







我自己的原文哦~ https://blog.51cto.com/whaosoft/11999205
#Carpentopod
当代版木牛流马?国外网友造出「会走路的桌子」,引百万人围观
你想喝瓶啤酒,于是就把桌子叫了过来。这不是吃了菌子才有的场景,而是国外网友的一项发明,名叫 Carpentopod。

整个桌子有 12 条腿,里面内置了电机,是木工、电子和编程结合的产物。只要按下遥控器,桌子就会向你走来,像一个家用机器人一样。
从图上可以看出,Carpentopod 走起来非常平稳,这是它的腿部参数不断「进化」的结果。这个「进化」过程在软件的虚拟环境中进行,数千个虚拟腿部变体在该环境中竞争,只有得分高的腿部变体才能混合「基因」。
如此精巧的结构制作起来自然是非常不易。作者表示,「早在 2008 年,我就写了一些有趣的软件来生成各种优化的步行机制。近年来,我掌握了一些电子和木工技能,于是能够将其中一种机制变成一个真正的无线步行木制咖啡桌。」
这种机器人技术与木工的结合令人眼前一亮。作者 @Giliam de Carpentier 表示将参加近期的一个活动,届时会做更多介绍。
这个咖啡桌在网上吸引了上百万人的关注,很多人表示想要一个。
在一篇文章中,作者介绍了从设计到材料选择,再到加工和装配的全过程。其中包括使用数控机床加工竹板部件,还包括控制电机和 Arduino 系统以实现桌子的移动功能。

文章链接:https://www.decarpentier.nl/carpentopod
设计新连杆
Carpentopod 腿部连杆是由作者编写的软件生成的。这个软件让数千个虚拟腿部变体进行竞争,以此进化。为了挑选出最佳的变体,每个变体都被赋予一个基于其行走速度、间隙和材料使用的「适应度」分数。在行走周期中最低的三分之一阶段,作者额外奖励了那些腿尖能更水平和更平滑移动的变体。这样的设计有助于三条腿协同作用,以最大程度减少行走时的晃动和足滑。
通过比较每种变体的适应度分数,只有最优秀的变体才能混合其基因(即腿部参数),创造出一代又一代的新变体。除了通过「自然选择」混合基因外,作者还定期引入基因突变,以帮助发现新的解决方案并保持多样性,直到找到最佳解决方案。作者用 C++ 编写了包括运动学求解器在内的所有程序,使得这个模拟每秒可以进化数十代,让人可以清晰地看到从初步设计到高度优化设计的转变。

上面的动图展示了 20 秒钟的进化过程。每帧显示 5000 个「存活」的变体中的一个。同时,视频中叠加了所有 5000 个个体的腿尖轨迹,这些轨迹随时间推移合并成一个红、绿色光晕,最终收敛成一个单一的解决方案。作者最终选择的腿部连杆,是通过运行一个规模更大、时间更长的模拟程序简单选出的。命名结合了古拉丁语和希腊语单词:carpentum(一种有盖的马车,如下图)和 pod(代表脚或有腿的)。

看过 Theo Jansen 鼓舞人心的 Strandbeest 雕塑的人可能都会发现,他的雕塑的腿部连杆机构与 Carpentopod 连杆机构十分相似。但 Carpentopod 的连杆具有一套完全不同的组件比率,以及一个额外的关节点和一个进化过的圆形脚趾直径。这些额外的参数使得进化过程能够找到一种更紧凑、减少脚部滑动的解决方案。


Strandbeests 是荷兰动感雕塑艺术家 Theo Jansen 发明的「风力仿生兽」,依靠机械原理和自然风力移动前行,结构巧妙之处在于合理的利用平衡性进行物理变量的转化,能源转化率非常高。
脚部滑动的原因是不同的脚趾着地的速度不完全一致,因此在实践中会导致这些腿试图相互减速。(不过,Strandbeest 的腿似乎通常都采用某种灵活 / 滚动的脚趾,而不是刚性的脚趾,这可能在一定程度上有助于弥补这种影响)。下面的动图比较了两种不同的设计,包括它们对尺寸、重心和脚滑动 / 滑行的影响。
设计会走的桌子
多年来,上述成果只是一个兴趣项目的有趣结果。但最近几年,作者也对制作实物产生了兴趣。他尝试制造的第一件东西是之前版本连杆的一个微型模型,由于其对紧凑性的优化较少,因此不适合成为最终的 Carpentopod 桌子。这只是为了测试他新开发的技能, 并在尝试更大项目之前试用新的 CNC(数控机床)。
接下来,他决定制作一个可以行走的木制咖啡桌,因为他认为这既实用又具有美观价值。由于 Carpentopod 连杆中的每个独立腿部只占行走周期的三分之一,因此这个桌子本身需要十二条腿以保持稳定。为了保证行走的平滑性,腿部组件也需要以亚毫米级的精度制作并维持这种状态。这就是作者选择用层压竹板进行 CNC 加工的原因,这种材料坚固、自然、耐用且稳定,非常适合将机械元素与有机风格结合起来。
作者使用 Autodesk Fusion 360 设计了桌子的所有组件,这使他能够在同一个软件包中完成建模、测试、渲染和所有 CNC 的准备工作。能够在其行走周期的任何阶段从任何角度实际查看完全组装的模型,极大地方便了美学调整和确保所有间隙都恰到好处。




在一端的六条腿和另一端的六条腿之间,作者还留出了一个中空的「腹部」,用来放置电子设备、电机和电池。为了让它看起来不那么棱角分明,他把框架和腹部设计成弧形,就像一个倒置的百宝箱。这可能是有些人说它看起来像 Terry Pratchett《碟形世界》(Discworld)小说中的「行李箱」(如下图)的原因之一。
中央的腹部还能使所有支腿至少与中心保持一定距离,从而使所有支腿都能更有效地参与转弯。每组六条腿都被设计成与自己的曲柄轴相连,由一个电机驱动。这样,它们只需要两个单独控制的电机就能像坦克一样「驱动」和转动桌子。
构建过程
为了将 3D 设计实物化,作者尽可能多地使用 CNC。这不仅因为精确度的需要,也因为这样可以更容易地批量制造出十二个相同的木制部件。由于这只是一个兴趣项目而不是生产线,所以作者决定使用他便宜的三轴 CNC 路由器亲手制作所有东西。
三轴 CNC 只能从顶部去除材料。但是由于许多零件也需要从底部和 / 或侧面移除材料,以制造更复杂的形状和凹陷,作者将大部分腿部零件设计成由三片层压竹子制成,他可以分别加工每层竹子,然后将其粘合在一起。
当然,即使是单个部件也可能需要使用不同尺寸和形状的切削工具多次过刀,并可能需要精确地翻转以进行双面加工。但这正是数控加工的现实 —— 如果你不想买更贵的五轴 CNC,也不想使用塑料进行 3D 打印的话,这就是你必须面对的。
除了作者自己数控加工、抛光、上漆并用更多的滚珠轴承和钢轴组装的 100 多个竹制部件外,设计还要求制作两个曲轴。他最终通过将 D 形轴和带 D 形孔的旋转偏心体锤在一起,精心地从普通铝杆和铝板中数控加工出这些部件。




桌子的弧形「腹部门」是通过在同一层压竹中精细地切割制成的,然后蒸汽处理使其更加柔韧,最后在弯曲夹具中干燥,以赋予其新的形状。然后,这些部分被粘贴在两个带有嵌入式磁铁的隐形铰链肋上,使得门易于打开和关闭。最后,他还焊接了一件与之高度相同的电视柜,并将一块芒果木加工成两件家具的桌板,有效地将它们组合成一套。
让桌子动起来
两个六腿部分应由各自的电机驱动。但实际上,是每个部分的单个曲轴协调腿部的相对运动。在下图中可以看到,作者只是简单地推动一个没有电机的部分向前移动,该部分就可以表现得像一个轮子。
图中还展示了脚趾是如何轻触地面(由黑线表示),但并不试图穿透它的。这意味着,桌子在行走时不会有太多的「颠簸」。当然,最小化颠簸也是连杆在进化过程中的适应度指标之一。
为了让它自行移动,作者订购了两个便宜的齿轮驱动的 24V 无刷电机,这类电机通常用于自动窗帘,输出最大 1.5 Nm @ 130 RPM。它们内置的电子设备还允许使用额外的 PWM 信号线直接控制速度。遗憾的是,当尝试让它们低速运行时,电机几乎立即进入了一种因温度过高而自动持续几秒的关机保护模式,即使仅在极小的负载下也是如此。幸运的是,将 PWM 信号保持在 100%,并直接改变电压,情况就好多了。如下图所示,作者直接将可调试的实验室电源连接到其中一个六腿部分的电机上。
为了能自动控制电机电压,作者购买了两个便宜的升降压转换器模块,这些模块可以将任何电池的电压转换成 0 至 24 伏之间的任意电压。然后,他对这些模块进行了改造,使它们的输出电压可以直接通过一个来自改造后的 Arduino Nano 微处理器板的快速 PWM 信号来设定。这些电压转换模块还提供了一个可调的最大电流设定功能,这使他能够对每个电机的最大堵转扭矩进行控制,从而确保了操作的安全性,尤其是保护了手指。
接下来,他将露出的霍尔效应电机传感器的信号接入了 Arduino 板,并用 C 语言编写了一套软件来实现自己的闭环电机控制系统。这样一来,电机现在能够独立且精确地控制到任何可能达到的速度和位置,而且这种控制不受负载的影响。

在最后一步,作者将一个蓝牙模块连接到 Arduino 上,并编写了一些 C 语言代码,使其能够连接并解析来自改造的无线 Nunchuck 操纵杆的数据。在安装了一个 14.8V 的锂电池之后,桌子就可以在客厅里任意走动了,作者通过一个小型遥控器控制桌子。
,时长00:17
最后,作者公开了他的连杆图纸,想要复制该项目的读者可以参考。

#Agent4SE
面向软件工程的AI智能体最新进展,复旦、南洋理工、UIUC联合发布全面综述
本篇综述的作者包括来自复旦大学 CodeWisdom 团队的研究生刘俊伟、王恺欣、陈逸轩和彭鑫教授、娄一翎青年副研究员,以及南洋理工大学的陈震鹏研究员和伊利诺伊大学厄巴纳 - 香槟分校(UIUC)的张令明教授。
自从首个全自动 AI 软件工程师 Devin 问世以来,面向软件工程的 AI 智能体广受关注、层出不穷,例如最近的 Genie、Replit、Cursor 等,它们正在对传统软件开发的范式产生着深刻影响。基于大模型的 AI 智能体(LLM-based Agents,后简称 Agent)通过增强推理、记忆、规划以及使用拓展工具的能力,极大地提升了大模型解决复杂软件开发维护任务的能力,为进一步实现自动化、智能化的软件开发提供了新思路。AI 智能体正在成为软件工程领域的研究新热潮。
复旦大学 CodeWisdom 团队联合南洋理工大学、UIUC 共同对 106 篇相关文献进行梳理和解读,分别从软件工程和 Agent 两个视角全面展现了 Agent 在软件工程领域的最新进展。从软件工程视角,该综述梳理了 Agent 在软件开发全周期各个任务上的应用现状;从 Agent 视角,该综述展示了目前应用于软件工程领域的 Agent 的基础架构、多智能体设计模式以及人机协同模式。最后,该综述展望了 Agent 在软件工程领域的研究机会与发展方向。

- 论文地址:https://arxiv.org/pdf/2409.02977
- Agent4SE 论文列表:https://github.com/FudanSELab/Agent4SE-Paper-List
一、Agent 覆盖软件开发维护全流程
如图 1 所示,目前 Agent 已基本覆盖了软件开发和维护的全流程,不仅可以解决某个特定的软件开发环节(例如静态检查和测试),而且在应对更复杂的端到端的软件开发和维护任务上也表现出了巨大潜力,包括:
- 端到端软件开发(End-to-end Software Development):Agent 通过执行多种开发子任务,包括需求工程、设计、代码生成和质量保证(包括静态检查和测试等),完成从需求到最终程序的全流程开发。
- 端到端软件维护(End-to-end Software Maintenance):Agent 支持多种维护活动,如故障定位、修复和特性维护,完成从问题报告到补丁生成的端到端维护。

图 1: 软件开发与维护任务流程上的 Agent 分布
端到端软件开发
目前面向端到端软件开发的 Agent 主要模拟真实的软件开发团队,设计不同的软件开发角色,互相协作共同完成软件开发任务。

表 1: 面向端到端软件开发任务的 Agent 文献列表
其中,有些 Agent 在工作流设计上主要遵循了现实软件开发中常见的软件过程模型,包括瀑布模型和敏捷开发(测试驱动开发和 Scrum)。

图 2: 面向端到端软件开发的 Agent 中采用的过程模型
端到端软件维护
目前,面向端到端软件维护任务的 Agent 遵循着 “缺陷定位 - 补丁生成 - 补丁验证” 的基本工作流程;在此基础上,不同 Agent 选择性地引入了预处理、故障重现、任务分解、补丁排名等步骤。

表 2: 面向端到端软件维护任务的 Agent 文献列表

图 3: 面向端到端软件维护任务的 Agent 中常用的工作流
这类 Agent 往往以 SWE-bench 及其衍生的数据集作为评测基准。

图 4: 端到端维护软件任务的数据集演化示意图
特定的软件开发 / 维护任务
除了端到端的软件开发和维护任务,目前 Agent 在面向单个特定的软件开发或维护环节也有着广泛应用,包括需求工程、代码生成、代码静态检查、测试、缺陷定位与修复等。该综述梳理了面向特定不同软件开发 / 维护任务的 Agent 的工作流。

图 5: 面向特定软件开发 / 维护环节的 Agent 工作流
二、面向软件工程的 Agent 设计
根据 Agent 的基础结构划分(即 规划(Planning)、记忆(Memory)、感知(Perception)、行动(Action)),该综述进一步总结目前面向软件开发和维护的 Agent 在每部分的设计特点。
Agent 中的常用工具
为了进一步提升 Agent 在软件开发和维护任务上的能力,目前 Agent 的行动模块中集成和使用了大量的工具,主要包括搜索、文件操作、静态程序分析、动态分析、测试、版本管理工具等。

图 6: 面向软件开发和维护的 Agent 中的常用工具分类
人机协作范式
目前在面向软件开发维护任务上,开发者和 Agent 的协作主要发生在规划、需求工程、开发和评估四个环节。主要的协同方式,是由人类提供反馈,引导、澄清或直接纠正 Agent 的输出。

图 7:面向软件开发和维护任务的 Human-Agent 协作范式
三、未来的研究方向
该综述进一步探讨了面向软件开发和维护的 Agent 的未来研究方向。
- 更全面的评测基准和更真实的评测数据。当前针对软工任务的 Agent 的评测主要集中在其端到端解决特定任务的能力上,缺少对决策过程和失败原因的深入分析,以及对鲁棒性等可信指标以及效率指标的关注。此外,当前用于评测 Agent 的数据集也存在一些问题,如逻辑过于简化,与现实场景相差较远等。因此,设计更多样化的评估指标和构建更高质量、更现实的数据集基准是准确评估 Agent 能力的重要方向。
- 探索人机协同新范式。当前针对软工任务的 Agent 人机协同主要局限于需求工程、设计、测试评估等环节,同时缺少对高效友好的交互接口的系统研究。因此,未来研究可关注于拓展人机协同的应用场景,以及提供更加流畅的人机协作模式。
- 多模态感知。目前针对软工任务的 Agent 主要依赖于文本或视觉感知。探索和整合多样化的感知模态,如语音命令或用户手势,会显著提高 Agent 编码助手的灵活性和可访问性。
- 将 Agent 应用于更多软工任务。尽管现有的 Agent 已经被部署在各种软工任务中,但一些关键阶段(如设计、验证和功能维护)仍未被充分探索,为这些阶段开发 Agent 系统可能会面临各方面的新挑战。
- 训练面向软件工程的基座大模型。目前 Agent 通常构建在以通用数据或者代码数据为主要训练数据的大模型之上,而软件开发的全周期往往涉及设计、架构、开发者讨论、程序动态执行、历史演化等代码以外的重要信息。有效利用这些信息可以构建面向软件工程领域的基座大模型,从而在此基础上构建更强大的面向软件开发与维护的 Agent。
- 将软件工程领域知识融入 Agent 设计。正如最近 Agentless 研究所揭示,流程复杂且高度自主的 Agent 在某些软件维护任务上的效果不如基于传统缺陷定位和程序修复流程所设计的简单工作流。软件工程领域的经典方法论和思想对于设计 Agent 的工作流有着重要的借鉴和指导意义,可以进一步提高 Agent 解决方案的有效性、鲁棒性和效率。
#端侧大模型的研究进展综述
边缘智能的新时代
- Jiajun Xu : Meta AI科学家,专注大模型和智能眼镜开发。南加州大学博士,Linkedin Top AI Voice,畅销书作家。他的AI科普绘本AI for Babies (“宝宝的人工智能”系列,双语版刚在国内出版) 畅销硅谷,曾获得亚马逊儿童软件、编程新书榜榜首。
- Zhiyuan Li : Nexa AI CTO,斯坦福校友,前斯坦福CEO协会主席, Octopus系列论文作者。他在 Google Labs 和 Amazon Lab126 拥有丰富的端侧 AI 模型训练、部署和产品开发经验。
- Wei Chen : Nexa AI CEO,斯坦福博士,前斯坦福CEO协会主席。他深耕人工智能领域,先后发表多篇Octopus系列模型论文,其中Octopus-V2模型曾在huggingface全球60万模型中位列第二,并在Google 2024 IO上被feature。
- Qun Wang : 旧金山州立大学计算机系助理教授,曾在劳伦斯伯克利国家重点实验室做博后,犹他州立大学博士。研究方向主要集中在下一代通信网络中边缘计算的能效和安全优化,以及边缘智能系统的通信和训练加速。先后在IEEE发布多篇论文。
- Xin Gao, Qi Cai : 北德州大学博士生
- Ziyuan Ling : Nexa AI 初创设计师,伯克利设计系研究生
1 序言:边缘智能的新纪元
在人工智能的飞速发展中,大型语言模型(LLMs)以其在自然语言处理(NLP)领域的革命性突破,引领着技术进步的新浪潮。自 2017 年 Transformer 架构的诞生以来,我们见证了从 OpenAI 的 GPT 系列到 Meta 的 LLaMA 系列等一系列模型的崛起,它们不仅在技术层面上不断刷新我们对机器理解与生成人类语言能力的认知,更在实际应用中展现出巨大的潜力和价值。
然而,这些模型传统上主要部署在云端服务器上,这种做法虽然保证了强大的计算力支持,却也带来了一系列挑战:网络延迟、数据安全、持续的联网要求等。这些问题在一定程度上限制了 LLMs 的广泛应用和用户的即时体验。正因如此,将 LLMs 部署在端侧设备上的探索应运而生,它不仅能够提供更快的响应速度,还能在保护用户隐私的同时,实现个性化的用户体验。
随着技术的不断进步,边缘 AI 市场的全球规模正以惊人的速度增长。预计从 2022 年的 152 亿美元增长到 2032 年的 1436 亿美元,这一近十倍的增长不仅反映了市场对边缘 AI 解决方案的迫切需求,也预示着在制造、汽车、消费品等多个行业中,边缘 AI 技术将发挥越来越重要的作用。

图 1:2022 年至 2032 年按终端用户划分的端侧 AI 全球市场规模(单位:十亿美元)。
在这样的背景下,本综述文章深入探讨了在边缘设备上部署 LLM 的策略和进展。我们将详细分析模型压缩技术、能效计算策略以及轻量级模型架构的创新设计。此外,文章还将讨论硬件加速策略、边缘 - 云协同部署方法,并重点介绍在边缘场景中有效利用 LLM 的部署策略,以及这些技术在行业中的应用实例和带来的益处。

- 论文标题:On-Device Language Models: A Comprehensive Review
- 论文链接:https://arxiv.org/abs/2409.00088
- 相关链接:LLMsOnDevice.com
通过本综述,我们希望为读者提供一份关于如何在端侧设备上部署和优化 LLMs 的全面指南,同时指出当前研究的方向和面临的挑战,为未来的技术发展提供参考和启示。我们相信,通过跨学科的共同努力,我们能够实现智能计算的普及。

图 2:本篇综述结构
2 技术进展:探索端侧 LLMs 部署
在人工智能的浪潮中,端侧大型语言模型(On-Device LLMs)正以其迅猛的发展速度和广泛的应用前景,成为技术革新的新宠。自 2023 年起,随着参数量低于 10B 的模型系列如 Meta 的 LLaMA、Microsoft 的 Phi 系列等的涌现,我们见证了 LLMs 在边缘设备上运行的可行性和重要性。这些模型不仅在性能上取得了长足的进步,更通过混合专家、量化和压缩等技术,保持了参数量的优化,为边缘设备的多样化应用场景提供了强大支持。
进入 2024 年,新模型的推出愈发密集,如图 3 所示,Nexa AI 的 Octopus 系列、Google 的 Gemma 系列等,它们不仅在文本处理上有所增强,更在多模态能力上展现了新的可能性,如结合文本与图像等多模态输入,以适应更复杂的用户交互需求。

图 3:on-device LLM 的演进,展示了自 2023 年以来的重要模型和发展里程碑。
然而,要在资源受限的设备上部署这些强大的模型,我们必须面对内存和计算能力的双重挑战。研究者们通过量化感知缩放、稀疏更新等创新方法,有效解决了这些问题,使得大型模型即便在参数量巨大的情况下,也能在设备端高效运行。
相较于完全依赖云端的 LLM 服务,端侧推理的优势显而易见。它不仅减少了数据传输的延迟,更保护了用户数据的隐私安全。图 4 的投票分布显示,大多数参与者更倾向于边缘云协作的架构,对现有仅云端的解决方案并不满意。端侧推理的低延迟特性,尤其适用于需要实时响应的应用场景,如 Google 的 Gemini Nano 支持的 TalkBack 功能,即便在完全离线的情况下也能正常工作。

图 4:用户对不同 LLM 部署方式的偏好情况
衡量端侧 LLMs 性能的指标包括延迟、推理速度、内存消耗等。这些指标直接关系到模型在边缘设备上的实际运行效果,以及用户的使用体验。随着技术的不断成熟,我们期待这些性能指标能得到进一步的优化,使得端侧大语言模型能在更多场景下发挥其潜力。
3 架构创新:优化边缘设备的性能
在智能手机和边缘设备上部署大型语言模型(LLMs)正成为人工智能领域的新挑战。面对有限的内存和计算能力,研究者们提出了一系列创新的架构设计原则和方法,旨在实现资源的高效利用和性能的最大化。架构创新变得尤为关键,其中包括参数共享、模块化设计以及紧凑的表示形式。例如,MobileLLM 通过深度和瘦长的模型结构优化了参数量在十亿以下的模型,而 EdgeShard 框架则通过边缘云协作计算实现了模型的分布式处理,显著降低了延迟并提高了吞吐量。
同时,模型压缩与参数共享技术的应用,如 AWQ 方法和 MobileLLM,不仅减少了模型尺寸,还在保持性能的同时加快了推理速度。这些技术通过保护关键权重和优化模型结构,为 LLMs 在端侧的部署提供了新的可能性。协作和层次化模型方法通过分散计算负载和利用不同能力模型的组合,解决了资源受限设备的部署难题。EdgeShard 和 LLMCad 的研究成果展示了这种方法的有效性,它们通过在多个设备上分配计算任务,提升了 LLMs 的可扩展性和效率。
在内存和计算效率的优化方面,Samsung Electronics 提出的 PIM 和 PNM 技术,以及 MELT 基础设施,都显著提升了内存带宽和容量,同时降低了能耗,为 LLMs 的移动部署铺平了道路。MoE 架构的应用,如 EdgeMoE 和 LocMoE,通过稀疏激活和动态路由,进一步提高了 LLMs 的效率。这些方法通过优化专家网络的选择和路由,减少了模型的内存占用和提高了计算速度。
此外,总体效率和性能提升的研究,如 Any-Precision LLM 和 LCDA 框架,通过提供多精度支持和软硬件协同设计,为 LLMs 在边缘设备上的高效运行提供了新的视角。随着这些创新技术的迅速发展,我们期待在移动设备和边缘设备上享受到与云端相媲美的智能体验,这将为用户带来更加快速、个性化的服务,同时确保数据的安全性和隐私保护。智能边缘计算的未来正变得愈发清晰,它将为人工智能领域带来深远的影响和无限的可能性。
4 模型压缩:平衡性能与效率
在边缘设备上部署大型语言模型(LLMs)时,保持性能的同时提升计算效率尤为关键。本文综述了四种关键的模型压缩技术:量化、剪枝、知识蒸馏和低秩分解,这些方法通过在性能、内存占用和推理速度之间找到平衡,确保了 LLMs 在端侧应用的可行性。
量化是一种通过降低模型权重和激活的精度来减少模型大小的技术。这种方法能够在几乎不损失模型性能的情况下,显著减少模型所需的存储空间和计算资源。后训练量化(PTQ)是一种在模型训练完成后应用的技术,它通过一些先进的补偿策略,如 GPTQ,可以在将模型权重量化到 3 或 4 位的情况下,保持模型的高准确度。而量化感知训练(QAT)则将量化集成到模型的训练过程中,使模型在训练时就适应低精度的约束,从而在量化后保持更高的准确度。
剪枝是另一种通过减少模型复杂性来提升计算效率的方法。结构化剪枝通过移除模型中的整个参数子集,如层、通道或过滤器,来优化硬件性能。无结构化剪枝则在更细的粒度上工作,移除单个权重,提供更高的压缩率。此外,上下文剪枝根据模型的运行上下文动态地移除权重,确保在不同条件下都能保持最优的性能。
知识蒸馏是一种将大型模型的知识迁移到小型模型的技术。黑盒 KD 只使用教师模型的输出进行学习,而白盒 KD 则允许学生模型访问教师模型的内部状态,实现更深入的学习。这种方法可以在不牺牲性能的情况下,显著减少模型的大小和计算需求。
低秩分解是一种将大型矩阵分解为较小矩阵的技术。这种方法利用了矩阵的低秩结构,减少了计算复杂性,同时保持了模型的准确性。Yao 等人的研究将 LRF 与 PTQ 结合,提出了低秩补偿(LoRC),在显著减少模型大小的同时,通过补偿策略保持了模型的准确性。
5 硬件加速:推动端侧 LLMs 的高效运行
硬件加速器在大型语言模型(LLMs)的端侧部署中扮演着至关重要的角色。GPU 和 TPU 等专用硬件提供了强大的计算能力和高内存带宽,它们是训练和加速 LLMs 的重要基础。NVIDIA 的 Tensor Cores 以及 Google TPU 的高效矩阵乘法能力,都为基于 Transformer 的模型提供了强有力的支持。同时,FPGA 以其灵活性,通过稀疏矩阵乘法和量化技术,在 Transformer 层的推理任务中展现出高效能,为特定模型架构提供了定制优化的可能。
软硬件协同设计的方法,如量化感知训练和模型压缩,进一步提升了 LLMs 的效率,使得它们能够跨越从高功率服务器到低功率边缘设备的广泛部署。这些技术通过参数共享和先进的内存管理,减少了模型的存储需求,确保了快速且成本效益更高的部署。此外,各种框架如 Llama.cpp、MNN、PowerInfer 等,根据不同的硬件平台和用例需求,提供了优化的部署策略,从而实现从云端到边缘的无缝协作。
在边缘云部署方面,MLC-LLM 和 VLLM 等技术通过支持高效的量化方法和关键内存管理,优化了 LLMs 在边缘设备和云环境中的部署。OpenLLM 等项目通过 BentoML 等工具,实现了开源 LLMs 的快速部署,提供了与 OpenAI 兼容的 API 服务。随着硬件技术的不断进步,如 NVIDIA A100 GPU 和 Google TPU v4,我们看到了端侧 LLMs 性能的显著提升,这些硬件不仅提供了巨大的计算能力,还通过混合精度训练等技术,大幅减少了模型的内存占用并提高了计算效率。
6 实例与应用:端侧 LLMs 的实践探索
端侧语言模型的实例:Gemini Nano 模型通过 Google AI Edge SDK 为移动操作系统提供了一个小型但功能强大的 LLM,它通过 4 位量化部署,提供了一流的性能和低延迟的推理速度。Nexa AI Octopus 系列模型则在边缘设备上运行,以超越 GPT-4 的准确性和延迟,同时减少了 95% 的上下文长度。Apple 的 OpenELM 和 Ferret-v2 模型通过 iOS 集成,提供了类似系统服务的功能扩展。Microsoft 的 Phi 系列,特别是 Phi-3-mini 模型,即使在移动部署中也展现出与大型模型相媲美的性能。此外,MiniCPM-Llama3-V 2.5 和 Gemma2-9B 等开源模型也在各自的领域内展现出卓越的性能。
端侧大语言模型的应用:端侧 LLMs 的应用范围极为广泛,从即时消息生成、实时语言翻译、会议摘要到医疗咨询、科研支持、陪伴机器人、残障人士辅助以及自动驾驶等。例如,Google 的 Gboard 应用利用 Gemini Nano 模型提供基于聊天内容的快速回复建议。在翻译领域,端侧模型能够在离线环境中快速响应,同时保证翻译质量。会议摘要应用通过分析会议内容,实时生成摘要,避免了云模型订阅服务费用和网络延迟问题。在医疗领域,端侧模型能够在本地处理患者数据,保护隐私同时提供紧急情况下的快速响应。
科研支持方面,端侧 LLMs 能够利用特定领域的大量专业数据进行训练,加速科研进展。陪伴机器人和 IoT 设备通过端侧 LLMs 提升了理解自然语言指令的能力。对于视障人士,端侧多模态模型能够将图像转换为文字,提供丰富的图像描述,并支持离线使用。此外,手语识别和翻译项目也利用了端侧模型的低延迟和离线可用性。
自动驾驶领域,结合大规模视觉语言模型的系统正在改善车辆对复杂和长尾场景的理解,提供即时响应并处理动态场景。

图 5 展示了端侧 LLMs 在不同应用领域的表现,从文本生成、翻译、会议摘要、医疗应用、科研支持、伴侣机器人、残障人士辅助到自动驾驶等,端侧 LLMs 正以其智能、响应迅速和个性化的特点,改变我们与技术的互动方式。
7 未来展望:边缘计算的智能转型

图 6:on-device LLM 的未来方向和面临的挑战
在设备上运行的大型语言模型(LLMs)正迅速发展,它们在数据安全、低延迟和个性化 AI 体验方面展现出巨大潜力。然而,要在资源受限的设备上部署这些模型,我们必须克服包括模型压缩、高效推理、安全性和能源效率等一系列挑战。未来的研究将致力于开发新的隐私保护技术,如查询混淆和先进的随机化技术,同时加强风险评估和监控,以确保模型的实用性和数据的安全性。此外,研究者们也在探索适应性边缘 - 云协作,通过智能缓存、请求分析和资源分配算法,优化数据在边缘设备与云服务器间的传输。
多模态和跨模态学习是推动 LLMs 发展的关键方向,它们使模型能够整合并理解多种数据类型,从而提供更丰富的用户体验。研究者们正致力于开发高效的多模态处理技术,以及能够适应不同模态输入的模型架构。同时,资源效率也成为研究的重点,通过模型压缩和执行算法的优化,以及利用模型稀疏性,可以显著降低模型在边缘设备上的能源消耗,这对环境保护具有重要意义。
为了进一步提升 LLMs 的性能,硬件 - 软件的协同设计变得至关重要。未来的研究将探索新的 PIM/PNM 架构,以及针对 AI 特定需求优化的编译器和运行时系统。此外,确保模型的鲁棒性和可靠性也是未来工作的重点,研究者们正在开发方法以检测和减轻模型输出中的偏见和幻觉,特别是在安全关键的应用中。
个性化 AI 体验是设备上 LLMs 的另一大优势,但这也带来了模型持续学习和适应新信息的挑战。未来的研究将集中于实现知识保留和遗忘的可控机制,以及开发持续学习的理论基础和优化策略。通过这些机制,模型能够根据用户交互和本地数据自主学习新技能,并提高现有能力。
8 结语
在设备上部署的大型语言模型(LLMs)正开启智能边缘计算的新篇章,预示着一个个性化、高效的 AI 时代即将到来。这些模型通过强化数据安全、降低延迟,并提供深度个性化的体验,将彻底改变我们与技术的互动。展望未来,随着技术的不断成熟,我们期待一个设备更智能、服务更精准、生活更便捷的新世界。个性化的 AI 将融入日常生活的方方面面,从智能家居到自动驾驶,从虚拟助手到健康监护,它们将以前所未有的方式提升我们的生活品质。随着研究的深入,一个更智能、更可靠、更贴近人心的 AI 未来正向我们招手,让我们满怀期待,迎接这个由 LLMs 引领的创新纪元。
为了进一步促进学术交流和知识共享,我们建立了一个专门的 GitHub 资源库 ——Awesome LLMs on Device。这个资源库不仅收录了本论文的详细内容,还将持续更新,以反映该领域的最新研究成果和技术动态。
诚邀学术界同仁访问我们的 GitHub 资源库,参与到 LLMs 在边缘设备上的研究中来,共同推动智能边缘技术的创新与发展。
Github Repo:https://github.com/NexaAI/Awesome-LLMs-on-device
#World Labs
李飞飞任CEO,空间智能公司World Labs亮相,全明星阵容曝光
World Labs 的创始团队中,有 ImageNet、NeRF、Style Transfer 和 Gaussian Splats 作者在列。
人工智能的下个大方向已经出现,标志性学者决定下场创业。
本周五,一个重磅消息引爆了 AI 圈:斯坦福大学计算机科学家李飞飞正式宣布创办 AI 初创公司 ——World Labs,旨在向人工智能系统传授有关物理现实的深入知识。
李飞飞说道:在 AI 领域中,真正难以解决的问题是什么?我的答案是空间智能 —— 这项技术可以赋能和实现创作、设计、学习、AR/VR、机器人等领域的无数可能用例。
为此,李飞飞与三位联合创始人 Justin Johnson、Christoph Lassner、Ben Mildenhall,以及一支世界级图像技术团队共同合作成立实验室,致力于解决这个大自然花费五亿年才解决的超级难题。
当前的生成式人工智能是基于语言的,而李飞飞看到了一个前沿领域,即系统利用物理、逻辑和物理现实的丰富细节构建完整的世界。
今年 5 月,李飞飞创业的消息首次曝光。尽管可能还需要一年的时间才能推出产品,但 World Labs 已收获多达 2.3 亿美元的投资。据报道,这家新兴初创公司的估值为 10 亿美元。
World Labs 的探索方向是李飞飞研究的进一步延伸。自 2007 年起,李飞飞等人基于超前的眼光创建了 ImageNet,帮助人工智能扭转了局面,ImageNet 是一个定制的数字图像数据库,是测量图片类应用运行准度、效率的行业标杆。它催生出了一系列先进的神经网络。李飞飞认为,如果人工智能要创造现实世界,无论是现实的模拟还是完全想象的宇宙,今天的深度学习模型也需要类似的推动。
李飞飞介绍道:「计算机的物理世界是通过摄像机看到的,而计算机大脑则位于摄像机后面。将愿景转化为推理、生成和最终的交互需要理解物理结构、物理世界的物理动力学。这项技术被称为空间智能。」
World Labs 的描述是一家空间智能公司,它的未来将决定空间智能是否会引发一场革命。
多年来,李飞飞一直对空间智能有着执着的追求。当大家都在为 ChatGPT 疯狂时,她和她的学生 Justin Johnson 却在电话里兴奋地讨论着 AI 的下一次迭代。Johnson 现为密歇根大学的助理教授,他表示:「未来十年将是创造全新内容的时代 ,这些内容会将计算机视觉、深度学习和 AI 从互联网世界带入真实的空间和时间。」
在与虚拟网络先驱 Martin Casado 共进晚餐后,李飞飞决定在 2023 年创办一家公司。Casado 如今是 Andreessen Horowitz 的合伙人,这家风投公司以其对 AI 近乎狂热的推崇而声名远扬。
World Labs 的愿景介绍
在组建团队时,Johnson 作为联合创始人加入。Casado 还推荐了 Christoph Lassner 和 Ben Mildenhall。前者曾在亚马逊、Meta 的 Reality Labs 和 Epic Games 工作,是渲染方案 Pulsar 的提出者。后者创造了一项强大的技术 —— 神经辐射场(NeRF),他离开谷歌的高级研究科学家职位,加入了这个新团队。
World Labs 的四位创始人。
最近,具身智能正在升温,使用大型世界模型进行训练,或许可以赋予机器人「世界感」。这确实在 World Labs 的计划之中,但成型还需要一段时间。在人们的预测中,第一阶段是构建一个对三维性、物理性以及空间和时间概念有深刻理解的 AI 模型。接下来,模型将支持增强现实技术。之后,World Labs 将进军机器人领域。如果这一愿景得以实现,大型世界模型将有助于改进自动驾驶汽车、自动化工厂,甚至可能推动类人机器人的发展。
前路漫漫,并且路途上困难重重。World Labs 承诺会在 2025 年推出产品。面对外媒连线记者提问「World Labs 将如何盈利」时,创始人李飞飞回应:「现在只是刚起步,有很多边界需要突破,还有许多未知的问题需要解决,当然,我们是全球最优秀的团队,能够解决这些未知问题。」
Casado 则给出了更具体的解释。他指出,像 ChatGPT 或 Anthropic 的 Claude 一样,模型本身就可以作为产品,作为一个供他人直接使用的平台,或者托管其他应用程序的平台。客户可能包括游戏公司或电影制片厂。
World Labs 并不是唯一一家涉足所谓「物理 AI」的公司。英伟达 CEO 黄仁勋在今年的 GTC 大会上就曾表示,为通用人形机器人构建基础模型是当今 AI 领域最令人兴奋的问题之一。
但 Casado 坚持认为,World Labs 的雄心、人才和愿景是独一无二的。「我已经做投资快 10 年了,这是我遇到过最强的团队,没有之一。」风投支持自己的投资是很常见的,但 Casado 不仅仅是投入资金:自从成为投资人以来,他首次作为兼职团队成员,每周花一天时间在公司里。
其他的投资公司也纷纷入局, 包括 Radical Ventures、NEA,值得关注的是还有英伟达的风险投资部门。此外,还有一长串明星级别的天使投资人,阵容包括 Marc Benioff、Reid Hoffman、Jeff Dean、Eric Schmidt、Ron Conway 以及 Geoff Hinton。看到 Hinton 出现在这里,可以说是 AI 教父正在支持 AI 教母。
在李飞飞宣布成立创业公司后,很多 AI 领域的知名学者纷纷发来祝贺,其中也有很多是她的学生。
OpenAI 创始成员、前特斯拉 AI 高级总监 Andrej Karpathy 表示:我在攻读博士学位期间与李飞飞和 Justin Johnson 共度了很长一段时间。我非常怀念这段时光,李飞飞是我的导师,也是我们无畏的领导者,Justin 和我一起撰写论文,我们三人共同开发了 CS231n 课程的第一个版本。World Labs 团队是顶级的,我很高兴看到他们采用当今的前沿研究并将 AI 扩展到 3D 领域!
英伟达资深研究科学家、AI 智能体项目负责人 Jim Fan 说道:李飞飞对具身智能的看法极大地影响了我的博士课程和研究品味。空间智能是计算机视觉和具身智能体的下一个前沿!
众多大佬看好,World Labs 的目标会成为人工智能的下一个大方向吗?
我们或许还需要等待。从一个角度来看,World Labs 的承诺与此前热炒过的词汇:元宇宙有些相似。不过 World Labs 的创始人认为,那场短暂的热潮来得太早,只是基于一些有前景的硬件,但缺乏真正的互动内容。他们暗示,世界模型或许能够解决这一问题。
另一方面,在大模型技术爆发后,大量新势力车企已经开始把自动驾驶技术的方向转向世界模型与端到端方案,探索具身智能的机器人创业公司也成批出现。越来越多的实践正在告诉我们:新方法已经展现出了跨代的优势。
可以想象,在这些世界里,AI 绝不会停滞不前。
参考内容:
https://x.com/drfeifei/status/1834584286932181300
https://www.wired.com/story/plaintext-the-godmother-of-ai-wants-everyone-to-be-a-world-builder/
#Scaling Law
OpenAI o1的价值意义及强化学习的Scaling Law
蹭下热度谈谈 OpenAI o1 的价值意义及 RL 的 Scaling law。
一、OpenAI o1 是大模型的巨大进步
我觉得 OpenAI o1 是自 GPT 4 发布以来,基座大模型最大的进展,逻辑推理能力提升的效果和方法比预想的要好,GPT 4o 和 o1 是发展大模型不同的方向,但是 o1 这个方向更根本,重要性也比 GPT 4o 这种方向要重要得多,原因下面会分析。
为什么说 o1 比 4o 方向重要?
这是两种不同的大模型发展思路,说实话在看到 GPT 4o 发布的时候我是有些失望的,我当时以为 OpenAI 会优先做 o1 这种方向,但是没想到先出了 GPT 4o。GPT 4o 本质上是要探索不同模态相互融合的大一统模型应该怎么做的问题,对于提升大模型的智力水平估计帮助不大;而 o1 本质上是在探索大模型在 AGI 路上能走多远、天花板在哪里的问题,很明显第二个问题更重要。
GPT 4o 的问题在于本身大模型的智力水平还不够高,所以做不了复杂任务,导致很多应用场景无法实用化,而指望靠图片、视频这类新模态数据大幅提升大模型智力水平是不太可能的,尽管确实能拓展更丰富的多模态应用场景,但这类数据弥补的更多是大模型对外在多模态世界的感知能力,而不是认知能力。提升大模型认知能力主要还要靠 LLM 文本模型,而提升 LLM 模型认知能力的核心又在复杂逻辑推理能力。LLM 的逻辑推理能力越强,则能解锁更多复杂应用,大模型应用的天花板就越高,所以不遗余力地提升大模型尤其是文本模型的逻辑能力应该是最重要的事情,没有之一。
如果 o1 模型能力越做越强,则可以反哺 GPT 4o 这种多模态大一统模型,可以通过直接用 o1 基座模型替换 GPT 4o 的基座、或者利用 o1 模型生成逻辑推理方面的合成数据增强 GPT 4o、再或者用 o1 蒸馏 GPT 4o 模型….. 等等,能玩的花样应该有很多,都可以直接提升 GPT 4o 的复杂任务解决能力,从而解锁更复杂的多模态应用场景。OpenAI 未来计划两条线,一条是 o1,一条是 GPT 4o,它的内在逻辑大概应该是这样的,就是说通过 o1 增强最重要的基座模型逻辑推理能力,而再把这种能力迁移到 GPT 4o 这种多模态通用模型上。
OpenAI o1 的做法本质上是 COT 的自动化。
我们知道,通过 COT 把一个复杂问题拆解成若干简单步骤,这有利于大模型解决复杂逻辑问题,但之前主要靠人工写 COT 来达成。从用户提出的问题形成树的根结点出发,最终走到给出正确答案,可以想像成类似 AlphaGo 下棋,形成了巨大的由 COT 具体步骤构成的树形搜索空间,这里 COT 的具体步骤的组合空间是巨大的,人写的 COT 未必最优。如果我们有大量逻辑数据,是由 <问题,明确的正确答案> 构成,则通过类似 AlphaGo 的 Monte Carlo Tree Search(MCTS)搜索 + 强化学习,确实是可以训练大模型快速找到通向正确答案的 COT 路径的。
而问题越复杂,则这个树的搜索空间越大,搜索复杂度越高,找到正确答案涉及到的 COT 步骤越多,则模型生成的 COT 就越复杂,体现在 o1 的速度越慢,生成的 COT Token 数越多。很明显,问题越复杂,o1 自己生成的隐藏的 COT 越长,大模型推理成本越高,但效果最重要,成本其实不是问题,最近一年大模型推理成本降低速度奇快,这个总有办法快速降下去。
从上面 o1 的做法可以知道 Prompt 工程会逐渐消亡。
之前解决复杂问题,需要人写非常复杂的 Prompt,而 o1 本质上是 COT 等复杂 Prompt 的自动化,所以之后是不太需要用户自己构造复杂 Prompt 的。本来让用户写复杂 Prompt 就是不人性化的,所有复杂人工环节的自动化,这肯定是大势所趋。
Agent 属于概念火但无法实用化的方向,主要原因就在于基座模型的复杂推理能力不够强。如果通过基座模型 Plan 把一个复杂任务分解为 10 个步骤,哪怕单个步骤的正确率高达 95%,要想最后把任务做对,10 个环节的准确率连乘下来,最终的正确率只有 59%,惨不忍睹。那有了 o1 是不是这个方向就前途坦荡?也是也不是,o1 的 Model Card 专门测试了 Agent 任务,对于简单和中等难度的 Agent 任务有明显提升,但是复杂的、环节多的任务准确率还是不太高。就是说,不是说有了 o1 Agent 就现状光明,但是很明显 o1 这种通过 Self Play 增强逻辑推理能力的方向应该还有很大的发展潜力,从这个角度讲说 Agent 未来前途光明问题应该不大。
OpenAI 很多时候起到一个行业指路明灯的作用,往往是第一个证明某个方向是行得通的(比如 ChatGPT、GPT 4、Sora、GPT 4o 包括这次的 o1),然后其他人开始疯狂往这个方向卷,到后来甚至卷的速度太快把 OpenAI 都甩到后面吃尾气。典型例子就是 Sora,如果 OpenAI 不是出于阻击竞争对手秀一下肌肉,大家都没有意识到原来这个方向是可以走这么远的,但当意识到这一点后,只要你专一地卷一个方向,方向明确且资源聚焦,是可能赶超 OpenAI 的,目前国内外各种视频生成模型有些甚至可能已经比 Sora 好了,Sora 至今仍然是期货状态,主要 OpenAI 想做的方向太多,资源分散导致分到具体一个方向的资源不够用,所以越往后发展期货状态的方向越多,也让人觉得尽显疲态。
OpenAI o1 等于给大家又指出了一个前景光明的方向,估计后面大家又开始都往这个方向卷。我觉得卷这个方向比去卷 GPT 4o 和视频生成要好,虽然具体怎么做的都不知道,但是大方向清楚且效果基本得到证明,过半年肯定头部几家都能摸清具体技术追上来,希望能再次让 OpenAI 吃尾气。而且这个方向看上去资源耗费应该不会特别大,偏向算法和数据一些,数据量规模估计不会特别巨大,卷起来貌似成本低一些。这是个卷的好方向。
二、预训练 Scaling Law 的来源及 O1 提到的 RL Scaling law
粗分的话,大语言模型最基础的能力有三种:语言理解和表达能力、世界知识存储和查询能力以及逻辑推理能力(包括数学、Coding、推理等理科能力,这里 Coding 有一定的特殊性,是语言能力和逻辑掺杂在一起的混合能力,Coding 从语言角度可以看成一种受限的自然语言,但是混杂着复杂的内在逻辑问题。从语言角度看,Coding 貌似是容易解决的,从逻辑角度看又相对难解决。总之,Coding 目前看是除了语言理解外,大模型做得最好的方向)。
语言理解和表达是 LLM 最强的能力,初版 ChatGPT 就可以完全胜任各种纯语言交流的任务,基本达到人类水准,目前即使是小模型,在这方面比大模型能力也不弱;世界知识能力虽说随着模型规模越大效果越好,但幻觉问题目前无法根治,这是制约各种应用的硬伤之一;逻辑推理能力一直都是 LLM 的弱项,也是最难提升的方面,从 GPT 4 开始往后,如何有效并大幅提升 LLM 的逻辑推理能力是体现不同大模型差异和优势的最核心问题。所以,大模型最重要的一个是世界知识方面如何有效消除幻觉,一个是如何大幅提升复杂逻辑推理能力。语言能力已不是问题。
从大模型的基础能力,我们再说回已经被谈滥了的大模型 Scaling law。现在普遍认为通过增加数据和模型规模来提升大模型效果的 Scaling law 模式,其增长速度在放缓。其实我们对照下大模型的三个基础能力的能力来源,基本就能看出来这是为啥(以下是我猜的,不保真):
本质上大模型的能力来源都来自训练数据,包含能体现这方面能力的训练数据越多,则这种能力越强。语言能力不用说了,任意一份预训练数据,其中都包含相当比例的语言的词法句法等成分,所以训练数据中体现语言能力的数据是最多的,这也是为何大模型的语言能力最强的原因。
而数据中包含的世界知识含量,基本是和训练数据量成正比的,明显数据量越多,包含的世界知识越多,Scaling law 是数据中包含的世界知识含量关系的一个体现,但是这里有个问题,大模型见过越多数据,则新数据里面包含的新知识比例越小,因为很多知识在之前的数据里都见过了,所以随着数据规模增大,遇到的新知识比例就越低,在世界知识方面就体现出 Scaling law 的减缓现象。
为啥逻辑推理能力最难提升?因为能体现这方面的自然数据(代码、数学题、物理题、科学论文等)在训练数据中比例太低,自然大模型就学不好,尽管通过不断增加数据,能增加逻辑推理方面数据的绝对数量,但因为占比太少,这方面提升的效果和增加的总体数据规模就不成比例,效果也不会太明显,就体现在逻辑推理能力 Scaling law 看上去的放缓。这是很自然的。这也是为何现在为了提高模型逻辑能力,往往在预训练阶段和 Post-training 阶段,大幅增加逻辑推理数据占比的原因,且是有成效的。
所以目前大模型的核心能力提升,聚焦到不断通过合成数据等方式构造更多比例的逻辑推理数据上来。但是大部分逻辑推理数据的形式是 < 问题,正确答案 >,缺了中间的详细推理步骤,而 o1 本质上是让大模型学会自动寻找从问题到正确答案的中间步骤,以此来增强复杂问题的解决能力。
OpenAI o1 提到了关于 RL 在训练和推理时候的 Scaling law,并指出这与预训练时候的 Scaling law 具有不同特性。很明显,如果 o1 走的是 MCTS 搜索技术路线,那么把 COT 拆分的越细(增加搜索树的深度),或提出更多的可能选择(节点的分支增多,就是说树的宽度越宽),则搜索空间越大,找到好 COT 路径可能性越大,效果越好,而训练和推理的时候需要算力肯定越大。看上去有着效果随着算力增长而增长的态势,也就是所谓的 RL 的 Scaling law。这其实是树搜索本来应有之义,我倒觉得把这个称为 RL 的 Scaling law 有点名不副实。
#Vec2Face
首次!用合成人脸数据集训练的识别模型,性能高于真实数据集
研究动机
一个高质量的人脸识别训练集要求身份 (ID) 有高的分离度(Inter-class separability)和类内的变化度(Intra-class variation)。然而现有的方法普遍存在两个缺点:
1)实现了大的 intra-class variation,但是 inter-class separability 很低;
2)实现了较高的 inter-class separability,但是 intra-class variation 需要用额外的模型来提高。
这两点要么使得在合成的人脸数据集训练的模型性能表现不佳,要么难以合成大型数据集。
因此,我们通过让提出的 Vec2Face 模型学习如何将特征向量转化为对应的图片,并且在生成时对随机采样的向量加以约束,来实现高质量训练集的生成。这一方法不但可以轻松控制 inter-class separability 和 intra-class variation,而且无需额外的模型进行辅助。此外我们还提出了 Attribute Operation algorithm 来定向的生成人脸属性,这一优势也可以被用来补足各类人脸任务的数据缺陷。
- 论文链接: https://arxiv.org/abs/2409.02979
- 代码链接: https://github.com/HaiyuWu/Vec2Face
- Demo 链接: https://huggingface.co/spaces/BooBooWu/Vec2Face
本文的亮点可以归纳为:
- 此工作提出的 Vec2Face 模型首次实现了从特征向量生成图片的功能,并且向量之间的关系,如相似度,和向量包含的信息,如 ID 和人脸属性,在生成的图片上也会得到继承。
- Vec2Face 可以无限生成不同身份 (synthetic ID) 的图像!之前的生成式模型 (GAN, Diffusion model, Stable diffusion model) 最多只能生成 8 万个不同身份的图像 [1]。本文利用 Vec2Face 生成了来自于 300K 个人的 15M 张图片。
- 用 Vec2Face 生成的 HSFace10k 训练的模型,首次在人脸识别的年龄测试集 (CALFW) 上实现了性能超越同尺度的真实数据集 (CASIA-WebFace [2])。另外,当合成数据集的 ID 数量大于 100k 后,训练的人脸识别模型在毛发测试集 (Hadrian) 和曝光度测试集 (Eclipse) 上也同样超越了 CASIA-WebFace。
主要实验
性能对比
我们在 5 个常用的人脸识别测试集 LFW [3]、CFP-FP [4]、AgeDB [5]、CALFW [6]、CPLFW [7] 上和现有的合成数据集进行了对比。

表一:对比用 Diffusion models,3D rendering,和 GAN 方法 (从上到下) 生成的合成数据集的性能。
第一:我们在生成的 0.5M 图片规模的训练集在上实现了 state-of-the-art 的平均精度(92%),并且在 CALFW 上超越了真实数据集 (CASIA-WebFace) 的精度。这证明了我们方法的有效性。第二:之前的最好的方法 Arc2Face [8] 使用了 Stable Diffusion V1.5 并且在 WebFace42M [9] 上进行微调,而我们的方法仅用了 1M 的数据进行训练。这足以证明我们方法的高效性和有效性。第三:HSFace 首次实现了 GAN 范式训练超过其他范式。
扩大数据集的有效性
因为 Vec2Face 可以无限生成不同的身份 (ID),所以我们对 Vec2Face 的 scalability 进行了测试。我们分别生成了 1M (20K ID),5M (100K ID),10M (200K ID) 和 15M (300K ID) 的数据集。在这之前最大的人脸合成训练集仅有 1.2M (60K ID)。

表二:测试 Vec2Face 在 scalability 上的表现。
从结果上看,当我们通过生成更多的 ID 来扩大数据集后,精度也随之提高,并且提高的趋势并未衰减!这证明 Vec2Face 能够有效的生成不同的身份。
计算资源对比
理论上来说,Arc2Face 也可以实现无限 ID 的生成并且扩大数据集。然而由于 SD 需要大量的计算资源来合成人脸,这在实际应用上并不高效。具体对比如下:

表三:对比 Arc2Face 和 Vec2Face 的模型大小,推理速度和 FID。对于 Arc2Face,我们使用 LCM-lora [10] 作为 scheduler 来生成图片。
对比结果显示,即使使用 4 步的 scheduler,Vec2Face 达到了 Arc2Face 的 311 倍同时保持了更高的与原图分布的相似度。
Vec2Face 的训练和生成方法
Vec2face 的训练
数据集:从 WebFace4M 中随机抽取的 5 万个人的图片。
方法逻辑:因为人脸识别模型是将人脸图像在高维空间 (512-dim) 聚类来实现 Open-set 的识别,并且由于高维空间的稀疏性,其空间内的身份总数要远远大于训练时所用的个数。因此在高维空间随机提取向量并且保证较低的相似度,那么就可以确保身份的独特性。还因为,人脸识别模型提取出的特征向量里不仅包含了身份信息,还包含了人脸属性等信息,所以对身份向量加小幅度的噪声

就可以在保证身份一致的前提下实现人脸属性的变化。因此,我们需要训练一个可以解码特征向量里的信息并且能够生成对应图片的模型。

Vec2Face 训练和推理框架。
为了让模型充分理解特征向量里的信息,我们的输入仅用预训练的人脸识别模型提取出来的特征向量(IM feature)。随后将由特征向量扩展后的特征图(Feature map)输入到 feature masked autoencoder(fMAE),来获取能够解码成图片的特征图。最后用一个图片解码器(Image decoder)来生成图片。整个训练目标由 4 个损失函数组成。

用于缩小合成图

和原图

之间的距离:


用于缩小合成图和原图对于人脸识别模型的相似度:

感知损失

[11] 和

用于提高合成图的图片质量。我们使用 patch-based discriminator [12, 13] 来组成 GAN 范式训练。
生成
因为 Vec2Face 仅需输入特征向量(512-dim)来生成人脸图片并且能够保持 ID 和部分人脸属性的一致,所以仅需采样 ID vector 并确保

即可保证生成的数据集的 inter-class separability。至于 intra-class variation,我们仅需在 ID vector 加上轻微的扰动 就能够在身份一致的情况下实现图片的多样性。
然而,由于在训练集里的大部分图像的头部姿态都是朝前的(frontal),这使得增加随机扰动很难生成大幅度的头部姿态(profile)。因此,我们提出了 Attribute Operation(AttrOP)算法,通过梯度下降的方法调整 ID vector 里的数值来使得生成的人脸拥有特定的属性。

Eq.5:

其他实验
AttrOP 的影响

我们通过 AttrOP 来定向提高生成的人脸质量和对应的头部姿态的变化。这一方法能够有效的大幅提高最终模型的性能。另外,增加头部姿态的变化度的同时也提高了在年龄测试集上的表现,从而实现了对真实数据集性能的超越。
衡量现有合成数据集的身份分离度

身份分离度是衡量数据集质量的重要指标。此实验衡量了 Vec2Face 和其他现有合成数据集内身份的分离度。具体过程:1)我们通过使用人脸识别模型提取出数据集里图片的特征;2)将他们的图片特征取平均来计算出身份特征;3)计算身份与身份之间的相似度;4)我们统计了所有身份与其他身份相似度相似度小于 0.4 的个数,从而衡量分离度。结果显示,Vec2Face 能够实现和真实数据集 WebFace4M 相同的分离度。这一优势为数据集的质量提供了保障。
Noise 采样中 σ 对于精度的影响

在本文中,σ 的大小对于 noise 的采样起到了直接的影响,从而影响到人脸属性的变化程度。于是我们对它的大小做了消融实验。结果显示,当σ 过小时 (=0.3) 和 σ过大时 (0.3, 0.5, 0.9),性能出现了大幅下降。从生成的结果上来说,过小的 σ 无法提供足够的人脸属性变化从而降低模型的泛化能力。过大的 σ 无法保持身份的一致,这会使模型无法学习到好的表达。因此,选择合适的采样范围至关重要。
ID 分离度对于精度的影响 (Avg. ID sim 越大,分离度越小)

这个实验研究了身份分离度对于精度的影响。虽然身份分离度的重要性是共识,但是目前为止并未有工作来验证它的真实性。因此,我们控制了数据集种身份与身份之间的平均相似度来进行消融实验。结果显示,高的分离度会大幅降低最终识别模型的性能,而过低的分离度也无法持续对最终性能提供帮助。
在其他识别测试集上 HSFace 和 CASIA-WebFace 的性能对比

因为前文的 5 个测试集只有对头部姿态变化和年龄变化的测试,为了更广泛的对比真实数据集和 HSFace 在其他人脸属性变化上的表现,我们引入了 Hadrian (面部毛发),Eclipse (面部光照),SSLFW (相似外表),和 DoppelVer (分身)。在 Hadrian 和 Eclipse 上,我们通过扩大数据集的规模最终超越了真实数据集的性能。然而,在 SSLFW 和 DoppelVer 上,我们并未实现超越。这一表现引出了另一个哲学方面的思考:目前来说,身份 (ID) 是由相似度进行定义。然而对于双胞胎,分身,近亲等,他们之间的人脸相似度会非常高但是他们又是不同的身份。这就暴露出单纯的用相似度来定义身份的缺点。因此,如何更好的定义不同的身份对于未来的工作至关重要。
#电力、芯片制造、数据和延迟成四大限制因素
Scaling Law能续到2030年吗?
近年来,人工智能模型的能力显著提高。其中,计算资源的增长占了人工智能性能提升的很大一部分。规模化带来的持续且可预测的提升促使人工智能实验室积极扩大训练规模,训练计算以每年约 4 倍的速度增长。
从这个角度来看,人工智能训练计算的增长速度甚至超过了近代史上一些最快的技术扩张。它超过了移动电话采用率(1980-1987 年,每年 2 倍)、太阳能装机容量(2001-2010 年,每年 1.5 倍)和人类基因组测序(2008-2015 年,每年 3.3 倍)的峰值增长率。
在最近的一份报告中,Epoch AI 研究了当前人工智能训练规模的快速增长(约每年 4 倍)在 2030 年之前是否始终在技术上可行。
报告提到了可能制约扩展的四个关键因素:电源可用性、芯片制造能力、数据稀缺性和「延迟墙」(人工智能训练计算中不可避免的延迟所造成的基本速度限制)。

报告中的分析包括生产能力的扩张、投资和技术进步。除其他因素外,这包括审查先进芯片封装设施的计划增长、额外发电厂的建设以及数据中心利用多个电力网络的地理分布。为了考虑这些变化,报告纳入了各种公开来源的预测:半导体代工厂的扩张计划、电力供应商的产能增长预测、其他相关行业数据以及自己的一些研究。
他们发现,到本个十年末,2e29 FLOP 的训练运行或许是可行的。换句话说,到 2030 年,我们将很有可能训练出规模超过 GPT-4 的模型,与 GPT-4 在规模上超过 GPT-2 的程度相同。如果继续努力,到本个十年末,我们可能会看到人工智能的巨大进步,就像 2019 年 GPT-2 的简陋文本生成与 2023 年 GPT-4 的复杂问题解决能力之间的差异一样。
当然,人工智能开发者是否真的会追求这种水平的扩展,取决于他们是否愿意在未来几年投资数千亿美元用于人工智能的扩展。但这不是报告讨论的重点。
在整个分析过程中,报告假定训练运行可持续 2 到 9 个月,这反映了持续时间越来越长的趋势。报告还假设,在为分布式训练和芯片分配人工智能数据中心电力时,公司只能获得现有供应量的 10% 到 40% 左右。
制约扩展的四个关键因素
电力限制
人们已经讨论过,到 2030 年数据中心园区达到 1 至 5 GW 的计划,这将支持 1e28 至 3e29 FLOP 的训练运行(作为参考,GPT-4 可能在 2e25 FLOP 左右)。地域分布式训练可以利用多个地区的能源基础设施,进一步扩大规模。根据目前美国数据中心扩张的预测,美国的分布式网络可能容纳 2 到 45 GW,假设数据中心之间有足够的带宽,则可支持 2e28 到 2e30 FLOP 的训练运行。除此之外,如果提前 3 到 5 年进行规划,愿意支付新发电站成本的参与者可以获得更多电力。

数据中心电力容量的快速扩张潜力巨大,这一点已被多种资料来源和预测所证实。SemiAnalysis 提供的历史数据显示,2019 年至 2023 年期间,数据中心容量的年增长率约为 20%(如图 2)。2024 年和 2025 年的扩建计划旨在加快这一速度,如果按时完成,年增长率将达到 32%。
总体而言,10-30% 的年增长率似乎是可以实现的。根据 15% 的中心增长率估算,到 2030 年,美国数据中心的容量将从 40 GW 增长到 90 GW,即增加 50 GW。注意,此处使用的是对实际增长的预测范围,并以此为基础估算可行的增长,因此这一数字可以说是保守的。
报告中提到,由本地电力支持的 2030 年训练运行可能需要 1 到 5 GW,到 2030 年可达到 1e28 到 3e29 FLOP。与此同时,分布在各地的训练运行可获得 2 至 45 GW 的电力供应,并在数据中心对之间实现 4 至 20 Pbps 的连接,从而实现 2e28 至 2e30 FLOP 的训练运行。上述估计背后的假设可以在下图 3 中找到。

芯片制造能力
人工智能芯片提供了训练大型人工智能模型所需的计算能力。目前,扩展受到先进封装和高带宽内存生产能力的限制。不过,考虑到制造商计划的规模扩张以及硬件效率的提高,即使考虑到 GPU 将在多个 AI 实验室之间分配,并且部分专用于服务模型,也可能有足够的能力让 1 亿个 H100 等效 GPU 专用于训练,为 9e29 FLOP 的训练运行提供动力。然而,这一预测具有很大的不确定性,估计值从 2000 万到 4 亿个 H100 等效处理器不等,相当于 1e29 到 5e30 FLOP(比 GPT-4 大 5000 到 300000 倍)。
报告中假设了一种情况,即从现在到 2030 年,台积电 5 纳米及以下的全部产能都用于 GPU 生产。在这种情况下,潜在计算量可能会增加一个数量级,达到 1e30 到 2e31 FLOP。这一上限基于当前的晶圆产量预测,说明了如果完全解决封装、HBM 生产和晶圆分配方面的现有限制,对人工智能训练能力可能产生的最大影响。图 4 展示了这些估计值,并列出了其背后的假设。

数据短缺
训练大型人工智能模型需要相应的大型数据集。索引网络包含约 500T 的独特文本,预计到 2030 年将增加 50%。从图像、视频和音频数据中进行多模态学习可能会适度促进扩展,使可用于训练的数据增加三倍。在考虑了数据质量、可用性、多 epoch 和多模态 tokenizer 效率等不确定因素后,估计到 2030 年可用于训练的 token 相当于 400 万亿到 20 亿亿个,允许 6e28 到 2e32 FLOP 的训练运行。人工智能模型生成的合成数据可能会大幅提高这一比例。
据估计,索引网络上的文本数据量为 20 亿亿个 token (Villalobos et al, 2024)。同时,互联网上图片和视频秒数的估计值为 40 万亿。如果也使用每张图片或每秒视频 100 个 token 的高端估计值,这意味着有四亿亿个视觉 token,或六亿亿个文本和视觉 token。如果还假设到 2030 年这些数据量翻一番,80% 的数据因质量过滤而被删除(FineWeb 丢弃了约 85% 的 token),模型在这些数据上训练 10 个 epoch,那么有效数据集的规模将达到约 20 亿亿个 token。有关这些参数的完整列表以及报告选择这些值范围的理由,如图 5 所示。

延迟墙
延迟墙是一种 「速度限制」,源于向前和向后传递所需的最短时间。随着模型规模的扩大,它们需要更多的顺序操作来训练。增加并行处理的训练 token 数量(即「批大小」)可以摊销这些延迟,但这种方法也有局限性。超过「临界批大小」后,批大小的进一步增加会导致训练效率的回报递减,训练更大的模型需要连续处理更多的批。这就为特定时间范围内的训练 FLOP 设定了上限。报告估计,现代 GPU 设置上的累积延迟将使训练运行的 FLOP 上限达到 3e30 到 1e32。要超越这一规模,需要采用其他网络拓扑结构、减少通信延迟,或者采用比目前更积极的批规模扩展。
OpenAI 之前的研究将临界批大小(在这个点之后,训练的收益会大幅递减)与梯度相对于训练数据的分散程度联系了起来。在此基础上,Erdil 和 Schneider-Joseph(即将发表)推测,批大小可能与可还原模型损失的倒数成比例,根据 Chinchilla 的说法,可还原模型损失的比例大致为模型参数数量的立方根。如果这种情况成立,它将把延迟墙推回一个数量级,参见下图。

什么限制因素影响最深?
上文讲到了人工智能扩展的四个主要瓶颈。如果将它们放在一起考虑,则意味着到本个十年末,训练运行高达 2e29 FLOP 是可行的。这将代表着相对于当前模型的大约 10000 倍的扩展,并意味着扩展的历史趋势可以不间断地持续到 2030 年(图 7)。深色阴影框对应四分位数范围,浅色阴影区域对应 80% 置信区间。

最具约束力的限制因素是电力和芯片的可用性。其中,电力的可塑性可能更大,能源行业的集中度较低,而且有扩大 100 GW 电力供应的先例,如果提前三到五年计划,供应商应该能够执行。
扩大芯片制造面临多重挑战:先进封装等关键工艺大多已分配给数据中心的 GPU,而建设新的晶圆厂需要大量资本投资和高度专业化的劳动力。
数据是最不确定的瓶颈,其不确定性范围跨越四个数量级。多模态数据对提高推理能力的作用可能有限,而且我们对此类数据的可用存量、质量以及当前 token 化方法效率的估计都不如对文本数据的估计那么确定。最终,合成数据可以实现无限扩展,但计算成本较高。
最后,虽然延迟墙是一个遥远的制约因素,但它作为一个需要克服的障碍,已经出现在地平线上。通过采用更复杂的网络拓扑结构,包括更大的 pod 或 pod 之间更多的连接,可能会将延迟墙推倒。
AI实验室们会扩展到这个程度吗?
迄今为止,人工智能模型规模的不断扩大一直带来能力的提升。这为人工智能的发展灌输了一种以规模为中心的观点,导致用于训练运行的支出以每年约 2.5 倍的速度增长。早期迹象表明,这种情况可能会继续下去。
值得注意的是,据报道,微软和 OpenAI 正在为一个名为 Stargate(星际之门)的数据中心项目制定计划,该项目耗资可能高达 1000 亿美元,将于 2028 年启动。这表明,大型科技公司确实正在准备实现本文所述的巨大规模。
将 GPT-4 升级到与 GPT-6 相当的模型,再加上算法的大幅改进和后期训练的改进,可以进一步证明人工智能系统具有足够大的经济回报潜力。这些证据可能表现为:GPT-5 等较新的模型在发布的第一年内就创造了超过 200 亿美元的收入;人工智能功能的显著进步,使模型能够无缝集成到现有的工作流程中,操作浏览器窗口或虚拟机,并在后台独立运行。
人工智能能够自动完成相当一部分经济任务,其潜在回报是巨大的。一个经济体投资数万亿美元建立与计算相关的资本储备,包括数据中心、半导体制造工厂和光刻机,是有可能实现的。要了解这一潜在投资的规模,需要考虑全球每年的劳动报酬约为 6000 万美元。即使不考虑人工智能自动化带来的经济加速增长,如果开发能够有效替代人类劳动力的人工智能变得可行,那么投资数万亿美元来获取这 6000 万美元中的一小部分,在经济上也是合理的。
据标准经济模型预测,如果人工智能自动化达到取代大部分或全部人类劳动力的程度,经济增长可能会加快十倍或更多。在短短几十年内,这种加速增长可使经济产出增加几个数量级。考虑到这一潜力,提前实现完全或接近完全自动化的价值可能占全球产出的很大一部分。认识到这一巨大价值,投资者可能会将传统行业的大部分资金转投人工智能开发及其重要基础设施(能源生产和分配、半导体制造工厂、数据中心)。这种前所未有的经济增长潜力可能会推动数万亿美元的人工智能开发投资 104。
#Learning Visual Parkour from Generated Images
从未见过现实世界数据,MIT在虚拟环境中训练出机器狗,照样能跑酷
如今,机器人学习最大的瓶颈是缺乏数据。与图片和文字相比,机器人的学习数据非常稀少。目前机器人学科的主流方向是通过扩大真实世界中的数据收集来尝试实现通用具身智能,但是和其他的基础模型,比如初版的 StableDiffusion 相比,即使是 pi 的数据都会少七八个数量级。MIT 的这个团队希望用生成模型来作为机器人学习的新数据源,用工程手段来取代传统的数据收集,实现一条通过由生成模型加持的物理仿真来训练机器人视觉的技术路线。
随着机器人在训练过程中持续进化,进一步提升技能所需的数据也在增长。因此获取足够的数据对于提升机器人的性能至关重要,但在当前实践中,针对新场景和新任务获取数据是一个从头开始不断重复的手动过程。
另一种替代方法则是在模拟环境中训练,从中可以对更多样化的环境条件进行采样,并且机器人可以安全地探索故障案例并直接从它们自己的行为中学习。尽管业界已经在模拟物理和渲染方面投入了大量资金,但目前为实现真实性所做的最佳实践仍与现实存在差距。
一方面渲染真实的图像意味着要制作细致、逼真的场景内容,但大规模手动制作此类内容以获得机器人 sim-to-real(模拟到现实)迁移所需要的多样性,成本过高。另一方面,如果缺少多样化和高质量的场景内容,在模拟环境中训练的机器人在迁移到真实世界时表现得太脆弱。
因此,如何在无限的虚拟环境中匹配现实世界,并将色彩感知融入到 sim-to-real 学习中,这是一个关键挑战。
近日, MIT CSAIL 的研究者开发出了一套解决方案,他们将生成模型作为机器人学习的新数据源,并使用视觉跑酷(visual parkout)作为试验场景,让配备单色相机的机器狗快速攀爬障碍物。
研究者的愿景是完全在生成的虚拟世界中训练机器人,而核心在于找到精确控制语义组成和场景外观的方法,以对齐模拟物理世界,同时保持对于实现 sim-to-real 泛化至关重要的随机性。
- arXiv 地址:https://arxiv.org/pdf/2411.00083
- 项目主页:https://lucidsim.github.io/
- 论文标题:Learning Visual Parkour from Generated Images
下图 2 为本文 LucidSim 方法概览:采用了流行的物理引擎 MuJoCo,并在每一帧上渲染了深度图像和语义掩码,这些一起被用作深度条件 ControlNet 的输入。然后从已知的场景几何和相机姿态变化中计算真值密集光流,并在接下来的六个时间步中扭曲原始生成帧以生成时间一致的视频序列。
在学习方面,研究者训练的视觉策略分为两个阶段完成:首先优化策略以模拟从特权教师收集的 rollout 中获得的专家行为。在经过这一预训练步骤后,策略表现不佳。因此,后训练步骤包括从视觉策略本身收集 on-policy 数据,并与当前收集的所有数据的学习交错进行。重复这一步骤三次使得该视觉策略显著提升了自身性能。
研究者表示,该策略足够稳健,在他们的测试场景中可以将零样本转换为真实世界的色彩观察。

下面我们来看一段视频展示:
LucidSim:利用物理引导生成多样化视觉数据
研究者考虑了这样一种 sim-to-real 设置,机器人在模拟环境中接受训练,并无需进一步调整就能迁移到现实世界。他们对自己打算部署机器人的环境已经有部分了解,可能是粗略的描述或者参考图像。
由于信息不完整,研究者依赖生成模型内部的先验知识来填补空白。他们将这一引导过程称为先验辅助域生成(Prior -Assisted Domain Generation,PADG),并首先采用对合成不同域至关重要的自动提示技术。
LLM 成为多样化、结构化的提示来源。研究者很早就观察到,从同一提示中重复采样往往会重现类似的图像。因此,为了获得多样化的图像,他们首先使用了包含标题块、查询详情的「元」提示,以提示 ChatGPT 生成批量结构化的图像块,最后以一个要求 JSON 结构化输出的问题结束。具体如下图 4 所示。

研究者的要求包括特定天气、一天中的时间、光照条件和文化遗址。手动编辑生成的图像提示是不切实际的,因而他们通过生成少量图像来调整元提示,并进行迭代直到它们始终可以生成合理的图像。下图 5 下面一行显示了相同元提示、不同图像提示的多样化样本示例。

在几何和物理引导下生成图像。研究者增强了一个原始文本到图像模型,在增加额外语义和几何控制的同时,使它与模拟物理保持一致。他们首先将图像的文本提示替换为提示和语义掩码对,其中每个对应一种资产类型。比如在爬楼梯场景中,研究者通过文本指定了粗略轮廓内台阶的材质和纹理。
为了使图像在几何上保持一致,研究者采用了现成的 ControlNet,该模型使用来自 MiDAS 的单目深度估计进行训练。条件深度图像则通过反转 z 缓冲区并在每一张图像内进行归一化处理来计算。此外,调整控制强度以避免丢失图像细节非常重要。他们采用的场景几何是以往工作中出现的简单地形,包括可选的侧墙。同时避免随机化几何地形以专注视觉多样性分析。
为了制作短视频,研究者开发了 Dreams In Motion(DIM)技术,它根据场景几何计算出的真值光流以及两帧之间机器人相机视角的变化,将生成图像扭曲成后续帧。生成的图像堆栈包含对跑酷至关重要的计时信息。生成速度也很重要,DIM 显著提高了渲染速度,这得益于计算流和应用扭曲要比生成图像快得多。具体如下图 6 所示。

通过 on-policy 闭环训练来学习稳健的真实世界视觉策略
训练过程分为两个阶段:一是预训练阶段,通过模拟有权直接访问高度图的特权专家来引导视觉策略,其中高度图通过 RL 进行训练。研究者从专家及其不完美的早期检查点收集 rollout,并向专家查询动作标签以监督视觉策略。该视觉策略在预训练后表现不佳,但在第二阶段即后训练阶段做出了足够合理的决策来收集 on-policy 数据。具体如下图 7 所示。
研究者遵循 DAgger,将 on-policy rollout 与上一步中的教师 rollout 相结合。他们从专家教师那里收集了动作标签,并用余弦学习率计划下使用 Adam 优化器运行 70 个梯度下降 epoch。研究者在实验中仅需重复迭代 DAgger 三次就可以实现接近专家表现程度的视觉控制器。实际上第二阶段中的闭环训练过程是机器人出色表现的主要原因。

一个简单的 transformer 控制模型架构。研究者提出了一个简单的 transformer 架构,与之前 extreme parkour, 使用 transformer 大大减少了处理多模态输入时控制模型架构的复杂度,如下图 8 所示。以往四足跑酷的相关工作使用复合架构,首先使用 ConvNet 将深度图处理成紧凑的潜在向量,然后使用循环骨干网络。
研究者使用了带有多查询注意力的五层 transformer 骨干网络,输入的相机视频被切成小块,并由一个卷积层并行处理。然后,他们将这些 token 与同一时间步的本体感受观察的线性嵌入堆叠在一起。研究者对所有时间步重复此操作,并在 token 级添加了可学习的嵌入。他们发现,对于 RGB 图像,在卷积之前包含批归一化层也有帮助。
最后,研究者通过堆叠在输入序列末尾的额外类 token 来计算动作输出,然后是 ReLU 潜在层和线性映射。

实验结果
在实验环节,研究者考虑了以下任务:
- 追踪足球(chase-soccer);
- 追踪橙色交通锥(chase-cone);
- 攀爬各种材质的楼梯(stairs)。
他们分别在现实世界和一小部分使用 3D 高斯泼溅来模拟创建的真实世界场景中评估学习到的控制器性能。这些基准环境的示例如下图 9 所示。

此外,研究者进行了以下基线比较:
- 需要特权地形数据(障碍)的专家策略;
- 使用相同 pipeline 训练的深度学生策略;
- 使用纹理上经典域随机化训练的 RGB 学生策略;
- 以及本文基于 DIM 生成的帧堆栈进行训练的 LucidSim。
从生成图像中学习要优于域随机化
在模拟评估中,研究者观察到 LucidSim 在几乎所有评估中都优于经典域随机化方法,如下表 1 和表 6 所示。其中,域随机化基线方法能够在模拟中非常高效地爬楼梯,但在跨越障碍任务中表现不佳。这是因为深度学生网络在 3D 场景中遭遇了微妙且常见的 sim-to-real 差距。
比如由于受到栏杆的影响,Oracle 策略在其中一个爬楼梯场景(Marble)中表现不佳,因为它在训练环境中从未见过栏杆。相反,LucidSim 受到的影响较小。


从零样本迁移到现实世界
研究者在配备廉价 RGB 网络摄像头的 Unitree Go1 上部署了 LucidSim,在 Jetson AGX Orin 上运行了推理。每个任务都在多种场景中进行评估,并记录了机器人是否追到了目标物(追逐)或成功跨越障碍物。
下图 11 展示了 LucidSim 与域随机化方法的比较结果,其中 LucidSim 不仅能够识别经典的黑白足球,而且由于之前看到了具有丰富多样性的生成数据,因而可以泛化到不同颜色的足球。
对于跨越障碍(hurdle)和爬楼梯(stair)场景,Domain Rand. 无法始终如一地识别前方障碍物,并经常出现正面碰撞,而 LucidSim 能够始终如一地预测前方的障碍物并成功跨越。

学习 on-policy 要优于原始的专家数据 Scaling
研究者在下图 12 中,将基于 on-policy 的学习与原始的专家数据收集方法进行了比较。结果显示,通过额外专家专用数据训练获得的性能增益很快达到饱和。在跨越障碍和爬楼梯场景中,通过 DAgger 进行 on-policy 学习对于制定足够稳健的策略很有必要。

下图 10 展示了 LucidSim 和域随机化基线方法下 DAgger 产生的益处,其中前者的整体性能更高。

仅深度的策略过拟合训练几何
除了极限跑酷,研究者还考虑了两种深度策略,它们都接受了与 LucidSim 相同的训练,但输入深度不同。第一种(如上表 1 和表 6 第三行)接收远距剪切至五米的深度,并实现 120° FoV(视场角)。第二种(上表 1 和表 6 第四行)接收剪切至两米的深度。
在模拟评估中,研究者观察到,使用未剪切深度的策略会过拟合训练场景中的最小和简单几何,并被评估场景背景中的干扰因素所干扰。而视觉有限的深度策略不太会受到测试场景中多样性的影响,并且性能可以显著地提高。
理解 DIM 的速度和性能
图像生成是本文 pipeline 中的瓶颈。DIM 大大加速了每个策略的展开,同时通过权衡多样性提供动态一致的帧堆栈。研究者探究了独立生成每一帧如何影响学生网络的性能,他们认为跨越障碍场景最具挑战性。如下图 13 所示,在性能类似的情况下,DIM 可以在短时间内实现相同结果。

强大的条件降低多样性和图像细节
研究者需要权衡几何准确率与生成图像细节丰富度。当条件强度过低时,图像会偏离场景几何(如下图 14 左侧)。当条件强度过高时,图像会失去多样性和丰富细节(图 14 右侧),并且由于过约束而变得失真严重。

#CROSS
突破无规则稀疏计算边界,编译框架CROSS数倍提升模型性能
本篇工作已被 HPCA 2025 接收,由上海交大先进计算机体系结构实验室蒋力教授课题组(IMPACT)完成,同时也获得了上海期智研究院的支持。第一作者是刘方鑫老师与博士生黄世远。
在现代 AI 模型的快速迭代中,如何在保持模型精度的同时提升计算效率成为关键课题。尤其在大规模 AI 推理中,非结构化稀疏矩阵的计算效率低下成为难以突破的瓶颈。面对这一挑战,我们自主研发了 CROSS—— 一种创新的端到端稀疏编译优化方案,为 AI 推理带来细粒度稀疏计算的加速效果。
稀疏计算的挑战:如何处理非均匀稀疏分布
非结构化细粒度稀疏场景下模型推理效率低下问题是 AI 编译社区面对的关键问题之一。相比于密集算子加速库(cuBlas),主要的稀疏算子加速库或编译框架需要在较高稀疏率下才能获得收益,而过高的稀疏率需求可能使我们面临模型精度下降的风险。

图 1. 相比于 cuBlas,不同稀疏加速库或编译框架在不同稀疏率下的加速比。Sputnik、TVM-Sparse、SparseTIR、ASpT 和 cuSPARSE 在稀疏率超过 76%、80.5%、82.6%、89.4% 和 98.1% 时才能获得正向收益(稀疏矩阵源于 Bert 模型中的稀疏权值矩阵)。
稀疏计算的机会:稀疏负载存在局部性
通过对稀疏模型进行调研我们发现,稀疏矩阵中非零元素的分布展现出严重的非均匀分布特性。这种非均匀分布对稀疏矩阵的计算效率产生了巨大的负面影响:
- 局部过密:部分区域的非零元素过于密集导致该区域不再适合稀疏矩阵运算;
- 局部过稀:部分区域的非零元素过于稀疏导致该区域相对于其他区域负载过低,造成计算单元负载失衡问题。这些问题严重影响了稀疏算子的执行效率。

图 2. Llama-2-7B 模型整体 70% 稀疏率场景下非零元素的分布。第 0、1、2 层的 Query weight 矩阵中不同区域的稀疏率跨度很大(30%~99%),展现出严重的非均匀分布特征;第 30、31 层的 Query weight 矩阵中不同区域的非均匀分布特性有所缓解(55%~99%)但依然严重。
CROSS:稀疏编译的破局之道
为应对上述挑战,CROSS 引入了一套全新的编译优化流程。CROSS 首先对稀疏矩阵的结构特点进行深入分析,通过代价模型精准判断稀疏与密集区域的不同计算需求,并自动分配最优的计算资源。其关键步骤包括:
1) 代价模型构建:首先,我们对不同 block 形状下、不同稀疏率下的稀疏矩阵乘(SpMM)和密集矩阵乘(GEMM)执行时间进行分析并建立代价模型(block 内的稀疏分布假设为均匀分布),如图 3 所示。SpMM 开销明显高于 GEMM 开销的稀疏率范围称为密集区(Dense band);将 SpMM 开销明显低于 GEMM 开销的稀疏率范围称为稀疏区(Sparse band),将 SpMM 与 GEMM 的执行开销相近的区域称为摇摆区(Swing band)。

图 3. 不同稀疏率下 SpMM 与 GEMM 的执行时间分布(SpMM 由 Sputnik 实现,GEMM 由 cuBlas 实现,矩阵形状 M=N=K=256, batch=10)。
2) Intra-batch 负载均衡:其次,我们将模型中的稀疏矩阵拆分为多个 block 并依据代价模型评估每个 block 适合的计算范式和计算开销。然后,我们依据 block 之间是否具有累加关系对整个矩阵的计算开销建立代价模型,如图 4(b)所示。针对矩阵中存在的负载不均衡问题,我们将稀疏计算与密集计算分别映射到不同的计算单元执行。当稀疏计算与密集计算的负载差异较大时,我们将摇摆类型的 block 转换为负载较小的类型,以实现单 batch 稀疏矩阵乘法的计算单元负载均衡(如图 4(c)所示)。

图 4. Intra-batch 负载均衡策略。(a)一个稀疏分布不均匀的稀疏矩阵案例。(b)原始稀疏矩阵乘法的执行开销。(c)负载均衡策略下的矩阵乘法执行开销。
3) Inter-batch 负载均衡:此外,由于 batch 之间使用相同的稀疏权值矩阵,当 batch size 较大时,矩阵中不同位置的负载失衡问题持续积累而变得更加严重。针对该问题我们将相邻两个 batch 之间的负载与计算单元的映射关系进行了重排。如图 5(a)所示,简单的将相邻两个 batch 合并执行会造成不同位置的负载失衡效应持续积累,造成更严重的负载失衡问题。为了应对该问题,我们对不同计算单元的负载进行重排序,相邻两个 batch 按照不同的顺序进行计算单元映射,以实现 batch 之间的负载均衡。

图 5. Inter-batch 负载均衡策略。(a)简单粗暴的将相邻两个 batch 合并会造成负载失衡效应累积。(b)对相邻 batch 中不同计算单元的负载重排能大幅缓解负载均衡问题。
实验成果:显著的性能提升
实验结果表明,相比于其他稀疏矩阵加速库或编译框架,CROSS 在不同稀疏率下都获得了显著性能提升,与业界最优设计相比平均获得 2.03× 的性能提升。相比于密集计算(cuBlas),CROSS 在稀疏率超过 60% 时开始获得正收益,显著突破了传统无规则稀疏加速设计的收益边界。

图 6. 五种整体模型稀疏率下,不同稀疏加速设计相比于密集加速库(cuBlas)的模型推理性能。相比于 cuBlas,我们最高可以获得 3.75× 性能收益,同时我们在稀疏率超过 60% 时开始获得正收益,而其他方案则需要接近或超过 80% 稀疏率。
CROSS 的未来:推动稀疏编译应用普及
CROSS 的成功不仅在于提升了稀疏矩阵计算的效率,更为未来 AI 推理在稀疏计算场景下的广泛应用奠定了坚实的基础。在 AI 模型规模不断扩展的今天,稀疏性在大模型中广泛存在,CROSS 为稀疏编译提供了高效、灵活、可持续的发展路径,助力未来 AI 应用的高效部署。
#SpargeAttn
清华稀疏Attention,无需训练加速一切模型!
在当今各类大语言模型以及视频模型中,长序列场景越来越普遍,而 Attention 的计算复杂度随着序列长度呈平方增长,成为长序列任务下的主要计算瓶颈。此前,清华大学陈键飞团队提出的即插即用量化的 SageAttention 系列工作已实现 3 倍加速于 FlashAttention,且在各类大模型上均保持了端到端的精度,已被业界和社区广泛使用。为了进一步加速 Attention,清华大学陈键飞团队进一步提出了无需训练可直接使用的稀疏 Attention(SpargeAttn)可用来加速任意模型。实现了 4-7 倍相比于 FlashAttention 的推理加速,且在语言,视频、图像生成等大模型上均保持了端到端的精度表现。
论文标题:SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
- 论文链接:https://arxiv.org/abs/2502.18137
- 开源代码:https://github.com/thu-ml/SpargeAttn
下图展示了 SpargeAttn 的速度,可以发现在 RTX4090 上,SpargeAttn 在 60% 稀疏度的情况下可以达到 900TOPS 的速度,甚至是使用 A100 显卡速度的 4.5 倍(A100 上 FlashAttention 只有 200TOPS)。

在 SpargeAttn 的 Github 仓库中可以发现,SpargeAttn 的使用方法比较简洁,只需要进行一次简单的超参数搜索过程,就可以永久地对任意的模型输入进行推理加速。
接下来,将从前言,挑战,方法,以及实验效果四个方面介绍 SpargeAttn。
前言
随着大模型需要处理的序列长度越来越长,Attention 的速度优化变得越来越重要。这是因为相比于网络中其它操作的 O (N) 的时间复杂度,Attention 的时间复杂度是 O (N^2)。尽管 Attention 的计算复杂度为 O (N^2),但幸运的是 Attention 具备很好的稀疏性质,即 P 矩阵的很多值都接近 0。如何利用这种稀疏性来节省计算就成为了 attention 加速的一个重要方向。大多数现有的工作都集中在利用 P 矩阵在语言模型中表现出来的固定的稀疏形状(如滑动窗口)来节省计算,或是需要重新训练模型,比如 DeepSeek 的 NSA 以及 Kimi 的 MoBA。此外,现有稀疏 Attention 通常需要较大的上下文窗口(如 64K~1M)才能有明显加速。SpargeAttn 的目标是开发一个无需训练、对各种模型(语言 / 视频 / 图像)通用、精度无损、对中等长度的上下文(如 4-32K)也有加速效果的注意力机制。

图 1: 不同的模型表现出不同的稀疏形状
实现通用的,无需训练的稀疏 Attenion 有哪些挑战?
挑战 1
通用性:Attention 虽然具备稀疏性质,但是其稀疏形状在不同的模型甚至同一模型的不同层中都是不同的,体现出很强的动态性。如图 1 所示,前两种模型分别为视频模型和图像生成模型,这两个模型中的 Attention 的稀疏形状相比语言模型更加没有规律。设计一种各种模型通用的稀疏 Attention 是困难的。
挑战 2
可用性:对于各种 Attention 的输入,很难同时实现准确且高效的稀疏 Attention。这是因为准确性要求了完全精确地预测 P 中的稀疏区域,高效性则要求了此预测的时间开销极短。在一个极短的时间内完全精准地预测 P 的稀疏形状是困难的。
方法
为了解决上述的两个挑战,研究团队提出了对应的解决办法。
- 研究团队提出了一种各模型通用的快速的对 P 矩阵稀疏部分进行预测的算法。该方法选择性地对 Q, K 矩阵进行压缩并预测 P 矩阵,接着使用 TopCdf 操作省略 P 中稀疏部分对应的 QK^T 与 PV 的矩阵乘法。
- 研究团队提出了在 GPU Warp 级别上的稀疏 Online Softmax 算法,该算法通过利用 Online Softmax 中全局最大值与局部最大值之间的差异,进一步省略了一些 PV 的矩阵乘法计算。
- 可选的,针对视频和图像模型,研究团队充分利用图像以及视频中的 Token 局部相似性质,使用希尔伯特重排的方法对 Attention 前的 Token 进行重新排列,进一步提高稀疏度。
- 最后,研究团队将这种稀疏方法与基于量化的 SageAttention 融合到一起,进一步加速 Attention。

图 2: SpargeAttn 的算法流程图
SpargeAttn 的算法流程如下所示:

实验效果
总的来说,SpargeAttn 在视频、图像、文本生成等大模型均可以实现无需训练的加速效果,同时保证了各任务上的端到端的精度。
下表展示了 SpargeAttn 在各模型上的稀疏度,Attention 速度,以及各任务上的端到端精度,可以发现 SpargeAttn 在保证了加速的同时没有影响模型精度:(注:此论文中的所有实验都是基于 SageAttention 实现,目前 Github 仓库中已有基于 SageAttention2 的实现,进一步提供了 30% 的加速。

值得一提的是,此前的稀疏 Attention 工作很多无法实际使用的原因之一是稀疏预测部分的 Overhead 较大,而 SpargeAttn 团队还将稀疏预测部分的代码进行了极致优化,将 Overhead 压缩到了几乎在各种长度的序列下都可以忽略的地步:

下表展示了对于各模型的端到端的加速效果,以视频生成模型 Mochi 为例,SpargeAttn 提供了近两倍的端到端加速效果:(注:此论文中的所有实验都是基于 SageAttention 实现,目前 Github 仓库中已有基于 SageAttention2 的实现,进一步提供了 30% 的加速)

#Lepton AI
外媒:英伟达将收购贾扬清创业公司Lepton AI,交易价值数亿美元
成为英伟达 AI 云基础设施的一部分?
又一家 AI 大佬的创业公司被巨头收购了。
据外媒 The Information 报道,英伟达即将达成收购知名 AI 创业公司 Lepton AI 的交易。Lepton AI 是一家为 AI 时代构建新型基础设施的公司,由贾扬清(Yangqing Jia)等人创立。有未具名的消息人士称,这笔交易价值数亿美元。
此举是英伟达进军云计算和企业软件市场行动的一部分。英伟达的业务正在向下游延伸,寻求与亚马逊和谷歌等主要云服务提供商展开竞争。
Lepton AI 成立于两年前,并于 2023 年 5 月从 CRV 、红杉中国和 Fusion Fund 筹集了 1100 万美元的种子轮融资。在大模型的浪潮之下,贾扬清的创业并没有选择构建基础模型,而是切入了 AI infra 赛道。
- 公司主页:https://www.lepton.ai/
- Github 链接:https://github.com/leptonai
Lepton AI 核心理念如同其标语「Why Lepton AI Cloud:Efficient, reliable and easy to use」所传达的——让 AI 模型的构建与部署变得简单高效。无论是经验丰富的开发者还是 AI 部署初学者,Lepton AI 都致力于通过精心设计的工具和服务降低技术门槛。
Lepton AI 并不训练自己的大模型,而是提供大模型训练、部署和应用时所需的基础设施。贾扬清团队希望通过技术解决 AI infra 层的三个核心问题:速度、价格和质量。

Lepton AI 主要提供两大核心产品:Python SDK 和云计算平台。通过 Python SDK,开发者仅需 2-3 行代码即可部署 AI 模型,无需深入了解复杂的部署流程。部署完成后,只需一个简单的 curl 命令或几行 Python/Node.js 代码就能实现客户端请求,快速将模型功能整合到应用中。
Lepton AI 的云平台提供按需分配的计算资源,包括 CPU、GPU(如 NVIDIA A100)和存储支持。开发者可将模型部署至云端,利用其托管服务轻松提供公开的 AI 服务,免去自行管理服务器或容器环境的麻烦。
在模型支持方面,Lepton AI 与 HuggingFace 平台兼容,开发者可利用其丰富的预训练模型库,通过转换工具集成到项目中。此外,Lepton AI 还支持从 GitHub 仓库创建 AI 模型(需符合特定配置),为开发者提供更多灵活选择。

2024 年 1 月 25 日,贾扬清在 X(Twitter)平台上宣传了一个 Lepton Search demo,用不到 500 行 Python 代码实现了 AI 对话搜索引擎,展现了构建 AI App 变得如此简单。之后他又公布了 Lepton Search 的开源项目链接,并表示任何人、任何公司都可以自由使用开源代码。
在 AI 领域,贾扬清是全球最受关注的科学家之一,他博士毕业于加州大学伯克利分校,主要研究方向为人工智能硬件和软件堆栈的设计和演进。在伯克利读博期间,他开发了深度学习框架 Caffe,以优异的结构、性能和代码质量成为机器学习领域最受欢迎、最成功的开源 AI 框架之一,对机器学习领域发展起到了极大的推动作用。
贾扬清曾在新加坡国立大学、NEC 美国实验室、谷歌工作。在 Google Brain 任研究科学家期间,他从事计算机视觉、深度学习和 TensorFlow 框架的研究,并共同创建了第一个超越人类图像分类准确率的神经网络 GoogLeNet。
2016 年,贾扬清加入 Facebook,后升任工程总监,负责为 Facebook 的所有应用程序从头开始构建通用的大型 AI 平台。
2017 年,贾扬清等人创建了神经网络通用交换格式 ONNX 的原型,后续又与 Facebook、微软、亚马逊和许多硬件供应商一起发布正式版 ONNX。2018 年 5 月,Facebook 正式公布 PyTorch 1.0,贾扬清担任 PyTorch 1.0 项目的共同负责人。
2019 年,贾扬清加入阿里巴巴,担任技术副总裁,负责领导大数据计算平台的研发工作。他领导的团队专注于构建基于云的大数据和人工智能平台,为公有云和私有云客户提供服务。
2023 年,贾扬清离开阿里成立 Lepton AI,旨在建立高效的 AI 应用平台,其创始团队来自于机器学习社区 ONNX、分布式系统研发平台 etcd 等。
此次收购成功后,我们还在期待这位知名 AI 学者新的故事。
参考内容:
https://techcrunch.com/2025/03/26/nvidia-is-reportedly-in-talks-to-acquire-lepton-ai/
#Vision-R1
VLM推理模型详细解读研究背景
- 研究问题:这篇文章要解决的问题是如何利用强化学习(RL)来提升多模态大型语言模型(MLLMs)的推理能力。尽管直接使用RL训练难以激活复杂的推理能力,如提问和反思,但本文提出了一种新的方法来解决这个问题。
- 研究难点:该问题的研究难点包括:缺乏大规模、高质量的多模态推理数据,以及直接RL训练在优化复杂推理过程时面临的挑战。
- 相关工作:该问题的研究相关工作有:OpenAI O1通过复杂的Chain-of-Thought(CoT)训练展示了强大的推理能力;其他研究尝试手动构建包含逐步推理过程的监督微调(SFT)数据集,但这些方法生成的“伪CoT”推理缺乏人类思维的自然认知过程。
研究方法
这篇论文提出了Vision-R1,一种结合冷启动初始化和RL训练的多模态推理MLLM。具体来说,
- 冷启动初始化:首先,利用现有的MLLM和DeepSeek-R1通过模态桥接和数据过滤构建一个无人工注释的高质量多模态CoT数据集。具体步骤如下:
- 使用MLLM生成“伪CoT”推理文本,明确包含视觉描述和结构化步骤级推理过程。
- 将富化的推理文本反馈到MLLM中,获得包含必要视觉信息的描述。
- 将文本描述传递给纯文本推理LLM DeepSeek-R1,提取高质量的CoT推理。
- 通过基于规则的数据过滤,最终获得一个包含200K多模态人类样复杂CoT推理样本的数据集,作为Vision-R1的冷启动初始化数据。

- 渐进式思维抑制训练(PTST):为了缓解冷启动初始化后过度思考的问题,提出了PTST策略,并结合Group Relative Policy Optimization(GRPO)和硬格式结果奖励函数来逐步精炼模型的推理能力。具体步骤如下:
- 在早期训练阶段,通过PTST压缩模型的推理长度,引导其进行正确的推理。
- 随着训练的进行,逐步放宽这些约束,使Vision-R1能够自动学习使用更长的CoT来解决日益复杂的问题。
公式解释:

其中,Ai表示第i个样本的训练阶段优势估计,πθold表示具有输出长度约束的策略模型,ε和β分别是PPO剪辑超参数和Kullback-Leibler(KL)惩罚系数。
实验设计
- 数据集和基准测试:为了获得冷启动数据集,使用了多模态视觉问答(VQA)数据集LLaVA-CoT(100K)和Mulberry数据集(260K),生成Vision-R1-cold(200K)。在GRPO过程中,混合了We-Math、MathVision、Polymath、SceMQA和Geometry3K等数学数据集,总共约10K条数据。评估推理能力的基准测试包括MM-Math、MathVista和MathVerse等多个多模态数学基准测试。
- 实现细节:使用128个NVIDIA H800 80G GPU部署开源MLLM Qwen-2.5-VL-72B和推理LLM DeepSeek-R1,处理VQA数据集约需2天。Vision-R1-7B的冷启动初始化采用Qwen-2.5-VL-7B-Instruct,在32个NVIDIA H800 80G GPU上进行2个epoch的监督微调,约需10小时。随后在64个NVIDIA H800 80G GPU上进行GRPO训练,采用两阶段的PTST策略。
结果与分析
- 数学推理能力:Vision-R1-7B在多个数学推理基准测试中表现出色,甚至在某些任务上超过了参数超过其10倍的现有最先进模型。例如,在MathVista基准测试中,Vision-R1-7B取得了73.5%的准确率,仅比领先的推理模型OpenAI O1低0.4%。

- 冷启动数据集质量:Vision-R1-cold数据集包含更高比例的人类样认知过程,如提问、反思和检查。与之前的Mulberry和LLaVA-CoT数据集相比,Vision-R1-cold数据集在这些指标上表现更好。

- 消融研究:比较了不同的RL训练策略,结果表明直接应用RL训练的效果不佳,而Vision-R1在平衡CoT复杂性和准确性方面表现出色。

总体结论
本文探讨了如何利用RL训练来激励MLLMs的推理能力,并提出了Vision-R1。通过结合冷启动初始化和RL训练,Vision-R1实现了强大的数学推理能力,达到了与现有最先进的MLLMs相当的性能。本文的贡献包括首次探索将RL应用于MLLMs以提高推理能力,构建了一个高质量的多模态CoT数据集,并提出了一种有效的PTST策略来解决冷启动初始化后的过度思考问题。
#EmoEdit
情感可编辑?深大VCC带你见证魔法!
EmoEdit 由深圳大学可视计算研究中心黄惠教授课题组完成,第一作者为杨景媛助理教授。深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。中心主任黄惠为深圳大学讲席教授、计算机学科带头人、计算机与软件学院院长。
论文标题:EmoEdit: Evoking Emotions through Image Manipulation
论文链接:https://arxiv.org/pdf/2405.12661
- 项目主页:https://vcc.tech/research/2025/EmoEdit
- 项目代码:https://github.com/JingyuanYY/EmoEdit
你有没有想过,情感也能被编辑?

当你翻开相册,看到一张平淡无奇的风景照,是否希望它能更温暖、更浪漫,甚至更忧郁?现在,EmoEdit 让这一切成为可能 —— 只需输入一个简单的情感词,EmoEdit 便能巧妙调整画面,使观众感知你想传递的情感。
情感无处不在,我们的每一次触动,往往源自身边微小的细节。心理学研究表明,视觉刺激是情感唤起的重要来源之一,而图像内容则是人类理解视觉信息的关键。这便引出一个值得探索的问题:我们能否通过编辑图像,有效引导观众的情感?
图像情感编辑(Affective Image Manipulation, AIM)具有双重目标:
- 保持编辑后图像与原图的结构一致性;
- 精准且显著地唤起目标情感。
然而,这两者本质上存在一定冲突,如何权衡成为关键挑战。尽管当前先进的生成模型在图像编辑任务中表现出强大能力,但难以权衡结构保持和情感唤起(如下图所示)。现有方法主要依赖颜色调整或风格变化进行情感迁移,但情感表达仍不够精准和显著,难以呈现更丰富且生动的情感效果。

为解决上述问题,本文的主要贡献如下:
- 提出 EmoEdit,一种基于内容感知的 AIM 框架,仅需目标情感类别作为提示词,即可在任意用户图像上实现多样化的情感编辑;
- 构建首个大规模 AIM 数据集 EmoEditSet,涵盖 40,120 组图像对,提供高质量、语义丰富的情感编辑基准,推动视觉情感研究;
- 设计即插即用的情感增强模块 Emotion Adapter,通过融合 EmoEditSet 的情感知识,有效提升扩散模型的情感感知能力。
EmoEditSet 的构建

鉴于 EmoSet 现有标签的局限性,我们在 CLIP 空间中对情感图片进行聚类,并利用 GPT-4V 总结各类的共性语义,构建情感因素树。其中,每个叶节点因素均能有效激发根节点的目标情感。
同时,我们从 MagicBrush、MA5K 和 Unsplash 等多个来源收集源图像,并利用 IP2P 和情感因素树生成目标图像。此外,考虑到 GPT-4V 与扩散模型在知识表达上的差异,我们合并语义相近的视觉因素,并剔除内容过于抽象的因素,以提升数据集的整体质量。
Emotion Adapter 的设计

微调虽能增强模型的情感知识,但成本高、泛化性差,且易导致灾难性遗忘。Q-Former 可利用一种模态的上下文优化对另一模态的理解。基于此,我们设计 Emotion Adapter,以提高情感感知能力。


Emotion Adapter 结合情感词典,目标情感和输入图像,旨在生成最合适的情感嵌入。
在训练过程中,我们通过扩散损失和指令损失共同优化网络:

其中,扩散损失侧重于像素级相似性,而指令损失则有助于更好地平衡语义准确性。
实验结果

在对比实验中,我们从全局编辑、局部编辑和情感迁移三个维度选择了对比方法。与其他方法相比,EmoEdit 编辑后的图像不仅有效保留了原始构图特征,还能显著传达目标情感,凸显了其在平衡图像结构与情感表达方面的优势。

在消融实验中,缺少 Emotion Adapter(w/o EmoAda)时,图像几乎相同。扩散损失有效保留了原始结构,而指令损失则提高了语义清晰度。例如,在 “满足” 情感下,EmoEdit 增加了「躺椅」,展现了结构完整性、语义清晰度和上下文契合度。

我们观察到,随着图像引导系数的降低,情感强度增加,而结构保持程度减少。尽管情感唤起和结构保持通常存在矛盾,EmoEdit 仍能有效平衡二者。用户可以根据需求和偏好调整引导系数,定制图像编辑效果,从而满足多样化的编辑需求。

在定量评估中,我们采用涵盖像素、语义和情感三个层面的六项指标。结果表明,EmoEdit 在大多数指标上优于对比方法,进一步验证了其在图像情感编辑任务中的卓越性能。

Emotion Adapter 可显著增强其他模型的情感表达能力。例如,在 ControlNet 中,插入 Emotion Adapter 之前,模型仅能将输入图像转换为黑白;引入后,则能生成包含「墓碑」等情感相关元素的图像,大幅提升情感保真度和上下文契合度。这进一步验证了 Emotion Adapter 在增强情感表达方面的有效性。

Emotion Adapter 不仅适用于图像编辑,还可拓展至风格图像生成。通过一次训练,它即可将情感极性(积极、消极)编码为准确、多元的语义表示。例如,在 「莫奈」风格生成的图像中,「日落」唤起「敬畏」(积极),而「墓地」则传递 「悲伤」(消极),充分展现了其在风格图像生成任务中的鲁棒性。
总结与展望
莎士比亚曾言:The emotion expressed by wordless simplicity is the most abundant.
「至简无言处,情深自丰盈」
近年来,我们课题组先后提出了情感计算领域的 Emo 系列研究工作:
- EmoSet(ICCV 2023):首个具有丰富属性标注的大规模视觉情感数据集;
- EmoGen(CVPR 2024):首个针对图像情感内容生成的研究;
- EmoEdit(CVPR 2025):首个聚焦于图像情感内容编辑的研究。
我们希望通过这一系列探索,为情感计算(Affective Computing)与生成式人工智能(AIGC)的交叉领域贡献新的思路与方法。未来,我们将持续深耕这一领域,也期待更多志同道合的朋友加入,共同探索「情感」这片蓝海!
#OverLoCK
卷积网络又双叒叕行了?OverLoCK:一种仿生的卷积神经网络视觉基础模型
作者是香港大学俞益洲教授与博士生娄蒙。
你是否注意过人类观察世界的独特方式?
当面对复杂场景时,我们往往先快速获得整体印象,再聚焦关键细节。这种「纵观全局 - 聚焦细节(Overview-first-Look-Closely-next)」的双阶段认知机制是人类视觉系统强大的主要原因之一,也被称为 Top-down Attention。
虽然这种机制在许多视觉任务中得到应用,但是如何利用这种机制来构建强大的 Vision Backbone 却尚未得到充分研究。
近期,香港大学将这种认知模式引入到了 Vision Backbone 的设计中,从而构建了一种全新的基于动态卷积的视觉基础模型,称为 OverLoCK (Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels)。该模型在 ImageNet、COCO、ADE20K 三个极具挑战性的数据集上展现出了强大的性能。例如,30M 的参数规模的 OverLoCK-Tiny 模型在 ImageNet-1K 达到了 84.2% 的 Top-1 准确率,相比于先前 ConvNet, Transformer 与 Mamba 模型具有明显的优势。
论文标题:OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
论文链接:https://arxiv.org/abs/2502.20087
动机
Top-down Attention 机制中的一个关键特性是利用大脑获得的反馈信号作为显式的信息指导,从而在场景中定位关键区域。然而,现有大多数 Vision Backbone 网络(例如 Swin, ConvNeXt, 和 VMamba)采用的仍然是经典的金字塔架构:从低层到高层逐步编码特征,每层的输入特征仅依赖于前一层的输出特征,导致这些方法缺乏显式的自上而下的语义指导。因此,开发一种既能实现 Top-down Attention 机制,又具有强大性能的卷积网络,仍然是一个悬而未决的问题。
通常情况下,Top-down Attention 首先会生成较为粗糙的全局信息作为先验知识,为了充分利用这种信息,token mixer 应该具备强大动态建模能力。具体而言,token mixer 应当既能形成大感受野来自适应地建立全局依赖关系,又能保持局部归纳偏置以捕捉精细的局部特征。然而我们发现,现有的卷积方法无法同时满足这些需求:不同于 Self-attention 和 SSM 能够在不同输入分辨率下自适应建模长距离依赖,大核卷积和动态卷积由于固定核尺寸的限制,即使面对高分辨率输入时仍局限于有限区域。此外,尽管 Deformable 卷积能在一定程度上缓解这个问题,但其可变的 kernel 形态会牺牲卷积固有的归纳偏置,从而会弱化局部感知能力。因此,如何在保持强归纳偏置的前提下,使纯卷积网络获得与 Transformer 和 Mamba 相媲美的动态全局建模能力,同样是亟待解决的关键问题。
方法
让 Vision Backbone 网络具备人类视觉的「两步走」机制
研究团队从神经科学获得关键启发:人类视觉皮层通过 Top-down Attention,先形成整体认知再指导细节分析(Overview-first-Look-Closely-next)。据此,研究团队摒弃了先前 Vision Backbone 网络中经典的金字塔策略,转而提出了一种新颖的深度阶段分解(DDS, Deep-stage Decomposition) 策略来构建 Vision Backbone 网络,该机制构建的 Vision Backbone 具有 3 个子模型:
- Base-Net:聚焦于提取中低层特征,相当于视觉系统的「视网膜」,利用了 UniRepLKNet 中的 Dilated RepConv Layer 来作为 token mixer,从而实现高效的 low-level 信息感知。
- Overview-Net:提取较为粗糙的高级语义信息,完成「第一眼认知」。同样基于 Dilated RepConv Layer 为 token mixer,快速获得 high-level 语义信息作为 Top-down Guidance。
- Focus-Net:在全局先验知识的引导下进行精细分析,实现「凝视观察」。基于一种全新的动态卷积 ContMix 和一种 Gate 机制来构建基本 block,旨在充分利用 Top-down Guidance 信息。
来自 Overview-Net 的 Top-down Guidance 不仅会在特征和 kernel 权重两个层面对 Focus-Net 进行引导,还会沿着前向传播过程在每个 block 中持续更新。具体而言,Top-down Guidance 会同时参与计算 Gate 和生成动态卷积权重,还会整合到 feature map 中,从而全方位地将 high-level 语义信息注入到 Focus-Net 中,获得更为鲁棒的特征表示能力。

图 1 OverLoCK 模型整体框架和基本模块

图 2 ContMix 框架图
具有强大 Context-Mixing 能力的动态卷积 --- ContMix
为了能够更好地适应不同输入分辨率,同时保持强大的归纳偏置,进而充分利用 Overview-Net 提供的 Top-down Guidance,研究团队提出了一种新的动态卷积模块 --- ContMix。其核心创新在于通过计算特征图中每个 token 与多个区域的中心 token 的 affinity map 来表征该 token 与全局上下文的联系,进而以可学习方式将 affinity map 转换为动态卷积核,并将全局上下文信息注入到卷积核内部的每个权重。当动态卷积核通过滑动窗口作用于特征图时,每个 token 都会与全局信息发生调制。简言之,即便是在局部窗口进行操作,ContMix 仍然具备强大的全局建模能力。实验中,我们发现将当前输入的 feature map 作为 query,并将 Top-down Guidance 作为 key 来计算动态卷积核,相较于使用二者级联得到的特征生成的 query/key pairs 具有更好的性能。
实验结果
图像分类
OverLoCK 在大规模数据集 ImageNet-1K 上表现出了卓越的性能,相较于现有方法展现出更为出色的性能以及更加优秀的 tradeoff。例如,OverLoCK 在近似同等参数量的条件下大幅超越了先前的大核卷积网络 UniRepLKNet。同时,相较于基于 Gate 机制构建的卷积网络 MogaNet 也具有非常明显的优势。

表 1 ImageNet-1K 图像分类性能比较
目标检测和实例分割
如表 2 所示,在 COCO 2017 数据集上,OverLoCK 同样展示出了更优的性能。例如,使用 Mask R-CNN (1× Schedule) 为基本框架时,OverLoCK-S 在 APb 指标上相较于 BiFormer-B 和 MogaNet-B 分别提升了 0.8% 和 1.5%。在使用 Cascade Mask R-CNN 时,OverLoCK-S 分别比 PeLK-S 和 UniRepLKNet-S 提升了 1.4% 和 0.6% APb。值得注意的是,尽管基于卷积网络的方法在图像分类任务中与 Transformer 类方法表现相当,但在检测任务上却存在明显性能差距。以 MogaNet-B 和 BiFormer-B 为例,两者在 ImageNet-1K 上都达到 84.3% 的 Top-1 准确率,但在检测任务中前者性能明显落后于后者。这一发现有力印证了我们之前的论点 — 卷积网络固定尺寸的卷积核导致有限感受野,当采用大分辨率输入时可能会性能下降。相比之下,我们提出的 OverLoCK 网络即使在大分辨率场景下也能有效捕捉长距离依赖关系,从而展现出卓越性能。

表 2 目标检测和实例分割性能比较

表 3 语义分割性能比较
语义分割
如表 3 所示,OverLoCK 在 ADE20K 上也进行了全面的评估,其性能在与一些强大的 Vision Backbone 的比较中脱颖而出,并且有着更优秀的 tradeoff。例如,OverLoCK-T 以 1.1% mIoU 的优势超越 MogaNet-S,较 UniRepLKNet-T 提升 1.7%。更值得一提的是,即便与强调全局建模能力的 VMamba-T 相比,OverLoCK-T 仍保持 2.3% mIoU 的显著优势。
消融研究
值得注意的是,所提出的 ContMix 是一种即插即用的模块。因此,我们基于不同的 token mixer 构建了类似的金字塔架构。如表 4 所示,我们的 ContMix 相较于其他 mixer 具有明显的优势,这种优势在更高分辨率的语义分割任务上尤为明显,这主要是因为 ContMix 具有强大的全局建模能力(更多实验请参见原文)。
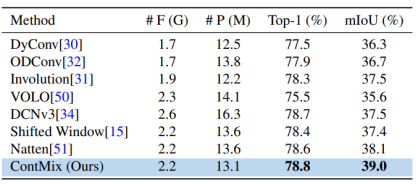
表 4 不同 token mixer 的性能比较
可视化研究
不同 vision backbone 网络的有效感受野对比:如图 3 所示,OverLoCK 在具有最大感受野的同时还具备显著的局部敏感度,这是其他网络无法兼备的能力。
Top-down Guidance 可视化:为了直观呈现 Top-down Guidance 的效果,我们采用 Grad-CAM 对 OverLoCK 中 Overview-Net 与 Focus-Net 生成的特征图进行了对比分析。如图 4 所示,Overview-Net 首先生成目标物体的粗粒度定位,当该信号作为 Top-down Guidance 注入 Focus-Net 后,目标物体的空间定位和轮廓特征被显著精细化。这一现象和人类视觉中 Top-down Attention 机制极为相似,印证了 OverLoCK 的设计合理性。

图 3 有效感受野比较

图 4 Top-down guidance 可视化
#TAO
模型调优无需标注数据!将Llama 3.3 70B直接提升到GPT-4o水平
现阶段,微调大型语言模型(LLMs)的难点在于,人们通常没有高质量的标注数据。
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
众所周知,LLM 很难适应新的企业级任务。提示(prompting)的方式容易出错,且质量提升有限,而微调(fine-tuning)则需要大量的标注数据,而这些数据在大多数企业任务中是不可用的。
Databricks 提出的模型调优方法,只需要未标注数据,企业就可以利用现有的数据来提升 AI 的质量并降低成本。
TAO(全称 Test-time Adaptive Optimization)利用测试时计算(由 o1 和 R1 推广)和强化学习(RL)算法,仅基于过去的输入示例来教导模型更好地完成任务。
至关重要的是,尽管 TAO 使用了测试时计算,但它将其作为训练模型过程的一部分;然后,该模型以较低的推理成本(即在推理时不需要额外的计算)直接执行任务。
更令人惊讶的是,即使没有标注数据,TAO 也能实现比传统调优模型更好的质量,并且它可以将像 Llama 这样的开源模型提升到与专有模型(如 GPT-4o 和 o3-mini)相当的质量水平。
借助 TAO,Databricks 已经取得了三项突破性成果:
- 在文档问答和 SQL 生成等专业企业任务中,TAO 的表现优于需要数千标注样本的传统微调方法。它让 Llama 8B/70B 等高效开源模型达到了 GPT-4o/o3-mini1 等商业模型的同等水平,且无需任何标注数据;
- 在零标注数据条件下,TAO 将 Llama 3.3 70B 模型在企业综合基准测试中的表现提升了 2.4%;
- 增加 TAO 训练阶段的算力投入,可以在相同数据条件下获得更优模型质量,且不会增加推理阶段的成本消耗。
图 1 展示了 TAO 在三个企业级任务中对 Llama 模型的提升效果:尽管仅使用原始输入数据,TAO 不仅超越了需要数千标注样本的传统微调 (FT) 方法,更让 Llama 系列模型达到了商业模型的性能水准。


图 1:Llama 3.1 8B 与 Llama 3.3 70B 在三大企业级基准测试中应用 TAO 的效果对比。TAO 带来显著的性能提升,不仅超越传统微调方法,更直指高价商业大语言模型的性能水平。
TAO 工作原理
基于测试时计算与强化学习的模型调优
TAO 的核心创新在于摒弃了人工标注数据,转而利用测试时计算引导模型探索任务的可能响应,再通过强化学习根据响应评估结果更新模型参数。
该流程通过可扩展的测试时计算(而非昂贵的人工标注)实现质量提升,并能灵活融入领域知识(如定制规则)。令人惊讶的是,在高质量开源模型上应用该方法时,其效果往往优于依赖人工标注的传统方案。

TAO pipeline
TAO 包含四个核心阶段:
- 响应生成:该阶段首先收集任务相关的输入提示或查询样本。在 Databricks 平台上,这些提示可通过 AI Gateway 自动采集;
- 响应评分:系统化评估生成响应的阶段。评分方法包含多种策略,例如基于奖励模型、偏好评分,或利用 LLM 评判器及定制规则进行任务特异性验证,确保每个响应都做到最优;
- 强化学习(RL)训练:最终阶段采用基于强化学习的方法更新大语言模型,引导模型生成与高分响应高度契合的输出。通过这一自适应学习过程,模型持续优化预测能力以提升质量;
- 持续改进:TAO 仅需 LLM 输入样本作为数据源。用户与 LLM 的日常交互自然形成该数据 —— 一旦模型部署使用,即可自动生成下一轮 TAO 训练数据。在 Databricks 平台上,借助 TAO 机制,模型会随着使用频次增加而持续进化。
虽然 TAO 在训练阶段使用了测试时计算,但最终产出的模型在执行任务时仍保持低推理成本。这意味着经过 TAO 调优的模型在推理阶段 —— 与原版模型相比 —— 具有完全相同的计算开销和响应速度,显著优于 o1、o3 和 R1 等依赖测试时计算的模型。实验表明:采用 TAO 训练的高效开源模型,在质量上足以比肩顶尖的商业闭源模型。
TAO 为 AI 模型调优提供了一种突破性方法:
- 不同于耗时且易出错的提示工程;
- 也区别于需要昂贵人工标注数据的传统微调;
- TAO 仅需工程师提供任务相关的典型输入样本,即可实现卓越性能。

LLM 不同调优方法比较。
实验及结果
接下来,文章深入探讨了如何使用 TAO 针对专门的企业任务调优 LLM。本文选择了三个具有代表性的基准。

表 2:该研究使用的基准测试概览。
如表 3 所示,在所有三个基准测试和两种 Llama 模型中,TAO 显著提升了基础 Llama 的性能,甚至超过了微调的效果。

表 3:在三个企业级基准测试中使用 TAO 的 Llama 3.1 8B 和 Llama 3.3 70B 实验结果。
与经典的测试时计算类似,当 TAO 能够使用更多的计算资源时,它会产生更高质量的结果(见图 3 中的示例)。然而,与测试时计算不同的是,这种额外的计算资源仅在调优阶段使用;最终的语言模型的推理成本与原始语言模型相同。例如,o3-mini 生成的输出 token 数量比其他模型多 5-10 倍,因此其推理成本也相应更高,而 TAO 的推理成本与原始 Llama 模型相同。

利用 TAO 提高模型多任务性能
到目前为止,该研究已经使用 TAO 来提升语言模型在单一任务(例如 SQL 生成)上的表现。接下来,该研究展示了 TAO 如何广泛提升模型在一系列企业任务中的性能。
结果如下,TAO 显著提升了两个模型的性能,将 Llama 3.3 70B 和 Llama 3.1 70B 分别提升了 2.4 和 4.0 个百分点。TAO 使 Llama 3.3 70B 在企业级任务上的表现显著接近 GPT-4o,所有这些改进都没有产生人工标注成本。

原文链接:https://www.databricks.com/blog/tao-using-test-time-compute-train-efficient-llms-without-labeled-data
#GPT-4o一键抠图
吉卜力只是开胃小菜,「换装换背景」!推理也初步显现
这几天,你要说 AI 圈最火的是哪个模型?OpenAI 的 GPT-4o 当仁不让。
吉卜力风格的图像和视频在社交圈疯传,被玩出了花。之心用 GPT-4o 和可灵做出了吉卜力版《甄嬛传》全网播放超 20w。
除了一些口型和神情还有出入,人物形象可谓是超绝还原。
X 平台上的网友利用 GPT-4o 和 Luma Ray 2,把《疯狂的麦克斯》动画版也做出来了。
,时长00:25
在网友探索 AI 动画生成的同时,还有一个功能被刨了个底朝天。在 OpenAI 的发布介绍中压根没提,但非常有用的功能 —— 画笔编辑。
,时长00:12
没错,就是这么一涂,你就能变身造物主,想怎么改图就怎么改图。
我们赶紧上手试了一下,发现效果真的很强!
把同事的照片转换成吉卜力风格后,点击生成的图片,右上方有一个画笔按钮,轻点之后就能进入到画板界面。

涂抹需要修改的部分,然后输入相关的 prompt,例如这张图里,我们输入了「移除外套只保留里面那件短袖」。

于是,一张保留了大量原图细节的脱去外套版图片就生成了。

不过,原图与新图之间还有一定差别。后面背景中石头和植被的布置以及人物的表情都发生了变化。不过整体细节相对保留完整,GPT-4o 也能够理解我们的指令。
还能换背景哦,下面这张图就把背景换成了小溪。

换个同事的童年照片,给她加顶海盗帽也是非常好用。

不过,复杂一些的转换看起来效果还不算完美。例如这个弥补了《大话西游》中至尊宝和紫霞仙子遗憾结局的换位。猴子脑袋快被金箍勒爆了,身体也没有被云雾覆盖。但是人物的细节和风格都保持住了。

推理与非推理集于一身,GPT-5 要来了?
在刷爆图像生成的同时,GPT-4o 还有了另一个重大发现:现在可以显示推理时间与思维链过程了。
这不禁令人联想,难道 OpenAI 开始合并推理与非推理模型了?正如奥特曼上个月提到的那样,OpenAI 计划统一 o 系列与 GPT 系列模型,构建可以自主判断任务需求的智能系统,不用再每次选择模型。

还有用户晒出了自己 2024 年底的截图,这可能意味着 OpenAI 并不是最近才开始测试,GPT-4o 的推理能力也持续很长时间了(6 个月以上)。

截图如下:


对此,以上两位用户展开了讨论,前一位表示现在的推理看起来比去年更长更好了。后一位称,这只是反映了 OpenAI 如何输出「推理」过程,可以看到过去是两种方式,与 o1 相同。而最近 o1、o3 与 4o 的推理看起来不一样了,非推理模型中开始出现推理了。

这并不是个例,越来越多人发现了 GPT-4o 的推理现象。

不过有人怀疑是不是 bug。即使是 bug,也许是非常有趣的 bug。

正如下面这位网友所说,看起来我们正在实时观察 GPT-5 的启动,模型版本之间的界限正在迅速模糊并合并。

#正在和DeepSeek-V3-0324做个大项目
「氛围编程」简直太疯狂了
最近超火的氛围编程(Vibe coding)你听说了吗?
这个概念是由 AI 大神 Andrej Karpathy 提出的,用户只需要自然语言描述,就能生成代码。
仅仅过去一个多月,这一术语就迅速席卷了开发者社区,大家开始纷纷整活。
刚刚,Hugging Face 联合创始人 Thomas Wolf 表示:打开 Hugging Face 上的 DeepSite 应用,你也可以体验氛围编程了。
做出这一研究的是一位名叫 enzostvs 开发者。

值得一提的是,该应用使用了最新版本的 DeepSeek-V3-0324,直接开箱即用,让你一次性创建应用程序和游戏。

体验地址:https://huggingface.co/spaces/enzostvs/deepsite
看到这,大家可能已经发现了一个有趣的事情,DeepSite 应用程序和 DeepSeek 模型都是完全开源的,开源界联手简直无敌了。
效果如何,我们先看官方 demo。
在该示例中,首先在左下角的输入框中输入提示:一个带有爆炸效果的网络版乒乓游戏。
就这么一句简单的指令,游戏就生成好了,代码、游戏全部展示在一个界面中,整个时间也就是你喝口水的功夫。
生成的游戏界面也无可挑剔,游戏名称、玩家区域、控制按钮等元素统统都包含。
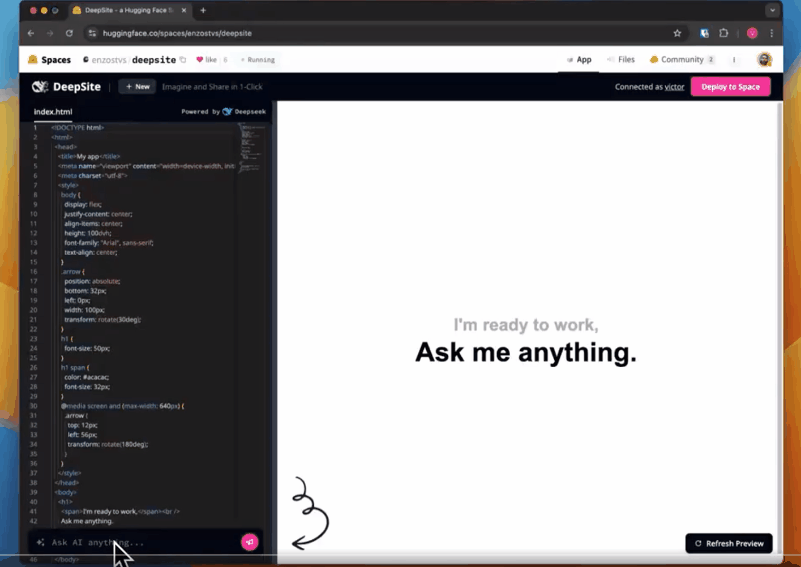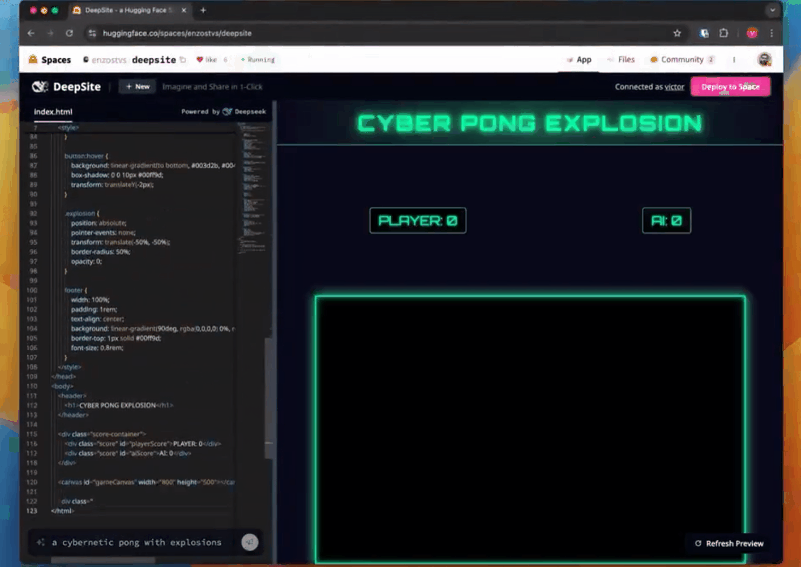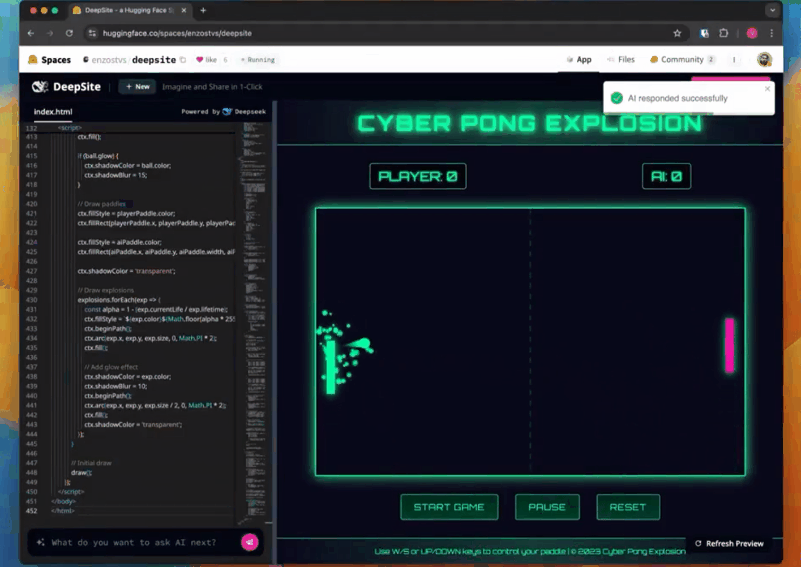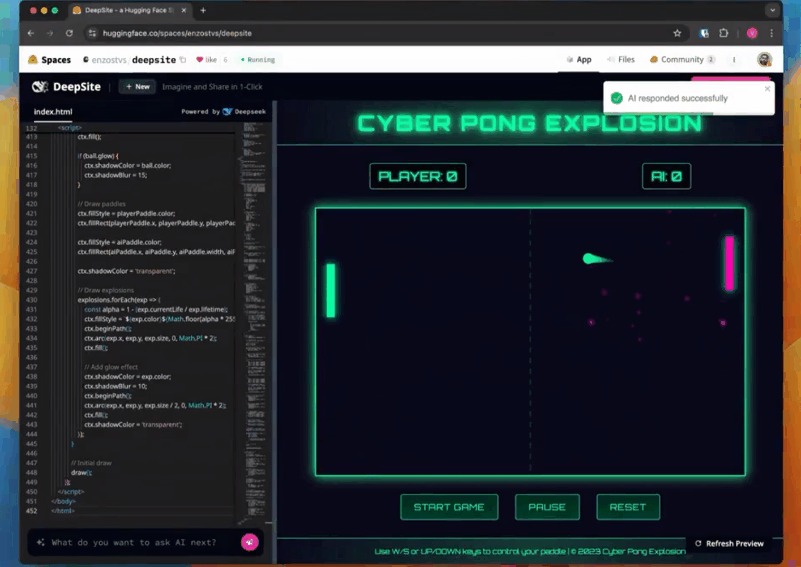
X 上也有用户展示使用效果,比如仅耗时两分半制作一个扫雷游戏。

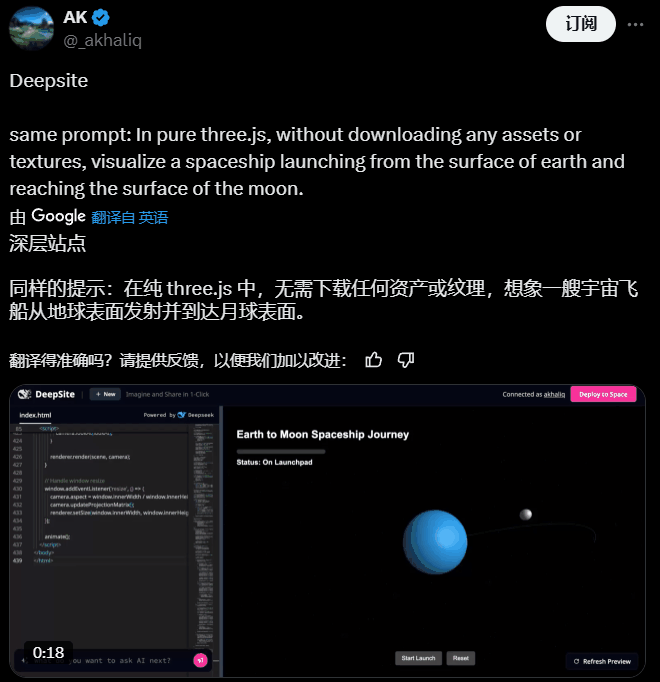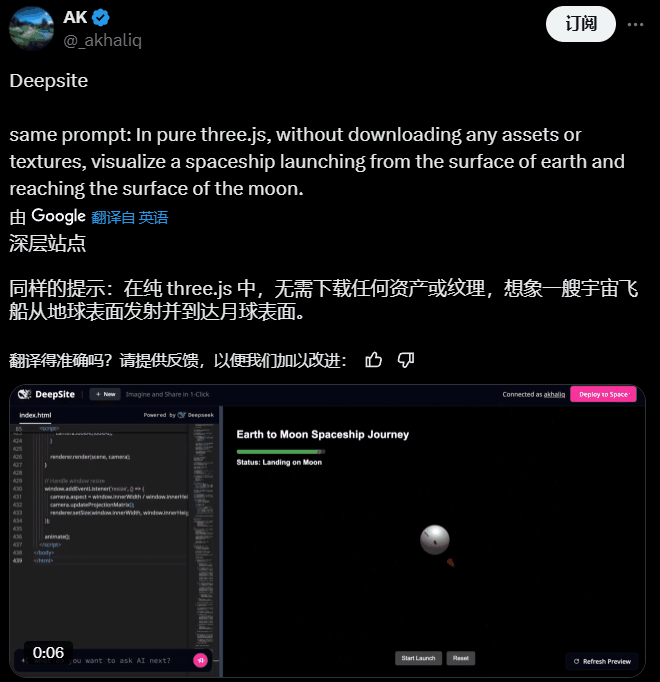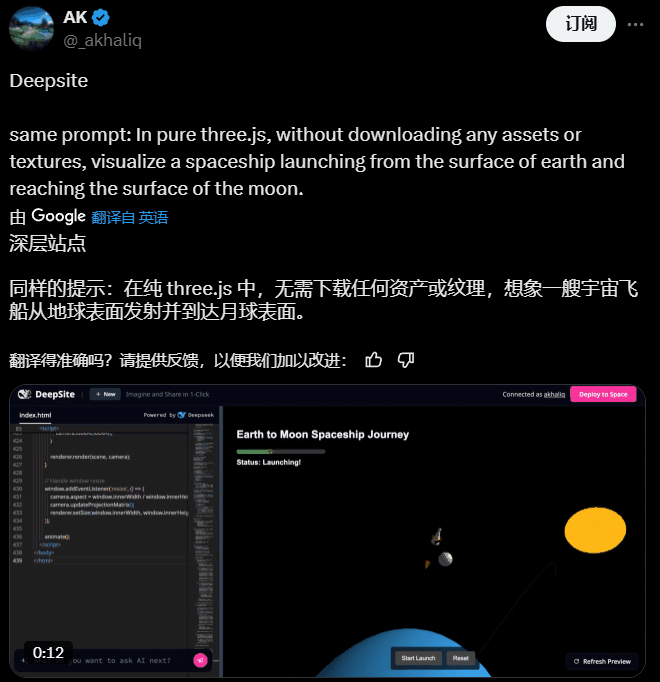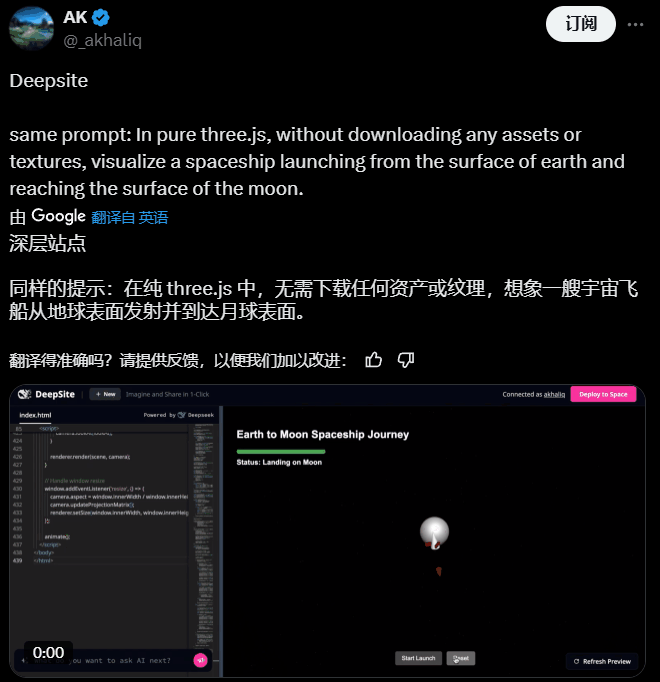
AI 大神 AK 用它创建了可交互的 3D 内容,而且它没有从外部读取图像等资产或纹理文件,而是完全通过代码实现了这种可视化!
还有用户用它制作了一个适用于 WhatsApp 的小型链接生成器。

让它生成一个动漫网站也是轻轻松松!
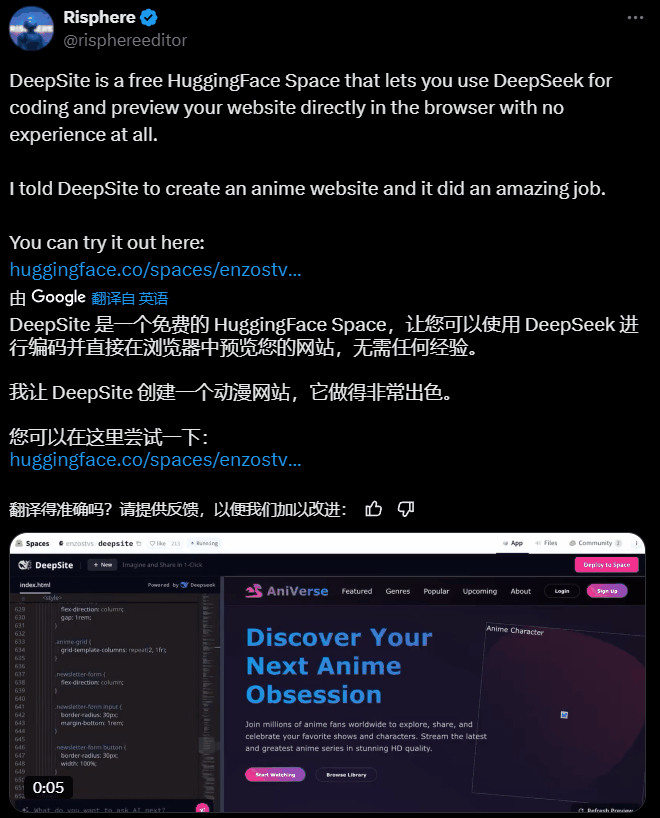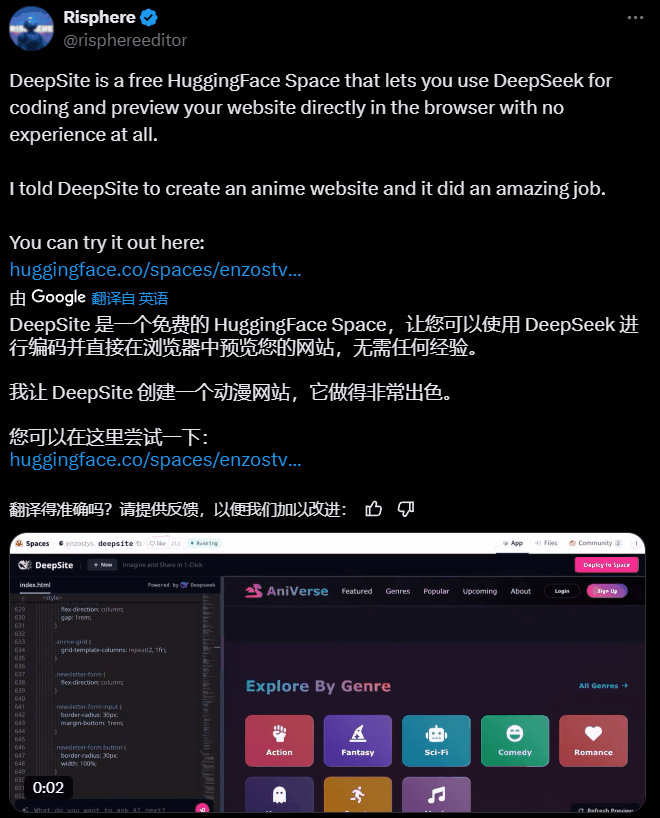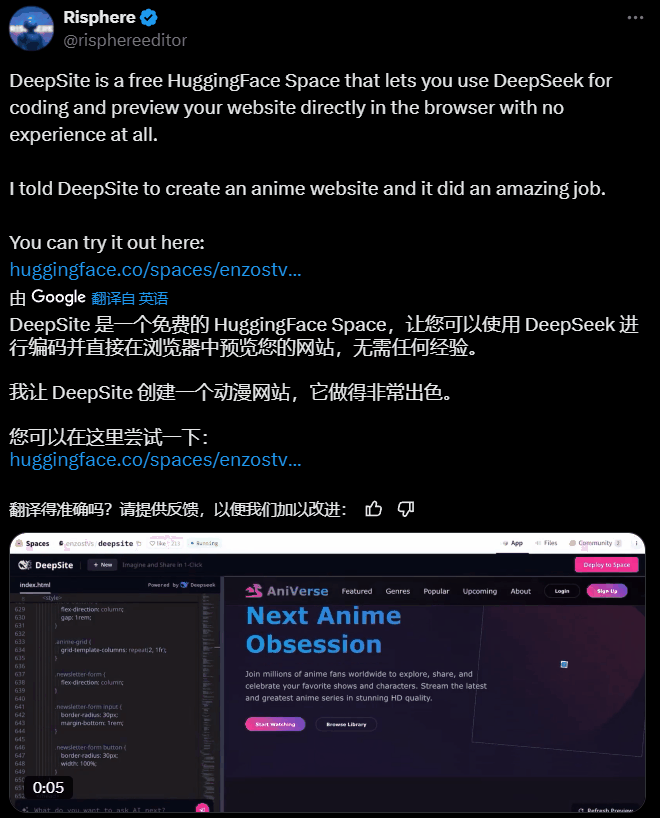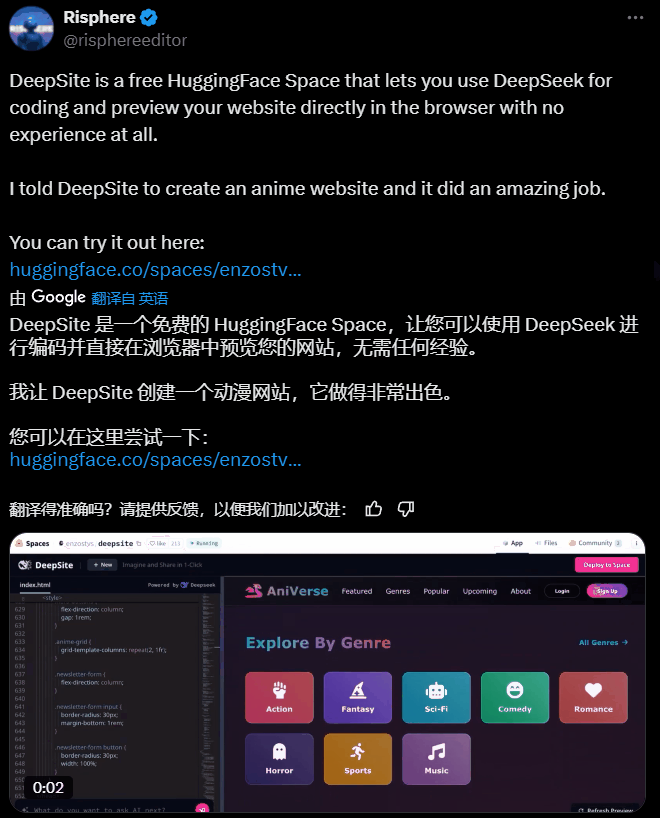
一手实测
接下来我们上手实测一下吧:
先来一个传统项目:贪吃蛇。
收到指令立刻上工,很快就搓出了一个赛博风格贪吃蛇。
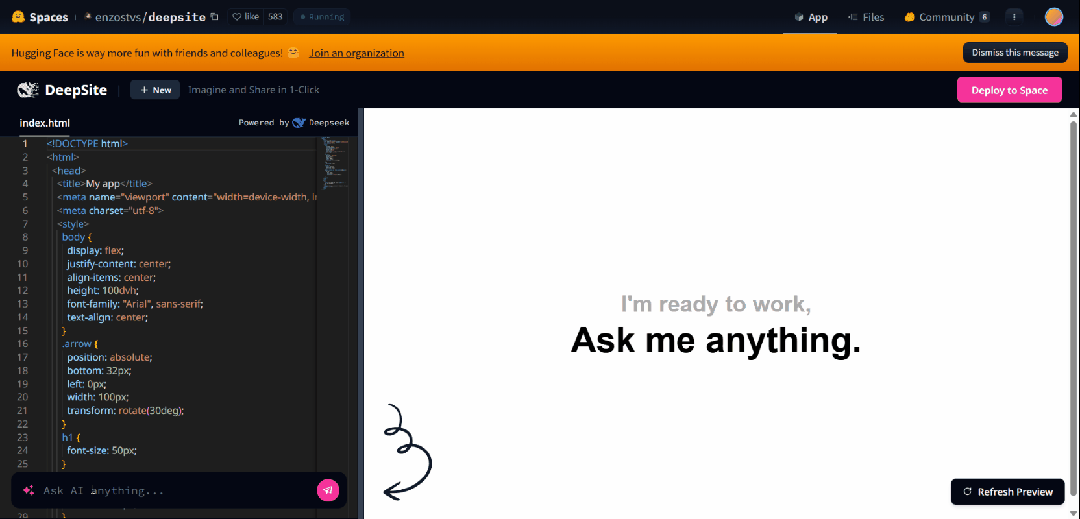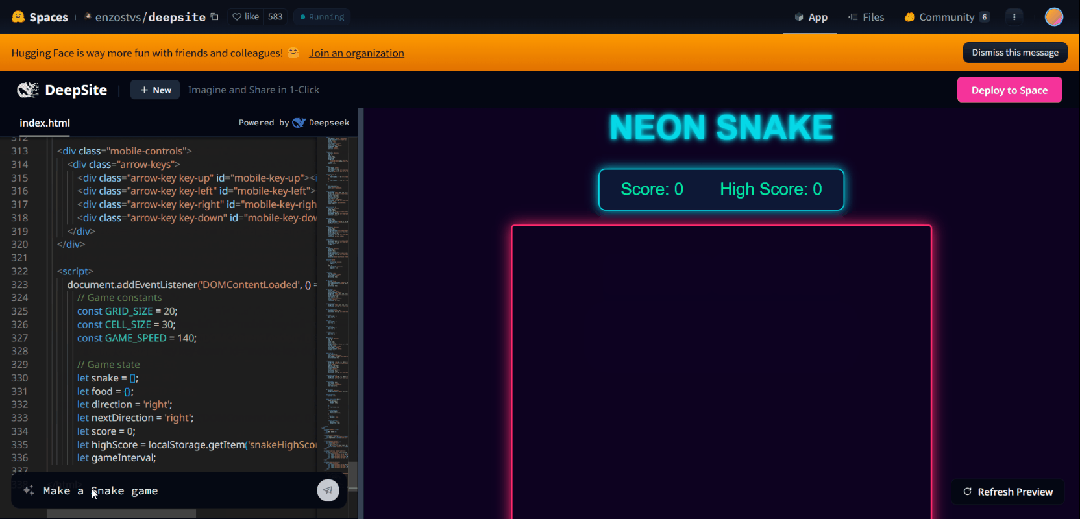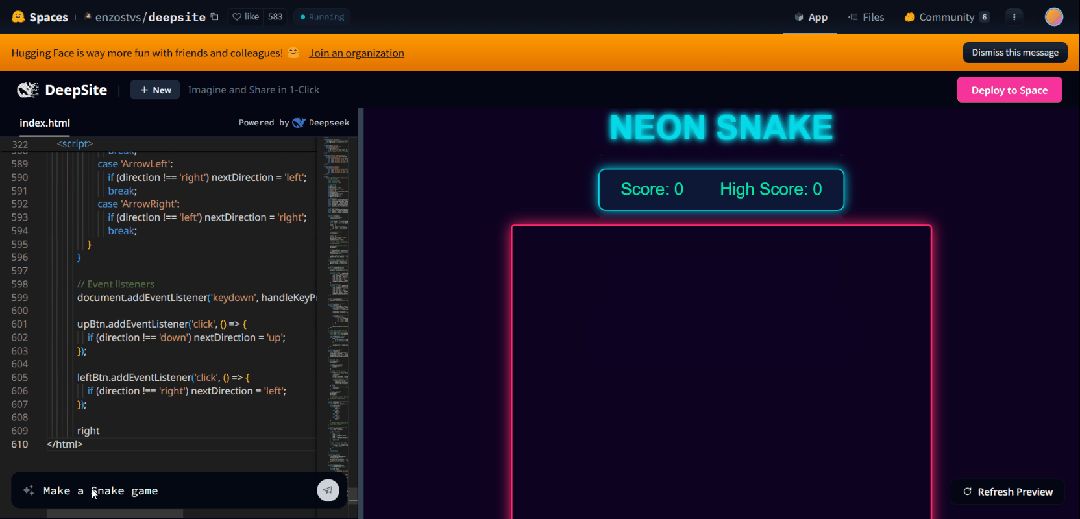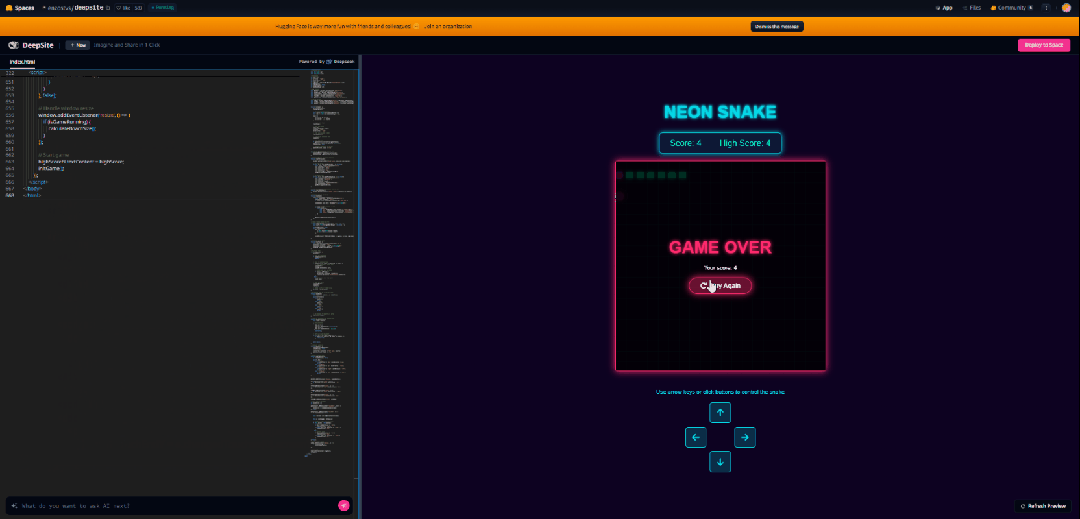
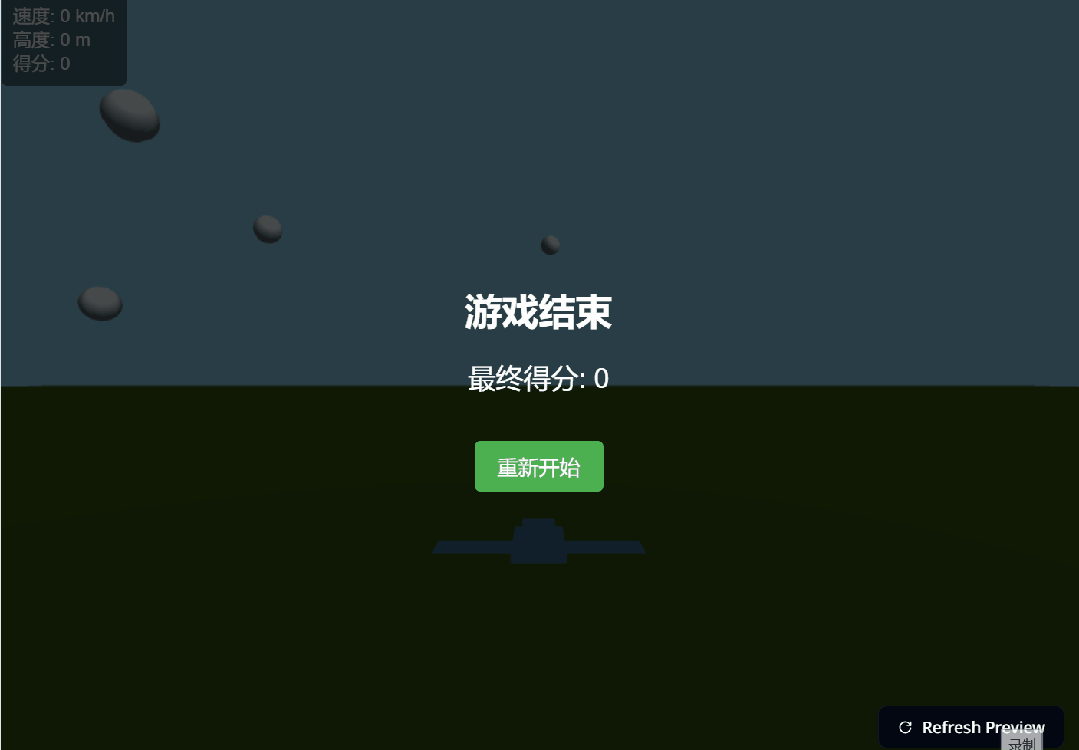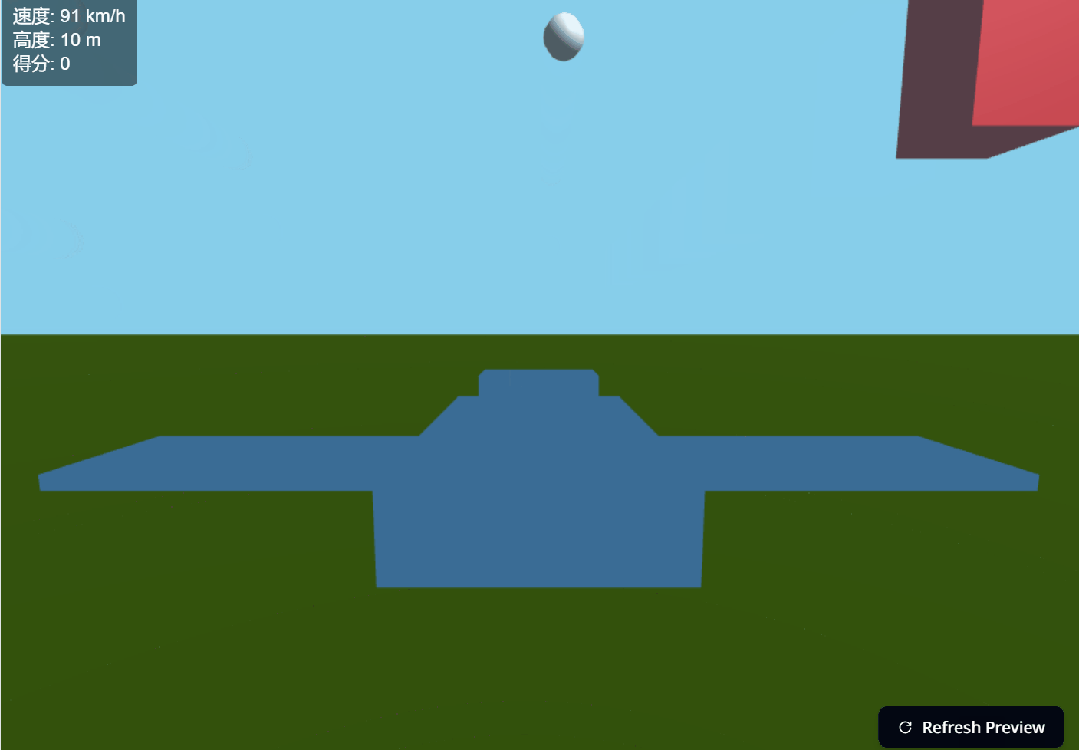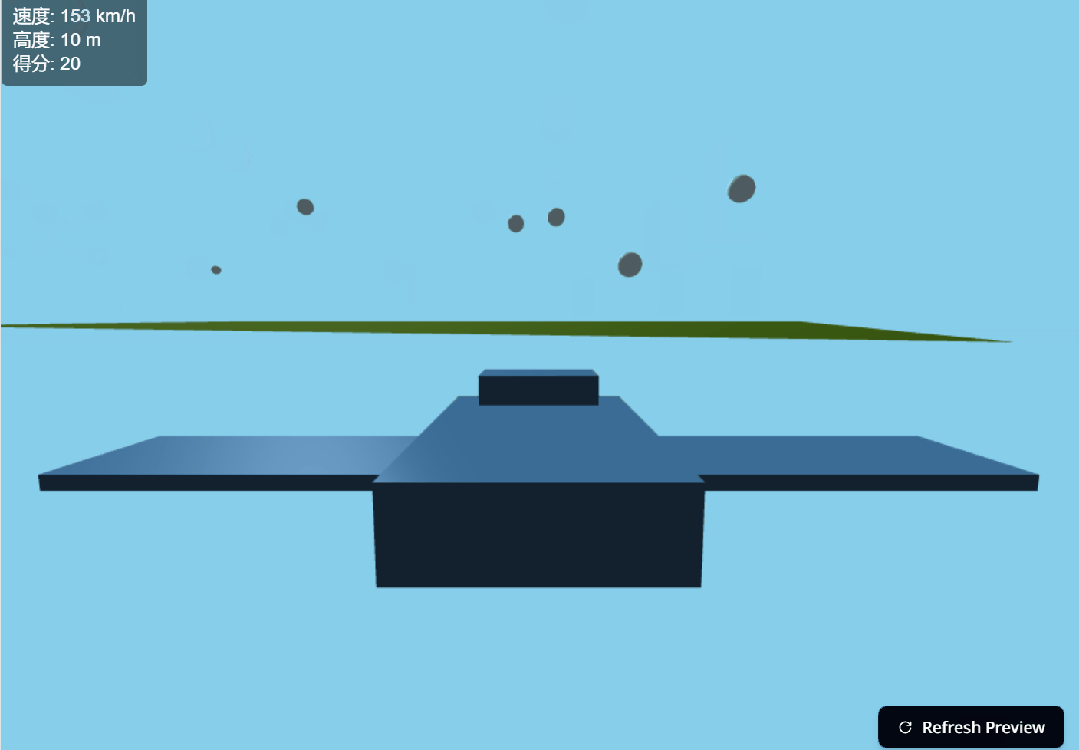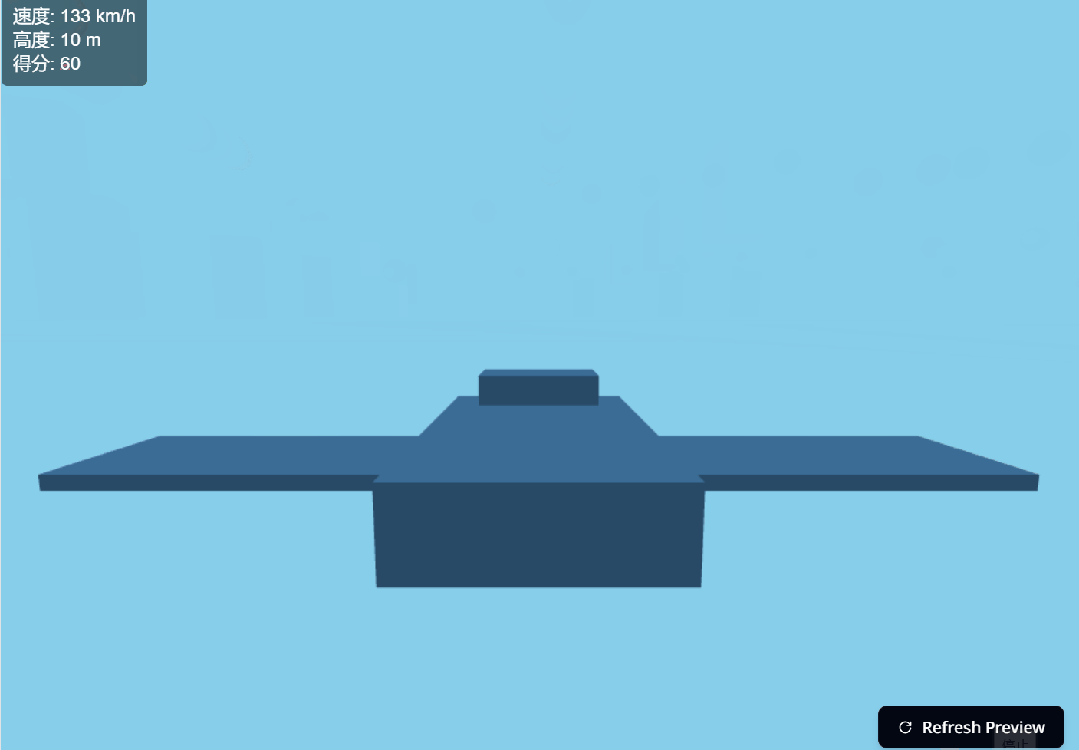
接下来,我们想要生成一个 3D 飞行模拟游戏。也是简单到只需要一句提示(帮我生成一个 3D 飞行模拟游戏)。只见 400 多行代码,嗖嗖的就跑完了,然后出现了如下右边界面。

生成的游戏也是可玩的。我们按照操作说明,实战了一番。
按下不同的操作键,效果如下所示。

最后,我们又输入提示:鹈鹕骑自行车,效果咋样,各位读者来评论吧。可能是提示词不那么准确,感觉效果不是那么好。
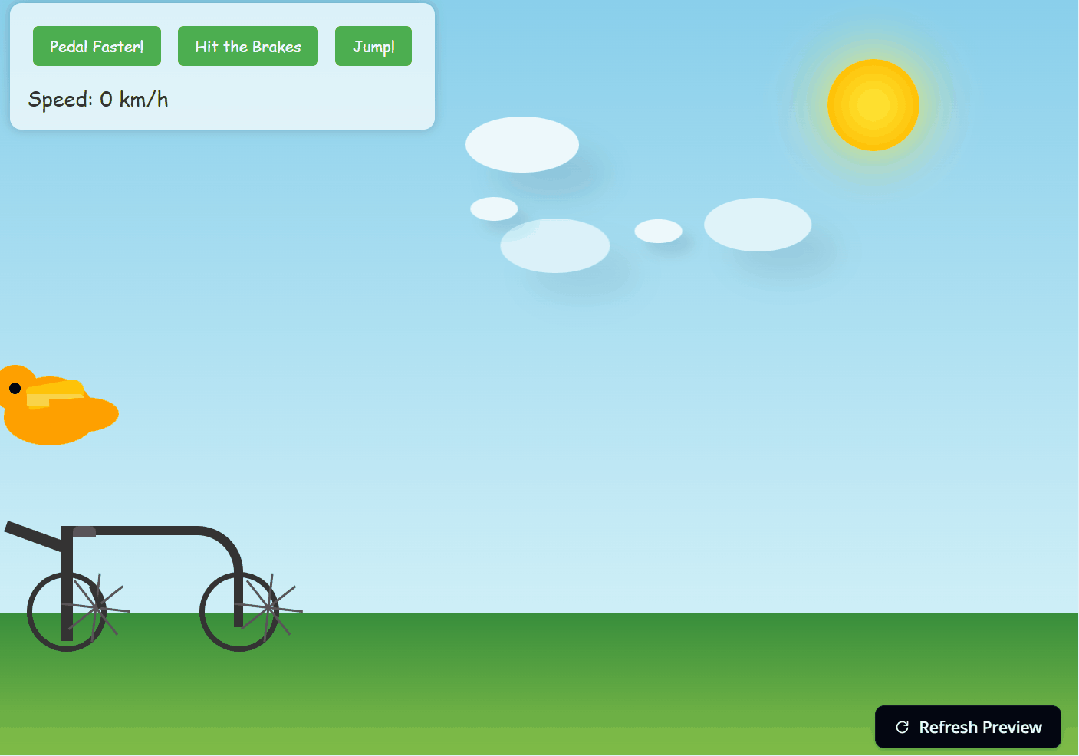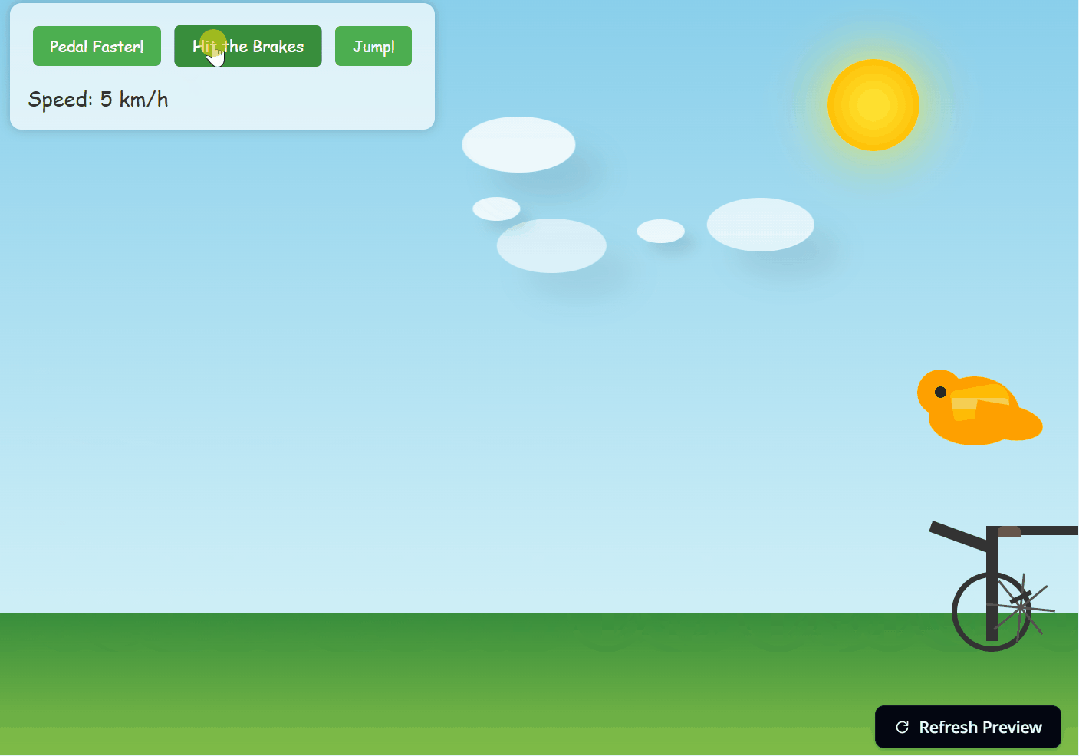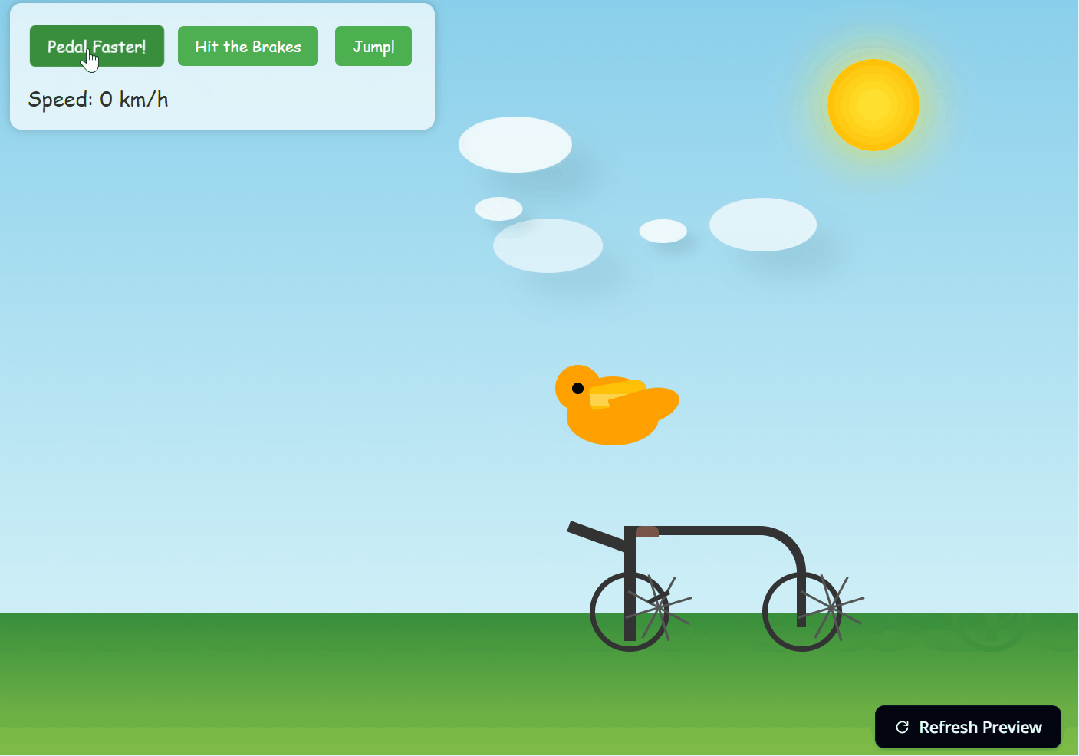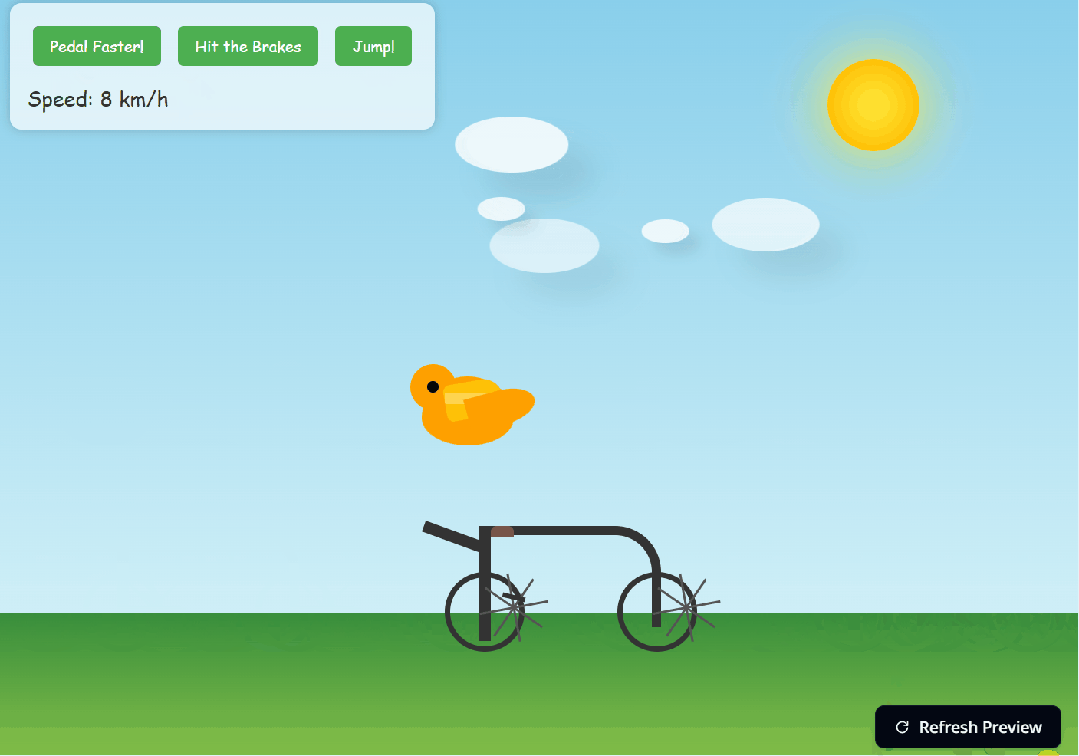
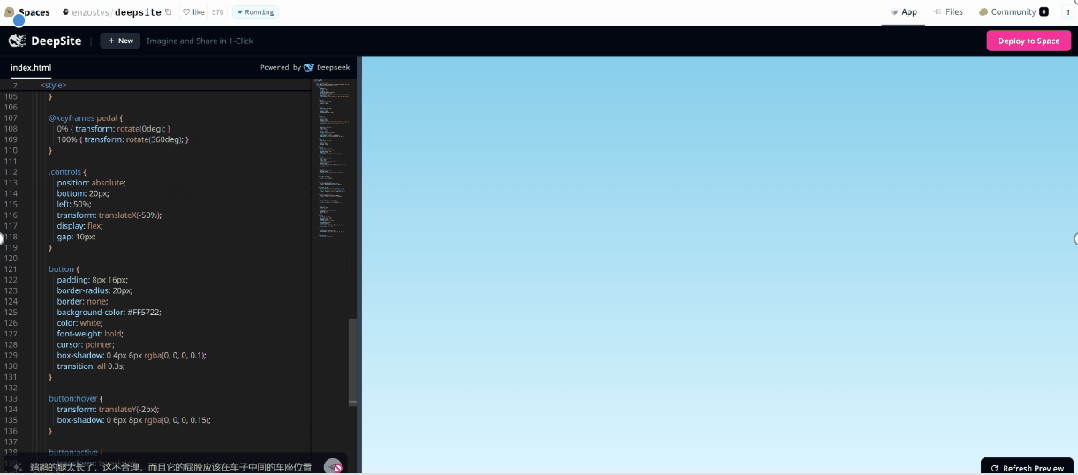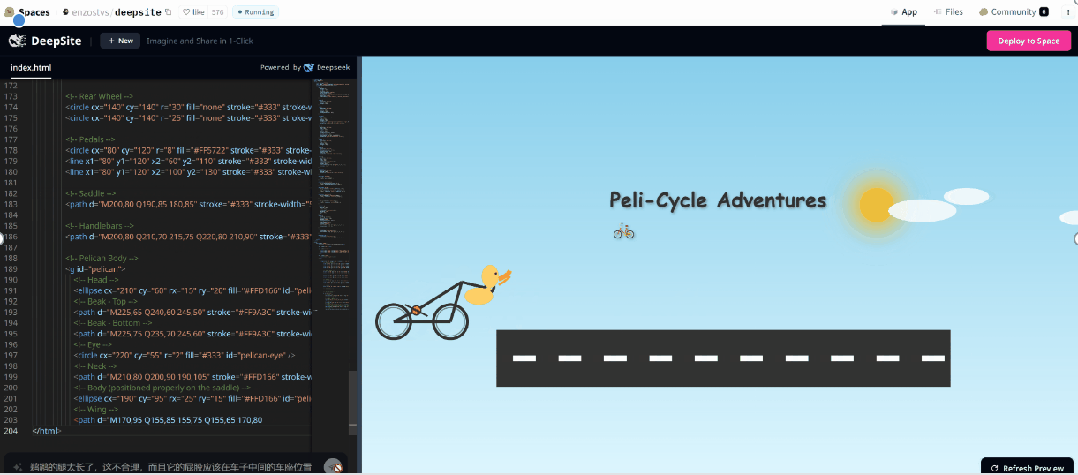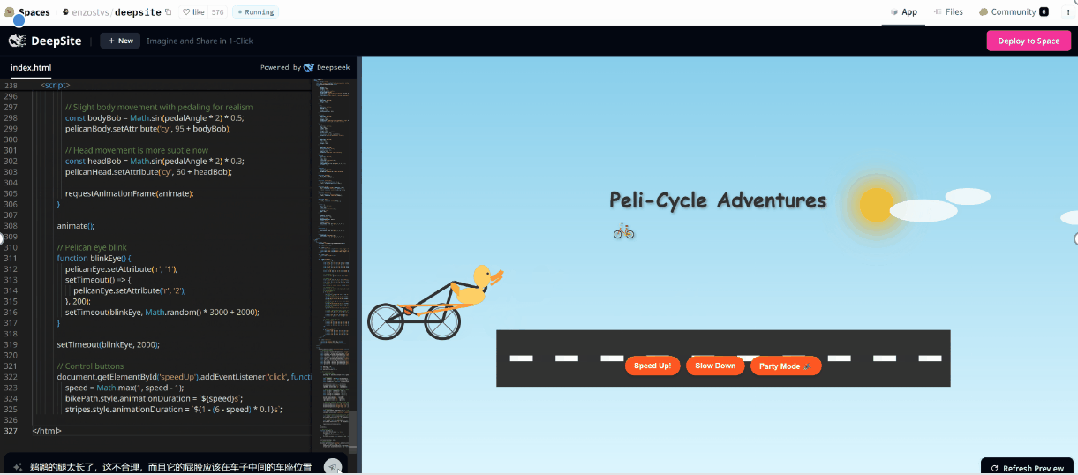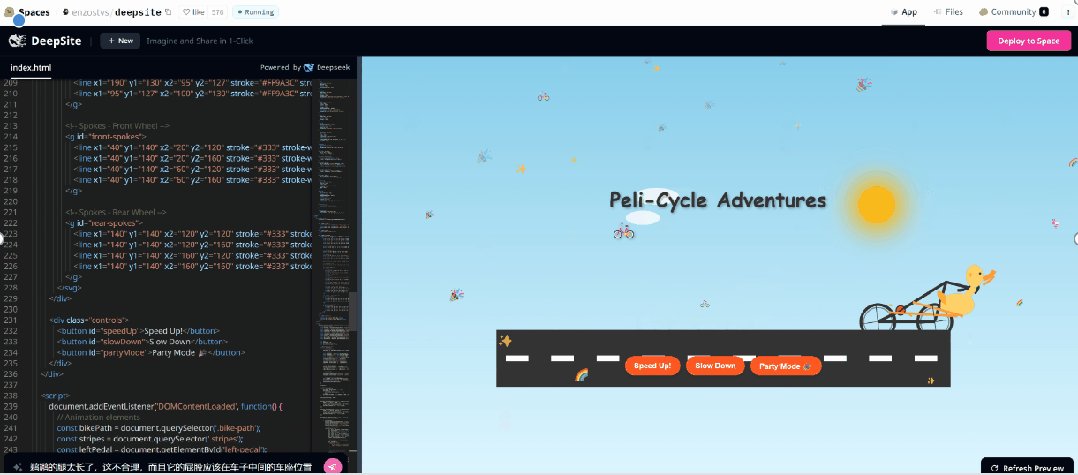
接着我们又输入:「编码一只骑自行车的鹈鹕,SVG。」后来因为轮子不转,我们又通过对话提示 AI,鹈鹕的脚应该和轮子联动,脚应该放在踏板上。结果,脚确实放在踏板上了,轮子也转了,而且可以调速度。但是,这个鹈鹕的位置还是很奇怪。
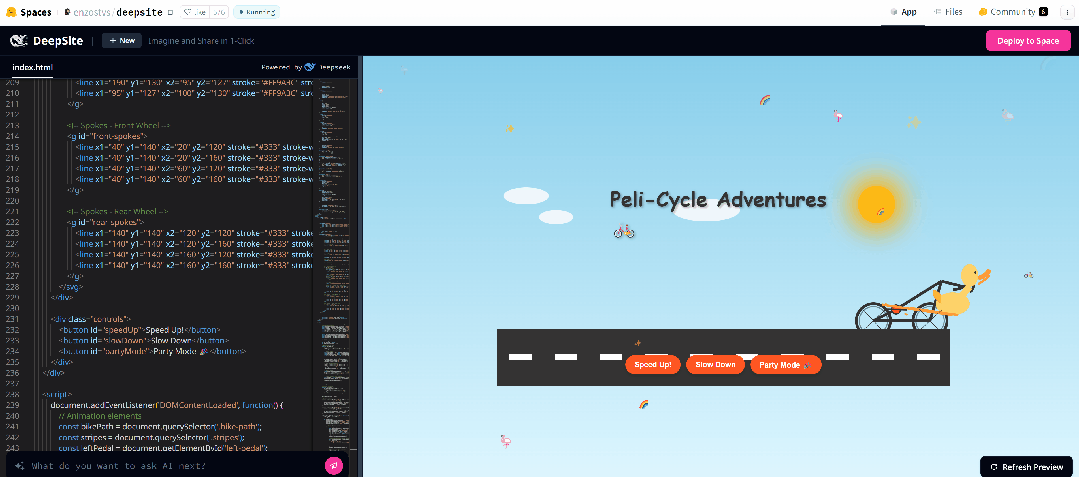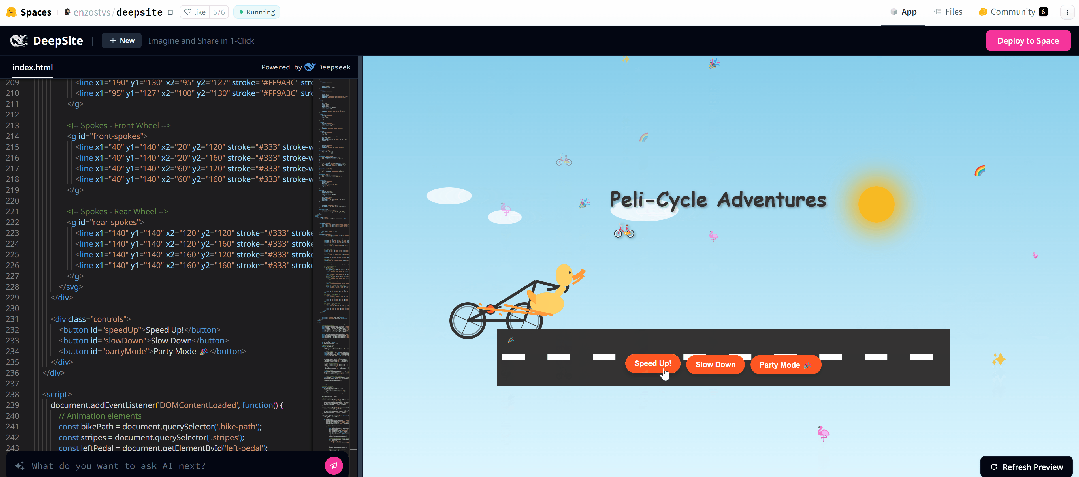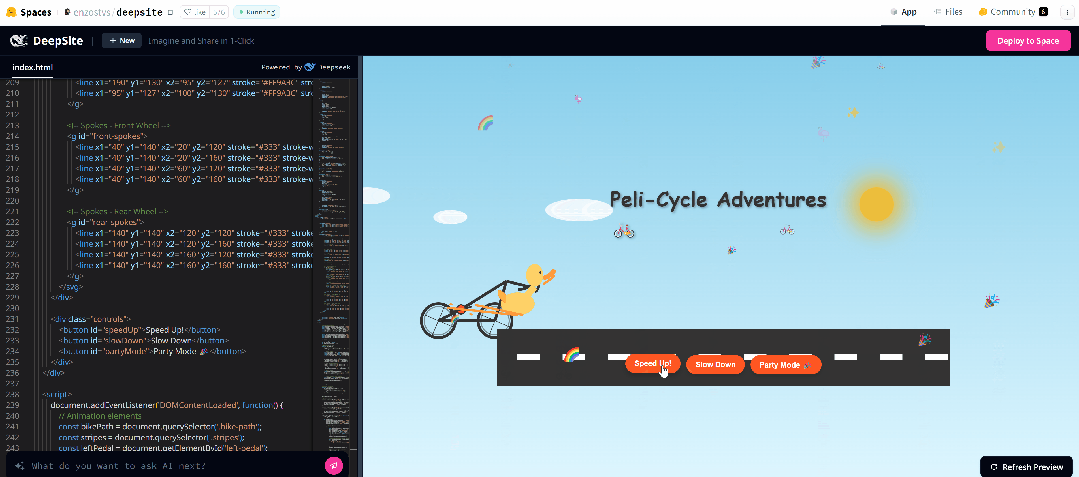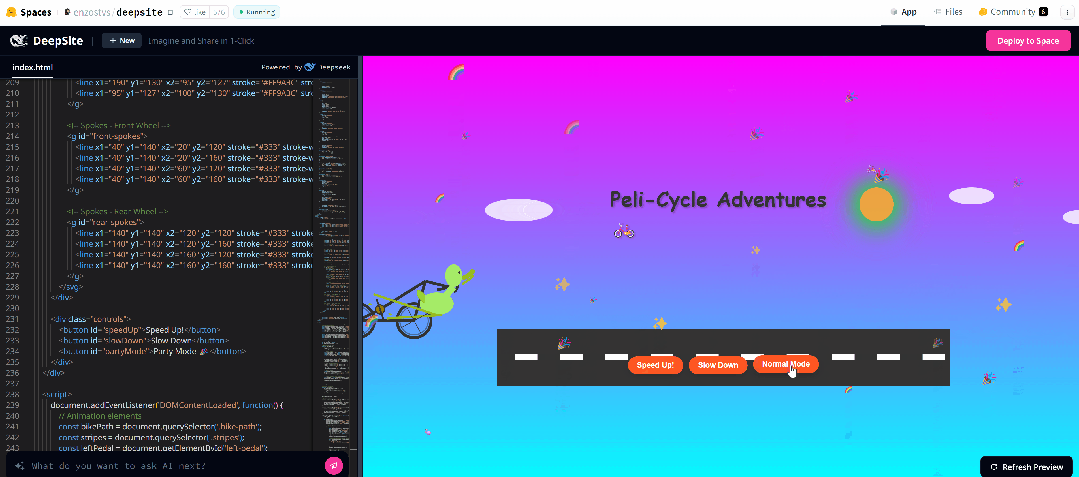
于是我们又提示 AI 进一步改进,但这次没有成功。
大家有什么新奇好玩的想法,可以前去一试,免费的应用,不薅白不薅。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









