,基于 LLM 的生成式改写方向,两年时间总共上线 4 期,提效显著。

4.2. 召回
电商场景下,用户的搜索需求除了搜索词 Query 的主动表达以外,还有背后的个性化需求,包括价格、品牌、款式等偏好。同时,商品广告库的丰富性意味着,即使满足基本的相关性需求,系统仍需在众多符合条件的商品中做出偏好筛选。所以深度挖掘用户兴趣偏好,才能更加全面理解用户的搜索需求。基于此,召回模块的核心目标就是在确保高召回率的前提下,检索出与后续排序阶段价值判定一致的最优广告集合子集,从而同时满足相关性和个性化的搜索需求。
召回模块的核心技术挑战是在计算性能有限的情况下近似做到全库打分检索,从而在准确率和召回率之间达到最优平衡。向量化检索是深度学习时期应用最为广泛的技术方案,其中索引结构是关键,通过 LSH、PQ 或 HNSW 等方法设计合理的数据结构,对索引进行分片或分层处理,可以减少大量不必要的计算,达到近似最近邻 ANN 的计算效果。然而电商搜索有别于传统的文本搜索,Query、User 和 Item 是异构实体且有不同模态,向量化检索模式有天然的优化瓶颈。主要体现在两方面,一方面是基于相似度量的索引构建与检索模型相分离会导致优化目标不统一,另一方面基于性能考虑实体间的计算只能局限在简单的线性计算模式。
大模型 LLM 的建模范式给生成式召回带来新思路,生成式召回可以从本质上统一索引构建和检索打分两个过程,此时模型参数即索引,模型的离线训练和在线推理的优化目标是一致的,而且可以自然地引入复杂的非线性计算,这类端到端的最优子集生成过程有更高的优化天花板。生成式召回有两类探索方向:1)参考 LLM 的自回归建模思路,基于 Transformer 架构自行构建 Next Item Prediction;2)将用户行为和 Query 一样文本化,直接借助 LLM 的世界知识和推理能力进行 Next Token Prediction。
关于以上两类探索方向,前者就是前文提到的 LUM 模型,该模型在召回和预估环节均有应用,这里不再赘述;后者是 LLM 应用于推荐系统中的最早且最直接的探索思路,因为召回对于打分精准度的要求不像预估这么严苛,所以针对该思路我们优先选择在召回侧做了大量尝试。其中最核心要解决的技术问题是如何让协同过滤信息融入到 LLM 模型中,我们分别做了几个改进工作:蕴含协同过滤信息的 ID Embedding 以特殊 Token 的方式引入、利用行为序列信息进行领域迁移的 SFT、Next Token 实际应用成 Next CPV(商品关键属性,结构化信息天然有聚类效果),实践表明该召回方式能够提升召回通道独占比,带来明确业务收益。当然,眼下关于生成式的计算性能问题还在逐步攻克中。
4.3. 相关性
在电商场景中,搜索广告结果通常以商品的原生形态呈现,因此搜索相关性对用户体验至关重要。相关性模型作为 NLP 技术在搜索广告中的核心应用,主要用于判断用户搜索需求(Query)的文本表达与商品展示的图文信息是否匹配。该技术体系包括实体识别模型、关键属性识别模型,以及贯穿召回与排序各阶段的相关性判别模型等多个关键模块。长期以来,相关性模型的技术迭代始终沿着 NLP 技术的发展路径演进。随着大语言模型 LLM 的崛起,NLP 技术范式正经历深刻变革。相关性模型有别于 CTR 等行为预测模型,它没有个性化信息,文本语义的深度理解是建模关键,所以我们认为它具备 LLM 迁移最先落地的可能性。
相关性模型一直以来的核心技术挑战是如何在标注数据稀少且昂贵的情况下做模型规模化。技术发展路线主要经历过两个阶段:1)挖掘行为数据作为弱标签,借助图学习和表征学习的能力做数据层面 Scale up;2)借鉴 BERT 系列的文本类多任务预训练 + 下游任务微调的范式,进行模型层面 Scale up。随着自回归模式的 GPT 架构兴起,模型的进一步规模化还能涌现出逻辑推理能力,而这正是相关性模型可以代际性进阶的突破机会。逻辑推理和可解释性对于相关性任务判定很重要,一方面我们实践论证通过思维链 CoT 慢推理的任务设计可以显著提升判定结果的准确性,另一方面推理的过程信息对于模型的再一次迭代以及业务应用都有助益。
所以,我们研发了基于思维链模式的聚焦逻辑推理的相关性大模型,并且升级了智能化标注系统,设计机器标注和人工校验的协同机制,彻底改变标注数据稀疏且昂贵的窘境。同时,考虑到相关性大模型无法在线毫秒级实时响应,我们设计一系列电商业务特色的细粒度蒸馏手段包括数据蒸馏、隐层蒸馏和过程蒸馏等,大幅提升在线传统相关性模型的预估能力。如上,基于 LLM 的相关性模型全面落地,配合 Case 驱动方法论践行,今年在相关性体验上做的提效收益高于过去三年之和。

欢迎探讨,【ELLM-rele】Explainable LLM-driven Multi-dimensional Distillation for E-Commerce Relevance Learning
论文链接:https://arxiv.org/abs/2411.13045
五、总结与展望
本文介绍了阿里妈妈搜索广告在多模态和大语言模型方面的成功实践,尽管取得了不错收益,但仍需关注当前 LLM 在线服务中的实际应用情况。目前,凡是依赖 LLM 原生能力的在线服务,主要依托异步缓存机制实现,而真正能支撑全流量实时服务的核心模块,依然以传统模型为主,LLM 主要作为增强手段提供辅助优化。因此,如何设计高性能推理架构,使大模型真正实现在线实时应用,将成为下一阶段的关键突破点。这不仅能带来更全面的业务收益,也意味着更大的效率提升空间。
曾参与深度学习改造搜推广系统的同学对此一定深有体会。在早期,DNN 作为一种从 CV 和 NLP 领域借鉴来的技术,能否顺利在搜推广系统中服役曾一度令人疑虑,整个落地过程充满挑战。然而,如今 DNN 已经成为行业的标配,背后支撑这一变革的核心因素,是算力成本的指数级下降。大模型的发展趋势亦然。尽管当前 LLM 的迭代受到算力瓶颈的制约,但可以预见,在不远的将来,随着计算成本的降低和推理架构的升级,LLM 也将全面在线化,成为搜推广系统的核心技术基座。
参考文献
[1] A Survey of Large Language Models
[2] Pre-train, Prompt, and Predict- A Systematic Survey of Prompting Methods in Natural Language Processing
[3] A Survey on Large Language Models for Recommendation
[4] A Survey on Multimodal Large Language Models
[5] A Comprehensive Survey on Multimodal Recommender Systems Taxonomy, Evaluation, and Future Directions
[6] Multimodal Recommender Systems- A Survey
[7] Pre-train, Prompt and Recommendation- A Comprehensive Survey of Language Modelling Paradigm Adaptations in Recommender Systems
[8] Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models- Discoveries and Insights
[9] Large Language Models for Information Retrieval- A Survey
[10] Towards Next-Generation LLM-based Recommender Systems: A Survey and Beyond
#GRUtopia
上海AI实验室发布通用具身智能仿真平台桃源2.0,三行代码定义任务,数采效率最高提升20倍
上海人工智能实验室发布了通用具身智能仿真平台GRUtopia 2.0,通过通用模块化框架、场景资产自动化生成和高效数据采集系统三大革新,实现了仅用三行代码定义任务,数据采集效率最高提升20倍,为具身智能研究提供了一站式的高效开发解决方案。
2月22日,2025 GDC“浦江AI生态论坛”在上海徐汇举行。论坛现场,上海人工智能实验室(上海AI实验室)发布通用具身智能仿真平台桃源2.0(GRUtopia2.0),并面向全球开发者开放。
在首个“城市级”大规模仿真平台GRUtopia1.0的基础上,升级后的GRUtopia2.0凭借通用模块化框架、场景资产自动化生成、高效数据采集系统三大革新,进一步向通用化、多样化、易用化迈进。仅通过单一平台、简单代码输入,即可实现仿真环境中机器人灵活训练,提升数据采集效率,为研究者提供了“一站式”具身智能开发解决方案。
近期,上海AI实验室完成首次“虚实贯通”技术体系全闭环验证,在“真实-模拟-真实”(Real-to-Sim-to-Real)路径下,加速打造可自主演进的具身智能进程。作为该体系“模拟”环节的核心,GRUtopia 2.0以高性能仿真,推动具身智能“在虚拟中走向现实”。平台数据集、模型、工具链等将陆续开源,与业界伙伴共同促进技术进步与生态繁荣。
项目链接:https://github.com/OpenRobotLab/GRUtopia
针对真实场景训练数据匮乏的核心痛点,上海AI实验室在业内较早开展数字模拟平台构建,于2024年7月发布的GRUtopia1.0,涵盖89种功能性场景、10万级别高质量可交互数据,以数据、工具链、评测三位一体赋能仿真训练。
本次全新升级的GRUtopia2.0版本,具备大规模数据生产能力,数据采集方式实现了三大方面的革新,并可以多样化和易用性适配多类型机器人:
- 新增通用模块化仿真框架: 支持包含导航、操作、运动控制在内的任意具身任务,用户无需切换多平台,“三行代码”即可定义任意任务,简化开发流程
- 场景资产自动化功能增强: 集成百万级标准化物体资产,结合场景的自动化生成和随机化工具,实现复杂场景“一键生成”。
- 数据采集系统更高效: 提供面向操作任务的多种低门槛遥操作工具,以及面向导航的批量化数据采集工具。遥操效率相较空间鼠标提升5倍,导航任务数据采集效率最高提升20倍。
通用平台:单平台实现控制到决策任务训练
为实现单一平台覆盖从底层控制到顶层决策任务的“通用性”训练需求,上海AI实验室研究团队为GRUtopia2.0设计了功能全面的模块化框架,具备代码轻量和灵活拓展的特性,从而提升用户使用体验。
模块化框架将训练任务拆解为“场景、机器人、任务指标”三要素,用户仅需三行代码即可完成任意具身任务的定义。平台内置多种机器人、控制器、评价指标、任务奖励等模块的实现,仅通过对原生模块的组合即可实现多种导航、操作和控制任务。

“任务信息、场景、机器人”三要素,定义任意具身任务
模块化设计同时赋予了GRUtopia2.0极高的扩展性。通过代码指令,用户可为机器人增加腰部雷达、加装灵巧手,为任务添加新的评价指标。得益于平台设计的扁平继承关系,用户可以快速定位并修改具体的功能逻辑,从而实现个性化的功能扩展。
为满足从底层控制到高层决策的多层级研究需求,平台提供了广义控制器模块,用户可根据需要定制机器人控制方式。多个控制器可以级联使用,实现复杂的控制行为。以人形机器人导航任务为例,用户可以定义多个控制器层次,如步态控制器、路径跟踪控制器和路径规划器,并通过级联实现高效的导航任务。
此外,GRUtopia2.0平台兼容标准Gym接口,支持与第三方算法库(如SB3)的对接,使得任务算法的训练更加便捷。
多样化生成:百万物体资产导入,复杂场景“一键生成”
当前,由于搭建难度高,高质量数字场景资产匮乏,成为仿真训练的主要限制之一。为此,GRUtopia2.0提供了高质量物体资产数据及自动化场景生成工具,使具身训练更贴近复杂的真实世界场景。

支持多样化复杂场景“一键生成”
延续GRScenes-100场景数据集的多样化特性,研究人员对其进行了进一步标准化处理,将场景拆分成物体组合、模型、材质,允许用户多粒度灵活复用。同时提供标准化工具,将3D物体数据集Objaverse的数据资产进行统一标准的结构化管理,转化为百万级可复用的物体资产。
GRUtopia2.0的自动化场景搭建工具,在Infinigen场景布局生成框架的基础上,引入高质量的物体资产和材质填充场景,并在生成过程加入一致性约束,使得生成的场景更加真实与和谐。用户使用随机化工具,可实现自动化的灯光、物体材质、模型和局部布局的随机替换,满足训练过程中对数据增强的高质量需求。
高效易用:导航遥操“全家桶”,最高增效20倍
真实定制化数据的匮乏,催生仿真平台数据采集。为满足用户对于定制化数据采集的需求,GRUtopia2.0提供了面向操作、导航任务等高效数据收集管线,让系统更易用高效。
弥补传统遥操作工具活动范围、距离感知、动作精度弱等带来的数据采集方式限制,研究人员为GRUtopia2.0引入VR、动作捕捉、双手协调的等机器人遥操作手段,提升模拟数据采集效率。进一步拉低使用门槛,首创设计双手协调的“隔空操作模式”,无需视觉及操作硬件,通过动作捕捉即可控制机器人的运动、视角转换、坐标系重定位和运动精度调整的功能。相较传统空间鼠标方式,可实现5倍的操作效率提升,单人一天即可采集上百条复杂操作数据。


首创双手协调的“隔空操作模式”
在面向导航的数据采集管线中,GRUtopia2.0利用全局地图ESDF并行采样合成海量轨迹数据,较人工操作传统方式提升近20倍。同时设置了针对轮式、足式及虚拟机器人提供了默认的路径规划控制器,以实现在GRScenes-100、Matterport3D场景中自动化的路径跟随和观测、动作数据采集。平台还提供了批量化工具,支持进行并行的大规模导航数据采集。

GRUtopia2.0利用全局地图ESDF并行采样合成海量轨迹数据

















 4798
4798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









