






本文介绍一篇ECCV2022发表的文章,其题目为《You Should Look at All Objects》,该文章深度剖析了在目标检测中引入FPN会导致大物体检测性能变差的问题。而这一问题往往被总体性能增加所掩盖(因为中、小物体的检测性能有所提升)。
FPN
首先回顾一下FPN的结构,其是一个Top-Down的特征融合结构,将顶层丰富的语义信息传递到浅层。
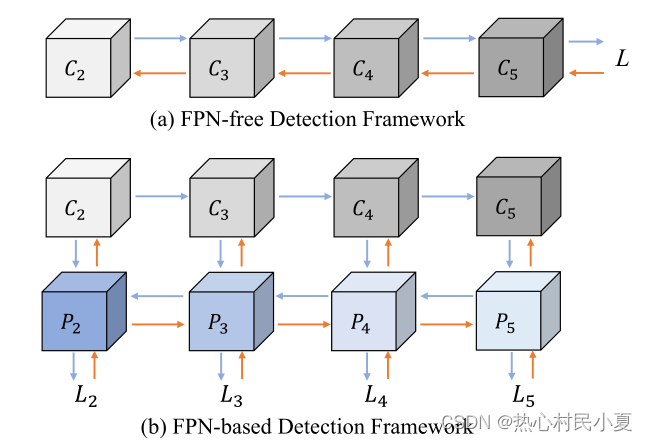
图(a)为不使用FPN。图(b)为FPN的结构,其中蓝色的箭头为正向传播,橙色的箭头为反向传播。
问题引出
(1)作者首先针对不使用FPN的结构增加辅助监督,即在原本仅在C5后面监督的基础上在C2、C3、C4后面都增加分类与回归分支再求Loss进行辅助监督,结果发现居然能够与FPN的性能相差无几。(红柱子跟黄柱子差不多高)
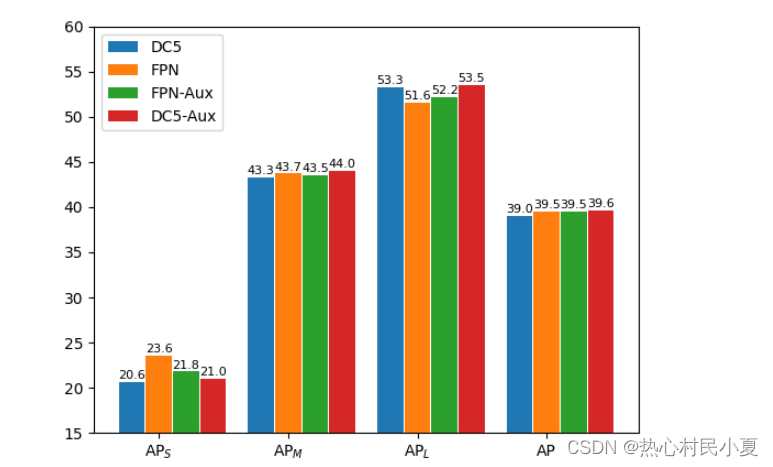
(2)作者根据上述分析证实了导致大物体的检测性能减小的问题是梯度的传递问题,因为浅层C2是用来检测小物体的,而他的反向传播学习到的只是针对小物体检测的能力,即梯度只传播到C2而不会传播到C3、C4、C5。但是C3、C4、C5又是C2经过下采样得到的,所以会导致深层针对小物体学习能力增加而越来越好。但是这同时会导致深层对大物体的学习能力变差,而深层又是负责对大物体进行检测的。(太绕了,具体可以见上面FPN那张图)
解决方法
针对上述问题,作者提出了辅助损失、改进FPN、级联结构三个模块进行解决。
(1)辅助损失
L
(
p
,
g
t
)
=
e
−
α
L
(
p
,
g
t
)
+
τ
α
L(p,gt)=e^{-\alpha} L(p,gt)+\tau \alpha
L(p,gt)=e−αL(p,gt)+τα
其中p为预测值、gt为真实值,
τ
\tau
τ是一个超参数,
α
\alpha
α是一个不确定的可学习参数,其是通过下述式子得到。
α
=
R
e
L
U
(
w
⋅
x
+
b
)
\alpha = ReLU(w\cdot x+b)
α=ReLU(w⋅x+b)
其中x为生成预测p的特征图。
(2)改进FPN
X
k
=
R
z
h
w
(
M
k
⊗
R
z
n
(
C
k
′
)
,
2
≤
k
≤
5
X_{k}=R^{zhw}(M_{k} \otimes R^{zn}(C_{ k}^{\prime} ),2\le k\le 5
Xk=Rzhw(Mk⊗Rzn(Ck′),2≤k≤5
其中R为reshape的操作,
M
k
M_{k}
Mk的生成如下述公式:
M
k
=
G
k
(
C
k
′
)
M_{k}=G_{k}(C_{ k}^{\prime} )
Mk=Gk(Ck′)
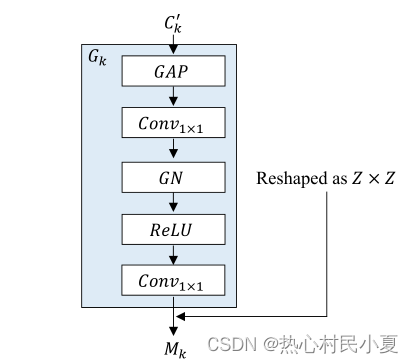
G
k
G_{k}
Gk的操作如上图所示。
得到了每一层的
X
k
X_{k}
Xk之后,会对其在通道维度上进行拆分,拆分公式如下所示:
X
k
=
X
k
,
2
,
X
k
,
3
,
X
k
,
4
,
X
k
,
5
X_{k}={X_{k,2},X_{k,3},X_{k,4},X_{k,5}}
Xk=Xk,2,Xk,3,Xk,4,Xk,5
上述公式将每一层差分为4份(代表最终生成的特征层个数),最后再将每一层对应1编号的进行拼接,这样就能够使得每一个特征层都进行有效的融合。
P
l
′
=
X
2
,
l
⊕
X
3
,
l
⊕
X
4
,
l
⊕
X
5
,
l
,
2
≤
l
≤
5
P_{l}^{\prime } =X_{2,l}\oplus X_{3,l}\oplus X_{4,l}\oplus X_{5,l},2\le l\le 5
Pl′=X2,l⊕X3,l⊕X4,l⊕X5,l,2≤l≤5
(3)级联模块
级联模块较为简单,就是堆叠多个上述改进的FPN模块,每次的输出作为下一次的输入。注意中间加入非线性即可。
最后附上原文链接,感兴趣可以阅读一下原文,讲解的特别清楚,有什么不对的地方可以一起讨论。
https://arxiv.org/pdf/2207.07889.pdf添加链接描述















 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









