







我自己的原文哦~ https://blog.51cto.com/whaosoft/11608335
#ProcessPainter
只要一张图就能「还原」绘画过程,这篇论文比爆火的Paints-UNDO实现得更早
作者介绍:宋亦仁:新加坡国立大学 ShowLab 博士研究生, 主要研究方向包括图像和视频生成, AI 安全性。
黄施捷:新加坡国立大学硕士二年级学生,目前在 Tiamat AI 任算法工程师实习生,主要研究方向是视觉生成。目前在寻找 2025 fall 博士入学机会。
最近,lvmin 带来了最新模型 Paints-UNDO。这款 AI 生成工具可以根据图片还原整个绘画过程,整个 AIGC 社区都为之震撼。

Paints-UNDO 的演示 demo。
早在 1 个月前,NUS,SJTU,Tiamat 等机构联合已经发布了一篇做类似任务的工作 ProcessPainter: Learn Painting Process from Sequence Data。Paints-UNDO 技术报告还未公布,让我们一起看看 ProcessPainter 是如何实现的吧!
- 论文标题:ProcessPainter: Learn Painting Process from Sequence Data
- 论文链接:https://arxiv.org/pdf/2406.06062
- 代码链接:https://github.com/nicolaus-huang/ProcessPainter
翻开任意一本绘画教学书籍,都能看到按照步骤画画的指导。然而,在生成式 AI 时代,通过去噪过程完成图像生成和人类画家绘画过程完全不同,AI 画画的过程无法直接用于绘画教学。
为了解决这一问题,ProcessPainter 通过在合成数据和人类画师绘画视频上训练时序模型,首次实现了让扩散模型生成绘画过程。此外,不同题材、画师的绘画过程差异巨大,风格迥异。然而,目前很少有研究将绘画过程作为研究对象。论文作者在预训练的 Motion Model 基础上,通过在特定画师的少量绘画序列上训练 Motion LoRA,学习画师的绘画技法。

深入解读 ProcessPainter 的核心技术

1. 时序注意力机制(Temporal Attention)
用时序注意力学习生成绘画过程是 ProcessPainter 的核心创新。绘画序列生成的关键是,整个序列是同一张图从抽象到具体的变化过程, 前后帧在内容和构图上是一致且相关的。为了实现这一目标,作者为 Unet 引入了来自 AnimateDiff 的时序注意模块。该模块位于每一层扩散层之后,通过帧间自注意机制来吸收不同帧的信息,确保整个序列的平滑过渡和连续性。
实验证明,该训练策略可以在帧之间保持一致的绘画效果。绘画过程生成和视频生成任务不同之处在于,绘画过程前后变化更加剧烈,首帧是完成度很低的色块或线稿,而尾帧是完整的画作,这对模型训练带来挑战。为此,论文作者先在大量合成数据集上预训练时序模块,让模型学习各种各种 SBR(Stroke-based rendering) 方法的逐步绘画过程,再用数十个艺术家的绘画过程数据训练 Painting LoRA 模型。
2. 艺术品复制网络(Artwork Replication Network)
绘画实践中,我们更希望知道一幅作品是如何画出来的,以及如何从半成品绘画继续细化以达到期待的成品效果。这就引申出了两个任务:绘画过程重建和补全。鉴于这两个任务都有图像的输入,论文作者提出了艺术品复制网络(Artwork Replication Network)。
这一网络设计能够处理任意帧的图像输入,灵活控制绘画过程的生成。与之前的可控性生成方法类似,论文作者引入一个 ControlNet 的变体,来控制生成结果中的特定帧与参考图一致。
3. 合成数据集与训练策略
由于真实绘画过程数据较难获取,数量不足以支持大规模训练。为此,论文作者构建了用于预训练的合成数据集。
具体采用了三种合成数据方法:
1. 采用 Learn to Paint 来产生半透明贝赛尔曲线笔触的绘画序列;
2. 通过自定义笔触,用 Neural style painting 生成油画风格和中国画风格的绘画序列。
3. 上述 SBR(Stroke base painting)方法是从粗到细的拟合一张目标图像, 意味着允许对于已经绘画的部分进行覆盖和修改,然而很多绘画种类,如中国画和雕刻,由于材料的限制,无法大幅度修改已经完成的部分, 绘画过程是分区域完成的。为此,论文作者采用 SAM(segment anything) 和显著性检测方法,从空白画布逐个子区域添加内容,先绘制显著性物体, 然后逐步向背景扩散,从而合成绘画过程视频。
在训练阶段,论文作者首先在合成数据集上预训练了 Motion Model,然后冻结了 Motion Model 的参数并训练了 Artwork Replication Network。在微调绘画 LoRA 模型时,第一步只使用最终帧来微调空间注意力 LoRA,以防止半成品绘画训练集损害模型的生成质量。
此后,论文作者冻结了空间注意力 LoRA 的参数,并使用完整的绘画序列微调时间注意力 LoRA。在推理阶段,当从文本生成绘画序列时,ProcessPainter 不使用艺术品复制网络。在绘画过程重建和补全任务中,ProcessPainter 使用艺术品复制网络接收特定帧的参考输入。为了确保生成的绘画序列中的帧尽可能与输入图像匹配,ProcessPainter 采用了 DDIM 反演技术来获取参考图像的初始噪声,并在 UNet 中替换特定帧的初始噪声。
ProcessPainter 效果展示
在合成数据集上训练的 ProcessPainter base model 可以生成过程上有风格差异的绘画序列。

通过在少量人类画师的绘画序列上分别训练 Motion Lora,ProcessPainter 可以学习特定画师的绘画过程和风格。

指定参考图像,ProcessPainter 可以将完成的艺术品逆向解构为绘画步骤,或者从半成品推演出完整的画作。

这些技术组件的结合,让 ProcessPainter 不仅能够从文本生成绘画过程,还能将参考图转换成绘画序列,或是对未完成的画作进行补全。这无疑为艺术教育提供了新工具,同时也为 AIGC 社区开辟了新赛道。也许不久的将来,Civitai 上会有各种模拟人类画师绘画过程的不同 Lora 出现。
#Gen-3 Alpha
Runway深夜炸场,Gen-3 Alpha图生视频上线,11秒让你脑洞乱飞
网友不吝赞叹:AI 视觉生成又迈出了一大步。
今天凌晨,Runway Gen 3 Alpha 模型的图生视频功能正式上线!
用户可以使用任何图片作为视频生成的首帧。上传的图片既可以单独使用,也可以使用文本提示进行额外指导。
目前,Gen 3 Alpha 支持生成的视频最长为 11 秒。
作为一项重大更新,Runway 表示,图生视频功能将极大提高了生成视频的艺术控制和一致性。
至于效果如何,大家可以先来欣赏以下官方给到的图生视频示例。
Runway 联合创始人兼 CEO Cristóbal Valenzuela 发推表示,是时候了(脑补:给视频生成领域再来波小小的震撼了)。
他也放上了一些惊艳的图生视频示例。
Runway 脑洞大开、逼真的视频生成效果赢得了评论区一众网友的认可和赞赏,都迫不及待想要尝试一番了。
当然已经有人用上了,X 用户 @NoBanksNearby 在试用后表示,「Runway 在图生视频领域又做到了很好。」
X 用户 @blizaine 测试了一张 Midjourney 生成的小罗伯特・唐尼即将扮演的毁灭博士,使用到的 Prompt 为「当男人走向相机时跟踪拍摄,背景中有神奇的电气爆炸。」
参考链接:
https://venturebeat.com/ai/you-can-now-turn-still-images-into-ai-videos-with-runway-gen-3-alpha/
#国产版Sora
又一「国产版Sora」全球上线!清华朱军创业团队,视频生成仅需30秒
AI 视频圈正「互扯头花」。
国外的 Luma、Runway,国内的快手可灵、字节即梦、智谱清影…… 你方唱罢我登场。无一例外,它们对标的都是那个传说中的 Sora。
其实,说起 Sora 全球挑战者,生数科技的 Vidu 少不了。
早在三个月前,国内外视频生成领域还一片「沉寂」之时,生数科技突然曝出自家最新视频大模型 Vidu 的宣传视频,凭借其生动逼真、不输 Sora 的效果,惊艳了一众网友。
就在今天,Vidu 正式上线。无需申请,只要有个邮箱,就能上手体验。(Vidu官网链接:www.vidu.studio)
例如,皮卡丘和哆啦 A 梦玩「贴脸杀」:
《暮光之城》男女主秀恩爱:
它甚至还解决了 AI 不会写字的问题:
此外,Vidu 的生成效率也贼拉猛,实现了业界最快的推理速度,仅需 30 秒就能生成一段 4 秒镜头。
接下来,我们就奉上最新的一手评测,看看这款「国产 Sora」的实力究竟如何。
上手实测:镜头语言大胆,画面不会崩坏!
这次,Vidu 亮出了绝活。
不仅延续了今年 4 月份展示的高动态性、高逼真度、高一致性等优势,还新增了动漫风格、文字与特效画面生成、角色一致性等特色能力。
主打一个:别人有的功能,我要有,别人没有的功能,我也要有。
哦莫,它竟然认字识数
现阶段,Vidu 有两大核心功能:文生视频和图生视频。
提供 4s 和 8s 两种时长选择,分辨率最高达 1080P。风格上,提供写实和动画两大选择。
先看看图生视频。
让历史重新鲜活起来,是当下最流行的玩法。这是法国画家伊丽莎白・路易丝・维瑞的名作《画家与女儿像》。
我们输入提示词:画家与女儿像,母女紧紧抱在一起。
生成的高清版本让人眼前一亮,人物动作幅度很大,连眼神都有变化,但效果挺自然。
再试试达芬奇的《抱银鼬的女子》。
提示词:抱银鼬的女子面露微笑。0
长达 8 秒的视频里,女子和宠物动作幅度较大,特别是女子的手部抚摸动作,还有身体、面部变化,但都没有影响画面的自然、流畅。
大幅度、精准的动作有助于更好地表现视频情节和人物情绪。不过,动作幅度一旦变大,画面容易崩坏。因此,一些模型为保证流畅性,会牺牲动幅,而 Vidu 比较好地解决了这一问题。
模拟真实物理世界的运动,还真不错。比如,复刻类似库布里克《2001 太空漫游》的情景!
提示词:长镜头下,缓缓走向消失。7
提示词:长镜头下,漂浮着,慢慢飘向尽头。
除了图生视频,还有文生视频。
提示词:两朵花在黑色背景下缓慢绽放,展示出细腻的花瓣和花蕊。
提示语:这次只她一人,独自坐在樱花深处的秋千架上,穿着粉红的春衫,轻微荡着秋千,幅度很小,像坐摇椅一般,微垂着头,有点百无聊赖的样子,缓缓伸足一点一点踢着地上的青草。那樱花片片飘落在她身上头上,她也不以手去拂,渐渐积得多了,和她衣裙的颜色相融,远远望去仿佛她整个人都是由樱花砌成似的。
Vidu 语义理解能力不错,还可以理解提示中一次包含多个镜头的片段要求。
比如,画面中既有海边小屋的特写,还有运镜转向海面远眺的远景,通过镜头切换,赋予画面一种鲜明的叙事感。
提示语:在一个古色古香的海边小屋里,阳光沐浴着房间,镜头缓慢过渡到一个阳台,俯瞰着宁静的大海,最后镜头定格在漂浮着大海、帆船和倒影般的云彩。
对于第一人称、延时摄影等镜头语言,Vidu 也能准确理解和表达,用户只需细化提示词,即可大幅提升视频的可控性。0:07
提示词:第一人称视角,女友牵着我的手,一起漫步在海边。
Vidu 是一款能够准确理解和生成一些词汇的视频生成器,比如数字。
提示词:一块生日蛋糕,上面插着蜡烛,蜡烛是数字 “32”。
蛋糕上换成「Happy Birthday」的字样,它也能hold住。
提示词:一块蛋糕,上面写着"HAPPY BIRTHDAY"。
动漫风格嘎嘎好用
目前市面上的 AI 视频工具大多局限于写实风格或源于现实的想象,而 Vidu 除了写实风格外,还支持动漫风格。
我们选择动画模型,直接输入提示词即可输出动漫风格视频。
例如,提示词:动漫风格,小女孩站在厨房里切菜。
说实话,这画风有宫崎骏老爷子的味道。Vidu 读懂了提示词,小女孩切菜动作一气呵成,就是手指和刀具在不经意间仍有变形。
提示词:动漫风格,一个戴着耳机的小女孩在跳舞。
Vidu 的想象力还挺丰富,自个儿把背景设置为带有喷泉的公园,这也让视频画面不那么单调。
当然,我们还可以上传一张动漫参考图片,再输入提示词,如此一来,图片中的动漫人物就能动起来啦。
例如,我们上传一张蜡笔小新的静态图,然后输入提示词:蜡笔小新大笑着举起手里的小花。图片用途选择「用作起始帧」。
我们来瞅瞅效果:
再上传一张呆萌皮卡丘的图像,输入提示词为「皮卡丘开心地蹦起来」。图片用途选择「用作起始帧」。
继续上效果:
上传《海贼王》路飞的图像,再喂给它提示词:男孩突然哭起来。
效果如下:
不得不说, Vidu 的动漫效果相当惊艳,在保持风格一致性的同时,显著提高了画面的稳定性和流畅性,没有出现变形、崩坏或者六指狂魔、左右腿不分等「邪门」画面。
梗图、表情包燥起来
在「图生视频」板块中,除了支持首帧图上传,Vidu 这次还上新一项功能 —— 角色一致性(Charactor To Video)。
所谓角色一致性,就是上传一个角色图像,然后可以指定该角色在任意场景中做出任意动作。
我们就拿吴京为例。
提示词:在一艘宇宙飞船里,吴京正穿着太空服,对镜头挥手。
提示词:吴京穿着唐装,站在一条古街上,向镜头挥手。
如果说,首帧图上传适合创作场景一致性的视频,那么,有了角色一致性功能,从科幻角色到现代剧,演员七十二变,信手拈来。
此外,有了角色一致性功能,普通用户创作「梗图」、「表情包」可以燥起来了!
比如让北美「意难忘」贾斯汀・比伯和赛琳娜再续前缘:
《武林外传》中佟湘玉和白展堂嗑着瓜子,聊着同福客栈的八卦:
还有《甄嬛传》皇后娘娘委屈大哭:
只要脑洞够大,什么地铁老人吃手机、鳌拜和韦小宝打啵、容嬷嬷喂紫薇吃鸡腿,Vidu 都能整出来。
就一个字,快!
视频生成过程中,用户最烦啥?当然是龟速爬行的进度条。
试想,为了一段几秒的视频,愣是趴在电脑前等个十分钟,再慢性子的人也很难不破防。
目前,市面上主流 AI 视频工具生成一段 4 秒左右的视频片段,通常需要 1 到 5 分钟,甚至更长。
例如,Runway 最新推出的 Gen-3 工具需要 1 分钟来完成 5s 视频生成,可灵需要 2-3 分钟,而 Vidu 将这一等待时间缩短至 30 秒,速度比业内最快水平的 Gen-3 还要再快一倍。
基于完全自研的 U-ViT 架构,商用精心布局
「Vidu」底层基于完全自研的 U-ViT 架构,该架构由团队在 2022 年 9 月提出,早于 Sora 采用的 DiT 架构,是全球首个 Diffusion 和 Transformer 融合的架构。
在 DiT 论文发布两个月前,清华大学的朱军团队提交了一篇论文 ——《All are Worth Words: A ViT Backbone for Diffusion Models》。这篇论文提出了用 Transformer 替代基于 CNN 的 U-Net 的网络架构 U-ViT。这是「Vidu」最重要的技术基础。
由于不涉及中间的插帧和拼接等多步骤的处理,文本到视频的转换是直接且连续的,「Vidu」 的作品感官上更加一镜到底,视频从头到尾连续生成,没有插帧痕迹。除了底层架构上的创新,「Vidu」也复用了生数科技过往积累下的工程化经验和能力。
生数科技曾称,从图任务的统一到融合视频能力,「Vidu」可被视为一款通用视觉模型,能够支持生成更加多样化、更长时长的视频内容。他们也透露,「Vidu」还在加速迭代提升。面向未来,「Vidu」灵活的模型架构也将能够兼容更广泛的多模态能力。
生数科技成立于 2023 年 3 月,核心成员来自清华大学人工智能研究院,致力于自主研发世界领先的可控多模态通用大模型。自 2023 年成立以来,团队已获得蚂蚁集团、启明创投、BV 百度风投、字节系锦秋基金等多家知名产业机构的认可,完成数亿元融资。据悉,生数科技是目前国内在多模态大模型赛道估值最高的创业团队。
公司首席科学家由清华人工智能研究院副院长朱军担任;CEO 唐家渝本硕就读于清华大学计算机系,是 THUNLP 组成员;CTO 鲍凡是清华大学计算机系博士生、朱军教授的课题组成员,长期关注扩散模型领域研究,U-ViT 和 UniDiffuser 两项工作均是由他主导完成的。
今年 1 月,生数科技旗下视觉创意设计平台 PixWeaver 上线了短视频生成功能,支持 4 秒高美学性的短视频内容。2 月份 Sora 推出后,生数科技内部成立攻坚小组,加快了原本视频方向的研发进度,不到一个月的时间,内部就实现了 8 秒的视频生成,紧接着 4 月份就突破了 16 秒生成,生成质量与时长全方面取得突破。
如果说 4 月份的模型发布展示了 Vidu 在视频生成能力上的领先,这次正式发布的产品则展示了 Vidu 在商业化方面的精心布局。生数科技目前采取模型层和应用层两条路走路的模式。
一方面,构建覆盖文本、图像、视频、3D 模型等多模态能力的底层通用大模型,面向 B 端提供模型服务能力。
另一方面,面向图像生成、视频生成等场景打造垂类应用,按照订阅等形式收费,应用方向主要是游戏制作、影视后期等内容创作场景。
#Segment Anything Model 2 (SAM 2)
刚刚,Meta开源「分割一切」2.0模型,视频也能分割了
还记得 Meta 的「分割一切模型」吗?这个模型在去年 4 月发布,被很多人认为是颠覆传统 CV 任务的研究。
时隔一年多,刚刚,Meta 在 SIGGRAPH 上重磅宣布 Segment Anything Model 2 (SAM 2) 来了。在其前身的基础上,SAM 2 的诞生代表了领域内的一次重大进步 —— 为静态图像和动态视频内容提供实时、可提示的对象分割,将图像和视频分割功能统一到一个强大的系统中。
SAM 2 可以分割任何视频或图像中的任何对象 —— 甚至是它以前没有见过的对象和视觉域,从而支持各种不同的用例,而无需自定义适配。
在与黄仁勋的对话中,扎克伯格提到了 SAM 2:「能够在视频中做到这一点,而且是在零样本的前提下,告诉它你想要什么,这非常酷。」
Meta 多次强调了最新模型 SAM 2 是首个用于实时、可提示的图像和视频对象分割的统一模型,它使视频分割体验发生了重大变化,并可在图像和视频应用程序中无缝使用。SAM 2 在图像分割准确率方面超越了之前的功能,并且实现了比现有工作更好的视频分割性能,同时所需的交互时间为原来的 1/3。
该模型的架构采用创新的流式内存(streaming memory)设计,使其能够按顺序处理视频帧。这种方法使 SAM 2 特别适合实时应用,为各个行业开辟了新的可能性。
当然,处理视频对算力的要求要高得多。SAM 2 仍然是一个庞大的模型,也只有像 Meta 这样的能提供强大硬件的巨头才能运行,但这种进步还是说明了一些问题:一年前,这种快速、灵活的分割几乎是不可能的。SAM 2 可以在不借助数据中心的情况下运行,证明了整个行业在计算效率方面的进步。
模型需要大量的数据来训练,Meta 还发布了一个大型带注释数据库,包括大约 51,000 个真实世界视频和超过 600,000 个 masklets。与现有最大的视频分割数据集相比,其视频数量多 4.5 倍,注释多 53 倍,Meta 根据 CC BY 4.0 许可分享 SA-V。在 SAM 2 的论文中,另一个包含超过 100,000 个「内部可用」视频的数据库也用于训练,但没有公开。
与 SAM 一样,SAM 2 也会开源并免费使用,并在 Amazon SageMaker 等平台上托管。为了履行对开源 AI 的承诺,Meta 使用宽松的 Apache 2.0 协议共享代码和模型权重,并根据 BSD-3 许可分享 SAM 2 评估代码。
目前,Meta 已经提供了一个 Web 的演示体验地址:https://sam2.metademolab.com/demo09
基于 web 的 SAM 2 演示预览,它允许分割和跟踪视频中的对象。
正如扎克伯格上周在一封公开信中指出的那样,开源人工智能比任何其他现代技术都更具有潜力,可以提高人类的生产力、创造力和生活质量,同时还能加速经济增长并推动突破性的医学和科学研究。人工智能社区利用 SAM 取得的进展给我们留下了深刻的印象, SAM 2 必将释放更多令人兴奋的可能性。
SAM 2 可立即应用于各种各样的实际用例 - 例如,跟踪对象(左)或分割显微镜捕获的视频中的移动细胞以辅助科学研究(右)。
未来,SAM 2 可以作为更大型 AI 系统的一部分,通过 AR 眼镜识别日常物品,并向用户提供提醒和说明。
SAM 2 前脚刚上线,大家就迫不及待的用起来了:「在 Meta 未提供的测试视频上试用 SAM 2。效果好得令人瞠目结舌。」
来源:https://x.com/BenjaminDEKR/status/1818066956173664710
还有网友认为,SAM 2 的出现可能会使其他相关技术黯然失色。
如何构建 SAM 2?
SAM 能够了解图像中对象的一般概念。然而,图像只是动态现实世界的静态快照。许多重要的现实用例需要在视频数据中进行准确的对象分割,例如混合现实、机器人、自动驾驶车辆和视频编辑。Meta 认为通用的分割模型应该适用于图像和视频。
图像可以被视为具有单帧的非常短的视频。Meta 基于这个观点开发了一个统一的模型,无缝支持图像和视频输入。处理视频的唯一区别是,模型需要依靠内存来调用该视频之前处理的信息,以便在当前时间步准确地分割对象。
视频中对象的成功分割需要了解实体在空间和时间上的位置。与图像分割相比,视频提出了重大的新挑战。对象运动、变形、遮挡、光照变化和其他因素可能会因帧而异。由于摄像机运动、模糊和分辨率较低,视频的质量通常低于图像,这增加了难度。因此,现有的视频分割模型和数据集在为视频提供可比的「分割任何内容」功能方面存在不足。
Meta 构建 SAM 2 和新 SA-V 数据集来解决这些挑战。
与用于 SAM 的方法类似,Meta 对视频分割功能的研究涉及设计新任务、模型和数据集。
研究团队首先开发了可提示的(promptable)视觉分割任务并设计了一个能够执行该任务的模型 ——SAM 2。
然后,研究团队使用 SAM 2 来帮助创建视频对象分割数据集 ——SA-V,该数据集比当前存在的任何数据集大一个数量级。研究团队使用它来训练 SAM 2 以实现 SOTA 性能。
可提示的视觉分割
2SAM 2 支持在任何视频帧中选择和细化对象。
研究团队设计了一个可提示的视觉分割任务,将图像分割任务推广到视频领域。SAM 经过训练,以图像中的输入点、框或掩码来定义目标对象并预测分割掩码。该研究训练 SAM 2 在视频的任何帧中获取输入提示来定义要预测的时空掩码(即「masklet」)。
SAM 2 根据输入提示立即预测当前帧上的掩码,并将其临时传播(temporally propagate)以生成跨所有视频帧的目标对象的 masklet。一旦预测出初始 masklet,就可以通过在任何帧中向 SAM 2 提供附加提示来迭代完善它。这可以根据需要重复多次,直到获得所需的 masklet。
统一架构中的图像和视频分割
2从 SAM 到 SAM 2 的架构演变。
SAM 2 架构可以看作是 SAM 从图像领域到视频领域的推广。
SAM 2 可以通过点击、边界框或掩码被提示,以定义给定帧中对象的范围。轻量级掩码解码器采用当前帧的图像嵌入和编码提示来输出该帧的分割掩码。在视频设置中,SAM 2 将此掩码预测传播到所有视频帧以生成 masklet,然后在任何后续帧上迭代添加提示以细化 masklet 预测。
为了准确预测所有视频帧的掩码,研究团队引入了一种由记忆编码器、记忆库(memory bank)和记忆注意力模块组成的记忆机制。当应用于图像时,内存组件为空,模型的行为类似于 SAM。对于视频,记忆组件能够存储关于该会话中的对象和先前用户交互的信息,从而允许 SAM 2 在整个视频中生成 masklet 预测。如果在其他帧上提供了额外的提示,SAM 2 可以根据对象存储的记忆上下文有效地纠正其预测。
帧的记忆由记忆编码器根据当前掩码预测创建,并放置在记忆库中以用于分割后续帧。记忆库由先前帧和提示帧的记忆组成。记忆注意力操作从图像编码器获取每帧嵌入,并根据记忆库进行调整以产生嵌入,然后将其传递到掩码解码器以生成该帧的掩码预测。对于所有后续帧重复此操作。
Meta 采用流式架构,这是 SAM 在视频领域的自然推广,一次处理一个视频帧并将有关分割对象的信息存储在记忆中。在每个新处理的帧上,SAM 2 使用记忆注意力模块来关注目标对象之前的记忆。这种设计允许实时处理任意长的视频,这不仅对于 SA-V 数据集的注释收集效率很重要,而且对于现实世界的应用(例如在机器人领域)也很重要。
当图像中被分割的对象存在模糊性时,SAM 会输出多个有效掩码。例如,当一个人点击自行车轮胎时,模型可以将这次点击解释为仅指轮胎或整个自行车,并输出多个预测。在视频中,这种模糊性可能会扩展到视频帧中。例如,如果在一帧中只有轮胎可见,则轮胎上的点击可能仅与轮胎相关,或者随着自行车的更多部分在后续帧中变得可见,这种点击可能是针对整个自行车的。为了处理这种模糊性,SAM 2 在视频的每个步骤创建多个掩码。如果进一步的提示不能解决歧义,模型会选择置信度最高的掩码,以便在视频中进一步传播。
9SAM 2 架构中的遮挡 head 用于预测对象是否可见,即使对象暂时被遮挡,也能帮助分割对象。
在图像分割任务中,在给定积极提示的情况下,帧中始终存在可分割的有效对象。在视频中,特定帧上可能不存在有效对象,例如由于对象被遮挡或从视图中消失。为了解释这种新的输出模式,研究团队添加了一个额外的模型输出(「遮挡 head(occlusion head)」),用于预测当前帧中是否存在感兴趣的对象。这使得 SAM 2 能够有效地处理遮挡。
SA-V:Meta 构建了最大的视频分割数据集
来自 SA-V 数据集的视频和掩码注释。
为了收集一个大型且多样化的视频分割数据集,Meta 建立了一个数据引擎,其中注释员使用 SAM 2 交互地在视频中注释 masklet,然后将新注释的数据用于更新 SAM 2。他们多次重复这一循环,以迭代地改进模型和数据集。与 SAM 类似,Meta 不对注释的 masklet 施加语义约束,注重的是完整的物体(如人)和物体的部分(如人的帽子)。
借助 SAM 2,收集新的视频对象分割掩码比以往更快,比每帧使用 SAM 快约 8.4 倍。此外,Meta 发布的 SA-V 数据集的注释数量是现有视频对象分割数据集的十倍以上,视频数量大约是其 4.5 倍。
总结而言,SA-V 数据集的亮点包括:
- 在大约 51,000 个视频中有超过 600,000 个 masklet 注释;
- 视频展示了地理上不同的真实场景,收集自 47 个国家;
- 覆盖整个对象、对象中的一部分,以及在物体被遮挡、消失和重新出现的情况下具有挑战性的实例。
结果
下方两个模型都是用第一帧中的 T 恤蒙版初始化的。对于 baseline,Meta 使用来自 SAM 的蒙版,问题是过度分割并包括人的头部,而不是仅跟踪 T 恤。相比之下,SAM 2 能够在整个视频中准确跟踪对象部分。
为了创建统一的图像和视频分割模型,Meta 将图像视为单帧视频,在图像和视频数据上联合训练 SAM 2。团队利用了去年作为 Segment Anything 项目的一部分发布的 SA-1B 图像数据集、SA-V 数据集以及额外的内部许可视频数据集。
SAM 2(右)提高了 SAM(左)图像中的对象分割精度。
SAM 2 论文也展示了该模型的多项提升:
1、SAM 2 在 17 个零样本视频数据集的交互式视频分割方面表现明显优于以前的方法,并且所需的人机交互减少了大约三倍。
2、SAM 2 在 23 个数据集零样本基准测试套件上的表现优于 SAM,而且速度快了六倍。
3、与之前的最先进模型相比,SAM 2 在现有的视频对象分割基准(DAVIS、MOSE、LVOS、YouTube-VOS)上表现出色。
4、使用 SAM 2 进行推理感觉很实时,速度大约为每秒 44 帧。
5、循环中使用 SAM 2 进行视频分割注释的速度比使用 SAM 进行手动每帧注释快 8.4 倍。
6、为了衡量 SAM 2 的公平性,Meta 对特定人群的模型性能进行了评估。结果表明,在感知性别和 18-25 岁、26-50 岁和 50 岁以上三个感知年龄组评估中,模型显示的差异很小。
更多结果,请查看论文。
论文地址:https://scontent-sjc3-1.xx.fbcdn.net/v/t39.2365-6/453323338_287900751050452_6064535069828837026_n.pdf?_nc_cat=107&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=TnvI-AaGawoQ7kNvgFJPdfC&_nc_ht=scontent-sjc3-1.xx&oh=00_AYAlCBmHCcIEnDo-YzzCScg8NZPgTQlwjE9FVlniLRw5JQ&oe=66AE2179
局限性
虽然 SAM 2 在分割图像和短视频中的对象方面表现出色,但仍然会遇到诸多挑战。
SAM 2 可能会在摄像机视角发生剧烈变化、长时间遮挡、拥挤的场景或较长的视频中失去对对象的追踪。
在实际应用中,Meta 设计了交互式模型来缓解这一问题,并通过在任意帧中点击校正来实现人工干预,从而恢复目标对象。
在拥挤的场景中,SAM 2 有时会混淆多个外观相似的对象。
当目标对象只在一帧中指定时,SAM 2 有时会混淆对象,无法正确分割目标,如上述视频中的马匹所示。在许多情况下,通过在未来帧中进行额外的细化提示,这一问题可以完全解决,并在整个视频中获得正确的 masklet。
虽然 SAM 2 支持同时分割多个单独对象的功能,但模型的效率却大大降低。实际上,SAM 2 对每个对象进行单独处理,只利用共享的每帧嵌入,不进行对象间通信。虽然这简化了模型,但纳入共享的对象级上下文信息有助于提高效率。
SAM 2 的预测可能会错过快速移动对象的细节。
对于复杂的快速运动对象,SAM 2 有时会漏掉一些细节,而且预测结果在帧之间可能不稳定,如上文骑自行车者的视频所示。
在同一帧或其他帧中添加进一步的提示来优化预测只能部分缓解此问题。在训练过程中,如果模型预测在帧间抖动,不会对其进行任何惩罚,因此无法保证时间上的平滑性。提高这种能力可以促进需要对精细结构进行详细定位的实际应用。
虽然 Meta 的数据引擎在循环中使用了 SAM 2,且在自动 masklet 生成方面也取得了长足进步,但仍然依赖人工注释来完成一些步骤,例如验证 masklet 质量和选择需要校正的帧。
因此,未来的发展需要进一步自动化这个数据注释过程,以提高效率。要推动这项研究,还有很多工作要做。
参考链接:
https://ai.meta.com/blog/segment-anything-2-video/
#Towards Next-Generation Logic Synthesis
新一代芯片电路逻辑综合,可扩展可解释的神经电路生成框架
本论文作者王治海是中国科学技术大学 2020 级硕博连读生,师从王杰教授,主要研究方向为强化学习与学习优化理论及方法、人工智能驱动的芯片设计等。他曾以第一作者在 TPAMI、ICML、NeurIPS、ICLR、AAAI 等顶级期刊与会议上发表论文七篇,一篇入选 ICML 亮点论文(前3.5%),曾获华为优秀实习生(5/400+)、两次国家奖学金(2017和2024)等荣誉。
近日,中科大王杰教授团队(MIRA Lab)和华为诺亚方舟实验室(Huawei Noah's Ark Lab)联合提出了可生成具有成千上万节点规模的神经电路生成与优化框架,具备高扩展性和高可解释性,这为新一代芯片电路逻辑综合工具奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。
- 论文标题:Towards Next-Generation Logic Synthesis: A Scalable Neural Circuit Generation Framework
- 论文地址:https://neurips.cc/virtual/2024/poster/94631
论文概览
逻辑综合(Logic Synthesis, LS)是芯片设计流程中承上启下的关键环节,对芯片设计的效率和质量都具有重要影响。具体来说,逻辑综合旨在生成精准满足给定功能要求(如由电路输入输出对构成的功能真值表)的最优逻辑电路图,是 NP 难问题。为了求解该问题,传统方法主要依赖于硬编码启发式规则,易陷入次优解。
该框架能够精确生成达1200节点规模的电路,该方案为新一代芯片电路逻辑综合工具提供了可行思路与奠定了关键基础。相关技术和能力已整合入华为自研EDA工具。
引言
芯片电路生成的目标是在给定电路功能描述的条件下,生成精准满足电路功能要求且节点数少的逻辑电路图。传统的电路生成方法将高级电路描述语言直接转译为冗余度较高的逻辑电路,这给后续的电路优化带来了较大压力。近期,一些研究通过引入机器学习方法,将电路生成与优化过程有机结合,展现了新一代逻辑综合技术的美好前景。
神经网络架构搜索(Differential Neural Network Architecture Search, DNAS)是一种利用梯度下降法搜索离散结构的技术。已有研究将其应用于生成低冗余电路,展现出了显著的潜力。然而,作者发现现有方法在生成电路时,尤其是在处理大规模电路时,难以实现完全准确的生成,且其性能对超参数极为敏感。
在深入的实验分析后,作者进一步总结出将 DNAS 应用于电路生成的三个主要难点:
- DNAS 倾向于生成大量的跨层连接,导致网络表达能力受限。
- 神经网络结构与电路固有结构存在较大偏差,显著降低了 DNAS 的搜索效率。
- 不同输入输出示例数据的学习难度差异显著,现有方法难以学习难例输入输出对。
为系统性地解决这些挑战,作者提出了一种新颖的正则化三角形电路网络生成框架(T-Net),实现了完全准确且可扩展的电路生成。此外,他们还提出了一种由强化学习辅助的演化算法,以实现高效且有效的电路优化。在四个电路评测标准数据集中,实验表明他们的方法能够精确生成多达 1200 节点规模的电路,且其性能显著优于国际逻辑综合竞赛 IWLS 2022 和 2023 中冠亚军方案。
背景与问题介绍
逻辑电路生成介绍
逻辑电路图(And-Inverter Graph, AIG)是逻辑电路的一种表示方式。AIG 为有向无环图,图中的节点代表与逻辑门,图中的边代表逻辑门间的连线,连线上可以添加非门。逻辑电路的大小为 AIG 中的节点数,在逻辑功能不变的情况下,节点数越少表示电路结构越紧凑,这将有助于后续的芯片设计优化。
逻辑电路生成方法将电路的完整输入输出对组合,即功能真值表,建模为训练数据集,并利用机器学习模型自动从数据集中学习生成逻辑电路图 [1,2,3]。在电路设计的实际应用中,要求设计精准满足功能要求的电路结构,因此生成的逻辑电路图必须在训练集上达到 100% 的准确率。
基于 DNAS 的电路生成介绍
神经网络架构搜索(Differential Neural Network Architecture Search, DNAS)[4] 近期被用于生成逻辑电路图 [2,3]。这类方法将一个 L 层,每层 K 个神经元的神经网络建模为 AIG,其中神经元视为逻辑门,神经元之间的连接视为逻辑门之间的电路连接,神经元可以连接到更浅层的任意神经元。对于一个参数化的神经网络,每个神经元都固定执行与逻辑运算,而神经元之间的连接参数是可学习的。
为了能够使用梯度下降法训练网络结构,现有方法会执行 2 种连续化操作:1. 神经元的逻辑运算用等价的可微方式计算,例如 a 与 b 用 a⋅b 代替 [5]。2. 将离散的网络连接方式参数化,并在前向传播时使用 gumbel-softmax [6] 对连接进行连续化和采样。
在训练期间,真值表的每一行输入 - 输出对都作为训练数据输入网络,通过梯度下降法训练连接参数。在测试期间,每个节点的输入根据参数只选择一条连接,从而将网络离散化,模拟实际的逻辑电路。
动机实验 ——DNAS 难以准确生成电路
作者使用上述 DNAS 方法生成电路,生成准确率和电路的规模如图 1(a)所示。结果显示,现有方法难以准确生成电路,且准确率随着电路规模增大而减小。同时,他们发现生成准确率对网络初始化方式及其敏感,方法的鲁棒性较差。

图 1. 观察实验。(a) 现有的 DNAS 方法难以准确生成电路,特别是大规模电路。(b) 输出节点位于网络浅层,跳过了大量可用节点。(c) 实际只有约四分之一的节点被使用 (深色)。(d) 电路各层节点数统计,与普遍使用的方形网络存在差异。
为了进一步分析产生上述挑战的原因,作者进行了详细的实验。
首先,他们发现网络利用率很低。由于节点间的连接可以跨层,因此存在被跳过的节点。图 1(b)展示了经过训练后输出节点位于网络中的位置,可以看到大部分网络层都被跳过,没有连接进最终电路。图 1(c)展示了网络中实际使用到的节点(深色),只有约四分之一的底层节点被使用。过度的跨层连接浪费了大量网络结构,限制了网络的表达能力。
接着,他们发现实际电路结构与网络之间存在结构偏差。他们统计了使用传统方法生成电路的各层节点数,如图 1(d)所示。图中展示了实际电路在底层有着更多节点,而顶层则节点更少,这与普遍使用的方形网络存在差异。
最后,他们发现不同输入 - 输出示例之间存在学习难度差。具体来说,它们在训练时的 loss 收敛速度存在显著差异。这与通常认为的独立同分布(IID)假设并不相同。更多细节可见原论文第 4 章节。
方法介绍
针对以上三个挑战,作者设计了新颖的正则化三角形电路生成框架(T-Net),如图 2 所示。它包含 3 个部分:多标签数据变换、三角形网络结构、正则化损失函数。

图 2. 作者提出的电路生成框架图,包含多标签数据变换、三角形网络结构、正则化损失函数三部分。
多标签数据变换:提高可扩展性
随着输入位数的增多,真值表的长度呈指数型增长。为了解决扩展性挑战,作者设计了基于香农定理的多标签训练数据变换。香浓定理证明了一个逻辑函数可以通过一个分解变量分解成两个子函数:

由于真值表是逻辑函数的对偶表示,他们通过以下两步完成数据变换:首先选定一个输入变量,通过固定它的值为 0 或 1,将真值表分解为 2 个长度减半的子表。接着将 2 个子表并列起来,每个输入组合的输出数量翻倍。
通过将真值表合并生成,网络可以学习到更多可复用的结构,从而减少最终的电路节点数。多标签数据变换可以不断减少真值表的输入位数,从而降低学习难度,加速电路生成。
三角形网络结构:减小搜索空间
为了使网络结构更好地适配电路特性,作者设计了三角形的网络结构。具体来说,更宽的底层结构增强了网络的表达能力,而细长的顶层结构减少了利用率低的冗余节点,减小了搜索空间,加速了收敛。同时,实验证明了这种窄顶结构也能有效加速具有大量输出的电路生成。
正则化损失函数:精确生成电路
本论文的方法包含跨层连接正则化和布尔难度识别损失函数两部分。对于跨层连接,作者对可学习的连接分布参数施加权重正则化,鼓励网络连接更临近层的节点。对于较难学习的输入 - 输出示例,他们在损失函数中为这些示例施加更大的权重,以在训练后期加速收敛。
同时,本论文的框架还包含电路优化部分。作者在强化学习优化算子序列调优的基础上,结合了演化算法和 agent 重启技术,避免陷入局部最优解,实现快速有效的电路优化。更多细节可见原文第 5 章节。
实验介绍
本论文实验的数据集包括 4 类开源电路数据集,节点数规模高达 1200,输入、输出数量最高为 16、63 位。
实验包含 4 个部分:1. 在多个电路上评估本论文电路生成和优化方法的准确性和电路性能。2. 评估本论文生成方法针对电路大小的可扩展性。3. 通过消融实验展示本论文方法各部分的效用。4. 验证本论文方法对超参数的鲁棒性。
作者在以下内容中详细介绍实验 1,其余实验请参见原论文的第 6 章节。
电路生成准确率
部分实验结果见图 3,作者在开源电路上对比了他们的方法与其他基于 DNAS 生成方法的准确率。实验结果显示,他们的方法准确率大幅提升,并可准确生成 1200 节点规模的电路。

图 3. 作者提出的 T-Net 相比其他 DNAS 电路生成方法准确率大幅提升。
电路综合效果
部分实验结果见图 4,作者在开源比赛电路上对比了他们的方法与开源逻辑综合工具 ABC 和 IWLS 比赛冠亚军的电路大小。实验结果显示,他们的方法显著优于开源逻辑综合工具 ABC 中的电路生成算子,且超过了 2022 和 2023 年比赛冠亚军的方案。

图 4. 作者提出的电路生成及优化框架效果显著优于开源逻辑综合工具 ABC 中的电路生成算子。
#SAM4MLLM
结合多模态大型语言模型和SAM实现高精度引用表达分割
本文提出一种允许MLLM理解像素级细节的方法SAM4MLLM,无需改变MLLM模型架构、引入新标记或使用额外损失,该方法简单但对引用表达分割(RES)非常有效。
论文地址:https://arxiv.org/abs/2409.10542
论文代码:https://github.com/AI-Application-and-Integration-Lab/SAM4MLLM
创新点
- 提出了一种允许
MLLM理解像素级细节的方法SAM4MLLM,无需改变MLLM模型架构、引入新标记或使用额外损失,该方法简单但对引用表达分割(RES)非常有效。 - 为了连接
MLLM和SAM,引入了一种新颖的方法,通过主动询问语言系统来获取提示点线索。 - 在各种
RES基准上进行实验,包括RES数据集、GRES和ReasonSeg,验证了SAM4MLLM的有效性,并展示了其在处理复杂像素感知任务中的优良性能。
内容概述
SAM4MLLM是一种创新的方法,集成Segment Anything Model(SAM)与多模态大型语言模型(MLLMs)以实现像素感知任务。
- 首先,在
MLLM训练数据集中引入像素级信息,而不改变原有的MLLM架构,这使得MLLM能够使用与主流LLM相同的文本交叉熵损失来理解像素级信息。 - 其次,考虑到输入分辨率限制和模型架构未明确设计用于视觉任务,
MLLM在像素表达方面可能存在的潜在限制。进一步利用SAM增强输出,通过后处理MLLM的输出以相对简单的方式获得更高精度的分割掩码。 - 最后,为了在
SAM和MLLM之间建立联系,一种简单的方法是使MLLM生成SAM的提示点。利用LLM的对话能力,主动要求MLLM获取SAM的有效提示点。
SAM4MLLM解决了RES问题,使得MLLMs能够学习像素级的位置信息。将详细的视觉信息与大型语言模型强大的表达能力以统一的基于语言的方式结合起来,而在学习中没有额外的计算开销。
SAM4MLLM
编码分割掩码为SAM提示
现有的用于分割的MLLMs依赖于模型架构的专门设计、分割特定的token和异构损失函数来预测对象掩码。而SAM4MLLM利用了SAM的特点,将少量文本提示token(边界框加上几个指示它们是否位于对象区域的点)转换为高质量的连续分割掩码。
SAM4MLLM 使用在边界框内采样的点作为离散提示。具体而言, 使用一个边界框 Prompt 和 个点来编码任意形状的掩码。 个点的提示, 每个点包含三个值: 坐标、 坐标以及它是否在掩码上, 编码为 。
通过将连续分割掩码编码为离散的SAM提示,避免了添加任何token或改变模型结构,同时仅使用文本自回归交叉熵损失进行训练。这种方法与语言模型的原始训练模式一致,使得MLLMs能够理解像素级信息,并促进未来的模型扩展变得更加容易。
使用MLLM提示SAM
为了将SAM以统一的方式纳入MLLM,一个主要问题在于获取SAM的提示点,包括在物体掩码区域内的正点(inside)和在外部的负点(outside)。为此,提出了两种解决方案:提示点生成(Prompt-Point Generation, PPG)和主动查询提示点(Proactive Query of Prompt-Points, PQPP)。
PPG直接采用MLLM来生成提示点和边界框,但同时生成多个点的学习将面临挑战,因此仅使用了少量提示点。PQPP则利用了MLLM的对话能力,首先询问一个粗略的边界框,然后通过问答的方式在边界框内探测多个感兴趣的点以提示SAM。
SAM4MLLM-PPG

PPG 采用了一种能够同时接受文本提示和图像输入的 MLLM 。为了使 MLLM 与分割任务对齐,使用了参数高效的微调技术 LORA,从而基于包含图像-文本对和真实掩码的 RES 数据集进行模型训练。LoRA 输出位置提示, 包括边界框 和 组正点和负点 Prompt , 如图 (a)所示,其中一组包含 个正点和 个负点( )。
为了向 LoRA 提供位置监督, 在训练阶段根据物体掩码随机采样 组点 , 然后将这些提示发送给 SAM 。对于每一组, SAM 输出分割结果。过滤掉与真实掩码相比 IoU 较低的提示, 仅保留前 组(如图(c)所示)。在该实现中,仅需要文本损失(自回归交叉摘损失)。 通常为 。
在推理阶段,LoRA直接输出发送给SAM进行分割的点,如图 (b) 所示。
SAM4MLLM-PQPP

PQPP 利用 MLLM 的查询-响应能力, 而不是直接生成提示。对提示点进行采样, 并主动询问 M LLM 这些点是否在掩码内(或外)。在训练阶段, 根据真实掩码随机采样一个边界框和 组点, 并进行两轮对话。在对话的第一轮中, LoRA 响应一个边界框。在第二轮中, 对于每个 个点, LoRA 在训练期间响应该点是否在掩码内(是或否)。
在推理阶段,LoRA在第一轮中为输入的文本查询和图像输出一个边界框。然后,在边界框内均匀采样点并在第二轮再次发送给MLLM-LoRA,并询问它们是否为正点(或负点),用于SAM进行分割。通常将网格大小设置为。为了在发送到SAM之前提供高质量的提示点,低置信度的点将被移除。
RES训练
为了使基础MLLM与RES任务对齐,使用包含与RES相关示例的三个数据集来指导模型朝目标前进。其中两个(RES数据集和gRefCOCO数据集)包含具有真实掩码的RES数据,第三个(VQA)是一个没有掩码的视觉对话数据集,用于进一步增强联合视觉-语言理解的总体能力。
在训练期间,为了保持MLLM在图像上的泛化能力,冻结了大部分网络参数,只调整了MLLM的视觉重采样器和LoRA适配器。
对于上述提到的所有数据集,我们在训练过程中不使用数据增强,因为翻转和/或裁剪可能会改变图像中物体的相对位置或关系。
主要实验




#满血版o1倒计时
震撼预警:满血版o1倒计时!奥特曼完整专访流出:o系列疯狂迭代,马上起飞
OpenAI满血版o1即将出世的消息,让科技圈瞬间沸腾!就连奥特曼本人透露,推理是OpenAI笃定的一个重要未来,o系列模型将在未来快速迭代。
确认了,满血版o1或许真的要来了!
两天前,「谜语人」Sam Altman一条神秘的o2「预告」,直接让全网炸开了锅。
要说营销鬼才,还的是奥特曼
而在调侃之余,也有网友发文直指问题要点:「o1泄露到底是怎么回事?模型是不是完整版?最近会不会发布?」
紧接着,外媒Futurism发文称,自己获得了一份官方声明——OpenAI的确准备开放o1模型的有限外部访问权限,但在过程中遇到了一个问题。
目前,这一问题已经得到了修复。(可能指的就是这次的泄露事件)
根据已知的信息,完整版o1将具备函数调用、开发者message、结构化输出、流式传输等能力,并且很可能会成为OpenAI有史以来最显著的一次突破性进展。
其中,图像理解和200k token上下文,已在上周末率先被全网玩疯。
种种这些猜测或许并非空穴来风,毕竟除了玩梗式的的推文外,Sam Altman本人也曾在公开场合暗示——o系列模型将会得到快速的改进。
几天前的OpenAI伦敦开发者日上,来自20VC的Harry Stebbings,与Altman开启了线上对谈。
Altman在QA环节中直言,OpenAI模型会越变越好,如果我们继续迭代下去,就会粉碎更多初创公司。
o系列全新进化,就在眼前
问题1:展望未来,OpenAI的发展方向是推出更多类似o1这样的模型,还是大家所预期的更大规模的模型?
Sam Altman表示当然希望在各个方面有所突破,而推理模型对OpenAI来说尤为重要。
他认为,也希望LLM推理能力的提升,能够打开一扇新的大门,让OpenAI能够实现多年来一直期待的许多功能。
比如,推理模型或许会为新的科学发现做出贡献;帮助人类编写更复杂的代码......这些都将推动科技的显著进步。
因此,我们可以期待o系列模型将会得到快速的改进,这对OpenAI自身来说,具有重要的战略意义。
问题2:展望OpenAI未来规划,你如何看待为非技术背景创始人,开发无代码工具,帮助其构建和扩展AI应用?
Altman坚定地认为这一定会实现的。而第一步是开发能够提高编程效率的工具,让已经会编程的人更加高效。
但最终目标是,OpenAI能够提供真正高质量的无代码工具。
实际上,现在市场中已经有一些优秀的0代码工具,但若要说,通过这一方式构建一个完整的创业项目,还需要一段时间。
初创公司机遇在哪?
问题3:如果有人现在花很多时间微调他们的RAG系统,这是不是在浪费时间?OpenAI最终可能会掌控应用层的这部分,对吗?你会如何去回答一个有这种疑虑的创始人?
Altman对此表示,「我们通常会这样回答:OpenAI会全力以赴,并且相信我们能够不断提升模型的性能」。
如果你的业务主要是修补当前模型的一些小缺陷,那么一旦我们成功改进了模型,你的业务可能就不那么重要了。另一方面,如果你的公司能够从模型的不断进步中受益,那就再好不过了。
他更进一步解释道,创业公司的机遇藏在哪里?
假设今天有个预言家告诉你,OpenAI o4模型将会非常出色,能够完成现在看来不可能的任务。那么即使预测可能有误,但至少这符合OpenAI的发展方向。
若是你选择了o1-preview表现不佳的某个领域,打算修补让其勉强能用。而这个问题,可能在OpenAI下一代模型中自然就解决了。
也就是说,与其小修小补,不如将更大的精力放在更有价值的方向上。
这也是OpenAI试图向创业公司传达的基本理念。
问题4:对于你刚才提到的某些领域,确实存在被OpenAI碾压的可能性。如果现在有创业者在思考,OpenAI可能会在哪些领域形成压倒性优势,而在哪些领域不会?作为投资人,也在寻找哪些不会受到冲击的投资机会。创业者和投资人应该如何看待这个问题呢?
Altman认为,未来将会有数万亿美元的新市值被创造出来。
这些市值将来自于利用AI开发的产品和服务,这些创新在之前要么是不可能实现的,要么是非常不切实际的。
OpenAI会把模型做到最好,无需投入巨大精力就能完成你想要的任务。但是除此之外,还有大量机会是在这项新技术基础上开发令人惊叹的产品和服务,Altman认为这些机会只会越来越多。
这里,他再次强调了,如果企业正在开发一个工具,是为了绕过某个模型的缺点,那么这个工具很快就会被淘汰掉。
在当时看起来,开发一些工具面部模型的不足,似乎是一个不错的方向。但现在,初创公司应该着眼于开发真正有价值的应用,比如出色的AI辅导老师、AI医疗顾问等。
Altman感觉,之前之前有95%的人在押注模型不会有太大进步,只有5%的人相信模型会显著改进。但现在,这个情况已经完全反转了。现在,人们已经意识到了模型改进的速度,也了解到了OpenAI发展计划。
AI创造数万亿美金价值
问题5:软银董事长孙正义预测每年AI将创造9万亿美元的价值,这将抵消他认为所需要的9万亿美元资本支出。我很好奇,当你看到这个预测时,你是怎么想的?你如何看待这个观点?
Altman表示,我不能把它归结为任何具体的数字。我认为如果能在数量级上大致正确,那对现在来说就足够了。显然,这个领域将会有大量的资本支出,同时也会创造巨大的价值。这在每一次重大技术革命中都会发生,而AI显然就是这样一次革命。
明年OpenAI将大力推进下一代系统。无代码软件智能体诞生,虽不知还需要多长时间,但可以以此为例来展望未来。
想象一下,如果任何人都可以描述他们想要的整套企业软件,这将为世界经济带来多大的价值。当然,这还需要一段时间。
但当我们实现这一目标时,想想现在开发这样的软件有多困难和昂贵。如果能维持相同的价值,但使它更容易获得、更便宜,这将产生巨大的影响。
Altman认为未来会看到许多类似的例子。包括此前,他提到的医疗保健和教育,这两个领域如果能得到改善,对世界来说都价值数万亿美元。如果AI能以全新的方式推动这些领域的发展,那将是非常令人兴奋的。
AI智能体,完成人类不可能的事
问题6:就AI价值传递的机制而言,开源是一种非常重要的方法。你如何看待开源在AI未来中的角色?当你们内部讨论是否应该开源某些模型时,考虑的因素是什么?
Altman同样认为在AI生态系统中,开源模型显然占据非常重要的位置。而且,现在已经有一些非常优秀的开源模型存在。同时,他认为也需要有市场需求为精心设计、集成良好的服务和API。
他表示,所有这些技术都应该被提供出来,让人们根据自己的需求进行选择。OpenAI有开源模型,但作为面向客户的最终产品和服务方式,OpenAI会选择提供AI智能体。
问题7:你如何定义今天的AI智能体?对你来说,什么是AI智能体,什么不是AI智能体?你认为人们对AI智能体的理解有什么误区?
对此,Altman认为AI智能体是这样的:你可以给它一个长期任务,在执行过程中只需要最少的监督。
在人们认知误区上,Altman称更多的是我们都还没有直觉去理解在未来世界里AI智能体会是什么样子。
对此,他举例做了说明。当人们谈论AI智能体代表他们行动时,经常给出的例子是:你可以让AI智能体为你预订餐厅。然后,它就会自己打开OpenTable或者直接给餐厅打电话。
但AI智能体更有趣的是,在这样一个世界里,你可以做一些作为人类你不会或不能做的事情。
比如,不是让AI智能体给一家餐厅打电话订餐,而是让它同时联系300家餐厅,并找出哪一家对你来说最特别的。
不仅如此,在300个地方可以接电话的也是智能体。它可以进行人类无法做到的大规模并行操作。
这只是一个简单的例子,但它展示了AI智能体可能突破人类带宽限制的潜力。
另外,Altman认为AI智能体更有趣的应用是,成为一个一个非常聪明的高级同事。你可以与之合作完成项目,它可以很好地完成一个为期两天或两周的任务。当它遇到问题时会联系你,但最终会给你带来很棒的工作成果。
问题7:这是否从根本上改变了SaaS的定价方式?通常SaaS是按用户数量收费,但现在AI智能体实际上是在替代人力。考虑到AI智能体可能成为企业劳动力的核心部分,你如何看待未来的定价模式?
对此,Altman推测道,你可以选择使用1个、10个或100个GPU来持续处理问题。这不是按用户数或按智能体数收费,而是基于持续为你工作的计算量来定价。
问题8:我们是否需要为AI智能体使用专门构建模型,还是现有模型就足够了?你怎么看?
毋庸置疑,OpenAI还需要构建大量基础设施和算法框架。目前,o1模型就是朝着完成出色智能体任务模型方向发展的。
模型是贬值资产,但会有正向效应
问题9:在模型方面,业界普遍认为模型是贬值资产,模型的商品化趋势非常明显。你如何看待这个问题?考虑到训练模型所需的资本投入不断增加,我们是否实际上看到了这种趋势的逆转,即只有少数人能够负担得起模型训练的成本?
Altman称,模型确实是贬值资产,但称其价值不如训练成本高,这种观点似乎完全错误。更不用说,当你不断训练模型时,会产生一个正向的复合效应,你会越来越擅长训练下一个模型。从模型中实际获得的收入,他认为是能够证明投资是合理的。
但这种情况并不适用于所有公司。可能有太多人在训练非常相似的模型。如果你的技术稍微落后,或者你的产品缺乏那种能提高用户粘性的常规商业特性,那么确实,你可能难以获得投资回报。ChatGPT是成功案例代表,拥有数亿用户。所以即使成本很高,OpenAI也可以在大量用户之间分摊这个成本。
问题10:你如何看待OpenAI模型如何随着时间的推移继续保持差异化,以及你最想关注哪些方面来扩大这种差异化?
推理是OpenAI目前最重要的关注领域。Altman认为这将是解锁下一个巨大价值飞跃的关键。
OpenAI团队会在很多方面改进模型,包括进行多模态工作,以及在模型中加入其他对用户非常重要的功能。
问题11:你如何看待推理和多模态工作?面临的挑战是什么,你想要达到什么目标?我很想了解这一点。具体是指推理和多模态的结合吗?
Altman肯定道,我希望这能自然而然地发挥作用,显然,实现这一目标需要付出一些努力,但你知道,就像人类婴儿和幼儿,即使在语言能力还不成熟的时候,也能进行相当复杂的视觉推理。所以这显然是可能实现的。
问题12:OpenAI如何在核心推理能力方面取得突破?我们是否需要开始推进强化学习作为一种途径,或者除了Transformer之外的其他新技术?
关于OpenAI做到这点的独门秘诀,即便是人们不确切如何做到的,也能复制出来。但真正令Altman自豪的一点是,团队能够反复去做一些全新的、完全未经证实的事情。这是推动人类进步最重要因素之一。
所以,Altman幻想退休后要做的事情之一是写一本书,分享自己学到的关于如何建立一个能做到这一点的组织和文化的所有经验,而不是仅仅复制其他人已经做过的东西。
要让公司伟大,就只招30岁以下员工?奥特曼:没这回事
问题13:你提到人才被浪费,能具体解释一下吗?
Altman表示,世界上有很多非常有才华的人没有发挥出他们的全部潜力,原因可能是他们在一家不适合的公司工作,或者他们生活在一个缺乏良好就业机会的国家,或者其他各种原因。
AI让我最兴奋的一点是,我希望它能帮助我们,比现在更好地让每个人发挥最大潜力,而我们现在离这个目标还很远。我相信,如果给予机会,世界上有很多人本可以成为杰出的AI研究人员。
问题14:在过去几年里,你个人经历了令人难以置信的超高速增长。如果回顾过去10年你在领导力方面的变化,你认为最显著的变化是什么?
他认为,这几年对自己来说最不寻常的是事物变化的速度。OpenAI几乎在两年内完成了从零增长到1亿美元收入,再到10亿,再到100亿的过程。
OpenAI不仅要做研究,还要从0开始建立一个公司。他们并不是一个传统意义上的硅谷创业公司,那种逐步扩大规模并服务大量客户的公司。而且,OpenAI面临的挑战是独特的,需要在极短的时间内完成从研究到大规模商业化的全过程。
问题15:有哪些事是你不知道,但希望能有更多时间去学习的?
他表示,在脑海中一长串问题中,有一个特别突出,那就是如何让公司实现下一个十倍增长,而不是10%增长。
这是个十分困难的问题,实现10%的增长,之前有效的方法会依然有效;但要让一个公司的收入从10亿美元达到百亿美元,就要发生许多变化。
在这个增长如此迅速的环境中,人们甚至没有时间掌握基础知识。
他严重低估了朝下一个大目标前进所需的努力,同时还要兼顾其他事情。
这就需要大量的内部沟通,包括分享信息、建立结构,让公司每隔几个月就能思考十倍的、更复杂的问题。比如如何规划当前的紧急任务和长期项目。
具体来说,为了一两年后的发展,怎样提前扩展算力?或者是一些看似普通但很复杂的事,比如在旧金山规划足够的办公空间。
因为没有任何先例,所有只能摸着石头过河。
问题16:企业家Keith Raboy在一次演讲中提到,他从Peter Thiel那里学到,雇佣30岁以下的年轻人,就是建立伟大公司的秘诀。你怎么看待这个建议?
Altman表示,自己创立OpenAI的时候,就是在30岁左右。这建议值得一试,但也没那么绝对。
每个公司和团队的情况都不同,关键是要找到适合公司文化和发展阶段的人才。
无论是带来青春、活力和雄心的「特洛伊木马」,还是经验丰富的「老人」,雇佣这两类人都能成功。
他提到,就在刚刚自己还在给同事发消息,讨论最近新雇佣的一个年轻人。虽然才20出头,但他的表现令人惊叹,能不能找到更多这样的人呢?不过另一方面,我们在设计人类史上最贵、最复杂的计算机系统时,完全没有经验的人会让人担忧,因为风险太高。
因此,理想的情况是二者兼顾,在任何年龄段都有极高才能标准的人。
按年龄划分人才,显然太简单粗暴了。Y Combinator给我的最大感悟就是,缺乏经验并不意味着没有价值,在职业生涯初期就表现出惊人潜力的人,可以创造更大的价值。我们应该押注这样的人。
问题17:现在很多人觉得Anthropic的模型在编码任务上表现更好,你怎么看待?开发者何时应该选择OpenAI,何时选择其他模型提供商?
奥特曼表示,的确他们的模型在编码上很出色。至于开发者如何选择,取决于具体任务和需求。每个提供商都有优势,开发者可以多尝试,看谁在特定用例中表现更好。
而在未来,AI将会无处不在。奥特曼认为,目前我们还是在讲单个AI模型,但未来我们一定会转向讨论整个AI系统。
Scaling Law还会多久
问题18:有人说Scaling Law不会持续太久了,但它比我们想象的时间长。你怎么看?模型性能提升的轨迹会像现在这样继续吗?
奥特曼表示,模型能力改进的轨迹会像从前一样继续演进,在很长一段时间内都会如此。
难道你从未对此怀疑过吗?
他表示,自己当然会遇到一些无法理解的模型行为,如失败的训练尝试等等。每当我们接近一个技术范式的极限,都必须开辟新的道路。
在这个过程中,他也曾遇到最难克服的挑战。
比如研究GPT-4时,一些棘手的问题在相当长一段时间内困扰了团队很久,但最终还是解决了。而在转向o1和推理模型的过程中,道路也是漫长而曲折。
这时如何保持团队士气呢?奥特曼表示,很多人都对AGI充满热情,这本身就是一个强大的动力,没有人会觉得这条路很轻松。
他引用了这样一句话:「我从不祈求上帝站在我这边,而是祈求自己站在正确的一边」。押注深度学习,感觉就像站在了正确的一边。
问题19:有一句名言叫,「生命中最沉重的东西不是铁或金,而是未做出的决定」。什么未做出的决定最令你沉重?
奥特曼表示,其实并没有一个特别大的决定困扰着自己。会有一些重要决策风险极高,一旦做出就难改变,比如是否投资下一个产品,或者如何构建下一代计算机系统。他会和大多数人一样,拖延做出决定。
要说真正困难的,是每天都会出现的「51/49」决定,也就是说这些决定几乎没有明显的对错之分。
之所以这些决定会到自己这儿,就是因为很难抉择,自己也并不见得比他人做得好。给人压力的这种抉择太多了,而非任何一个特定的决定。
而面对这些时,奥特曼也没有一个固定的商量人选。
他认为,正确的做法是有15到20个信赖的人,每个人在特定领域都有良好的直觉和丰富的经验。
奥特曼的担心:复杂性疯长
问题20:你最担心的是什么?
Altman称,我最担心的是我们整个AI领域正在尝试做的所有事情的普遍复杂性。虽然我相信最终一切都会好起来,但目前这感觉像是一个极其复杂的系统。
现在,这种复杂性在每个层面上都在疯狂地增长。不仅仅是整个行业,在OpenAI内部,甚至在任何一个团队内部都是如此。
举个例子,刚刚谈到的半导体担忧,你必须平衡电力供应、网络决策、及时获得足够芯片的能力,以及可能存在的各种风险。
同时,你还需要准备好相应的研究来配合这些资源。这样你就不会措手不及,或者拥有一个无法充分利用的系统。你需要有正确的产品来使用这些研究成果,以支付那些令人瞠目结舌的系统成本。
所以,仅仅说「供应链」可能会让它听起来太像一个简单的流水线了。实际上整个生态系统的复杂性,在每个层面就像分形扫描一样,与自己之前在任何行业看到的都不一样。
AI与互联网革命完全不同
问题21:很多人将当前的AI浪潮比作互联网泡沫时期,因为它们都有类似的兴奋和热情。你觉得这种比较恰当吗?
Altman认为这两者有很大的不同,尤其是在资金投入方面。Larry Ellison曾说,要入局基础模型的竞赛,起步就需要1000亿美元。
你同意这个说法吗?当你听到这个数字时,你的反应是什么?
Altman称,不,我认为实际花费会比这少。但这里有一个有趣的观点:人们总是喜欢用以前的技术革命来类比新的技术变革,试图将新事物置于更熟悉的背景中。我认为这总体上是一个坏习惯,尽管我理解为什么人们这么做。更重要的是,我认为人们选择用来类比AI的那些例子特别不恰当。
比如说,互联网显然与AI非常不同。你提到了成本问题,是否需要100亿美元或1000亿美元才能在AI领域具有竞争力。但互联网革命的一个显著特征是,很容易入门。
现在,有一点可能更接近互联网的是,对于许多公司来说,AI可能只是互联网的延续。就像其他公司制造AI模型,而你可以使用这些模型来构建各种创新产品。AI在这种情况下就像是构建技术的一个新的基本要素。但如果你试图构建AI系统本身,那就是一个完全不同的游戏了。
还有人将AI比作电力革命,你怎么看?
Altman表示,人们确实经常用电力来类比AI,但我认为这在很多方面都说不通。如果非要做类比的话,我认为晶体管可能是一个更好的例子。
晶体管是物理学的一个重大发现。它具有令人难以置信的扩展性,很快渗透到各个领域。就像我们有摩尔定律来描述计算能力的指数增长,现在我们可以想象出一系列关于AI的定律,告诉我们它将如何快速迭代。
整个科技行业都从晶体管技术中受益。你使用的产品和服务中涉及了大量晶体管,但你并不会把这些公司看作是「晶体管公司」。同样,未来AI可能会无处不在,但不是每个使用AI的公司都会被称为「AI公司」。
OpenAI未来两年蓝图
关于OpenAI未来五到十年的发展规划,如果你有一根魔杖,能够描绘未来的场景,你能为我勾勒一下OpenAI在五年和十年后的蓝图吗?
Altman对此表示,自己可以轻松描绘出未来两年情况:如果OpenAI目前方向是正确的,并且能够开发出优秀的AI系统,特别是推动科学进步方面。
他认为,在5年内,我们可会看到技术本身以令人难以置信的速度改进。
预测的第二部分是,尽管技术飞速发展,但社会本身的变化可能出人意料地小。举个例子,如果5年前问人们,计算机是否会通过图灵测试,他们可能会说不会。如果你告诉他们计算机真的通过了,他们可能会认为这将给社会带来翻天覆地的变化。
事实上,OpenAI在某种程度上满足了图灵测试的标准,但社会并没有发生那么大的变化。
这种现象可能会继续发生:科学进步不断超出所有人的预期,而社会变化相对缓慢。当然,从长远来看,社会终究会发生巨大的变化。
快问快答
Harry:如果你现在是23、24岁,以我们今天的技术基础设施,你会选择开发什么?
Altman:我会选择开发一些由AI支持的垂直领域产品。比如说,一个最先进的AI辅导系统,能够教授任何类别的知识。它可以是AI律师,也可以是AI辅助的CAD程师,诸如此类。
Harry:你之前提到过想写一本书。如果你要写这本书,你会给它起什么名字?
Altman:我还没有想好具体的标题。但我知道我希望这本书能够存在,因为它可以释放大量人类潜力。
Harry:在AI领域,有什么是目前被忽视,但你认为每个人都应该更关注的?
Altman:一个能够理解你个人生活的AI系统。它不一定要有无限的记忆容量,但至少是一个AI助手,它了解关于你的一切,可以访问你所有的数据等。这个问题有很多不同的解决方法,但核心是创造一个真正了解个人的AI。
Harry:在过去的一个月里,有什么事让你感到特别惊讶?
Altman:是一个我不能公开讨论的研究结果。但我可以说,它令人惊叹地好。
Harry:你最尊重哪个竞争对手?为什么是他们?
Altman:说实话,我某种程度上尊重这个领域的每个参与者。我认为整个AI领域都有令人惊叹的工作在进行,有许多才华横溢、非常勤奋的人在其中。我不是想回避这个问题,而是真的觉得在这个领域到处都有非常有才华的人在做出色的工作。
Harry:所以没有特别突出的一个?
Altman:确实没有特别突出的一个。
Harry:你最喜欢的OpenAI API是什么?
Altman:我们新推出的Realtime API非常棒。但要知道,我们现在有一个相当大的API业务,里面有很多优秀的产品。
Harry:你现在最尊重AI领域的哪位人物?
Altman:虽然AI领域有很多人在做令人难以置信的工作,但我认为Cursor团队的成就真的很特别。我本可以列举一些杰出的研究人员,但说到使用AI提供真正神奇的体验并创造巨大价值,以一种别人还没完全掌握的方式,我觉得Cursor团队做得相当出色。在思考这个问题时,我特意没有考虑OpenAI的任何人,否则OpenAI的人会占据名单的前列。
Harry:你如何看待AI系统中延迟和准确性之间的权衡?你认为是否需要一个调节器来在它们之间切换?
Altman:这是一个很好的问题。就像现在我们在进行快速问答一样,我虽然没有回答得特别快,但也在尽量不过多思考。在这种情况下,低延迟是我们想要的。但如果你说:「嘿,Sam,我希望你在物理学上做出一个重要的新发现」,你可能会很乐意等待几年。所以答案是,这应该是用户可控的。根据不同的使用场景,用户应该能够调整AI系统的响应速度和准确度。
Harry:你希望在改进领导力方面时,最想在哪方面改进?
Altman:这周我最困扰的事情是,我对我们的产品策略细节感到比以往更加不确定。我认为产品总体上是我的一个弱项。而现在公司需要我在这方面提供更强有力和更清晰的愿景。我们有一位出色的产品负责人和一个优秀的产品团队,但这是一个我希望自己能更强的领域。现在我正急切地感受到这种不足。
Harry:你提到了产品团队,你雇佣了Kevin Weil。我认识Kevin已经很多年了,他真的非常出色。在你看来,是什么让Kevin成为世界级的产品领导者?
Altman:「原则」是首先浮现在我脑海中的词。
Harry:在专注方面呢?
Altman:专注包括我们要果断地说「不」的能力,真正努力站在用户的角度思考为什么我们要做某事或不做某事,以及严格地避免陷入异想天开的幻想。我们需要保持务实和专注。
参考资料:
https://x.com/HarryStebbings/status/1853467276911300836
#EMOS
港大最新成果!基于大模型多智能体的异构多机器人操作系统
当人类进行团队协作的时候,为了协作效率,总是根据任务的需求和协作成员自身的背景能力,讨论协商包括任务分配在内的协作方案 。对于协作异构机器人系统 (Cooperative Heterogeneous Multi-robot Systems),如何去协作往往基于专家设计和编写的一套固定协作逻辑。然而开放世界任务的复杂性,越来越丰富的机器人硬件,对人工设计规则的多机协作系统扩展性构成了极大的挑战。
近日,来自新加坡国立大学、香港大学、上海人工智能实验室、牛津大学、CAMEL-AI社区等多家机构的联合研究团队提出了一种创新的异构多机器人操作系统EMOS(Embodiment-aware Heterogeneous Multi-robot Operating System)。该框架基于大语言模型的多智能体系统 (LLM-based Multi-agent System),以机器人物理定义文件和环境信息为输入,实现了对机器人空间物理能力和任务需求的理解,从而实现了更有效的任务规划,并利用大模型工具调用(Function Call)能力,进行多机系统分布式动作的执行。
同时该工作提出了 Habitat-MAS 评测基准,包含多种任务,例如跨楼层物体导航、协作感知、单层家庭重新排列和多机器人、多物体、跨楼层协作重新排列。实验结果表明,EMOS 框架在 Habitat-MAS 基准上取得了优异的性能,证明了其有效性。
论文地址:https://arxiv.org/abs/2410.22662

研究背景与动机
现有的异构多机器人系统(HMRS)在处理复杂任务时面临两大挑战:
高度依赖人工设计的协议, 泛化能力有限
自动化程度不足, 任务拆解和子任务的分配尚未实现完全自动化
由于每个机器人的硬件差异(如轮式、腿式或飞行平台),如何让各自的物理特性得以充分利用并进行有效协作,也是一大难题。比如轮式机器人不能通过楼梯跨楼层移动,不同机器人深度相机的位姿对能感知的物体空间范围有很大影响,不同机器人机械臂工作空间决定了能抓取到的物体高度,水平距离等。为解决这些问题,研究团队提出了基于LLM的多智能体框架EMOS,通过"机器人简历"机制实现对机器人物理能力的精确理解,从而实现更智能、自主的任务规划与执行。
主要方法介绍
机器人简历(Robot Resume)机制
EMOS 摒弃了传统的人工角色分配方式,通过大模型阅读分析以及前向运动学工具(Forward Kinematics Tools)调用的混合方法理解URDF文件,生成包含机器人移动能力、感知能力和操作能力的“机器人简历”。这些基于运动学计算的统计数据和数字数据,在后续会作为机器人代码生成的context 输入,去实现精确的空间检查和空间推理。比如一个物体是否可能超出了机器人抓取的范围。

分层式任务规划与执行
Habitat-MAS通过仿真器真实(Ground Truth)的场景布局和机器人信息,基于规则构建包含场景布局、机器人状态和物体状态的场景上下文(Scene Context)。这些上下文信息会和任务描述信息一起输入EMOS多智能体系统,进行处理。EMOS采用"集中式群组讨论+分布式并行执行"的两阶段架构:
- 为了得到一个结构化文本和task planning的收敛性,多轮集中式群组讨论后,大语言模型会对发言历史进行总结,并转换生成一个机器人任务分配的字典,用于分发子任务到各个机器人。
- 各机器人智能体通过大模型工具调用分布式并行执行子任务,机器人动作执行的API已经预先提供好。

实验平台与结果展示
Habitat-MAS基准测试平台
研究团队还开发了Habitat-MAS基准测试平台, 包含多层楼房等复杂场景并支持无人机、轮式机器人、腿式机器人等多种类型。这个测试基准中设计了4类测试任务, 这些任务包括跨楼层物体导航、协作感知、单楼层物体整理(object rearrangement)和多机器人、多物体、跨楼层物体整理等。各个任务或者子任务经过筛选处理,只有特定的机器人才能完成,随机策略会失败。
,时长00:18
实验结果
实验结果表明,EMOS在Habitat-MAS的各类任务中均显著优于现有方法,尤其在需要多机器人协作的复杂任务中表现突出。具体而言:
- 在需要机器人理解自身物理限制,部分机器人才能完成的任务中,EMOS在任务成功率上具有显著优势。
- 在复杂长序任务中,机器人简历和多智能体系统的集中讨论显著提升了任务完成率。
一些总结与展望
EMOS首次实现了基于机器人物理特性的自动化任务规划和分配,尝试去解决传统系统中人工规则设计过多的问题,为未来异构多机器人系统的完全自动提供了新的思路和一次探索,并且提供了评估异构多机器人协作系统的标准化测试平台。
未来,EMOS框架还可以进一步扩展:
- 增强系统的适应性:将EMOS框架扩展到更动态的环境和更复杂的任务。
- 与其他AI技术结合:将EMOS框架与强化学习和深度学习等技术结合,进一步提升HMRS的性能。
- 未来提升物理仿真效果,减小sim-to-real gap,可以进一步提升探索EMOS在真实机器人系统中的应用潜力
#AgentOccam
不靠更复杂的策略,仅凭和大模型训练对齐,零样本零经验单LLM调用,成为网络任务智能体新SOTA
网络智能体旨在让一切基于网络功能的任务自动发生。比如你告诉智能体你的预算,它可以帮你预订酒店。既拥有海量常识,又能做长期规划的大语言模型(LLM),自然成为了智能体常用的基础模块。
于是上下文学习示例、任务技巧、多智能体协同、强化学习算法…… 一切适用于通用智能体的想法都抢着在大模型落地。
然而有一个问题始终横亘在 LLM 和智能体之间:基于 LLM 的网络智能体的行动 / 观测空间与 LLM 训练数据的空间相去甚远。
智能体在充斥着具身行为的行动空间(如鼠标悬停、键盘组合键)和遍布前端功能强化、格式渲染的观测空间下运作,大语言模型的理解和推理能力能充分发挥作用吗?尤其是大语言模型的主要训练任务是文本补全、问答和对齐人类偏好,这一点值得思考。
来自伊利诺伊大学香槟分校和亚马逊的研究人员选择和这些问题进一步对话。他们去除了上下文示例、技巧、多智能体系统,仅仅通过行动 / 观测空间与 LLM 的训练任务对齐。他们训练的 AgentOccam 成为了零样本基于 LLM 的网络智能体新 Sota。
,时长01:09
帮你写email
,时长02:47
帮你找导师
这正呼应了奥卡姆剃刀原则:「若无必要,勿增实体」。然而换个思考的角度,AgentOccam 的研究团队也想发问:构建通用智能体时,在铺设复杂的系统框架前,是否已经优化了行动 / 观测空间,让这些功能模块达到了最优状态?
- 论文链接:https://arxiv.org/abs/2410.13825
- 论文名:AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
背景及动机
某天你刷着短视频,看中了主播手中拿着的商品。于是,你兴致勃勃地对智能助手说:「我是学生,让这个老板送我一张优惠券!」
随后,智能体申请了你的私人账号权限、后台私信商家、绘声绘色地写下「我是学生」,发送消息,一套动作无需人为干预,行云流水......一切这样的任务,再也不必动手,都有智能体代劳。
大语言模型是构建智能体的热门选择。过去,基于 LLM 的网络智能体通常专注于让智能体学会某种应用,比如构建上下文学习样本、积累任务经验与技巧、以及多智能体角色扮演等等。然而,在实际交互中,智能体的行动 / 观测空间与 LLM 的技能点不太匹配,这之间的差距却少有人研究。
于是,针对如何对齐基于 LLM 的网络智能体的观测和行动空间与其训练期间学到的功能,来自伊利诺伊大学香槟分校和亚马逊的研究人员们展开了研究。
网络智能体需要准确地从格式各异、编码脚本不一的网页中提取信息,并在网页上定义的动作(例如,鼠标滑轮滚动、点击或悬停在按钮上)中进行选择。这些网络观测和行动空间在 LLM 的预训练和后续训练数据中都较为罕见,这阻碍了 LLM 充分调动潜能,完成任务。
因此,基于不让智能体策略变得更复杂,而是让智能体与 LLM 更加匹配的想法,由此构建的智能体得名 AgentOccam。
形式化与方法
该团队通过部分可观测的马尔可夫决策过程(POMDP),将网络交互过程形式化为:<O,S,A,P,R,p_0,γ>。
在 POMDP 中,观测 o∈O 是智能体从网络环境接收到的信息,例如 HTML,以及任何指令和提示。行动 a∈A 是网络环境认可的动作指令。
为解决 POMDP,常见目标是寻找策略

,最大化预期累积奖励,其中 h_t 表示观测历史

。
在基于 LLM 的网络智能体设计中,这等价于借助一个或多个基础 LLM 策略

和一组算法模块来设计策略

。
在这项工作中,该团队专注于一类特殊的策略,可以表示为:

,其中 f 和 g 是处理观测和行动空间的基于规则的函数,该团队将其称为「观测和行动空间对齐问题」。
在这样的问题设置下,接下来的所有更改仅应用于观测和行动。值得注意的是,并非所有以往方法中的智能体策略都能以这种方式表示。

例如上表中,基于搜索的算法需要一个顶层控制程序来选择行动并触发回溯;带有评估器、反思或记忆模块的方法也需要一个管理中心来在主 LLM 和这些辅助模块或其他角色扮演 LLM 之间切换。
不同于以往复杂化智能体策略,我们能否仅通过优化观测和行动映射 f 和 g,使用基础 LLM 策略

构建一个强大的网络智能体?这是 AgentOccam 关注的问题。

如上图所示,AgentOccam 包括三个组成部分:
- 首先,减少非必要的网络交互动作,让智能体的具身和琐碎互动需求达到最小;
- 其次,消除冗余和不相关的网页元素,并重构网页内容块,以获取更简洁但同样信息丰富的表示,从而精炼观察空间;
- 最后,引入两个规划动作(分支和修剪),这使得智能体能够以规划树结构自组织导航工作流,并使用相同结构过滤历史步以进行回放。
整个框架通过一套适用于所有标记语言的通用规则来格式化网页,无需依赖测试基准中的任务相关信息。

网络智能体的行动空间规定了可以用来与网络环境交互的有效命令。
研究团队从智能体常见的失败中得出总结:想要成功完成任务,需要编辑行动空间来解决两个关键问题:第一,去除 LLM 难以理解且经常误用的无关行动;第二,当执行任务需要规划、尝试多个潜在路径时,要提高智能体的记忆和规划能力。
为此,该团队提出了对应的解决方法。第一个问题可以通过简单地移除或合并操作来解决(如上图中的步骤 1 和 2)。对于第二个问题,过去的研究通常依赖人工制定规则或任务技巧,但这些方法难以泛化。在本研究中,LLM 将自主生成计划和管理任务流程(如步骤 3 所示)。

AgentOccam 的观测空间(提示词)包含了任务概述的通用指令、期望的输出和可用操作说明,以及关于当前任务目标、智能体过去的交互记录和最新的观察信息。
过往互动和当前观测的部分占据了最多的字符数。这主要归因于两个因素:单页面的长度和历史跨度的范围,这是 AgentOccam 观测空间的主要优化对象。

网页标记语言主要用于前端加载和渲染,往往包含大量格式化字符,显得冗余且重复(如上图步骤 1 所示)。因此,此时的目标是优化这些表示方式,使得单页内容对 LLMs 更加简洁易读。
将观测历史作为输入,对于执行长程任务至关重要。因为一些关键信息可能不会显示在当前页面上。然而,观测历史也会显著增加上下文长度,并增加推理难度以及推断成本。
为了解决这个问题,设置仅选择先前网页上最重要和相关的信息,这一选择依据两个规则,分别基于关键节点和规划树,见于步骤 2 和 3。
结果
研究团队在 WebArena 上评估了 AgentOccam 性能。WebArena 含有 812 项任务,横跨网购、社交网站、软件开发、在线商贸管理、地图等。
测试对象为 AgentOccam 框架下的 GPT-4-Turbo。对比的基线包括:一、WebArena 随配智能体,二、SteP,前 WebArena 上最优智能体,涵盖 14 条人类专为 WebArena 任务编写的技巧,三、多智能体协同方法 WebPilot;四、总结智能体交互经验的工作 AWM。

从上表不难看出,AgentOccam 性能优于以往及同期工作。其中,AgentOccam 分别以 9.8(+29.4%)和 5.9(+15.8%)的绝对分数领先往期和同期工作,并且通过其观测与行动空间的对齐,使得相似的基本网络智能体的成功率提高了 26.6 点(+161%)。




消融实验
逐模块对比行动与观测空间的对齐对最终结果的贡献。从下表可以看出,行动空间对齐能使智能体完成更多 click、type 等引导环境变化的动作,观测空间对齐则减少大模型调用的字符数与智能体完成任务所需的步数。

LLM-as-a-Judge
研究团队发现,智能体的决策行为波动性很强。简而言之,面对一个目标,智能体有一定概率做出正确的行为决断,但由于 token 预测的随机性,它可能做出一些高成本、低回报的决定。这也导致它在后续步骤中难以纠正之前的错误而失败。
例如,要求智能体在某个最相关的话题下发布帖子,单次 LLM 调用的 AgentOccam 往往轻率地选择话题,未考虑「最相关」的要求。
为了解决此类问题,他们引导 AgentOccam 生成单步内所有可能的行动,这系列行动将交付另一个 Judge 智能体(同样调用 GPT-4-turbo)决断,做出最大化回报的选择。
与复合策略结合使用
复合策略中,与任务相关的经验可以提升智能体性能。同时,不因为加入了更多背景知识扰乱决策,不会影响泛化性,能够纠正错误行为模式。
由于行为 / 观测空间对齐和复合策略方法正交,因此能结合利用。该团队试验将 AgentOccam 与 1)SteP 和 2)上述的 LLM-as-a-Judge 方法联合使用。
对于和前 SOTA 方法 SteP 联合,由于它引入人类编写的 WebArena 任务攻略,在经验密集型任务,如购物网页任务中,人类撰写的引导性经验大幅提升任务成功率。
而在常识泛化密集型任务,如社交网页发帖任务中,不相关知识出现会错误扰乱智能体决策。对于 LLM-as-a-Judge 方法,Judge 角色的引入不影响智能体的泛化性,同时纠正了智能体仓促决策的错误行为模式,在 WebArena 上进一步提升 2.6 的绝对分数。
#Manus
不吹不黑,拿到邀请码一手实测Manus,还有人0天就复刻出了开源版
在这篇文章中,我们记录了 Manus 的实际使用感受,并介绍了 Manus 的开源复刻版本。
昨天,一个叫「Manus」的通用 AI Agent 产品引起热议。它可以完成从文件处理、数据分析、代码编写到内容创作等多种任务,比如帮助用户生成旅行计划、分析股票数据、筛选简历或开发简单的网页游戏。
但是,由于「Manus」只发放了少量邀请码,能够体验到这款应用的人数目前还比较少。在电商平台上,邀请码的价格一度被炒到几万元,甚至还有人做起了帮助他人申请 Manus 邀请码的生意。
一系列行为,导致许多人无法直接体验到 Manus,这也为 Manus 招来了不小的质疑声音。
当然,大家最关心的还是 Manus 到底好不好用,这也是 Manus 的根本。
在拿到邀请码后,进行了一些测试,并将体验过程中感受到的 Manus 的优点和不足写了出来。我们不做「吹嘘」式的语言描述,只供大家参考。
此外,我们还注意到,一些行动力超强的 Agent 团队已经做出了 Manus 的开源复刻,包括 CAMEL AI 团队开源的 OWL 和 MetaGPT 团队开源的 OpenManus。
据观察,AI 学术 / 技术社区对于 Manus 的爆火保持相对冷静态度,尤其是 Agent 领域的专业人士。关于如何评价 Manus,读者可在了解相关信息后自行判断。
接下来,我们先分享一下 Manus 的实际使用体验。
Manus 效果如何?上手实测
首先来个基础的,「写个贪吃蛇小游戏」。是的,提示词就这么简单,看看 Manus 能否给我们带来惊喜。
按下发送键之后,Manus 一共执行了 5 分多钟,其中包含多步过程,包括创建贪吃蛇游戏文件、实现游戏基本机制、添加用户控制功能、开发计分系统、进行游戏功能测试、编写游戏使用说明文档、打包并交付游戏。
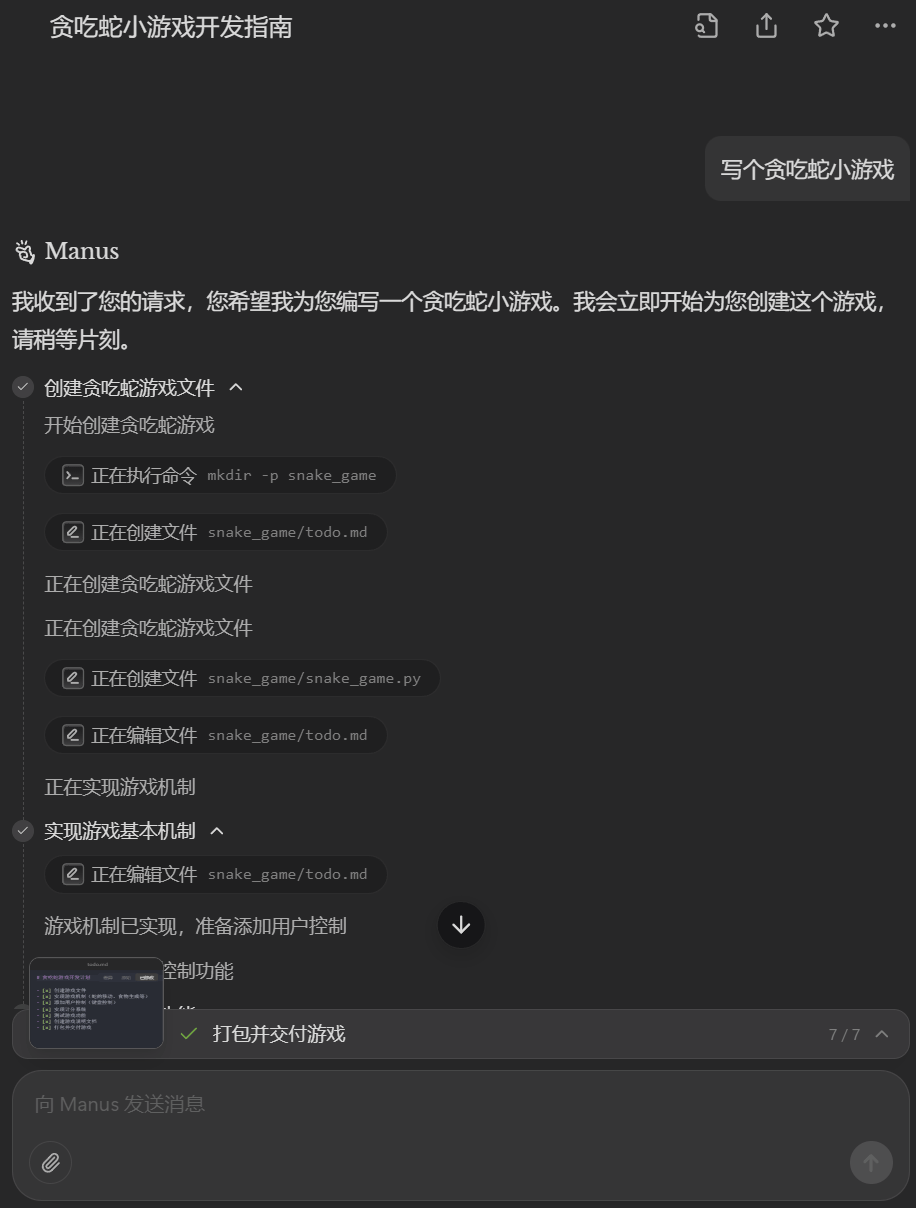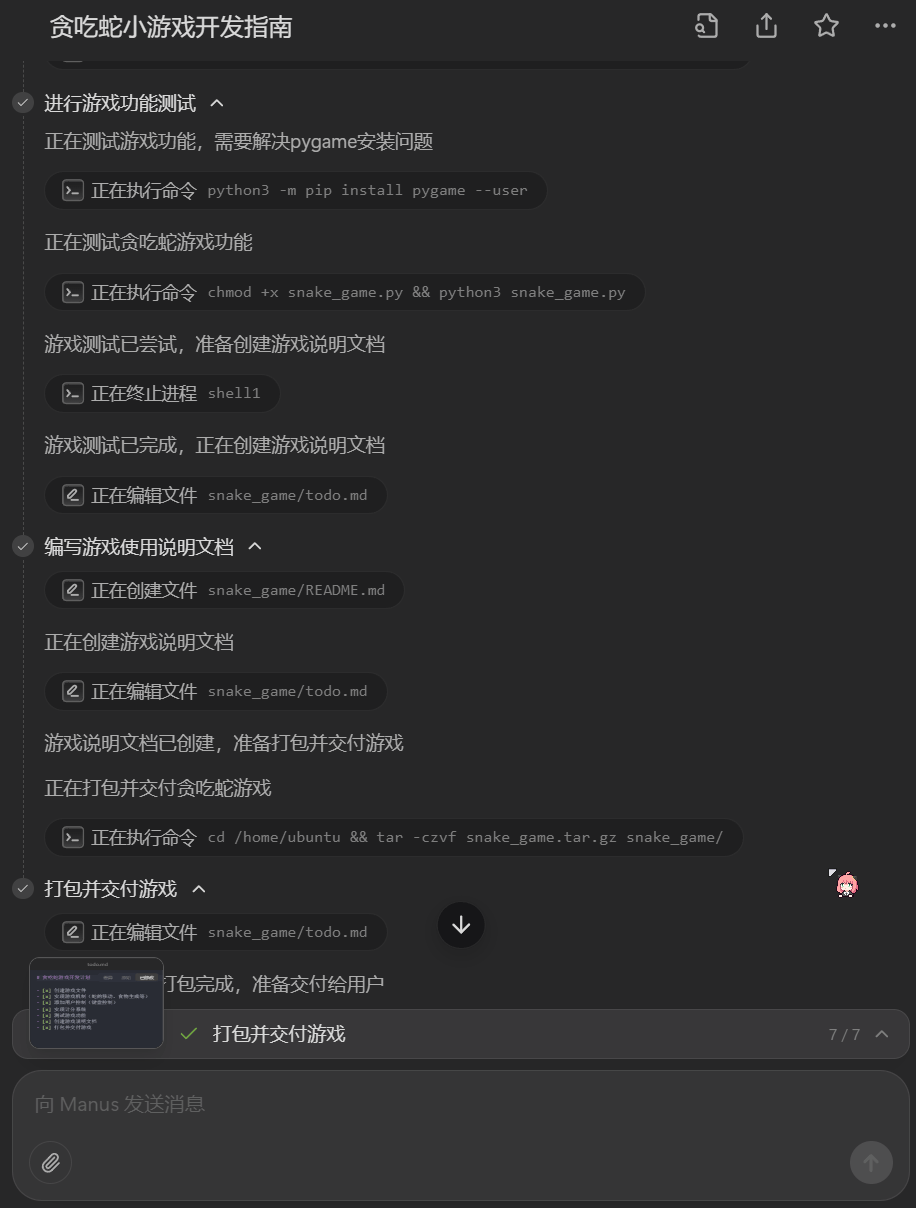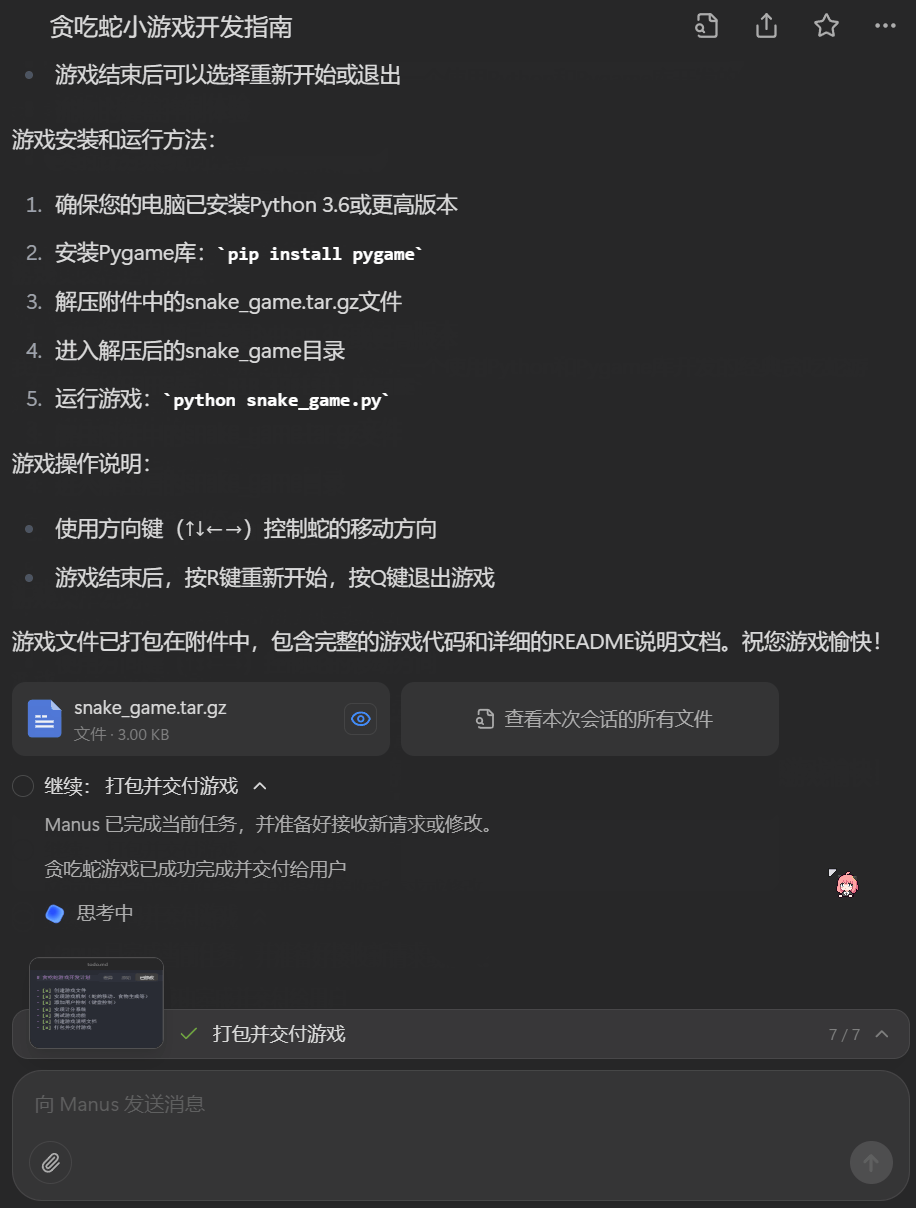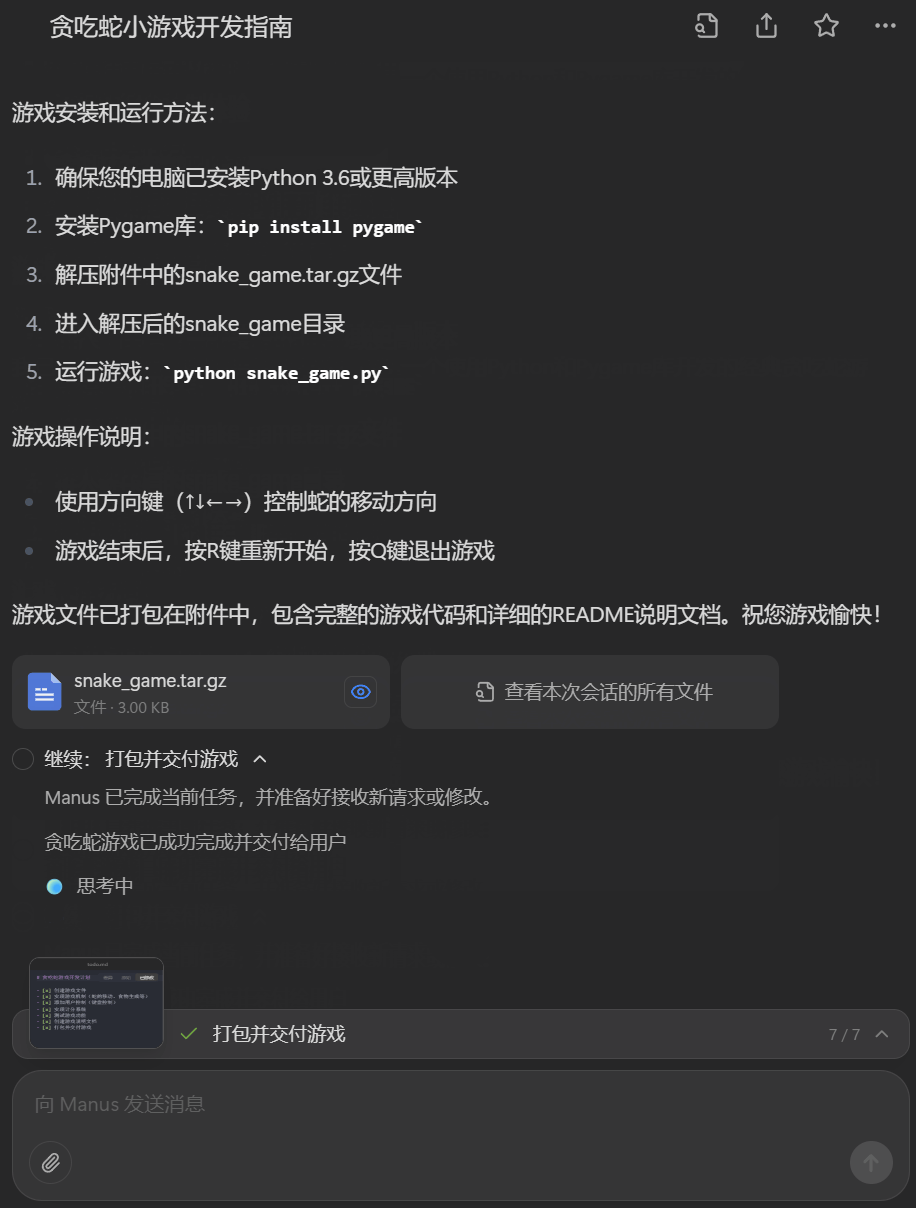
下载其输出的压缩包,看看效果如何。比较费解的是,Manus 这一次的输出结果是一个双重压缩包,也就是一个经过两次压缩的压缩包。
实测一下,是可玩的。Manus 确实实现了贪吃蛇游戏的基本逻辑和计分系统,不过看起来没有设定撞墙死亡判定,只有撞到自己时才会游戏结束。另外就是其网格线设计得过于明显 —— 但如果我们能在提示词中给出进一步的细节描述,效果应该会更好一些。
接下来,我们让 Manus 分析一下 Manus 话题的传播趋势,我们给出的提示词是:「检索网络,分析一下 Manus 话题的传播趋势,并写一份总结报告。」
这一次,Manus 思考的时间更长了,达到了 14 分钟,同样也分成 7 个步骤:搜索 Manus 话题的基础信息、分析 Twitter 平台上的 Manus 话题传播趋势、在其它社交媒体平台搜索 Manus 相关提及、整合趋势分析数据、撰写传播趋势总结报告。
其中每个步骤又包含若干小步骤,比如编写一个 Python 脚本来使用 Twitter API 等等。
并且在执行过程中,我们也能展开「Manus 的电脑」,查看其浏览网络和撰写报告的过程。
不过这一次,Manus 的表现并不好,比如在「分析 Twitter 平台上的 Manus 话题传播趋势」这一步,其未能成功使用 Twitter API,故而未能找到任何有用信息。它给出的解释是:「我注意到在 Twitter API 搜索中未找到 Manus 相关推文。这可能是因为 Manus 是一个较新的产品,或者搜索条件需要调整。我将继续在其他平台搜索 Manus 的提及情况,以全面分析其传播趋势。」考虑到 Manus 当前的热度,这个解释显然并不正确。
不管怎样,还是来看看报告结果吧。如下动图所示,输出结果包含三个 Markdown 文件,分别是趋势报告、趋势分析和背景信息。整体上看,虽然没有 Twitter 上的相关信息输入,但是通过分析和引述知乎文章以及一些媒体报道,内容还算充实详尽,其中甚至说明了 Manus 传播中自媒体先行的传播趋势以及引发的争议。
接下来试试看 Manus 能否帮助我们省钱:「预算 6000,给我配置一台可以剪视频、玩游戏的高性价比主机,把配置单发给我。」
这一次,Manus 规划的任务步骤达到了 8 步:研究当前 PC 组件市场、分析视频剪辑和游戏的硬件需求、分析视频剪辑和游戏的硬件需求、创建详细配置清单、验证组件兼容性、优化性价比、准备最终配置文档、发送配置给用户。
下面动图展示了 Manus 浏览网页查找相关信息的过程示例(原过程慢得多,这里有所提速):
18 分钟后,Manus 完成了这个任务,这是它给出的最终配置单。你觉得合理吗?

接下来,我们试了试让 Manus 玩 4399 小游戏。Manus 成功打开了网页,但却在登录页面受阻了。我们选择接管页面,微信登录,没有问题;但实名认证时却出现了状况 —— 我们无法在 Manus 内置的电脑中录入中文。以下视频展示了这次测试的全过程。
,时长04:31
最后,我们尝试了让 Manus 根据我们提供的一个排版网页编写一个 Notepad++ 宏,方便我们的排版工作。为此,Manus 首先需要分析所提供的网页完成的功能,然后还要学习 Notepad++ 宏的语法。
提示词:把这个网页 https://www.dute.org/type-setting 的功能转写成一个 Notepad++ 的宏。
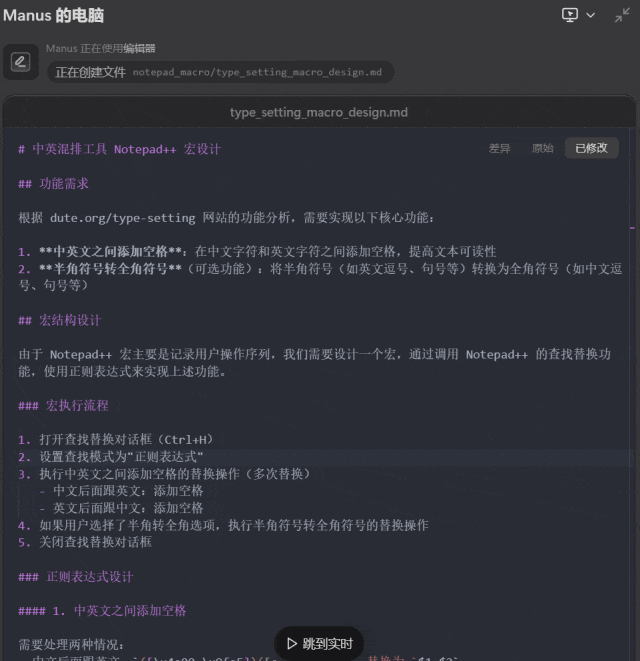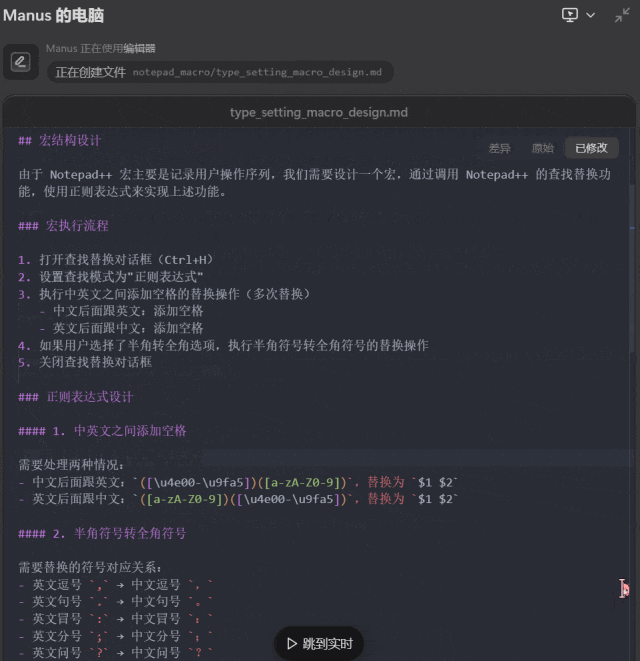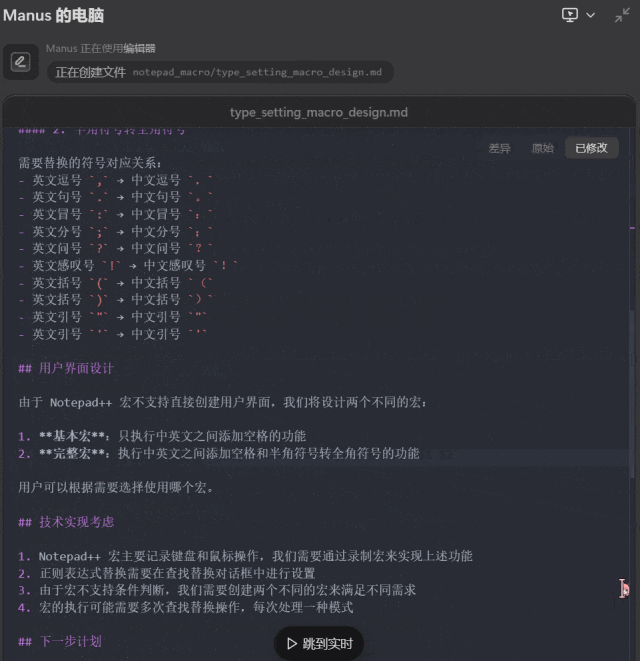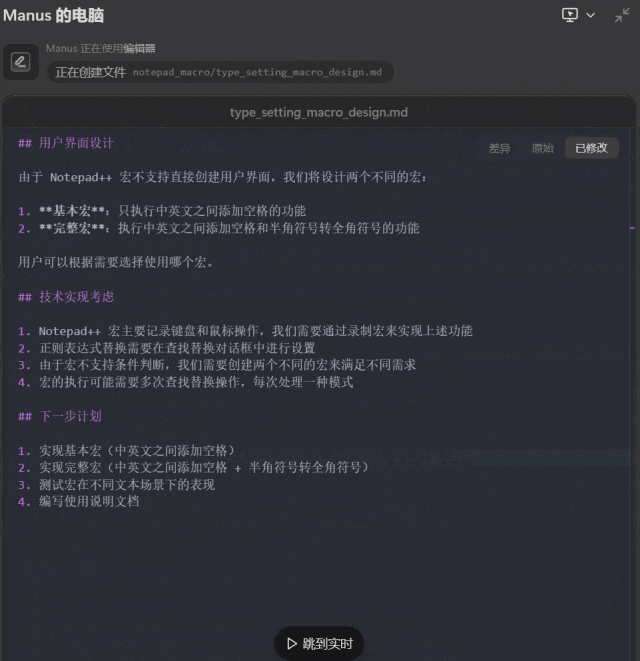
这一次,Manus 足足思考了 21 分钟,但结果却不尽如人意:在 Notepad++ 中的实测结果表明,Manus 编写的基本版和完整版都未能正确完成指定的任务,反而把我们的测试文本删除了。
这一次,Manus 失败了。
到这里,我们的每日用量限制就达到了极限,无法再进行更多测试了。

整体体验下来,可以简单总结一下 Manus 执行任务的过程:
- 首先,自然是分析问题。
- 接下来,Manus 会创建一个代办事项,其中包含主要步骤以及每个主要步骤下的各个细分任务;这通常是一个 todo.md 文件。
- 之后,Manus 会按照这个 todo.md 文件的事项一步步地执行。
- 最后,整理好结果并发送给用户。
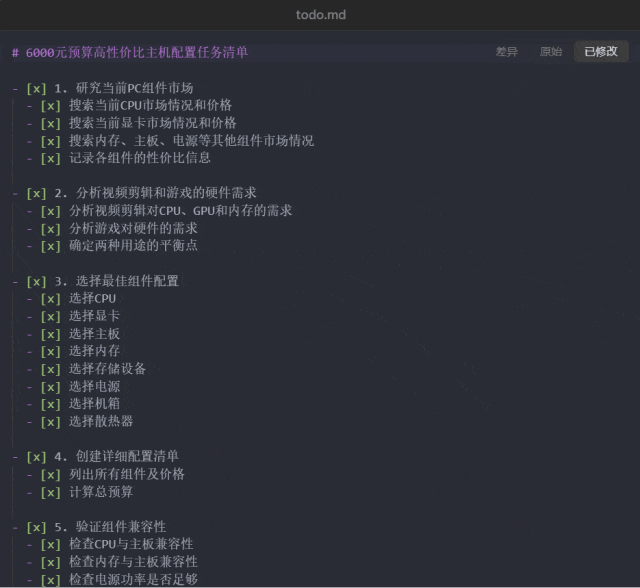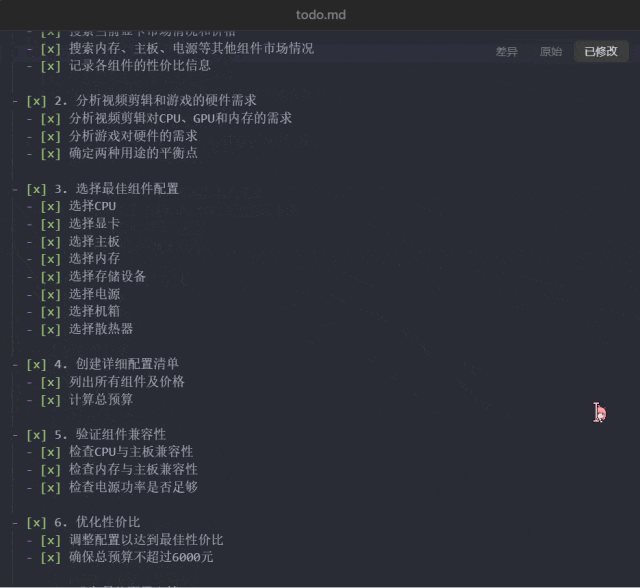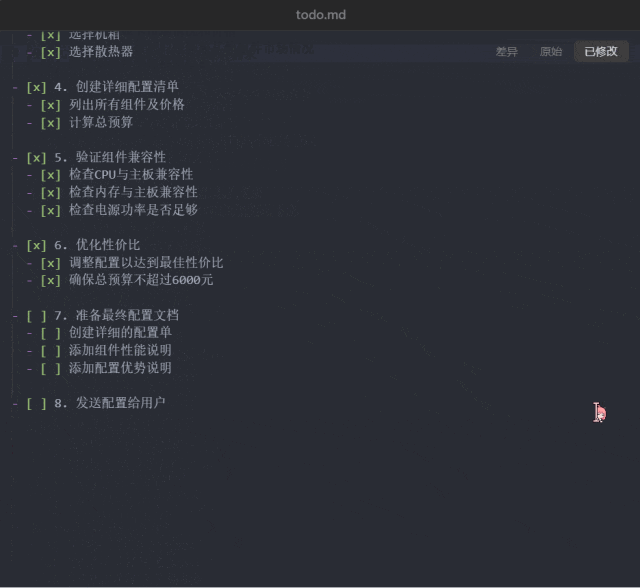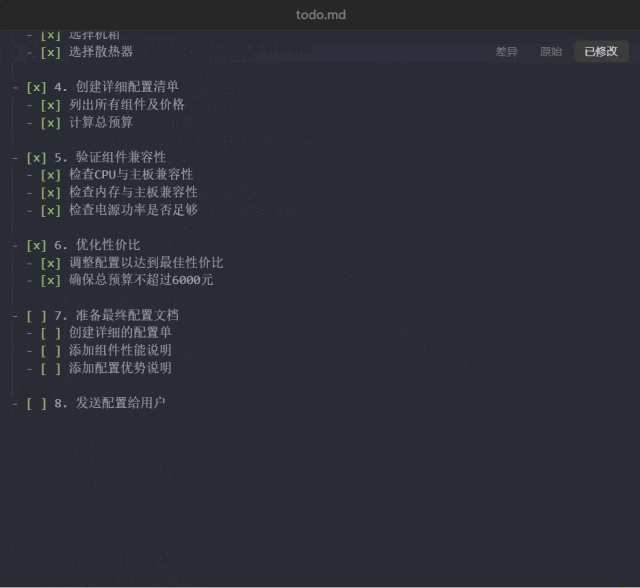
以上配置电脑任务中已经执行到第 6 步的 todo.md 文件
至于效果,虽有失败,但可以说整体还是相当不错的。虽然用户的体感速度很慢,但考虑到如果让用户自己来完成同样的任务,可能会耗费更多时间,因此使用这种性能的智能体来辅助工作应该是个不错的选择。
开源复刻版 Manus
接下来,我们介绍两个 Manus 开源复刻项目。
「别抢 Manus 邀请码了,开源版已经在路上。」这是国内开源平台 CAMEL AI 今天一大早带来的好消息。
他们的 Manus 开源复刻版名叫「OWL」,在 GAIA Benchmark 上性能达到 57.7%,超越了 Huggingface 提出的 Open Deep Research 55.15% 的表现,成为开源界 GAIA 性能天花板。(GAIA 是一个用于评估通用人工智能助手能力的基准测试,Manus 也做了相关测试。)

GitHub:https://github.com/camel-ai/owl
为了让 OWL 进化成真正的全自动多 Agent 打工神器,CAMEL AI 还对 Manus 的技术路线做了一波野生 Reverse Engineering(逆向工程),并顺势启动了深度复刻计划。
在这个计划中,他们把 Manus 核心工作流拆成了 6 步:

该项目可以说是把技术框架、工作流程、核心能力全都公开,代码全在 GitHub 上。感兴趣的读者可以自行跟进。
针对 Manus,CAMEL 的发起人李国豪评价说,「我们在提出全球首个 ChatGPT Multi-agent 框架思想也将近两年了,看到 Monica 团队把 Multi-agent 技术落地成产品是非常惊喜的,Monica 团队的 Manus 系统设计其实非常巧妙,特别他们通过文件系统来实现 Context 管理和持久化、使用 Ubuntu 虚拟机的命令行来实现灵活的工具使用是非常值得学习工程思路,我们还在开源复现中!也非常期待他们承诺将要开源的 Post Training 模型!
除了 Web 和命令行的操控之外,我们非常有信心电脑、手机、机器人、车载等各种跨平台的操控会成为可能,那时候才是真正的赛博 workforce,因为 OS 端 Agent 的一个最大的优势是比较容易拿到 Verifiable 的奖励信号,未来强化学习 RL 可以训得飞起,也许会在一年内就会出现 DeepSeek R1 Zero 这样的 Aha moment 出现在 OS / Web Agent 领域!可惜我们资源有限还上不去 RL,非常期待大家一起来做开源探索!」
OpenManus 是除了 OWL 之外的另一个 Manus 开源复刻,允许用户无需邀请码创建自己的 AI 智能体。其使用方法包括设置新的 conda 环境、克隆仓库、安装依赖并在 config.toml 文件中配置 API 密钥(如 OpenAI 的 API)。用户可以通过终端输入想法,与智能体交互,智能体会使用 LLM API 处理并生成响应。

项目地址:https://github.com/mannaandpoem/OpenManus
其中,也有一些不同点。前文我们提到,Manus 是自己有个云端的电脑,而 OpenManus 则直接让 Agent 操作你的电脑。
MetaGPT 团队表示,当前项目仍在开发中,计划改进包括更好的规划、实时演示、重放功能、强化学习微调模型和全面基准测试。
最后想说的是,期待 Agent 在今年能给我们带来更多惊喜,成为切实可用的产品。
#Mistral发布世界最强文件扫描API
千页只需7块钱,实测仍有缺陷
法国大模型独角兽 Mistral AI 进军 OCR(光学字符识别)领域了。
一出手就是号称「世界上最好的 OCR 模型」!

新产品 Mistral OCR 是一种光学字符识别 API,它为文档理解树立了新标准。与其他模型不同,Mistral OCR 能够以前所未有的准确度和认知能力理解文档的每个元素(媒体、文本、表格、公式)。它以图像和 PDF 作为输入,并从有序交错的文本和图像中提取内容。
因此,Mistral OCR 称得上一种理想的模型,可以与以多模式文档(如幻灯片或复杂 PDF)作为输入的 RAG 系统结合使用。
从现在开始,Mistral OCR 功能可以在 Le Chat 上免费试用。Mistral AI 已经将它作为 le Chat 上数百万用户的默认文档理解模型,并以 1000 页 / 美元的价格发布了 API「mistral-ocr-latest」。目前,该 API 已经在开发者套件 la Plateforme 上提供,并将很快提供给 Mistral AI 的云和推理合作伙伴,同时可以有选择地本地部署。
对复杂文档实现 SOTA 理解
Mistral OCR 擅长理解复杂的文档元素,包括交错图像、数学表达式、表格和高级布局(如 LaTeX 格式)。该模型可以更深入地理解丰富的文档,尤其是包含图表、图形、公式和数字的科学论文。
比如 Alphafold 3 的 OCR 识别效果,从给定 PDF 中将文本、图像提取到 markdown 文档。
下面将 PDF 和对应的 OCR 输出结果进行了并排比较。
比如数学公式:

比如阿拉伯文字:

基准测试成绩全方位第一
Mistral OCR 在严格的基准测试中始终优于其他领先的 OCR 模型,其在文档分析的多个方面都表现出色。Mistral AI 从文本文档中提取嵌入图像和文本,不过进行比较的其他 LLM 不具备此功能。
因此,为了公平比较,Mistral AI 在包含各种发表论文的内部「仅文本」测试集以及网络 PDF 上进行了性能测试。

支持原生多语言
自成立以来,Mistral AI 一直渴望用自己的模型服务全世界,因此努力在产品中实现多语言功能。
Mistral OCR 将这一目标提升到了一个新水平,能够解析、理解和转录各大洲的数千种脚本、字体和语言。对于需要处理来自不同语言背景的文档的全球组织以及服务小众市场的超本地化企业而言,这种通用性至关重要。
在「Fuzzy Match in Generation」(生成模糊匹配)指标比较中,Mistral OCR 获得了第一。

在各种语言的比较中,Mistral OCR 同样超越了 Azure OCR 和 Google Doc AI。

同类产品中速度最快
Mistral OCR 比同类产品中的大多数都更轻量,速度也明显快于它们,并且在单个节点上每分钟可以处理 2000 多页。这一快速处理文档的能力确保即使在高吞吐量环境中也能持续学习和改进。
文档即提示、结构化输出
Mistral OCR 还引入了使用文档作为提示的功能,从而实现了更强大、更精确的指令遵循。此功能允许用户从文档中提取特定信息并将其格式化为结构化输出,例如 JSON。用户还可以将提取的输出链接到下游函数调用和构建智能体中。
自行托管
最后,对于具有严格数据隐私要求的组织,Mistral OCR 提供了自行托管选项。这可确保敏感或机密信息在组织内部的基础设施内保持安全,从而符合监管和安全标准。
实测:Mistral OCR 很好,但也有局限
面对 Mistral AI 号称的「全球最好 OCR 模型」,Pulse AI 团队进行了一番测试,结论是:确实很好,但尚未完全为企业使用做好准备。
Mistral OCR 绝对超越了一些前沿 LLM,但在真实商业文档中出现了一些限制。

图源:https://x.com/ritvikpandey21/status/1897800421357588546
对于财务文档:Mistral OCR 难以处理复杂的表格,出现了 17% 的列错位、±1.5% 的精度偏差以及丢失了表示负值的关键括号。

对于法律文档:复选框检测基本不存在,部分层次结构丢失,多行表格单元格合并或切断。

正如 Mistral AI 博客中所说,他们正在收集用户的反馈,并希望未来几周 Mistral OCR 继续变得更好。
博客地址:https://mistral.ai/fr/news/mistral-ocr
参考链接:https://www.runpulse.com/blog/beyond-the-hype-real-world-tests-of-mistrals-ocr
#谷歌创始人拉里·佩奇出山成立大模型公司,目标智能制造
回来了。
谷歌联合创始人、全球第七富豪拉里・佩奇 (Larry Page) 已经成立了一个 AI 创业公司。
据外媒 The Information 本周四报道,拉里・佩奇成立了名为 Dynatomics 的创业公司,旨在用人工智能颠覆制造业。
有两位知情人士透露,佩奇和一小群工程师正在研究如何使用大语言模型(LLM)为各种物体创建高度优化的设计,然后让工厂制造它们。佩奇等人并不是唯一在探索利用 AI 提升工业制造的团队,目前已有不少利用 AI 发现材料、模拟工业流程、进行异常探测的项目。
利用人工智能提升工艺制造流程,或许是技术应用的下一个爆点。
知情人士表示,这家低调的公司由 Chris Anderson 经营,他曾是另一家佩奇支持的公司 Kittyhawk 的首席技术官,这是一个雄心勃勃的项目,旨在制造小型电动飞机(飞行汽车),致力于彻底改变人们在城市中的出行方式。

该公司生产的飞行汽车名为 Flyer,飞行速度 32 公里 / 小时,可飞行 20 分钟。由于原型机失败和监管问题,该公司于 2022 年关闭。
说到拉里・佩奇与 AI 领域的联系,人们可能会想起 2015 年他与伊隆·马斯克的一场著名辩论,彼时马斯克和佩奇已是相识十多年的老友。但在一场派对上聊到「AI 最终会不会取代人类」的话题上时,两人的意见有了分歧。
佩奇相信人类最终会和 AI 融为一体,未来会有很多种智能争夺资源,强大的种族将成为赢家;马斯克则认为一旦 AI 兴起,人类将会陷入危机。
在这之后他们分道扬镳,马斯克参与建立了目标通用人工智能的 OpenAI,旨在把 AI 这项革命性的技术用于造福人类,并阻止谷歌对 AI 技术的垄断。
然而十年之后,马斯克建起了 Grok 团队,开始与 OpenAI 对簿公堂。而在另一边,拉里・佩奇虽然仍是谷歌(Alphabet)的董事会成员,也是最有权势的股东,但已基本不参与谷歌的日常运营。
如今拉里・佩奇开启了新的创业项目,其他老谷歌高管也在投身 AI,可见硅谷对于 AI 技术未来的持续看好。
最近一段时间,谷歌联合创始人谢尔盖・布林 (Sergey Brin) 一直在一线亲自参与谷歌大语言模型 Gemini 的研发。他本周还向谷歌员工喊话「回归办公室,每周最好工作 60 小时」。
谷歌的前 CEO 埃里克・施密特(Eric Schmidt)去年在斯坦福大学的演讲被人们疯传,其中他提到了 AI 智能体的重要性、大模型长文本能力,以及 AI 对于复杂任务处理的前景。
施密特最近提出了反对美国「人工智能曼哈顿计划」的意见,指出超级智能不能被一个国家垄断。
谢尔盖·布林、埃里克・施密特与拉里·佩奇。
全球围绕 AI 与大模型技术的竞争,势必还会更加激烈。
参考内容:
https://www.theinformation.com/articles/larry-page-has-a-new-ai-startup
https://techcrunch.com/2025/03/06/google-co-founder-larry-page-reportedly-has-a-new-ai-startup/
#DiffSensei
北大开源多模态驱动的定制化漫画生成框架DiffSensei,还有4.3万页漫画数据集
随着生成式人工智能技术(AIGC)的突破,文本到图像模型在故事可视化领域展现出巨大潜力,但在多角色场景中仍面临角色一致性差、布局控制难、动态叙事不足等挑战。
为此,北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。
- 论文地址:https://arxiv.org/pdf/2412.07589
- GitHub 仓库:https://github.com/jianzongwu/DiffSensei
- 项目主页 - https://jianzongwu.github.io/projects/diffsensei/
- 数据链接 - https://huggingface.co/datasets/jianzongwu/MangaZero
该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制,并支持对话布局的灵活编码。同时,团队发布了首个专为漫画生成设计的 MangaZero 数据集(含 4.3 万页漫画与 42.7 万标注面板),填补了该领域的数据空白。实验表明,DiffSensei 在角色一致性、文本跟随能力与图像质量上显著优于现有模型,为漫画创作、教育可视化、广告设计等场景提供了高效工具。
团队公开了训练,测试代码、预训练模型及 MangaZero 数据集,支持本地部署。开发者可通过 Hugging Face 获取资源,并利用 Gradio 界面快速体验生成效果。
,时长02:42
1.DiffSensei 效果及应用

DiffSensei 功能
DiffSensei 生成漫画的技术优势:
- 角色一致性:跨面板保持角色特征稳定,支持连续叙事,可根据文本动态调整任务状态和动作。
- 布局精准:通过掩码机制与边界框标注,实现多角色与对话框的像素级定位。
- 动态适应性:MLLM 适配器使角色可依据文本提示调整状态(如 “愤怒表情” 或 “挥手动作”),突破传统模型的静态生成限制。
2.DiffSensei 应用场景
真人长篇故事生成

DiffSensei 真人长篇故事生成效果
定制漫画生成

DiffSensei 定制漫画生成效果
更多结果

DiffSensei 生成整页漫画结果,每页漫画的故事梗概在其上方,更多结果在项目主页
4. 模型框架

DiffSensei 方法框架
DiffSensei 的技术架构以 “动态角色控制” 和 “高效布局生成” 为核心,通过以下模块实现端到端的漫画生成:
- 多模态特征融合:
- 结合 CLIP 图像编码器 与 漫画专用编码器(Magi),提取角色语义特征,避免直接复制像素细节导致的 “粘贴效应”。
- 通过重采样模块将特征压缩为低维 token,适配扩散模型的交叉注意力机制,增强生成灵活性。
- 掩码交叉注意力机制:复制扩散模型的键值矩阵,创建独立的角色注意力层,仅允许角色在指定边界框内参与注意力计算,实现布局的像素级控制。
- 引入对话布局嵌入,将对话框位置编码为可训练的嵌入向量,与噪声潜在空间融合,支持后期人工文本编辑。
- MLLM 驱动的动态适配器:以多模态大语言模型(如 LLaVA)为核心,接收面板标题与源角色特征,生成与文本兼容的 目标角色特征,动态调整表情、姿势等属性。训练中结合 语言模型损失(LM Loss) 与 扩散损失,确保生成特征既符合文本语义,又与图像生成器兼容。
- 多阶段训练优化
- 第一阶段:基于 MangaZero 数据集训练扩散模型,学习角色与布局的联合生成。
- 第二阶段:冻结图像生成器,微调 MLLM 适配器,强化文本驱动的角色动态调整能力 813,从而适应与文本提示对应的源特征。在第一阶段使用模型作为图像生成器,并冻结其权重。
5.MangaZero 数据集

MangaZero 数据集统计信息
上图展示了 MangaZero 数据集的基本信息,该数据集中包含最著名的日本黑白漫画系列。图 a 显示了所有 48 系列的封面。这些漫画系列之所以被选中,主要是因为它们的受欢迎程度、独特的艺术风格和广泛的人物阵容,为该模型提供了发展强大而灵活的 IP 保持能力。
图 b 展示了一些人物和对话标注的示例。
图 c 描绘了数据集中的面板分辨率分布。为了提高清晰度,其中包括三条参考线,分别表示 1024×1024、512×512 和 256×256 的分辨率。大多数漫画画板都集中在第二行和第三行周围,这表明与最近研究中通常强调的分辨率相比,大多数画板的分辨率相对较低。这一特性是漫画数据所固有的,该工作专门针对漫画数据。因此,可变分辨率训练对于有效处理漫画数据集至关重要。

MangaZero 数据集和同类数据集对比
MangaZero 数据集相比同类数据,规模更大,来源更新,标注更丰富,漫画以及画面分辨率更多样。与广为人知的黑白漫画数据集 Manga109 相比,MangaZero 数据集收录了更多在 2000 年之后出版的漫画,这也正是其名称的由来。此外,MangaZero 还包含一些 2000 年之前发行、但并未收录于 Manga109 的著名作品,例如《哆啦 A 梦》(1974 年)。

MangaZero 数据集标注流程
上图展示了 MangaDex 数据集的构建过程,作者通过三个步骤构建 MangaZero 数据集。
- 步骤 1 - 从互联网中下载一些现有的漫画页面。
- 步骤 2 - 使用预先训练好的模型自主为漫画面板添加相关标注。
- 步骤 3 - 利用人工来校准人物 ID 标注结果。
MangaZero 数据集应用潜力
- 多 ID 保持,灵活可控的图片生成训练。漫画数据天然拥有同一个人物多个状态的图像,对可根据文本灵活控制人物状态的定制化生成训练有很大帮助。
- 风格可控的漫画生成。MangaZero 中包含的漫画系列多样且具有代表性,可以在模型结构中增加风格定制模块,实现画风可控的漫画生成。例如生成龙珠风格的柯南。
6. 结论
DiffSensei 通过多模态技术的深度融合,重新定义了 AI 辅助创作的边界。其开源属性与行业适配性,将加速漫画生成从实验工具向产业级应用的跨越。未来,研究方向可扩展至彩色漫画与动画生成,进一步推动视觉叙事技术的普惠化。
#QwQ-32B
全球首发:QwQ-32B本地一键部署、3090单卡可跑,共享算力成关键
个人设备进入最强模型时代。
仅仅过了一天,阿里开源的新一代推理模型便能在个人设备上跑起来了!
昨天深夜,阿里重磅开源了参数量 320 亿的全新推理模型 QwQ-32B,其性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。
基准测试数据显示,QwQ-32B 在数学推理、代码生成及通用任务处理能力上实现了显著突破,充分展现了强化学习应用于预训练基础模型的巨大潜力。

QwQ-32B 与原始 DeepSeek-R1、DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 的基准测试结果比较。
可以说,QwQ-32B 的开源不仅代表着大模型技术的又一次飞跃,更预示着「最强模型」走入个人设备的时代正式到来。
然而,这只是模型一侧的改进。对于大多数人来说,高性能大模型的部署门槛一直居高不下,常面临着「存不下、跑不动、散不了热、供不起电」等诸多挑战,是阻碍个人用户体验前沿技术的最大障碍。
不过大模型时代,技术的进步永远很快。
这不,一家利用闲时 GPU 算力资源支持科学研究和 AI 推理并获得收益的平台「算了么」,为普通用户体验并一键部署阿里最新推理模型提供了便捷途径。
,时长00:54
备注:参照此一键部署 DeepSeek-32B 的视频,也可一键部署 QwQ-32B。
全球首发:3090 显卡跑 QwQ-32B 只需几步
此次,「算了么」平台首个推出了 QwQ-32B 模型在个人电脑上的一键部署方案,只需简单几步即可轻松体验比肩 DeepSeek-R1 的强大推理能力。
这意味着,普通人也能分分钟把这几百亿参数的模型跑起来,完全不用懂代码,门槛极低。

实测数据显示,在消费级 RTX 3090 显卡上,QwQ-32B 模型的推理速度可达 30-40tokens/秒。流畅高效得到保证,可以完全满足日常使用场景。
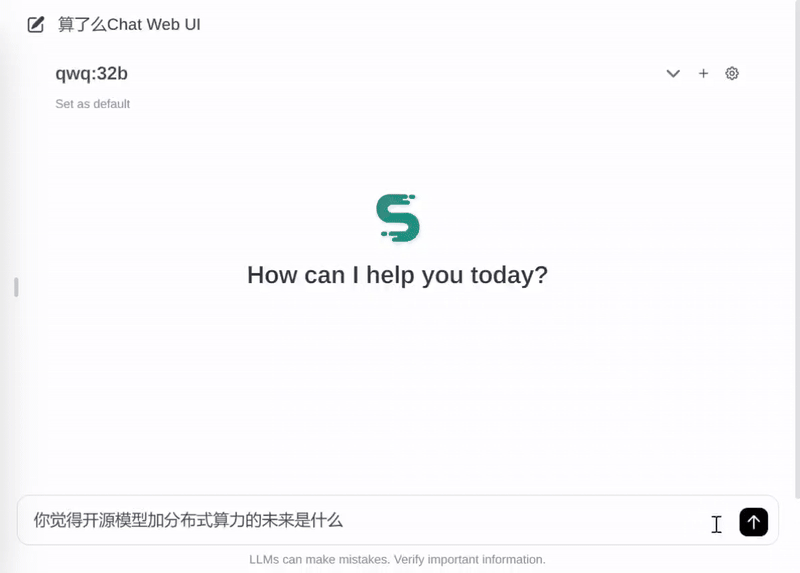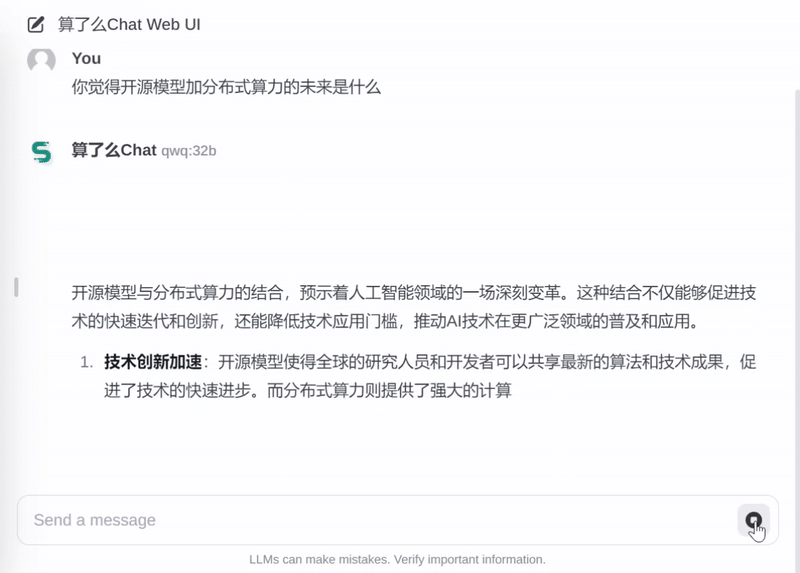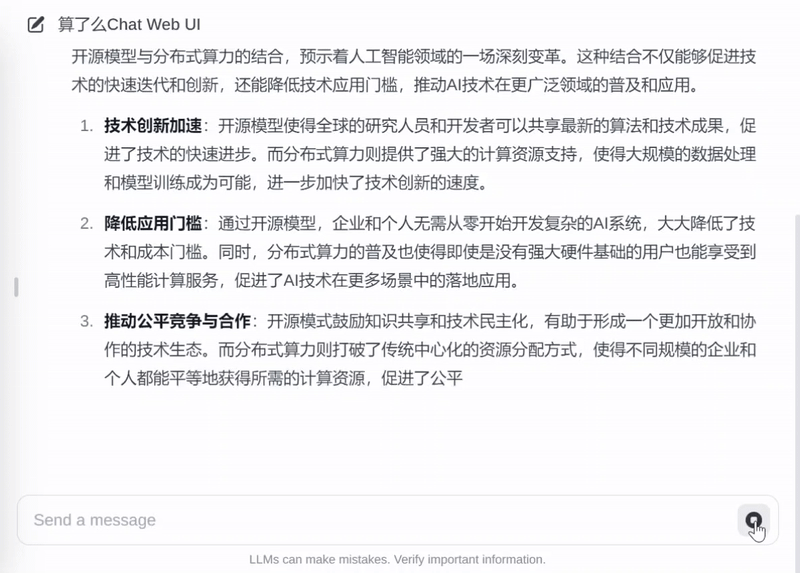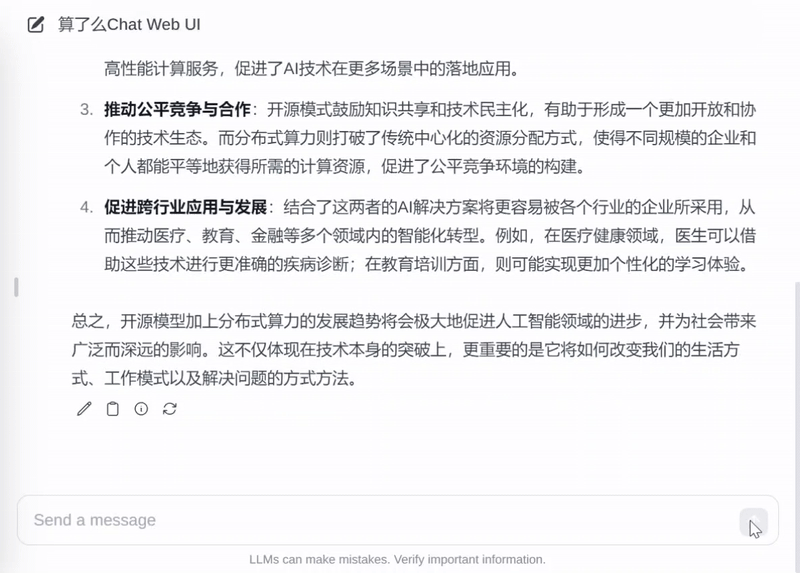
当然,没有 90 系显卡的用户也无需担忧。
目前,「算了么」平台基于共享的资源,将 QwQ-32B 以免费 API 和 Chat 的方式提供给广大用户,欢迎试用!当然,平台也呼吁身边有 90 系显卡设备的同学,可以共享出来给更多人使用。

- 免费 API 获取:qwq.aigpu.cn
- 免费试用 Chatbot:aigpu.cn
开启个人算力共享新纪元
一键部署只是开胃菜,算力普惠是「算了么」平台想要实现的更长远目标。
作为国内领先的分布式算力共享平台,「算了么」通过一种全新的方法破解算力不均衡问题——其支持用户在部署模型之后,在空闲不用时选择将本地算力共享给社区的用户使用,并可以获取一定的积分收益。

一边是排队使用 GPU 的项目,另一边是大部分时间闲时的算力,一个平台解决两边的问题。这就是「算了么」平台一直以来的做法——降低算力使用门槛,释放个人设备潜能。
具体来讲,平台利用动态闲时资源,构建安全稳定的分布式计算网络,目前已经接入超万台个人电脑、数十万台网吧的闲时算力资源,为灵活、临时的弹性算力需求提供安全、稳定、低价的算力服务。
此前已有非常成功的落地案例,2024 年 10 月,「算了么」平台利用百余台共享个人电脑设备,为清华大学 AI 课堂上的 100 多位学生提供了长达 2 个多小时的在线稳定算力服务。此举不仅验证了弹性共享算力的可行性和稳定性,也为未来普惠 AI 教育、算力生态建设提供了典型示范样本。

平台官网:suanleme.cn
团队介绍
「算了么」团队拥有深厚的学术和技术背景,核心成员来自清华大学、北京大学以及 Intel、字节跳动等知名企业。
团队在分布式资源调度领域深耕多年,曾获 2024 年中国国际大学生创新大赛亚军(金奖,创业组冠军),并已获得奇绩创坛、水木创投等知名机构的投资。

早在平台创立之初,「算了么」团队就敏锐洞察到大模型发展的两大趋势:「小型化」与「分布式」。两者均对当前大模型的实际应用落地具有重要的推动作用。
团队坚信,随着模型技术的不断演进,大模型将不再是少数巨头的专属,而是遵循密度定律不断「小型化」,在更小算力下释放更强能力。同时,分布式算力将成为支撑未来 AI 发展的关键基础设施,个人算力的价值将得到前所未有的凸显。

「算了么」平台正是基于这一前瞻性认知而生,致力于构建开源、普惠、共赢的算力生态,让每一份个人算力都能汇聚成推动 AI 发展的强大力量。
随着单卡跑最强模型的时代已经到来,「算了么」平台期待广大开发者、AI 爱好者的踊跃加入,共同开启个人算力共享新篇章!
#DeepSeek 反思潮
AGI 既被重新审视,又被持续低估
DeepSeek 反思潮
在 DeepSeek 的集体反思潮中,无论是大厂内部的“AGI 创业团队”、还是 AGI 的明星创业公司,都进行了战略调整。很显然,DeepSeek 的暴击让整个行业都进行了一次深刻的反思,值得注意的几个变化是:
首先,大模型创业公司重新将技术突破提升到一个新的高度、超越产品更新成为公司战略发展的优先级。
据近日与张予彤接触过的 VC 反馈,DeepSeek 不花一分钱投流的崛起启示了 AGI 的技术高度,也让 Moonshot 反思了过去一年类互联网打法、过度重视产品投流的策略局限性。在未来的一年,Moonshot 要将基础模型的突破作为重点,将更多资源投到技术而非研发上。
事实上,这不仅仅是月之暗面的结论,也是这波 AGI 创业潮中卡技术生态位的大模型公司的普遍转变。与此相对应的,是产品团队的资源比重下降,因为 DeepSeek 的成功已经侧面证明了:AGI 时代可能不需要产品经理,也不需要投流,只要技术实力提升后就会有用户增长。
2024 年的投流大战,以 DeepSeek 不花一分钱、DAU 最高时达 4000 万落下帷幕,而受创最重的自然是投流团队,因为钱相当于白花了。投流越多、伤害越大,如 Moonshot;投流越少,伤害越小,如 MiniMax。
据 AI 科技评论获悉,MiniMax 前产品一号位离职的原因之一,就是曾与创始人在投流上发生分歧。MiniMax 的组织架构之前是互联网打法,按照不同产品进行分组,产品团队一度达到 200 人,但 2024 年年中开始就一直在调整产品团队,接下来可能会进一步裁减产品人员。
其次,是字节与腾讯的攻守异位,以及字节大模型技术团队的架构调整。
过去一周,腾讯元宝接入 DeepSeek 后在中国区苹果免费 APP 下载排行榜上超过豆包,排名第二、仅次于 DeepSeek。在“DeepSeek+”的风潮下,相比百度、阿里、字节等有技术包袱的大厂来说,腾讯的元宝与微信等应用迅速抓住了机会,毫无负担地接入了 DeepSeek,一下子由过去两年的被动防守转为主动出击,变守为攻,扭转了局势。
业内周知,在过去的两年,腾讯在大模型、AIGC 相关技术与产品上虽然努力追赶,但始终不温不火。又由于将算力与人才等资源更多投入基础模型,文生视频等方向的研究资源被影响,团队核心骨干从腾讯流向快手、字节等团队。可以说,DeepSeek 救了腾讯大模型一把。
也因此,有业内人士认为:基础模型的研究最终只需要 DeepSeek 一家即可。随之引发的,是近日传出的大模型公司有老股东开始张罗退股的声音,认为“智谱、阶跃甚至字节、阿里等公司的大模型都没戏了”。——对于这种声音,笔者不敢苟同,认为应该持续观望。
有一个比喻能很好地形容当前中国大模型创业潮的格局:
一个富二代学霸做了一份接近满分的卷子,并把答案公布了出来。但这份答案的学习有一定的资源成本与面子成本,另一个能承担起这两种成本的富二代学渣直接拿来抄了、也考了接近满分的成绩。现在留下一群从农村通过赞助入学、平时考七八十分的学生,以及同是富二代但努力方向错了的学生,不知所措。
他们终将认识到,开放社会的竞争不一定公平,但一定残酷。打破这种结构性困境很难,或许需要“一命二运三风水四积阴德五读书”,但他们没有其他选择。
回到现实,字节的大模型团队进行调整,也是因为 AGI 的竞争格局发生了变化——DeepSeek 冲出来之前,业内几乎所有人都在夸字节的豆包,豆包也上升十分迅猛,给 kimi 造成极大的围剿;但 DeepSeek 霸屏整个春节后,字节意识到,AGI 仍是一个高度的果实,必须换一个更能打的将领。
据 AI 科技评论验证,此前字节的基础模型技术研究由朱文佳带领,春节后进行了一次大的人员调整,基础模型技术研发的一号位换成了由吴永辉,黄文灏等在 2024 年新加入的大模型骨干都向吴永辉汇报,而朱文佳则转向了模型应用一号位,吴永辉与朱文佳都向梁汝波汇报。
经 AI 科技评论梳理,2023 年字节刚组建大模型团队时,团队人员主要来自字节内部,包括搜索、抖音、西瓜、TikTok 等等多条知名业务线,在字节过往产品上有过大大小小的胜仗,朱文佳下面各个小组中一号位人选从外面招入的人才并不多。
从 2024 年年中开始,越来越多 AGI 方向的知名人才被招入字节,团队开始换血。据知情人士分析,这背后的原因是:朱文佳等人来自搜推广技术背景,而大模型是新的范式,两者不一定适合。字节、MiniMax 等公司此前低估 RL 技术路线就是一个例证。吴永辉代替朱文佳成为基础模型研究一号位,意味着字节换血的决心更彻底。
吴永辉此前在谷歌的职级仅次于 Jeff Dean,是谷歌 Gemini 的核心贡献者之一。而据几位硅谷华人的信源,吴永辉擅长模型工程。谷歌自 2017 年发布 Transformer 后一直在大模型赛道上持续创新,且谷歌研究大模型一直是从底层框架、算力到上层算法的系统性推进,从知识面上吴永辉确更适合大模型技术一号位的角色。
据知情人士透露,朱文佳此前在带领字节大模型技术研发时,在人才任用上更重用以往一起打过仗的亲信乔木等人,同时在大模型基础研究的创新 idea 采用上不够开放。这背后的逻辑不难理解:AGI 的技术有极高不确定性、用熟悉的队友能减少沟通成本。如果 AGI 是一个很低的桃子,“钱多人傻”的打法也许可以,但事实或许并非如此。
据了解,新加入字节的技术人员曾向朱文佳提过诸如 SPPO 等强化学习方向、火星优化器等高效训练方向的技术方案,“一些方案明明自己验证了 work、但被朱文佳移交给身边的人验证后被反馈不 work 而弃掉”。此前字节内部赛马文生视频,其他团队赛赢,但后续成果被朱文佳划到了 Seed 团队。
大模型是一项有门槛的创新技术,无论在大厂还是创业公司,实际上都需要创业者的心态。第一批低估 AGI 的人已经被摁倒,但并非所有人都吸取了教训。
AGI 的壁垒在哪?
“算法是没有壁垒的。”一位大模型 VC 这样评论道。与此同时,还有相似的声音:“DeepSeek 现象只是昙花一现,过 6 个月就会被追上”,以及“大模型创业公司必然会死,最后赢家只有 DeepSeek 与大厂,你看腾讯元宝”。
笔者认为,在下论断之前,首先要回答一个问题:DeepSeek 已经实现终极 AGI 了吗?答案显然是否定的,即使是 DeepSeek 官方都承认,R1 模型仍有一些致命缺陷,比如通用能力不足、语言混淆、提示词敏感以及软件工程能力不足。
如果这个问题达成了共识,那么我们就要思考下一层:
第一,DeepSeek 是不是一定能解决 AGI 的所有技术问题?
第二,DeepSeek 是不是只需一家之力就能实现终极 AGI?
第三,中国是不是只有 DeepSeek 一家有实力解决 AGI 的各个技术问题?
同样以腾讯元宝为例。虽然元宝接入 DeepSeek 后可以赢得一时的胜利,但没有人能保证 DeepSeek 永远满分。如果有一天 DeepSeek 不开卷、竞争的规则被改写,又将攻守异位。
对于上述问题,笔者均持怀疑态度,原因很简单:DeepSeek 并非聚集了中国乃至全球所有的 AGI 技术人才。即使曾经明星如云的 OpenAI,也因为2023、2024 年经历了大批核心人才出走,发展受阻。
关于 AGI,如果不将其当成只是 DeepSeek 一家的责任,而是作为整个 AI 行业的必然终局,那么就不难有一种朴素的感觉:AGI 的大航海,需要的不只是一个“DeepSeek”,也不会只有一个“DeepSeek”。AGI 是一个行业,而不是一个产品。
在 2 月的交流中,笔者总结,造成 AGI 从业者这种“既重视又低估”的矛盾心理的一个重要原因,或许是互联网思维的惯性。
经历过互联网大战的从业者向 AI 科技评论举例,“互联网产品就是竞争到最后往往就是只有一家胜出,比如出行大战、3Q 大战等等。”但笔者认为,这种类比不太恰当,因为互联网产品的技术如搜推广从谷歌开始、再到国内时,大体的技术天花板已经确定,而 DeepSeek 证明了 AGI 的天花板比 OpenAI 所取得的成绩还高。
与 AGI 或大模型能在同一个层面类比的技术分支,或许用自动驾驶的 L4、英伟达芯片等高难度的技术来类比更合适。虽然 L4 至今没有实现,但自动驾驶技术从 L2 到 L4 的过程中曾衍生了不同维度的产品商业化(如扫地机器人),同样,AGI 也是一个逐步取得胜利、逐步催生商业技术产品的过程。
有些团队本就不具备竞争 AGI 的技术实力,但这并不能推断出“DeepSeek 是唯一能竞争 AGI 的创业团队”或“中国只需要一家 AGI 公司”的结论。哪怕是海外的各家基础模型,也在能力上各有分工,如 GPT 更擅长听指令、Claude 更擅长代码。
再回顾更大的行业规律:如果说搜广推技术由谷歌开启、字节抖音推至巅峰,那么大模型技术由 OpenAI 开启,由将由谁推至巅峰?互联网时代经历了 20 年才得出答案、中间也经历了许多故事,那么 AGI 时代也不可能只在 2 年内验证最初的赢家与最后的赢家。
那么,AGI 的壁垒在哪?
笔者认为,AGI 的壁垒实际是:算法的优势、技术的创新虽然无法构成坚不可摧的壁垒,但可以赢得时间差。
以月之暗面为例。事实上,Moonshot 与 DeepSeek 都是在 2023 年的上半年成立、前后相差只有一个月。
在 2021 年智源的“悟道”大模型项目中,杨植麟也是悟道 2.0 大模型的核心开发者之一,从底层 Transformer 到上层大模型的算法训练都有完整、系统的研究背书。相比之下,DeepSeek 创始团队、包括梁文锋虽是计算机专业背景,但在 NLP、Transformer 与预训练等大模型的关键技术上与 Moonshot 团队必然存在技术学习的时间差。
如果以 Moonshot 在成立时就具备训练千亿大模型的能力开始算起,到 DeepSeek 在 2024 年 5 月发布 V2,那么这个时间差粗略计算大约是 1 年;如果严格考虑 V2 训练成本大幅降低的研发时间,这个时间差也至少是 6 个月以上。
但由于 Moonshot 在过去两年更重视产品增长、而非基础模型的底层技术创新,Moonshot 与 DeepSeek 的基础模型时间差也从 2023 年“DeepSeek 至少比 Moonshot 落后半年”变成了 2025 年“Moonshot 至少比 DeepSeek 落后 XXX 年”。在互联网思维的过度指导下,前后相减,Moonshot 至少失去了一年的优势,主动变被动。
据知情人士透露,DeepSeek 内部计划今年 3 月发布 V3.5,6 月之前发布 V4。换言之,假设其他团队的基础模型能在 6 月赶上 V3 与 R1,作为先行者,DeepSeek 已经利用时间差赢得了领先的技术研发期,以及这半年内的生态护城河。模型的效果容易提升,但生态不容易割据。
是坐享其成,还是参与竞争,亦或看清局势、早早转向自身的优势所在,不容易判断。尽管 DeepSeek 当前风头正盛,但 AGI 仍然是一个挂在高处的果子,需要持续的底层技术创新。
在跋涉的过程中,一定会有人退出,无论是 VC 也好、创业者也好、技术人员也好,但无论如何,这条路上不会只有 DeepSeek,也希望不会只有 DeepSeek。
#为什么Manus火了
上周末,脖子突然抽筋坏了,比落枕难受100倍。所以停更了几天。做了CT,做了核磁,开了膏药,也开了口服药,这两天能动弹了。
一夜之间,被“中国团队做的通用 AI Agent 产品”——Manus刷屏了。
不少声音都在说“AI Agent 的 GPT 时刻”、“中国 AI 再次震惊世界”、“又一个 DeepSeek”,总之各种溢美之词扑面而来,帽子又高又帅!
Agent——
现在这个时刻,已经是一个说烂的词儿了,从 22 年底 ChatGPT 发布后的几个月开始,尤其是 AutoGPT(Agent 概念开始“火”起来的关键节点)火了之后,到现在一直没停过讨论。
那为啥这次 Manus 就火了呢?
这篇文章仅从我个人理解角度上,浅谈一下。
整体我觉得可以概括成三点:
1、是对 OpenAI 的贴身超越
2、是一次技术突破的集中爆发
3、与用户心理的精准共振
先看一个官方的 demo 视频——
任务是:Research the Rockefeller family relationships(研究洛克菲勒家族关系)
,时长00:28
一段操作猛如虎,中间各种分析、整理、执行,最后生成了家族图谱。
首先看官方发布的榜单——
在衡量通用 AI 助手能力的基准 GAIA 评测中,Manus 的评分遥遥领先,超越了 OpenAI 的 DeepResearch,稳坐第一。
GAIA 基准由 Meta AI (FAIR)、Hugging Face 团队在 2023 年联合推出的,旨在评估 AI 助手解决实际问题的能力。研究团队提出了一系列问题,这些问题“对于人类来说在概念上很简单,但对于最先进的人工智能来说却具有挑战性”,共包含 466 个需要多步骤推理的复杂问题,分为 Lv.1、Lv.2、Lv.3 三个难度级别。人类在 GAIA 测试中的平均正确率高达92%,GPT-4 在 GAIA 测试中的综合正确率仅为15%,且在最高难度级别(Lv.3)的问题上表现更差,部分得分甚至为零。直到有了推理模型 +Deep Research 后,才拿下当时的 SOTA。
看榜单数据,Manus 从三个 level 上均超越了 Deep Research。
再来看几个 demo:
任务 1:充当 HR 的角色,筛选存放在压缩包里面装的 10 份简历
,时长00:59
Manus 被塞过来文件后,就开始干活:
(1)解压文件,浏览简历,提取关键信息
(2)分析所有 15 份简历,给出专业的排名建议
(3)提供详细的候选人资料和评估依据
(4)根据用户的偏好生成电子表格形式的报告
任务2:用户想要在纽约购买房产,要求安全的环境,低犯罪率,要有不错的学区,而且还不能超预算。
,时长00:39
看 Manus 的执行过程,它分成以下几步:
(1)分解为 todo:将复杂任务分解为待办事项列表,包括研究安全社区、识别优质学校、计算预算、搜索房产等
(2)搜索:网络搜索有关纽约最安全社区的文章,收集相关信息
(3)写代码:编写 Python 程序根据用户收入计算可负担的房产预算
(4)筛选:筛选房地产网站上相关的房价信息,根据预算范围筛选房产列表
(5)整合:整理所有收集的信息,撰写详细报告。
任务3:分析过去三年中英伟达、迈威尔科技和台积电股票价格之间的相关性
,时长00:49
拿到任务就开干:
(1)通过 API 访问雅虎金融等信息网站,来获取股票历史数据
(2)交叉验证数据准确程度(这点很聪明严谨,让我很放心!)
(3)写 python 代码进行数据分析、可视化
(4)结合金融分析的工具生成综合分析报告,向用户反馈其中的因果关系
整个执行过程的输出很详细,有很多像人的操作,比如上下滑动、点击元素。
完全像一个人在完成任务的过程一样。
仔细看所有的任务,不外乎有几个核心的流程:上网搜索、编辑器、执行 Linux 终端命令、写代码。
更多感觉,它像一种“DeepResearch + Computer Use + Artifacts”多种现有技术的结合体。
这就是 Manus 区别于其他的关键。背后是靠一套云端的虚拟机环境支持。
比如 DeepResearch——
能联网检索、快速获取、整理和分析大量数据。
Claude 的 Computer Use——
更像是一个背后的操盘手,负责任务调度和执行、高效地管理和分配计算资源
Artifacts——
借鉴 Claude 策略,给 Manus 提供与现实世界交互的能力,最后的呈现结果直接在网页上立竿见影地看到。
综合起来,Manus 就变成了一个高效协同的整体,可以处理复杂的任务流程。
因为官方这次并没有放出来技术报告,一切猜测也仅是基于以往技术形态,所以我更倾向于把它看作是一个系统创新。
除了简历筛选、选房、炒股这三个案例之外, Manus 官网还展示了十多个 manus 能够胜任的场景,比如整理行程、个性化推荐旅游路线。
回到一个问题上来,Manus 为什么就突然火了呢?
回答之前,我们先回顾一下,OpenAI 的 规划的 AGI 路线图——
Level1: 常规的 chatbot 形态;
Level2: 对应目前的强推理模型;
Level3: 具备 agent 能力,基于指令,可以 take action 的 AI 系统
Manus 这个产品,就是来到了这个阶段。
就像官方对 Manus 的定义——
“Manus is a general AI agent that bridges minds and actions: it doesn't just think, it delivers results”
翻译过来就是——
Manus 是一款通用型 AI agent,它连接思想与行动:它不仅思考,更能交付成果。
再看“Manus”这个名字——
它来源是拉丁语单词 “manus”,意思是 “手”,象征着 行动、执行、操作。
和 Agent 的特点非常吻合——
就是能够自主地执行任务,将想法转化为行动,就像一只能够执行各种操作的 “手”。
你就理解成是,Manus 是一个能动手、交付结果的 AI 助理。
manus 网址:https://manus.im
但是,目前 Manus 还只能是少部分内测用户可以用,大部分用户都在求邀请码。网上大部分 case 也都是官方跑好放出来的。
但是实际效果怎么样,不知道。用户量上来后,使用体验也不知道。所以蹲一个后续表现吧。
单看 demo 视频,还是挺强大的。
但至少,此时此刻,Manus 让我们看到了 AI Agent 的实际应用方式以及未来的样子。
个人觉得,从大模型发展阶段和用户体验看,Manus 确实击中了心理共振点。
大模型作为单一工具 chatbot 已经很成熟了,像 deepseek R1 配合联网功能,回答精准,但是无法执行,没办法自动执行多步骤的任务。
比如让它能写代码给你分析数据,能给你思路,但是不能打开 Excel 操作啊。
用户心理上已经从“惊艳”转向了“期待更多”,我把任务丢给你,直接给我完成的结果多省事儿啊。这样就解放双手,顺便也解放了大脑。
职场打工人干的最多的事儿就是:从一坨 XXX,整理 + 处理 + 分析,到 word、Excel 这种结构化数据。
Manus 就是 match 了当下用户的这个心理共振点。
更惊喜的是,这次又是国产力量!来自于成立于 2023 年的 AI 创业公司。
宣发视频里的就是 Co-founder 季逸超,是一位 90 后连续创业者,早期开发过猛犸浏览器一度出圈,还获得过红杉资本和真格基金联合投资,成立 Peak Labs 实验室,徐小平曾公开表示“投的是季逸超这个人,支持他做最野的事”。
资料太有限了,只能用 deepseek 帮我生成了一些资料(AI 生成,不一定 100% 准确)
上面季逸超是联创,创始人是肖弘,毕业于华中科技大学,连续创业者,夜莺科技创始人,曾推出“壹伴助手”“微伴助手”等工具,近几年转型做的和 AI 相关的产品则是 Monica,定位是轻量级 AI 助手,Manus 是最新发布的 AI 产品,两者定位不同,为解决复杂任务执行,技术理念强调“Less structure, more intelligence”,通过多代理架构实现自主规划与执行。
这次 Manus 的发布,堪称是——
凤衔金榜出门来,平地一声雷!
开心的是,这是继 DeepSeek 之后,又一个中国 AI 的崛起。
从此不是追赶者的叙事,而是开启 Agent 新纪元的火种!
#从 LLM 到 Agent
Manus 们莫不是「推理模型 + RPA」 ?
近期,由蝴蝶效应公司推出的一款通用 AI Agent 产品「Manus」在 AI 圈内引发了极多的关注。
去年 10 月,在微软、谷歌、Anthropic 等巨头大厂集体发布 AI Agent 方向功能的热潮之时,发布了一篇深度解读《从文本到屏幕:「Project Jarvis」们能实现 AGI 吗?》,对用作 Browser Use、Computer Use 的 AI Agent 等进行了深入探讨。RPA Agent 正在成为各家大厂巨头实际业务落地的方向,尽管各有差异,但均是为其已有或重点业务方向所服务。
目录
01. 「Manus」 爆火,与以往的 AI Agent 产品有何不同?
「Manus」 为何突然爆火?热度之下,实际能力如何?与以往的 AI Agent 产品有何不同?
02. 用 AI 操控计算机,RPA Agent 成为更实际的落地方向
为什么说 AI Agent 实际上就是更先进的 RPA?AI Agent 和 RPA 有何不同?
03. 微软、谷歌等 AI 头部公司为何都选择自主 AI 操控计算机成为下一步方向?
微软、谷歌、Anthropic 在 AI Agent 方面的动作有何异同?
04. 实现自主操控计算机的 AI Agent 需要哪些方面的能力?
AI Agent自主操控计算机需要具备哪些能力?.....
01 「Manus」 爆火,与以往的 AI Agent 产品有何不同?
1、近期,由蝴蝶效应公司推出的一款通用 AI Agent 产品「Manus」在 AI 圈内引发了极多的关注,被称为是「全球首款真正自主的 AI Agent」,甚至出现了邀请码「一码难求」的情况。
2、在「Manus」公布的官方 Demo 演示中,展示了其可以进行市场调研、繁琐文件批量处理、旅行规划以及专业数据分析等任务的能力。与以往的 Browse Use、Computer Use 的 AI Agent 最大的不同是,「Manus」给自己配备了一个独立的虚拟云端浏览器,而不是直接操控用户的电脑。在与用户对话的屏幕右侧,「Manus」会将其执行任务的过程呈现出来。
3、在其官方组织的闭门会上,同样也着重提到了这一点,即坚持「Less structure,more intelligence」的理念,减少对 AI 的结构化限制,依赖模型自主进化能力,而非人工预设流程。通过给 Agent 配备「电脑」的形式,让其获取访问浏览器和工具的能力,而不是 AI 频繁打断用户。
4、但「Manus」的实际能力如何,是否真如其官网 Demo 所展示的「丝滑般体验」?等多家科技媒体以及个人用户进行了实测,主要测试围绕在针对「Manus」的专业内容分析、代码开发与工程问题解决、复杂任务拆解与执行等方面的能力。综合各家实测情况来看,「Manus」的效果一般,并未超出已有的 AI Agent 产品的预期,如会出现在调用其他平台的 API 时会发生错误、处理复杂任务时易触发服务器宕机等情况。
5、实际上,做「Manus」的技术难度并不大,可以简单理解为「大模型主干+多个小模型组件」的架构。「Manus」 采用了「Multiple Agent」(多代理)的架构,运行在独立的虚拟机中。架构包含规划代理、执行代理和验证代理,通过分工协作机制来提升复杂任务的处理效率。
6、更通俗一点来讲,可以理解为「手脑协同」的模式,「Manus」以基础大模型为核心,作为「大脑」来提供通用的智能和推理能力。在这个基础上,通过多个小模型组件(如规划代理、执行代理和验证代理)分工协作,分别负责任务规划、具体执行和结果验证。这些小模型组件就像是「手脚」,能够灵活地完成各种具体任务,比如编写代码、浏览网页、分析数据等。
7、也因为技术难度相对并不大,后续开源社区中出现了一些针对 Manus 的开源项目,比如 CAMEL AI 团队开源的 OWL 和 MetaGPT 团队开源的 OpenManus。
8、「AI Agent」更像是实现了新型自动化的 RPA(机器人流程自动化)。RPA 主要使用结构化数据和规则执行预定义的重复任务,而 Agent 可以根据复杂的数据和上下文做出决策并适应情况,本质上即是在用户交互界面级别模仿人类行为。[2-13]
9、Anthropic 首席科学官兼约翰霍普金斯大学副教授贾里德·卡普兰 (Jared Kaplan)曾表示:「我认为我们将进入一个新时代,模型可以使用人类使用的所有工具来完成任务。」,而让 AI Agent 使用人类所有工具来完成任务对于目前来说,仍是一种畅想。可以说,「Manus」们正在做的都是同一件事情。
10、同样,在去年 10 月,在微软、谷歌、Anthropic 等巨头大厂集体发布 AI Agent 方向功能的热潮之时,就发布了一篇名为《从文本到屏幕:「Project Jarvis」们能实现 AGI 吗?》的深度解读,对用作 Browser Use、Computer Use 的 AI Agent 产品/功能进行了深入探讨,后续小节内容节选自该篇解读。
02 用 AI 操控计算机,RPA Agent 成为更实际的落地方向
推进自主 AI Agent 的发展是今年人工智能领域公司最重要的技术趋势之一。Gartner 预测,到 2028 年,至少 15% 的日常工作决策将通过 AI Agent 完成。微软、谷歌、Anthropic 等公司陆续推出了 AI Agent 及相关功能,使用 AI Agent 帮助用户自主操控计算机、手机等智能设备。[2-1] ......


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









