







我自己的原文哦~ https://blog.51cto.com/whaosoft/13320248
#IDM
北大、KAUST、字节联合提出“可逆扩散模型”赋能图像重建,代码已开源!
本篇分享 TPAMI 2025 论文Invertible Diffusion Models for Compressed Sensing,北大、KAUST、字节联合提出“可逆扩散模型”赋能图像重建,代码已开源!
论文作者:Bin Chen(陈斌), Zhenyu Zhang(张振宇), Weiqi Li(李玮琦), Chen Zhao(赵琛), Jiwen Yu(余济闻), Shijie Zhao(赵世杰), Jie Chen(陈杰) and Jian Zhang(张健)
作者单位:北京大学信息工程学院、阿卜杜拉国王科技大学、字节跳动
发表刊物:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
发表时间:2025年2月5日
正式版本:https://ieeexplore.ieee.org/document/10874182
ArXiv版本:https://arxiv.org/abs/2403.17006
开源代码:https://github.com/Guaishou74851/IDM
任务背景
扩散模型作为当前非常知名且强大的生成模型之一,已在图像重建任务中展现出极大的潜力。扩散模型的基本实现方式是在训练阶段构建一个噪声估计网络(通常是一个UNet),并在推理阶段通过迭代的去噪和加噪过程完成图像生成与重建。然而,如何进一步提升扩散模型在图像重建中的性能与效率,仍然是业界探索的重点问题。
当我们将扩散模型应用于图像重建任务时,面临两个关键挑战:
- 挑战一:“噪声估计”任务与“图像重建”任务之间的偏差。扩散模型中的深度神经网络主要针对“噪声估计”任务(即,从当前变量中估计出噪声)得到最优化,而非“图像重建”任务(即,从低质量的观测数据中预测原始图像)本身。这可能导致其图像重建性能存在进一步提升的空间。
- 挑战二:推理速度慢、效率低。尽管扩散模型能够生成较为真实的图像,但其推理过程往往需要大量的迭代步骤,运行时间长,计算开销大,不利于实际应用。
针对这两个挑战,本文提出了一种可逆扩散模型(Invertible Diffusion Models,IDM)。这一方法通过引入(1)端到端的训练框架与(2)可逆网络设计,有效提升了图像重建的性能与效率。
主要贡献
我们的方法在图像重建任务中带来了两个主要创新:
1. 端到端的扩散采样图像重建学习框架
传统扩散模型在训练阶段的目标任务是“噪声估计”,而实际的目标任务是“图像重建”。
为了提升扩散模型的图像重建性能,我们将它的迭代采样过程重新定义为一个整体的图像重建网络,对该网络进行端到端的训练,突破了传统噪声估计学习范式所带来的局限。如图所示,通过这种方式,模型的所有参数都针对“图像重建”任务进行了最优化,重建性能得到大幅提升。
实验结果表明,基于Stable Diffusion的预训练权重与这一端到端学习框架,在图像压缩感知重建任务中,相比其他模型,我们的方法在PSNR(峰值信噪比)指标上提升了2dB,采样步数从原本的100步降到了3步,推理速度提升了约15倍。

2. 双层可逆网络设计:减少内存开销
大型扩散模型(如Stable Diffusion)采样过程的端到端训练需要占用很大的GPU内存,这对于其实际应用来说是一个严重的瓶颈。
为了减少内存开销,我们提出了一种双层可逆网络。可逆网络的核心思想是通过设计特殊的网络结构,让网络每一层的输出可以反向计算得到输入。
在实践中,我们将可逆网络应用到(1)所有扩散采样步骤和(2)噪声估计网络的内部,通过“布线”技术将每个采样步骤与其前后模块连接,形成一个双层可逆网络。这一设计使得整个训练过程中,程序无需存储完整的特征图数据,只需存储较少的中间变量,显著降低了训练模型的GPU内存需求。
最终,这使得我们可以在显存有限的GPU(如1080Ti)上对该模型进行端到端训练。

实验结果1. 图像压缩感知重建
在图像压缩感知重建任务中,我们的方法IDM与现有基于端到端网络和扩散模型的重建方法进行了对比。实验结果显示,IDM在PSNR、SSIM、FID和LPIPS等指标上取得明显提升。


2. 图像补全与医学成像
在掩码率90%的图像补全任务中,我们的方法能够准确恢复出窗户等复杂结构,而传统的扩散模型(如DDNM)无法做到这一点。此外,我们还将该方法应用于医学影像领域,包括核磁共振成像(MRI)和计算机断层扫描(CT)成像,取得了良好的效果。

3. 计算成本与推理时间的优化
基于传统扩散模型的图像重建方法往往需要较长的推理时间和计算开销,而我们的可逆扩散模型IDM显著缩短了这一过程。在重建一张256×256大小的图像时,推理时间从9秒缩短至0.63秒,大幅降低了计算开销。与现有方法DDNM相比,IDM的训练、推理效率和重建性能得到了显著提升。

欲了解更多细节,请参考原论文。
#特征提取:传统算法 vs 深度学习
概述
特征提取是计算机视觉中的一个重要主题。不论是SLAM、SFM、三维重建等重要应用的底层都是建立在特征点跨图像可靠地提取和匹配之上。特征提取是计算机视觉领域经久不衰的研究热点,总的来说,快速、准确、鲁棒的特征点提取是实现上层任务基本要求。
特征点是图像中梯度变化较为剧烈的像素,比如:角点、边缘等。FAST(Features from Accelerated Segment Test)是一种高速的角点检测算法;而尺度不变特征变换SIFT(Scale-invariant feature transform)仍然可能是最著名的传统局部特征点。也是迄今使用最为广泛的一种特征。特征提取一般包含特征点检测和描述子计算两个过程。描述子是一种度量特征相似度的手段,用来确定不同图像中对应空间同一物体,比如:BRIEF(Binary Robust IndependentElementary Features)描述子。可靠的特征提取应该包含以下特性:
(1)对图像的旋转和尺度变化具有不变性;
(2)对三维视角变化和光照变化具有很强的适应性;
(3)局部特征在遮挡和场景杂乱时仍保持不变性;
(4)特征之间相互区分的能力强,有利于匹配;
(5)数量较多,一般500×500的图像能提取出约2000个特征点。
近几年深度学习的兴起使得不少学者试图使用深度网络提取图像特征点,并且取得了阶段性的结果。图1给出了不同特征提取方法的特性。本文中的传统算法以ORB特征为例,深度学习以SuperPoint为例来阐述他们的原理并对比性能。

图1 不同的特征提取方法对比
传统算法—ORB特征
尽管SIFT是特征提取中最著名的方法,但是因为其计算量较大而无法在一些实时应用中使用。为了研究一种快速兼顾准确性的特征提取算法,Ethan Rublee等人在2011年提出了ORB特征:“ORB:An Efficient Alternative to SIFT or SURF”。ORB算法分为两部分,分别是特征点提取和特征点描述。ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。其速度是SIFT的100倍,是SURF的10倍。
Fast特征提取
从图像中选取一点P,如图2。按以下步骤判断该点是不是特征点:以P为圆心画一个半径为3 pixel的圆;对圆周上的像素点进行灰度值比较,找出灰度值超过 l(P)+h 和低于 l(P)-h 的像素,其中l(P)是P点的灰度, h是给定的阈值;如果有连续n个像素满足条件,则认为P为特征点。一般n设置为9。为了加快特征点的提取,首先检测1、9、5、13位置上的灰度值,如果P是特征点,那么这四个位置上有3个或3个以上的像素满足条件。如果不满足,则直接排除此点。

图2 FAST特征点判断示意图
上述步骤检测出的FAST角点数量很大且不确定,因此ORB对其进行改进。对于目标数量K为个关键点,对原始FAST角点分别计算Harris响应值,,然后根据响应值来对特征点进行排序,选取前K个具有最大响应的角点作为最终的角点集合。除此之外,FAST不具有尺度不变性和旋转不变性。ORB算法构建了图像金字塔,对图像进行不同层次的降采样,获得不同分辨率的图像,并在金字塔的每一层上检测角点,从而获得多尺度特征。最后,利用灰度质心法计算特征点的主方向。作者使用矩来计算特征点半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:
![]()
计算图像的0和1阶矩:

则特征点的邻域质心为:

进一步得到特征点主方向:
![]()
描述子计算
BRIEF算法计算出来的是一个二进制串的特征描述符,具有高速、低存储的特点。具体步骤是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512。另外,为了增加特征描述符的抗噪性,算法首先需要对图像进行高斯平滑处理。在选取点对的时候,作者测试了5种模式来寻找一种特征点匹配的最优模式(pattern)。

图3 测试分布方法
最终的结论是,第二种模式(b)可以取得较好的匹配结果。
深度学习的方法—SuperPoint
深度学习解决特征点提取的思路是利用深度神经网络提取特征点而不是手工设计特征,它的特征检测性能与训练样本、网络结构紧密相关。一般分为特征检测模块和描述子计算模块。在这里以应用较为广泛的SuperPoint为例介绍该方法的主要思路。
该方法采用了自监督的全卷积网络框架,训练得到特征点(keypoint)和描述子(descriptors)。自监督指的是该网络训练使用的数据集也是通过深度学习的方法构造的。该网络可分为三个部分(见图1),(a)是BaseDetector(特征点检测网络),(b)是真值自标定模块。(c)是SuperPoint网络,输出特征点和描述子。虽然是基于深度学习的框架,但是该方法在Titan X GPU上可以输出70HZ的检测结果,完全满足实时性的要求。

图4 SuperPoint 网络结构示意图
下面分别介绍一下三个部分:
BaseDetector特征点检测:
首先创建一个大规模的合成数据集:由渲染的三角形、四边形、线、立方体、棋盘和星星组成的合成数据,每个都有真实的角点位置。渲染合成图像后,将单应变换应用于每个图像以增加训练数据集。单应变换对应着变换后角点真实位置。为了增强其泛化能力,作者还在图片中人为添加了一些噪声和不具有特征点的形状,比如椭圆等。该数据集用于训练 MagicPoint 卷积神经网络,即BaseDetector。注意这里的检测出的特征点不是SuperPoint,还需要经过Homographic Adaptation操作。

图5 预训练示意图
特征检测性能表现如下表:

图 6 MagicPoint 模型在检测简单几何形状的角点方面优于经典检测器
真值自标定:
Homographic Adaptation 旨在实现兴趣点检测器的自我监督训练。它多次将输入图像进行单应变换,以帮助兴趣点检测器从许多不同的视点和尺度看到场景。以提高检测器的性能并生成伪真实特征点。

图7 Homographic Adaptation操作
Homographic Adaptation可以提高卷积神经网络训练的特征点检测器的几何一致性。该过程可以反复重复,以不断自我监督和改进特征点检测器。在我们所有的实验中,我们将Homographic Adaptation 与 MagicPoint 检测器结合使用后的模型称为 SuperPoint。

图8 Iterative Homographic Adaptation
SuperPoint网络:
SuperPoint 是全卷积神经网络架构,它在全尺寸图像上运行,并在单次前向传递中产生带有固定长度描述符的特征点检测(见图 9)。该模型有一个共享的编码器来处理和减少输入图像的维数。在编码器之后,该架构分为两个解码器“头”,它们学习特定任务的权重——一个用于特征检测,另一个用于描述子计算。大多数网络参数在两个任务之间共享,这与传统系统不同,传统系统首先检测兴趣点,然后计算描述符,并且缺乏在两个任务之间共享计算和表示的能力。

图 9 SuperPoint Decoders
SuperPoint 架构使用类似VGG编码器来降低图像的维度。编码器由卷积层、通过池化的空间下采样和非线性激活函数组成。解码器对图片的每个像素都计算一个概率,这个概率表示的就是其为特征点的可能性大小。
描述子输出网络也是一个解码器。先学习半稠密的描述子(不使用稠密的方式是为了减少计算量和内存),然后进行双三次插值算法(bicubic interpolation)得到完整描述子,最后再使用L2标准化(L2-normalizes)得到单位长度的描述。
最终损失是两个中间损失的总和:一个用于兴趣点检测器 Lp,另一个用于描述符 Ld。我们使用成对的合成图像,它们具有真实特征点位置和来自与两幅图像相关的随机生成的单应性 H 的地面实况对应关系。同时优化两个损失,如图 4c 所示。使用λ来平衡最终的损失:

实验效果对比:

图10 不同的特征检测方法定性比较

图 11 检测器和描述符性能的相关指标
结论
在特征检测上,传统方法通过大量经验设计出了特征检测方法和描述子。尽管这些特征在光照变化剧烈,旋转幅度大等情况下还存在鲁棒性问题,但仍然是目前应用最多、最成熟的方法,比如ORB-SLAM使用的ORB特征、VINS-Mono使用的FAST特征等都是传统的特征点。深度学习的方法在特征检测上表现了优异的性能,但是:
(1)存在模型不可解释性的问题;
(2)在检测和匹配精度上仍然没有超过最经典的SIFT算法。
(3)大部分深度学习的方案在CPU上运实时性差,需要GPU的加速。
(4)训练需要大量不同场景的图像数据,训练困难。
本文最后的Homograpyhy Estimation指标,SuperPiont超过了传统算法,但是评估的是单应变换精度。单应变换在并不能涵盖所有的图像变换。比如具有一般性质的基础矩阵或者本质矩阵的变换,SurperPoint表现可能不如传统方法。
参考
https://its304.com/article/monk1992/93469078
#Transfusion
生成理解统一模型解读 (一)|Transfusion:只用一个模型搞定图像生成和理解任务!
本文介绍了一种名为 Transfusion 的多模态模型,它通过结合语言建模(文本)和扩散模型(图像)的训练目标,实现了在单一模型中无缝生成离散文本和连续图像。研究通过大规模实验表明,Transfusion 在多模态任务上表现出色,生成质量和效率均优于现有的离散化图像处理方法,并在图像生成和文本生成任务中达到了与专门模型相当的性能。
一个模型完成图像生成和理解任务的先驱。
Transfusion 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。Transfusion 的训练数据是图像文本混合模态的数据,训练的目标函数是 Diffusion Loss (常用于训练图像生成模型) 和 Language Modeling Loss (Next Token Prediction,常用于训练语言模型)。Transfusion 可以达到 7B 的参数量级。
实验表明,Transfusion 模型既可以做文本生成和图像生成任务,也可以做图像理解任务。且作者将其与具有相似功能的 Chameleon 模型进行了对比,Transfusion 模型明显优于 Chameleon。通过引入特定于模态的编码和解码层,可以进一步提高 Transfusion 模型的性能,甚至将每个图像压缩到只有 16 个 Patch。
将 Transfusion 扩展到 7B 参数和 2T 多模态 token 训练之后可以得到一个模型,该模型可以与相似尺度的扩散模型相媲美生成图像,与相似尺度的语言模型媲美生成文本。

图1:Transfusion 框架。离散 (文本) token 自回归处理,并以 next-token prediction 方式训练。连续 (图像) 向量并行处理并在扩散目标上进行训练
1 Transfusion:类卷积线性扩散 Transformer
论文名称:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
论文地址:http://arxiv.org/pdf/2408.11039
1.1 Transfusion 研究背景
多模态生成模型需要能够感知、处理并生成离散元素 (比如 text 或 code) 和连续元素 (比如 image、audio 和 video 数据)。虽然使用 next-token prediction 技术训练的 LLM 主导离散模态的数据,那对于连续模态的数据而言,Diffusion Model 及其变体 Flow Matching 仍是最好的技术。
一个很自然的想法就是组合这两者,即 LLM 和 Diffusion Model。事实上已经有很多这样的尝试了。比如 DreamLLM,把预训练的 Diffusion Model 嫁接到 LLM 上。或者,在离散 token 上训练标准语言模型,以丢失信息为代价简化模型架构。
本文提出 Transfusion,通过训练单个模型 (不是一个 Diffusion Model,一个 LLM 嫁接)来预测离散 text token 和扩散连续 image ,可以在不损失信息的情况下完全集成两种模态。Transfusion 无缝集成了连续和离散两种模态。
Transfusion 为每个模态使用不同的目标:在 50% 文本和 50% 图像数据上预训练 Transformer 模型,文本使用 next token prediction,图像使用 diffusion。在训练的每一步,Transfusion 都使用两种模态的损失函数来训练。标准 Embedding 层将 text token 转换为向量,patchify 层把 image 表示为 patch 向量的序列。对 text token 应用 causal mode attention,对 image patch 应用 bi-directional attention。对于推理,引入了一种解码算法,它结合了语言模型文本生成的标准做法和来自扩散模型的图像生成。
Transfusion 是一个 7B transformer (包含约 0.27B 的 U-Net down/up 层),在 2T token 上进行训练。1T text token,1T image tokens (约 692M images)。图 2 显示了从模型中采样的一些生成的图像。在 GenEval 基准测试中,Transfusion 优于其他流行的模型,如 DALL-E 2 和 SDXL;与图像生成模型不同,Transfusion 还可以生成文本,且达到与 Llama 1 相同的性能水平。因此,Transfusion 是训练生成理解统一模型的一种很有前途的方法。


图2:在 2T 多模态 tokens 上训练的 7B Transfusion 模型生成的图像
1.2 Transfusion 的两个目标函数
Transfusion 是一个用两个目标训练的单一模型:语言建模和扩散。
语言建模损失就是给定一系列离散 tokens ,语言模型预测序列 的概率。标准语言模型将 分解为条件概率的乘积 $\prod_{i=1}^n P_\theta\left(y_i \mid y_{<i}\right)$ 。这就是一个自回归分类任务。="" next-token="" predictinotallow="" 的目标函数,也可以说成是="" lm="" loss:<="" p="">

一旦经过训练之后,语言模型也可用于通过从模型分布 P_\theta 的 token 中采样 token 来生成文本,通常使用温度和 top-p 截断。
DDPM 学习逆转噪声添加的过程。与通常使用离散 token 的语言模型不同,扩散模型在连续向量( )上运行,这使它们特别适合涉及图像等连续数据的任务。扩散模型涉及 2 个过程:描述原始数据如何变成噪声的前向过程,以及模型学习执行的反向去噪过程。
前向过程
前向过程定义了如何创建噪声数据。给定一个数据点 ,定义一个马尔可夫链,它在 步上逐渐添加高斯噪声,创建一系列越来越嘈杂的版本 。每个步骤的定义是: ,其中 根据预定义的噪声时间表随时间增加。这个过程可以重参数化,允许使用单个高斯噪声样本 从 直接采样 :

其中, 。
反向过程
训练扩散模型执行反向过程 ,学习逐步去噪数据。训练一个参数为 的模型 来估计给定噪声数据 和时间步 的噪声 。在实践中,模型通常以额外的上下文信息 为条件,例如在生成图像时的 caption。因此,通过最小化均方误差损失来优化噪声预测模型的参数:

噪声 schedule
在创建噪声 时, 决定了噪声方差,本文基本遵循 。
推理
解码是迭代完成的,每一步处理一些噪声。从 处的纯高斯噪声开始,模型 预测在时间步 积累的噪声。然后根据噪声调度对预测的噪声进行缩放,从 中去除预测噪声的比例量,生成 。Classifier-free guidance(CFG)将以上下文 为条件的模型的预测与无条件得预测进行对比来改进生成,但代价是计算量加倍。
1.3 Transfusion 具体方法
Transfusion 是一种训练单个统一的模型来理解和生成离散和连续模态的方法。主要创新是证明了可以在在共享数据和参数的情况下,使用对于不同模态的单独的损失函数,即用于文本的语言建模损失函数、用于图像的扩散损失。图 1 是 Transfusion 的流程。
数据准备
作者对两种模态的数据进行了实验:离散的文本和连续的图像。每个文本字符串都被标记为来自固定词汇表的离散 token 序列,其中每个 token 表示为一个整数。每个图像都使用 VAE 编码为 latent patch,其中每个 patch 表示为一个连续向量。patch 从左到右的从上到下排序。也就是每个图像最终都会转化为一系列的 patch 向量。作者在把这些向量插入到文本序列之前,使用特殊的 BOI 作为开始 token,EOI 作为结束 token,围绕图像序列。
因此,最终序列的样子是:包含了离散元素 (表示文本 token 的整数) 和连续元素 (表示图像 patch 的向量)。
模型架构**
模型参数的绝大部分都属于一个 Transformer,它输入一个序列,输出一个序列,无论模态如何。为了将数据转换到这个空间,作者对于不同模态的数据使用了具有非共享参数的特定的组件。
对于文本而言,文本是嵌入矩阵,将每个输入整数转换为向量空间,每个输出向量转换为词汇表上的离散分布。
对于图像,将 的 patch 转化为单个向量的方法,作者试了 2 种:1) 线性层;2) U-Net Up 或者 Down 层。如图 3 所示。

图3:使用预训练的 VAE 将图像从潜在表示转换为 latent 表征,然后使用简单线性层或 U-Net 下采样块转换为 patch 表征
注意力机制**
语言模型通常使用 causal mask 在单个前向后向传递中有效地计算整个序列的损失和梯度,而不会泄露来自未来 token 的信息。虽然文本自然是连续的,但图像不是,并且通常使用不受限制的 bi-directional attention 进行建模。Transfusion 通过将 causal attention 应用于序列中的每个元素以及每个单独图像元素之间的 bi-directional attention 来结合这两种注意力模式。这允许每个图像 patch 关注同一图像中的所有其他 patch,但只关注序列中先前出现的其他图像 patch 或者文本 。作者发现启用图像内注意力可以显着提高模型性能。图 4 显示了一个示例 Transfusion attention mask。

图4:在 causal mask 的基础上,Transfusion 允许同一图像的 patch 相互看见
训练目标
为了训练本文模型,作者将语言建模目标 LM Loss 应用于文本标记的预测,将扩散目标 DDPM Loss 应用于图像 patch 的预测。LM Loss 是 per-token 计算的,而 DDPM Loss 是 per-image 计算的,这可能会跨越序列中的多个元素(图像 patch)。具体来说,根据扩散过程为每个输入 添加噪声 ,在 patchification 之前产生 ,然后计算图像级扩散损失。通过简单地将每个模态上计算的损失与平衡系数 结合起来:

这个目标函数将离散分布损失与连续分布损失结合以优化相同的模型。未来作者将继续探索将扩散替换为流匹配。
推理过程
Transfusion 的解码算法在两种模式之间切换:LM 和 Diffusion。在 LM 模式下,遵循从预测分布中逐 token 采样。当采样 BOI 令牌时,解码算法切换到扩散模式,从扩散模型中解码。具体来说,以 个图像 patch 的形式附加到输入序列(取决于所需的图像大小),并去噪 步。在每一步 ,采用噪声预测并使用它来生成 ,然后覆盖序列中的 。一旦扩散过程结束,将 EOI 标记附加到预测图像上,并转换回 LM 模式。该算法能够生成任何混合文本和图像模式。
1.4 实验设置评测
在单模态和跨模态任务上评测 Transfusion,如图 5 所示。text-to-text 任务使用在 Wikipedia 和 C4 corpus 上的困惑度进行评测,text-to-image 任务使用 MS-COCO benchmark 进行评测,还有 GenEval 评测框架。image caption 任务在 MS-COCO 上评测,汇报 CIDEr 得分。

图5:本文使用的评估方法
Baseline
本文遵循 Chameleon 的训练策略,训练一系列数据和计算控制的模型。Chameleon 和 Transfusion 之间的主要区别在于,虽然 Chameleon 离散化图像并将它们处理为 token,但 Transfusion 将图像保持在连续空间中,消除了量化信息瓶颈。为了进一步最小化任何混杂变量,使用完全相同的数据、计算和架构训练 Chameleon 和 Transfusion 的 VAE,唯一区别是 Chameleon VQ-VAE 的量化层和码本损失。Chameleon 还修改了 Llama 架构,添加了 query-key normalization, post-normalization, denominator loss 和使用较低学习率 1e-4 来应对训练不稳定性。
数据
对于几乎所有的实验,作者以 1:1 的 token 比从两个数据集中采样 0.5T token。对于文本,使用 Llama 2 分词器和语料库,包含跨不同域分布的 2T tokens。对于图像,使用 380M 许可 Shutterstock 图像和字幕的集合。每个图像都是中心裁剪的,并调整大小以产生 256×256 像素。
Latent 图像表征
作者训练了一个 86M 参数的 VAE。使用 CNN 编码器和解码器,latent 维度为 8。训练目标结合了重建损失和正则化损失。将 256×256 像素的图像降维到 32×32×8,其中每个 latent 的 8 维 latent 像素 (在概念上) 代表原始图像中的 8×8 patch,并训练 1M 步。对于 VQ-VAE 训练,与 VAE 训练描述的设置遵循相同的训练策略。除了 的 替换 codebook commitment loss。我们使用 16,384 个标记类型的码本。
模型配置
为了研究缩放趋势,作者按照 Llama 的标准设置,训练了 5 种不同的大小的模型,即 0.16B、0.37B、0.76B、1.4B 和 7B 参数。图 6 详细描述了每个设置。

图6:Transfusion 的模型大小和配置
推理
在文本模式下,使用 greedy decoding 生成文本。对于图像生成,采样 250 个 diffusion steps (模型在 1,000 个 time steps 上进行训练)。遵循 Chameleon 并在比较实验中使用系数为 5 的 CFG。该值对于 Transfusion 是次优的。因此,Transfusion 在消融实验使用 3 的 CFG,并遵循在大规模实验中调整每个系数的标准实践。
1.5 与 Chameleon 的比较
作者做了一系列对照实验来比较不同模型大小和 token 数的 Transfusion 与 Chameleon 进行比较。为简单起见和参数控制,这些实验中的 Transfusion 使用简单的 linear 图像 Encoder/Decoder,Patch Size 为 2×2,以及双向注意力。对于每个基准,在 log-FLOPs 曲线上的对数度量上绘制所有结果。
图 7 显示了缩放趋势。在每个测试中,Transfusion 始终表现出比 Chameleon 更好的 scaling law。虽然线条接近平行,但 Transfusion 显着更好。图像生成中计算效率的差异尤为显着,Transfusion 使用 34× 的计算量获得与 Chameleon 相当的 FID。

图7:Transfusion 和 Chameleon 模型在不同尺度下的性能,控制参数、数据和计算
图8 是 parity FLOP ratio,即 Transfusion 和 Chameleon 达到相同性能水平所需的 FLOPs 之比。

图8:最大 (7B) Transfusion 和 Chameleon 模型的性能。这两个模型都在 0.5T token 上训练
令人惊讶的是,Transfusion 也在纯文本 benchmark 表现出好的性能,即使 Transfusion 和 Chameleon 模型以相同方式建模文本。图 9 显示,Chameleon 存在对架构所做的稳定性修改,也引入 image token。对量化 image token 的训练在所有 3 个 benchmark 上降低了文本性能比扩散更多。一个假设是这源于输出分布中 text token 和 image token 之间的竞争;或者,扩散在图像生成方面可能更高效,且需要更少的参数,允许 Transfusion 模型使用比 Chameleon 更多的容量来对文本进行建模。

图9:与原始 Llama 2 方法相比,0.76B Transfusion 和 Chameleon 模型在纯文本基准上的性能
1.6 消融实验Patch Size
Transfusion 模型可以使用不同大小的 Patch Size。更大的 Patch Size 允许模型在每个 training iteration 中打包更多的图像并显着减少推理计算,但代价是可能会损失性能。图 10 展示了这些性能权衡。虽然性能会持续下降,因为每个图像都用更少的 patches 表示了,但 U-Net encoding 的模型受益于更大 Patch。作者认为这是由于训练期间看到的总图像的数量更多。作者还观察到,对于较大的 Patch Size,文本性能会恶化,这可能是因为 Transfusion 需要更多的参数来学习如何处理 patches 较少的图像,从而减少推理计算。

图10:不同 Patch Size 的 0.76B Transfusion 模型的性能
Patch Encoder 和 Decoder 架构
到目前为止,实验表明,使用 U-Net 比简单的线性层具有优势。一个可能的原因是该模型受益于 U-Net 架构的归纳偏置;另一种假设是,这一优势源于 U-Net 层引入的整体模型参数增加。为了将这 2 个混杂因素解耦,将核心Transformer 扩展到 7B 参数,同时保持 U-Net 参数数量,额外的编码器/解码器参数仅占总模型参数的 3.8%,相当于 token Embedding 参数的数量。
图 11 显示,尽管 U-Net 的相对优势随 Transformer 尺寸的增长而缩小,但依然是有的。例如,在图像生成中,U-Net Encoder 和 Decoder 使得更小的模型,比具有 linear patchify 层的 7B 模型获得了更好的 FID 分数。作者观察到 image caption 的类似趋势,添加 U-Net 层可以提高 1.4B Transformer 的 CIDEr 分数,超过 linear 层的 7B 模型的性能。总体而言,U-Net Encoder 和 Decoder 似乎确实具有归纳偏差的好处,而不仅仅是加了额外的参数。

图11:不同大小 Transfusion 的 Linear 和 U-Net 变体的性能。Patch Size 设置为 2×2 latent。模型参数仅指 Transformer
图像噪声
本文训练数据中,80% 的数据是 text-image 对,就是以 text 作为 condition 来生成 image。20% 的数据是 image-caption 对,就是以 image 作为 condition 来生成 caption。直觉是图像生成可能比图像理解更需要大量数据的任务。但是,这些图片因为 diffusion loss,是 noised 的。作者测试了 20% 数据中,将 diffusion noise 限制为 t=500 (一半) 的效果。图 12 显示,噪声限制显着提高了 image caption,如 CIDEr 分数,而其他 benchmark 的影响相对较小 (小于 1%)。
生成实验结果
到目前为止,Transfusion 比了 Chameleon 和 Llama,但尚没有将其图像生成能力与最先进的图像生成模型进行比较。为此,作者训练了一个具有 U-Net Encoder 和 Decoder 的 7B 参数大小,在 2T token (包括 1T 文本语料库标记和 3.5B 图像及其标题) 上训练的模型。该变体的设计选择和数据混合更倾向于图像生成。图 2 和展示了该模型生成的图像。

图12:与类似尺度模型相比,在等效 2T token 上训练的 7B Transfusion 模型 (U-Net Encoder 和 Decoder、2×2 潜在像素块) 的性能。除了 Chameleon 之外,所有其他模型都仅限于生成一种模态 (文本或图像)。
作者将 Transfusion 与其他相似尺度图像生成模型的结果以及一些公开可用的文本生成模型进行比较。图 12 显示 Transfusion 实现了与 DeepFloyd 等高性能图像生成模型相似的性能,同时超越了之前发布的模型,包括 SDXL。最后,Transfusion 模型也可以生成文本,并且与在相同文本数据分布上训练的 Llama 模型相当。
#SAFE
仅用1.44M参数超越SOTA 4.5个点!小红书&中科大提出轻量高效的AI图像检测模型
仅用1.44M参数量实现了通用AI图片检测,在33个测试子集上达到96.7% 准确率,超 SOTA 模型 4.5 个百分点。
当下,AI生成图像的技术足以以假乱真,在社交媒体肆意传播。
如何对不同生成模型实现通用检测?
小红书联合中国科学技术大学给出了解决方案,仅用1.44M参数量实现了通用AI图片检测,在33个测试子集上达到96.7% 准确率,超 SOTA 模型 4.5 个百分点。
这项研究目前已经被 KDD 2025 接收。
AI图像共性:源于成像机制
要实现通用的 AI 图像检测,核心问题是如何泛化到未知的生成模型上去,现在主流的生成模型包括生成对抗网络 GANs 和扩散模型 DMs。
研究团队从生成模型架构的共性出发,期望从 AI 图像和真实图像的成像机制的差异中找到突破口。

在 GANs 中,先通过全连接层把低分辨率的潜在特征变成高分辨率,然后用上采样和卷积操作合成图像。DMs 呢,先把有噪图像通过池化和卷积操作降维,再通过同样的操作升维预测噪声。
这两种模型在合成图像时,都大量使用上采样和卷积,而这两个操作在数值计算上相当于对像素值加权平均,会让合成图像相邻像素的局部相关性变强,留下独特的 “伪影特征”,这就是 AI 图像检测的关键线索。
检测方法 “跑偏”:错在训练策略
想象一下,你要在一堆真假难辨的画作里找出赝品,如果用来鉴定的方法本身就有缺陷,那肯定很难完成任务。
现有的 AI 图像检测方法,就面临着这样的困境。
当前的 AI 图像检测方法大多将重点放在挖掘真实图像与AI图像之间的通用差异,,也就是“通用伪影特征”,却忽略了训练过程中的关键问题。
研究团队发现,当前的训练模式存在两大问题。

第一个问题是“弱化的伪影特征”。
AI 图像在生成过程中,由于使用了上采样和卷积等操作,图像像素之间的联系变得更加紧密,从而留下了可供检测的痕迹。然而,许多检测方法在对图像进行预处理时,常常采用下采样操作来统一图像尺寸,这一操作会“抹除”那些细微的痕迹,大大增加了检测的难度。
第二个问题是“过拟合的伪影特征”。
现有的检测方法在训练时,数据增强方式较为单一,比如仅仅进行水平翻转操作。这就使得模型过度适应了训练数据中的特定特征,出现过拟合现象。一旦遇到未曾见过的 AI 图像,模型就无法准确识别,泛化性能较差。
简单图像变换:有效去偏
为了解决这些问题,研究团队提出了 SAFE,它凭借三种简单的图像变换直击难题。
第一是痕迹保留(Artifact Preservation)。
SAFE在图像预处理阶段,舍弃了传统的下采样(Resize)操作,改为采用裁剪(Crop)操作。在训练过程中进行随机裁剪(RandomCrop),测试时则使用中心裁剪(CenterCrop)。这样一来,AI图像中的细节以及像素之间的微妙联系得以保留,方便检测器发现那些细微的“破绽”,显著提升了捕捉 AI 伪影的能力。
第二是不变性增强(Invariant Augmentation)。
SAFE引入了ColorJitter和RandomRotation两种数据增强方式。ColorJitter通过在色彩空间中对图像进行调整,能够有效减少因颜色模式差异而带来的偏差。RandomRotation则让模型在不同旋转角度下依然能够聚焦于像素之间的联系,避免受到与旋转相关的无关特征的干扰,增强了模型对图像旋转的适应能力。
第三是局部感知(Local Awareness)。
SAFE提出了基于 Patch 的随机掩码策略(RandomMask)。在训练时,按照一定概率对图像实施随机掩码,引导模型将注意力集中在局部区域,进而提升模型的局部感知能力。令人惊喜的是,即使图像的大部分区域被掩蔽,模型依然能够依据剩余的未掩蔽部分准确判断图像的真伪。
此外,SAFE利用简单的离散小波变换(DWT)来提取高频特征,并将其作为检测的伪影特征。由于AI图像与自然图像在高频分量上存在明显差异,DWT能够很好地保留图像的空间结构,有效提取这些差异特征。
实验对比:轻量且高效
研究团队开展了大量实验,以验证SAFE的实际效果。
在实验设置上,训练数据选用 ProGAN 生成的 AI 图像以及对应的真实图像,测试数据则广泛涵盖了多种来源的自然图像,以及由 26 种不同生成模型所生成的 AI 图像,包括常见的 GANs 和 DMs 等。并且选取了 10 种极具代表性的方法作为基线进行对比,通过精确的分类准确率(ACC)和平均精度(AP)来衡量检测效果。
1. 泛化性能对比
SAFE在33个测试子集上达到了平均96.7%的准确率,超过SOTA方法4.5个点。
值得注意的是,SAFE只有1.44M的参数量,在实际推理时的FLOPs仅为2.30B,相比于SOTA 方法有 50 多倍的效率提升,便于工业部署。

针对最新的基于 DiTs 的生成器,研究团队构建了DiTFake测试集,包含最新的生成模型Flux、SD3以及PixArt。SAFE在DiTFake上表现堪称卓越,平均准确率达到99.4%,对新型生成器的泛化能力极强。

2. 即插即用的特性
值得一提的是,由于SAFE具有模型无关的特性,研究人员将其提出的图像变换作为一个即插即用的模块,应用到现有的检测方法之中。从GenImage测试集的对比结果来看,这一应用带来了令人惊喜的效果,检测性能得到了一致提升。

3. 消融实验
研究团队还进行了充分的消融实验,深入探究模型各个组成部分的具体作用。
在图像预处理环节,重点聚焦于裁剪(Crop)操作的效能探究。实验数据有力地证实,在训练进程中,裁剪操作相较于传统的下采样(Resize),具有不可替代的关键作用。
即使测试图片在传输过程中不可避免地经历了下采样操作,基于裁剪方法比基于下采样方法训练出的模型仍表现出更好的检测效果。

对于数据增强技术,分别对 ColorJitter、RandomRotation 和 RandomMask 进行了单独和组合的效果评估。这三种数据增强技术不仅各自都能发挥有效的作用,而且当它们共同作用时,效果更加显著,能够进一步提升检测性能。

在特征提取方面,研究团队对不同的图像处理算子进行了消融,包括用原图(Naive)、频域变换算子(FFT、DCT、DWT)、边缘提取算子(Sobel、Laplace)以及不同的频带(LL、LH、HL、HH)。

因为 AI 图像在高频部分的拟合能力相对较弱,通过高频信息的差异进行判别展现出了卓越的性能。在高频信息提取上,FFT和DCT仍表现出和DWT相当的性能,说明简单的频域变换已经能够很好地进行 AI 图像检测。
SAFE为AI图像检测领域开辟了新的方向。它促使我们重新思考复杂的人工设计特征的必要性,也启发后续研究可以从优化训练模式入手,减少训练偏差。
论文链接:https://arxiv.org/abs/2408.06741
代码链接:https://github.com/Ouxiang-Li/SAFE
#ToCa
无需训练的Token级 DiT加速方法
本篇分享 ICLR 2025 论文ToCa: Accelerating Diffusion Transformers with Token-wise Feature Caching,提出的 ToCa 模型通过 token 粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。
- 论文:https://arxiv.org/abs/2410.05317
- Github:https://github.com/Shenyi-Z/ToCa
- 联系方式:shenyizou@outlook.com
- 通讯作者:zhanglinfeng@sjtu.edu.cn
摘要 Abstract
Diffusion Transformer在图像和视频生成中展现了显著的效果,但代价是巨大的计算成本。
为了解决这一问题,特征缓存方法被引入,用于通过缓存前几个时间步的特征并在后续时间步中复用它们来加速扩散Transformer。然而,之前的缓存方法忽略了不同的token对特征缓存表现出不同的敏感性,而对某些token的特征缓存可能导致生成质量整体上高达10倍的破坏,相较于其他token。
在本文中,我们提出了基于token的特征缓存方法,允许我们自适应地选择最适合进行缓存的token,并进一步使我们能够为不同类型和深度的神经网络层应用不同的缓存比率。
通过在PixArt-α、OpenSora和DiT, 以及FLUX上的广泛实验,我们证明了在图像和视频生成中无需训练即可实现我们方法的有效性。例如,在OpenSora和PixArt-α上分别实现了2.36倍和1.93倍的接近无损的生成加速。
背景 Backgrounds
扩散模型(Diffusion Models)在图像生成、视频生成等多种生成任务中展现了出色的性能。近年来,以FLUX, Sora, 可灵等模型为代表的 Diffusion Transformers 通过扩展参数量和计算规模进一步推动了视觉生成领域的发展。
然而,Diffusion Transformers面临的一个重大挑战在于其高计算成本,这导致推理速度缓慢,从而阻碍了其在实时场景中的实际应用。为了解决这一问题,研究者们提出了一系列加速方法,主要集中在减少采样步数和加速去噪网络模型。
近期,基于特征缓存来实现去噪模型加速的方法由于其优秀的无损加速性能,以及无需训练的优良性能,受到工业界的广泛关注。
上海交通大学张林峰团队进一步注意到一个自然而有趣的现象:不同计算层,以及同计算层的不同 Token 对于缓存误差的适应性不同,同样的缓存误差在不同位置对模型影响最高可以达到数十,百倍的差异,因此有必要进一步将模型加速的粒度由特征级进一步到 token 级,并考虑了如何衡量视觉生成模型中 token 的重要性,以实现重要 token 的筛选保留。
核心贡献 TL,DR
- ToCa 首次在DiT加速中中引入 token 级的缓存复用策略,并首次从误差积累与传播的角度分析特征缓存方法。
- ToCa 提出 4 种从不同角度出发,适用于不同情形的 token selection策略:(a)基于Self-Attention Map来评估 token对其它token的影响; (b)基于Cross-Attention Map评估文生图/视频任务中 image token 对 text token的关注分布,以加强控制能力; (c) 基于该 token在先前去噪步中的被连续缓存复用的次数设计增益策略,鼓励token在时间步上被更均匀地计算,避免局部误差积累过大,破坏全局图像; (d)将各个token的重要性得分基于空间分布进行加权,鼓励被计算的token在空间上分布更均匀。
- ToCa 被应用于多种最新模型上开展实验,证明了其相比现有方法更加优秀,包含文生图模型PixArt-alpha,FLUX-dev和FLUX-schnell,文生视频模型 OpenSora,以及基于ImageNet类标签生成图像的DiT模型。
研究动机

如图1所示,不同token在相邻两步间进行特征缓存引入的误差值的差异高达几十上百倍;图2说明不同token上引入同样大小的误差,这最初幅度相同的误差在模型推理过程经过积累和传播,对模型的输出的影响差异也极大。
因此,有必要考虑token级别的特征缓存-复用策略,使得模型的计算更集中在关键被需要的token上。
方法
计算流程

ToCa的缓存-复用流程如图3(a)所示:
- Cache 初始化 首先推理一个完整的时间步,将各层的特征放入cache中以便使用。
- 重要性得分计算在使用ToCa的时间步上,对于每一层:先计算各个token的重要性得分,将最低的部分token 标记为cache状态(例如图示中ID为1和3的token),不传入网络层进行计算。
- 部分计算对于被传入的token(2,4,5),执行正常的计算,得到它们的输出。
- Cache更新从cache中调出存储的 token 1,3的输出,并将计算得到的新的token 2,4,5输出更到cache中。
通常这样的一个循环长度为2~4个时间步,即1步充分计算后续搭配1至3个ToCa step。此外,ToCa还基于不同层的重要性,设计了随着层深度上升而衰减的计算比例,详情请参考论文。
重要性得分计算

如图4所示,ToCa设计了基于4个不同方面考虑的重要性分数计算,在实际应用中它们以 加权求和给出总重要性得分,详情请参考论文。
实验结果
ToCa被应用于文本到图像生成模型 PixArt-alpha, FLUX, 类到图像生成模型 DiT, 以及文本到视频生成模型 OpenSora以验证其方法有效性,充分的实验结果证明,ToCa具有超越其他同类方法的加速效果。
图像生成模型: PixArt-alpha,FLUX, DiT

如上图所示,ToCa相比另两种加速方法和无加速的高质量原图对齐效果更佳,且具有更佳的图-文对齐能力(例如从左到右第四列的wooden dock)。

从FID-30k和 CLIP Score上衡量,ToCa也取得了远超其他方法的表现。

如上图所示,ToCa在FLUX 模型上的生成质量也极佳,可以看到和原图基本没有差异。但值得考虑的是在文字生成这类对细节要求极其高的任务上(例如左下角的地图)仍有差异,这将作为我们后续研究的出发点。

对于高级的模型,使用Image Reward通常能更好地对生成质量进行衡量,我们分别在50step的FLUX-dev和4step的FLUX-schnell上开展了实验,可以看到,ToCa在FLUX上1.5倍加速,相比未加速模型的数值指标基本不变,远远优于其他方法。

在基础模型DiT上的结果也证明了ToCa的优越性。
视频生成模型:OpenSora
我们制作了一个网页来展示OpenSora上的加速效果,期待您的到访。
- web page: https://toca2024.github.io/ToCa
此外,我们将视频生成结果部分抽帧以供快速浏览:


我们在VBench上测试了ToCa的加速效果,实验结果表明,ToCa远优于其他方法,取得了高达2.36倍的无损加速,在加速效果和生成质量上都取得最优表现。

如上图所示,ToCa在 VBench的大部分指标上都取得了和原模型几乎相同的得分。
总结
ToCa 作为首次被提出的从Token级来实现扩散模型加速的方法,相比以往加速方法具有更强的适配性,(尽管设计时作为专为DiT加速的方案,它的结构也可以被复用到U-Net结构的模型上),同时在多种任务上具有极佳的表现。
近年来,包括ToCa在内的系列基于特征缓存的扩散模型加速方法兼具无需训练的优越性和强劲的无损加速效果,取得了卓越的成效,是一种不同于蒸馏类方法的值得被进一步探索的加速方案。
#通过相机标定提高视觉应用的准确性
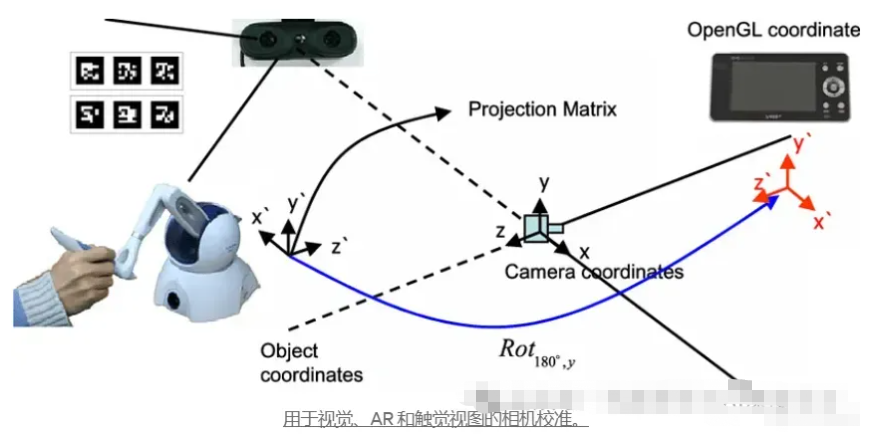
什么是相机标定
相机校准就像验光师检查眼睛一样。就像眼科医生测量眼睛如何处理视觉信息一样,相机校准可以帮助我们了解相机如何将 3D 世界转换为 2D 图像。这种理解对于从智能手机摄影到自动驾驶汽车等各种应用都至关重要。
从本质上讲,相机校准依赖于一个非常优雅的数学方程:x = PX

- x表示图像中的二维点
- P是相机矩阵(包含所有相机参数)
- X表示现实世界中的 3D 点
可以将相机矩阵视为P相机将 3D 场景转换为 2D 图像的个人“配方”。此矩阵包含两组关键成分:
1. 内部参数(相机的“个性”)
- 焦距:视野“放大”的程度
- 主点:图像中心的真正位置
- 倾斜:像素的形状和排列方式
- 长宽比:像素宽度和高度之间的关系
2. 外部参数(相机的“位置”)
- 旋转:相机指向哪个方向
- 翻译:相机在空间中的位置
为什么需要相机标定
想象一下,仅使用一张照片测量两座建筑物之间的距离。如果没有适当的校准,您可能会得到完全错误的测量结果!这就是相机校准如此重要的原因:
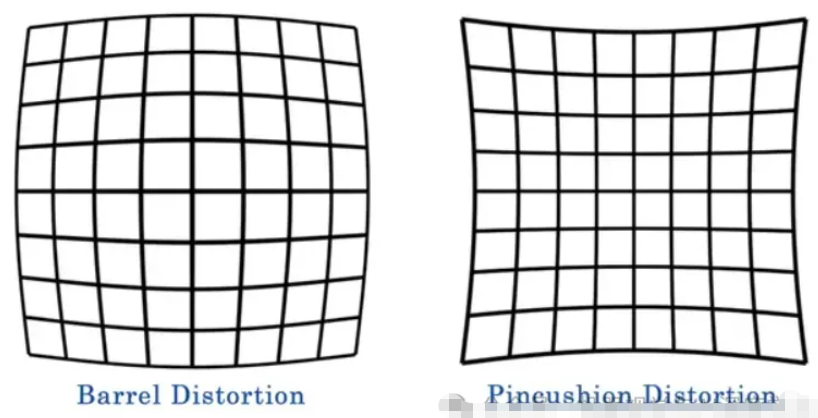
- 镜头失真校正:有没有注意到广角自拍照会让脸部看起来有点扭曲?这就是镜头失真。
- 精确的测量:对于制造业和建筑业等行业至关重要。
- 增强计算机视觉:帮助人工智能系统通过摄像头准确地解读世界。
- 改进的增强现实:使虚拟物体与现实世界正确对齐。
如何校准相机:分步指南
要校准相机,请按照以下步骤操作:
1. 准备校准目标:最常用的目标是棋盘图案。您可以将此图案打印在纸上,或使用已知尺寸的方格实体棋盘。

2. 拍摄图像:从不同角度和距离拍摄棋盘的多张照片。确保每张图像中都能看到整个图案。
3. 检测角点:使用软件工具检测每个图像中棋盘上方格的角点。
4. 计算参数:利用检测到的角和已知的正方形尺寸,使用张的方法或 OpenCV 函数等算法计算内在和外在参数。
5. 评估校准:通过计算重投影误差来检查校准的准确性。
一个简单的 Python 实现Demo
以下是使用 OpenCV 校准相机的实际示例:
import cv2
import numpy as np
import glob
# Termination criteria for corner sub-pixel accuracy
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# Prepare object points (3D points in real-world space)
objp = np.zeros((6*7, 3), np.float32)
objp[:, :2] = np.mgrid[0:7, 0:6].T.reshape(-1, 2)
# Arrays to store object points and image points
objpoints = [] # 3D point in real-world space
imgpoints = [] # 2D points in image plane
# Load images
images = glob.glob('path/to/calibration/images/*.jpg') # Update with your path
for img in images:
gray = cv2.imread(img)
gray = cv2.cvtColor(gray, cv2.COLOR_BGR2GRAY)
# Find the chessboard corners
ret, corners = cv2.findChessboardCorners(gray, (7, 6), None)
if ret:
objpoints.append(objp)
corners2 = cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
imgpoints.append(corners2)
# Calibrate the camera
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
print("Camera matrix:\n", mtx)
print("Distortion coefficients:\n", dist)准备您自己的校准图像:
- 打印棋盘图案或以数字方式创建一个棋盘图案。
- 拍摄图像时确保良好的光照条件。
- 从各个角度拍摄至少 10 至 15 张图像以获得准确的结果。
- 将这些图像保存在专用文件夹中,以便在编码期间轻松访问。
相机校准的实际应用
相机校准在各个领域都具有广泛的实际应用。以下是其发挥关键作用的一些关键领域:
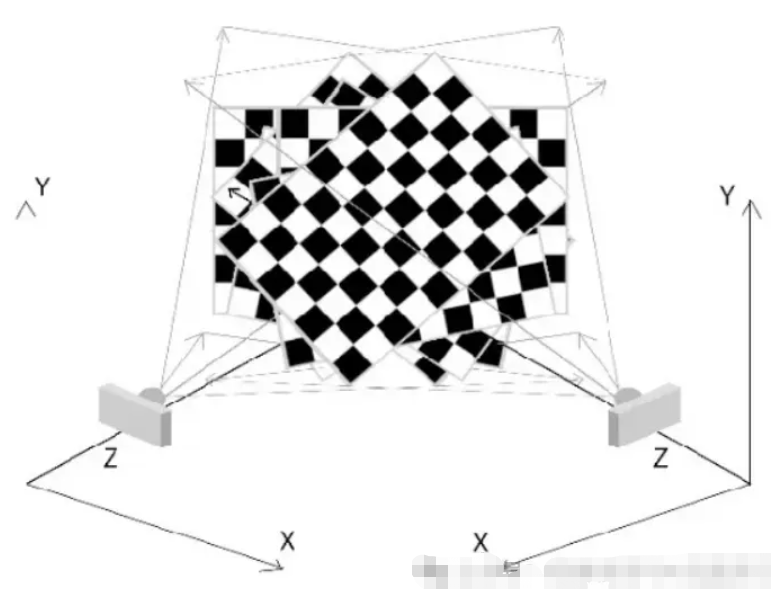
1. 三维重建
在虚拟现实 (VR) 和增强现实 (AR) 等应用中,准确的 3D 重建至关重要。相机校准允许系统通过了解不同图像在三维空间中彼此之间的关系,从多个 2D 图像创建精确的 3D 模型。这在需要逼真交互的游戏和模拟环境中尤为重要。
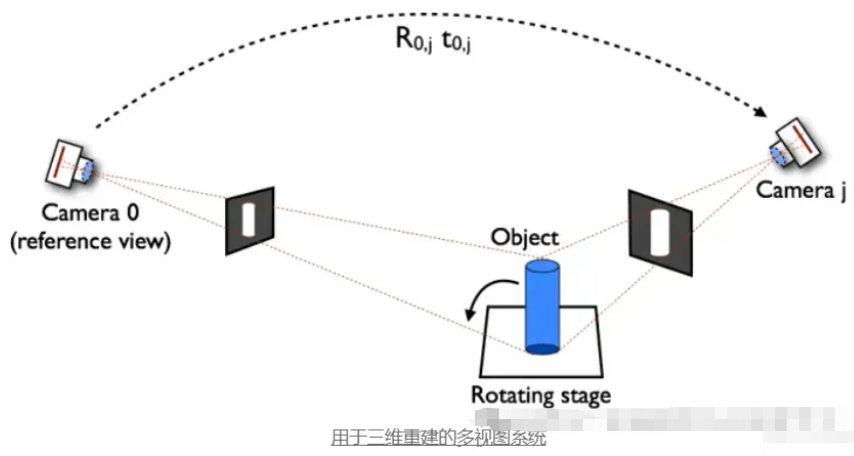
2. 机器人技术
机器人在很大程度上依赖视觉输入来导航和与环境互动。摄像头校准使机器人能够准确感知周围物体的距离和大小。例如,在自动驾驶汽车中,经过校准的摄像头有助于确定障碍物和其他车辆的位置,从而促进安全导航。
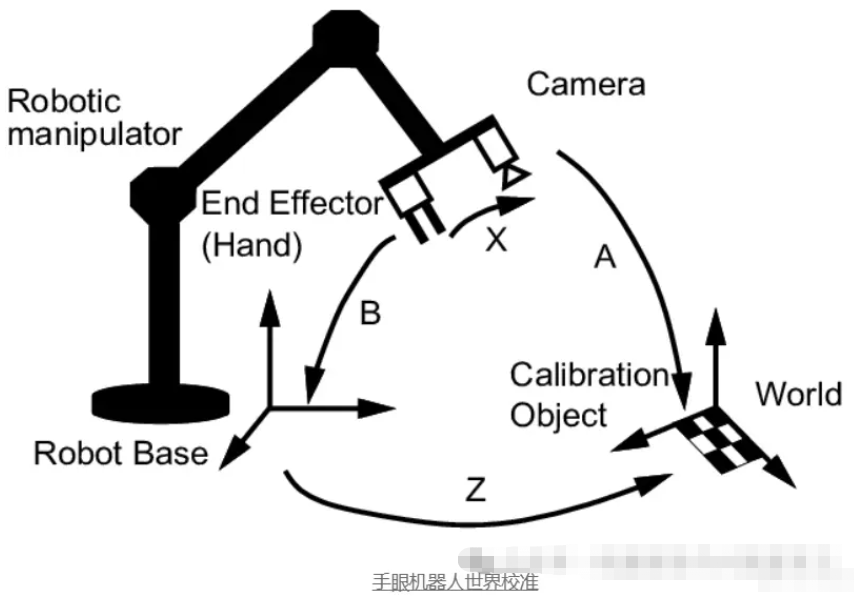
3. 增强现实
在增强现实应用中,将数字信息叠加到现实世界需要虚拟元素和现实世界物体之间的精确对齐。相机校准可确保虚拟内容相对于物理环境的位置和比例正确,从而增强用户体验。
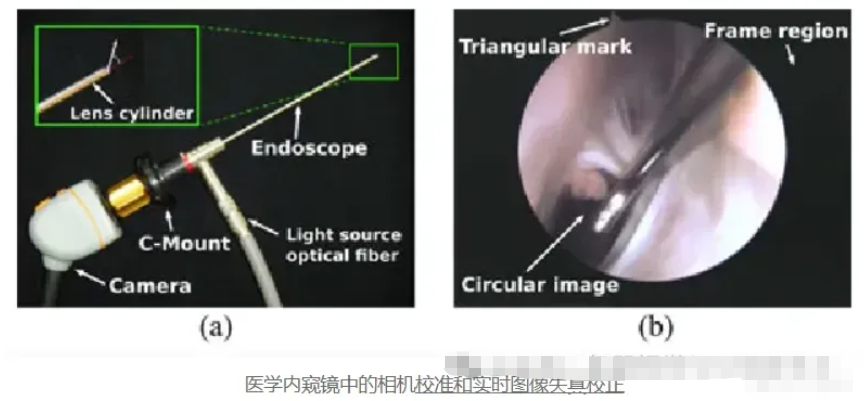
4. 医学成像
在内窥镜或放射学等医学成像技术中,相机校准对于准确的诊断和治疗计划至关重要。它确保图像反映真实的解剖尺寸,帮助医疗专业人员做出明智的决定。
5. 体育分析
摄像机校准用于体育技术,以分析运动员的动作和比赛动态。通过校准运动场或竞技场周围的摄像机,分析师可以捕捉运动员和设备的精确动作,从而制定更好的训练方法和策略。

相机校准乍一看可能很复杂,但这是一个基本过程,可以帮助我们从相机中获取最准确的信息。无论您是业余摄影师还是开发计算机视觉应用程序,了解相机校准对于获得精确的结果都至关重要。
#Locate Anything on Earth
半自动化构建LAE-1M数据集,推动遥感开放词汇目标检测新突破
本篇分享 AAAI2025 论文Locate Anything on Earth: Advancing Open-Vocabulary Object Detection for Remote Sensing Community,提出通过半自动化的方式,构建一个大规模的遥感目标检测数据集 LAE-1M,该数据集包含100万个标注实例。
- 会议:39th Annual AAAI Conference on Artificial Intelligence (CCF-A会议)
- 论文:https://arxiv.org/abs/2408.09110
- 项目:https://jaychempan.github.io/LAE-website/
- 代码:https://github.com/jaychempan/LAE-DINO
- 年份:2025
- 单位:清华大学,浙江工业大学,中国科学院大学,苏黎世联邦理工大学等
创新点
- 数据引擎构建:面对当前遥感领域目标检测标注类别稀缺,开发了LAE-Label Engine,用于收集、自动标注和统一多达10个遥感数据集,为提供遥感基础模型提供可扩展数据基础。
- 数据集构建:构建了LAE-1M数据集。LAE-1M是首个大规模遥感目标检测数据集,涵盖了广泛的类别,包含100万个标注实例。
- 模型设计:当前多模态大模型对定位能力不准确,提出了LAE-DINO模型,这是针对遥感领域的大规模开放词汇目标检测器。

LAE-Label 数据引擎
LAE-Label Engine旨在解决遥感领域缺乏多样化、大规模标注数据的问题。LAE-Label Engine 的主要任务是通过半自动化的方式,构建一个大规模的遥感目标检测数据集 LAE-1M,该数据集包含100万个标注实例。

LAE-FOD 数据集构建
LAE-FOD 数据集是通过对现有的标注遥感数据集进行处理和统一构建的。具体步骤如下:
- 图像切片:由于遥感图像通常分辨率较高,LAE-Label Engine 首先对这些高分辨率图像进行切片处理,将其分割为适合模型训练的小尺寸图像。
- 格式对齐:不同数据集的标注格式可能不同,LAE-Label Engine 将这些标注格式统一为 COCO 格式,便于后续处理。
- 采样:为了确保数据集的多样性和平衡性,LAE-Label Engine 对每个类别的实例进行随机采样,避免某些类别的实例过多或过少。
LAE-COD 数据集构建
LAE-COD 数据集是通过半自动化的方式构建的,主要利用了大模型(如SAM 和 LVLM)进行自动标注。具体步骤如下:
- SAM(Segment Anything Model):首先,LAE-Label Engine 使用 SAM 模型从遥感图像中提取感兴趣区域(RoI)。SAM 能够根据点或框提示精确地分割出物体的边缘,但无法识别具体的类别。
- LVLM(Large Vision-Language Model):接着,LAE-Label Engine 使用 LVLM(本实验主要基于开源的书生多模态大模型InternVL)对SAM 提取的 RoI 进行类别标注。LVLM 能够根据图像内容生成可能的物体类别,并提供类别的置信度。
- 规则过滤:最后,LAE-Label Engine 通过规则过滤去除无效或低质量的标注。例如,去除单调的图像、低置信度的类别标注等。
LAE-1M 数据集
LAE-1M 数据集涵盖了广泛的类别,包含100万个标注实例。以下是 LAE-1M 数据集的具体内容:
数据集的具体内容
- LAE-FOD 数据集:包含来自多个现有遥感数据集的标注实例,如 DOTA、DIOR、FAIR1M、NWPU VHR-10、RSOD、Xview、HRSC2016 和 Condensing-Tower 等。这些数据集经过图像切片、格式对齐和随机采样处理后,形成了 LAE-FOD 数据集。
- LAE-COD 数据集:包含通过 SAM 和 LVLM 自动标注的实例,主要来自 AID、NWPU-RESISC45、SLM 和 EMS 等数据集。这些数据集经过 SAM 提取 RoI、LVLM 进行类别标注和规则过滤后,形成了 LAE-COD 数据集。
数据集的特点
- 大规模:LAE-1M 数据集包含100万个标注实例,是迄今为止最大且类别覆盖最广的遥感目标检测数据集。
- 多样性:LAE-1M 数据集涵盖了广泛的类别,包括飞机、船舶、车辆、建筑物、道路、机场、港口等,能够为模型提供丰富的训练数据。
- 半自动化结合:LAE-1M 数据集通过自动化(SAM 和 LVLM)和半自动化(规则过滤)的标注方式构建,能够在保证标注质量的同时,大幅减少人工标注的工作量。
LAE-DINO开放词汇检测器
总体框架

LAE-DINO引入了两个新模块:
- 动态词汇构建(Dynamic Vocabulary Construction, DVC):动态地为每个训练批次选择正负词汇,解决了大规模词汇集带来的训练效率问题。
- 视觉引导的文本提示学习(Visual-Guided Text Prompt Learning, VisGT):通过将视觉特征映射到语义空间,增强文本特征,从而更好地利用图像和文本之间的关系进行目标检测。
动态词汇构建(DVC)
传统的开放词汇目标检测模型通常使用固定长度的文本编码器(如 BERT 或 CLIP),将所有类别词汇拼接成一个超长文本序列。然而,当词汇集规模较大时(如1600个类别),这种方法会导致计算效率低下,甚至超出文本编码器的最大长度限制。
- 动态词汇长度:DVC 设置一个动态词汇长度(如60),每个训练批次只选择部分正负词汇进行训练。
- 正负词汇选择:对于每个训练批次,DVC首先选择当前批次中的所有正类别词汇,然后从剩余的词汇集中随机选择负类别词汇,直到达到的设定的长度。
优势:DVC 显著减少了文本编码器的计算负担,同时保留了模型对大规模词汇集的适应能力。
视觉引导的文本提示学习(VisGT)
遥感图像中的场景通常非常复杂,单一的文本提示难以充分表达图像中的语义信息。传统的开放词汇目标检测模型主要依赖文本提示来引导视觉特征,但在复杂场景中,文本提示的稀疏性和局限性可能导致检测效果不佳。
- 场景特征提取:VisGT 首先通过平均所有正类别文本特征,生成“场景特征”(Scene Feature)。场景特征代表了图像中所有物体的整体语义信息。
- 视觉特征映射:VisGT 使用多尺度可变形自注意力(MDSA)模块,将视觉特征映射到语义空间,生成视觉引导的文本特征。
- 模态对齐:VisGT 将视觉引导的文本特征与原始文本特征结合,输入到 Transformer 编码器中,增强图像和文本之间的模态对齐。
VisGT 使用对比损失(Contrastive Loss)来监督视觉特征到语义空间的映射过程。具体来说,对比损失用于最小化预测的场景特征与真实场景特征之间的差异。
实验设置
在多个遥感基准数据集(如DIOR、DOTAv2.0)和新构建的含有80类的LAE-80C基准上进行了广泛的实验,验证了LAE-1M数据集和LAE-DINO模型的有效性。
- 开放集检测:LAE-DINO 在开放集检测任务中显著优于现有的开放词汇目标检测方法(如 GLIP 和 GroundingDINO)。

- 封闭集检测:LAE-DINO 在封闭集检测任务中也表现出色,尤其是在少量数据微调的情况下,仍能取得优异的检测效果。

应用前景
该研究为地球科学应用(如环境监测、自然灾害评估、土地利用规划等)提供了强大的工具,推动了遥感领域开放词汇目标检测的发展。
#Chameleon数据集和AIDE检测方法
小红书等给AI图像检测上难度!数据集均通过人类感知“图灵测试”
小红书团队联合中科大和上海交通大学在ICLR 2025上提出了Chameleon数据集和AIDE检测方法。Chameleon是一个高逼真度的AI生成图像检测基准,图像通过人类感知“图灵测试”,涵盖多类别和高分辨率图像。AIDE模型通过融合低级像素统计和高级语义特征,显著提升了AI生成图像的检测准确率,分别在现有基准上提高了3.5%和4.6%。
AI生成内容已深度渗透至生活的方方面面,从艺术创作到设计领域,再到信息传播与版权保护,其影响力无处不在。
然而,随着生成模型技术的飞速发展,如何精准甄别AI生成图像成为业界与学界共同聚焦的难题。
来自小红书生态算法团队、中科大、上海交通大学联合提出行业稀缺的全人工标注Chameleon基准和行业领先的AIDE检测方法。
团队经过分析,几乎所有模型都将Chameleon基准中AI生成的图像归类为真实图像
于是他们提出了AIDE(具有混合特征的AI -generated Image DE tector ),它利用多个专家同时提取视觉伪影和噪声模式。最终分别比现有的最先进方法提高了 3.5% 和 4.6% 的准确率。
重新定义AI生成图像检测任务
Train-Test Setting-I:在现有研究中,AI 生成图像检测任务通常被设定为在一个特定的生成模型(如 GAN 或扩散模型)上训练模型,然后在其他生成模型上进行测试。
![]()
然而,通常来说,这种设定存在两个主要问题:
评估Benchmark过于简单:现有Benchmark中的图像通常会有一些artifacts。
训练数据的局限性:将模型限制在特定类型的生成模型上 (GAN or 扩散模型) 训练,限制了模型从更先进的生成模型中学习多样化特征的能力。
为了解决这些问题,团队提出了一个新的问题设定:
Train-Test Setting-II:鉴别器可以将多种生成模型的图像混合一起训练,然后在更具挑战性的、真实世界场景中的图像上进行测试。这种设定更符合实际应用中的需求,能够更好地评估模型的泛化能力和鲁棒性。
![]()
为了更真实地评估 AI 生成图像检测方法的性能,团队精心构建了Chameleon 数据集。
Chameleon数据集具有以下显著特点:
高度逼真性:所有AI生成图像均通过了人类感知“图灵测试”,即人类标注者无法将其与真实图像区分开来。这些图像在视觉上与真实图像高度相似,能够有效挑战现有检测模型的极限。
多样化类别:数据集涵盖了人类、动物、物体和场景等多类图像,全面模拟现实世界中的各类场景。这种多样性确保了模型在不同类别上的泛化能力。
高分辨率:图像分辨率普遍超过720P,最高可达4K。高分辨率图像不仅提供了更丰富的细节信息,也增加了检测模型对细微差异的捕捉能力。
数据集构建
为构建一个能够真实反映 AI 生成图像检测挑战的高质量数据集,团队在数据收集、清洗和标注环节均采取了创新且严谨的方法,确保数据集的高质量和高逼真度。

数据收集:多渠道、高逼真度图像获取
与之前的基准数据集不同,团队从多个流行的 AI 绘画社区(如 ArtStation、Civitai 和 Liblib)收集了超过 150K 的 AI 生成图像,这些图像均由广泛的用户创作,使用了多种先进的生成模型(如 Midjourney、DALL·E 3 和 Stable Diffusion 等)。这些图像不仅在视觉上逼真,而且涵盖了丰富多样的主题和风格,包括人物、动物、物体和场景等。此外,还从 Unsplash 等平台收集了超过 20K 的真实图像,这些图像均由专业摄影师拍摄,具有高分辨率和高质量。所有图像均获得了合法授权,确保了数据的合法性和可用性。
相比之下,之前的基准数据集通常使用生成效果较差的模型生成图像,缺乏多样性和真实感,如下图所示。
数据清洗:多维度、精细化过滤
为确保数据集的高质量,团队对收集的图像进行了多维度、精细化的清洗过程:
分辨率过滤:团队过滤掉了分辨率低于 448×448 的图像,确保所有图像具有足够的细节和清晰度,以反映 AI 生成图像的真实特性。
内容过滤:利用先进的安全检查模型(如 Stable Diffusion 的安全检查模型),团队过滤掉了包含暴力、色情和其他不适宜内容的图像,确保数据集的合规性和适用性。
去重处理:通过比较图像的哈希值,团队去除了重复的图像,确保数据集的多样性和独立性。
文本-图像一致性过滤:利用 CLIP 模型,团队计算了图像与对应文本描述的相似度,过滤掉了与文本描述不匹配的图像,确保图像与文本的一致性和相关性。
之前的基准数据集往往缺乏严格的过滤步骤,导致数据集中包含大量低质量、不适宜或重复的图像,影响了数据集的整体质量。
数据标注:专业标注平台与多轮评估
为确保数据集的准确性和可靠性,团队建立了专门的标注平台,并招募了 20 名具有丰富经验的人类标注者对图像进行分类和真实性评估:
分类标注:标注者将图像分为人类、动物、物体和场景四类,确保数据集覆盖了多种现实世界中的场景和对象。
真实性评估:标注者根据“是否可以用相机拍摄”这一标准对图像的真实性进行评估。每个图像独立评估两次,只有当两名标注者均误判为真实时,图像才被标记为“高逼真”。
多轮评估:为确保标注的准确性,团队对标注结果进行了多轮审核和校对,确保每个图像的分类和真实性评估结果准确无误。
与之前的基准数据集不同,该数据集经过了严格的人工标注,确保了数据集的高质量和高逼真度。之前的基准数据集往往缺乏严格的人工标注,导致数据集中的图像质量和标注准确性参差不齐。
通过上述多维度、精细化的数据收集、清洗和标注过程,构建了一个高质量、高逼真度的 AI 生成图像检测基准数据集,为后续的研究和模型评估提供了坚实的基础。该数据集不仅在规模上更大,而且在图像质量和标注精度上也有了显著提升,能够更好地反映 AI 生成图像检测的实际挑战。
数据集对比Chameleon数据集可以作为现有评测数据集的扩展,Chameleon数据集在规模、多样性和图像质量等方面均展现出显著优势:
规模:Chameleon数据集包含约26,000张测试图像,是目前最大的AI生成图像检测数据集之一。
多样性:数据集涵盖了多种生成模型和图像类别,远超其他数据集的单一类别。
图像质量:图像分辨率从720P到4K不等,提供了更高质量的图像数据,增加了检测模型的挑战性。
AIDE模型:多专家融合的检测框架
在AI生成图像检测领域,现有的检测方法往往只能从单一角度进行分析,难以全面捕捉AI生成图像与真实图像之间的细微差异。
为了解决这一问题,研究者们提出了简单且有效的AIDE(AI-generated Image DEtector with Hybrid Features)模型,该模型通过融合多种专家模块,从低级像素统计和高级语义两个层面全面捕捉图像特征,实现了对AI生成图像的精准检测。
AIDE模型主要由两个核心模块组成:Patchwise Feature Extraction(PFE)模块和Semantic Feature Embedding(SFE)模块。这两个模块通过多专家融合的方式,共同为最终的分类决策提供丰富的特征信息。
Patchwise Feature Extraction(PFE)模块
PFE模块旨在捕捉图像中的低级像素统计特征,特别是AI生成图像中常见的噪声模式和纹理异常。具体而言,该模块通过以下步骤实现:
Patch Selection via DCT Scoring:首先,将输入图像划分为多个固定大小的图像块(如32×32像素)。然后,对每个图像块应用离散余弦变换(DCT),将其转换到频域。通过设计不同的带通滤波器,计算每个图像块的频率复杂度得分,从而识别出最高频率和最低频率的图像块。
Patchwise Feature Encoder:将筛选出的高频和低频图像块调整为统一大小(如256×256像素),并输入到SRM(Spatial Rich Model)滤波器中提取噪声模式特征。这些特征随后通过两个ResNet-50网络进行进一步处理,得到最终的特征图。
Semantic Feature Embedding(SFE)模块SFE模块旨在捕捉图像中的高级语义特征,特别是物体共现和上下文关系等。具体而言,该模块通过以下步骤实现:
Semantic Feature Embedding:
利用预训练的OpenCLIP模型对输入图像进行全局语义编码,得到图像的视觉嵌入特征。通过添加线性投影层和平均空间池化操作,进一步提取图像的全局上下文信息。
Discriminator模块
将PFE和SFE模块提取的特征在通道维度上进行融合,通过多层感知机(MLP)进行最终的分类预测。具体而言,首先对高频和低频特征图进行平均池化,得到低级特征表示;然后将其与高级语义特征进行通道级拼接,形成最终的特征向量;最后通过MLP网络输出分类结果。
实验结果
数据集: 实验在AIGCDetectBenchmark、GenImage和Chameleon三个数据集上进行。AIGCDetectBenchmark和GenImage是现有的基准测试数据集,而Chameleon是研究者们新构建的更具挑战性的数据集。
模型对比:研究者选择了9种现成的AI生成图像检测器进行对比,包括CNNSpot、FreDect、Fusing、LNP、LGrad、UnivFD、DIRE、PatchCraft和NPR。
评价指标:实验采用分类准确率(Accuracy)和平均精度(Average Precision, AP)作为评价指标。
团队评测了AIDE在AIGCDetectBenchmark和GenImage上的结果,如下表所示:
AIDE模型在这两个数据集上的优异表现表明,融合低级像素统计和高级语义特征的方法能够有效捕捉AI生成图像与真实图像之间的差异,从而提高检测准确率。
随后在Chameleon benchmark上测评了9个现有的detectors,如下表所示。
同时团队可视化了,之前的SOTA方法PatchCraft在AIGCDetectBenchmark & GenImage 以及Chameleon上的表现
结果表明,之前在AIGCDetectBenchmark &GenImage上表现优异的模型,在Chameleon benchmark上均表现很差,这表明Chameleon数据集中的图像确实具有高度的逼真性,对现有检测模型提出了更大的挑战。
本论文通过对现有 AI 生成图像检测方法的重新审视,提出了一个新的问题设定,构建了更具挑战性的 Chameleon 数据集,并设计了一个融合多专家特征的检测器 AIDE。实验结果表明,AIDE 在现有的两个流行基准(AIGCDetectBenchmark 和 GenImage)上取得了显著的性能提升,分别比现有的最先进方法提高了 3.5% 和 4.6% 的准确率。然而,在 Chameleon 基准上,尽管 AIDE 取得了最好的性能,但与现有基准相比,仍存在较大的差距。
这表明,检测 AI 生成图像的任务仍然具有很大的挑战性,需要未来进一步的研究和改进。希望这一工作能够为这一领域的研究提供新的思路和方向,推动 AI 生成图像检测技术的发展。
尽管AIDE模型在AI生成图像检测领域取得了显著进展,但研究者们仍计划在未来的工作中进一步优化模型架构,探索更高效的特征提取和融合方法。
此外,研究者们还计划扩大Chameleon数据集的规模,涵盖更多类别、更多场景、更多生成模型的图像,以推动AI生成图像检测技术的进一步发展。
论文:https://arxiv.org/pdf/2406.19435
主页:https://shilinyan99.github.io/AIDE/
代码:https://github.com/shilinyan99/AIDE
#AIDE
小红书等给AI图像检测上难度!数据集均通过人类感知“图灵测试”
AI生成内容已深度渗透至生活的方方面面,从艺术创作到设计领域,再到信息传播与版权保护,其影响力无处不在。然而,随着生成模型技术的飞速发展,如何精准甄别AI生成图像成为业界与学界共同聚焦的难题。
来自小红书生态算法团队、中科大、上海交通大学联合提出行业稀缺的全人工标注Chameleon基准和行业领先的AIDE检测方法。
- 论文:https://arxiv.org/pdf/2406.19435
- 主页:https://shilinyan99.github.io/AIDE/
- 代码:https://github.com/shilinyan99/AIDE
团队经过分析,几乎所有模型都将Chameleon基准中AI生成的图像归类为真实图像。
于是他们提出了AIDE(具有混合特征的AI -generated Image DE tector ),它利用多个专家同时提取视觉伪影和噪声模式。最终分别比现有的最先进方法提高了 3.5% 和 4.6% 的准确率。
重新定义AI生成图像检测任务
Train-Test Setting-I:在现有研究中,AI 生成图像检测任务通常被设定为在一个特定的生成模型(如 GAN 或扩散模型)上训练模型,然后在其他生成模型上进行测试。
![]()
然而,通常来说,这种设定存在两个主要问题:
- 评估Benchmark过于简单:现有Benchmark中的图像通常会有一些artifacts。
- 训练数据的局限性:将模型限制在特定类型的生成模型上 (GAN or 扩散模型) 训练,限制了模型从更先进的生成模型中学习多样化特征的能力。
为了解决这些问题,团队提出了一个新的问题设定:
Train-Test Setting-II:鉴别器可以将多种生成模型的图像混合一起训练,然后在更具挑战性的、真实世界场景中的图像上进行测试。这种设定更符合实际应用中的需求,能够更好地评估模型的泛化能力和鲁棒性。
![]()
为了更真实地评估 AI 生成图像检测方法的性能,团队精心构建了Chameleon 数据集。

Chameleon数据集具有以下显著特点:
- 高度逼真性:所有AI生成图像均通过了人类感知“图灵测试”,即人类标注者无法将其与真实图像区分开来。这些图像在视觉上与真实图像高度相似,能够有效挑战现有检测模型的极限。
- 多样化类别:数据集涵盖了人类、动物、物体和场景等多类图像,全面模拟现实世界中的各类场景。这种多样性确保了模型在不同类别上的泛化能力。
- 高分辨率:图像分辨率普遍超过720P,最高可达4K。高分辨率图像不仅提供了更丰富的细节信息,也增加了检测模型对细微差异的捕捉能力。
数据集构建
为构建一个能够真实反映 AI 生成图像检测挑战的高质量数据集,团队在数据收集、清洗和标注环节均采取了创新且严谨的方法,确保数据集的高质量和高逼真度。
数据收集:多渠道、高逼真度图像获取
与之前的基准数据集不同,团队从多个流行的 AI 绘画社区(如 ArtStation、Civitai 和 Liblib)收集了超过 150K 的 AI 生成图像,这些图像均由广泛的用户创作,使用了多种先进的生成模型(如 Midjourney、DALL·E 3 和 Stable Diffusion 等)。这些图像不仅在视觉上逼真,而且涵盖了丰富多样的主题和风格,包括人物、动物、物体和场景等。此外,还从 Unsplash 等平台收集了超过 20K 的真实图像,这些图像均由专业摄影师拍摄,具有高分辨率和高质量。所有图像均获得了合法授权,确保了数据的合法性和可用性。
相比之下,之前的基准数据集通常使用生成效果较差的模型生成图像,缺乏多样性和真实感,如下图所示。

数据清洗:多维度、精细化过滤
为确保数据集的高质量,团队对收集的图像进行了多维度、精细化的清洗过程:
- 分辨率过滤:团队过滤掉了分辨率低于 448×448 的图像,确保所有图像具有足够的细节和清晰度,以反映 AI 生成图像的真实特性。
- 内容过滤:利用先进的安全检查模型(如 Stable Diffusion 的安全检查模型),团队过滤掉了包含暴力、色情和其他不适宜内容的图像,确保数据集的合规性和适用性。
- 去重处理:通过比较图像的哈希值,团队去除了重复的图像,确保数据集的多样性和独立性。
- 文本-图像一致性过滤:利用 CLIP 模型,团队计算了图像与对应文本描述的相似度,过滤掉了与文本描述不匹配的图像,确保图像与文本的一致性和相关性。之前的基准数据集往往缺乏严格的过滤步骤,导致数据集中包含大量低质量、不适宜或重复的图像,影响了数据集的整体质量。
数据标注:专业标注平台与多轮评估
为确保数据集的准确性和可靠性,团队建立了专门的标注平台,并招募了 20 名具有丰富经验的人类标注者对图像进行分类和真实性评估:
分类标注:标注者将图像分为人类、动物、物体和场景四类,确保数据集覆盖了多种现实世界中的场景和对象。
真实性评估:标注者根据“是否可以用相机拍摄”这一标准对图像的真实性进行评估。每个图像独立评估两次,只有当两名标注者均误判为真实时,图像才被标记为“高逼真”。
多轮评估:为确保标注的准确性,团队对标注结果进行了多轮审核和校对,确保每个图像的分类和真实性评估结果准确无误。
与之前的基准数据集不同,该数据集经过了严格的人工标注,确保了数据集的高质量和高逼真度。之前的基准数据集往往缺乏严格的人工标注,导致数据集中的图像质量和标注准确性参差不齐。
通过上述多维度、精细化的数据收集、清洗和标注过程,构建了一个高质量、高逼真度的 AI 生成图像检测基准数据集,为后续的研究和模型评估提供了坚实的基础。该数据集不仅在规模上更大,而且在图像质量和标注精度上也有了显著提升,能够更好地反映 AI 生成图像检测的实际挑战。
数据集对比
Chameleon数据集可以作为现有评测数据集的扩展,Chameleon数据集在规模、多样性和图像质量等方面均展现出显著优势:
- 规模:Chameleon数据集包含约26,000张测试图像,是目前最大的AI生成图像检测数据集之一。
- 多样性:数据集涵盖了多种生成模型和图像类别,远超其他数据集的单一类别。
- 图像质量:图像分辨率从720P到4K不等,提供了更高质量的图像数据,增加了检测模型的挑战性。
AIDE模型:多专家融合的检测框架
在AI生成图像检测领域,现有的检测方法往往只能从单一角度进行分析,难以全面捕捉AI生成图像与真实图像之间的细微差异。
为了解决这一问题,研究者们提出了简单且有效的AIDE(AI-generated Image DEtector with Hybrid Features)模型,该模型通过融合多种专家模块,从低级像素统计和高级语义两个层面全面捕捉图像特征,实现了对AI生成图像的精准检测。
AIDE模型主要由两个核心模块组成:Patchwise Feature Extraction(PFE)模块和Semantic Feature Embedding(SFE)模块。这两个模块通过多专家融合的方式,共同为最终的分类决策提供丰富的特征信息。
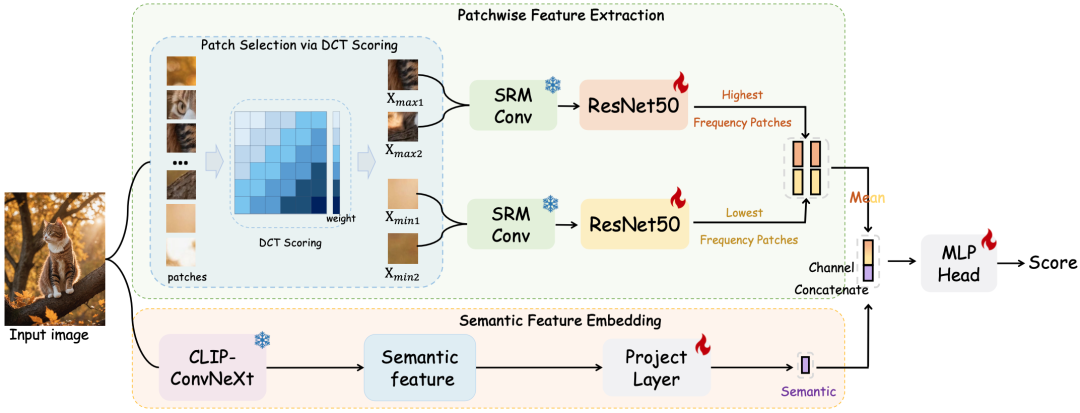
Patchwise Feature Extraction(PFE)模块
PFE模块旨在捕捉图像中的低级像素统计特征,特别是AI生成图像中常见的噪声模式和纹理异常。具体而言,该模块通过以下步骤实现:
- Patch Selection via DCT Scoring:首先,将输入图像划分为多个固定大小的图像块(如32×32像素)。然后,对每个图像块应用离散余弦变换(DCT),将其转换到频域。通过设计不同的带通滤波器,计算每个图像块的频率复杂度得分,从而识别出最高频率和最低频率的图像块。
- Patchwise Feature Encoder:将筛选出的高频和低频图像块调整为统一大小(如256×256像素),并输入到SRM(Spatial Rich Model)滤波器中提取噪声模式特征。这些特征随后通过两个ResNet-50网络进行进一步处理,得到最终的特征图。
Semantic Feature Embedding(SFE)模块
SFE模块旨在捕捉图像中的高级语义特征,特别是物体共现和上下文关系等。具体而言,该模块通过以下步骤实现:
- Semantic Feature Embedding:利用预训练的OpenCLIP模型对输入图像进行全局语义编码,得到图像的视觉嵌入特征。通过添加线性投影层和平均空间池化操作,进一步提取图像的全局上下文信息。
Discriminator模块
将PFE和SFE模块提取的特征在通道维度上进行融合,通过多层感知机(MLP)进行最终的分类预测。具体而言,首先对高频和低频特征图进行平均池化,得到低级特征表示;然后将其与高级语义特征进行通道级拼接,形成最终的特征向量;最后通过MLP网络输出分类结果。
实验结果
数据集:实验在AIGCDetectBenchmark、GenImage和Chameleon三个数据集上进行。AIGCDetectBenchmark和GenImage是现有的基准测试数据集,而Chameleon是研究者们新构建的更具挑战性的数据集。
模型对比:研究者选择了9种现成的AI生成图像检测器进行对比,包括CNNSpot、FreDect、Fusing、LNP、LGrad、UnivFD、DIRE、PatchCraft和NPR。
评价指标:实验采用分类准确率(Accuracy)和平均精度(Average Precision, AP)作为评价指标。
团队评测了AIDE在AIGCDetectBenchmark和GenImage上的结果,如下表所示:


AIDE模型在这两个数据集上的优异表现表明,融合低级像素统计和高级语义特征的方法能够有效捕捉AI生成图像与真实图像之间的差异,从而提高检测准确率。
随后在Chameleon benchmark上测评了9个现有的detectors,如下表所示。

同时团队可视化了,之前的SOTA方法PatchCraft在AIGCDetectBenchmark & GenImage 以及Chameleon上的表现

结果表明,之前在AIGCDetectBenchmark &GenImage上表现优异的模型,在Chameleon benchmark上均表现很差,这表明Chameleon数据集中的图像确实具有高度的逼真性,对现有检测模型提出了更大的挑战。
本论文通过对现有 AI 生成图像检测方法的重新审视,提出了一个新的问题设定,构建了更具挑战性的 Chameleon 数据集,并设计了一个融合多专家特征的检测器 AIDE。实验结果表明,AIDE 在现有的两个流行基准(AIGCDetectBenchmark 和 GenImage)上取得了显著的性能提升,分别比现有的最先进方法提高了 3.5% 和 4.6% 的准确率。然而,在 Chameleon 基准上,尽管 AIDE 取得了最好的性能,但与现有基准相比,仍存在较大的差距。
这表明,检测 AI 生成图像的任务仍然具有很大的挑战性,需要未来进一步的研究和改进。希望这一工作能够为这一领域的研究提供新的思路和方向,推动 AI 生成图像检测技术的发展。
尽管AIDE模型在AI生成图像检测领域取得了显著进展,但研究者们仍计划在未来的工作中进一步优化模型架构,探索更高效的特征提取和融合方法。
此外,研究者们还计划扩大Chameleon数据集的规模,涵盖更多类别、更多场景、更多生成模型的图像,以推动AI生成图像检测技术的进一步发展。
#MobileMamba
轻量级多感受野视觉Mamba主干
该框架通过三阶段网络设计、高效多感受野特征交互模块(MRFFI)以及优化的训练和测试策略,在保持低计算复杂度的同时,显著提升了模型的性能和推理速度,尤其在高分辨率输入下表现出色,超越了现有基于CNN、Transformer和Mamba的轻量化模型。
(来自浙大,腾讯优图,华中科技大学)
论文链接:https://arxiv.org/pdf/2411.15941
项目代码:https://github.com/lewandofskee/MobileMamba(所有代码/模型权重均已开源)

图1 顶部:不同结构下有效感受野ERF的可视化图像;底部:最近基于CNN/Transformer/Mamba方法的效果 vs. FLOPs对比。
总结
过去轻量化模型研究主要集中在基于CNN和Transformer的设计。但是CNN的局部有效感受野在高分辨率输入时难以获得长距离依赖。而Transformer尽管有着全局建模能力但是其平方级计算复杂度限制了其在高分辨率下的轻量化应用。最近状态空间模型如Mamba由于其线性计算复杂度和出色的效果被广泛用在视觉领域。然而基于Mamba的轻量化模型虽然FLOPs低但是其实际的吞吐量极低。因此,作者提出了MobileMamba的框架良好的平衡了效率与效果,推理速度远超现有基于Mamba的模型。具体来说,首先作者在粗粒度上设计了三阶段网络显著提升推理速度。随后在细粒度上提出了高效多感受野特征交互 (MRFFI)模块包含长距离小波变换增强Mamba (WTE-Mamba)、高效多核深度可分离卷积 (MK-DeConv)和去冗余恒等映射三个部分。有利于在长距离建模的特征上融合多尺度多感受野信息并加强高频细节特征提取。最后使用两个训练和一个推理策略进一步提升模型的性能与效率。大量实验验证了MobileMamba超过现有方法最高可达83.6在Top-1准确率上。并且速度是LocalVim的21倍和EfficientVMamba的3.3倍。大量的下游任务实验也验证了方法在高分辨率输入情况下取得了效果与效率的最佳平衡。

图2:现有基于Mamba的轻量化模型效果 vs. 吞吐量。
具体内容
随着移动设备的普及,资源受限环境中对高效、快速且准确的视觉处理需求日益增长。开发轻量化模型,有助于显著降低计算和存储成本,还能提升推理速度,从而拓展技术的应用范围。现有被广泛研究的轻量化模型主要被分为基于CNN和Transformer的结构。基于CNN的MobileNet设计了深度可分离卷积大幅度减少了计算复杂度。GhostNet提出将原本将原本全通道1x1卷积替换为半数通道进行廉价计算,另半数通道直接恒等映射。这些方法给后续基于CNN的工作奠定了良好的基础。但是基于CNN方法的主要缺陷在于其局部感受野,如图1(i)所示,其ERF仅在中间区域而缺少远距离的相关性。并且在下游任务高分辨率输入下,基于CNN的方法仅能通过堆叠计算量来换取性能的少量提升。
ViT有着全局感受野和长距离建模能力,如图1(ii)所示。但是由于其平方级别的计算复杂度,计算开销比CNN更大。一些工作尝试从减少分辨率或者减少通道数上来改减少所带来的计算复杂度的增长取得了出色的效果。但是基于纯ViT的结构缺少了归纳偏置,因此越来越多的研究者将CNN与Transformer结合得到混合结构得到更好的效果并获得局部和全局的感受野如图1(iii)所示。但是尤其在下游任务高分辨率输入下,基于ViT的方法仍然受到平方级别计算复杂度的问题。
最近,基于状态空间模型由于其出色的捕捉长距离依赖关系并且线性的计算复杂度引起了广泛关注。大量的研究者将其应用于视觉领域在效果和效率上取得了出色的效果。基于Mamba的轻量化模型LocalMamba提出了将图像划分为窗口并在窗口内局部扫描的方式减少计算复杂度。EfficientVMamba设计了高效2D扫描方式降低了计算复杂度。但是他们都仅仅公布了FLOPs,而FLOPs低并不能代表推理速度快。经实验发现如图2所示,现有的基于Mamba结构的推理速度较慢并且效果较差。
因此,作者提出了MobileMamba,并分别从粗粒度、细粒度和训练测试策略三个方面来设计高效轻量化网络。首先,在3.1节作者讨论了四阶段和三阶段在准确率、速度、FLOPs上的权衡。在同等吞吐量下,三阶段网络会取得更高的准确率。同样的相同效果下三阶段网络有着更高的吞吐量。因此作者选择三阶段网络作为MobileMamba的粗粒度设计框架。在细粒度模块设计方面在3.2节,作者提出了高效高效多感受野特征交互 (MRFFI)模块。具体来说,将输入特征根据通道维度划分三个部分。第一部分将通过小波变换增强的Mamba模块提取全局特征的同时加强边缘细节等细粒度信息的提取能力。第二部分通过高效多核深度可分离卷积操作获取多尺度感受野的感知能力。最后部分通过去冗余恒等映射,减少高维空间下通道冗余的问题,并减少计算复杂度提高运算速度。最终经过MRFFI得到的特征融合了全局和多尺度局部的多感受野信息,并且加强了边缘细节的高频信息提取能力。最后,在3.3节作者通过两个训练阶段策略知识蒸馏和延长训练轮数增强模型的学习能力,提升模型效果;以及一个归一化层融合的测试阶段策略提升模型的推理速度。
如图1(iv)所示,MobileMamba有着全局感受野的同时,高效多核深度可分离卷积操作有助于提取相邻信息。图1底部与SoTA方法的对比可知,MobileMamba从200M到4G FLOPs的模型在使用训练策略后分别达到76.9,78.9,80.7,82.2,83.3,83.6的Top-1在ImageNet-1K上的效果均超过现有基于CNN、ViT和Mamba的方法。与同为Mamba的方法相比如图2所示,MobileMamba比LocalVim在Top-1上提升0.7↑的同时速度快21倍。比EfficientVMamba提升2.0↑的同时速度快3.3↑倍。显著优于现有基于Mamba的轻量化模型设计。同时,在下游任务目标检测、实力分割、语义分割上大量实验上也验证了方法的有效性。在Mask RCNN上比EMO提升1.3↑在mAP并且吞吐量提升56%↑。在RetinaNet上比EfficientVMamba提升+2.1↑在mAP并且吞吐量提升4.3↑倍。在SSDLite通过提高分辨率达到24.0/29.5的mAP。在DeepLabv3, Se-mantic FPN, and PSPNet上有着较少的FLOPs分别最高达到37.4/42.7/36.9的mIoU。在高分辨率输入的下游任务与基于CNN的MobileNetv2和ViT的MobileViTv2相比分别提升7.2↑和0.4↑,并且FLOPs仅有其8.5%和11.2%。
总的来说,作者贡献如下:
- 作者提出了一个轻量级的三阶段MobileMamba框架,该框架在性能和效率之间实现了良好的平衡。MobileMamba的有效性和效率已经在分类任务以及三个高分辨率输入的下游任务中得到了验证。
- 作者设计了一个高效的多感受野特征交互(MRFFI)模块,以通过更大的有效感受野增强多尺度感知能力,并改进细粒度高频边缘信息的提取。
- MobileMamba通过在不同FLOPs大小的模型上采用训练和测试策略,显著提升了性能和效率。

图2 MobileMamba结构概述。(a) 粗粒度结构设计: 三阶段MobileMamba总体框架。(b) 16 ×16 下采样PatchEmbed. (c) MobileMamba Block结构。(d) 细粒度结构设计: 所提出的高效多感受野特征交互模块 (MRFFI).
更多实验结果如下:



#视觉~~~
随着深度学习技术的迅速发展,计算机视觉技术领域迎来了新的机遇。传统的成像系统受限于硬件能力和物理法则,往往难以在高分辨率和高速成像之间找到平衡。然而,深度学习凭借其强大的数据处理能力和模式识别优势,正逐步突破这些瓶颈。在基于深度学习的计算机视觉技术中,神经网络能够有效建模和分析复杂数据,从而实现超分辨率成像、快速成像和高精度成像等多项挑战性任务。这一技术不仅提升了成像质量,而且显著缩短了数据处理时间,极大地扩展了其在各领域的应用范围。特别是在医学影像、材料科学和工业检测等领域,深度学习驱动的计算机视觉技术展现出巨大的潜力和优势。通过深度学习算法的优化,计算机视觉系统能够更高效地捕捉和解析图像,推动相关技术向更高水平发展。
深度学习在计算机视觉技术中的应用极为广泛,包括但不限于:
1、深度光学设计:结合深度学习技术设计光学系统的参数与配置,从而实现高性能的成像任务。
2、医学成像:深度学习广泛应用于医学图像的分析和重建,如MRI和CT扫描图像的处理。
3、超分辨率重建与去模糊:利用深度学习技术提升图像的空间分辨率。
4、图像去噪:对模糊图像进行恢复与去噪,从而改善成像质量。
5、语义分割:义分割是计算机视觉任务,通过将图像中的每个像素分类为预定义的类别,来实现图像的像素级别标注和区域划分。
6、深度估计:深度估计是计算机视觉任务,旨在从单张图像或图像对中推测场景中物体的距离信息,从而生成深度图或三维空间结构。
随着深度学习技术的迅速发展,计算光学成像领域迎来了新的机遇。传统光学成像系统受限于硬件能力和物理法则,难以在高分辨率和高速成像间取得平衡。而深度学习以其强大的数据处理和模式识别能力,正在突破这一瓶颈。基于深度学习的计算光学成像通过神经网络对复杂数据进行建模与分析,实现了超分辨率成像、快速成像和高精度成像等多种高难度任务。这种技术不仅提升了成像质量,还显著减少了数据处理时间,极大拓展了光学成像的应用范围。尤其在医学影像、材料科学和工业检测等领域,深度学习驱动的计算光学成像正展示出强大的潜力与优势。通过深度学习算法优化光学系统,研究人员能够更高效地捕获和解析图像,推动成像技术向更高水平发展。深度学习在计算光学成像的应用领域非常广泛,包括但不限于:
超分辨率成像:通过深度学习技术提高图像的空间分辨率。
图像重建和去模糊:处理模糊图像或降噪,改善成像质量。
光学逆问题求解:利用神经网络处理复杂的光学逆问题,如光学成像系统中的反演。利用深度学习模型对光学成像过程进行优化和控制,实现更高效的成像方法。
深度光学:利用深度学习设计光学系统的参数和配置,实现高性能成像。
医学成像:应用于MRI、CT扫描等医学图像的分析和重建。
遥感和地球观测:处理和分析遥感图像,提取地表特征和环境信息。
工业视觉:在自动化和质检领域中,利用深度学习技术进行视觉检测和分析。
这些应用展示了深度学习在改进成像质量、优化光学系统设计以及推动各种领域的创新应用中的潜力。
光学设计作为连接物理理论与工程应用的核心领域,长期以来受限于高维参数空间搜索与复杂物理场耦合的挑战。深度学习技术的引入为这一传统领域注入了新的活力:通过构建数据驱动的智能模型,能够高效解决从纳米光子器件到宏观光学系统的设计难题。在超表面光学领域,深度学习实现了宽带消色差透镜、多功能超构表面的逆向设计,突破了传统方法的性能极限;在成像系统优化中,基于神经网络的端到端设计框架显著提升了像差校正与分辨率增强的效率;而在复杂光场调控方面,深度学习为全息显示、量子光学等前沿方向提供了全新的设计工具。特别值得关注的是,物理约束深度学习(如PINN)的兴起,进一步将麦克斯韦方程等物理规律融入网络架构,为光学设计赋予了更高的可解释性与可靠性。随着算法创新与计算能力的持续突破,深度学习正推动光学设计从“经验驱动”向“智能驱动”跨越,为下一代光学技术与应用开辟了广阔前景。
ISP技术及其实践
1. 引言
1.1ISP简介
定义:图像信号处理器(Image Signal Processor,ISP)是专门用于图像数据处理的硬件或软件组件,主要处理从传感器获取的RAW图像信号,最终输出高质量的图像。
ISP的作用:提高图像质量,减小噪声,增强细节,校正色彩,执行图像锐化等。ISP广泛应用于消费电子、汽车视觉、医疗影像等领域。
1.2 ISP技术的应用领域
智能手机:拍照质量提升、视频处理与后期优化。
数字相机:高性能成像与快速处理。
汽车驾驶辅助:自动驾驶、车道偏离检测、行人识别。
安防监控:实时视频监控、动态范围扩展、低光照增强。
工业视觉:质量检测、图像识别、自动化检测。
2. ISP工作原理
2.1图像信号链
传感器输入(RAW图像):从图像传感器(如CMOS、CCD)获取未经处理的原始图像数据(RAW格式),此数据通常包含噪声与色彩失真,需要进一步处理。
核心ISP处理步骤:包括去噪、白平衡、自动曝光、自动对焦、色彩校正、锐化等多个环节。
输出(RGB图像):经过ISP处理后,图像信号转化为清晰、高质量的RGB图像,适合于显示或后续分析。
2.2 ISP关键技术步骤
去噪(Denoising):使用滤波器(如中值滤波、均值滤波、双边滤波)去除原始图像中的噪声,提高图像质量。
白平衡(White Balance):调整图像的色温,使白色物体呈现为白色,避免色彩失真。
自动曝光(Auto Exposure, AE):根据场景的亮度动态调整相机的曝光设置(如快门速度、增益等)以确保图像的曝光恰当。
自动对焦(Auto Focus, AF):根据图像内容调整镜头焦距,确保图像的清晰度。
色彩校正(Color Correction):将RAW图像的颜色信息进行转化和校正,调整色调和饱和度,使颜色尽可能真实。
图像增强(Image Enhancement):改善图像的清晰度、对比度和细节,通常用于低光照环境或运动模糊场景中。
3. 关键技术细节及实践(实操环节)
3.1 RAW图像处理及实践
RAW格式与存储:常见的RAW图像格式包括YUV、RGB等,存储方式包括压缩与未压缩。
传感器输出的数据格式:每个传感器的数据格式不同(如8-bit、10-bit或12-bit),这影响图像处理时的动态范围和色深。
RAW到RGB的转换:从RAW数据中提取颜色信息,经过去噪、白平衡、色彩校正等处理后,转换为RGB图像进行显示。
3.2去噪算法及实践
空间域去噪:常用的算法有均值滤波、中值滤波、双边滤波,这些方法对图像中的噪声有良好的去除效果,但可能会模糊图像细节。
频域去噪:使用傅里叶变换或小波变换对图像进行频域处理,去除高频噪声,提高图像质量。
基于深度学习的去噪:使用卷积神经网络(CNN)或生成对抗网络(GAN)来去除噪声,同时保持图像的细节和结构。
3.3自动白平衡(AWB)及实践
灰世界假设:通过假设图像中大部分像素的平均色彩应该是灰色,来推测正确的白平衡设置。
色温校正:根据场景的光照类型(如日光、白炽灯等)动态调整色温,使图像呈现自然颜色。
深度学习AWB:使用深度学习方法,通过大量样本数据训练模型,自动调整图像的色温和色调,适应不同的光照条件。
3.4自动曝光与动态范围优化及实践
自动曝光控制(AEC):根据图像亮度自动调整曝光时间和增益,以确保图像亮度适中。
高动态范围(HDR):通过多帧曝光合成,扩展图像的动态范围,保证高光和阴影部分都能清晰显示,适用于强光和阴影共存的场景。
3.5色彩校正与色彩空间转换及实践
色彩空间转换:将RAW图像从原始色彩空间(如YUV、RGB)转换为目标色彩空间(如sRGB、AdobeRGB等),以适配不同显示设备。
颜色矩阵与查找表(LUT):通过查找表进行颜色校正,将图像中的色彩信息调整为更自然和准确的颜色。
3.6图像锐化技术及实践
锐化算法:如Unsharp Mask(USM)、拉普拉斯滤波等,通过强调边缘信息,增强图像的清晰度。
去噪与锐化的平衡:在去噪时要考虑细节的保留,避免图像过度模糊,同时锐化过程中要避免噪点增强。
4. ISP技术的硬件架构
4.1 ISP硬件架构
图像信号处理单元(IPU):ISP的核心硬件模块,负责图像处理的所有功能,如去噪、白平衡、曝光控制等。
内存与缓存管理:ISP硬件通常包括多个缓存与存储区域,用于存储图像数据、中间结果以及处理后的最终输出。
输入/输出接口:ISP需要与图像传感器(输入接口)以及显示设备或存储设备(输出接口)进行数据传输。
4.2硬件加速与并行处理
多核处理架构:为了提高图像处理速度,ISP硬件通常使用多核并行处理架构,支持多任务同时进行。
GPU加速:高端ISP系统可以使用GPU来加速图像处理中的高计算任务,如深度学习模型推理和实时图像优化。
4.3 ISP芯片设计挑战
性能与功耗平衡、高速数据传输、硬件与软件的协同设计
5. ISP技术的实际应用概述
1.智能手机中的ISP
拍照性能优化:如何通过ISP提升低光、逆光等复杂场景下的拍照质量。
实时视频处理:视频流的去噪、自动曝光和实时对焦等技术在视频录制中的应用。
背景虚化与人脸识别:利用ISP进行景深控制与人脸检测,提升人像拍摄效果。
2.车载视觉系统中的ISP
自动驾驶中的图像处理:如何利用ISP处理来自多个摄像头的数据,实现物体检测、车道识别等自动驾驶功能。
前视与后视影像优化:前后摄像头图像处理,确保在各种环境条件下都能提供清晰影像。
3.安防监控系统中的ISP
低光增强与动态范围扩展:如何处理低光环境下的图像,确保夜间监控效果。
视频流分析与实时反馈:实时图像处理与分析,用于异常行为检测、人脸识别等应用。


数字图像处理技术及其实践(实操环节)
1. 图像预处理及实践
1.1图像去噪(Denoising)
1.2直方图均衡(Histogram Equalization)
2.图像增强及实践
2.1对比度增强(Contrast Enhancement)
方法:调整图像的对比度,增强图像的明暗差异。
直方图拉伸(Histogram Stretching):通过线性变换扩展图像灰度范围,增加图像的对比度。
2.2锐化(Sharpening)
拉普拉斯滤波(Laplacian Filtering):利用拉普拉斯算子检测图像中的边缘并增强边缘部分。
高通滤波(High-pass Filtering)
原理:高通滤波器通过去除低频成分,增强图像中的高频细节(如边缘和纹理)。
实现:通过傅里叶变换对图像频谱进行处理,保留高频信息,去除低频噪声。
3. 图像分割及实践
3.1阈值分割(Thresholding)
3.2区域生长(Region Growing)
3.3边缘检测(Edge Detection)
Canny 边缘检测:基于梯度信息检测图像的边缘,包含平滑、梯度计算、非极大值抑制和双阈值检测。
步骤:
1. 高斯滤波平滑图像,去噪。
2. 计算图像梯度,找到边缘方向和幅度。
3. 非极大值抑制,细化边缘。
4. 双阈值检测,确定边缘强度。
4.特征提取及实践
4.1 SIFT(尺度不变特征变换)
4.2 SURF(加速稳健特征)
4.3 HOG(方向梯度直方图)
5. 图像复原及实践
5.1盲去卷积(Blind Deconvolution)
5.2 Wiener滤波(Wiener Filtering)
5.3非局部均值去噪(Non-Local Means Denoising)
6. 图像压缩及实践
6.1 JPEG压缩
6.2小波压缩(Wavelet Compression)
原理:通过小波变换将图像分解为不同的频带,并通过阈值处理来去除不重要的系数。
实现:使用离散小波变换(DWT)对图像进行分解,保留高频信息,去除低频信息。

软件实操及深度光学设计(实操环节)
1.软件实操
1.1 Python环境的搭建
1.了解anaconda的安装
2.运行环境创建及激活
3.学习编译器spyder的使用
1.2 Python基本操作
1.变量、数据类型、控制流
2.函数、文件操作
1.3深度学习环境实践
1.pytorch安装及验证
2.学习编译器spyder的使用
3.Shell脚本的使用
2.深度学习基础
2.1 深度学习技术基础内容
1.了解神经网络的基本原理
2.了解反向传播和链式梯度计算
2.2主流神经网络构型讲解
1.典型卷积网络讲解
2.Transformer网络结构
3.MLP网络结构
2.3典型神经网络的搭建及训练
1.制备数据集
2.ResNet网络模型搭建
3.网络训练
3.深度光学设计
3.1相机建模
1.光学公式描述
2.光学成像过程数学建模
3.2深度相关图像形成
1.光信息到图像信息的形成
3.3深度估计网络设计
3.4实验结果及评估

低层次语义任务实践(实操环节)
1. 深度学习的图像去噪及实践
1.1 图像去噪概述
定义:图像去噪旨在消除图像中由传感器噪声、传输误差等引入的噪声,以恢复图像的清晰度。
噪声类型:高斯噪声、椒盐噪声、斑点噪声、泊松噪声等。
挑战:在去噪过程中,如何保持图像细节和纹理,同时有效去除噪声。
1.2 深度学习方法
卷积神经网络(CNN):利用卷积神经网络对图像进行端到端训练,自动学习噪声去除与图像恢复。
生成对抗网络(GAN):通过生成器和判别器优化去噪过程,生成器去除噪声,判别器判断图像质量。
自编码器(Autoencoders):卷积自编码器结构学习图像特征,去噪自编码器进行噪声去除。
1.3 主要算法和模型
DnCNN:基于深度卷积神经网络,针对高斯噪声图像进行去噪。
Noise2Noise:无监督学习,使用带噪图像进行训练,避免对干净图像的依赖。
REDNet:利用残差学习来增强去噪性能,改善细节恢复。
Denoising GAN:生成对抗网络用于噪声去除,提升去噪效果。
1.4 技术实现步骤
数据准备:准备噪声图像与干净图像的配对。
网络设计:选择合适的深度学习架构,常用的包括CNN、U-Net、GAN等。
损失函数:使用均方误差(MSE)或感知损失(Perceptual Loss)进行优化。
训练与评估:使用PSNR、SSIM等指标进行模型评估和优化。
2. 深度学习的图像超分辨与去模糊实践
2.1 图像超分辨与去模糊概述
图像超分辨:通过算法从低分辨率图像重建高分辨率图像,提升细节和清晰度。
去模糊:从模糊的图像恢复清晰图像,去除运动模糊或光学模糊。
2.2 深度学习在图像超分辨与去模糊中的应用
超分辨技术(Super-Resolution):
SRCNN:通过卷积神经网络进行超分辨,使用深度学习方法恢复图像的高频信息。
ESRGAN:利用生成对抗网络恢复图像细节和纹理,尤其在细节恢复方面优于传统方法。
VDSR:使用多层网络提升图像的分辨率,改善图像质量。
去模糊技术(Deblurring):
DeepDeblur:基于深度卷积神经网络去除模糊,提高图像清晰度。
DeblurGAN:采用生成对抗网络进行去模糊,优化图像恢复质量。
2.3 技术实现步骤
数据准备:低分辨率图像与高分辨率图像的配对,模糊图像和清晰图像配对。
网络设计:设计适合超分辨率与去模糊的深度学习模型。
损失函数:使用均方误差(MSE)、感知损失(Perceptual Loss)等。
训练与评估:通过PSNR、SSIM等评价超分辨率与去模糊的效果。
3. 深度学习的低照度图像增强实践
3.1 低照度图像增强概述
定义:低照度图像增强旨在提升低光照环境下拍摄的图像质量,改善亮度、对比度和细节。
挑战:低照度图像通常含有大量噪声,细节丢失,且对比度低。
3.2 深度学习方法
EnlightenGAN:结合生成对抗网络,增强低照度图像的亮度与对比度,恢复细节。
Low-light Image Enhancement using CNN:使用卷积神经网络对低照度图像进行增强。
Zero-Reference Deep Curve Estimation:无需参考图像,使用深度网络估算曲线,增强低光照图像。
3.3 技术实现步骤
数据准备:使用低照度图像及其高照度参考图像进行训练。
网络设计:选择生成对抗网络或卷积神经网络架构,针对低光图像特点进行设计。
损失函数:使用亮度损失、感知损失等优化网络。
训练与评估:评估增强后的图像质量,使用PSNR、SSIM等指标进行评估。
4. 深度学习的深度估计实践
4.1 深度估计概述
定义:深度估计任务旨在从图像中预测每个像素的深度,通常用于三维重建、机器人导航等应用。
挑战:单目深度估计较为困难,需要从二维图像中恢复出三维空间信息。
4.2 深度学习方法
单目深度估计:
Monodepth:使用卷积神经网络进行单目图像的深度估计,通过无监督学习方法训练。
DeepLabv3:结合深度神经网络进行图像分割与深度估计,提升复杂场景下的深度估计精度。
双目深度估计:
StereoNet:基于双目图像计算视差图,从中推断深度信息。
PSMNe
StereoNet:基于双目图像计算视差图,从中推断深度信息。
PSMNet:使用金字塔结构提升深度估计的精度,通过多尺度匹配优化视差图生成。
4.3 技术实现步骤
数据准备:收集带有深度信息的图像数据集。
网络设计:以Monodepth为典型方法进行网络架构的讲解分析,并提供代码和分析。
损失函数:使用均方误差(MSE)、交叉熵、SSIM Loss等作为损失函数进行监督训练。
训练与评估:通过δ1,δ2,δ3对预测的深度图进行评测。


高层次语义任务实践(实操环节)
1. 深度学习的图像识别实践
1.1 图像识别概述
定义:图像识别旨在自动识别和分类图像中的物体或场景。它是计算机视觉领域的核心任务之一。
应用场景:
人脸识别
动物、植物、物品分类
自动驾驶中的物体识别
挑战:
类别的不平衡
对复杂背景和不同光照条件的适应性
细节和模糊图像的处理
1.2 深度学习在图像识别中的应用
卷积神经网络(CNN):CNN是图像识别任务的基础,擅长从图像中提取局部特征,并对全局信息进行有效整合。
迁移学习:利用在大规模数据集(如ImageNet)上预训练的网络,进行迁移到特定任务,如分类和识别。
深度残差网络(ResNet):利用跳跃连接解决深度网络训练中的梯度消失问题,提高模型的表达能力。
1.3 主要模型和方法
LeNet-5:最早的卷积神经网络之一,适用于手写数字识别。
AlexNet:深度卷积神经网络,改进了图像识别的精度,并广泛应用于计算机视觉领域。
VGGNet:通过使用非常深的网络层次,改进了特征提取和表示能力。
ResNet:通过引入残差模块,解决了深度网络中的退化问题,极大提高了深度学习的表现。
InceptionNet:通过使用不同大小的卷积核在同一层进行多尺度特征提取,提升了模型的识别能力。
1.4 技术实现步骤
数据准备:图像数据的采集与标签标注,数据增强技术(旋转、裁剪、翻转等)。
网络设计:根据任务选择适合的网络结构,如CNN、ResNet、Inception等。
损失函数:分类任务中通常使用交叉熵损失(Cross-Entropy Loss)。
训练与评估:使用标准的数据集(如ImageNet、CIFAR-10)进行训练,评估指标包括准确率(Accuracy)、Top-1和Top-5精度等。
2. 深度学习的目标检测实践
2.1 目标检测概述
定义:目标检测不仅要求识别图像中的物体类别,还需要准确定位物体在图像中的位置(通过边界框)。
应用场景:自动驾驶中的行人、车辆检测,视频监控中的异常行为检测,无人机中的目标跟踪与识别
挑战:小物体的检测,多尺度目标检测,对遮挡、复杂背景和光照变化的鲁棒性
2.2 深度学习在目标检测中的应用
基于区域的卷积神经网络(R-CNN):R-CNN:首先通过选择性搜索提取候选区域,再通过CNN提取特征,并分类和回归边界框。
Fast R-CNN:改进R-CNN,通过ROI池化层来共享特征图,提高了检测速度和精度。
Faster R-CNN:引入区域提议网络(RPN),大大提高了目标检测的速度。
单阶段检测器(Single-stage Detectors):
YOLO(You Only Look Once):将目标检测转化为回归问题,网络直接预测边界框坐标和类别概率,速度较快,适用于实时检测。
SSD(Single Shot MultiBox Detector):通过多尺度的卷积层生成不同大小的默认框进行物体检测,速度和精度较好。
Anchor-based与Anchor-free方法:
Anchor-based:如YOLO、Faster R-CNN使用预定义的框(anchor box)进行预测。
Anchor-free:如CornerNet、CenterNet不依赖于预定义框,直接回归关键点位置进行检测。
2.3 技术实现步骤
数据准备:收集并标注数据集(如COCO、Pascal VOC),使用数据增强(翻转、缩放、裁剪等)增加训练数据。
网络设计:选择适合的目标检测架构,如Faster R-CNN、YOLO、SSD等。
损失函数:通常使用分类损失(交叉熵)和回归损失(边界框回归损失)来优化目标检测模型。
训练与评估:通过精度(mAP)、召回率(Recall)等评估目标检测的性能。
3. 深度学习的语义分割实践
3.1 语义分割概述
定义:语义分割旨在将图像中的每个像素分类为特定的类别,实现像素级别的分类。
应用场景:
医学图像分析(如肿瘤分割)
自动驾驶中的道路、行人、障碍物分割
遥感图像中的土地覆盖分类
挑战:
对复杂背景和细小物体的分割精度
像素级别的准确性和鲁棒性
计算开销和实时性要求
3.2 深度学习在语义分割中的应用
全卷积网络(FCN):将卷积神经网络扩展为全卷积网络,以处理像素级别的分类任务。
U-Net:通过对称的编码器-解码器结构,利用跳跃连接来有效恢复图像细节,广泛应用于医学图像分割。
SegNet:采用编码器-解码器结构,通过池化和上采样逐步恢复图像信息,适用于图像分割任务。
DeepLab:使用空洞卷积(Dilated Convolution)来扩大感受野,处理大范围上下文信息,提高分割精度。
3.3 技术实现步骤
数据准备:收集并标注数据集(如Cityscapes、Pascal VOC),进行数据增强(旋转、裁剪、翻转等)。
网络设计:选择合适的分割网络结构,如FCN、U-Net、DeepLabV3等。
损失函数:常用损失函数包括交叉熵损失(Cross-Entropy Loss)和Dice系数损失,用于优化分割性能。
训练与评估:通过评估指标(IoU、mIoU、Pixel Accuracy)对语义分割模型的精度进行评估。


02
专题二:深度学习计算光学成像
SIMPLE STYLE
第一章:光学成像基础
第一节:绪论
1.什么是光学成像?
2.光学成像进展
第二节:光学成像重要属性
1.物距、焦距、空间带宽乘积
2.分辨率、视场、景深
3.球差、慧差、场曲、畸变、色差、像差
4.点扩散函数、调制传递函数
第三节:成像质量评价指标
1.全参考评价
2.半参考评价
3.无参考评价
第四节:光学成像发展趋势
1.功能拓展 (相位、三维、非视距、穿云透雾、遥感)
2.性能改善(视场大小、分辨率、成像速度)
3.系统优化(小型化、廉价化、高效制造)

第二章:实操软件介绍及运行(实践)
第一节:Python环境的搭建
1.了解anaconda的安装
2.运行环境创建及激活
3.学习编译器spyder的使用
4.Shell脚本的使用
第二节:Python基本操作
1. 变量、数据类型、控制流
2. 函数、文件操作
第三节:深度学习环境实践
1.pytorch安装及验证
2.学习编译器spyder的使用
3.Shell脚本的使用
第四节:深度学习基础
1.了解神经网络的基本原理
2.了解反向传播和链式梯度计算
第五节:主流神经网络构型讲解
1.典型卷积网络讲解
2.Transformer网络结构
3.MLP网络结构
第六节:典型神经网络的搭建及训练(实操)
1.制备数据集
2.ResNet网络模型搭建
3.网络训练

第三章 高分辨成像技术及实践
第一节:超分辨率成像
1.基本概念及模型
2.典型方法介绍
3.高分辨成像技术实践
3.1 案例讲解
3.2 数据集及网络搭建讲解
3.3 网络结果及评价
第二节:图像去模糊
1.基本概念及模型
2.典型方法介绍
3.图像去模糊技术实践
3.1 案例讲解
3.2 数据集及网络搭建讲解
3.3 网络结果及评价
第三节:图像去雾
1.基本概念及模型
2.典型方法介绍
3.图像去雾技术实践
3.1 案例讲解
3.2 数据集及网络搭建讲解
3.3 网络结果及评价
第四节:低照度图像增强
1.基本概念及模型
2.典型方法介绍
3.低照度图像增强技术实践
3.1 案例讲解
3.2 数据集及网络搭建讲解
3.3 网络结果及评价


第四章 计算光学成像逆问题求解
第一节:CT成像逆问题求解
1.基本概念及模型
2.典型方法介绍
3.CT成像逆问题案例分析
3.1 相关论文分析
3.2 数据集及网络搭建
3.3 网络训练及结果评价
第二节:无透镜成像逆问题求解
1.基本概念及模型
2.典型方法介绍
3.无透镜成像逆问题案例分析
3.1 相关论文分析
3.2 数据集及网络搭建
3.3 网络训练及结果评价
第三节:非视距成像逆问题求解
1.基本概念及模型
2.典型方法介绍
3.非视距成像逆问题案例分析
3.1 相关论文分析
3.2 数据集及网络搭建
3.3 网络训练及结果评价
第四节:压缩感知成像逆问题求解
1.基本概念及模型
2.典型方法介绍
3.压缩感知成像逆问题案例分析
3.1 相关论文分析
3.2 数据集及网络搭建
3.3 网络训练及结果评价
第五章 遥感和地球观测
第一节:高光谱成像
1.基本概念及模型
2.典型方法讲解
3.高光谱成像技术案例解析
3.1 典型研究方案设计动机分析
3.2 网络结构分析及网络搭建
3.3 网络训练及结果分析
第二节:合成孔径雷达成像
1.基本概念及模型
2.典型方法讲解
3.合成孔径雷达成像案例解析
3.1 典型研究方案设计动机分析
3.2 网络结构分析及网络搭建
3.3 网络训练及结果分析
第三节:TOF成像
1.基本概念及模型
2.典型方法讲解
3.TOF成像案例解析
3.1 典型研究方案设计动机分析
3.2 网络结构分析及网络搭建
3.3 网络训练及结果分析
第四节:遥感目标检测
1.基本概念及模型
2.典型方法讲解
3.遥感目标检测案例解析
3.1 典型研究方案设计动机分析
3.2 网络结构分析及网络搭建
3.3 网络训练及结果分析

第六章 深度光学技术及实践
第一节:用于HDR成像的深度光学
1.基本概念及模型
2.典型方法介绍
3.技术实操
3.1 设备系统分析
3.2 深度模型的构建及训练
3.3 评测结果及创新改进分析
第二节:畸变感知对焦深度
1.基本概念及模型
2.典型方法介绍
3.技术实操
3.1 设备系统分析
3.2 深度模型的构建及训练
3.3 评测结果及创新改进分析
第三节:用于衍射快照高光谱成像的量化感知深度光学技术
1.基本概念及模型
2.典型方法介绍
3.技术实操
3.1 设备系统分析
3.2 深度模型的构建及训练
3.3 评测结果及创新改进分析



03
专题三:深度学习光学设计
SIMPLE STYLE
第一章 导论
第一节 深度学习与光网络综述
1.1 衍射神经网络
1.2 片上集成光学神经网络
第二节 深度学习与超表面反向设计综述
第三节 光网络与超表面反向设计的挑战
第四节 光网络与超表面反向设计未来的发展趋势
第二章 软件基础知识(Python实操)
第一节 Python 环境的搭建
1.1 Anaconda 、Numpy、Matplotlib 和 Pandas 安装
1.2 虚拟环境的搭建以及 Pytorch 安装
1.3 Pytorch GPU 版本的安装
第二节 Python 的基础教程
2.1 Python 常见的数据结构与数据类型
2.2 Numpy 基础教程
2.3 Pandas 基础教程
2.4 Matplotlib 基础教程
第三节 Pytorch 基本教程
3.1 数据操作
3.2 数据预处理
3.3 线性代数
3.4自动微分

第三章 深度学习模型(python实操)
第一节机器学习基本组件
第二节线性神经网络实例
2.1线性回归
2.2softmax 回归
第三节多层感知机实例
3.1多层感知机
3.2权重衰减
3.3Dropout
第四节卷积神经网络实例
4.1从全连接层到卷积
4.2通道和汇聚层
4.3卷积神经网络(LeNet)
第五节循环神经网络实例
5.1序列模型
5.2语言模型和数据集
5.3循环神经网络
第四章 基于马赫-增德尔干涉仪的光计算
第一节光计算及光神经网络的简介
1.1光计算的背景介绍
1.2光神经网络的发展与分类
1.3光神经网络的研究现状
第二节基于MZI的光神经网络原理
2.1全连接神经网络原理讲解
2.2MZI级联的相干光矩阵计算原理
2.3N阶酉矩阵分解
2.4基于MZI拓扑级联的酉矩阵通用架构
第三节训练数据集的获取与处理(Python 实操)
3.1Python程序环境安装
3.2Pycharm主要功能介绍
3.3数据集的获取方法
3.4训练数据集的前期处理
第四节酉矩阵通用架构的搭建(Python 实操)
4.1 二阶酉矩阵的搭建
4.2 clement架构的搭建
第五节光神经网络的模型运行(Python 实操)



第五章 超材料
第一节超材料概述
第二节光子晶体(COMSOL实际操作)
2.1 光子晶体基础和应用
2.2 传递矩阵方法求解一维光子晶体能带
2.3 平面波展开法求解一维光子晶体能带
2.4 有限元法求解光子晶体能带
2.4.1二维正方晶格能带
2.4.2二维正方晶格光子晶体板能带
2.4.3二维三角晶格光子晶体板能带
2.4.4二维六角晶格光子晶体板能带
2.5 光子晶体板中的连续谱束缚态(BIC)及其拓扑荷的计算
第三节超表面在光场调控中的作用
3.1相位调控
3.2光强调控
3.3偏振调控
3.4频率调控
3.5联合调控
第四节超表面仿真实例(COMSOL 实际操作)
4.1 频率选择表面周期性互补开口谐振环
4.2 超表面光束偏折器
第五节超构表面在量子光学中的研究与应用
5.1量子等离激元
5.2量子光源
5.3量子态的测量与操纵
5.4量子光学的应用


第六章 全光衍射神经网络
第一节标量衍射理论基础
1.1 惠更斯-菲涅耳原理
1.2 瑞利-索莫菲衍射公式
1.3 衍射角谱理论
1.4 离散傅里叶变换
第二节光学衍射神经网络(Python 实操)
2.1 人工神经网络结构
2.2 光学衍射神经网络结构
2.3 自由空间光学衍射神经网络
2.4 硅基集成衍射神经网络(Comsol 仿真)


第七章 硅光子学平台上矢量矩阵乘法的反向设计(COMSOL 实操)
第一节基于密度的拓扑优化
1.1前向传播场
1.2伴随场
1.3折射率插值
第二节有效折射率仿真
第三节向量乘法

第八章 基于深度学习的超表面反设计(COMSOL + python实操)
第一节 基于全连接实现全介质超表面的设计
1.1 超表面元的模拟
1.2 超表面元的参数提取
1.3 训练数据集的搭建
1.4 预测模型的训练
第二节 长短期记忆神经网络预测纳米鳍超表面极化灵敏度
2.1 长短期记忆神经网络搭建
2.2 超表面仿真
2.3 数据库建立
2.4模型训练
第三节 基于深度学习的混合全局优化设计超低损耗波导交叉
3.1 直接二分查找算法建立数据集
3.2 基于物理的生成对抗神经网络
3.3 模型训练与预测



#MITracker
多视角视觉目标跟踪新突破!高效融合多视角特征,解决遮挡与目标丢失问题!
一种高效的多视角目标跟踪方法MITracker,它通过融合多视角特征解决了传统单视角跟踪中的遮挡和目标丢失问题,并通过构建大规模多视角跟踪数据集MVTrack推动了该领域的发展。
Title: MITracker: Multi-View Integration for Visual Object Tracking
论文: https://arxiv.org/abs/2502.20111
主页: mii-laboratory.github.io/MITracker/

动机:
视觉目标跟踪是计算机视觉领域的核心任务之一,广泛应用于增强现实、自动驾驶等场景。然而,传统的单视角跟踪方法在面对遮挡、目标丢失等挑战时表现不佳。尽管多视角跟踪(MVOT)通过多视角信息的互补性提供了潜在的解决方案,但该领域的发展受到以下限制:
- 数据集限制:现有的多视角数据集大多局限于特定类别(如行人或鸟类),缺乏通用性。
- 方法限制:现有的多视角跟踪方法主要依赖于检测和重识别技术,难以实现类无关的目标跟踪。
- 跨视角信息融合不足:现有的方法在跨视角信息融合方面效果有限,难以应对复杂的空间关系和视角变化。
为了解决这些问题,我们提出了一个新的多视角跟踪数据集 MVTrack 和一个高效的多视角跟踪方法 MITracker,旨在通过多视角信息的融合提升跟踪的鲁棒性和准确性。
本文贡献:
- MVTrack数据集:我们构建了一个大规模的多视角跟踪数据集,包含234K高质量标注帧,涵盖27个不同类别的物体和9种具有挑战性的跟踪属性(如遮挡、变形等)。MVTrack是首个支持类无关多视角跟踪训练和评估的综合性数据集。
- MITracker方法:我们提出了一种新颖的多视角跟踪方法MITracker,通过将2D图像特征转换为3D特征体积,并利用鸟瞰图(BEV)引导的多视角信息融合机制,显著提升了跟踪的稳定性和准确性。
- 性能提升:MITracker在MVTrack和GMTD数据集上均达到了最先进的性能,特别是在遮挡和目标丢失等复杂场景下,恢复率从56.7%提升至79.2%。
MVTrack数据集特性:
- 多视角数据:3-4个同步相机拍摄,确保多视角重叠。
- 丰富类别:涵盖27个日常物体,从小型物体(如笔)到大型物体(如雨伞)。
- 高质量标注:每帧提供精确的2D边界框(BBox)和鸟瞰图(BEV)标注。
- 挑战性属性:包含9种常见的跟踪挑战,如背景杂乱、运动模糊、部分遮挡、完全遮挡、目标消失等。
- 大规模数据:包含260个视频,总计234,430帧,分为训练集、验证集和测试集。

MITracker方法亮点:
- 多视角特征融合:通过将多视角的2D特征投影到3D空间,并利用BEV引导的特征聚合,显著增强了模型的空间理解能力。
- 空间增强注意力机制:通过引入3D感知的注意力机制,MITracker能够在目标丢失或遮挡的情况下快速恢复跟踪。
- 高效跟踪:MITracker能够在任意长度的视频帧中跟踪任意物体,并在多视角场景下保持稳定的跟踪效果。

实验与结果:
我们在MVTrack和GMTD数据集上进行了广泛的实验,MITracker在多个评估指标上均达到了最先进的性能。特别是在多视角场景下,MITracker的表现显著优于现有的单视角跟踪方法,展示了其在复杂场景下的强大鲁棒性。

未来工作:
我们计划进一步扩展MVTrack数据集,增加室外场景和更多类别的物体,以提升模型的泛化能力。同时,我们也将探索减少对相机校准的依赖,使MITracker在更多实际场景中应用。
总结:
MITracker通过多视角信息的有效融合,解决了传统单视角跟踪中的遮挡和目标丢失问题,为多视角视觉目标跟踪领域提供了新的解决方案。我们相信,MVTrack数据集和MITracker方法将为未来的研究提供强有力的支持,推动视觉目标跟踪技术的进一步发展。
#一块2080Ti搞定数据蒸馏,GPU占用仅2G
来自上交大“最年轻博导”课题组
只要一块6年前的2080Ti,就能做大模型数据蒸馏?
来自上交大EPIC实验室等机构的一项最新研究,提出了一种新的数据集蒸馏方法——NFCM。
与前SOTA相比,新方法的显存占用只有1/300,并且速度提升了20倍,相关论文获得了CVPR满分。
NCFM引入了一个辅助的神经网络,将数据集蒸馏重新表述为一个极小化极大(minmax)优化问题。
在多个基准数据集上,NCFM都取得了显著的性能提升,并展现出可扩展性。
在CIFAR数据集上,NCFM只需2GB左右的GPU内存就能实现无损的数据集蒸馏,用2080Ti即可实现。
并且,NCFM在连续学习、神经架构搜索等下游任务上也展现了优异的性能。
将数据蒸馏转化为minmax优化
NCFM的核心是引入了一个新的分布差异度量NCFD,并将数据集蒸馏问题转化为一个minmax优化问题。
通过交替优化合成数据以最小化NCFD,以及优化采样网络以最大化NCFD,NCFM在提升合成数据质量的同时,不断增强分布差异度量的敏感性和有效性。
特征提取与频率参数采样
NCFM的第一步,是进行特征提取,也就是从真实数据集和合成数据集中分别采样一批数据,并将其输入到特征提取网络中。
特征提取网络将原始数据从像素空间映射到一个特征空间,得到对应的特征表示,目的是提取数据的高层语义特征,为后续的分布匹配做准备。
特征提取网络可以是一个预训练的模型,也可以是一个随机初始化的模型,这里NCFM采用了一种混合方式。
接下来,NCFM引入了一个轻量级的神经网络作为采样网络,它接受一个随机噪声作为输入,输出一组频率参数。
这些频率参数将用于对特征函数(Characteristic Function,CF)进行采样。
特征函数计算与分布差异度量
对于每一个频率参数,将其与特征表示进行内积运算,然后取复指数,就得到了对应的CF值。
这两个CF值都是复数,其中实部刻画了数据在该频率上的分布范围,捕捉分布的散度或多样性;虚部则反映了数据在该频率上的分布中心,捕捉分布的典型性或真实性。
通过比较真实数据和合成数据的CF值,就可以全面地度量它们在特征空间上的分布差异。
为了定量地度量真实数据和合成数据之间的分布差异,NCFM引入了一个称为神经特征函数差异(Neural Characteristic Function Discrepancy,NCFD)的度量。
NCFD综合考虑了所有采样频率上的CF差异,将其汇总为一个标量值。NCFD越小,说明两个分布越接近;NCFD越大,说明两个分布差异越大。
minmax优化
有了NCFD这个分布差异度量,NCFM的优化目标就很清晰了——
最小化NCFD,使得合成数据和真实数据的分布尽可能接近;同时,望最大化NCFD对合成数据的敏感度,使之能够准确反映合成数据的变化。
为了同时实现这两个目标,NCFM引入了一个minmax优化框架:
- 在极小化阶段,固定采样网络的参数,调整合成数据,目标是最小化NCFD。这一步使得合成数据向真实数据分布不断靠拢。
- 在极大化阶段,固定合成数据,调整采样网络的参数,目标是最大化NCFD。这一步使得NCFD对合成数据的差异更加敏感,提升其作为差异度量的有效性。
通过交替进行极小化阶段和极大化阶段的优化,NCFM不断改进合成数据的质量,同时也不断强化NCFD度量的敏感性和准确性。
模型微调与标签生成
为了进一步提升合成数据的质量,NCFM在优化过程中还引入了两个额外的步骤——模型微调和标签生成。
- 在模型微调阶段,NCFM用合成数据微调特征提取网络,使其更加适应合成数据的特征分布,从而进一步缩小合成数据和真实数据之间的特征差异,提高合成数据的真实性;
- 在标签生成阶段,用一个预训练的教师模型来为合成数据生成软标签。软标签提供了更加丰富和细粒度的监督信息,可以指导合成数据更好地模仿真实数据的类别分布,提高合成数据的多样性。
一块2080Ti搞定CIFAR实验
相比于此前方法,NCFM在多个数据集上实现了显著的性能提升。
在CIFAR-10、CIFAR-100、等数据集中上,NCFM在每类1/10/50张图片的情况下的测试精度均超过了所有baseline方法。
在ImageNet的各个子集上,NCFM也展现了卓越的性能。
例如在ImageNette上,每类10张图片时,NCFM达到了77.6%的测试精度,比现有最佳方法(RDED)高出14.4个百分点;
在ImageSquawk上,每类10张图片时,NCFM达到了72.8%的测试精度,比现有最佳方法(MTT)高出20.5个百分点。
在性能提升的同时,NCFM还实现了大量的速度提升和资源节约。
在CIFAR-100上,NCFM每轮迭代的平均训练时间比TESLA快了29.4倍,GPU内存消耗仅为TESLA的1/23.3(每类50张图片);
在Tiny ImageNet上,NCFM每轮迭代的平均训练时间比TESLA快了12.8倍,GPU内存消耗仅为TESLA的1/10.7(每类10张图片)。
并且,NCFM在CIFAR-10和CIFAR-100上实现了无损的数据集蒸馏,仅使用了约2GB的GPU内存,使得CIFAR上的所有实验都可以在一块2080Ti上进行。
此外,NCFM生成的合成数据在跨模型泛化能力上超过了现有方法。
例如在CIFAR-10上,用NCFM生成的合成数据训练AlexNet、VGG和ResNet,都取得了比现有方法更高的测试精度。
来自上交大“最年轻博导”课题组
本文第一作者,是上交大人工智能学院EPIC实验室博士生王少博。
王少博本科就读于哈工大软件工程专业,专业排名第一名;然后在上交大读研,导师是严骏驰教授,研究方向为深度学习理论和可解释性机器学习,其间专业排名第二。
现在王少博正在张林峰助理教授负责的EPIC实验室读博,研究方向为“高效、可解释的深度学习和”大模型。
王少博现在的导师张林峰,是本文的通讯作者。
张林峰出生于1997年,去年6月在清华叉院取得博士学位,然后到上交大人工智能学院担任博导并负责EPIC实验室,时年仅有27岁。
同时,张林峰还在NeurIPS、ICML、ICLR、CVPR等顶级学术会议当中担任审稿人
张林峰还曾到香港科技大学(广州)担任访问助理教授,他的邀请人胡旭明同样是一名年轻博导,并且也参与了本项目。此外还有EPIC实验室的其他成员,以及来自上海AI实验室的学者,亦参与了NFCM的研究。
论文地址:
https://github.com/gszfwsb/NCFM/blob/main/asset/paper.pdf
GitHub仓库:

















 4801
4801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









