







我自己的原文哦~ https://blog.51cto.com/whaosoft/11603901
#CSWin-UNet
将自注意力机制集成到UNet中!CSWin-UNet:U型分割方法,显著提高计算效率和感受野交互!本文提出了CSWin-UNet,这是一种新颖的U型分割方法,它将CSWin自注意力机制集成到UNet中,以实现水平和垂直条纹的自注意力。这种方法显著提高了计算效率和感受野交互。
深度学习,尤其是卷积神经网络(CNNs)和Transformer架构,在医学图像分割领域受到了广泛关注,并取得了令人瞩目的成果。然而,CNN固有的归纳偏置限制了它们在更复杂、更多变的分割场景中的有效性。
相反,尽管基于Transformer的方法擅长捕捉全局和长距离的语义细节,但它们面临着计算成本高的挑战。
在本研究中,作者提出了CSWin-UNet,这是一种新颖的U型分割方法,它将CSWin自注意力机制集成到UNet中,以实现水平和垂直条纹的自注意力。这种方法显著提高了计算效率和感受野交互。
此外,作者创新性的解码器采用了一种内容感知重组算子,该算子根据预测的核策略性地重组特征,以精确恢复图像分辨率。作者在包括突触多器官CT、心脏MRI和皮肤病变在内的多样化数据集上的广泛实证评估表明,CSWin-UNet在保持低模型复杂性的同时,提供了高分割精度。
I Introduction
医学图像分割是医学图像计算和计算机辅助干预领域的一个基本研究课题,主要通过处理图像以获取有益信息,例如病变器官或组织的形状、大小和结构,从而提供更准确和详细的诊断和治疗建议[1, 2]。
基于深度学习的医学图像分割方法能够直接在像素 Level 对整张图像进行分类,并已在多个医学领域得到广泛应用,包括肺部计算机断层扫描(CT)图像分割、脑部磁共振成像(MRI)分割以及心脏超声图像分割等。这些方法不仅提高了分割的准确性,还进一步推动了医学成像领域的发展。卷积神经网络(CNN)是计算机视觉领域中应用最广泛的深度学习技术之一。全卷积网络(FCN)[5],作为CNN的一种扩展,促进了医学图像分割领域的发展。现有研究提出了扩展卷积和上下文学习方法,以解决传统卷积操作感受野有限的问题。此外,UNet以其创新的U形编码器-解码器设计和跳跃连接,将编码器和解码器的特征图合并,保留了浅层的关键空间细节。这种架构已成为图像分割领域的标准。UNet的增强衍生版本,如UNet++、AttentionUNet 和 ResUNet,进一步细化了分割能力,并在多种成像模态上提供了改进的性能。
尽管基于卷积神经网络(CNN)的方法在医学图像分割中取得了成功,但它们在捕获全局和长距离语义信息方面的能力有限,并且存在固有的归纳偏置问题。受到 Transformer 架构在自然语言处理(NLP)领域[16]的变革性影响,研究行人开始将这项技术应用于计算机视觉任务,旨在缓解CNN的一些局限性。Transformer 架构的核心是自注意力机制,它并行处理输入序列中所有位置嵌入的信息,而不是顺序处理。这种机制使得 Transformer 能够熟练地管理长距离信息依赖关系,并适应不同的输入序列长度。一种针对图像处理的特定改编——视觉 Transformer (Vision Transformer)[20],通过将输入图像分割成一系列固定 Patch ,每个 Patch 转换成一个向量,然后由 Transformer 编码器处理,体现了这一点。通过编码阶段,自注意力建立 Patch 间的关系,捕捉全面的上下文信息。这些编码后的特征随后被用于目标检测和图像分割等任务,利用解码器或分类器。视觉 Transformer 的引入不仅为图像处理注入了新视角,而且取得了与传统CNN相媲美或超越的结果[21, 22, 23, 24]。尽管 Transformer 架构在处理全局和长距离语义信息方面表现出色,但由于其自注意力机制的广泛性,其计算效率往往受到影响。针对这种低效问题,Swin Transformer[25]创新性地采用了窗口自注意力机制,将注意力限制在图像中的离散窗口内,极大地降低了计算复杂性。然而,这种方法在一定程度上限制了感受野之间的交互。为了克服这一点,CSWin Transformer[26]提出了交叉形状窗口(CSWin)自注意力,它可以水平垂直并行地计算自注意力,以更低的计算成本取得更好的结果。此外,CSWin Transformer还引入了局部增强位置编码(LePE),在每个 Transformer 块上施加位置信息。与之前的位置编码方法[27, 28]不同,LePE直接操纵注意力权重的结果,而不是添加到注意力计算的输入中。LePE使得CSWin Transformer在目标检测和图像分割方面更为有效。随着 Transformer 的发展,许多研究将CNN与 Transformer 块结合起来。TransUNet[13]和LeViT-UNet[29]将UNet与 Transformer 结合,在腹部多器官和心脏分割数据集上取得了竞争性结果。此外,一些研究行人还开发了使用纯 Transformer 的分割模型。Swin-UNet[30]采用Swin Transformer块构建类似UNet架构的编码器和解码器,与TransUNet[31]相比,性能有所提升。然而,基于Swin Transformer的这种分割方法在感受野交互方面仍有限制,且计算成本也相对较高。
医学图像通常具有高分辨率,并包含许多相互关联的精细结构。作者主要关注的问题是如何在消耗较少计算资源的情况下更好地处理医学图像中的长距离依赖关系。此外,与语义分割相比,医学图像中准确的边界分割对于诊断和治疗至关重要。因此,作者研究的另一个重点是,在分割过程中如何保留更多详细信息并提供更明确的边界。受到创新的CSWin Transformer [26] 的启发,作者提出了一种新型的基于Transformer的医疗图像分割方法,名为CSWin-UNet。该方法旨在降低计算成本的同时提高分割准确性。
与TransUNet [13] 这种CNN-Transformer混合架构不同,CSWin-UNet类似于Swin-UNet [30],是一种纯Transformer基础的U形架构。CSWin-UNet与Swin-UNet的关键区别在于,前者在编码器和解码器中配备了CSWin Transformer块,并根据不同尺度设计了不同数量的块。此外,作者在解码器中引入了CARAFE(内容感知特征重组)层 [31] 用于上采样。
最初,输入的医学图像被转换为卷积标记嵌入,然后由编码器处理以提取上下文特征。这些特征随后由CARAFE层上采样,该层能够精确地重新组装特征。此外,作者还使用了跳跃连接,以持续融合高级语义信息与低级空间细节。这个过程最终将特征嵌入转化为与原始输入尺寸相匹配的分割 Mask 。
通过十字形窗口自注意力机制,作者的方法可以在降低计算复杂性的同时,保持对医学图像的高效特征提取能力。此外,结合经典的UNet架构,它能够有效地在编码器和解码器中整合不同尺度的特征,从而提高分割准确性。最后,引入CARAFE层进行上采样可以更有效地保留分割目标的边缘和详细特征。
对CSWin-UNet方法的综合实验评估表明,与现有方法相比,它在分割准确性和稳健泛化能力方面具有优势。此外,它在降低医学图像分割任务的计算复杂性方面也显示出显著的优势。
本研究的主要贡献如下:
- 作者开发了一种新型的U形编码器-解码器网络架构CSWin-UNet,专门针对医疗图像分割采用了CSWin Transformer块。
- 引入了CSWin自注意力机制来实现水平和垂直条纹自注意力学习。这一增强显著扩大了每个标记的关注区域,促进了更全面的分析和上下文整合。
- 在解码器中,采用了CARAFE层替代传统的转置卷积或插值策略进行上采样。这种选择使得能够更精确地生成像素级分割 Mask 。
- 综合实验结果验证了CSWin-UNet不仅轻量级,而且在计算效率和分割准确性方面都超过了现有方法。
本文的结构安排如下:第二部分回顾了医疗图像分割领域的近期工作和进展,为本研究引入的创新技术提供了背景。第三部分详细描述了新提出的CSWin-UNet的方法论,突出了其架构及其组件的创新之处。第四部分展示了实验结果,证明了CSWin-UNet与现有方法相比的有效性和效率。第五部分总结了全文。
II Related works
Self-attention mechanisms in image segmentation_
在图像分割领域中,对自注意力机制的应用已经得到了广泛的研究。中的研究显示,为适合的场景设计不同的自注意力机制可以显著提高分割性能。在医学图像分割任务中,常涉及到微妙但关键的结构,自注意力机制能够更好地捕捉这些复杂结构之间的关系,使得设计出有效且适当的自注意力机制尤为重要。然而,许多现有的视觉Transformer仍然使用计算复杂度高的全局注意力机制,如图1(a)所示。为了解决这个问题,Swin Transformer [25]采用了移位版的局部自注意力机制,如图1(b)所示,通过滑动窗口机制实现了不同窗口之间的交互。此外,轴向自注意力[35]和交错注意力[36]分别沿水平和垂直方向计算条带内的注意力,如图1(c)和(d)所示。然而,轴向自注意力受限于序列机制和窗口大小,而交错注意力在特定应用中由于窗口重叠而表现不佳。CSWin Transformer [26]引入了十字形窗口(CSWin)自注意力机制,它能并行地计算水平和垂直条带区域的自我注意力。与之前的注意力机制相比,这种注意力机制在处理图像处理任务时更为通用且有效。

CNN-based medical image segmentation_
在医学图像分割领域,卷积神经网络(CNNs)被广泛采用,一些关键架构推动了该领域的发展。其中,全卷积网络(FCN)[5]以其端到端的架构脱颖而出,直接对像素进行分类,将全连接层转换为卷积层以适应任意大小的图像。UNet[9]模型,其特点是具有对称的U形编码器-解码器架构,在医学图像的精确分割方面表现出色。在FCN和UNet的基础上,已经提出了许多改进方法。例如,SegNet[37]结合了FCN和UNet的思想,使用最大池化操作符来提高分割 Mask 的准确性,并且已有效地应用于各种医学分割任务[38, 39]。UNet++[10]通过整合密集嵌套的跳跃连接扩展了原始UNet的设计,最小化了编码器和解码器之间的信息丢失,从而提高了分割性能。AttentionUNet[11]通过在UNet架构中增加注意力机制,提高了准确性和鲁棒性。最后,nnU-Net[40]提出了一种自适应的网络架构选择方法,能够根据特定任务需求和数据集特性自动优化模型配置,从而在各种分割挑战中增强了适应性。此外,MRNet[41]提出了一种多评分者一致模型来校准分割结果,而Pan等人[42]设计了一种混合监督学习策略来解决医学图像标签稀缺的问题。
Transformer-based medical image segmentation
鉴于医学影像的高分辨率和复杂性,它们包含了大量的像素和复杂的局部特征,传统的基于CNN的医学图像分割方法虽然在捕捉详细图像信息方面有效,但在获取全局和长距离语义上下文方面往往力不从心。相比之下,凭借其全局上下文建模能力,Transformer在有效编码更大接受域并学习远距离像素间关系方面发挥关键作用,从而提升分割性能。这一优势促使研究行人将Transformer融入到医学图像分割框架中。例如,TransUNet [13] 使用Transformer作为编码器来从医学图像中提取上下文表示,并结合基于UNet的解码器进行精确的像素级分割。这种组合展示了Transformer捕捉全局上下文信息的增强能力,从而提高了分割的准确性。同样,TransFuse [43] 在单一框架内整合了CNN和Transformer分支,并使用专门模块合并两条路径的输出以产生最终的分割 Mask 。此外,UNetR [44] 利用Transformer编码输入的3D图像,配合CNN解码器完成分割过程,而MT-UNet [45] 引入了一种混合Transformer架构,学习样本内和样本间的关系。HiFormer [46] 则提出了另一种混合模型,将两个CNN与Swin Transformer模块和双 Level 融合模块结合,以整合并传递多尺度特征信息到解码器。在纯Transformer方法中,SwinUNet [30] 使用Swin Transformer [25] 作为编码器来捕捉全局上下文嵌入,然后由UNet解码器逐步上采样,利用跳跃连接增强细节保留。此外,DFQ [47] 在Vision Transformer(ViT)框架内引入了解耦的特征 Query ,使分割模型能更广泛地适应不同的任务。
受到多头自注意力机制,尤其是CSWin Transformer [26] 的启发,作者开发了CSWin-UNet,这是一种基于CSWin自注意力的医学图像分割方法。该模型在节约计算资源的同时提升了分割的准确性,代表着将Transformer应用于医学图像分割领域的一个重大进步。
III Methodology
CSWin-UNet的整体架构如图2所示, 它由编码器、解码器和跳跃连接组成, 基本单元是 CSWin Transformer块。对于输入尺寸为 的医学图像, 与CvT[34]类似, 作者使用卷积标记嵌入(使用 的核和步长为 4 )来获得 的 Patch 标记, 其通道数为 。编码器和解码器均由四个阶段组成。与UNet[5]一样, 跳跃连接被用于在编码器和解码器的每个阶段合并特征, 以更好地保留上下文信息。在编码器中, 使用卷积层 的核和步长为 2) 进行下采样, 将分辨率降低到输入大小的一半, 同时将通道数加倍。解码器中的上采样通过CARAFE层完成,将分辨率增加到输入大小的两倍,同时将通道数减半。最后,执行 CARAFE上采样操作将分辨率恢复到输入分辨率 , 并使用线性层将特征图转换为分割 Mask 。
CSWin Transformer块

传统的Transformer架构凭借其自注意力机制,在处理所有像素位置以建立全局语义依赖方面表现出色,然而这在高分辨率医学成像中会导致计算成本高昂。Swin Transformer [25]通过移位窗口注意力机制减轻了这些成本,该方法将图像划分为不同的、不重叠的窗口,从而实现局部的自注意力。这种适应有助于管理图像的高分辨率,同时控制计算复杂度。然而,这种方法的有效性取决于窗口大小;较小的窗口可能会遗漏一些全局信息,而较大的窗口可能会不必要地提高计算需求和存储要求。与移位窗口注意力机制相比,CSWin自注意力将注意力组织成水平和垂直的条纹,增强了并行计算能力。这种结构不仅节约计算资源,还拓宽了感受野内的交互作用。如图3所示,基于这种创新的自注意力设计构建的CSWin Transformer块包括一个CSWin自注意力模块、一个LayerNorm(LN)层、一个多层感知机(MLP)以及跳跃连接。这种配置在局部和全局信息处理之间达到了最优平衡,显著提高了复杂医学图像分割任务的效率和有效性。
在多头自注意力机制中, 输入特征 首先经过一次变换, 在 个头之间进行线性映射, 通常选择为偶数。与传统的自注意力和基于移位窗口的多头自注意力不同, CSWin自注意力独特地促进了在划分的水平或垂直条纹内进行局部自注意力学习, 如图4所示。这种配置允许每个头在其指定的条纹内水平或垂直地计算自注意力。这些操作并行进行, 有效地拓宽了注意力计算区域的范围, 同时减少了整体计算复杂度。

图4:CSWin自注意力机制的说明。首先, 将多个头 分为两组 和 , 分别在水平和垂直条纹上并行执行自注意力, 并连接输出。接下来, 可以调整条纹的宽度 以达到最佳性能。通常, 对于更高分辨率选择较小的 , 对于更低分辨率选择较大的 。
在CSWin Transformer的水平条纹自注意力配置中, 输入特征 被系统地划分为 个不重叠的水平条纹, 表示为 , 其中每个条纹的宽度为 由比例 确定。参数 是可调整的, 对于平衡计算复杂度与模型的学习能力至关重要。具体来说, 较大的 增强了模型在每个条纹内探索长距离像素相关性的能力, 有可能捕捉到更广泛的环境信息。考虑在一个特定 Head 的计算, 记为第 个 Head 。在这种情况下, Query (Q)、键(K)和值 (V) 的维度各为 , 其中 是通道数, 是总 Head 数。第 个水平条纹内第 个 Head 的自注意力输出 计算如下:

其中 是第 个水平条纹的特征图; , 表示第 个 Head 的 、 和 V 的权重矩阵。这个操作分别对每个条纹并行执行,以允许在特定的水平条纹内进行自注意力。 个水平条纹的自注意力被连接起来, 构建第 个 Head 的水平自注意力H-Attention o 。
类似于水平条纹自注意力机制, 输入特征 被均匀划分为 个不重叠的垂直条纹 以进行垂直自注意力处理。其中条纹的高度也是 , 且 。以第 个注意力头为例, 其中 、 和 V 的维度为 。第 个注意力头在第 个垂直条纹中的自注意力输出 可以按以下方式计算:

其中, 是第 个垂直条纹的特征图。 个垂直条纹的自注意力被连接起来, 构建第 个注意力头的垂直自注意力 -Attention :

作者将 个注意力头分为两组, 每组包含 个头。这些组中的每个头都生成其自注意力输出。第一组负责学习水平条纹自注意力, 而第二组学习垂直条纹自注意力。在分别计算自注意力之后, 这两个组的输出被连接起来。这种连接沿着通道维度进行:

式中 表示第 个注意力头; 是一个权重矩阵, 用于将多注意力头自注意力机制的拼接输出线性转换以产生最终的注意力输出, 这种线性转换有助于学习不同头之间的关系并融合注意力信息。拼接输出有效地结合了水平和垂直的上下文信息, 全面学习输入图像内的空间关系。
基于上述自注意力机制,CSWin Transformer块可以定义为:

其中 表示第 个CSWin Transformer块的输出或每个阶段的先前卷积层的输出。
Encoder
在编码器中, 输入图像的尺寸为 , 然后它们进入四个阶段进行特征提取。前三个阶段伴随着下采样操作。四个阶段中CSWin Transformer块的数量各不相同, 关于块数量的设置细节将在后文讨论。下采样层通过一个 Kernel 大小为 、步长为 2 的卷积层实现,将分辨率降低到输入大小的一半, 同时通道数翻倍。条带宽度 在不同阶段相应变化。随着分辨率的持续降低和通道数的增加, 在较大分辨率的阶段选择较小的 , 在较小分辨率的阶段选择较大的 , 有效地扩大了在每个较小分辨率阶段的每个标记的注意力区域。此外, 输入图像的分辨率为 。为了确保输入图像的中等特征图大小可以被 整除, 作者将四个阶段的 设置为 、、 和 7 。
Decoder
与编码器相对应, 解码器同样包含四个阶段。在最后三个阶段中, 通过CARAFE层实现图像分辨率和通道数的增加。这四个阶段中用于注意力学习的CSWin Transformer块的数量和条带宽度 与编码器中设定的参数一致。常用的上采样方法包括线性插值和转置卷积。双线性插值仅考虑相邻像素, 可能会模糊图像边缘, 导致分割结果的边界不清; 而转置卷积的感受野通常受限于核大小和步长, 这不仅限制了其表示局部变化的能力, 还需要学习转置卷积核的权重和偏置。与这些方法不同, 作者使用CARAFE [31] 来实现上采样。
CARAFE层是一种先进的上采样机制, 它主要由两个核心组件构成:一个核预测模块和一个内容感知重组模块。核预测模块首先通过一个卷积层从编码特征中预测重组核。它包括三个子模块:通道压缩器、上下文编码器和核归一化器。通道压缩器降低了输入特征图 中通道空间的维度, 从而降低了计算复杂性, 并专注于重要的特征信息。通道压缩之后, 上下文编码器处理降维后的特征图以编码上下文信息, 这对于生成重组核至关重要。每个预测的重组核通过核归一化器中的Softmax函数进行归一化, 以确保权重的输出分布是概率性的, 总和为 1 , 这增强了上采样过程的稳定性和性能。具有上采样比 (其中 为整数), CARAFE旨在生成一个扩展的特征图 。对于 中的每个像素 , 它对应于 中的特定像素 , 由 和 确定。核预测模块 根据邻域 为每个像素 预测一个唯一的重组核 , 这是一个以 上的像素 为中心的 区域。这个邻域提取局部特征, 预测的核使用这些特征有效地重组并上采样特征图。

其中 表示内容编码器的感受野。
第二步是内容感知重组, 输入特征通过卷积层进行重组, 而内容感知重组模块 使用重组核 重组 。

其中 是重装核的大小。对于每个重装核 , 内容感知重装模块在局部方形区域内重新组装特征。模块 执行加权求和。对于像素位置 及其中心邻域 , 重装过程如下:

其中 。
中的每个像素对上采样像素 的贡献各不相同。重新组装的特征图能够增强对局部区域内相关信息关注, 相较于原始特征图, 提供了更稳健的语义信息。此外, 与 UNet [9]类似, 作者使用跳跃连接将编码器和解码器输出的特征图进行合并, 从而提供了更丰富、更精确的空间信息, 有助于恢复图像细节。随后, 使用 卷积核在拼接后减少通道数, 确保与上采样过程中的特征通道数保持一致。
IV Experiments
Implementation details
CSWin-UNet是使用Python和PyTorch框架实现的。模型的训练和评估是在一块拥有24GB VRAM的NVIDIA(r) GeForce RTX(tm) 3090 GPU上进行的。作者使用从ImageNet [48]预训练的权重来初始化CSWin Transformer块, 以利用先验知识并加速收玫过程。在数据增强方面, 采用了翻转和旋转等方案, 以增强训练数据集的多样性, 从而帮助模型更好地泛化到未见过的数据。在训练阶段, 批量大小设置为 24 , 学习率设置为 0.05 。使用带有 0.9 动量和 权重衰减的随机梯度下降(SGD)方法进行优化。这种设置旨在平衡快速学习和收玫稳定性。此外, 为了有效地训练CSWin-UNet, 作者采用了一个组合损失函数, 该函数融合了Dice损失和交叉熵损失, 定义如下:

其中, 和 是两个超参数, 分别用于平衡 和Loss 对最终损失的影响。这个组合损失旨在同时关注像素 Level 的准确性和整体分割质量, 确保在各种医学图像分割任务中实现健壮的学习和性能提升。
Datasets and metrics
深度学习模型的性能在很大程度上依赖于用于训练的数据集的质量和规模。近年来,大规模数据集的发展显著推动了深度学习技术在各个领域的进步。在本节中,作者回顾了文献中常用的数据集以及用于评估深度学习模型性能的评价指标。
数据集
大多数深度学习研究依赖于大规模和高质量数据集的可用性。以下作者总结了文献中广泛使用的几个流行数据集。
- ImageNet
ImageNet是一个视觉数据库,用于视觉目标识别软件研究。它是计算机视觉领域最有影响力的数据集之一,包含超过1400万张图片和超过2万个类别。
- CIFAR-10和CIFAR-100
CIFAR数据集是一组常用于训练机器学习和计算机视觉算法的图像。CIFAR-10包含60,000张32x32彩色图像,分为10个类别;而CIFAR-100有100个类别,每个类别包含600张图像。
- MNIST
MNIST数据集是机器学习社区中的一个经典数据集,由28x28灰度手写数字图像组成。它包括一个包含60,000个样本的训练集和一个包含10,000个样本的测试集。
评价指标
评估深度学习模型的性能需要使用适当的评价指标。作者讨论文献中一些最常用的评价指标。
- 准确度
准确度是最直观的评价指标之一,通常被用作分类任务的标准默认度量。它定义为正确预测的数量除以总预测数量。
- 精确度、召回率和F1分数
在处理不平衡数据集时,精确度、召回率和F1分数是更具有信息量的评价指标。精确度衡量正确识别为阳性的比例,而召回率衡量正确识别出的实际阳性样本比例。
- Top-k准确度
Top-k准确度是标准准确度指标的一个变体。它衡量正确标签在top k预测中的百分比。
Iv-B1 Synapse dataset
synapse多器官分割数据集包括来自2015年MICCAI多图谱腹部器官分割挑战赛的30个CT扫描, 总共包含 3779 张腹部CT图像。每个CT扫描由85到198个切片组成, 每个切片像素为 , 每个 Voxel 的大小为 毫米 3 。按照文献 113 , 50,18]中的设置,选择了用于训练的集合以及用于评估的12个集合。对八种腹部器官(主动脉、胆囊、左肾、右肾、肝脏、胰腺、脾脏、胃) 的分割性能使用平均Dice相似系数 (DSC)和平均Hausdorff距离 (HD) 作为评价指标。
Iv-B2 ACDC dataset
自动心脏诊断挑战(ACDC)数据集在2017年的ACDC挑战期间发布,提供了一个包含多个类别的心脏3D MRI数据集,其中包括通过电影式MR 1.5T和3T扫描仪获取的100组短轴MR心脏图像。医学专家为三个心脏结构提供了标注:右心室(RV)、心肌(MYO)和左心室(LV)[51]。作者随机选择了70组MR图像用于训练,10组用于验证,20组用于评估。ACDC数据集使用平均_dice相似性系数(DSC)作为评估指标,以评价三个心脏结构的分割结果。
Iv-B3 Skin lesion segmentation datasets
作者在ISIC2017 [52],ISIC2018 [53],以及PH[54]数据集上进行了实验。ISIC数据集包含了大量的皮肤镜图像,覆盖了各种皮肤病变。遵循HiFormer [46]中的设置,作者在ISIC2017数据集中使用了1400张图像进行训练,200张图像进行验证,以及400张图像进行测试;在ISIC2018数据集中使用了1815张图像进行训练,259张图像进行验证,以及520张图像进行测试;在数据集中使用了80张图像进行训练,20张图像进行验证,以及100张图像进行测试。作者使用平均Dice相似系数(DSC)、敏感性(SE)、特异性(SP)和准确率(ACC)作为指标来评估皮肤病变分割任务。
Results on Synapse dataset
如下表1所示,作者在Synapse数据集上提出的方法改善了平均DSC和HD。同时,作者在图5中展示了平均DSC、平均HD以及每个器官DSC的误差条(95%置信区间)。与TransUNet [13]和Swin-UNet [30]相比,作者的平均DSC分别提高了3.64%和1.99%,平均HD分别改善了12.83%和2.69%。值得注意的是,在胰腺分割方面,CSWin-UNet的DSC显著高于其他分割方法。与其他器官不同,胰腺具有模糊的边界和多变性,作者的方法在胰腺分割上取得了更精确的结果,表明作者的CSWin-UNet在复杂的分割环境中提供了更高的分割精度。


为了更直观地评估所提出的方法,作者进行了分割结果的视觉分析。图6展示了在Synapse数据集上的比较结果。第一行显示,在分割像胆囊(绿色标签)这样的小器官时,Swin-UNet和HiFormer-B出现了明显的错误,Swin-UNet [30]未能准确勾勒边界,而HiFormer-B [46]错误地将其他区域识别为胆囊。第二行表明,Swin-UNet、TransUNet [13]、HiFormer-B和UNet [9]在完全分割胃(橙色标签)方面均失败。第三行揭示,Swin-UNet和HiFormer-B错误地将大片其他器官区域标记为胰腺(黄色标签)。考虑到定量指标和视觉结果,作者提出的CSWin-UNet实现了对精细和复杂器官的准确分割,产生了更精确的分割结果,展示了在复杂背景下更强的鲁棒性,并且在边缘结构处理方面表现更佳。

Results on ACDC dataset
表2展示了作者提出的CSWin-UNet在ACDC数据集上的实验结果,并将其与其他先进方法进行了比较。图7表示了每个心脏结构平均DSC和DSC的错误条(95%置信区间)。在表中,RV代表右心室,MYO代表心肌,LV代表左心室。结果显示,提出的CSWin-UNet能更好地识别和分割这些器官,准确率达到91.40%,显示出良好的泛化能力和鲁棒性。


Results on skin lesion segmentation datasets
表3展示了实验结果,图8显示了在三个皮肤病变分割数据集上DSC、SE、SP和ACC的误差条(95%置信区间)。实验结果表明,在大多数评估指标上,所提出的CSWin-UNet方法优于其他方法。特别是,与Swin-UNet [30]相比,CSWin-UNet在大多数指标上取得了更好的性能,显示出满意的泛化能力。作者还将在图9中可视化的皮肤病变分割结果。与Swin-UNet [30]相比,作者的CSWin-UNet在保留分割目标的边缘和详细特征方面具有一定的优势。然而,在低对比度或遮挡的情况下,如图9(d)所示,分割产生了显著的错误。



Comparison of computational efficiency
神经网络模型设计的一个基本目标是尽可能减少参数数量和计算复杂度,同时保持其性能。这种减少对于在计算资源有限的设备上实现更高效的模型训练和部署至关重要。因此,在评估一个模型时,不仅要考虑其准确性和泛化能力,还要考虑其参数数量和计算复杂度。在这里,作者使用浮点运算次数(FLOPs)和参数数量(以百万计,M)来衡量计算复杂度。在Synapse数据集上的性能比较显示在表4中。结果表明,所提出的CSWin-UNet在最低复杂度条件下实现了出色的分割性能。

Ablation studies
在本文的这一部分,作者对CSWin-UNet在Synapse数据集上的性能进行了消融研究。具体来说,作者探讨了解码器中不同的上采样策略、跳跃连接的数量、不同的网络架构以及组合损失函数中不同超参数对性能的影响。
V-B1 Upsampling strategy
在编码器中,通过使用步长为2的卷积层进行下采样,相应地,在解码器中需要上采样以恢复特征图,从而保留更多信息。在本文中,作者引入了CARAFE层以实现上采样并增加特征通道数,该层使用输入特征本身的内容来指导上采样过程,从而更准确、高效地进行特征重组。为了验证CARAFE层的有效性,作者在Synapse数据集上进行了实验,比较了双线性插值、转置卷积以及CARAFE层在CSWin-UNet中的表现,如表5所示。采用CARAFE层进行上采样获得了最高的分割准确度。此外,与转置卷积相比,CARAFE引入的计算开销非常小。实验结果表明,结合了CARAFE层的CSWin-UNet能够达到最优性能。

V-B2 Skip connection
类似于UNet,作者也引入了跳跃连接以增强细粒度的分割细节,通过恢复低级空间信息。在CSWin-UNet中,跳跃连接位于1/4、1/8和1/16的分辨率尺度上。作者依次减少了1/16、1/8和1/4尺度上的跳跃连接,将跳跃连接的数量设置为3、2、1和0,以探索不同数量的跳跃连接对分割精度的影响。如表6所示,分割精度通常随着跳跃连接数量的增加而提高。值得注意的是,相比于大器官(如肝脏、脾脏和胃),CSWin-UNet在小器官(如主动脉、胆囊、肾脏和胰腺)的分割精度上有更显著的提升。因此,为了达到最佳性能,作者将跳跃连接的数量设置为3。

V-B3 Network architecture
层数过少的神经网络可能导致特征表示丰富度和准确性不足,难以理解图像上下文,从而造成分割性能不佳。相反,过多的层数会增加计算负担,使网络难以收敛。因此,在设计网络架构时,在网络深度和模型性能之间取得了平衡,使得模型能够在有限的计算资源下实现高分割精度。此外,为防止因层数过多而导致的不收敛问题,在最后阶段将模块数量设置为1。通过比较其他基于Transformer的医学图像分割方法的参数数量和计算成本,作者将四个阶段的模块数量设置为、和,编码器和解码器模块对称排列。如表7所示,具有模块设置的网络架构实现了最佳性能。

Iv-C4 Combined loss function
作者探讨了组合损失函数的不同超参数对分割准确性的影响。在这里,作者将方程式10中的 和 分别设置为 、、、 和 。作者在Synapse数据集上进行了一项消融研究, 实验结果表明, 使用组合损失函数比单独使用Dice损失或交叉摘损失能获得更高的分割准确度,尤其是在仅使用Dice损失而不结合交叉摘损失的情况下。表8显示,当 和 设置为 时, 分割性能达到最优。

Discussions
作者在三个不同类型的医学图像分割数据集上的全面实验结果证明了作者提出的CSwin-UNet在多种模态的医学图像中比其他最先进的医学图像分割方法更为先进和适用。这些数据集包括CT、MRI和皮肤病变图像。
然而,作者的方法在一些具有挑战性的情况下表现出一些不足,例如在Synapse数据集中,胆囊和肾脏区域不同样本的分割精度存在显著差异,如图6所示。根据图9的可视化结果,在处理皮肤病变分割数据集中的低对比度图像时,分割性能还有很大的提升空间。
此外,模型的预训练对其性能产生了显著影响。在本次研究中,作者使用在ImageNet [48]上由CSwin Transformer [26]训练的权重来初始化编码器和解码器。因此,探索端到端的医学图像分割方法是作者在未来努力追求的研究课题之一。
V Conclusion
在本论文中,作者通过引入一种高效且轻量级的方法——CSWin-UNet,解决了先前基于Transformer的医疗图像分割模型在感受野交互方面的局限性。利用来自CSWin Transformer的CSWin自注意力机制,作者将这项技术融入了一种U形编码器-解码器架构中。
这种融合不仅降低了计算成本,还提升了感受野的交互作用和分割精度。在解码器中,采用了CARAFE层进行上采样,这有助于保留复杂的细节,并提高器官边缘分割的精确度。
在三个大规模医疗图像分割数据集上的全面评估表明,CSWin-UNet在分割精度上超越了其他最先进的方法。此外,CSWin-UNet在模型参数和计算负载方面更为轻量,这表明在复杂的医疗图像分割任务中,深度学习应用具有进一步的优化和增强的巨大潜力。
#GLARE
GLARE 利用外部正常光照先验,实现逼真的低光照增强效果!
本文提出一种新型的基于生成式隐层特征的码本检索的低光照增强网络GLARE,大量实验证明GLARE在多个基准数据集和真实数据上的卓越性能,以及GLARE在低光照目标检测任务中的有效性进一步验证了其在高层次视觉应用中的适用性。
论文链接:https://arxiv.org/pdf/2407.12431
GitHub链接:https://github.com/LowLevelAI/GLARE
亮点直击
- 首次采用外部正常光码本作为指导,去自然地增强低光照图像。
- 提出一种名为 GLARE 的新型低光照图像增强器,利用潜在归一化流来学习低光照图像特征分布,使其与自然光图像特征对齐。
- 提出一种具有可调功能的自适应特征变换模块,以在保证输出自然性的同时巩固保真度。
- 大量实验证明,GLARE在5个配对基准和4个真实世界数据集上的低光照图像增强任务中显著优于现有的最先进方法,并且作为高层次目标检测任务的预处理方法时,GLARE也具有很强的竞争力。
本文提出一种新型的基于生成式隐层特征的码本检索的低光照增强网络,命名为GLARE。其中码本先验是使用矢量量化(VQ)策略从未受损的正常光图像中提取的。更重要的是,我们开发了一种生成式可逆的隐层归一化流模块,将低光照图像的特征分布对齐到正常光图像的隐层表征,从而保证了在码本中正确的代码检索。为了保留由码本先验提供的真实细节的同时进一步提高保真度,我们设计了一种新颖的自适应特征变换模块。该模块包括一个自适应特征混合环节和一个双解码器结构,并具备用户调节功能。大量实验证明GLARE在多个基准数据集和真实数据上的卓越性能,以及GLARE在低光照目标检测任务中的有效性进一步验证了其在高层次视觉应用中的适用性。
方法
除了引入外部自然光码本来指导低光到正常光的映射外,本文工作的创新之处还在于独特的可逆潜在归一化流和自适应特征变换模块。这些模块旨在最大限度地发挥自然光码本先验的潜力,并生成具有高保真度的逼真结果。
本文提出的方法的概览如图3所示,其中我们方法的训练可以分为三个阶段。在第一阶段,在数千张清晰的自然光图像上预训练VQGAN,以构建一个全面的码书。在第二阶段,利用低光照-正常光照图像对训练I-LNF模块,实现低光照和正常光照特征之间的分布变换。在最后阶段,提出AFT模块(包含固定的自然光解码器、自适应混合块和多尺度融合解码器),用于保留码本所提供的自然性的同时增强细粒度细节。

阶段I:正常光码本学习
为了学习一个通用且全面的码本先验, 我们利用了一个结构类似于[15]的 VQGAN。具体来说, 一个自然光图像 首先被编码并重塑为隐层表征 , 其中 和 分别表示图像宽度、图像高度、隐层特征的维度和隐层特征的总数; 是自然光编码器的下采样因子。每个潜在向量 可以使用最近邻匹配量化为对应的代码 , 公式如下:

其中 表示包含 个离散码的可学习码本, 每个码由 表示。随后, 量化后的码 被传送到自然光解码器 (记作 ) 以生成重建的图像 。
为了更好地展示正常光码本先验的优势和局限性,本文在低光照-正常光图像对上微调了预训练的VQGAN编码器。具体来说,本文在图2b的第2列中展示了增强后的结果,并使用t-SNE可视化了由微调后的自然光编码器生成的低光照图像特征(见图2a),这证明了外部自然光先验在低光照图像增强中的有效性。此外,这些可视化结果启发作者设计额外的网络来对齐低光照特征和正常光隐层表征,以进一步提高增强性能。

阶段II:生成式隐层特征学习
为了充分利用外部码本先验的潜力,本文从减少低光照和正常光照特征分布差异的角度设计了额外的机制。具体来说,本文开发了一种可逆潜在归一化流,以实现低光照和正常光照特征分布之间的转换,从而实现更准确的码本检索。
如图 3 所示, 本文在第二阶段优化了两个关键组件:条件编码器和可逆归一化流模块。1) 条件编码器 :其结构与自然光编码器 相同,输入一个低光图像并输出条件特征 。2)本工作中的可逆归一化流模块通过一个可逆网络实现,表示为 。该模块利用 作为条件,将复杂的自然光特征分布 转换为一个潜在特征,即 。第二阶段训练的重点是获得一个在 空间中的简化分布 , 例如高斯分布。因此, 条件分布 [45] 可以隐式表示为:

与传统的归一化流方法 不同, 本文在特征层面而不是图像空间独特地应用了归一化流, 并且本文的设计中没有集成任何压缩层。此外, 本文提出使用由卷积层基于 生成的低光照特征 作为 的均值, 而不是使用标准高斯分布作为 的分布。公式 (2) 中的条件分布使得可以通过最小化公式 (3) 中的负对数似然来训练条件编码器和可逆归一化流模块。此外, 可以从 中采样 并使用完全可逆的网络 得到低光照输入的高质量特征 。

第二阶段训练完成后,本文在LOL数据集[65]上评估了提出的模型,以验证可逆归一化流模块的有效性。如图2a所示,由可逆归一化流模块生成的低光照特征分布与正常光照特征分布高度一致,促进了准确的码本组装。此外,令人满意的增强结果(图2b,第3列)表明本文提出的方法在第二阶段后,已经具备良好的低光照图像增强性能。然而,这些结果仍然有很大的改进空间,特别是在保真度方面。例如,颜色(图2b,第1行)或结构细节(图2b,第2行)与真实值有显著差异。这一观察促使作者将输入信息融入解码过程中,以提高保真度。
阶段III:自适应特征融合
为了进一步增强纹理细节和保真度, 本文提出了一种自适应特征变换模块, 该模块灵活地将条件编码器生成的特征 融入解码过程中, 其中 表示分辨率级别。具体来说, 为了保持正常光解码器 (NLD) 的真实输出并避免受损的低光照特征的影响, 本文采用了双解码器架构, 并参考 开发了多尺度融合解码器 (MFD)。双解码器设计使本文如方程 4 所示, 能够利用可变形卷积 (dconv) 来对 NLD 特征 ( ) 进行变形处理, 并将变形后的特征 输入多尺度融合解码 得到最终的增强结果。

其中 和 分别表示分辨率级别和目标特征本文设计了一种新颖的特征融合网络,该网络自适应地将低光照信息融入上述变形操作,并在实际测试中为用户提供潜在的调整功能。
自适应混合块 多尺度融合解码器(MFD)在结构上与正常光解码器(NLD)相似,旨在解码生成的低光照特征 并获得中间层表征 ,其中 表示分辨率级别。在每个分辨率级别,来自条件编码器信息 被添加到相应的 中, 以引入更多的低光照信息。不同于常规的特征融合操作,本文使用了一种自适应混合策略, 如下所示:

其中 表示可学习系数, 表示 Sigmoid 运算符, 用于实际测试中的调整, 训练时设置为 1 。
灵活调整功能 尽管公式(5)中 β 在训练阶段被设置为1,但在测试真实世界图像时,用户可以根据个人偏好灵活调整。这种设计的灵感来自于许多现有方法在处理真实世界数据时通常表现不佳,造成这一现象的原因是因为真实世界数据中的光照情况通常与训练阶段使用的图像有所不同。
实验
与现有方法的比较
- 比较的方法:包括 KinD, MIRNet, DRBN, SNR, Restormer, Retformer, MRQ, LLFlow, LL-SKF等
- 数据集:LOL,LOL-v2-real, LOL-v2-synthetic, SDSD-indoor, SDSD-outdoor, 分别在这些数据集的训练数据上训练,在相应测试集上评估。
- 跨数据集验证:在LOL训练集上训练,在真实世界数据集: MEF, LIME, DICM 和NPE上测试。
定量比较 如表1所示 GLARE在五个基准数据集上优于当前最先进的方法。本文提出的GLARE在PSNR上表现出色,在LOL和LOL-v2-synthetic数据集上分别超过LL-SKF 0.55 dB和0.74 dB。此外,在SDSD-indoor和SDSD-outdoor数据集上,它比Retformer分别提高了0.33 dB和1.01 dB。另外,GLARE的LPIPS在表1中分别超过了第二名20.9%和12.6%,这表明本文提出的方法的增强结果与人类视觉系统更为一致。表2展示了在非配对的真实世界数据集上的跨数据集评估结果。本文首先在LOL训练集上训练GLARE。然后,将在LOL测试数据上表现最佳的模型应用在四个非配对真实世界数据集上。与当前最先进的方法相比,GLARE在DICM和MEF数据集上表现优越,并在平均表现上达到最佳。这些结果不仅证明了本文方法在生成高质量视觉结果方面的优越性,也展示了其良好的泛化能力。


定性比较 图4、图5和图6展示了本文提出的 GLARE 与其他方法的视觉对比结果。显然,以往的方法在噪声抑制方面表现较差。此外,它们还往往会产生明显的色彩失真(参见图4中的KinD、LLFlow、Retformer、LL-SKF的增强结果,以及图5中的SNR和LLFlow)。此外,从定性比较来看,可以看到LLFlow、LL-SKF和Retformer在其增强结果中可能会导致细节缺失(参见图4和图5),而图4中的KinD和图5中的SNR由于引入了不自然的伪影而表现不佳。相比之下,GLARE能够有效增强低光照图像,同时可靠地保留色彩和纹理细节且。图6中在非配对真实世界数据集上的视觉比较也展示了本文提出的 GLARE 在细节恢复和色彩保持方面的优势。



低光照物体检测
在ExDark数据集上进行实验该数据集收集了7,363张低光图像,分为12个类别,并附有边界框注释,旨在研究低光图像增强(LLIE)方法作为预处理步骤在改善低光物体检测任务中的有效性。本文使用在LOL数据集上训练的不同的LLIE模型来增强ExDark数据集内图片,然后对增强后的图像进行目标检测。本文采用的目标检测器是预先在COCO数据集上训练的YOLOv3,并使用计算平均精度(AP)和平均的AP(mAP)作为评估指标。
表3 提供了本文方法 GLARE 与其他方法的定量比较结果。与KinD、MBLLEN、LLFlow和LL-SKF相比,本文提出的GLARE在mAP方面至少提高了0.8分。更重要的是,GLARE也优于在低光照目标检测中表现突出的IAT方法。图9展示了各个LLIE方法低光目标检测上的视觉比较结果。可以看出,尽管每种LLIE方法在一定程度上提高了图像的可见度,但本文方法 GLARE 实现了最佳的视觉表现,从而对下游的检测任务最有利。不出所料,GLARE 的增强效果使得YOLO-v3检测器能够以更高的置信度识别更多的目标。


消融实验
为了验证GLARE每个组件的有效性并证明用于训练的优化目标的合理性,本节在LOL数据集上进行了广泛的消融实验。具体来说,本节讨论了自适应特征融合模块、可逆归一化流模块和正常光码本先验的重要性。
自适应特征融合模块 从GLARE中移除自适应特征融合模块,可以得到一个简单的低光图像增强模型,称为SimGLARE。基本上,SimGLARE仅利用自然光码本先验中的信息而不进行特征变换。SimGLARE的定量结果如表4所示。在PSNR、SSIM和LPIPS方面,SimGLARE在低光照图像增强任务中相当具有竞争力(与表1中的SOTA方法相比)。然而,借助提出的自适应特征融合模块,本文提出的GLARE在定量指标和视觉结果上均取得了进一步的改进(如图7所示)。此外,表4中还检验了各种损失函数,显示了本文在第三阶段选择的损失函数是合理的。本文还设计了两个变体,分别命名为Variant 1和Variant 2,以说明所提出的双解码器架构和自适应混合块的重要性。具体来说,Variant 1直接将低光照特征通过自适应混合块引入到正常光解码器(NLD),而Variant 2采用并行解码器策略,但用skip-connection操作[26]替换了自适应混合块。通过比较表4中的(4)与(2)和(3),可以发现PSNR和SSIM与LPIPS呈负相关,这验证了本文提出的自适应混合块和双解码器设计的有效性。

可逆归一化流模块 为了展示I-LNF和采用的NLL损失的重要性,本文基于SimGLARE进行了几种调整:(1)使用L1损失训练SimGLARE,以验证本文采用的NLL损失的有效性。(2)用一个结构上类似于[84]的Transformer模型取代可逆归一化流模块,直接预测码本中的码索引。(3)在(1)的基础上移除可逆归一化流模块,并在低光-正常光图像对上训练条件编码器。定量结果如表5所示。通过比较(4)和(1),可以验证NLL损失的优越性。此外,比较图8中第二列和第三列的图像也表明,与L1损失相比,使用NLL损失可以产生更清晰的轮廓和边缘。此外,与基于Transformer的码预测方法相比,本文提出的可逆归一化流模块可以帮助生成更好地与正常光特征对齐的低光特征,从而确保更准确的码匹配并实现更优的性能。更重要的是,当从SimGLARE(L1)中移除可逆归一化流模块时,PSNR(降低1.16 dB)和SSIM(降低0.017)显著下降,这证明了本文提出的可逆归一化流模块的有效性。

自然光码本先验

结论
本文提出了一种名为GLARE的低光图像增强(LLIE)新方法。鉴于LLIE的病态性质引起的不确定性和模糊性,本文利用从清晰、曝光良好的图像中使用VQGAN获得的正常光码本来指导低光到正常光的映射。为了更好地发挥码本先验的潜力,本文采用了可逆潜在归一化流来生成与正常光隐层表征对齐的低光照特征,从而最大限度地提高码向量在码本中正确匹配的概率。最后,本文引入了具有双解码器架构的自适应特征变换模块,以灵活地在解码过程中提供输入信息,从而在保持感知质量的同时进一步提高增强结果的保真度。大量实验表明,本文提出的GLARE在5个配对数据集和4个真实世界数据集上显著优于当前最先进的方法。GLARE在低光目标检测中的卓越性能使其成为高层次视觉任务中有效的预处理工具。
#SLAB
华为开源,通过线性注意力和PRepBN提升Transformer效率
本文提出了一种渐进策略,通过使用超参数控制两种归一化层的比例,逐步将LayerNorm替换为BatchNorm。
论文地址:https://arxiv.org/abs/2405.11582
论文代码:https://github.com/xinghaochen/SLAB
Introduction
transformer架构最初引入用于自然语言处理任务,迅速成为语言模型领域的杰出模型。随着Vision Transformer(ViT)的引入,其影响力显著扩展,展示了基于transformer的架构的有效性和多样性。这些架构在与卷积神经网络(CNNs)相比,在各种视觉任务中表现出了竞争力的性能基准。由于其强大的性能,transformer已成为深度学习中的主流架构。然而,transformer架构的计算需求构成了一个重大挑战,这主要是由于其注意力机制的二次计算复杂性和LayerNorm组件在线统计计算的必要性。
许多工作致力于提升transformer架构的效率。有的方法试图通过限制自注意机制中token交互的范围来减少计算复杂度,例如降采样键和值矩阵、采用稀疏全局注意模式以及在较小的窗口内计算自注意力。与此同时,线性注意力作为一种替代策略出现,通过将注意力机制分解为线性计算成本来增强计算效率,然而,在效率和准确性之间取得良好平衡仍然是一个具有挑战性的任务。此外,由于LayerNorm在推理过程中额外的计算开销,一些探索尝试将BatchNorm(BN)替代transformer中的LayerNorm(LN),比如在前向网络的两个线性层之间添加一个BatchNorm层来稳定训练。然而,LayerNorm和BatchNorm的transformer之间仍存在性能差距。
论文的重点是通过深入研究计算效率低下的模块,即归一化层和注意力模块,来获取高效的transformer架构。首先,论文探索了用BatchNorm替换LayerNorm以加速transformer的推理过程。BatchNorm可以降低推理延迟,但可能导致训练崩溃和性能下降,而LayerNorm可以稳定训练,但在推理过程中会增加额外的计算成本。因此,论文提出了一种渐进策略,通过使用超参数控制两种归一化层的比例,逐步将LayerNorm替换为BatchNorm。最初,transformer架构由LayerNorm主导,随着训练的进行逐渐过渡到纯BatchNorm。这种策略有效地减轻了训练崩溃的风险,并且在推理过程中不再需要计算统计信息。除了渐进策略外,论文还提出了一种新的BatchNorm重新参数化公式(RepBN),以增强训练稳定性和整体性能。
此外,注意力机制的计算成本对于高效的transformer架构至关重要,之前的方法在效率和准确性之间难以取得良好的平衡。因此,论文提出了一种简化的线性注意力(SLA)模块,该模块利用ReLU作为核函数,结合深度可分卷积来进行局部特征增强。这种注意力机制比之前的线性注意力更高效,而且能达到可比较的性能水平。
论文在各种架构和多个基准测试上广泛评估了提出的方法。渐进重新参数化的BatchNorm在图像分类和物体检测任务中表现出强大的性能,以更低的推理延迟获得类似的准确性。此外,结合渐进RepBN和简化线性注意力模块的SLAB transformer在提高计算效率的同时,与Flatten transformer相比达到了竞争性的准确性。例如,SLAB-Swin-S在ImageNet-1K上达到了83.6%的Top-1准确率,推理延迟为16.2毫秒,比Flatten-Swin-S的准确率高出0.1%,延迟则减少了2.4毫秒。论文还对提出的方法在语言建模任务上进行了评估,获得了可比较的性能和更低的推理延迟。
Preliminaries
给定输入为 个令牌的特征 , 其中 是特征维度, Transformer 块的一般架构可以写成:
其中, 计算注意力分数, 表示多层感知机, 是归一化函数。在 Transformer 块的默认配置中, 通常是一个 LayerNorm 操作, 是基于 sof tmax 的注意力机制
注意力在 Transformer 中扮演着重要角色。将查询、键和值矩阵表示为 , softmax 注意力首先计算查询和键之间的成对相似性。成对相似性计算导致与查询和键的数量 相关的二次计算复杂度 , 使得 Transformer 在处理具有长序列输入的任务时计算成本昂贵。线性注意力旨在解耦 softmax 函数, 通过适当的近似方法或者用其他核函数先计算 , 计算复杂度变为 , 与查询和键的数量 线性相关。
然而,LayerNorm在推理过程中需要统计计算,因此占据了不可忽视的延迟部分。因此,论文探索利用BatchNorm来构建高效的Transformer模型,BatchNorm仅在训练过程中存在,并且可以与前置或顺序线性层合并。此外,注意力模块对于Transformer至关重要,而基于softmax的注意力机制由于其二次计算复杂度而在计算效率上存在问题。因此,论文提出了一种简单而高效的注意力形式,极大地减少了延迟,同时在各种视觉任务上保持了良好的性能。
Methods
论文专注于构建高效的Transformer模型,并提出了一系列策略,包括逐步替换LayerNorm(LN)为重新参数化的BatchNorm(BN)以及简化的线性注意力(SLA)模块。所提出的SLAB Transformer模型在与先前方法相比表现出了强大的性能,同时具备更高的计算效率。
Progressive Re-parameterized BatchNorm
LayerNorm在训练和推理过程中都需要进行统计量计算,因此显著影响了Transformer的运行速度。相比之下,BatchNorm在推理过程中可以简单地与线性层合并,更适合于高效的架构设计。然而,直接在Transformer中使用BatchNorm会导致性能表现不佳。为此,论文提出在训练过程中逐步替换LayerNorm为BatchNorm,并且还提出了一种受Repvgg启发的新的BatchNorm重新参数化公式,以进一步提高性能,如图2所示。
- Re-parameterized BatchNorm
RepBN公式如下:
其中,是一个可学习的参数,以端到端的方式联合训练。一旦训练完成,RepBN可以重新参数化为BatchNorm的一种规范形式。
根据引理 4.1, RepBN 输出的分布由 和 控制, 分别对应于方差和均值。R epBN 可以借助 和 来恢复分布。
同时, 当 时, 相当于跳过了 BatchNorm 。当 时, RepBN 则退化为纯粹的 BatchNorm 。
- Progressive LN RepBN
为了促进基于纯粹BN的Transformer模型的训练,论文建议在训练过程中逐步过渡从LN到RepBN,即
其中, 是一个超参数, 用于控制不同归一化层的输出。通常, 在训练初期 LN 主导架构时, ; 在训练结束时, 为了确保过渡到基于纯粹 BN 的 Transformer, 。我们采用了一个简单而有效的衰减策略来调整 的值:
其中, 表示使用 LayerNorm 进行训练的总步数, 表示当前的训练步数。这种渐进策略有助于减轻训练纯粹基于BN的Transformer的难度,从而在各种任务上实现强大的性能表现。 还有一些其他衰减策略可以逐渐减小 的值,例如余弦衰减和阶梯衰减。从实验来看,线性策略是比较有效且简单的一种方法。
Simplified Linear Attention
注意力模块是Transformer网络中最重要的部分,通常表述为:
其中, 将输入的标记投影到查询 (query) 、键 (key) 和值 (value)张量。 表示相似性函数。对于注意力的原始形式, 相似性函数是
这种基于softmax的注意力导致了较高的计算复杂度。近年来,有几种方法研究了使用线性注意力来避免softmax计算,从而提高Transformer的效率。然而,这些方法仍然存在相当复杂的设计,并且计算效率不够高。因此,论文提出了一种简化的线性注意力(SLA):
其中,表示深度可分离卷积(depth-wise convolution)。这是一种简单而高效的线性注意力方法,因为它通过先计算,享受了解耦的计算顺序,从而显著减少了复杂度。此外,该方法只使用了ReLU函数和深度可分离卷积,这两种操作在大多数硬件上都具有良好的计算效率。
这里的整体逻辑跟FLatten Transformer基本一样,只是将其提出聚焦函数替换为ReLU函数。这里的效率提升通过摘除softmax计算从而达到先计算 实现的(公式7做下乘法结合律),ReLU(也有保证内积为正数的作用)和DWC是补充计算顺序改变带来的性能损失。
为了展示该方法仍然保持特征多样性,论文通过可视化注意力图表明了应用了渐进重新参数化批归一化和简化线性注意力(SLAB)策略的DeiT-T的效果,如图3所示。可以看出,论文提出的方法仍然保持了较高的排名,表明其在捕捉注意力信息方面具有良好的能力。
Experiments
#小扎老黄亲密换衣炉边对谈
小扎竟破防爆粗,老黄自曝第一批Blackwell已出炉
就在刚刚,老黄在SIGGRAPH大会上透露:Blackwell的工程样片,已在本周正式向全世界发送!随后,老黄和小扎展开了炉边对话,并且亲密换衣,说到激动处,小扎气得一度爆粗。
惊爆消息来了!
刚刚,老黄在SIGGRAPH计算机图形会议上透露:就在本周,英伟达已经开始向全世界发送Blackwell的工程样片了!
紧接着,主持人Lauren Goode便调侃道:没错,大家低个头,凳子下面就有。
值得一提的是,在这款当今最强的AI芯片背后,同样也离不开AI——
没有AI,Hopper将无法问世;没有AI,Blackwell也无法成为可能。
在他和小扎上演的一场炉边对话中,讲到情绪激动时,小扎甚至一度忍不住出口爆粗。
由于两位大佬之前的换衣效果实在是一言难尽。
这次,小扎专门给老黄送上了定制的「黑皮衣风」棉服。
上身之后,的确效果拔群!
当然,小扎也穿上了老黄仅用了2小时的「二手」皮衣。(这可比全新的值钱多了)
英伟达的数字「副本」世界
在大会上,老黄宣布,英伟达构建了世界上首个能够理解基于 OpenUSD(语言、几何、材料、物理和空间的生成性AI模型,
什么是OpenUSD呢?它指的就是Universal Scene Description,可以理解为一种通用场景描述。
老黄表示,比起AI对文本执行的操作,更令人兴奋的,是我们可以对图像执行同样的操作。
比如英伟达创建的Edify AI模型,就是一个文本到2D的基础模型。
对于品牌来说,它可以创造出可口可乐、汽车、奢侈品等等,然而控制提示,就是一件困难的事。
这是因为,词语的纬度非常低,它在内容上极其压缩,但同时又非常不精确。
为此,英伟达创造了一种方法——创造另一个模型,实现控制和调整它与更多条件的对齐。
使用Omniverse,可以组合所有这些多模态数据和内容,无论是3D,AI,动画,还是材质。
我们可以改变它的姿势、位置,总之改变我们想要的任何东西。
使用Omniverse中的条件化提示,就跟检索增强生成一样,可以理解为一种3D增强生成。
这样,我们就可以按照喜欢的方式生成图像了。
接下来,WPP用Shutterstock与世界知名品牌完成的作品,直接震撼了全场。
在一个空房间里给我建一张桌子,周围摆着椅子,在一个繁忙的餐馆里。
在晨光中给我建一张摆着玉米卷和一碗莎莎酱的桌子。
在一条空旷的道路上给我建一辆车,周围是树木,靠近一座现代房屋。
在一片空旷的田野里给我建一棵树。
在所有方向给我建数百棵这样的树。
让这片树林有灌木丛和藤蔓悬挂其间。
给我建一片巨大的热带雨林,里面有奇异的鲜花和阳光射线。
Omniverse现在能够理解文本到USD的转换。它能够理解文本,并拥有一个语义数据库,因此可以搜索所有的3D对象。
因此,小女孩可以描绘自己想以什么方式填充3D树,完成之后,3D场景就会进入生成式AI模型,将其转化为照片级真实感的模型。
从此,越来越多的生成式AI会出现在Omniverse中,帮人们创建这些模拟,或数字孪生。
比如下面这个数字AI,将使每家公司都有客户服务。
在当下,客户服务是由人类完成的,但在未来,AI将参与其中。
客户服务会连接到一个数字人前端,也就是一个IO。这个IO可以说话,还能与我们眼神交流。
各类AI都可以连接到这个数字人,甚至数字人还可以连接到英伟达的检索增强生成客户服务AI上。
NIM服务
这次大会上,英伟达推出了一套全新的NIM微服务。
NIM专为不同的工作流量身定制,包括OpenUSD、3D 建模、物理、材料、机器人、工业数字孪生和物理AI。
在AI和图形领域,英伟达推出了专为生成物理AI应用程序设计的全新OpenUSD NIM微服务。
这个工作流包括,用于机器人模拟等的新NIM微服务,来加速人形机器人的开发。
「三体」创造机器人
老黄预言,下一波AI,是物理AI。
如果机器人技术想进步,就需要先进的AI和逼真的虚拟世界;而在部署下一代人形机器人之前,我们需要对AI进行训练。
机器人技术需要三台计算机:一台用于训练AI,一台在物理精确的模拟中测试AI,另一台位于机器人本身内部,可以学习如何优化机器人。
也就是说,第三台AI是实际运行AI 的计算机。
为此,英伟达创造了三台计算机。
没有AI,就没有H100/H200和B100
从1990年代开始的英伟达历史中,真正的DNA就在于计算机图形学。
计算机图形学,也一路把英伟达带到了今天的位置。
这幅图中,展示了计算机行业一些重要的里程碑,包括IMB 360系统、犹他茶壶、光追、可编程着色等等
1993年,英伟达成立。八年后,他们发明了第一个可编程着色GPU,很大程度上推动了英伟达的发展历程。
可以说,英伟达所做的一切,背后的核心就是加速计算。他们坚信,如果创建一种计算模型来增强通用计算,就可以解决普通计算机无法解决的问题。
首选的领域,就是计算机图形学。他们赌对了。
将计算机图形学应用到当时非主流的领域——3D图形视频游戏,直接推动了英伟达的飞轮。
此后,他们花了很长时间让CUDA无处不在,然后在2012年,就仿佛《星际迷航》中一般,英伟达第一次接触了AlexNet。
在2012年,那是一个爆炸性的时刻,AlexNet在计算机视觉上取得了惊人的突破。它的核心——深度学习如此深刻,再也不需要工程师们提供输入后,去想象输出的样子了。
2016年,英伟达推出了第一台为深度学习打造的计算机DGX-1,被马斯克看上,随后产品被交付给当时名不见经传的OpenAI。
随后,RTX、DLSS被发明出来。
然后,就是ChatGPT的诞生。
未来人人都有AI助手
如今,我们已经学会用AI学习一切,不仅仅是单词,还有图像、视频、3D、化学物质、蛋白质、物理学、热力学、流体动力学、粒子物理学等等。
我们理解了所有这些不同模态的意义。
在老黄看来,基于视觉计算的生成式AI革命,正在增强人类的创造力。
我们真正处于革命性的时刻,迈向软件3.0的时代——没有哪个行业,能逃过AI的影响!
老黄预言:每个人都会有一个AI助手,每家公司、公司内的每一项工作,都将得到AI的帮助
加速计算,让能源问题有解
虽然生成式AI有望提高人类生产力,但AI基础设施的耗能问题,却是困扰整个地球的大问题。
ChatGPT的一次搜索,相当于10次谷歌搜索的电量。
数据中心消耗了全球总体能源的1%到2%,甚至可能在十年内达到6%。
怎么办?老黄有解。
他表示,加速计算技术,有望使计算更节能。
「加速计算可以帮我们节省大量能源,它能节省20倍、50倍,并且执行相同的处理,」老黄说。
「作为一个社会,我们要做的第一件事就是加速我们能做到的每一项应用:这减少了全世界的能源使用量。」
这也是为什么Blackwell备受期待,因为它使用同样的能量,却大大加速了应用程序。
而且,它还会越来越便宜。
老黄强调:要记住,生成式AI的目标并不是训练,而是推理。理想情况下,推理可以为我们创建预测天气的新模型、预测新材料、优化供应链等等。
要知道,数据中心并不是唯一消耗能源的地方。全球数据中心只占总计算量的40%,60%的能源消耗在网上,移动着电子、比特和字节。
因此,生成式AI将减少网上的能源消耗,因为不需要去检索信息,我们可以在现场直接生成了。
而且就在刚刚,英伟达在GCP中部署了GPU,来运行Pandas。
这个世界上最领先的数据科学平台,直接把速度从50提升到了100倍,超过了通用计算。
在过去10到12年的时间里,我们已经将深度学习的速度提升了100万倍,成本和能耗降低了100万倍,这就是为什么LLM能够诞生。
不过,英伟达还会通过设计新的处理器、新系统、Tensor核心GPU和NVLink交换机结构,给AI带来新的创新。
老黄和小扎的炉边对谈
今年SIGGRAPH上两位CEO的炉边对谈让很多人期待已久。用小扎本人的话来说,「两个行业内最资深的创始人」,究竟会碰撞出怎样的火花?
下一波浪潮
不出意外的是,这两位「青梅煮酒」的英雄都各自分享了自己的预判,大谈未来的技术发展趋势,从GenAI,到Agent,再到小扎始终念念不忘的「元宇宙」。
老黄表示,GenAI的技术力量也让他感到震撼,「我不记得有哪项技术以如此迅猛的速度影响了消费者、企业、工业和学界,而且跨越了从气候技术到生物技术,再到物理科学的所有不同领域。」
小扎也表示,GenAI很可能会重塑Meta的各类社交媒体软件。
曾经,这些产品的核心——推荐系统,仅仅是将感兴趣的内容推送给用户。
但GenAI将不再局限于已有内容,不仅能协助创作者,还会为用户创建即时内容,或综合现有内容进行生成。
关于Agent的发展,两人似乎也有类似的观点。
在之前的演讲中,老黄就明确表示,「未来每个人都将有自己的AI助手」。
这场对谈中,小扎也表述了类似的愿景。他正在为Meta规划AI助手和AI Studio产品,让每个人都能为不同用途创建自己的Agent。
未来,每个企业都将拥有自己的AI,正如今天所有公司都有自己的社交媒体和邮箱账号一样。
他们口中的「AI助手」,究竟要达到何种程度的「智能」?
我们目前看到的Llama 3仅仅是一个「聊天机器人」般的语言模型,只能对人类的提问做出响应。但小扎希望,可以给AI赋予「意图」(intent)。
老黄则将其描述为「规划能力」,能像人类一样在脑海中形成「决策树」,进而指导行为。
他甚至更大胆地预测,这种AI助手的成本仅有每小时10美元,却能大大提高工程师们的工作表现。「如果你还没雇佣AI,就赶紧行动起来!」
对于Meta最核心也是最独特的AR/VR技术,小扎的蓝图也相当精确,充分体现了他的强迫症人格。
(据老黄爆料,小扎切西红柿都有毫米级的精度,而且每片西红柿都不能相互接触。)
去年9月,Meta联合雷朋推出了新款智能眼镜,配备音频设备和摄像头,让用户直接从双眼视角拍照,或将眼镜中看到的视野直接直播到Facebook或Instagram上,并集成了对话助手Meta AI。
小扎表示,基于雷朋眼镜现在的情况,定价300美元的无显示屏AI眼镜将成为非常热门的产品。
根据他的预测,智能眼镜在未来会成为一种类似手机的设备,每个戴眼镜的人都将带上智能眼镜(全世界超过10亿人)。
接下来几年时间,Meta还将推出有全息AR功能的眼镜,虽然成本依旧很高,但将会是可行的产品。
与智能眼镜不同,混合现实头显更类似于工作站或游戏机,不方便携带但算力更强,能为用户提供更加沉浸式的体验。
而且,随着全息AR技术的发展,「虚拟会议」即将成为现实。
不同于Zoom平台上的头像或视频,每个人都将有自己的全息影像,即使身处不同的物理空间,也能让全息图打造的「虚拟人」在同一空间内合作交互。
开源是前进之路
提到Meta,他们一贯实行的「开源」策略也是不得不谈的要点。
老黄就十分赞赏这种策略,他表示,Llama 2可能是去年AI领域最重要的事件;加上PyTorch和最新发布的Llama 3.1,Meta已经构建了一整个生态系统。
但小扎表示,他们走上开源之路也是一种「随机应变」。
在很多赛道上,尤其是分布式计算系统和数据中心方面,Meta的起跑线其实落后于其他公司,因此团队想到了开源,尤其是开放计算(open compute)。
没有想到的是,这种权宜之计反而成为「弯道超车」的关键策略。
正是开源,让Meta发布的产品成为行业标准,整个供应链也围绕其建立。通过将项目开源,Meta甚至还节省了数十亿美元。
比如,Meta进入GPU领域的时间其实晚于大多数公司,但他们目前运营的GPU超算集群,规模几乎超过了所有竞争对手。
当然,这背后少不了老黄的大力支持,毕竟Meta的60万张GPU也都出自英伟达之手。
开源虽然能推动这个社区和行业的进步,但小扎也很诚实地表示,开源不是做慈善,我们选择这种策略并不是因为有一颗无私奉献的心。
更主要的目的,是希望让正在构建的产品登峰造极,成为最好的东西。
PyTorch就是最典型的例子,全世界的开发人员,包括英伟达的两三百名工程师,都在帮这个开源框架找bug、做优化,构成了老黄口中的「PyTorch的工程之山」。
虽然小扎自己也承认,开源是有私心的,但谈到「封闭」平台时还是克制不住地情绪激动。全场唯一脏话就出自这个话题。
虽然Meta坐拥一众王者级社交软件,但这些应用程序都需要通过竞争对手的平台进行分发,尤其是苹果应用商店,以及谷歌的安卓系统。
让小扎很气恼的是,他曾经有过很多产品创意,但受限于这些移动平台的各种限制,最终都无法成行。
移动互联网时代的这种极度依赖平台的特点,与曾经PC时代的开放完全不同,这让小扎相当怀念网页端的Facebook。
因此,他满怀信心地表示,我们正在塑造下一代计算平台,即混合现实技术,其中开源软件将重新拥有更大的价值。
下一代平台和生态系统将更具有开放性、包容性,类似之前的Windows或安卓生态,而非完全封闭的苹果。
这种「让开源重新伟大」的雄心,让人不禁想起Llama 3.1发布时他的比喻——Llama 3.1是这个时代的Linux。
CEO不好做
整个对谈过程中,两人颇有惺惺相惜之感,而且经常谈到CEO这份职业的艰难。
时年61岁、穿着皮夹克的Jensen甚至一脸严肃地自比娇花:「我们是CEO,像娇嫩的花朵,需要很多支持。」
小扎甚至紧跟着接了一句,「我们现在相当憔悴了」。
这种感慨,也许来自于两位资深创始人曾经和公司共同经历的风雨。
在小扎看来,老黄当年顶着不被看好的压力,硬要把计算机做成「超级巨兽」,让英伟达终成行业传奇;
在老黄看来,小扎带着Meta多次转型,从PC端到移动端,从社交媒体到VR/AR和AI的研究。
对谈的最后,老黄直言两人的共同之处,「我知道那样做(转型)有多难,我们两个都曾经被狠狠打击过,但这就是成为先锋和创新所必备的。」
参考资料:
https://www.youtube.com/watch?v=H0WxJ7caZQU
https://www.youtube.com/watch?v=w-cmMcMZoZ4
#HourVideo
空间智能版ImageNet来了!李飞飞吴佳俊团队出品,来自斯坦福李飞飞吴佳俊团队!
HourVideo,一个用于评估多模态模型对长达一小时视频理解能力的基准数据集,包含多种任务。
通过与现有模型对比,揭示当前模型在长视频理解上与人类水平的差距。
2009年,李飞飞团队在CVPR上首次对外展示了图像识别数据集ImageNet,它的出现极大推动计算机视觉算法的发展——懂CV的都是知道这里面的门道有多深。
现在,随着多模态迅猛发展,团队认为“现有的视频基准测试,大多集中在特定领域或短视频上”,并且“这些数据集的平均视频长度较短,限制了对长视频理解能力的全面评估”。
于是,空间智能版ImageNet应运而生。
HourVideo包含500个来自Ego4D数据集的第一人称视角视频,时长在20到120分钟之间,涉及77种日常活动。
评测结果表示,人类专家水平显著优于目前长上下文多模态模型中最厉害的Gemini Pro 1.5(85.0%对37.3%)。
在多模态能力上,大模型们还任重而道远。
HourVideo如何炼成?
之所以提出HourVideo,是因为研究人员发现目前长视频理解越来越重要,而现有评估benchmark存在不足。
多模态越来越卷,人们期待AI被赋予autonomous agents的类似能力;而从人类角度来看,由于人类具备处理长时间视觉处理的能力,因此能在现实视觉中感知、计划和行动。
因此,长视频理解对实现这一目标至关重要。
而当前的多模态评估benchmark,主要还是集中在评测单张图像或短视频片段(几秒到三分钟),对长视频理解的探索还有待开发。
不可否认的是,AI评估长视频理解面临诸多挑战,譬如要设计任务、避免通过先验知识或简短片断回答等。
因此,团队提出HourVideo。
这是一个为长视频理解而设计的基准数据集。
为了设计出需要长期理解的任务,团队首先提出了一个新的任务对应套件,包含总结、感知(回忆、跟踪)、视觉推理(空间、时间、预测、因果、反事实)和导航(房间到房间、对象检索)任务,共18个子任务。
其中,总结任务要求模型对视频中的关键事件、主要交互等进行概括性描述,例如总结出脖子上挂了个相机的人在超市中有什么关键交互行为。
感知任务由两部分构成,
一个是回忆任务,包括事实回忆(比如脖子上挂了个相机的人,在超市拿起的乳制品)和序列回忆(比如那个人在超市称完西红柿过后做了什么),以及对时间距离的判断(比如吃了多久的披萨才扔掉盒子)。
还有一个是跟踪任务,主要用来识别脖子上挂了个相机的人在特定场景(比如超市、药店)中互动的独特个体。
接下来是视觉推理任务,分为空间推理和时间推理。
空间推理负责判断物体之间的空间关系、空间接近度(如微波炉与冰箱或水槽相比是否更近)以及空间布局(如选择正确描绘脖子上挂相机的人的公寓的布局图)。
时间推理则包括对活动持续时间的比较、事件发生频率的判断、活动的先决条件、预测(如洗完衣服后最可能做的活动)、因果关系(如第二次离开车库的原因)以及反事实推理(如用烤箱做土豆泥会怎样)。
导航任务包含了房间到房间的导航、对象检索导航。
以上每个任务有精心设计的问题原型,以确保正确回答问题需要对长视频中的多个时间片段进行信息识别和综合,从而有效测试模型的长期理解能力。
与此同时,研究人员通过pipeline来生成了HourVideo数据集。
第一步,视频筛选。
团队从Ego4D数据集中手动审核1470个20到120分钟的视频,让5位人类专家选择了其中500个视频,
至于为啥要从Ego4D中选呢,一来是其以自我为中心的视角与autonomous agents和助手的典型视觉输入非常一致;二来是它具有广泛的视觉叙述,有助于创建多样化的题;三来Ego4D的访问许可非常友好。
第二步,候选MCQ生成。
这需要在长视频中跨多个时间片段,进行信息分析和合成。
具体来说,研究人员以20分钟为间隔分割了视频,提取信息转化为结构化格式供大模型处理。最终一共开发了25个特定任务的prompts。
第三步,LLM优化与人工反馈。
在这个阶段,团队实现了一个人工反馈系统,7名经验丰富的人员人工评估每个问题的有效性、答案准确性、错误选项合理性。最终收集了400多个小时的人工反馈,然后设计prompt,自动优化 MCQ₂得到 MCQ₃。
第四步,盲选。
这一阶段的目标是消除可以通过大模型先验知识的问题,或者消除那些可以在不用视频中任何信息就可以回答的问题。
团队用两个独立的大模型——GPT-4-turbo和GPT-4,对MCQ₃进行盲筛,确保剩余 MCQ₄高质量且专门测试长视频语言理解。
第五步也是最后一步,专家优化。
这一步是用来提升MCQ₄质量,将宽泛问题精确化,经此阶段得到高质量 MCQ₅。
4个专家干的事be like,把 “挂着相机的人把钥匙放在哪里了?” 精确成“挂着相机的人购物回家后,把自行车钥匙放在哪里了?”
如上pipeline中,研究图纳队使用了GPT-4来遵循复杂的多步骤指令,同时还使用了CoT提示策略。
此外,pipeline中涉及大模型的所有阶段的问题被设为0.1。
据统计,HourVideo涵盖77种日常生活场景,包含500个Ego4D视频,视频时长共381个小时、平均时长45.7分钟,其中113个视频时长超过1小时。
每个视频有约26个高质量五选一题,共计12976个问题。
除因果、反事实和导航任务外,问题在任务套件中均匀分布。
最好表现仍远低于人类专家水平
在实验评估方面,HourVideo采用五选多任务问答(MCQ) 任务,以准确率作为评估指标,分别报告每个任务以及整个数据集的准确率。
由于防止信息泄露是评估长视频中的MCQ时的一个重要挑战——理想情况下,每个MCQ应独立评估,但这种方法计算成本巨高,且十分耗时。
因此,实际评估中按任务或子任务对问题进行分批评估,对于预测任务,提供精确的时间戳以便对视频进行有针对性的剪辑,从而平衡计算成本和评估准确性。
研究团队比较了不同的多模态模型在零镜头设置下理解长视频的性能。
主要评估了三类模型,所有这些模型都在一个通用函数下运行:
盲LLM:
指是指在评估过程中,不考虑视频内容,仅依靠自身预先训练的知识来回答问题的大型语言模型。
实验中以GPT-4为代表。它的存在可以揭示模型在多大程度上依赖于其预训练知识,而不是对视频中实际视觉信息的理解。
苏格拉底模型:
对于大多数当前的多模态模型,直接处理非常长的视频存在困难。
因此,采用Socratic模型方法,将视频(总时长为t分钟)分割成1分钟的间隔,每个间隔独立加字幕,然后将这些字幕聚合形成一个全面的基于语言的视频表示,并与通用任务无关的提示一起作为输入进行长视频问答。
实验中分别使用GPT-4和LLaVA- NEXT-34-DPO 为视频字幕生成器,并最终使用GPT-4进行实际问题回答。
原生多模态模型:
像Gemini 1.5 Pro这样的原生多模态模型,在多模态数据(包括音频、视频、图像和文本)上联合训练,能够处理非常长的上下文长度*((2M +),适合直接对HourVideo进行端到端评估。
为了与模型性能进行对比,实验人员从基准数据集中选取了14个视频,涵盖>18种场景,包括手工制作/绘画、烹饪、建筑/装修、园艺、清洁/洗衣和庭院工作等。
然后邀请了3位人类专家,对上述总时长11.2小时的视频内容进行进行评估,共涉及213个MCQ。
为确保评估的公正性,参与评估的人类专家未参与过这些视频的早期注释工作。
最终,人类专家在评估中的准确率达到了85.0% 。
而盲LLM的准确率为19.6%,Socratic模型准确率略高,原生多模态模型准确率最高,达到了37.3%,仍然远低于人类专家水平。
此外,独立评估每个MCQ与按任务级别评估相比,性能下降2.1%,但成本增加3倍以上,证明了任务级评估方法的效率和有效性。
最后,团队表示未来计划扩展基准测试,包括更多样化的视频来源(如体育和YouTube视频),纳入音频模态支持,并探索其他感官模态。
同时强调在开发模型时需考虑隐私、伦理等问题。
团队成员
HourVideo项目来自斯坦福李飞飞和吴佳俊团队。
论文共同一作是Keshigeyan Chandrasegaran和Agrim Gupta。
Keshigeyan Chandrasegaran是斯坦福大学计算机科学博士二年级学生,从事计算机视觉和机器学习研究,导师是李飞飞和斯坦福视觉与学习实验室(SVL)联合主任胡安·卡洛斯·尼贝莱斯。
共同一作Agrim Gupta是斯坦福大学计算机科学专业的博士生,2019年秋季入学,同样是李飞飞的学生。
此前,他曾在微软、DeepMind,有Meta的全职经历,也在Google做过兼职。2018年时,他就跟随李飞飞一同在CVPR上发表了论文。
目前,Agrim的Google Scholar论文被引用量接近6400次。
李飞飞是大家熟悉的AI教母,AI领域内最具影响力的女性和华人之一。
她33岁成为斯坦福计算机系终身教授,44岁成为美国国家工程院院士,现任斯坦福以人为本人工智能研究院(HAI)院长。
计算机视觉领域标杆成果ImageNet亦是由她一手推动。
此前,李飞飞也曾短暂进入工业界,出任谷歌副总裁即谷歌云AI首席科学家。她一手推动了谷歌AI中国中心正式成立,这是Google在亚洲设立的第一个AI研究中心。并带领谷歌云推出了一系列有影响力的产品,包括AutoML、Contact Center AI、Dialogflow Enterprise等。
今年,李飞飞宣布创办空间智能公司World Labs,公司成立不到4个月时间,估值突破10亿美元。
所谓空间智能,即“视觉化为洞察;看见成为理解;理解导致行动”。
吴佳俊,现任斯坦福大学助理教授,隶属于斯坦福视觉与学习实验室(SVL)和斯坦福人工智能实验室(SAIL)。
他在麻省理工学院完成博士学位,本科毕业于清华大学姚班,曾被誉为“清华十大学神”之一。
同时,他也是李飞飞创业公司World Labs的顾问。
参考链接:
[1]https://arxiv.org/abs/2411.04998v1
[2]https://www.worldlabs.ai/team
[3]https://keshik6.github.io/
#梳理下Flash Attention的dispatch逻辑
本文分析了Flash Attention在不同场景下的内核调度逻辑,特别关注了在解码阶段何时会使用split_kv实现,并探讨了影响这一决策的因素,如K序列的最大长度、注意力头数和GPU的流处理器数量。
1. 前言
这篇文章来源是当运行下面的对HuggingFace Qwen2.5-7B-Instruct模型使用Flash Attention的代码时,使用Nsight System工具抓取的kernel trace会发现在prefill和decode阶段,Flash Attention调用了不同的kernel并且decoding的Flash Attention kernel使用了split_kv的实现。然后如果把下面代码中max_new_tokens改成64,我发现在Nsight System工具抓取的kernel trace中,decode阶段的Flash Attention kernel又变成了和prefill阶段一样的kernel,并没有使用split_kv的实现。这篇文章就尝试跟踪下Flash Attention的dispatch逻辑,弄清楚什么情况下decode阶段的Flash Attention kernel会使用split_kv的实现(split_kv的实现也被叫作Flash Decoding,专用大模型的Decoding阶段)。
# /opt/nvidia/nsight-systems/2024.5.1/bin/nsys profile --trace-fork-before-exec=true --cuda-graph-trace=node -o hf_qwen2.5_7b_flash_attn python3 debug.py
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import nvtx
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "/mnt/bbuf/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "帮我计划一次去北京的旅行,我想明年春天出发,大概五天的行程。"
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
for i in range(1):
with nvtx.annotate(f"step={i}", color="blue"):
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
这张图是max_new_tokens=512时,prefill和decode阶段的Flash Attention kernel的trace。红色框表示prefill阶段调用的Flash Attention kernel,绿色框表示decode阶段调用的Flash Attention kernel。可以看到prefill阶段调用了flash_fwd_kernel,decode阶段调用了flash_fwd_splitkv_kernel和flash_fwd_splitkv_combine_kernel两种kernel。

这张图是max_new_tokens=64时,prefill和decode阶段的Flash Attention kernel的trace。可以看到两个阶段都调用了同一个flash_fwd_kernel。
为什么产生了这种差别,什么情况下decode阶段的Flash Attention kernel会使用split_kv的实现?我们需要深入看一下Flash Attention的相关Dispatch逻辑。
2. Qwen2是如何访问Flash Attention API的
下面是 HuggingFace Qwen2 模型 Qwen2FlashAttention2 模块的实现,我们可以从这个代码中看到 flash attention 的 API 是如何被调用的。这里调用的 _flash_attention_forward 实际上又是调用了 flash-attention 库(https://github.com/Dao-AILab/flash-attention)中的 flash_attn_varlen_func api,这个api是flash attention库中用来处理Attention前向计算的核心函数,并且可以从名字看出来这个api还支持可变长的多个序列的Attention计算。
class Qwen2FlashAttention2(Qwen2Attention):
# ...
def forward(
self,
hidden_states: torch.Tensor, # 输入隐藏状态
attention_mask: Optional[torch.Tensor] = None, # 注意力mask
position_ids: Optional[torch.LongTensor] = None, # 位置编码id
past_key_value: Optional[Cache] = None, # KV缓存
output_attentions: bool = False, # 是否输出注意力权重
use_cache: bool = False, # 是否使用KV缓存
cache_position: Optional[torch.LongTensor] = None, # 缓存位置
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # 位置编码,在v4.46中将成为必需
):
# 获取输入维度
bsz, q_len, _ = hidden_states.size()
# QKV投影
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# 重塑维度以适应多头注意力
query_states = query_states.view(-1, self.num_heads*self.head_dim)
key_states = key_states.view(-1, self.num_key_value_heads*self.head_dim)
value_states = value_states.view(-1, self.num_key_value_heads*self.head_dim)
# 应用旋转位置编码(RoPE)
query_states, key_states = self.rotary_emb(position_ids, query_states, key_states)
# 重塑维度为[batch_size, num_heads, seq_len, head_dim]
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
# 处理KV缓存
if past_key_value is not None:
cache_kwargs = {"cache_position": cache_position} # RoPE模型特有的参数
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
# 如果KV头数小于注意力头数,需要重复KV
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
dropout_rate = 0.0 if not self.training else self.attention_dropout
# 处理数据类型转换
input_dtype = query_states.dtype
if input_dtype == torch.float32:
if torch.is_autocast_enabled():
target_dtype = torch.get_autocast_gpu_dtype()
elif hasattr(self.config, "_pre_quantization_dtype"):
target_dtype = self.config._pre_quantization_dtype
else:
target_dtype = self.q_proj.weight.dtype
logger.warning_once(
f"输入隐藏状态似乎被静默转换为float32,这可能与embedding或layer norm层被上采样到float32有关。"
f"我们会将输入转回{target_dtype}。"
)
query_states = query_states.to(target_dtype)
key_states = key_states.to(target_dtype)
value_states = value_states.to(target_dtype)
# 重塑维度以适应Flash Attention
query_states = query_states.transpose(1, 2)
key_states = key_states.transpose(1, 2)
value_states = value_states.transpose(1, 2)
# 处理滑动窗口注意力
if (
self.config.use_sliding_window
and getattr(self.config, "sliding_window", None) is not None
and self.layer_idx >= self.config.max_window_layers
):
sliding_window = self.config.sliding_window
else:
sliding_window = None
# 调用Flash Attention前向传播
attn_output = _flash_attention_forward(
query_states,
key_states,
value_states,
attention_mask,
q_len,
position_ids=position_ids,
dropout=dropout_rate,
sliding_window=sliding_window,
is_causal=self.is_causal,
use_top_left_mask=self._flash_attn_uses_top_left_mask,
)
# 重塑输出并应用输出投影
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value这里的代码省略掉了类的相关初始化,在forward函数中涉及到rope,kv cache更新,reshape输入以适应Flash Attention的输入格式,以及调用Flash Attention,以及应用输出投影等等Attention计算的细节。
3. Flash Attention单独的调用例子
这里来关注一下使用 flash_attn_varlen_func 这个 api 的单独例子。由于它可以支持多个不同的序列,所以这里我们用2个序列来调用一下,我写了一个测试,脚本如下:
import torch
import math
from flash_attn import flash_attn_varlen_func
# 朴素实现的缩放点积注意力函数
# Efficient implementation equivalent to the following:
def scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False, scale=None) -> torch.Tensor:
# 调整输入张量的维度顺序
query = query.transpose(0, 1) # [nheads, seqlen, headdim]
key = key.transpose(0, 1) # [nheads, seqlen, headdim]
value = value.transpose(0, 1) # [nheads, seqlen, headdim]
L, S = query.size(1), key.size(1)
scale_factor = 1 / math.sqrt(query.size(-1)) if scale is None else scale
attn_bias = torch.zeros(L, S, dtype=query.dtype, device=query.device)
if is_causal:
assert attn_mask is None
temp_mask = torch.ones(L, S, dtype=torch.bool, device=query.device).tril(diagnotallow=0)
attn_bias.masked_fill_(temp_mask.logical_not(), float("-inf"))
attn_bias = attn_bias.to(query.dtype)
if attn_mask is not None:
if attn_mask.dtype == torch.bool:
attn_bias.masked_fill_(attn_mask.logical_not(), float("-inf"))
else:
attn_bias += attn_mask
# 调整注意力计算以适应多头
attn_weight = torch.matmul(query, key.transpose(-2, -1)) * scale_factor # [nheads, L, S]
attn_weight = attn_weight + attn_bias.unsqueeze(0) # 广播 attn_bias 到所有头
attn_weight = torch.softmax(attn_weight, dim=-1)
if dropout_p > 0.0:
attn_weight = torch.nn.functional.dropout(attn_weight, p=dropout_p, training=True)
output = torch.matmul(attn_weight, value) # [nheads, L, headdim]
return output.transpose(0, 1) # 返回 [L, nheads, headdim]
# 设置随机种子以确保结果可复现
torch.manual_seed(0)
# 参数设置
batch_size = 2
seq_lengths = [128, 256] # 两个序列的长度
nheads = 16
headdim = 32
dropout_p = 0.0
causal = True # 是否使用因果性掩码
scale = None # 缩放因子,默认为 1 / sqrt(headdim)
# 为每个序列生成随机的 q, k, v 张量
qs = []
ks = []
vs = []
for seqlen in seq_lengths:
q = torch.randn(seqlen, nheads, headdim, requires_grad=True, dtype=torch.bfloat16, device="cuda") # (L, nheads, headdim)
k = torch.randn(seqlen, nheads, headdim, requires_grad=True, dtype=torch.bfloat16, device="cuda")
v = torch.randn(seqlen, nheads, headdim, requires_grad=True, dtype=torch.bfloat16, device="cuda")
qs.append(q)
ks.append(k)
vs.append(v)
# 将所有序列的 q, k, v 拼接起来
q_total = torch.cat(qs, dim=0) # (total_q, nheads, headdim)
k_total = torch.cat(ks, dim=0)
v_total = torch.cat(vs, dim=0)
# 计算累积序列长度,用于索引
cu_seqlens_q = torch.zeros(batch_size + 1, dtype=torch.int32, device="cuda")
cu_seqlens_q[1:] = torch.cumsum(torch.tensor(seq_lengths, dtype=torch.int32), dim=0)
cu_seqlens_k = cu_seqlens_q.clone()
print('cu_seqlens_q: ', cu_seqlens_q)
# 最大序列长度
max_seqlen_q = max(seq_lengths)
max_seqlen_k = max(seq_lengths)
# 任意传入一个softmax_scale
softmax_scale = 0.2
# 调用 flash_attn_varlen_func 函数
out_flash = flash_attn_varlen_func(
q_total,
k_total,
v_total,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p=dropout_p,
softmax_scale=softmax_scale,
causal=causal,
)
# 使用朴素实现对每个序列进行计算,并将输出拼接起来
outputs_naive = []
for i in range(batch_size):
q = qs[i] # (L_i, nheads, headdim)
k = ks[i]
v = vs[i]
out = scaled_dot_product_attention(
q,
k,
v,
attn_mask=None,
dropout_p=dropout_p,
is_causal=causal,
scale=softmax_scale
) # 输出形状为 (L_i, nheads, headdim)
outputs_naive.append(out)
# 将朴素实现的输出拼接起来
out_naive = torch.cat(outputs_naive, dim=0) # (total_q, nheads, headdim)
print('out_naive st: ', out_naive.flatten()[:10])
print('out_flash st: ', out_flash.flatten()[:10])
print('='*20)
print('out_naive en: ', out_naive.flatten()[-10:])
print('out_flash en: ', out_flash.flatten()[-10:])
# 比较两个实现的输出是否一致
assert torch.allclose(out_flash, out_naive, atol=1e-2), "Outputs do not match!"
print("测试通过")这个测试是可以通过的,相信通过上面2个对上层接口调用的例子可以让我们对Flash Attention的接口调用有比较清晰的认识。下面我们可以关注一下Flash Attention这个借口的实现,我们不需要深入到cuda实现中,只需要把握一下整体的调用逻辑,搞清楚文章开头抛出的问题即可。
4. flash_attn_interface.py中的上层接口
flash-attention 库中使用 cuda 实现了Flash Attention的计算,然后通过 Torch Binding 将varlen_fwd这个接口暴露给Python,而flash_attn_varlen_func则是对varlen_fwd的进一步封装,我们可以在 https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/flash_attn_interface.py 中查看到flash_attn_varlen_func这个接口的实现。去掉了反向相关的逻辑,如下所示:
def _flash_attn_varlen_forward(
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
cu_seqlens_q: torch.Tensor, # Q序列的累积长度
cu_seqlens_k: torch.Tensor, # K序列的累积长度
max_seqlen_q: int, # Q序列的最大长度
max_seqlen_k: int, # K序列的最大长度
dropout_p: float, # dropout概率
softmax_scale: float, # softmax缩放因子
causal: bool, # 是否使用因果掩码
window_size_left: int = -1, # 滑动窗口左侧大小
window_size_right: int = -1, # 滑动窗口右侧大小
softcap: float = 0.0, # softmax的上限值
alibi_slopes: Optional[torch.Tensor] = None, # ALiBi位置编码的斜率
return_softmax: bool = False, # 是否返回softmax结果
block_table: Optional[torch.Tensor] = None, # 分块表
leftpad_k: Optional[torch.Tensor] = None, # K序列左侧填充
seqused_k: Optional[torch.Tensor] = None, # K序列使用的长度
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
# 确保输入张量是连续的内存布局
q, k, v = [maybe_contiguous(x) for x in (q, k, v)]
# 调用CUDA实现的前向传播函数
out, softmax_lse, S_dmask, rng_state = flash_attn_cuda.varlen_fwd(
q, k, v,
None, # 原始掩码矩阵(未使用)
cu_seqlens_q,
cu_seqlens_k,
seqused_k,
leftpad_k,
block_table,
alibi_slopes,
max_seqlen_q,
max_seqlen_k,
dropout_p,
softmax_scale,
False, # 未使用的参数
causal,
window_size_left,
window_size_right,
softcap,
return_softmax,
None, # 随机数生成器状态(未使用)
)
return out, softmax_lse, S_dmask, rng_state
# FlashAttnVarlenQKVPackedFunc类实现了PyTorch的自动微分接口
class FlashAttnVarlenQKVPackedFunc(torch.autograd.Function):
@staticmethod
def forward(
ctx, # 上下文对象,用于保存反向传播需要的信息
qkv, # 打包的QKV张量
cu_seqlens, # 累积序列长度
max_seqlen, # 最大序列长度
dropout_p, # dropout概率
softmax_scale, # softmax缩放因子
causal, # 是否使用因果掩码
window_size, # 滑动窗口大小
softcap, # softmax上限值
alibi_slopes, # ALiBi位置编码斜率
deterministic, # 是否确定性计算
return_softmax, # 是否返回softmax结果
):
# 如果未指定缩放因子,使用默认的1/sqrt(head_dim)
if softmax_scale is None:
softmax_scale = qkv.shape[-1] ** (-0.5)
# 分离Q、K、V并detach,避免建立反向图
q, k, v = qkv[:, 0].detach(), qkv[:, 1].detach(), qkv[:, 2].detach()
# 获取原始head size
head_size_og = q.size(2)
# 如果head size不是8的倍数,进行padding
if head_size_og % 8 != 0:
q = torch.nn.functional.pad(q, [0, 8 - head_size_og % 8])
k = torch.nn.functional.pad(k, [0, 8 - head_size_og % 8])
v = torch.nn.functional.pad(v, [0, 8 - head_size_og % 8])
# 调用前向计算函数
out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_varlen_forward(
q, k, v,
cu_seqlens,
cu_seqlens,
max_seqlen,
max_seqlen,
dropout_p,
softmax_scale,
causal=causal,
window_size_left=window_size[0],
window_size_right=window_size[1],
softcap=softcap,
alibi_slopes=alibi_slopes,
return_softmax=return_softmax and dropout_p > 0,
block_table=None,
)
# 移除padding,恢复原始head size
out = out_padded[..., :head_size_og]
# 根据需要返回softmax结果
return out if not return_softmax else (out, softmax_lse, S_dmask)
def flash_attn_varlen_func(
q,
k,
v,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p=0.0,
softmax_scale=None,
causal=False,
window_size=(-1, -1), # -1 means infinite context window
softcap=0.0, # 0.0 means deactivated
alibi_slopes=None,
deterministic=False,
return_attn_probs=False,
block_table=None,
):
return FlashAttnVarlenFunc.apply(
q,
k,
v,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p,
softmax_scale,
causal,
window_size,
softcap,
alibi_slopes,
deterministic,
return_attn_probs,
block_table,
)上面这段代码清晰展示了 flash_attn_varlen_func 这个接口的调用逻辑,接下来我们就可以去看一下flash_attn_cuda.varlen_fwd这个接口的具体dispatch逻辑了。
5. flash_attn_cuda.varlen_fwd的初步dispatch逻辑
首先来到这里:https://github.com/Dao-AILab/flash-attention/blob/main/csrc/flash_attn/flash_api.cpp#L1518 ,
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.doc() = "FlashAttention";
m.def("fwd", &mha_fwd, "Forward pass");
m.def("varlen_fwd", &mha_varlen_fwd, "Forward pass (variable length)");
m.def("bwd", &mha_bwd, "Backward pass");
m.def("varlen_bwd", &mha_varlen_bwd, "Backward pass (variable length)");
m.def("fwd_kvcache", &mha_fwd_kvcache, "Forward pass, with KV-cache");
}可以发现flash_attn_cuda.varlen_fwd接口对应了mha_varlen_fwd这个c++函数。从这里我们应该就可以看到flash attention forward的dispatch逻辑了。
std::vector<at::Tensor>
mha_varlen_fwd(at::Tensor &q, // total_q x num_heads x head_size, total_q为每个batch中序列长度的总和
const at::Tensor &k, // total_k x num_heads_k x head_size, total_k为每个batch中序列长度的总和,如果有block_table则为num_blocks x page_block_size x num_heads_k x head_size
const at::Tensor &v, // total_k x num_heads_k x head_size, total_k为每个batch中序列长度的总和,如果有block_table则为num_blocks x page_block_size x num_heads_k x head_size
c10::optional<at::Tensor> &out_, // total_q x num_heads x head_size, total_q为每个batch中序列长度的总和
const at::Tensor &cu_seqlens_q, // b+1
const at::Tensor &cu_seqlens_k, // b+1
c10::optional<at::Tensor> &seqused_k, // b。如果提供了该参数,则每个batch元素只使用这么多个key
c10::optional<const at::Tensor> &leftpad_k_, // batch_size
c10::optional<at::Tensor> &block_table_, // batch_size x max_num_blocks_per_seq
c10::optional<at::Tensor> &alibi_slopes_, // num_heads或b x num_heads
int max_seqlen_q,
const int max_seqlen_k,
const float p_dropout,
const float softmax_scale,
const bool zero_tensors,
bool is_causal,
int window_size_left,
int window_size_right,
const float softcap,
const bool return_softmax,
c10::optional<at::Generator> gen_) {
// 获取当前CUDA设备的属性
auto dprops = at::cuda::getCurrentDeviceProperties();
// 检查GPU架构版本
// 判断是否为Ampere(SM8x)架构
bool is_sm8x = dprops->major == 8 && dprops->minor >= 0;
// 判断是否为Hopper(SM90)架构
bool is_sm90 = dprops->major == 9 && dprops->minor == 0;
// 检查GPU架构要求 - 目前只支持Ampere或更新的架构
TORCH_CHECK(is_sm90 || is_sm8x, "FlashAttention only supports Ampere GPUs or newer.");
// 检查输入数据类型
auto q_dtype = q.dtype();
// 只支持fp16和bf16数据类型
TORCH_CHECK(q_dtype == torch::kFloat16 || q_dtype == torch::kBFloat16,
"FlashAttention only support fp16 and bf16 data type");
// bf16只在Ampere及以上架构支持
if (q_dtype == torch::kBFloat16) {
TORCH_CHECK(is_sm90 || is_sm8x, "bfloat16 is only supported on Ampere GPUs or newer");
}
// 检查QKV的数据类型一致性
TORCH_CHECK(k.dtype() == q_dtype, "query and key must have the same dtype");
TORCH_CHECK(v.dtype() == q_dtype, "query and value must have the same dtype");
// 检查序列长度累加和的数据类型为int32
TORCH_CHECK(cu_seqlens_q.dtype() == torch::kInt32, "cu_seqlens_q must have dtype int32");
TORCH_CHECK(cu_seqlens_k.dtype() == torch::kInt32, "cu_seqlens_k must have dtype int32");
// 检查所有输入tensor是否在同一设备上
CHECK_DEVICE(q); CHECK_DEVICE(k); CHECK_DEVICE(v);
CHECK_DEVICE(cu_seqlens_q);
CHECK_DEVICE(cu_seqlens_k);
// 检查分块表相关参数
at::Tensor block_table;
const bool paged_KV = block_table_.has_value(); // 是否使用分页KV缓存
if (paged_KV) {
block_table = block_table_.value();
CHECK_DEVICE(block_table); // 检查设备
TORCH_CHECK(block_table.dtype() == torch::kInt32, "block_table必须是int32类型");
TORCH_CHECK(block_table.stride(-1) == 1, "block_table最后一维必须连续");
}
// 检查QKV张量的内存布局
TORCH_CHECK(q.stride(-1) == 1, "输入张量最后一维必须连续");
TORCH_CHECK(k.stride(-1) == 1, "输入张量最后一维必须连续");
TORCH_CHECK(v.stride(-1) == 1, "输入张量最后一维必须连续");
CHECK_CONTIGUOUS(cu_seqlens_q); // 检查序列长度累加和是否连续
CHECK_CONTIGUOUS(cu_seqlens_k);
const auto sizes = q.sizes(); // 获取Q的形状
// 获取基本参数
const int batch_size = cu_seqlens_q.numel() - 1; // 批次大小
int num_heads = sizes[1]; // Q的注意力头数
const int head_size = sizes[2]; // 每个头的维度
const int num_heads_k = paged_KV ? k.size(2) : k.size(1); // K的注意力头数
// softcap和dropout不能同时使用
if (softcap > 0.f) { TORCH_CHECK(p_dropout == 0.f, "Softcapping暂不支持dropout"); }
// 分页KV缓存相关参数
const int max_num_blocks_per_seq = !paged_KV ? 0 : block_table.size(1); // 每个序列最大块数
const int num_blocks = !paged_KV ? 0 : k.size(0); // 总块数
const int page_block_size = !paged_KV ? 1 : k.size(1); // 每块大小
TORCH_CHECK(!paged_KV || page_block_size % 256 == 0, "分页KV缓存块大小必须是256的倍数");
// 因果掩码和窗口大小相关处理
if (max_seqlen_q == 1 && !alibi_slopes_.has_value()) { is_causal = false; }
if (is_causal) { window_size_right = 0; }
void *cu_seqlens_q_d = cu_seqlens_q.data_ptr();
// 判断是否需要对Q进行重排
// 满足以下条件时需要重排:
// 1. Q序列长度为1(即解码阶段)
// 2. Q的注意力头数大于K的注意力头数(即MQA/GQA场景)
// 3. 不使用滑动窗口(window_size_left和window_size_right都为-1)
// 4. 不使用dropout
// 5. head_size是8的倍数
// 6. 不使用ALiBi位置编码
const int seqlenq_ngroups_swapped = max_seqlen_q == 1 && num_heads > num_heads_k
&& window_size_left < 0 && window_size_right < 0
&& p_dropout == 0.f && head_size % 8 == 0
&& !alibi_slopes_.has_value();
// 计算每个K/V头对应多少个Q头
const int ngroups = num_heads / num_heads_k;
// 如果需要重排
if (seqlenq_ngroups_swapped) {
// 将Q的形状从(batch_size, 1, num_heads_k * ngroups, head_size)
// 重排为(batch_size * ngroups, num_heads_k, head_size)
// 这样可以让同一个K/V头对应的Q头在内存上连续,提高访问效率
q = q.reshape({batch_size, num_heads_k, ngroups, head_size})
.transpose(1, 2)
.reshape({batch_size * ngroups, num_heads_k, head_size});
// 更新相关参数
max_seqlen_q = ngroups; // Q序列长度变为ngroups
num_heads = num_heads_k; // Q的头数变为K的头数
cu_seqlens_q_d = nullptr; // 不再需要Q的序列长度累加和
}
const int total_q = q.sizes()[0]; // Q的总token数
// 检查输入参数的合法性
// 1. batch_size必须为正数
TORCH_CHECK(batch_size > 0, "batch size must be positive");
// 2. head_size必须小于等于256,这是Flash Attention的限制
TORCH_CHECK(head_size <= 256, "FlashAttention forward only supports head dimension at most 256");
// 3. head_size必须是8的倍数,这是为了内存对齐和CUDA优化
TORCH_CHECK(head_size % 8 == 0, "query, key, value, and out_ must have a head_size that is a multiple of 8");
// 4. Q的head数必须是K/V的head数的整数倍,这是为了支持MQA/GQA
TORCH_CHECK(num_heads % num_heads_k == 0, "Number of heads in key/value must divide number of heads in query");
// 如果滑动窗口大小超过了K序列的最大长度,则设置为-1表示不使用滑动窗口
if (window_size_left >= max_seqlen_k) { window_size_left = -1; }
if (window_size_right >= max_seqlen_k) { window_size_right = -1; }
// 检查Q张量的形状是否正确: [total_q, num_heads, head_size]
CHECK_SHAPE(q, total_q, num_heads, head_size);
// 根据是否使用分页KV缓存来检查K/V张量的形状
if (!paged_KV) {
// 不使用分页KV缓存时,K/V的形状应为[total_k, num_heads_k, head_size]
const int total_k = k.size(0);
CHECK_SHAPE(k, total_k, num_heads_k, head_size);
CHECK_SHAPE(v, total_k, num_heads_k, head_size);
} else {
// 使用分页KV缓存时,K/V的形状应为[num_blocks, page_block_size, num_heads_k, head_size]
// block_table的形状应为[batch_size, max_num_blocks_per_seq]
CHECK_SHAPE(k, num_blocks, page_block_size, num_heads_k, head_size);
CHECK_SHAPE(v, num_blocks, page_block_size, num_heads_k, head_size);
CHECK_SHAPE(block_table, batch_size, max_num_blocks_per_seq);
}
// 检查序列长度累加和张量的形状,应为[batch_size + 1]
CHECK_SHAPE(cu_seqlens_q, batch_size + 1);
CHECK_SHAPE(cu_seqlens_k, batch_size + 1);
// 如果提供了K序列使用长度的信息,检查其属性
if (seqused_k.has_value()){
auto seqused_k_ = seqused_k.value();
// 数据类型必须是int32
TORCH_CHECK(seqused_k_.dtype() == torch::kInt32, "seqused_k must have dtype int32");
// 必须在CUDA设备上
TORCH_CHECK(seqused_k_.is_cuda(), "seqused_k must be on CUDA device");
// 必须是连续的内存布局
TORCH_CHECK(seqused_k_.is_contiguous(), "seqused_k must be contiguous");
// 形状必须是[batch_size]
CHECK_SHAPE(seqused_k_, batch_size);
}
// 创建输出张量
at::Tensor out;
// 如果提供了输出张量
if (out_.has_value()) {
out = out_.value();
// 检查输出张量的属性:
// 1. 数据类型必须与输入相同
TORCH_CHECK(out.dtype() == q_dtype, "Output must have the same dtype as inputs");
// 2. 必须在同一设备上
CHECK_DEVICE(out);
// 3. 最后一维必须是连续的
TORCH_CHECK(out.stride(-1) == 1, "Output tensor must have contiguous last dimension");
// 4. 形状必须正确
CHECK_SHAPE(out, sizes[0], sizes[1], head_size);
// 如果序列长度和组数需要交换
if (seqlenq_ngroups_swapped) {
// 重塑张量维度并转置,用于处理分组注意力
out = out.reshape({batch_size, num_heads_k, ngroups, head_size})
.transpose(1, 2)
.reshape({batch_size * ngroups, num_heads_k, head_size});
}
} else {
// 如果没有提供输出张量,创建一个与输入形状相同的空张量
out = torch::empty_like(q);
}
// 定义一个lambda函数,用于将数字向上取整到m的倍数
auto round_multiple = [](int x, int m) { return (x + m - 1) / m * m; };
// 计算head_size的对齐值:
// - 如果head_size <= 192,向上取整到32的倍数
// - 否则设为256
const int head_size_rounded = head_size <= 192 ? round_multiple(head_size, 32) : 256;
// 将Q序列长度向上取整到128的倍数
const int seqlen_q_rounded = round_multiple(max_seqlen_q, 128);
// 将K序列长度向上取整到128的倍数
const int seqlen_k_rounded = round_multiple(max_seqlen_k, 128);
// 设置CUDA设备,确保在正确的GPU上执行
at::cuda::CUDAGuard device_guard{(char)q.get_device()};
// 获取输入张量q的选项(设备、数据类型等)
auto opts = q.options();
// 创建softmax_lse张量,用于存储每个注意力头的log-sum-exp值
auto softmax_lse = torch::empty({num_heads, total_q}, opts.dtype(at::kFloat));
at::Tensor p;
// 只有在有dropout时才返回softmax结果,以减少编译时间
if (return_softmax) {
// 确保dropout概率大于0
TORCH_CHECK(p_dropout > 0.0f, "return_softmax is only supported when p_dropout > 0.0");
// 创建p张量存储softmax结果
p = torch::empty({ batch_size, num_heads, seqlen_q_rounded, seqlen_k_rounded }, opts);
}
else {
// 如果不需要返回softmax,创建一个空张量
p = torch::empty({ 0 }, opts);
}
// 如果需要将张量初始化为0
if (zero_tensors) {
out.zero_(); // 输出张量置0
softmax_lse.fill_(-std::numeric_limits<float>::infinity()); // softmax_lse填充负无穷
if (return_softmax) {p.zero_();} // softmax结果张量置0
}
// 创建前向传播参数结构体
Flash_fwd_params params;
// 设置前向传播的各项参数
set_params_fprop(params,
batch_size,
max_seqlen_q, max_seqlen_k,
seqlen_q_rounded, seqlen_k_rounded,
num_heads, num_heads_k,
head_size, head_size_rounded,
q, k, v, out,
cu_seqlens_q_d,
cu_seqlens_k.data_ptr(),
seqused_k.has_value() ? seqused_k.value().data_ptr() : nullptr,
return_softmax ? p.data_ptr() : nullptr,
softmax_lse.data_ptr(),
p_dropout,
softmax_scale,
window_size_left,
window_size_right,
softcap,
seqlenq_ngroups_swapped,
/*unpadded_lse*/true);
params.total_q = total_q;
// 如果使用分页KV缓存
if (paged_KV) {
params.block_table = block_table.data_ptr<int>(); // 设置分块表指针
params.block_table_batch_stride = block_table.stride(0); // 设置分块表的batch步长
params.k_batch_stride = k.stride(0); // 设置K的batch步长
params.v_batch_stride = v.stride(0); // 设置V的batch步长
}
params.page_block_size = page_block_size; // 设置页块大小
// 保持对这些张量的引用以延长其生命周期
at::Tensor softmax_lse_accum, out_accum;
if (seqlenq_ngroups_swapped) {
// 仅在解码时应用split-k
std::tie(softmax_lse_accum, out_accum) =
set_params_splitkv(params, batch_size, num_heads, head_size,
max_seqlen_k, max_seqlen_q, head_size_rounded,
p_dropout, /*num_splits*/ 0, dprops, opts);
}
// 如果提供了K序列的左侧填充信息
if (leftpad_k_.has_value()) {
auto leftpad_k = leftpad_k_.value();
// 检查:不能同时使用分页KV和左侧填充
TORCH_CHECK(!paged_KV, "We don't support Paged KV and leftpad_k running at the same time yet");
// 检查数据类型必须是int32
TORCH_CHECK(leftpad_k.dtype() == torch::kInt32, "leftpad_k must have dtype int32");
CHECK_DEVICE(leftpad_k); // 检查设备
CHECK_CONTIGUOUS(leftpad_k); // 检查连续性
CHECK_SHAPE(leftpad_k, batch_size); // 检查形状
params.leftpad_k = static_cast<int *>(leftpad_k.data_ptr()); // 设置左侧填充指针
}
// 为每个线程生成随机数的次数,用于偏移THC随机状态中的philox计数器
// 我们使用自定义的RNG,将偏移量增加batch_size * num_heads * 32
int64_t counter_offset = params.b * params.h * 32;
// 创建一个CUDA上的float32类型的张量选项
auto options = torch::TensorOptions().dtype(torch::kFloat32).device(torch::kCUDA);
// 创建一个大小为2的int64类型的空张量,用于存储RNG状态
auto rng_state = torch::empty({2}, options.dtype(torch::kInt64));
// 前向传播kernel将用种子和偏移量填充内存
params.rng_state = reinterpret_cast<uint64_t*>(rng_state.data_ptr());
// 如果设置了dropout
if (p_dropout > 0.0) {
// 获取默认的CUDA生成器或使用提供的生成器
auto gen = at::get_generator_or_default<at::CUDAGeneratorImpl>(
gen_, at::cuda::detail::getDefaultCUDAGenerator());
// 使用互斥锁保护随机数生成器的访问
std::lock_guard<std::mutex> lock(gen->mutex_);
// 设置philox随机数生成器的状态
params.philox_args = gen->philox_cuda_state(counter_offset);
}
// 设置ALiBi(Attention with Linear Biases)的参数
set_params_alibi(params, alibi_slopes_, batch_size, num_heads);
// 如果K序列长度大于0,执行前向传播
if (max_seqlen_k > 0) {
// 获取当前CUDA流
auto stream = at::cuda::getCurrentCUDAStream().stream();
// 运行前向传播kernel
run_mha_fwd(params, stream, paged_KV);
} else {
// 如果K序列长度为0,说明是空张量,需要将输出置零
out.zero_();
// 将softmax的对数和填充为负无穷
softmax_lse.fill_(std::numeric_limits<float>::infinity());
}
// 如果进行了序列长度和组数的交换
if (seqlenq_ngroups_swapped) {
// 定义reshape前后的维度大小
int64_t size_before[] = {batch_size, max_seqlen_q, num_heads_k, head_size};
int64_t size_after[] = {batch_size, num_heads_k * max_seqlen_q, head_size};
// 重新排列输出张量的维度
out = out.reshape(size_before).transpose(1, 2).reshape(size_after);
q = q.reshape(size_before).transpose(1, 2).reshape(size_after);
// 重新排列softmax对数和的维度
softmax_lse = softmax_lse.reshape({num_heads * max_seqlen_q, batch_size});
}
// 返回输出张量、softmax对数和、注意力分布(如果需要)和RNG状态
return {out, softmax_lse, p, rng_state};
}由于Flash Attention的准备工作比较多,上面的代码很长,我们主要关注
if (seqlenq_ngroups_swapped) {
// 仅在解码时应用split-k
std::tie(softmax_lse_accum, out_accum) =
set_params_splitkv(params, batch_size, num_heads, head_size,
max_seqlen_k, max_seqlen_q, head_size_rounded,
p_dropout, /*num_splits*/ 0, dprops, opts);
}和
if (max_seqlen_k > 0) {
// 获取当前CUDA流
auto stream = at::cuda::getCurrentCUDAStream().stream();
// 运行前向传播kernel
run_mha_fwd(params, stream, paged_KV);
}这几行代码即可,set_params_splitkv决定了是否使用split-k以及要在kv的序列纬度上切分多少次,run_mha_fwd会根据set_params_splitkv的配置以及在上面的函数中其它部分设置的params的参数来dispatch不同的kernel。现在来看一下set_params_splitkv的实现:
std::tuple<at::Tensor, at::Tensor> set_params_splitkv(Flash_fwd_params ¶ms, const int batch_size,
const int num_heads, const int head_size, const int max_seqlen_k, const int max_seqlen_q,
const int head_size_rounded, const float p_dropout,
const int num_splits, cudaDeviceProp *dprops, struct c10::TensorOptions opts) {
// 这里的block_n需要和run_mha_fwd_splitkv_dispatch中的配置匹配
// 根据head_size的大小选择不同的block_n:
// - head_size <= 64: block_n = 256
// - 64 < head_size <= 128: block_n = 128
// - head_size > 128: block_n = 64
const int block_n = head_size <= 64 ? 256 : (head_size <= 128 ? 128 : 64);
// 计算在K序列维度上需要多少个block
const int num_n_blocks = (max_seqlen_k + block_n - 1) / block_n;
// 对于splitKV kernel,kBlockM固定为64
// 一般在推理时Q序列长度不会超过64
const int num_m_blocks = (max_seqlen_q + 64 - 1) / 64;
// 设置切分数量
params.num_splits = num_splits;
// 声明用于存储中间结果的tensor
at::Tensor softmax_lse_accum;
at::Tensor out_accum;
// splitKV目前不支持dropout
if (p_dropout == 0.0f) {
if (num_splits < 1) {
// 如果num_splits < 1,则使用启发式方法计算切分数量
// 这里乘以2是因为每个block使用128个线程
params.num_splits = num_splits_heuristic(batch_size * num_heads * num_m_blocks,
dprops->multiProcessorCount * 2,
num_n_blocks, 128);
}
// 如果需要切分(num_splits > 1)
if (params.num_splits > 1) {
// 分配存储中间结果的tensor
softmax_lse_accum = torch::empty({params.num_splits, batch_size, num_heads, max_seqlen_q},
opts.dtype(at::kFloat));
out_accum = torch::empty({params.num_splits, batch_size, num_heads, max_seqlen_q, head_size_rounded},
opts.dtype(at::kFloat));
// 设置指向中间结果的指针
params.softmax_lseaccum_ptr = softmax_lse_accum.data_ptr();
params.oaccum_ptr = out_accum.data_ptr();
}
// 切分数量不能超过128
TORCH_CHECK(params.num_splits <= 128, "num_splits > 128 not supported");
}
return std::make_tuple(softmax_lse_accum, out_accum);
}由于调用set_params_splitkv时设置了num_splits=0所以上面的代码会进入到启发式计算切分数量的逻辑中,启发式计算切分数量的逻辑在num_splits_heuristic中,我们来看一下这个函数的实现:
// 这个函数用于找到最大化 GPU 占用率的切分数量。
// 例如,如果 batch * n_heads = 48,且有 108 个 SM,那么:
// - 使用 2 个切分(效率 = 0.89)比使用 3 个切分(效率 = 0.67)更好
// 但是我们也不希望切分太多,因为这会导致更多的 HBM 读写。
// 所以我们先找到最佳效率,然后找到能达到最佳效率 85% 的最小切分数量。
inline int num_splits_heuristic(int batch_nheads_mblocks, int num_SMs, int num_n_blocks, int max_splits) {
// 如果当前 batch_nheads_mblocks 已经能填充 80% 的 SM,就不需要切分了
if (batch_nheads_mblocks >= 0.8f * num_SMs) { return 1; }
// 取 max_splits、SM数量和 n_blocks 三者的最小值作为最大切分数量
max_splits = std::min({max_splits, num_SMs, num_n_blocks});
float max_efficiency = 0.f;
std::vector<float> efficiency;
efficiency.reserve(max_splits);
// 向上取整除法
auto ceildiv = [](int a, int b) { return (a + b - 1) / b; };
// 有些切分数量是无效的。例如,如果我们有 64 个 blocks:
// - 选择 11 个切分,我们会有 6 * 10 + 4 个 blocks
// - 选择 12 个切分,我们会有 6 * 11 + (-2) 个 blocks(实际上还是 11 个切分)
// 所以我们需要检查每个切分的 block 数量是否与前一个切分数量相同
auto is_split_eligible = [&ceildiv, &num_n_blocks](int num_splits) {
return num_splits == 1 || ceildiv(num_n_blocks, num_splits) != ceildiv(num_n_blocks, num_splits - 1);
};
// 第一轮循环:计算每个切分数量的效率,并找到最大效率
for (int num_splits = 1; num_splits <= max_splits; num_splits++) {
if (!is_split_eligible(num_splits)) {
efficiency.push_back(0.f);
} else {
// n_waves 表示每个 SM 平均需要处理多少波 blocks
float n_waves = float(batch_nheads_mblocks * num_splits) / num_SMs;
// 效率 = 理论处理时间 / 实际处理时间
float eff = n_waves / ceil(n_waves);
if (eff > max_efficiency) { max_efficiency = eff; }
efficiency.push_back(eff);
}
}
// 第二轮循环:找到能达到最佳效率 85% 的最小切分数量
for (int num_splits = 1; num_splits <= max_splits; num_splits++) {
if (!is_split_eligible(num_splits)) { continue; }
if (efficiency[num_splits - 1] >= 0.85 * max_efficiency) {
return num_splits;
}
}
return 1;
}从上面的代码我们就可以看出来影响splitkv的参数不仅有max_seqlen_k,head_num,还有SM个数等等。对于文章开头的例子,head_num和SM个数是固定的,但由于max_new_tokens从512变成64引起了max_seqlen_k的改变从而导致了num_splits的改变,最终表现为我们在max_new_tokens为512的nsys中观察到了decoding时使用了splitkv的flash attention实现,而在max_new_tokens为64的nsys中则没有使用splitkv的flash attention实现。run_mha_fwd的dispatch逻辑为:
void run_mha_fwd(Flash_fwd_params ¶ms, cudaStream_t stream, bool force_split_kernel=false) {
FP16_SWITCH(!params.is_bf16, [&] {
HEADDIM_SWITCH(params.d, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
if (params.num_splits <= 1 && !force_split_kernel) { // If we don't set it num_splits == 0
run_mha_fwd_<elem_type, kHeadDim, Is_causal>(params, stream);
} else {
run_mha_fwd_splitkv_dispatch<elem_type, kHeadDim, Is_causal>(params, stream);
}
});
});
});
}可以看到这里对num_splits进行判断,如果num_splits <= 1且没有设置force_split_kernel则dispatch不使用splitkv的kernel,否则dispatch使用splitkv的kernel。flash_attn_cuda.varlen_fwd的初步dispatch逻辑就梳理完了,不过我们从文章开头的nsys可以看到调用splitkv实现的时候每个decoding step的每个Attenion计算都有2个kernel:



在KV的seq纬度切分之后还需要把单独计算的结果组合成最终的计算结果,这就是flash_fwd_splitkv_combine_kernel的作用。实际上这个也被叫作Flash Decoding,你可以参考https://mp.weixin.qq.com/s/hvqPhNo3l0tL_-lf978euw 这里的介绍。
5. run_mha_fwd_splitkv_dispatch的上层实现逻辑
template<typename Kernel_traits, bool Is_causal>
void run_flash_splitkv_fwd(Flash_fwd_params ¶ms, cudaStream_t stream) {
// 确保kernel特征不支持Q在寄存器中和Q/K共享共享内存
static_assert(!Kernel_traits::Is_Q_in_regs, "SplitKV implementation does not support Is_Q_in_regs");
static_assert(!Kernel_traits::Share_Q_K_smem, "SplitKV implementation does not support Share_Q_K_smem");
// 获取共享内存大小
constexpr size_t smem_size = Kernel_traits::kSmemSize;
// 计算M维度的block数量
const int num_m_block = (params.seqlen_q + Kernel_traits::kBlockM - 1) / Kernel_traits::kBlockM;
// 设置grid维度:
// x: M维度的block数
// y: 如果有splits则为splits数量,否则为batch size
// z: 如果有splits则为batch*heads,否则为heads数量
dim3 grid(num_m_block, params.num_splits > 1 ? params.num_splits : params.b, params.num_splits > 1 ? params.b * params.h : params.h);
// 判断序列长度是否能被block大小整除
const bool is_even_MN = params.cu_seqlens_q == nullptr && params.cu_seqlens_k == nullptr && params.seqlen_k % Kernel_traits::kBlockN == 0 && params.seqlen_q % Kernel_traits::kBlockM == 0;
// 判断head维度是否匹配
const bool is_even_K = params.d == Kernel_traits::kHeadDim;
// 使用一系列宏来根据不同条件选择不同的kernel实现
BOOL_SWITCH(is_even_MN, IsEvenMNConst, [&] {
EVENK_SWITCH(is_even_K, IsEvenKConst, [&] {
LOCAL_SWITCH((params.window_size_left >= 0 || params.window_size_right >= 0) && !Is_causal, Is_local, [&] {
BOOL_SWITCH(params.num_splits > 1, Split, [&] {
BOOL_SWITCH(params.knew_ptr != nullptr, Append_KV, [&] {
ALIBI_SWITCH(params.alibi_slopes_ptr != nullptr, Has_alibi, [&] {
SOFTCAP_SWITCH(params.softcap > 0.0, Is_softcap, [&] {
// 选择合适的kernel实现
auto kernel = &flash_fwd_splitkv_kernel<Kernel_traits, Is_causal, Is_local && !Is_causal, Has_alibi, IsEvenMNConst && !Append_KV && IsEvenKConst && !Is_local && Kernel_traits::kHeadDim <= 128, IsEvenKConst, Is_softcap, Split, Append_KV>;
// 如果共享内存超过48KB,需要设置属性
if (smem_size >= 48 * 1024) {
C10_CUDA_CHECK(cudaFuncSetAttribute(
kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));
}
// 启动kernel
kernel<<<grid, Kernel_traits::kNThreads, smem_size, stream>>>(params);
C10_CUDA_KERNEL_LAUNCH_CHECK();
});
});
});
});
});
});
});
// 如果有splits,需要启动combine kernel来合并结果
if (params.num_splits > 1) {
// 根据head维度选择合适的block大小
constexpr static int kBlockM = Kernel_traits::kHeadDim % 128 == 0 ? 4 : (Kernel_traits::kHeadDim % 64 == 0 ? 8 : 16);
dim3 grid_combine((params.b * params.h * params.seqlen_q + kBlockM - 1) / kBlockM);
// 根据splits数量选择合适的combine kernel
EVENK_SWITCH(is_even_K, IsEvenKConst, [&] {
if (params.num_splits <= 2) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 1, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 4) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 2, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 8) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 3, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 16) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 4, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 32) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 5, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 64) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 6, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 128) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 7, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
}
C10_CUDA_KERNEL_LAUNCH_CHECK();
});
}
}
// 根据head维度选择合适的block大小并调用run_flash_splitkv_fwd
template<typename T, int Headdim, bool Is_causal>
void run_mha_fwd_splitkv_dispatch(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int kBlockM = 64; // 固定M维度的block大小为64
// 根据head维度选择N维度的block大小:
// head维度<=64: 256
// head维度<=128: 128
// 其他: 64
constexpr static int kBlockN = Headdim <= 64 ? 256 : (Headdim <= 128 ? 128 : 64);
run_flash_splitkv_fwd<Flash_fwd_kernel_traits<Headdim, kBlockM, kBlockN, 4, false, false, T>, Is_causal>(params, stream);
}我们可以看到无论是在序列维度切分计算的flash_fwd_split_kv_kernel还是最后合并结果的flash_fwd_splitkv_combine_kernel,他们都有非常多的模板来决定当前的输入下应该使用哪种kernel来获得最佳性能。如果你对这里的cuda实现感兴趣可以自行阅读源码学习或者修改。
6. 总结
本文主要探讨了Flash Attention在不同场景下的kernel dispatch逻辑,特别关注了decode阶段使用split_kv实现的触发条件。通过分析源码发现,Flash Attention的dispatch逻辑主要由max_seqlen_k(K序列的最大长度)、head_num(注意力头数)、SM数量(GPU的流处理器数量)等因素决定。这些因素会通过启发式函数num_splits_heuristic来计算num_splits(KV序列维度的切分数量),该函数的目标是找到能最大化GPU利用率的切分数量。当计算得到num_splits > 1时,会使用split_kv实现,这种实现会启动两个kernel:flash_fwd_splitkv_kernel用于在KV序列维度上进行切分计算,flash_fwd_splitkv_combine_kernel用于合并各个切分的计算结果。这就解释了文章开头的例子中,当max_new_tokens=512时由于序列长度较长导致num_splits > 1而使用split_kv实现,而max_new_tokens=64时由于序列长度较短导致num_splits <= 1而使用普通实现的现象。这种灵活的dispatch机制设计使得Flash Attention能够在不同场景下都获得较好的性能表现:在长序列场景下通过split_kv更好地利用GPU资源,在短序列场景下避免不必要的开销。
#了解X-Ray点料机原理与应用
XRAY自动点料机是一种利用X射线成像技术来实现对电子元件数量进行自动计数的设备。这种技术在SMT(Surface Mount Technology,表面贴装技术)行业特别有用,因为它可以快速准确地计算出料盘或料箱中的元件数量,从而提高生产效率并减少人为错误。
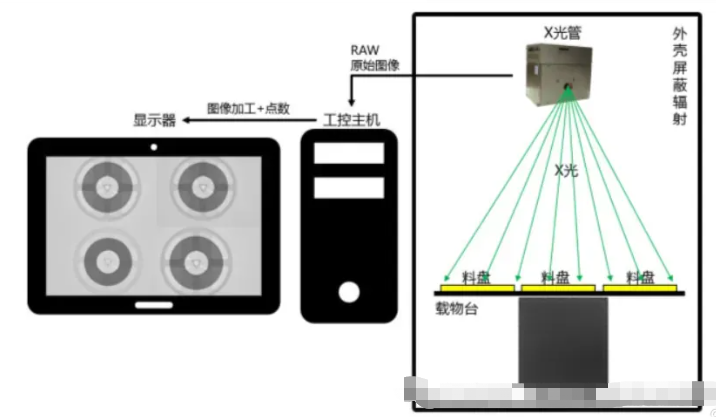
设备组成
- X射线源:这是产生X射线的核心部件,通常包括X射线管和高压发生器。X射线管通过高速电子撞击阳极靶材产生X射线。
- 探测器:探测器将X射线转换为电信号,常见的有平板探测器和平行板探测器等。探测器需要具有高灵敏度和良好的分辨率,以便捕捉到微小的细节。
- 运动系统:包括承载物料的平台、平移机构和旋转机构,确保物料能够在X射线扫描过程中平稳移动。
- 控制系统:由计算机硬件和专用软件组成,负责控制整个系统的运行流程,包括X射线发射的时间、探测器读取数据的频率、运动系统的动作等。
- 图像处理与分析系统:该系统负责从探测器获取的数据进行处理,提取有用的特征信息,并进行分析,最终输出结果。
原理
当物料放置在XRAY自动点料机的工作台上时,系统会启动X射线源,发射X射线穿过物料。由于不同材料对X射线的吸收程度不同,穿过物料后的X射线强度会在探测器上形成不同的影像。图像处理系统会对这些影像进行处理,通过对比背景和目标物之间的灰度差异,识别出物料的轮廓、大小、形状等特征,进而计算出物料的数量。
应用
- 电子制造业:主要用于SMT生产线上的元件管理,如IC芯片、电阻、电容等的自动计数。
- 质量控制:确保包装中的元件数量正确无误,防止因数量不足而产生的生产问题。
- 制药行业:用于药物胶囊、片剂等的计数。
- 珠宝行业:用于细小宝石或贵金属颗粒的计数。
- 航空航天:用于精密零部件的检验和计数。
- 科研领域:作为研究工具,帮助科学家们分析材料内部结构。
算法
为了提高计数精度,XRAY自动点料机通常会采用多种算法相结合的方法:
- 图像预处理:包括噪声去除、图像增强等步骤,确保后续处理的准确性。
- 分割算法:将目标物与背景分开,常用的方法有阈值分割、区域生长等。
- 边缘检测:使用Canny、Sobel等边缘检测算子,帮助识别元件的边界。
- 特征提取:从图像中提取出元件的关键特征,如尺寸、形状等。
- 模式识别:通过支持向量机(SVM)、深度学习等技术,识别元件种类,并结合特征提取的结果计算数量。
- 校正与验证:对计数结果进行校正,确保结果的可靠性。

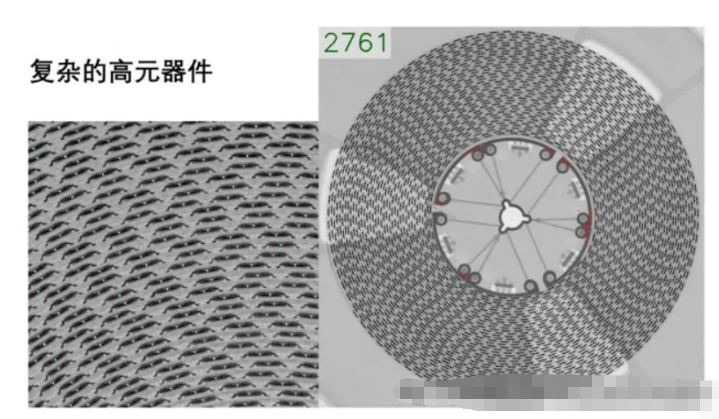

通过这些技术和算法的应用,XRAY自动点料机可以在短时间内完成大量元件的清点工作,大大提高了工作效率,并且减少了由于人工操作带来的误差。
#VL4AD
让语义分割认识未知类别,无需额外数据和训练的OOD语义分割
本文提出了一种无需额外数据和训练即可识别未知类别的语义分割方法,通过结合视觉-语言模型和新的评分函数来提高对离群样本的检测能力。
论文地址:https://arxiv.org/abs/2409.17330
创新性
- 提出VL4AD模型用于解决语义分割网络难以检测来自未知语义类别的异常的问题,避免额外的数据收集和模型训练。
- VL4AD将视觉-语言(VL)编码器纳入现有的异常检测器,利用语义广泛的VL预训练来增强对离群样本的感知,还加入max-logit提示集成和类别合并策略用于丰富类别描述。
- 提出了一种新的评分函数,可通过文本提示实现无数据和无训练的离群样本监督。
VL4AD视觉文本编码器

视觉编码器 是与文本编码器 共同预训练, 解码器 处理多尺度的视觉和文本嵌入,生成两种类型的输出:掩码预测分数 和掩码分类分数 , 其中 表示对象查询的数量。
对象查询是可学习的嵌入,类似于目标检测网络中的先验框。掩码预测分数以类别无关的方式识别物体,而掩码分类分数计算掩码属于特定语义类别的概率。
基于编码后的视觉嵌入 和 ID 类别文本嵌入 之间的余弦相似性计算掩码分类分数:

在架构上, 和 , 以及 和 是相当相似的, 区别在于 在预训练后保持不变, 仅对视觉-语言解码器 进行微调。通过这种方式, 将零样本 CLIP 在图像级别的竞争性 00 D 检测性能转移到像素级任务中。
Max-Logit提示集成于类合并
优化ID类文本嵌入可以使其更好地与相应的ID视觉嵌入对齐,提高ID和OOD类别之间的可分离性,但盲目地微调文本编码器可能导致灾难性遗忘。
为此,论文通过max-logit提示集成在文本提示中引入概念词汇多样性和具体化,显著提高模型对OOD输入的敏感性。词汇多样性包括同义词和复数形式,而具体化涉及更好地与CLIP预训练对齐的分解概念。例如,使用概念{vegetation, tree, trees, palm tree, bushes}来表示类vegetation。
max-logit 集成考虑给定类 的所有替代概念,替换内容为视觉嵌入 与所有 个替代文本嵌入 的最大余弦相似度:

此外,单靠在类维度上的最大像素级得分可能导致次优性能,因为在两个ID类之间的边缘像素的不确定性较高,尤其是当类别数量增加时。
为了解决这个问题,将相关的ID类合并为超类。通过在测试期间将各个语义类的文本提示作为不同的替代概念连接到超类中来实现,而无需重新训练。然后,可以使用max-logit方法获得超类的不确定性。
通过OOD提示实现无数据、无训练异常监督
通过视觉-语言预训练,通常能够很好地检测到与ID类不同的语义OOD类(远OOD类)。但当OOD类与ID类非常相似的情况(近OOD类),则更具挑战性。例如,在CityScapes类别中,OOD类大篷车在城市驾驶场景中可能在视觉上与ID类卡车相似。
利用视觉-语言模型的开放词汇能力,论文引入了一种新的评分函数,旨在更好地检测这些近OOD类,而不需要额外的训练或数据准备。
为了在测试时整合 个新的 000 概念, 需要通过 个额外的项 扩展公式1中的掩码分类得分 。遵循公式 2, 即通过将 的前 个通道与掩码预测得分 进行组合,获得最终的不确定性得分 :

通过这一整合, 类中的 000 对象将(在大多数情况下)正确分配到其相应的类别。如果没有这一整合, 它们可能会被错误地分配到与其实际 OOD 类别相似的 ID 类。相反, 如果输入中不存在 00D 对象, 额外的 类的影响将保持微不足道。
主要实验

#所有数据集上给神经网络刷分的通用方法
本文介绍了几种在神经网络上普遍有效的刷分技巧,包括对抗训练、EMA(指数滑动平均)、TTA(测试时数据增强)、伪标签学习和特定样本处理。这些方法简单易用,且在多数数据集上都能提升模型性能。
背景
(本号原创开启日更模式了)事情的起因其实这样,实验室老同学的论文要冲分,问我有没有啥在NN上,基本都有用的刷点方法,最好是就是短小精悍,代码量不大,不需要怎么调参。
一般通用的trick都被写进论文和代码库里了,
像优秀的优化器,学习率调度方法,数据增强,dropout,初始化,BN,LN,确实是调参大师的宝贵经验,大家平常用的也很多。
除了这些,天底下还有这样的好事?
确实有一些这样的方法的,他们通用,简单。根据我的经验,在大多数的数据上都有效。
一、对抗训练
第一个,对抗训练。
对抗训练就是在输入的层次增加扰动,根据扰动产生的样本,来做一次反向传播。以FGM为例,在NLP上,扰动作用于embedding层。
给个即插即用代码片段吧,引用了知乎id:Nicolas的代码,写的不错,带着看原理很容易就明白了。
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()具体FGM的实现
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilnotallow=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}二、EMA
第二个,EMA(指数滑动平均)
移动平均,保存历史的一份参数,在一定训练阶段后,拿历史的参数给目前学习的参数做一次平滑。这个东西,我之前在earhian的祖传代码里看到的。他喜欢这东西+衰减学习率。确实每次都有用。
代码引用博客:https://fyubang.com/2019/06/01/ema/
# 初始化
ema = EMA(model, 0.999)
ema.register()
# 训练过程中,更新完参数后,同步update shadow weights
def train():
optimizer.step()
ema.update()
# eval前,apply shadow weights;eval之后,恢复原来模型的参数
def evaluate():
ema.apply_shadow()
# evaluate
ema.restore()具体EMA实现,即插即用:
class EMA():
def __init__(self, model, decay):
self.model = model
self.decay = decay
self.shadow = {}
self.backup = {}
def register(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.shadow[name] = param.data.clone()
def update(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()
def apply_shadow(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
self.backup[name] = param.data
param.data = self.shadow[name]
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}三、TTA
第三个,TTA。
这个一句话说明白,测试时候构造靠谱的数据增强,简单一点的数据增强方式比较好,然后把预测结果加起来算个平均。
这个实现实在是比较简单,就不贴代码了。
四、伪标签
第四个,伪标签学习。
这个也一句话说明白,就是用训练的模型,把测试数据,或者没有标签的数据,推断一遍。构成伪标签,然后拿回去训练。注意不要leak。
下面那个老图,比较形象。
五、特定样本处理
第五个,特定样本处理。
说这个通用勉强一点,但确实在这类数据上基本都有效。
就是小样本,长尾样本,或者模型不太有把握的样本。把分类过程为根据特征检索的过程。
用向量表征去查找最近邻样本。这块,有个ICLR2020的文章写的比较好,facebook的老哥把几种典型的方法整理了一下,具体可以参考:https://arxiv.org/abs/1910.09217
#DTNet
动态网络!同一个模型走不同路径,就能生成不同的图像描述结果!
本文探讨了一种用于视觉和语言任务的新型动态网络,其中推理结构针对不同的输入动态定制。之前大多数最先进的方法都是静态的和手工制作的网络,它们不仅严重依赖于专家知识,而且忽略了输入样本的语义多样性,因此导致性能不佳。
为了解决这些问题,我们提出了一种用于图像字幕的新型Dynamic Transformer Network (DTNet),它为不同的样本动态分配定制的路径,从而产生具有辨别力且准确的字幕。
具体而言,为了构建丰富的路由空间并提高路由效率,我们引入了五种基本单元,并根据其操作域即空间和通道将它们分组到两个单独的路由空间中。然后,我们设计了一个Spatial-Channel Joint Router (SCJR),它使模型能够根据输入样本的空间和通道信息进行路径定制。
为了验证我们提出的 DTNet 的有效性,我们在 MS-COCO 数据集上进行了大量实验,并在 Karpathy 分割和在线测试服务器上都取得了新的最先进的性能。
- 论文:https://arxiv.org/abs/2406.00334
- 源代码:https://github.com/xmu-xiaoma666/DTNet
- 索引词:图像字幕,输入敏感,动态网络,Transformer
@ARTICLE{ma2024image,
author={Ma, Yiwei and Ji, Jiayi and Sun, Xiaoshuai and Zhou, Yiyi and Hong, Xiaopeng and Wu, Yongjian and Ji, Rongrong},
journal={IEEE Transactions on Neural Networks and Learning Systems},
title={Image Captioning via Dynamic Path Customization},
year={2024},
volume={},
number={},
pages={1-15},
keywords={Routing;Visualization;Transformers;Adaptation models;Task analysis;Feature extraction;Semantics;Dynamic network;image captioning;input-sensitive;transformer},
doi={10.1109/TNNLS.2024.3409354}}介绍
图像字幕旨在生成一个自然语言句子来描述给定的图像,是视觉和语言 (V&L) 研究中最基本但最具挑战性的任务之一。近年来,随着一系列创新方法的出现[1, 2, 3, 4, 5, 6, 7, 8],图像字幕得到了快速发展。
然而,最近大多数用于图像字幕的架构[9, 10, 11, 12, 13, 14, 15, 11]都是静态的,所有输入样本都通过相同的路径,尽管它们的外观差异和语义多样性很大。这种静态架构有两个局限性:1) 静态网络无法根据输入样本调整其架构,因此缺乏灵活性和辨别力。如图 1 (a) 所示,由于模型容量的限制,当输入语义相似的图像时,静态模型往往会忽略细节并生成相同的句子,这一点在之前的工作 [16, 17, 12] 中也有提及。值得注意的是,这种使用静态网络的“安全”字幕模式严重阻碍了为图像生成信息丰富且描述性的句子。2) 这种静态网络的设计严重依赖于开发人员和用户的专业知识和经验反馈。

图 1: Vanilla Transformer (静态) 和我们的 DTNet (动态) 的说明。不同颜色的圆圈代表不同的单元,不同颜色的箭头代表不同输入样本的数据流。注意,橙色和绿色圆圈分别代表空间和通道操作。在这个例子中,静态模型 (a) 倾向于为相似的图像生成相同的句子,而动态网络 (b) 可以通过动态路由生成信息丰富的字幕。图 5 中显示了更多示例。
为了解决这些问题,如图 1 (b) 所示,我们探索了一种新的范式,在网络设计中加入动态路由,以实现自适应和灵活的字幕生成。然而,将典型的动态路由策略应用于图像字幕时,会出现三个问题:
- 大多数动态网络 [18, 19, 20] 主要关注卷积核的动态设计,而忽略了空间多尺度建模和通道级建模。
- 当前的动态方法将所有候选模块置于同一个路由空间,导致路由效率低下。
- 动态网络 [21, 20, 22, 18, 19, 23] 中的大多数路由器都基于 Squeeze-and-Excitation [24] 架构,其中空间信息被 全局平均池化 操作破坏。
在本文中,我们提出了一种新颖的输入依赖型 Transformer 架构,称为 Dynamic Transformer Network (DTNet),以同时解决这三个问题。为了解决第一个动态设计问题,我们引入了五个基本单元来对空间域和通道域中的输入样本进行建模,从而构建更丰富的路由空间。为了解决第二个路由效率问题,我们将五个提出的单元分组到两个独立的路由空间,这降低了路由优化的难度。
具体而言,在空间域中,三个单元用于全局、局部和轴向建模;在通道域中,两个单元分别通过投影和注意力机制进行通道级建模。为了解决最后的信息损失问题,我们提出了一种新颖的 Spatial-Channel Joint Router (SCJR),它对输入样本的空间和通道信息进行全面的建模,以生成自适应路径权重。特别地,SCJR 将空间和通道域的建模解耦到两个分支,然后综合处理两个分支的输出以生成相应的路径权重。
基于上述新颖的设计,在推理过程中,不同的样本自适应地通过不同的路径进行定制处理。值得注意的是,与自注意力和前馈网络相比,大多数提出的基本单元都是轻量级的,因此我们提出的 DTNet 在参数增加可忽略的情况下,相对于普通 Transformer (i.e., 36.15 M vs. 33.57 M) 取得了显著的性能提升。
总之,我们的贡献有三方面:
- 我们提出了一种自适应的 Dynamic Transformer Network (DTNet) 用于输入敏感的图像字幕生成,它不仅为相似的图像生成更多有区别性的字幕,而且为多样化的图像字幕生成提供了一种创新的范式。
- 我们引入了五个基本单元,这些单元在空间和通道域中使用不同的机制对输入特征进行建模,以构建一个丰富的路由空间,实现更灵活的动态路由。
- 我们提出了 Spatial-Channel Joint Router (SCJR),通过联合考虑空间和通道建模来进行动态路径定制,以弥补之前路由器的信息损失。
在 MS-COCO 基准测试集上的大量实验表明,我们提出的 DTNet 显著优于之前的 SOTA 方法。此外,在 Flickr8K [25] 和 Flickr30K [26] 数据集上的实验结果也验证了 DTNet 的有效性和泛化性。

图 2:所提出的 Dynamic Transformer Network (DTNet) 用于图像字幕生成的框架。视觉特征是根据 [27] 提取的。接下来,堆叠的动态编码器层用于编码视觉特征,这些特征具有各种依赖于输入的架构,这些架构由我们提出的 Spatial-Channel Joint Router (SCJR) 确定。最后,来自编码器的特征将被馈送到解码器中以逐字生成字幕。为了简便起见,编码器中的残差连接被省略。最好在彩色下查看。
相关工作
之前的 V&L 研究主要集中在面向任务的网络架构设计上,这在很大程度上依赖于专家经验和经验反馈。与之前的工作不同,我们提出的 DTNet 将动态地为每个输入样本定制最合适的路径,这在图像字幕中很少被探索。在本节中,我们将首先回顾图像字幕的发展,然后介绍动态网络的最新趋势。
图像字幕
图像字幕是一项具有挑战性和基础性的任务,促进了多种应用的发展,例如,人机交互。随着深度学习的快速发展,我们可以观察到大量的改进,其中出现了许多方法[28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42],例如,SCST [43],Up-Down [44],AoANet [45],M2Transformer [46],X-LAN [35] 和 OSCAR [47]。通常,当前的字幕方法可以分为三类,即,基于模板的方法 [48, 49],基于检索的方法 [50, 51, 52, 42] 和基于生成的方法 [53, 44]。基于模板的方法 [48, 49] 识别视觉概念,如物体、属性和关系,然后将它们插入预定的短语模板中,这些模板包含几个空位,以完成字幕。基于模板的方法可以创建语法上准确的字幕。
然而,模板是预先定义的,因此语言的灵活性和生成的字幕的长度受到严重限制。基于检索的方法 [51, 52] 试图从现有的字幕池中搜索与查询图像匹配的句子。由于这些方法不会生成新的字幕来描述给定的图像,因此它们很难捕捉图像的独特性和复杂的语义。随着自然语言处理 (NLP) 和计算机视觉 (CV) 中生成模型的兴起,基于生成的图像字幕方法 [53, 44] 正在成为主流方法。
具体来说,大多数基于生成的方法遵循编码器-解码器范式,其中编码器用于将图像编码为视觉矢量表示,解码器用于基于这些矢量表示生成描述给定图像的字幕。由于其高度灵活性和高性能,基于生成的方法已获得研究人员大量的时间和精力投入。
但是,大多数以前的图像字幕模型都是静态的,它们严重依赖于专业设计,并阻碍了多样化句子的生成。与静态模型相比,我们的 DTNet 基于输入样本进行路径定制,因此提高了模型的灵活性和适应性。此外,静态模型只能为一张图像生成一个句子,而我们的 DTNet 可以通过控制路径权重为同一个输入生成不同的句子。
动态网络
神经科学领域的实证证据 [54, 55] 表明,在处理不同的信息时,海马体的不同部分会被激活,这揭示了大脑的动态特性。
受此发现的启发,旨在根据相应的输入调整架构的动态网络已成为计算机视觉中的一个新的研究重点,例如,图像分类 [19, 18, 56, 57, 58]、目标检测 [59, 60]、语义分割 [61, 62, 63]、长尾分类 [64]。Chen 等人 [19] 提出了动态卷积,这是一种新设计,可以在不增加网络深度或宽度的同时提高模型的复杂性。Li 等人 [62] 研究了一种新方法,即动态路由,以减轻语义表示中的尺度差异,该方法根据图像的尺度分布生成与数据相关的路由。Duggal 等人 [64] 提出了提前退出框架 (ELF) 来解决长尾问题,其中简单的示例将首先退出模型,而困难的示例将由更多模块处理。在 V&L 领域,Zhou 等人 [23] 提出了一个动态设计,通过感受野掩蔽来捕获视觉问答 (VQA) 的局部和全局信息。
然而,动态路由很少在更通用的 V&L 任务中得到探索,例如 图像字幕。直接将现有的动态机制融入图像字幕模型会导致次优性能。因此,在本文中,我们探索了一种用于图像字幕的动态方案,以实现更好的性能并生成多样化的字幕。
值得注意的是,尽管 TRAR [23] 也借鉴了动态网络的概念,但我们提出的 DTNet 与它有很大的不同。首先,TRAR 侧重于动态空间建模,因此动态思想只体现在对动态感受野的使用中,而我们提出的 DTNet 的动态思想同时体现在空间和通道建模中。
其次,TRAR 是一种具有动态感受野的 Transformer,它使用注意力掩码来控制感受野。我们的 DTNet 提出了多个建模单元和空间-通道联合路由器来实现对输入敏感的网络架构。值得注意的是,我们的研究引入了五个新颖的基本单元,每个单元都有独特的角色,并以独特的方式为特征提取过程做出贡献。
当单独考虑这些单元时,感知到的边际增益掩盖了我们在将它们全部组合在一起时观察到的协同性能增益。实际上,正是这组单元所带来的综合方法,而非单个单元的性能,真正促成了我们所取得的最先进技术的进步。
方法
在本节中,我们介绍了用于图像字幕的提出的 动态 Transformer 网络 (DTNet) 的细节,其中特定的网络架构随输入样本而变化。特别地,我们首先在第 III-A 节中介绍 DTNet 的概述。然后,我们在第 III-B 节和第 III-C 节中详细介绍了空间和通道路由空间中五个基本单元的架构。之后,我们在第 III-D 节中展示了我们提出的 空间-通道联合路由器 (SCJR) 的设计。最后,我们在第 III-E 节中详细阐述了图像字幕训练过程中的目标。
概述
图 2 说明了我们提出的 DTNet 的总体架构。给定一张图像 I,我们首先根据 [27] 提取视觉特征 V∈ℝH×W×C,其中 H、W、C 分别表示视觉特征的高度、宽度和通道维数。
然后,我们将视觉特征输入到提出的动态编码器中,以获得编码的视觉特征 V^∈ℝH×W×C,其公式为:
![]()
其中 η(⋅) 表示动态编码器中的操作。如图 2 中间部分所示,前向路径不是静态的,而是由我们提出的路由器自适应地确定的,即 架构随输入而变化。
特别地,动态路由操作可以表述如下:

其中 K 是路由空间中的单元数量,即 候选路径的数量,x 是输入,πk(x) 是给定 x 的第 k 个单元的路径权重,Yk 是第 k 个单元的输出,Y^ 是动态输出。
最后,编码的视觉特征将被输入到解码器中,解码器遵循 Vanilla Transformer [65] 的架构,以生成相应的标题。

图 3:空间和通道路由空间中不同单元的详细架构。为简化起见,省略了 BatchNorm。

图 4:不同单元的感受野说明。(a) 全局建模单元,(b) 局部建模单元,(c) 轴向建模单元。深蓝色网格是查询网格,浅蓝色区域是感受野,其余白色区域是不可感知区域。
空间建模单元
为了感知空间域中不同感受野的信息,我们定制了三个单元,包括 全局建模单元 (GMC)、局部建模单元 (LMC) 和 轴向建模单元 (AMC),如图 3 中的粉色块所示。特别是,GMC、LMC 和 AMC 分别在空间维度上对全局、局部和轴向信息进行建模,起着特定的作用。
全局建模单元 (GMC)
为了捕捉视觉特征中的全局依赖关系,引入了全局建模单元 (GMC)。如图 3 [S1] 所示,它是利用 Transformer [65] 的多头自注意力 (MHSA) 机制实现的。
MHSA 的 i 头可以表示为:

其中,WiQ、WiK、WiV∈ℝC×C/ℋ 是可学习的投影矩阵,ℋ 代表头的数量,dk 是 XWiK 中通道维度的数量。之后,所有头的输出在通道维度上连接在一起,如下所示:
![]()
其中 [;] 是在通道维度上的连接操作,WO∈ℝC×C 是可学习的参数矩阵。GMC 的感受野如图 4 (a) 所示。
局部建模单元 (LMC)
一系列工作 [66, 67, 68, 69, 70, 71] 表明,平移不变性和局部感知对于图像识别至关重要。因此,除了全局建模之外,我们还引入了 LMC 来感知不同尺度的物体。如图 3 [S2] 所示,LMC 由两个多分支卷积、一个激活函数(即 ReLU)和一个归一化函数(即 Sigmoid)组成。每个多分支卷积可以表示为:

其中 i∈{0,1} 是多分支卷积的索引,BNi(⋅)、Fi1×1(⋅)、Fi3×3(⋅) 分别表示批量归一化 [72]、1×1 Conv 和 3×3 Conv 1 。使用 ReLU 激活模块来连接这两个多分支卷积。
之后,我们将对输出进行归一化并将归一化权重应用于输入:
![]()
其中 δ(⋅) 是 Sigmoid,⊗ 是逐元素乘法。LMC 的感受野如图 4 (b) 所示。
轴向建模单元 (AMC)
之前的工作 [69, 73] 已经表明,图像中的轴向建模对于信息感知至关重要。因此,我们还引入了一个简单的单元来在图像中执行轴向注意,详细说明如图 3 [S3] 所示。
具体来说,X∈ℝH×W×C 表示 AMC 的输入。我们采用两个全连接 (FC) 层来覆盖输入的宽度和高度维度,分别获得 XW∈ℝH×W×C 和 XH∈ℝH×W×C。之后,X 将与 XH 和 XW 连接如下:

为了进行后处理,我们使用一个 FC 层来降低 Xcon 的通道维度,并使用 sigmoid 函数来归一化输出,得到轴向注意力权重。最后,根据注意力权重重新加权输入,这可以表示为:
![]()
其中 Wrec∈ℝ3C×C 是可学习的参数矩阵。AMC 的感受野如图 4 (c) 所示。
通道建模单元
我们探索了在通道域中建模信息的两种替代方法,i.e., 基于投影和基于注意力的方法。具体来说,我们引入了两种单元来通过投影和注意力对信息进行建模。通道投影单元 (CPC) 和通道注意力单元 (CAC) 分别在通道维度上运行并执行不同的操作。
通道投影单元 (CPC)
CPC 是一种基于投影的方法,用于在通道域中建模信息,它使用前馈网络 (FFN) [65] 实现。具体来说,如图 3 [C1] 所示,它包含两个 FC 层,中间有一个 ReLU 激活函数:

其中 W1CPC∈ℝC×4C 和 W2CPC∈ℝ4C×C 是可学习的投影矩阵,b1 和 b2 是偏差项,σ(⋅) 是激活函数,i.e., ReLU [74]。
通道注意力单元 (CAC)
CAC 是一种基于注意力的通道建模方法,如图 3 [C2] 所示。具体来说,我们采用广泛使用的 Squeeze-and-Excitation (SE) [24] 来实现它,它包含一个多层感知器和一个 Sigmoid 函数,如下所示:
![]()
其中 Pool(⋅) 是空间域中的平均池化操作,W1CAC∈ℝC×C16 和 W2CAC∈ℝC16×C 是可学习的投影矩阵,δ(⋅) 是 Sigmoid 函数,σ(⋅) 是 ReLU 激活函数。
具体而言,将 CAC 集成到我们模型背后的主要动机源于它在增强表示能力方面的重要作用。通过调整自适应权重,CAC 有选择地强调和增强最相关的特征通道。通过通道注意机制,我们的模型获得了动态分配注意力的能力,以关注特定的特征通道。这种动态分配使模型能够专注于最有信息量的通道,同时抑制不太有用的通道。此外,CAC 的包含旨在补充我们模型架构中的通道投影单元 (CPC)。虽然 CPC 负责使用具有非线性激活的堆叠全连接层学习复杂的特征表示,但 CAC 通过微调各个特征通道的重要性,在更细粒度的层面上运行。CAC 和 CPC 的组合产生了更强大、更灵活的特征表示能力,正如 Tab. II 中最后三行的分析所示。
空间-通道联合路由器
以前大多数动态网络 [23, 21, 19] 中的路由器都是基于 SE [24] 的,在全局池化期间会破坏空间位置信息。为了克服这一局限性,我们提出了一种新颖的空间-通道联合路由器 (SCJR),如图 2 的绿色块所示。在我们的提议中,输入特征由两个分支处理,即一个用于通道域,另一个用于空间域。在通道分支中,输入首先通过全局空间池化 (𝒢𝒮𝒫) 在空间域中被压缩,然后由多层感知器 (MLP) 处理,其公式为:

其中 σ(⋅) 是 ReLU 激活函数,W1Cha∈ℝC×Cr1,W2Cha∈ℝCr1×p(r1=16 是我们实验中的默认设置),p 是候选路径的数量。
同样,空间分支可以表示为:

其中 𝒢𝒞𝒫(⋅) 是全局通道池化,W1Spa∈ℝN×N/r2,W2Spa∈ℝN/r2×p(r2=7 是我们实验中的默认设置),为了简便起见,省略了重塑操作,N 是网格的数量,即 i.e., N=H×W。
最后,通道分支和空间分支的输出将被连接起来,然后输入到一个 MLP,然后进行 Softmax 归一化:

其中 [;] 是张量的连接操作,W1Joint∈ℝ2p×p,W2Joint∈ℝp×p,W^∈ℝp 是每条路径的最终权重。
优化
DTNet 可以用于各种 V&L 下游应用。对于图像字幕,我们首先使用交叉熵 (CE) 损失预训练我们的模型,该损失表示为:

其中 y1:T∗ 是具有 T 个词的真实字幕,θ 表示我们模型的参数。
然后,根据 CIDEr [75] 和 BLEU-4 [76] 的总和,模型按照自关键序列训练 (SCST) [43] 进行优化:

其中 k 是束搜索大小,r(⋅) 表示奖励,b=(∑ir(y1:Ti))/k 表示奖励基线。
实验
数据集和实验设置
我们在流行的图像字幕基准 MS-COCO [77] 上评估我们提出的方法,该基准包含超过 120,000 张图像。具体来说,它包括 82,783 张训练图像、40,504 张验证图像和 40,775 张测试图像,每张图像都标注了 5 个标题。为了离线评估,我们采用 Karpathy 分割 [78],其中 5,000 张图像用于验证,5,000 张图像用于测试,其余图像用于训练。为了在线评估,我们将生成的 COCO 官方测试集的标题上传到在线服务器。
视觉特征是从 Jiang 等人 et al. [27] 提供的 Faster R-CNN [79] 中提取的。为了减少自注意力机制的计算量,我们按照 Luo 等人 et al. [36] 将特征平均池化到 7×7 网格大小。
为了公平比较,我们使用与经典方法类似的实验设置,例如 [36, 37, 46]。具体来说,dmodel 为 512,头部数量为 8,FFN 的扩展率为 4,波束大小为 5,优化器为 Adam [80],编码器和解码器的层数为 3。请注意,除了简单的增强(e.g., 随机裁剪、随机旋转)之外,我们没有使用任何额外的预处理数据。在 CE 训练阶段,批次大小为 50,学习率在最初的 4 个时期线性增加到 1×10-4。之后,我们将其设置为 2×10-5,4×10-6 在第 10 个和第 12 个时期。在 18 个时期的 CE 预训练之后,我们选择了在批次大小为 100 和学习率为 5×10-6 的情况下,在 SCST 优化中取得最佳 CIDEr 分数的检查点。学习率将在第 35 个、第 40 个、第 45 个、第 50 个时期分别设置为 2.5×10-6,5×10-7,2.5×10-7,5×10-8,SCST 训练将持续 42 个时期。
按照标准评估协议,我们利用流行的字幕指标来评估我们的模型,包括 BLEU-N [76]、METEOR [81]、ROUGE [82]、CIDEr [75] 和 SPICE [83]。
表 I:空间建模单元的消融研究。所有值均以百分比 (%) 表示。B-N、M、R、C 和 S 分别代表 BLEU-N、METEOR、ROUGE-L、CIDEr-D 和 SPICE 得分。GMC、LMC 和 AMC 分别代表全局建模单元、局部建模单元和轴向建模单元。

表 II:关于通道建模单元的消融研究。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 得分。CAC 和 CPC 分别代表通道注意力单元和通道投影单元。

表 III:关于动态空间和通道块的各种排列的消融研究。‘S’ 和 ‘C’ 分别代表空间和通道。‘&’ 和 ‘+’ 分别代表并行和串行连接。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 得分。

表 IV:关于各种路由器的消融研究。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 得分。

表 V:关于单元分组操作的消融研究。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 分数。

表 VI:不同分组组合的性能比较。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 分数。

消融分析
对空间建模单元的消融
为了深入了解三个空间建模单元,我们进行了详细的消融研究。如表 I 所示,我们观察到无论配备哪个单元,性能都会显著提高,这证明了我们提出的单元的有效性。此外,与 LMC 和 AMC 相比,GMC 实现了更好的性能,这表明全局建模比局部和轴向建模起着更重要的作用。此外,我们可以观察到,与单独依赖一种类型相比,同时使用两种空间建模单元可以提高性能。
例如,当 GMC 和 AMC 同时参与时,我们注意到 CIDEr 分数显着增加;根据测量结果,与仅使用 GMC 或 AMC 相比,分别增加了 1.0 CIDEr 和 0.9 CIDEr。此外,我们发现,将所有三个空间建模单元(GMC、LMC 和 AMC)结合起来可以获得更大的收益。这种现象可以归因于全局、局部和轴向建模在空间域中的协同效应。总之,这些不同的建模技术共同增强了对图像中视觉语义的理解。因此,这种协调有助于生成更准确、更流畅的图像字幕。
重要的是,在使用我们提出的三个空间建模单元的实验中,CIDEr 分数提高了 2.4(即从 132.5 到 134.9)。这表明这些单元为空间信息建模提供了一种有效的机制。
关于通道建模单元的消融
为了探索通道建模单元的影响,我们还进行了增量消融研究。如表 II 所示,我们可以观察到,配备通道建模单元也有助于提高性能。具体来说,CAC 和 CPC 帮助字幕模型在 CIDEr 分数上分别提高了 0.8% 和 1.0%,因此基于注意力的单元和基于投影的单元都可以提高模型的语义建模能力和生成字幕的准确性。
此外,配备这两个通道建模单元可以进一步提高性能,即 CIDEr 分数提高 2.8%。虽然 CAC 和 CPC 都是通道域中的建模模块,但由于它们的建模原理不同(即 基于注意力的方法和基于投影的方法),它们可以互相促进以实现更高的性能。重要的是,表 II 显示由于我们提出的两个通道建模单元,CIDEr 分数提高了 2.8(从 132.1 到 134.9),从而证明了它们在通道信息建模方面的有效性。
表 VII:关于各种路由类型的消融研究。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr、SPICE 分数。

不同单元排列的影响
为了探索不同建模单元排列的影响,我们比较了三种排列空间和通道建模单元的方式:并行通道-空间 (S&C)、顺序通道-空间 (C+S) 和顺序空间-通道 (S+C)。表 III 总结了不同排列方法的结果。通过分析实验结果,我们发现 S+C 的性能始终优于 S&C 和 C+S。
表 VIII:Karpathy 测试集上的 SOTA 比较。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 分数。

表 IX:COCO 在线测试服务器上已发表的最先进的图像字幕模型的排行榜。†代表同时采用网格和区域视觉特征。

表 X:使用相同的 ResNeXt-101 网格特征在 Karpathy 测试集上与 SOTA 方法进行比较。B-1、B-4、M、R、C 和 S 分别代表 BLEU-1、BLEU-4、METEOR、ROUGE、CIDEr 和 SPICE 分数。

不同路由器的影响
与之前的工作不同,之前的路由器基于 Squeeze-and-Excitation [24],我们提出的 SCJR 根据输入样本的通道和空间信息执行路径定制。
为了验证其有效性,我们通过解耦 SCJR 的空间和通道分支进行了大量的消融实验。此外,我们还报告了“静态路由器”的性能,它直接对所有单元的输出进行求和。如表 IV 中所述,我们观察到我们提出的 SCJR 比基于空间和基于通道的路由器表现得更好,这证实了在空间和通道域中联合建模的重要性。
特别是,在 CIDEr 分数上,SCJR 的性能比基于空间和基于通道的路由器分别高出 1.8% 和 1.3%。请注意,所有动态路由器都比“静态路由器”表现得更好,这表明动态路由对于推动图像字幕中的性能至关重要。
单元分组操作的影响
为了探索单元分组操作的影响,我们还通过将所有空间和通道建模单元放置在相同的路由空间中进行实验。如表 V 所示,我们观察到,如果没有分组操作,性能会显著下降(即 在 CIDEr 分数上下降 1.4%)。原因可能是空间和通道单元是互补的,将它们放置在相同的路由空间中会损害路由效率。在根据先验知识进行分组后,模型不再需要决定是走通道路径还是空间路径,从而降低了优化难度。
不同路由类型的影响
使用 Gumbel-Softmax 技巧 [99],我们还实现了一种端到端的硬路由方案,它在编码器中实现了二进制路径选择。如表 VII 所示,我们发现硬路由模型的性能比软路由模型差,但仍然优于静态模型,这可以用子模型的数量来解释。在静态模型中,所有样本都通过相同的路径,因此静态模型中的子模型数量为 1。同样,由于二进制路径选择,硬路由模型中子模型的上限数量为 Πi=1L(NsiNci),其中 L 是编码器层的数量,Nsi,Nci 是 i 层中的空间和通道建模单元的数量。软路由模型可以根据输入样本分配不同的路径权重,因此软路由模型中子模型的上限数量为 +∞。
不同分组组合的影响
为了研究不同分组组合的影响,我们广泛地检查了一系列分组配置,其中包括在同一路由空间内空间建模单元和通道建模单元的不同组合。我们的实证结果如表 VI 的前六行所示,一致地表明,当空间和通道建模单元在路由空间中混合时,性能会下降,程度不同。当我们将这两类单元分配到单独的路由空间时,图像字幕模型获得了对空间和通道建模的集中关注,我们认为这是获得优异性能的关键。这一观察结果证实了我们早期的假设,即空间建模单元和通道建模单元的功能是相互补充的,从而表明不同分组的关键作用。基于这些经验基础的观察和后续分析,我们建议将五种基本单元类型分别划分为两个不同的组,分别用于空间建模和通道建模。
通用性能比较
离线评估
在表 VIII 中,我们报告了我们提出的 DTNet 与以前 SOTAs 在离线 COCO Karpathy 分割上的性能比较。为了公平比较,我们报告了单个模型的结果,不使用任何集成技术。可以观察到,我们的 DTNet 在大多数指标方面都优于其他模型。具体来说,DTNet 的 CIDEr 分数为 134.9%,显著优于所有先前的方法。

图 5:Transformer [65]、Transformer M2[46]、RSTNet [37] 和 DTNet 生成的字幕示例。“GT” 是 “Ground Truth” 的缩写。
表 XI:标准 Transformer 和我们的 DTNet 不同字幕指标的性能比较。P 值来自使用配对样本进行的双尾 t 检验。粗体显示的 P 值在 0.05 的显著性水平上具有显著性。

表 XII:标准 Transformer 和我们提出的 DTNet 的 SPICE 指标子类别。P 值是通过使用配对样本进行的双尾 t 检验计算得出的。请注意,粗体显示的 p 值在 0.05 的显著性水平上具有显著性。

表 XIII:与 Flickr8K 数据集上最先进技术的比较。所有值均以百分比 (%) 报告,其中 B-N、M、R 和 C 分别代表 BLEU-N、METEOR、ROUGE-L 和 CIDEr 分数。† 表示集成模型的结果。

在线评估
表 IX 总结了 SOTA 和我们方法在在线测试服务器上的性能。请注意,我们采用了两个常见的骨干网络(ResNeXt-101 和 ResNeXt-152 [103])和四个模型的集成,遵循 [35, 46]。结果表明,DTNet 在大多数评估指标上取得了迄今为止的最佳结果。提出的 DTNet 在以下方面优于 DLCT:
- DTNet 训练效率更高:在离线获取特征训练领域,DTNet 明显优于 DLCT。这种显著的差异源于 DLCT 集成了网格和区域特征,这不可避免地增加了计算开销。相反,DTNet 通过战略性地排除区域特征,在交叉熵训练阶段的计算速度是 DLCT 的三倍。这种优化方法降低了固有的算法复杂度,并提高了训练效率。
- DTNet 推理加速:DTNet 的单阶段设计确保了快速推理,超过了 DLCT。如 [27] 中所强调,DLCT 延迟的一个重要来源是它对区域特征提取的依赖,特别是耗时的 NMS 操作,该操作消耗了总推理时间的 98.3%。相比之下,DTNet 通过采用端到端设计并省略区域特征,极大地提高了其推理吞吐量,为运营效率树立了新标准。
- DTNet 架构简化但高效:虽然 DLCT 由于其高结构复杂性而需要复杂的設計,但 DTNet 提供了一种性能强大的简洁设计。DLCT 设计挑战的关键在于制定复杂的交互机制,以利用不同特征之间的互补性。然而,DTNet 采用了一种新的轨迹,利用自动结构优化。它只要求从一组精心挑选的架构中进行选择,并利用一种样本自适应方法来动态地确定最有效的结构。
- 最后,在性能方面,尽管 DLCT 使用了多种视觉特征,但 DTNet 在 COCO 在线测试服务器上的大多数评估指标上始终优于 DLCT。值得注意的是,大多数性能指标明确支持 DTNet 的优越性,仅在 METEOR-c40 指标中观察到微小的差异。因此,DTNet 有效地证明了效率和性能之间的出色平衡,清楚地展示了其优于 DLCT 的优势。

图 6:路径可视化。(a) 图 8 中的示例。(b) 由相同数量(即 8)的单元处理的示例。
与 SOTA 方法的公平比较
为了消除采用不同视觉特征带来的干扰,我们还在相同的视觉特征上进行了广泛的实验,以比较 DTNet 和之前的 SOTA。如表 X 所示,与其他 SOTA 相比,DTNet 在使用相同的视觉特征时仍然表现出显著的性能优势。
Flickr 数据集上的泛化
我们还在 Flickr8K 和 Flickr30k 数据集上进行了广泛的测试,以验证我们提出的 DTNet 的泛化能力。
表 XIV:与 Flickr30K 数据集上最先进方法的比较。所有值均以百分比 (%) 表示,其中 B-N、M、R 和 C 分别代表 BLEU-N、METEOR、ROUGE-L 和 CIDEr 分数。† 表示集成模型的结果。

Flickr8K 上的性能比较
Flickr8K [25] 是从 Flickr 收集的 8,000 张图片的集合。它包含每张图片的五句标注。该数据集提供了训练、验证和测试集的传统划分,我们在实验中使用这些划分。共有 6,000 张训练图片、1,000 张验证图片和 1,000 张测试图片。表 XIII 详细说明了我们提出的 DTNet 和以前方法在 Flickr8K 数据集上的字幕性能。通过分析实验结果,我们可以观察到我们提出的 DTNet 优于以前的 SOTA。值得注意的是,我们提出的 DTNet 甚至超越了一些集成模型(即 Google NIC [53])。
Flickr30K 上的性能比较
Flickr30K [26] 是 Flickr8K 集合的扩展。它还为每张图片提供了五句标注。它有来自公众的 158,915 条描述 31,783 张图片的字幕。此数据集的标注在语法和风格上与 Flickr8K 相似。遵循先前研究,我们采用 1,000 张图像进行测试。表 XIV 展示了我们提出的 DANet 与 Flickr30K 数据集上先前最先进方法的性能比较。DTNet 在 Flickr30K 上的出色表现再次揭示了动态网络在图像字幕任务中的有效性和泛化能力。

图 7: 由提出的 DTNet 中四个随机采样的路径生成的字幕。

图 8: 图像和相应的通过单元格数量。一些示例的路径可视化如图 6 (a) 所示。
表 XV:与最先进方法相比,VQA-v2 的val分割上的准确率。


图 9: 由 Transformer [65]、 Transformer M2[46]、 RSTNet [37] 和提出的方法获得的负面定性可视化。“GT” 代表“真实值”。
显著性检验
为了说明我们提出的 DTNet 的有效性和优越性,我们对 DTNet 与标准 Transformer 进行了详细的比较。具体来说,我们对每个指标进行配对样本双尾 t 检验,以查看 DTNet 带来的改进是否具有统计学意义。为了验证 DTNet 生成的标题的语义是否比标准 Transformer 有显著提高,我们还报告了两种模型的 SPICE 分数的语义子类别 (i.e.,关系、基数、属性、大小、颜色和对象)。此外,我们对每个详细的 SPICE 分数进行了配对样本的双尾 t 检验。
t 检验的常用指标和 p 值如表 XI 所示。正如我们所观察到的,图像字幕的所有常用指标在显著性水平 α=0.05 下均显着提高,这证明了我们提出的 DTNet 的有效性。此外,t 检验的详细 SPICE 分数和相应的 p 值如表 XII 所示。我们观察到,所有 SPICE 的详细语义子类别都获得了改进。此外,Attribute、Color 和 Object SPICE 分数在显著性水平 α=0.05 下显着提高,这证明了我们提出的 DTNet 可以充分挖掘图像中的语义并生成准确的标题。
视觉问答 (VQA) 的泛化
虽然 DTNet 的主要关注点是图像字幕,但我们也探讨了它在其他多模态任务(如视觉问答 (VQA))上的性能。为了彻底评估 DTNet 超越其主要应用的能力,我们对广泛认可的 VQA-V2 数据集进行了广泛的实验。我们的发现如表 XV 所示,表明我们提出的 DTNet 模型在 VQA 任务中表现出色,突出了其泛化性和多功能性。具体来说,与 MCAN [110](一种静态 Transformer 类架构)相比,我们的方法在所有指标上都表现出显著的改进。
定性分析
路径分析
在图8中,我们展示了一系列通过不同数量路径的图像。具体而言,我们使用 0.3 作为阈值对学习到的路径进行离散化(即,权重小于该阈值的路径将被移除)。值得注意的是,路径数量通常随着图像复杂度的增加而增加,这与人类感知系统 [54] 相符。原因可能是,少量细胞足以处理简单图像,只有复杂图像才需要更多细胞的参与。图6 说明了针对不同图像的定制路径。
字幕质量
图 5 说明了 Transformer 和 DTNet 对类似图像的几个图像标题生成结果。值得注意的是,图5 的前两行表明 Transformer 模型无法辨别相似图像之间的细微差别,导致它生成相同的描述。相反,我们的 DTNet 对区分不同样本的特定特征表现出敏感性,允许它定制适当的路径并生成信息丰富的字幕。这个结果再次突出了我们图像字幕方法中采用的动态方案的优越性。为了进一步说明这一点,请参考图5 中第一行的前两列。Transformer 模型为这两张截然不同的图像生成了相同的字幕:“带马桶和水槽的浴室”。
相反,我们的 DTNet 准确地识别出这两幅图像在细节上的差异,并为每幅图像生成不同的描述。此外,值得注意的是,Transformer 模型可能会生成错误的标题来描述图像,而 DTNet 生成的标题则具有更高的准确性。如图 5 最后一行第一列所示,我们观察到 Transformer 模型错误地预测了火车的数量,从而导致了不正确的标题:“两列红色的火车在雪中的轨道上”。相反,我们提出的模型生成了一个精确的标题:“一列红色的火车在雪中的轨道上”。
为了深入了解 DTNet 的每条路径,我们随机抽取了四条路径,并在图 7 中说明了这些抽样路径生成的标题。一个有趣的观察结果是,不同路径生成的标题是多样化的,但都是准确的。因此,除了实现新的最先进的性能之外,我们的 DTNet 还为 DIV 提供了一种新方法。
限制
虽然我们提出的 DTNet 已证明了其卓越的性能,但承认其局限性至关重要。首先,DTNet 偶尔可能会对外观相似的物体做出错误的预测。例如,如图 9 的第一列所示,一只黑白色的狗在阳光下可能会呈现出与棕色和白色相似的毛色。因此,我们的 DTNet 可能会错误地将其预测为棕色和白色的狗。
此外,在复杂的场景中,DTNet 可能难以捕捉和描述所有存在的复杂细节。这在图 9 的第三列中很明显,其中 DTNet 生成了标题“一个有床和椅子的酒店房间”来描述图像。虽然生成的标题没有错误,但它未能对图像中所有细节进行详尽的描述。
结论
在本文中,我们提出了用于图像字幕的动态 Transformer 网络 (DTNet)。具体来说,我们引入了五个基本单元来构建路由空间,并将它们按域分组以实现更好的路由效率。我们提出了空间通道联合路由器 (SCJR),用于根据输入的空间和通道信息定制动态路径。在 MS-COCO 基准测试上的广泛结果表明,我们提出的 DTNet 优于之前的 SOTA。提出的单元设计和路由方案也为将来研究输入敏感学习方法提供了见解。
#Mono-InternVL
视觉语言模型新范式
目前流行的多模态大模型的结构是模块化的,和LLaVA、MiniGPT-4、Qwen-VL和DeepSeek-VL等系列一样,都会有视觉Encoder、Projector、Text Embedding Layer和LLM,最近也有一些工作没有视觉Encoder的多模态大语言模型,今天要介绍的论文《Mono-Internvl: Pushing The Boundaries Of Monolithic Multimodal Large Language Models With Endogenous Visual Pre-Training》提出了一种新的多模态大语言模型结构:Mono-Internvl以及对应的训练策略:endogenous visual expert(EViP)。
arxiv.org/pdf/2410.08202
internvl.github.io/blog/2024-10-10-Mono-InternVL/
huggingface.co/OpenGVLab/Mono-InternVL-2B
Fig 1
和其他范式的多模态大语言模型的结构如图Fig 1所示,细节见Fig 2.
Fig 2

多模态特征蓄力作为LLM的输入,为了处理输入的文本和视觉特征,文中提出了混合专家结构,即

Fig 3
Fig 4
模型的训练也是采用了预训练和指令微调的范式,其中预训练包含三个阶段的训练,训练数据量以及相关的优化参数如图Fig 4所示。
模型预训练阶段分为概念学习(S1.1)、语义学习(S1.2)和对齐学习(S1.3)三个步骤,具体如下:
概念学习(S1.1)
- 目标:鼓励模型学习基本视觉概念,如对象类别或基本形状。
- 数据:使用约 9.22 亿个噪声样本,这些样本来自 Laion - 2B 和 Coyo - 700M。
- 训练策略:采用简单提示进行生成式学习,例如 “为图像提供一个句子的字幕”。为提高训练效率,将视觉标记器的图像块最大数量限制为 1,280。在概念学习期间,整个 LLM的参数保持不变,优化patch embedding和visual experts的参数。
语义学习(S1.2)
- 目标:在模型理解图像基本概念的基础上,实现更高级的视觉理解。
- 数据:利用预训练的 InternVL - 8B 为 2.58 亿张图像生成合成字幕,这些字幕包含更复杂的视觉知识且噪声信息较少。
- 训练策略:与概念学习采用相同的优化策略,但将图像块的最大数量增加到 1,792。
对齐学习(S1.3)
- 目标:使模型满足下游任务的视觉要求。
- 数据:从 InternVL - 1.5 的预训练数据中采样 1.43 亿个样本,包括图像字幕、检测和光学字符识别(OCR)数据,其中字幕数据、检测数据和 OCR 数据分别约占总数的 53.9%、5.2% 和 40.9%。
- 训练策略:利用 InternVL - 1.5 的特定任务提示进行生成式学习,并将图像块的最大数量增加到 3,328。与前两个阶段不同,此阶段还额外优化多头注意力层,以实现更好的视觉 - 语言对齐。
在预训练的各个阶段用到的训练数据如图Fig 5所示。
Fig 5
在指令微调的各个阶段用到的数据如图Fig 6所示。
Fig 6

















 6036
6036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









