







文章目录
12-1 多叉树
课程贴:https://ceshiren.com/t/topic/11792
多叉树与红黑树
引言
时间复杂度分析
树的插入,删除,查找的时间复杂度与树的高度成正比: O(高度) == O(最大层数 - 1) ,最符合需求的就是完全二叉树,来看下完全二叉树的最大高度:

完全二叉树除最后一层,每层结点数:1, 2, 4,…, 2k-1
最后一层:1~2(L-1)
完全二叉树的结点数 n :
n >= 1+2+4+8+…+2L-2 + 1
n <= 1+2+4+8+…+2L-2 + 2L-1
利用等比数列求和公式:
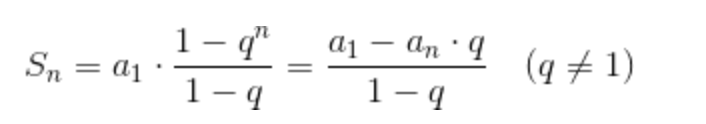
L 的范围是 [log2(n+1), (log2n) +1]。完全二叉树的层数 <= (log2n) +1 ,其高度小于等于 log2n
二叉查找树会出现树的高度过高,从而导致各个操作的效率下降,比如下图只有右孩子的树(退化成了链表):
为避免这种情况,一般选用平衡二叉查找树:红黑树。
什么是平衡二叉查找树?
平衡二叉树:任意节点左右子树的高度差 <= 1:
- 完全二叉树
- 满二叉树
- 一些非完全二叉树
平衡二叉树:

非平衡二叉树

早期的 AVL 树是平衡二叉树 + 查找 = 平衡二叉查找树。
但为了实际应用,后续的树都没遵从平衡树的定义(比如红黑树),只要树的高度不比 log2n 大很多,都符合定义。
红黑树
红黑树的英文是 Red-Black Tree,简称 R-B Tree。
- 根节点是黑色。
- 叶子节点是黑色的空节点(为了简化代码,本章节可以不考虑)
- 每个红色结点的两个子结点都是黑色(从每个叶子到根的所有路径上不能有两个连续的红色结点)
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点

为什么红黑树的高度可以稳定地趋近 log2n ?
将红色节点删除,变成下图(四叉树),由于每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点,于是四叉树可以转换成完全二叉树,于是仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小。

把红色节点加回去,由于红色节点不能相邻(红色数量 ~= 黑色数量)。红黑树的高度近似 2log2n。
平衡树比较
- Treap(树堆)、Splay Tree(伸展树)无法避免时间复杂度的退化
- AVL 树是一高度平衡的二叉树,查找效率非常高,但是为了维持高度平衡,每次插入、删除都要做调整
- 红黑树做到了近似平衡,维护平衡的成本比 AVL 树低
12-2 递归算法
课程贴:https://ceshiren.com/t/topic/11613
什么是递归?
递归应用非常广泛,比如 DFS 深度优先搜索、前中后序二叉树遍历等等。
假设一群人在排队,你不清楚自己前面有多少人,可以问前面的人:

但你前面也不清楚,整体过程就是递归:

如果用递推公式描述:
f(n)=f(n-1)+1 其中,f(1)=1
int f(int n) {
if (n == 1) return 1;
return f(n-1) + 1;
}
什么情况可以使用递归 ?
1.一个问题可以拆分成子问题.
2.这些问题求解思路相同(数据规模不同)
3.拥有终止条件
来看一个问题:
假如 n 个台阶(n >= 3),每次可以走 1 或 2 个台阶,走完 n 个台阶有多少种走法?
比如有 3 个台阶,可以 1,2 或者 2,1 :
f(n) = f(n-1)+f(n-2) 其中,f(1)=1,f(2)=2
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n-1) + f(n-2);
}
常见问题
深度问题

重复计算问题


public int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
// hasSolvedList可以理解成一个Map,key是n,value是f(n)
if (hasSolvedList.containsKey(n)) {
return hasSolvedList.get(n);
}
int ret = f(n-1) + f(n-2);
hasSolvedList.put(n, ret);
return ret;
}
内存开销问题
int f(int n) {
if (n == 1) return 1;
return f(n-1) + 1;
}
空间复杂度:O(n)
将递归改写为非递归
int f(int n) {
int ret = 1;
for (int i = 2; i <= n; ++i) {
ret = ret + 1;
}
return ret;
}
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
int ret = 0;
int pre = 2;
int prepre = 1;
for (int i = 3; i <= n; ++i) {
ret = pre + prepre;
prepre = pre;
pre = ret;
}
return ret;
}
原理:函数调用底层原理是栈,可以利用 for 循环模拟入栈和出栈操作
12-3 单例
课程贴:https://ceshiren.com/t/topic/11910
为什么要使用单例
普通的类就像生产机器,可以生产多个实例(动物糕点),就像下图:

单例设计模式(Singleton Design Pattern)对实例做限制,一个类只允许创建一个对象。

那么,对类进行限制有什么好处?假设对文件进行写入,同一个对的多个线程同时写入会造成资源竞争问题,比如两个线程同时给一个共享变量加 1 ,共享变量最后的结果可能只加了 1 。

如果是同一个对象,加入对象级别互斥锁就能解决问题。

如果是 Java 程序,可以用 synchronized 关键字给写入操作加入互斥锁:
public class Logger {
private FileWriter writer;
public Logger() {
// 创建文件
File file = new File("/Users/wangzheng/log.txt");
// 进行追加写入
writer = new FileWriter(file, true);
}
public void log(String message) {
// 为 write 加入互斥锁
synchronized(this) {
writer.write(mesasge);
}
}
}
但是,这段代码存在两个问题:
1.FileWriter 本身就是对象安全的,代码多此一举,。
2.这是对象锁,不同线程使用同一对象才有效,若使用不同对象,没有效(如果不理解,见下图)。

其实问题不难解决,把对象级别锁提升到类级别即可:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true);
}
public void log(String message) {
// 使用类级别的锁
synchronized(Logger.class) {
writer.write(mesasge);
}
}
}

其实还有很多方案,分布式锁,并发队列等等,但这些方案都比较复杂,而单例模式的思路简单清晰。下面来实现多个单例。
饿汉式单例
顾名思义,饥饿难忍,在类加载时就创建好实例。

很多语言都支持在类加载前就初始化变量的操作,比如 Java 的静态变量和 Python 的类变量,利用这个特性就能实现饿汉式单例。
java 实现
public class IdMaker {
// Java 静态属性只会加载一次,所以 instance 只会被初始化一次
// 利用 Java 静态属性,可以避免多线程资源竞争问题
// 饿汉式:静态属性,在类加载阶段,完成初始化
private static IdMaker instance = new IdMaker();
// ID 计数器,默认值是 -1
private int id = -1;
// 把 IdMaker 的构造函数,设为私有(用于阻止调用者实例化 IdMaker)
private IdMaker() {
}
// 获取实例
public static IdMaker getInstance() {
return instance;
}
// 通过 ++ 操作,获取不一样的 ID 值
public int getId() {
id++;
return id;
}
}
class TestIdMaker {
public static void main(String[] args) {
// 获取唯一的 ID
int id1 = IdMaker.getInstance().getId();
int id2 = IdMaker.getInstance().getId();
int id3 = IdMaker.getInstance().getId();
System.out.println(id1);
System.out.println(id2);
System.out.println(id3);
// 0 1 2
}
}
python
class IdMaker:
# python 的类变量会被多个类,实例共享
__instance = None
# __id 也是类变量,多个实例或类共享
__id = -1
# python 在类加载阶段,通过父类的 __new__ 创建实例,如果我们重写 __new__
# 就不会调用父类的 __new__ ,就会调用我们写的 __new__ 创建实例
# __new__ 需要返回一个实例,如果不返回,就不会实例化
def __new__(cls):
if cls.__instance is None:
# 父类的 __new__ ,参数接收一个类名,会返回类的实例
cls.__instance = super().__new__(cls)
return cls.__instance
# 计数器,在获取前,进行 + 1
def get_id(self):
self.__id += 1
return self.__id
def test_id_maker():
# IdMaker 是单例类,只允许有一个实例
id1 = IdMaker().get_id()
id2 = IdMaker().get_id()
id3 = IdMaker().get_id()
print(id1, id2, id3)
if __name__ == "__main__":
test_id_maker()
# 0 1 2
因为过于饥饿,该实现不支持延迟加载(用到的时候再初始化),如果实例占用资源多会造成初始化的慢,卡。其实,将占用资源多的方法提前(饿汉),有利有弊:
- 利:避免运行中卡顿,在初始化阶段就能发现错误
- 弊:提前初始化浪费资源
懒汉式单例
懒汉非常懒惰,在类使用阶段才会创建实例。

懒汉式可以弥补饿汉式缺点,由于在使用实例时才创建,避免初始化阶段卡慢。
Java 实现
public class IdMaker {
// Java 引用类型的默认属性是 null
// 在类加载阶段,不进行初始化
private static IdMaker instance;
// ID 计数器,默认值是 -1
private int id = -1;
// 把 IdMaker 的构造函数,设为私有(用于阻止调用者实例化 IdMaker)
private IdMaker() {
}
// 懒汉式:在获取实例的阶段,进行初始化
// synchronized 是互斥锁,为了保证在多线程时,只实例化一次
public static synchronized IdMaker getInstance() {
// 如果发现 instance 没有被初始化,就完成初始化
if (instance == null)
instance = new IdMaker();
return instance;
}
// 通过 ++ 操作,获取不一样的 ID 值
public int getId() {
id++;
return id;
}
}
class TestIdMaker {
public static void main(String[] args) {
// 获取唯一的 ID
int id1 = IdMaker.getInstance().getId();
int id2 = IdMaker.getInstance().getId();
int id3 = IdMaker.getInstance().getId();
System.out.println(id1);
System.out.println(id2);
System.out.println(id3);
// 0 1 2
}
}
python 实现
from threading import Lock
class IdMaker:
# 申请一个线程锁
__instance_lock = Lock()
# python 的类变量会被多个类,实例共享
__instance = None
# __id 也是类变量,多个实例或类共享
__id = -1
# 如果 __new__ 抛出异常,就不允许调用者进行实例化
def __new__(cls):
raise ImportError("Instantition not allowed")
# 类方法不用实例化也能调用,因为我们不允许进行实例化,所以要使用类方法
@classmethod
def get_instance(cls):
# with 会帮我们自动的上锁和释放,不用我们操心
with cls.__instance_lock:
if cls.__instance is None:
# 因为我们的 __new__ 代码不允许进行实例化,所以可以借用父类的 __new__ 进行实例化
cls.__instance = super().__new__(cls)
return cls.__instance
# 计数器,在获取前,进行 + 1
def get_id(self):
self.__id += 1
return self.__id
def test_id_maker():
# IdMaker 是单例类,只允许有一个实例
id1 = IdMaker.get_instance().get_id()
id2 = IdMaker.get_instance().get_id()
id3 = IdMaker.get_instance().get_id()
print(id1, id2, id3)
if __name__ == "__main__":
test_id_maker()
# 0 1 2
12-4 工厂方法
课程贴:https://ceshiren.com/t/topic/11937
简介
当创建对象的代码多而杂时,可以用工厂模式将对象的创建和使用分离,让代码更加清晰。
比如下面代码根据不同的 rule 创建不同的对象。
java demo
public class Demo {
// 解析文件,返回解析内容
public void load(String rule) {
IParse parse = null;
// 根据不同的文件类型,执行不同的内容
// 分析:如果代码中创建对象的过程很复杂,就需要把这段代码移出去,单独封装成类,封装的类就是工厂类
if ("xml".equals(rule))
parse = new XmlParse();
else if ("json".equals(rule))
parse = new JsonParse();
else if ("excel".equals(rule))
parse = new ExcelParse();
else if ("csv".equals(rule))
parse = new CsvParse();
else
parse = new OtherParse();
// parse 是解析类之一,具体是哪一个,要根据 rule 来决定
parse.parse();
// 省略其它有关 load 的大量操作
}
public static void main(String[] args) {
Demo demo = new Demo();
// 传入 json
demo.load("json");
}
}
// 所有解析类的接口,规定解析类的方法
interface IParse {
// 需要解析类去实现
public void parse();
}
class XmlParse implements IParse {
// 解析结果
public void parse() {
System.out.println("XmlParse");
}
}
class JsonParse implements IParse {
public void parse() {
System.out.println("JsonParse");
}
}
class ExcelParse implements IParse {
public void parse() {
System.out.println("ExcelParse");
}
}
class CsvParse implements IParse {
public void parse() {
System.out.println("CsvParse");
}
}
class OtherParse implements IParse {
public void parse() {
System.out.println("OtherParse");
}
}
python demo
# Demo 用于加载不同的文件,对不同的文件作不同的处理
class Demo:
def load(self, rule):
parse = None
# 根据不同的 rule ,创建不同的对象
if "xml" == rule:
parse = XmlParse()
elif "json" == rule:
parse = JsonParse()
elif "excel" == rule:
parse = ExcelParse()
elif "csv" == rule:
parse = CsvParse()
else:
parse = OtherParse()
# 调用对象的方法进行操作
parse.parse()
# 相当于接口,用于规范各个解析类
# 每个解析类都要实现 parse 方法,否则在调用的时候就会报错
class IParse:
def parse(self):
raise ValueError()
class XmlParse(IParse):
def parse(self):
print("XmlParse")
class JsonParse(IParse):
def parse(self):
print("JsonParse")
class ExcelParse(IParse):
def parse(self):
print("ExcelParse")
class CsvParse(IParse):
def parse(self):
print("CsvParse")
class OtherParse(IParse):
def parse(self):
print("OtherParse")
if __name__ == "__main__":
Demo().load("json")
简单工厂
把创建大量实例的代码放到工厂类中。
java 实现
public class Demo {
// 解析文件,返回解析内容
public void load(String rule) {
IParse parse = ParseFactory.createParse(rule);
// parse 是解析类之一,具体是哪一个,要根据 rule 来决定
parse.parse();
// 省略其它有关 load 的大量操作
}
public static void main(String[] args) {
Demo demo = new Demo();
// 传入 json
demo.load("json");
}
}
// 简单工厂:把创建对象的代码移动到这个类中的一个方法,这个类就叫做简单工厂
// 简单工厂的类名字通常以 Factory 结尾
// 简单工厂的方法,通常叫 createParse
class ParseFactory {
public static IParse createParse(String rule) {
IParse parse = null;
// 根据不同的文件类型,执行不同的内容
if ("xml".equals(rule))
parse = new XmlParse();
else if ("json".equals(rule))
parse = new JsonParse();
else if ("excel".equals(rule))
parse = new ExcelParse();
else if ("csv".equals(rule))
parse = new CsvParse();
else
parse = new OtherParse();
return parse;
}
}
// 所有解析类的接口,规定解析类的方法
interface IParse {
// 需要解析类去实现
public void parse();
}
class XmlParse implements IParse {
// 解析结果
public void parse() {
System.out.println("XmlParse");
}
}
class JsonParse implements IParse {
public void parse() {
System.out.println("JsonParse");
}
}
class ExcelParse implements IParse {
public void parse() {
System.out.println("ExcelParse");
}
}
class CsvParse implements IParse {
public void parse() {
System.out.println("CsvParse");
}
}
class OtherParse implements IParse {
public void parse() {
System.out.println("OtherParse");
}
}
python 实现
# Demo 用于加载不同的文件,对不同的文件作不同的处理
# 问题:如果创建对象的代码比如多,可能还会创建 text ,md,yml 等等
# 简单工厂解决:把对象的创建移动到其它类中, load 方法就会很简洁
class Demo:
def load(self, rule):
parse = ParseRuleFactory().create_parse(rule)
# 调用对象的方法进行操作
parse.parse()
# 简单工厂类:用于实例的创建,根据 rule 创建不同的实例。本质就是把 Demo 中原来创建实例的代码,给迁移过来
class ParseRuleFactory:
def create_parse(self, rule):
parse = None
# 根据不同的 rule ,创建不同的对象
if "xml" == rule:
parse = XmlParse()
elif "json" == rule:
parse = JsonParse()
elif "excel" == rule:
parse = ExcelParse()
elif "csv" == rule:
parse = CsvParse()
else:
parse = OtherParse()
return parse
# 相当于接口,用于规范各个解析类
# 每个解析类都要实现 parse 方法,否则在调用的时候就会报错
class IParse:
def parse(self):
raise ValueError()
class XmlParse(IParse):
def parse(self):
print("XmlParse")
class JsonParse(IParse):
def parse(self):
print("JsonParse")
class ExcelParse(IParse):
def parse(self):
print("ExcelParse")
class CsvParse(IParse):
def parse(self):
print("CsvParse")
class OtherParse(IParse):
def parse(self):
print("OtherParse")
if __name__ == "__main__":
Demo().load("json")
工厂方法
如果创建实例的代码非常复杂,就可以把创建实例的代码单独放入一个类。
比如下面的例子,创建实例代码复杂:
java 实现
public class Demo {
// 如果创建对象时,代码很复杂,简单工厂就不能解决问题,因为即使使用简单工厂,创建实例依旧很复杂
// 此时就需要工厂方法来解决、
// 工厂方法解决方案:将每一个创建过程都封装到工厂类中
// 比如下面的 JsonParseRuleFactory ,将复杂的代码都放到了 JsonParseRuleFactory 类中
public void load(String rule) {
IParse parse = null;
if ("xml".equals(rule))
// 省略了 1000 行代码
parse = new XmlParse();
else if ("json".equals(rule))
parse = new JsonParseRuleFactory().createParse();
else if ("excel".equals(rule))
// 省略了 1000 行代码
parse = new ExcelParse();
else if ("csv".equals(rule))
// 省略了 1000 行代码
parse = new CsvParse();
else
// 省略了 1000 行代码
parse = new OtherParse();
// parse 是解析类之一,具体是哪一个,要根据 rule 来决定
parse.parse();
// 省略其它有关 load 的大量操作
}
public static void main(String[] args) {
Demo demo = new Demo();
// 传入 json
demo.load("json");
}
}
// 工厂方法的接口:要根据不同的调用,实现不同的操作
interface IParseRuleFactory {
// createParse 接口要创建对象以及复杂操作
public IParse createParse();
}
// 把原来 json 处理的所有代码,都迁移过来
class JsonParseRuleFactory implements IParseRuleFactory {
public IParse createParse() {
// 省略了 1000 行代码
return new JsonParse();
}
}
// 所有解析类的接口,规定解析类的方法
interface IParse {
// 需要解析类去实现
public void parse();
}
class XmlParse implements IParse {
// 解析结果
public void parse() {
System.out.println("XmlParse");
}
}
class JsonParse implements IParse {
public void parse() {
System.out.println("JsonParse");
}
}
class ExcelParse implements IParse {
public void parse() {
System.out.println("ExcelParse");
}
}
class CsvParse implements IParse {
public void parse() {
System.out.println("CsvParse");
}
}
class OtherParse implements IParse {
public void parse() {
System.out.println("OtherParse");
}
}
python 实现
# 问题:简单工厂不能解决创建实例的代码可能很复杂,即使迁移到了简单工厂中,复杂的创建过程依旧存在
# 解决:使用工厂方法,把创建过程封装到工厂类
class Demo:
def load(self, rule):
parse = None
if "xml" == rule:
# 省略 1000 行代码
parse = XmlParse()
elif "json" == rule:
parse = JsonParseRuleFactory().create_parse()
elif "excel" == rule:
# 省略 1000 行代码
parse = ExcelParse()
elif "csv" == rule:
# 省略 1000 行代码
parse = CsvParse()
else:
# 省略 1000 行代码
parse = OtherParse()
# 调用对象的方法进行操作
parse.parse()
# 相当于接口,用于规范各个工厂类
class IParseRuleFactory:
def create_parse(self):
raise ValueError()
# 工厂:把 Json 的解析放到此工厂下面
class JsonParseRuleFactory (IParseRuleFactory):
def create_parse(self):
# 省略 1000 行代码
return JsonParse()
# 相当于接口,用于规范各个解析类
# 每个解析类都要实现 parse 方法,否则在调用的时候就会报错
class IParse:
def parse(self):
raise ValueError()
class XmlParse(IParse):
def parse(self):
print("XmlParse")
class JsonParse(IParse):
def parse(self):
print("JsonParse")
class ExcelParse(IParse):
def parse(self):
print("ExcelParse")
class CsvParse(IParse):
def parse(self):
print("CsvParse")
class OtherParse(IParse):
def parse(self):
print("OtherParse")
if __name__ == "__main__":
Demo().load("json")
抽象工厂
假设有 A 公司, B 公司,C 公司… 都要有自己的解析方法,比如:A 公司有 AXmlParseFactory ,B 公司有 BXmlParseFactory ,C 公司有 CXmlParseFactory 。如果此时使用简单工厂和工厂方法,工作量非常大,因为要给每一个公司都创建所有的解析工厂。
此时可以用抽象工厂解决问题。解析工厂返回多个实例,比如,XmlParseFactory 可以返回 A ,B , C 的实例。
java 实现
// 抽象工厂:使工厂类具有返回多个实例的功能
interface IParseRuleFactory {
public IParse AcreateParse();
public IParse BcreateParse();
public IParse CcreateParse();
}
class XmlParseRuleFactory implements IParseRuleFactory{
public IParse AcreateParse() {}
public IParse BcreateParse(){}
public IParse CcreateParse(){}
}
python 实现
# 问题:如果多个公司都要封装工厂,比如 A, B, C ...公司都要封装自己的工厂,就要封装 n 个工厂类
# 解决:可以使用抽象工厂解决问题,每个工厂类可以创建多个实例,比如 JsonParseRuleFactory ,可以创建 A, B, C 公司的实例
# 一个工厂类,可以生成多个公司的解析方法
class IParseRuleFactory:
def a_create_parse(self):
raise ValueError()
def b_create_parse(self):
raise ValueError()
def c_create_parse(self):
raise ValueError()
# 实现时候,一个工厂类就可以生成多个公司的实例
class JsonParseRuleFactory(IParseRuleFactory):
def a_create_parse(self):
"""
"""
def b_create_parse(self):
"""
"""
def c_create_parse(self):
"""
"""
12-6 设计模式基本原则解读

SOLID
| 英文名 | 中文 | 解释 |
|---|---|---|
| Single Responsibility Principle | 单一职责 | 一个类或者模块只负责完成一个职责(或者功能) |
| Open Closed Principle | 开闭原则 | 对扩展开放、对修改关闭 |
| Liskov Substitution Principle | 里式替换 | 子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏 |
| Interface Segregation Principle | 接口隔离原则 | 客户端不应该被强迫依赖它不需要的接口 |
| Dependency Inversion Principle | 依赖反转原则 | 高层模块不要依赖低层模块。高层模块和低层模块应该通过抽象来互相依赖。除此之外,抽象不要依赖具体实现细节,具体实现细节依赖抽象。 |
其它原则
| 简称 | 英文名 | 中文 | 解释 |
|---|---|---|---|
| KISS | Keep It Simple and Stupid | 尽量保持简单 | 保持简单 |
| YAGNI | You Ain’t Gonna Need It | 你不会需要它,不要做过度设计 | |
| DRY | Don’t Repeat Yourself | 不重复 | 不要编写重复的代码 |
| LOD | Law of Demeter | 迪米特法则 | 每个模块只应该了解那些与它关系密切的模块的有限知识 |
















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











