






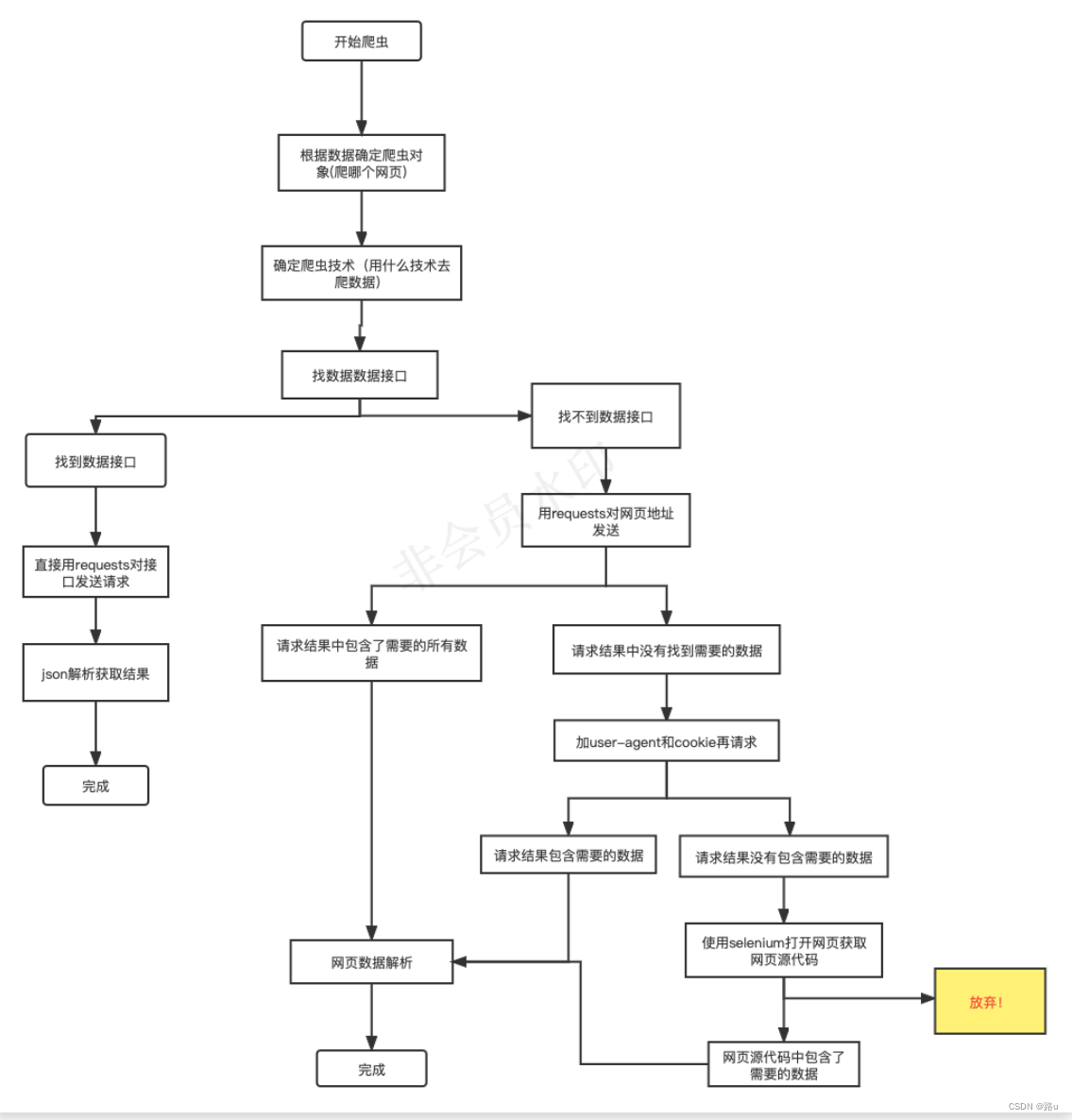
爬虫流程
-
根据所需数据确定爬虫网页
-
首先考虑resquests(需要提前导入)
1)若是文本数据,用response.text
2)若是下载视频、图片、音频,用response.content
3)若是json接口,用response.json()
4)若出现编码方式问题,提前在网页中的charset查看编码方式,并在response.encoding = ’ '中添加
-
找到该网页是否有数据接口(json)(Request URL下)
1)若有,直接用resquests对接口发送请求,解析获取结果,浏览器中提前下好json解析器方便查看数据;requests.get(json)
2)若没有,直接用resquests对网页地址发送数据请求requests.get(网页地址)
-
resquests对网页地址发送数据请求成功,既可利用正则、bs4、xpath方法对网页数据爬取
-
resquests对网页地址发送数据请求失败
1)伪装浏览器,在header中添加user-agent
2)若失败,再在header中添加cookie,重新发送请求
-
若依旧失败,放弃resquests,使用selenium
-
若依旧失败,便放弃
注意:
1)以上方法出现需要登录才能继续时,都需要利用cookie;
2)当IP被被封时,需要添加代理IP














 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









