






在介绍多核处理器的同步机制之前,先来看一个同步问题的例子。有两个处理器核P0和P1分别对同一共享地址的变量A进行加1的操作。于是,处理器P0先读取A的值,然后加1,最后将A写回内存。同样,处理器核P1也进行一样的操作。然而,如图11.11所示,实际的运算过程却有可能产生两种不一样的结果,注意整个运算过程是完全符合Cache一致性协议规定的。所以A的值可能增加了1,如图11.11a所示;也可能增加了2,如图11.11b所示。然而,这样的结果对于软件设计人员来说是完全无法接受的。因此,需要同步机制来协调多个处理器核对共享变量的访问。
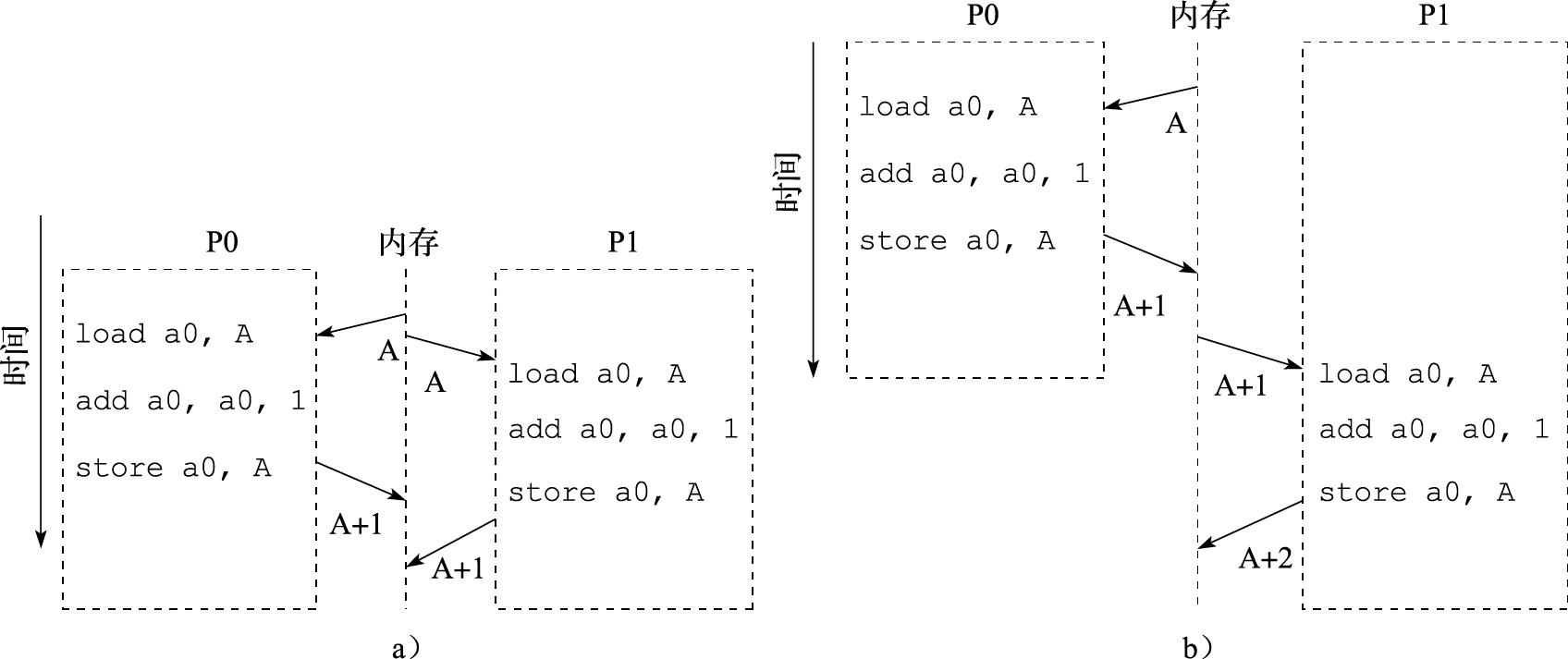
图 11.11: 一个并行程序产生两种不同结果
为了解决同步问题,需要采用同步机制。常见的同步机制包括锁操作、栅障操作和事务内存。锁操作和事务内存主要用于保护临界区;栅障操作用于实现全局同步。锁操作和栅障操作属于传统同步方法,广泛用于并行系统中,事务内存则是适应多核处理器设计需求的一种新同步机制。同步机制一般建立在用户级软件例程(Routine)上,而这些软件例程主要基于硬件提供的同步指令来实现。
1.原子操作
硬件设计人员在处理器中增加了一种特殊的机制,支持多个操作之间的原子性(Atomic,也就是不可分割性)。在硬件上实现满足不可分割性的原子操作有许多种方法,既可以在寄存器或者存储单元中增加专门的硬件维护机制,也可以在处理器的指令集中添加特定的原子指令。早期的处理器大多选择在存储单元中增加特殊的原子硬件维护机制,而现代处理器大多使用原子指令方式。原子指令的实现方式可以分为两种,其中一种是直接使用一条“读-改-写”(Read-Modify-Write,RMW)原子指令来完成,另一种是使用一组原子指令对LL/SC(Load-Linked/Store-Conditional)来完成指定的原子操作。
常见的“读-改-写”原子指令包括Test_and_Set、Compare_and_Swap、Fetch_and_Op等。Test_and_Set 指令取出内存中对应地址的值,同时对该内存地址赋予一个新的值。Compare_and_Swap指令取出内存中对应地址的值和另一个给定值A进行比较,如果相等,则将另一个给定值B写入这个内存地址,否则不进行写操作;指令应返回状态(例如X86的cmpxchg指令设置eflags的zf位)来指示是否进行了写操作。Fetch_and_Op指令在读取内存对应地址值的同时将该地址的值进行一定的运算再存回。根据运算操作(Op)的不同,Fetch_and_Op指令又有许多种不同的实现形式。例如,Fetch_and_Increment指令就是读取指定地址的值,同时将该值加1并写回内存。可以看出“读-改-写”原子指令和内存的交互过程至少有两次,一次读内存,另一次写内存,而两次交互过程之间往往还有一些比较、加减之类的运算操作(改)。
使用原子指令对LL/SC实现原子操作方式的过程如下:首先,LL指令将对应地址的内存数据读入寄存器,然后可以对该寄存器中的值进行任意的运算,最后使用SC指令尝试将运算后的数据存回内存对应的地址。当且仅当LL指令完成之后没有其他对该地址内存数据的修改操作,则SC指令执行成功并返回一个非零值,运算后的数据顺利写回内存,否则SC指令执行失败并返回值0,修改后的数据不会被写回内存,也不会产生任何对内存的改动。SC指令失败后一般需要重新执行上述过程,直到SC指令成功为止。SC指令的成功说明了LL/SC指令之间没有其他对同一地址的写入操作,也就保证了LL/SC指令之间的不可分割性。图11.12的例子采用LL/SC指令实现了寄存器R1的内容与R3对应的内存位置的内容的原子交换。

图 11.12: 用LL/SC指令对实现原子交换操作
LL/SC原子指令对的优点在于设计简单,每条指令只需和内存交互一次,且在LL指令和SC指令之间可以加入任意的运算指令,可以灵活地实现类似于“读-改-写”的复杂原子操作。其缺点在于密集共享时,SC不容易成功,一种优化措施是LL访问时把相应Cache行置为EXC状态,而不是SHD状态,这样可以提高SC成功的概率。相对于Test_and_Set指令和Fetch_and_Op指令等实现复杂的单条原子指令,LL/SC指令对成为目前最常见的原子指令,被多种现代RISC指令系统所采用,如MIPS、IBM Power、DEC Alpha和LoongArch等等。
2.锁的软件实现方法
锁(Lock)是并行程序中常用的对多个线程共享的临界区(Critical Section)进行保护的同步操作。自旋锁(Spin Lock)是锁操作的一种最基本的实现形式。Test_and_Set自旋锁是最简单的自旋锁,通过使用Test_and_Set原子指令来完成锁的获取、等待和查询。Test_and_Set锁的基本步骤如图11.13所示,假设1表示锁被占用,0表示锁空闲。处理器使用Test_and_Set原子指令读取锁变量的值,同时将锁变量的值改为1。如果读取到锁的值为0,说明锁空闲,该处理器成功获得锁。由于Test_and_Set指令已经将锁的值同时改为了1,所以其他处理器不可能同时获得这把锁。如果锁的值为1,说明已经有其他处理器占用了这把锁,则该处理器循环执行Test_and_Set指令自旋等待,直到成功获得锁。由于当时锁的值已经是1了,Test_and_Set指令再次将锁的值设为1,实际上锁的值并没有发生变化,所以不会影响到锁操作的正确性。当获得锁的处理器打算释放锁时,只需要简单地执行一条普通的store指令,将锁的值设置为0即可。由于一次只能有一个处理器核获得锁,所以不用担心多个处理器核同时释放锁而引发访存冲突,也就不需要使用原子指令来释放锁了。

图 11.13: Test-and-Set自旋锁
Test_and_Set自旋锁最主要的一个缺点就是对锁变量的访存冲突。当一个处理器核获得锁以后,其他等待的处理器核会不断循环执行Test_and_Set指令访问锁变量,试图获取锁权限,从而在片上互连上产生大量的访存通信。一种简单的优化方法就是在Test_and_Set指令之间加入一定的延迟,减少等待阶段Test_and_Set原子指令自旋执行的次数以减轻访存的压力。此外,研究人员还提出了排队锁(Ticket Lock)、基于数组的队列锁(Array-Based Queuing Lock)、基于链表的队列锁(List-Based Queuing Lock)等优化机制。
3.栅障软件实现方法
栅障(Barrier)是并行程序中常用的同步操作。栅障要求处理器核等待,一直到所有处理器核都到达栅障后,才能释放所有处理器核继续执行。栅障有多种实现方式,下面主要介绍比较简单的集中式栅障。集中式栅障就是在共享存储中设置一个共享的栅障变量。每当一个处理器核到达栅障以后,就使用原子指令修改栅障值表示自己已经到达(如将栅障的值加1),然后对该栅障值进行自旋等待,如图11.14的伪代码所示。当栅障的值表明所有处理器核都已经到达(即栅障的值等于预计到达的总的处理器核的数量)时,栅障操作顺利完成,所有自旋等待的处理器核就可以继续往下执行了。集中式栅障的实现简单、灵活,可以支持各种类型的栅障,包括全局栅障和部分栅障,适用于可变处理器核数量的栅障操作。
在集中式栅障中,每一个到达的处理器核都需要对同一个共享的栅障值进行一次修改以通告该处理器核到达栅障,已到达栅障的处理器核会不断访问栅障值以判断栅障是否完成。由于Cache一致性协议的作用,这个过程会在片上互连上产生许多无用的访存通信,并且随着处理核数的增加,栅障的时间和无用的访存数量都会快速增长,所以集中式栅障的可扩展性不好。为了减少上述查询和无效的访存开销,集中式栅障也可以采用类似于Test_and_Set锁的方式,在查询操作之中增加一些延迟。加入延迟虽然可以减少一些网络带宽的浪费,但是也可能降低栅障的性能。针对集中式栅障的弱点,研究人员提出了软件合并树栅障等优化方法。

图 11.14: 集中式栅障伪代码
4.事务内存
1993年,Herlihy和Moss以事务概念为基础,针对多核处理器中并行编程的同步效率问题提出了事务内存的概念。在事务内存中,访问共享变量的代码区域声明为一个事务(Transaction)。事务具有原子性(Atomicity),即事务中的所有指令要么执行要么不执行;一致性(Consistency),即任何时刻内存处于一致的状态;隔离性(Isolation),即事务不能看见其他未提交事务涉及的内部对象状态。事务执行并原子地提交所有结果到内存(如果事务成功),或中止并取消所有的结果(如果事务失败)。
事务内存实现的关键部分包括:冲突检测、冲突解决以及事务的提交和放弃。冲突检测就是确定事务并发执行过程中是否存在数据的冲突访问。冲突解决是指在发生冲突时决定继续或者放弃事务的执行。如果支持事务的暂停操作,可以暂停引起冲突的事务,直到被冲突的事务执行结束;如果不支持事务的暂停操作,就必须在引起冲突的事务中选择一个提交,同时放弃其他事务的执行。事务的提交或放弃是解决事务冲突的核心步骤,事务提交需要将结果数据更新到内存系统中,事务放弃需要将事务的结果数据全部丢弃。
事务内存实现方式主要有软件事务内存和硬件事务内存两种。软件事务内存在通过软件实现,不需要底层硬件提供特殊的支持,主要以库函数或者编程语言形式实现。例如,RSTM、DSTM、Transactional Locking等以库函数实现,线程访问共享对象时通过对应的库函数来更新事务执行的状态、检测冲突和处理等;HSTM语言中扩展了事务原语;AtomCaml在ObjectCaml语言中增加了对事务内存同步模型的支持等。硬件事务内存主要对多核处理器的Cache结构进行改造,主要包括:增加特定指令来标示事务的起止位置,使用额外的事务Cache来跟踪事务中的所有读操作和写操作;扩展Cache一致性协议来检测数据冲突。软件事务内存实现灵活,更容易集成到现有系统中,但性能开销大;硬件事务内存需要修改硬件,但是性能开销小,程序整体执行性能高。Intel Haswell处理器和IBM Power8处理器中实现了对硬件事务内存的支持。下面来看一个具体的实现例子。
Intel TSX(Transactional Synchronization Extensions)是Intel公司针对事务内存的扩展实现,提出了一个针对事务内存的指令集扩展,主要包括3条新指令:XBEGIN、XEND和XABORT。XBEGIN指令启动一个事务,并提供了如果事务不能成功执行的回退地址信息;XEND指令表示事务的结束;XABORT指令立刻触发一个中止,类似于事务提交不成功。硬件实现以Cache行为单位,跟踪事务的读集(Read-Set)和写集(Write-Set)。如果事务读集中的一个Cache行被另一个线程写入,或者事务的写集中的一个Cache行被另一个线程读取或写入,则事务就遇到冲突(Conflict),通常导致事务中止。Intel Haswell处理器中实现了Intel TSX。















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









