









文章目录
传送门
由于操作系统知识太多,再加上我总结的比较细,所以一篇放不下,拆分成了多篇文章。
操作系统笔记——概述、进程、并发控制
操作系统笔记——储存器管理、文件系统、设备管理
操作系统笔记——Linux系统实例分析、Windows系统实例分析
北理工操作系统实验合集 | API解读与例子
北京理工大学操作系统复习——习题+知识点
资料包百度云下载,含2022年真题一套,提取码cyyy
储存器管理
概述

这些功能由软件(操作系统)和硬件(MMU)协同完成。
存储区分内核区和用户区,储存管理仅针对用户区。
地址空间与映射

- 用户使用符号(变量名)访问变量和子程序,这两种东西都有对应的空间
- 从程序角度看,程序是独占内存的,所以逻辑上都是从0开始的。甚至每一个obj文件中都是以0开始的
- 将obj链接后,构成了一个完整的程序,有一个合并后的逻辑地址区域。
- 最后把程序装入内存后,逻辑地址将会转换成物理地址。
逻辑地址又叫相对地址,逻辑地址,虚地址。
物理地址又叫绝对地址,物理地址,实地址。
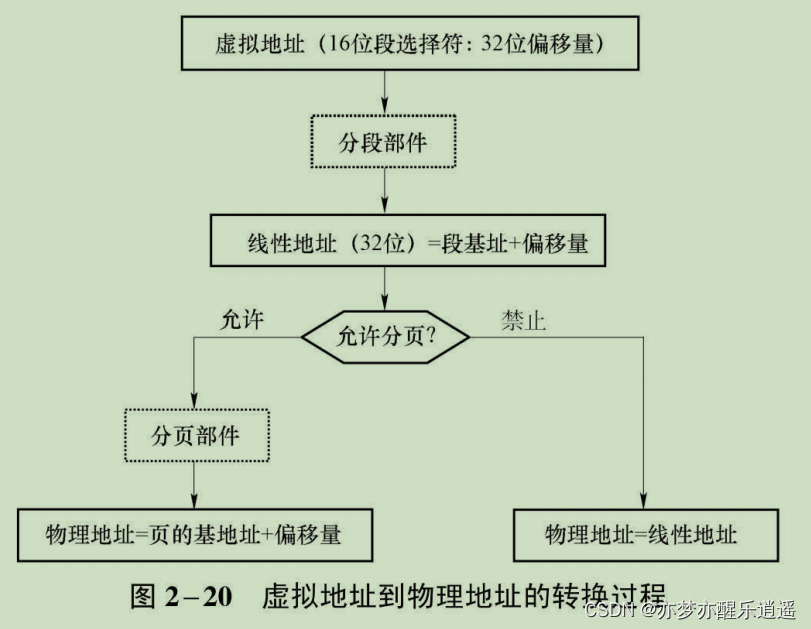
从逻辑地址到物理地址的过程叫地址重定位/地址映射/地址变换,分两种:
- 静态重定位。装入内存前,将程序中逻辑地址转换为物理地址。优点是实现简单,不需要额外的硬件,缺点是程序运行后就不可以再进行程序位置变动,主存利用不充分,不可共享主存。
- 动态重定位。程序指令不做修改,通过一个重定位寄存器记录程序在内存中的偏移,程序寻址时通过寄存器进行逻辑地址转换,如果程序移动,移动过程很简单,附加的步骤也只不过是把重定位寄存器中的偏移修改一下罢了。优点是程序可移动,主存利用充分,可以共享主存。缺点是需要额外的硬件基础。
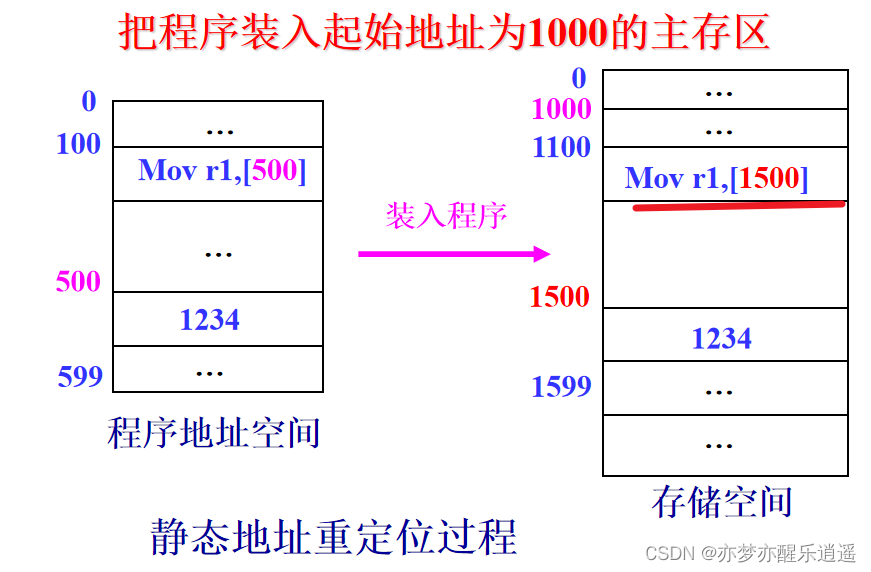
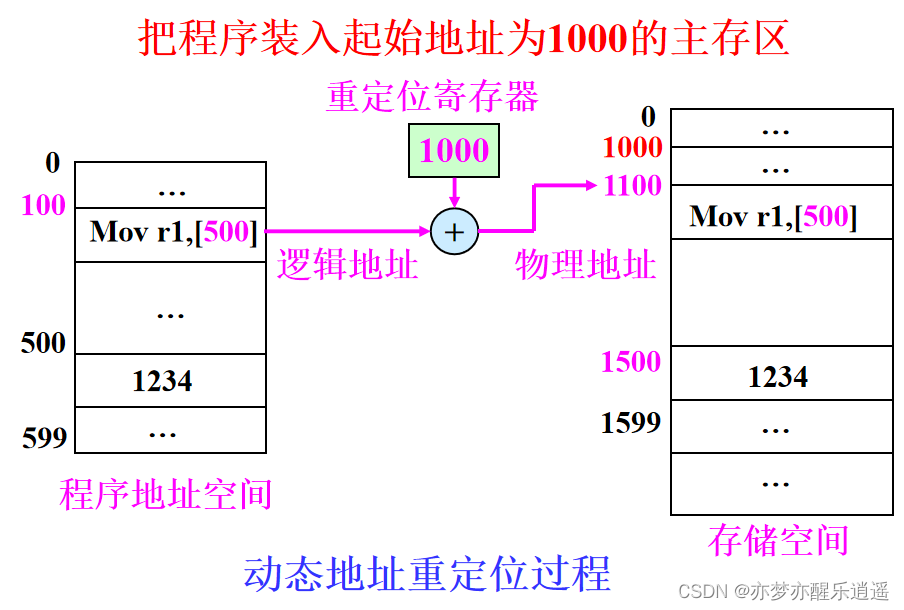
静态链接和动态链接的区别
最开始是静态链接,要什么库就拉进来什么模块(obj)。但是,假设AB程序都用到了L库,那么在AB同时执行的之后,都要装载在内存中,即内存中会同时出现两个L模块的内容,这很明显是一种浪费。
于是就有了动态链接。操作系统将一些很容易重复使用的库做成动态链接库(windows下的 .dll),在链接的时候这些库不会被加入到exe文件中。在exe运行的时候,第一个用到动态链接库的程序会把dll装载到内存中,后面再有用这个dll的程序就不需要装载了,当没有程序用这个dll的时候,就会把这个dll从内存中释放。
这就能解释为什么你从网上下载的一些软件没法用了,因为你缺一些动态链接库。解决的方法也很简单,上网搜到以后,放到对应的磁盘位置,操作系统要用的时候就会去这里找dll装载,参考这篇文章:
其实动态链接还有一个边装载边链接的方法,不过不常用。
储存器保护
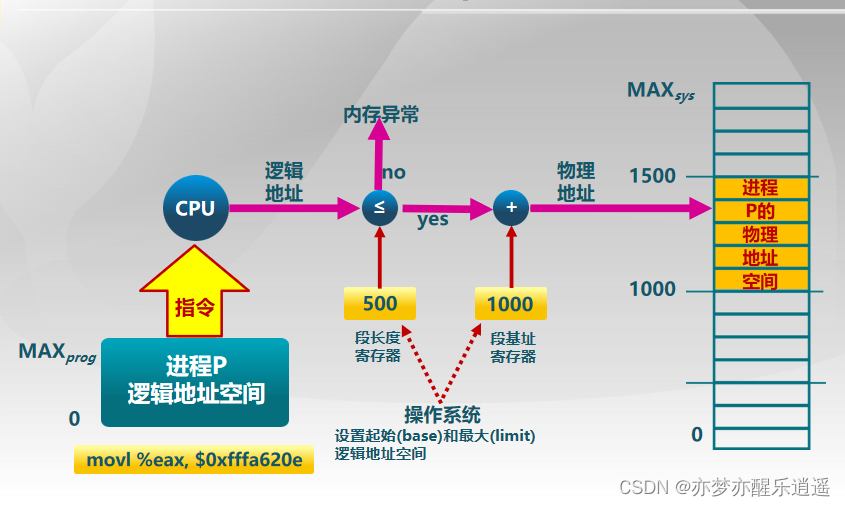
图中,保护是溢出保护。先用长度判断空间大小是否够用,确定够用以后才会加基地址偏移。
存储器共享
多进程共享一片内存,可以是数据区,也可以是程序区。
共享程序必须是纯代码(可重入程序),即无论运行多少次都不会变的代码。否则,一个进程修改了代码,另一个进程就会受到影响。
储存器分配:单用户单通道程序——直接分配
最原始的,因为只有一个进程,所以起始位置是固定的,区域也是连续的,定位也是静态的,不需要转换。存储保护也很简单,限定不可以进入内核空间就行。
总之,用户空间是固定的,连续的。
储存器分配:多用户多通道程序——分区分配
多进程,所以要把一个内存划分,每个区域是连续的。
分区与管理是核心问题。下面介绍的固定式分区和可变分区都是比较落后的方式,最先进的还是虚拟段页式管理。
固定式分区
区域大小位置是固定的,但是大小不一定相等,有大有小。
进程进来以后找到可以满足进程的最小分区即可。如果没有适合的,那就等待。

多进程队列中,按照程序需要的空间大小,将程序分成若干队列。缺点是可能会造成有的分区是空的。有的分区在排队。
单进程队列中,如果小的在排队,那么可能就直接去用大的了。缺点是容易造成空间浪费。
无论是单进程队列还是多进程队列,总之都会造成空间浪费。
但凡是分区,那就一定要管理分区元数据,就会有分区管理表。
分配与回收内存的时候,会修改分区表中的占用状态。

可变分区
因为固定分区会造成明显的空间浪费,所以出现了可变分区。根据进程需求动态划分区域。

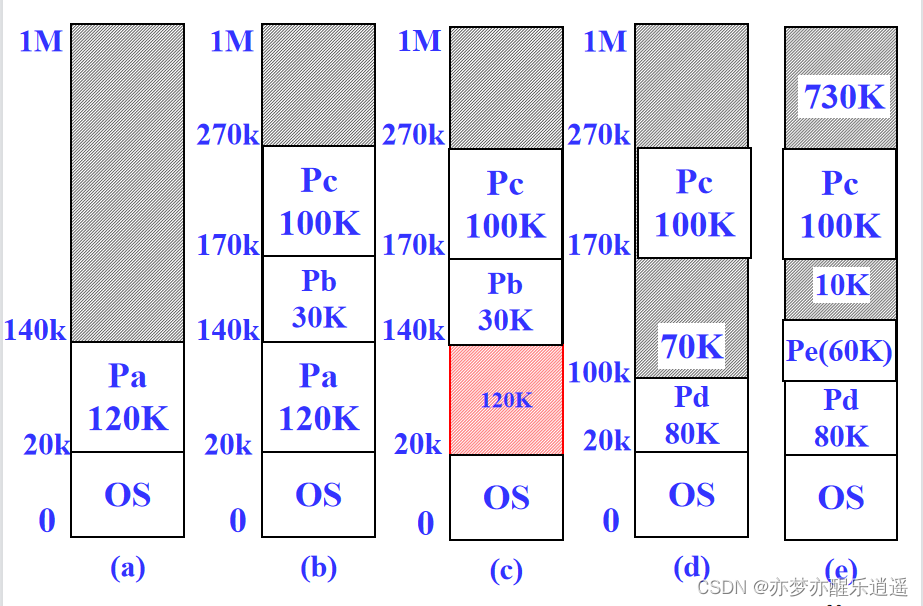
很明显,动态内存也是有缺点的,那就是会形成一些细碎的空间碎片。
可变分区的管理结构
动态分区的数据结构比较复杂一些。

分区说明表
分区说明表本身是要占用内存的,长度也是固定的。既然长度固定,表的长度就不好确定了,太大了浪费,太小了装不下。
所以可变分区基本是不用分区说明表的,分区说明表用在固定分区比较合适。
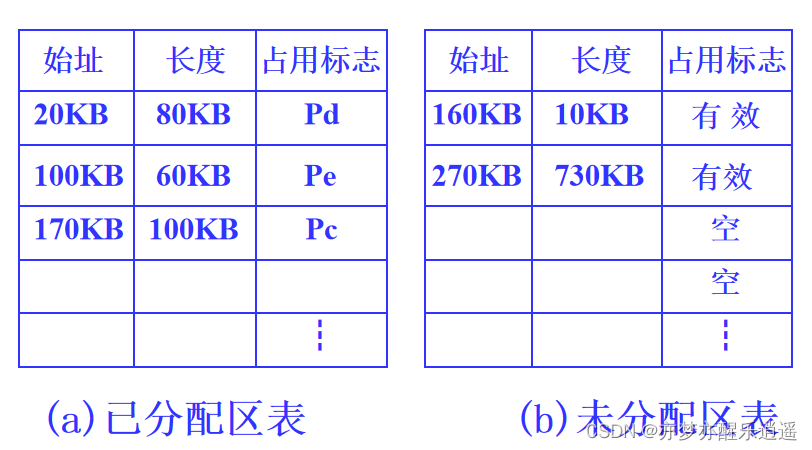
分配与回收的时候无非就是两张表同时修改。

空闲区链
既然长度不好确定,那就用链表。
实际上,链表里把已分配区和空闲区都存了,一般是按照内存顺序连续排列。

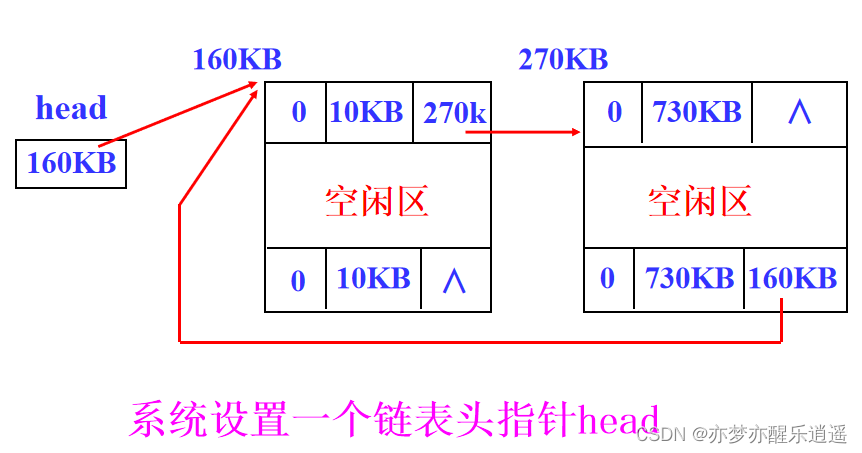
空间分配算法
- 首次适应法。分区顺序排序,遍历,只要找到一个可以的就放进去
- 最佳适应法。遍历分区,找到最省的放进去,将剩下的留在空闲链表中。一个是搜索速度慢(可以通过按大小排序解决),另外还会产生大量的内存碎片。
- 最坏适应法。遍历分区,找到最大的,将需要的切割出来用,将剩下的留在空闲链表中。优点是不会产生碎片了,因为剩下的很多,但是可能满足不了大进程的需要了。
内存回收与合并
如果释放区与空闲区相邻,就会进行合并操作。
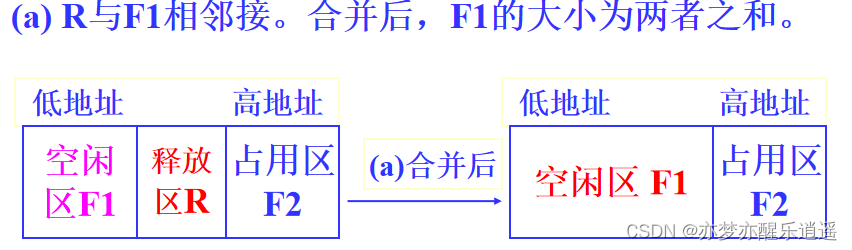
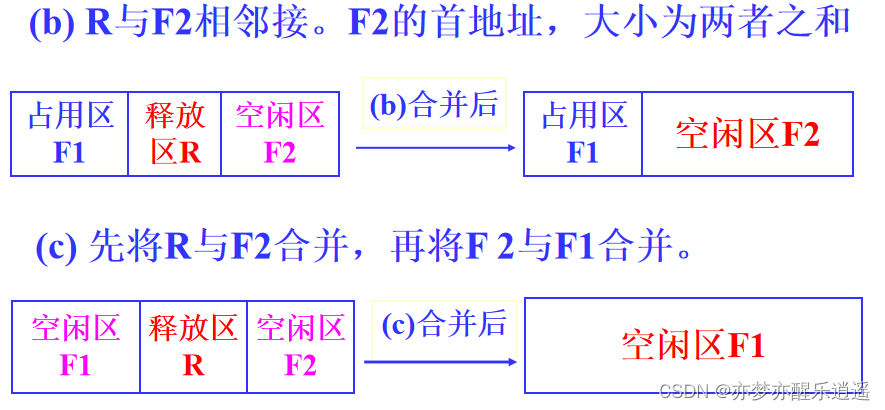
如果不相邻,那就把释放出的空间从占用链里去掉,丢进空闲区链里。
地址重定位与储存器保护


分区管理的优缺点
用简单的方法实现了多进程并存管理与保护。系统设计比较简单,即使是动态分区要用MMU,开销也很小。
因为太简单了,所以无论是静态还是动态,那都会浪费内存,形成内存碎片。
另一个问题在于,空间必须是连续的(这也是无法利用碎片的原因)。
最后,没有虚拟内存(也不一定是虚拟内存),无法实现主存的扩充。
现在都用虚拟段页式技术。
覆盖与交换技术——内存“扩充”
大进程需要用大内存,但是内存往往不足,所以要扩充内存。平时最常见的是虚拟内存,但是不止。
覆盖
因为很多程序还是顺序执行的,那么程序就可以划分为多个程序段,其中必然有不会同时执行的,那这两个程序段就可以共用一个内存,反正不会同时执行。
这两段程序叫覆盖段,公用区叫覆盖区,区域大小取覆盖段中最大的。
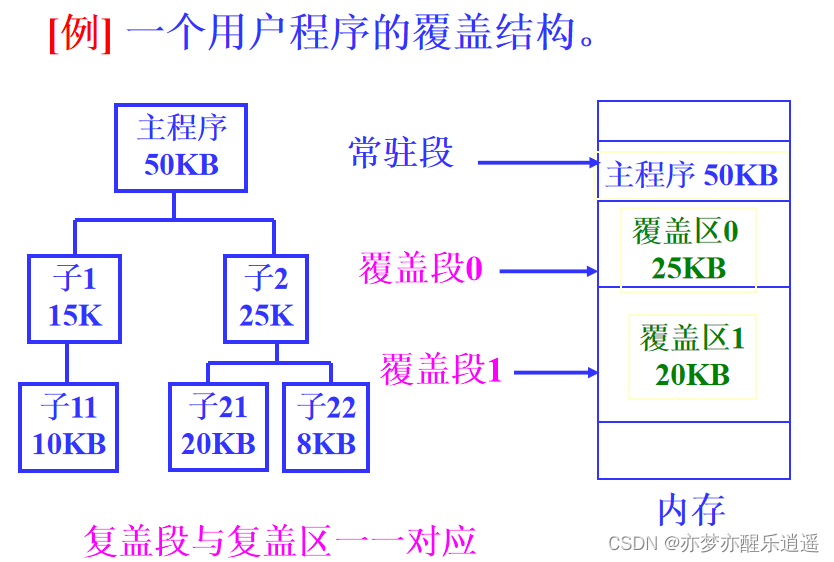
很明显,这种管理需要程序员提供覆盖结构。因为二进制指令不可能自动分析出覆盖结构。同时操作系统需要配套覆盖管理机制。
虽然可以在逻辑上扩充内存(实际上是压缩程序空间),但是执行起来很复杂,很影响开发和执行效率,以前用的多,现在不用了。
交换
虽然一次性运行不完,但是可以把需要运行的放在主存,用不到的先放外存,等需要的时候再换回来。
本质上,是允许程序运行到一半就可以从内存中临时撤出。
相当于用外存空间扩充内存,因为要频繁交换,所以这种情况下相当于牺牲了速度,换取大空间。
什么时候交换呢?就针对交换的目的说:
- 分时系统中时间片轮转的时候,或者阻塞的时候
- 进程需要的内存空间不够的时候
交换技术的缺点是开销大,解决如下:
- 减少交换次数,能不交换就不交换
- 减少交换信息量。将进程副本备份到外存,每次交换只交换更改部分。
因为交换区要频繁读写,而且不受用户控制,所以交换区肯定不能放用户文件,否则一不小心就被覆盖了,所以操作系统通常将外存分为文件区和交换区。
覆盖和交换的比较
其实交换也可以发生在进程内部,有时候离谱的程序一个你都放不下。
更多的时候,交换发生在进程间。

页式储存器管理
分区管理中,因为程序需要用连续的空间,导致必然会产生空间浪费,空间碎片。
而页式储存基本解决了这个问题。
实现原理
要实现非连续,可以将内存管理的粒度变细。
将内存切分,称作页框或者内存块,一块的大小一般为1K或4K之类,总之是2的整次幂。
把程序要用的内存切分,称作页,程序的一页空间对应主存中的页框,程序的一页空间可以随便放在任何一个页框中。
记录这个存放信息的,就是大名鼎鼎的页表,一个进程对应一个页表,存在内存中,分级管理(页表描述符表,页表)
左边一列是逻辑页号,右边一列是内存中的物理页号。从物理页号到页的物理始地址,只需要×一个页大小即可,比如页号2对应内存中2048的物理始地址。
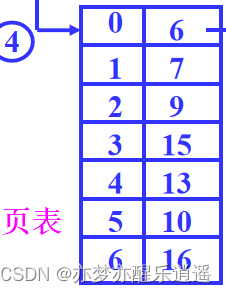
那程序如何通过逻辑地址去找物理地址呢?
首先在页表中,通过逻辑页号查找物理页号,然后物理页号×页大小获得内存的物理起始地址,最后加上页内地址的偏移即可。
页式动态地址变换
其实前面已经说了:
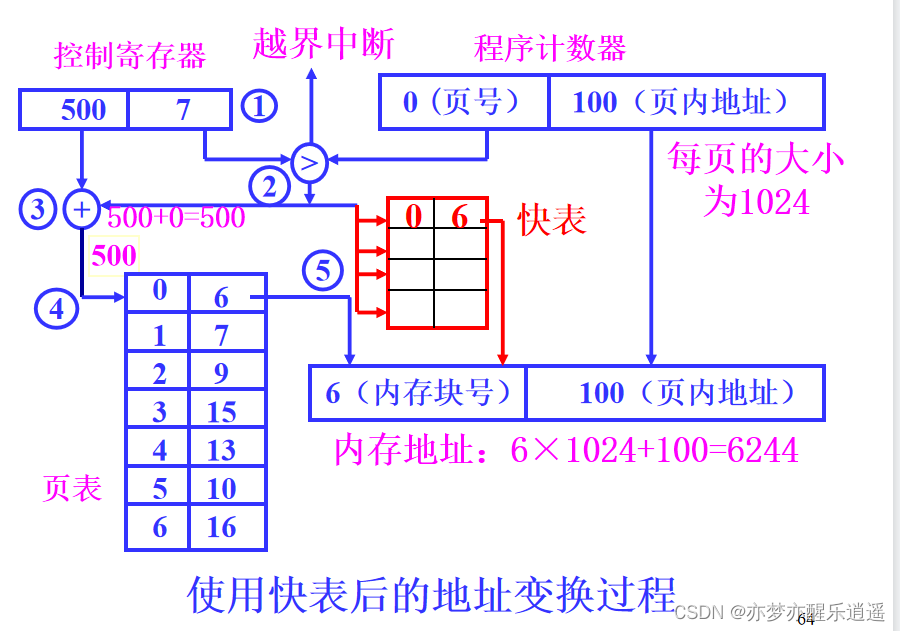
- 控制寄存器储存了当前程序,页表的起始地址和大小。
- 如果逻辑地址的页号大于页表大小,就会产生越界中断,如果正常则继续。
- 找到页表后,通过逻辑页号对应到物理页号,然后×页大小得到物理起始地址。
- 最后加上页内偏移得到物理地址。


上图只是简单的模型,实际上肯定是更复杂的,详见汇编:
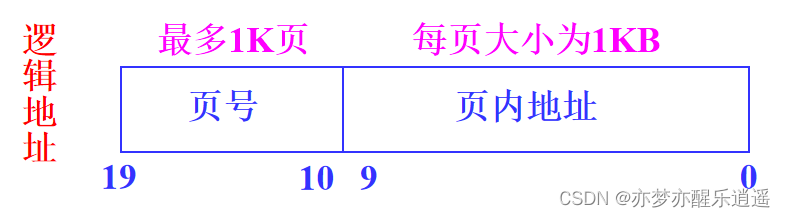
如下图,线性地址实际上有32位,10+10+12,中间的10位就是我们前面的10位页号,后面12位是前面说的页内偏移。为什么是12位呢?因为10位代表1K,12位是4K一页。

联想储存器与快表
联想储存器(TLB)
因为从逻辑地址到物理地址之间要多走一层页表,而页表在内存中,这会减慢访问速度。但是这一层访问是无法简化的,所以只能从储存介质上下手了。这就是缓冲的思想。
MMU中开一些寄存器(8-16个),专门储存最近访问过的局部页表,这些寄存器组构成了联想储存器(TLB, Translation Lookaside Buffer),从这里查找速度会很快,但是不一定能查到。
实际查找的时候,会并行查找,一边在内存中查,一边在TLB中查,如果TLB里面有,那就停止内存中的查找,如果TLB中没有,等内存中查完以后,会把这一项页描述符加入TLB中。
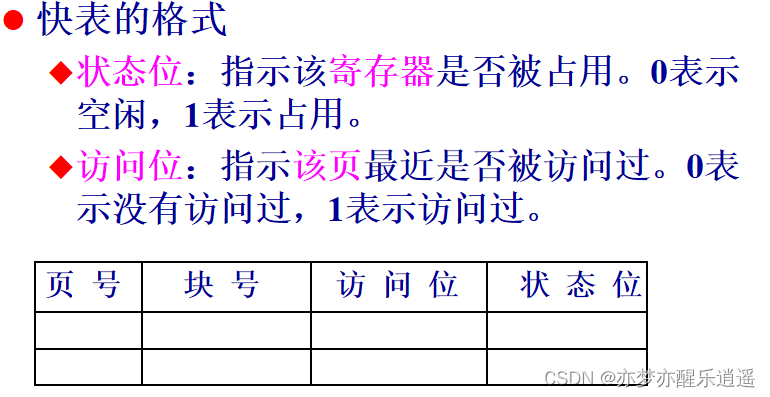
快表结构与写入
TLB只是一个储存器,具体存在其中是有一个数据结构的,即快表,上图也已经给出了快表。
除了页号(逻辑页号)和块号(物理页号),还多了访问位和状态位。
这两个位用于维护快表,因为TLB空间有限,所以新进来的条目覆盖哪一条旧的就由访问位和状态位决定。如果是空闲的,说明这里还没有条目,直接写入,如果没有空闲的,就找一个最近还没有被访问过的覆盖,维持快表活性。
页式管理宏观总结
从进程的级别来说,一个进程对应一个页表,但是页表不是存在PCB里面的,而是如前面给出的分级图,存在内存里。而PCB里只是储存页表的首地址与页长度,相当于页表指针。
空间分配管理
从操作系统级别来说,操作系统要知道主存中所有区域的内存使用情况,所以有储存分块表(采用了块储存后,之前的空闲区链表已经不用了):
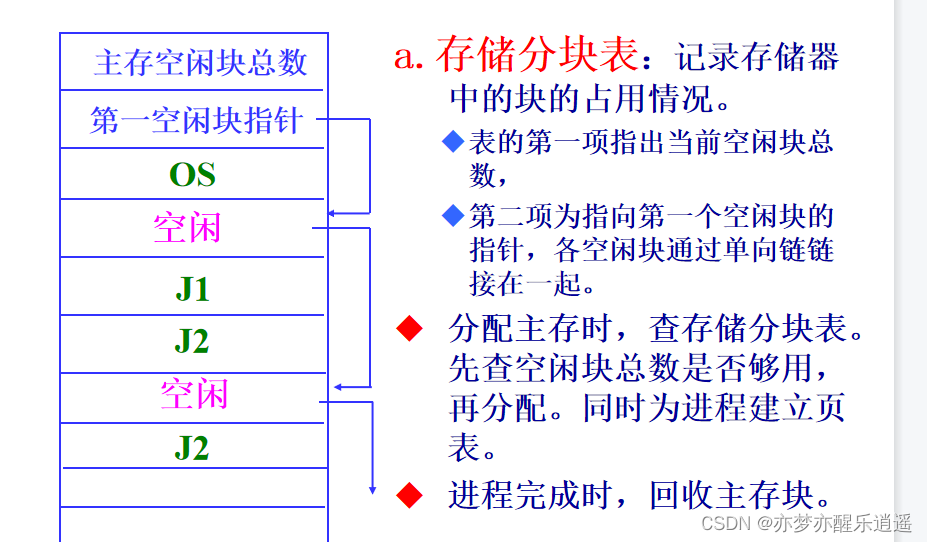
看起来很占空间,假设对一个块的描述用4字节储存,那4K的一页到分块表中就会抽象成4Byte的一个描述符,虽然缩小1K倍,但是仍然要占用很多内存,所以现在已经不用了
另一种方式是位示图,使用01来抽象储存分块表,主存不需要知道内存是被哪个进程占用,只需要直到内存中哪些地方被占用,哪些地方是空闲的。所以现在多用位示图。

储存器共享与保护
因为一个进程里面的程序数据是被一个进程掌控的,页是连续的,不论是代码,还是数据,都被打乱后变成了一维数据,所以如果不是本进程,要想共享页表里的对应页数据,是不容易的,就算一次性把页表都共享出去,也会有安全性的问题。所以后面会将进程内部的各种数据分类,产生了段,这就可以选择性共享了。
至于保护,就涉及到权限管理了,这些信息储存在描述符中。
段式储存器管理
书接上回,进程中所有的数据索引被一股脑放到了一个页表里,而且顺序完全是不受掌控的,各种类别也是混杂的。本质上来说,还是因为粒度太细了,应该进一步整合分类一下,这就是段。
当然,最开始是没想整合的,而是干脆把页换成段,取代了,但是后面发现可以结合,也就是我上面的思路(段页式管理)。
基本方法
在进程内部,将进程的空间切分为若干连续区域,每一个区域都是一段。这些区域由段表管理。这样可以实现一定程度上的内存切分,同时能实现段空间共享。
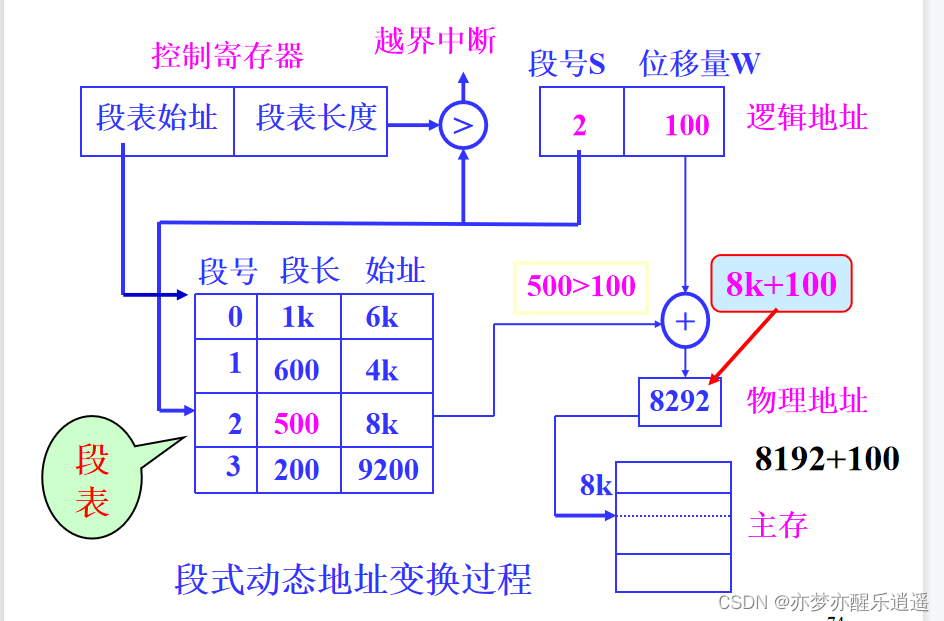
下图给出通过段号+段内偏移寻址的流程:
要判断两个越界,一是段号不能超过段表长度,而是段内偏移量不能超过段长。
除了长度检查外,还有权限检查,即在描述符中增加字段做优先级判断,这个在汇编里会学习。
因为每一段都有物理含义,所以一次性可以共享某个段而不是全部进程内存。
本质上来说,这个和可变式分区没太大区别。只不过,可变式分区是一个进程分配一个分区,但是段分配是一个进程的总分区被切分成n个可变式分区(段),从粒度上来说,比可变式分区要更细节(多加一层可变式分区),但是比页式储存还要粗,因为有一些段比4K大多了。
段页区别
关于(3),页是一维,可以理解为,一个进程的页逻辑上是顺序排列的,相当于一个整体,而段是吧一个进程的内存切分,这就是所谓的二维了。(然而呢,页和段只是切分粒度不同罢了)
关于(5),虽然段比可变式分区更加细化,但是仍然会产生稀碎的空间,毕竟根子上还是可变式分区。
关于(6),因为页式管理相当于一整块,所以没办法拆,也就没办法动态链接了。而段可以选择性拆出一些内容,其实动态链接本质上就是代码共享。

段页式管理
之前的方案,是把页表直接替换了,不再用页。实际上,有更好的方案,即把页表拆分成若干子页表,一个子页表对应一段,用一个段把相关的页整合起来。
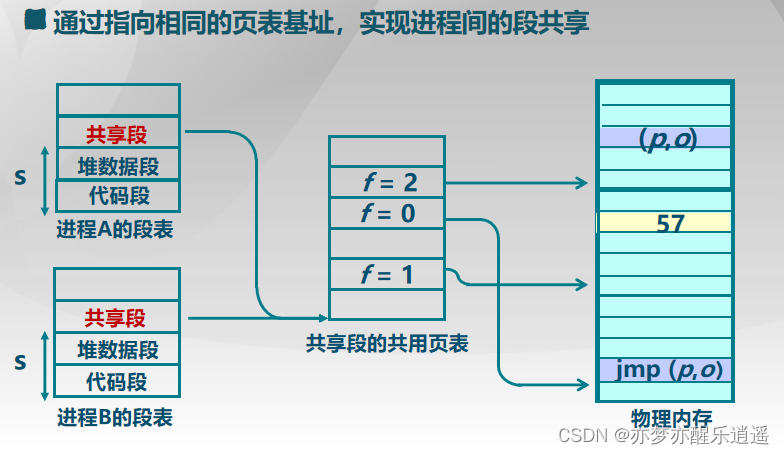
结合下图的逻辑地址进行解析,一个程序有一个段表其首地址在STBR寄存器中,用s区的位锁定段表中的一个段描述符,通过一个段描述符指向一个页表,通过p区的位从页表中找出一个页描述符,最后加上页内偏移o就可以锁定物理地址。
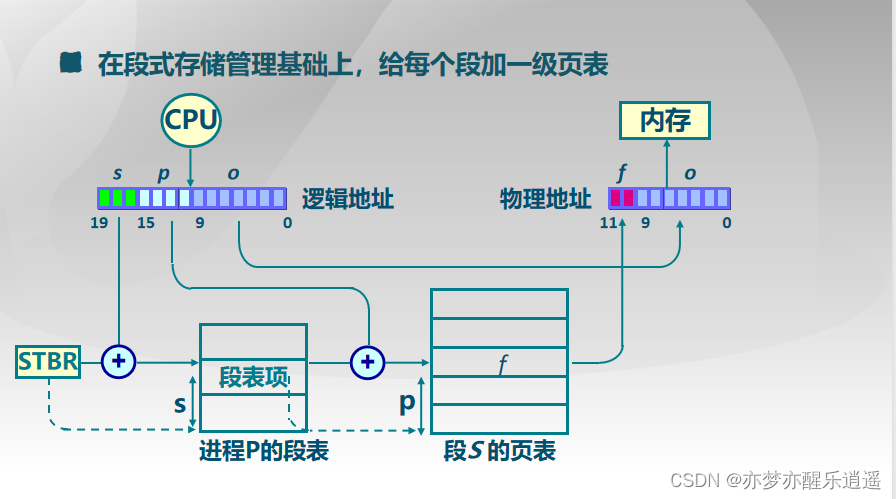
从这里可以看出,段页式管理结合了段和页,虽然一段在逻辑上是连续的,但是实际上是离散的,中间通过一个子页表来转换。
共享一段,就是指向一个段描述符(里面有页表基址)
虚拟储存器管理
基本原理
前面讲的都是物理内存技术,一个程序运行就需要把所有东西装入内存中,如果太多,就跑不了了。比如进程要用5G内存,结果内存只有4G,那就不可能跑通。
为了扩展内存,出现了虚拟内存,进程的一部分活跃内容装入内存,一部分休眠内容装入外存。随着进程推移,会进行内外存交换。
虚拟储存器
程序不知道物理内存多大,只知道操作系统给他的虚拟内存空间。这个空间由地址总线位数决定,如果32位,就是4G,64位就很恐怖了,远远超出物理内存,甚至远远超出外存空间。所以现在多用48位,去掉一些特殊位后有一个64TB的数字产生,和现在的大容量外存基本匹配。
程序访问的局部性原理——理论基础
局部性原理保证了,程序在一段时间内只会执行一部分代码,这支持了虚拟内存的发展。

这里给出一些经典的例子。这个例子中,int是4字节,×1024就是4K,一行正好占一页。
在循环执行过程中,如果是先行后列,每1024次操作就都是在一页内执行的,在这段时间内,程序只占用1页4K的区域。如果是先列后行,每1024次操作,都要分别在1024页中去找,那么就会同时占用4M区域,不仅内存占用多,而且消耗时间还特别多,这就是汇编中经常举的经典例子的原理。

虚拟储存的物质基础
最基础的,地址总线要宽(CPU地址结构要大),外存要大。
然后MMU中还要有支持地址转换的机制。
虚拟储存中的页式管理
实现原理
页式管理和实存方式基本相同。只不过要在页表方面要做一些改动。
一方面要增加页表项的位数,另一方面新设置外页表,用于辅助实现虚拟空间和外存的转换。
在进程运行过程中,会根据下面的调度策略来进行内外存交换。具体的交换规则,由页表中的辅助字段+算法来实现。

页表结构与策略

对于修改位,如果没有被修改过,那么占用这一页的时候就直接覆盖即可,但是修改过以后,占用前就得先将这一页写回外存。

缺页中断
这个概念经常被提起。
当进程通过一个指令操作一个内存空间,但是这个地方没有我们想要的东西的时候,说明这些东西在外存。缺页中断就在此时发生。之后系统从外存把要用的东西调到内存,这个指令就可以恢复了。
所以中断这个名字还是比较形象的,执行到一半被打断。
缺页中断处理过程就是交换的过程,同时要修改维护页表,位示图,与外页表。

页面置换算法
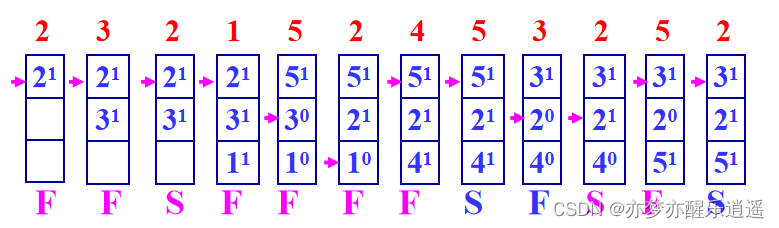
这四种算法的前提都是局部置换。一个经典的问题是抖动,抖动会极大地影响效率,会常常讨论。
做题须知:OPT算法是直接找到那个要换的页面当场置换。FIFO和LRU如果发生缺页中断会从上往下推一个位置。时钟置换算法是当场置换。

OPT的前提是已经知道页面访问顺序,之后就可以通过一个算法计算出优先级最低的页面,将其覆盖。优先级低的页面,要么是以后不访问的,要么是过很久才访问。一种简单的算法就是从当前时间往后寻找,如果过了很久才需要a页或者以后干脆就不用a页了,那就把a页替换掉。
很显然,OPT的前提不是那么容易满足的。

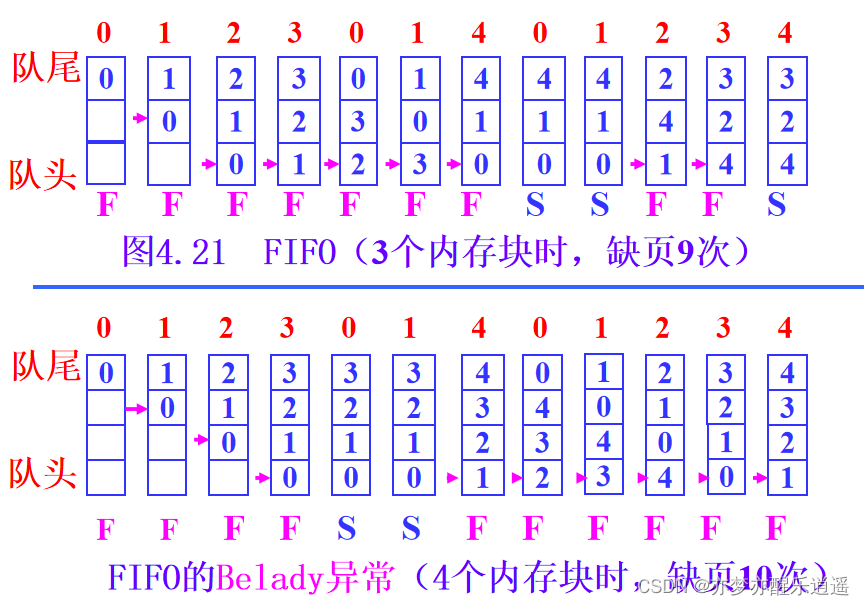
FIFO算法相当于OPT的弱化版本,不需要知道未来的访问路线,只需要通过已有的序列判断。如果一个页面进来很久了,那么很有可能已经用过了。但是也有可能一直在用,也有可能马上就要重新用了,你这个时候把这一块覆盖了,马上又要调入,所以容易发生抖动现象。

下图给出两个例子,第一个例子中有抖动现象,调用3的时候把0抹去,但是马上又要调用0,有点滑稽。第二个例子,明明增加了内存块,却导致了更强烈的抖动,反而缺页中断增加,表现出缺内存,这就是Belady异常。
为了解决抖动问题,需要重新认识一下问题的本质。一个页面是否重要,其实是取决于其使用频率的,所以计算频率比计算FIFO更加有效,可以解决部分抖动问题,至少那种频繁使用造成的抖动可以避免了,belady异常也可以避免。

具体来说,LRU利用栈记录页的使用。正在引用的页放在栈顶,最近最少使用的页放在栈底。为了便于栈中元素移动,可采用双向链。
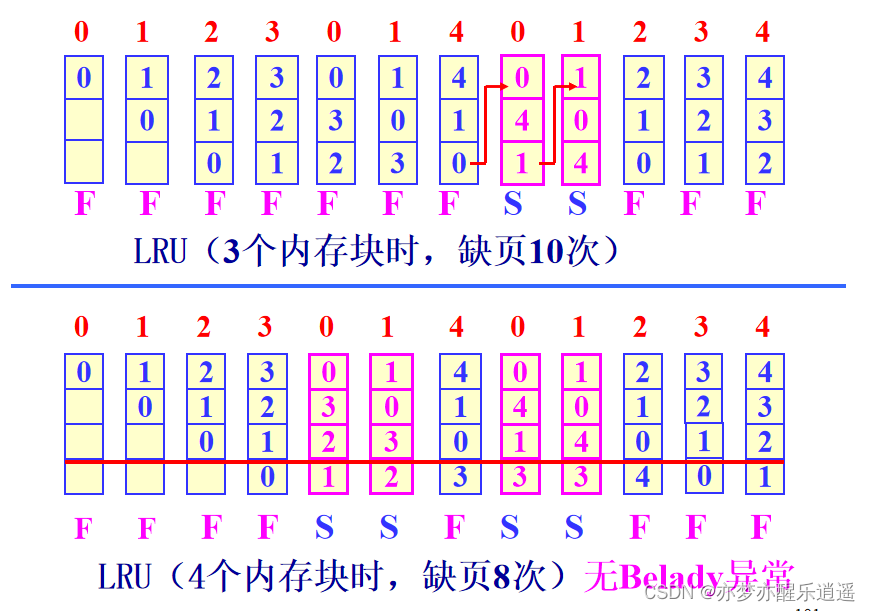
下图中,前面和FIFO一样,但是在中间0的时候,因为前面访问0和1次数比较多,虽然没有缺页中断,但是还是把0移回栈顶,保持高优先级,下面的1也是如此。
使用4个内存块的时候,缺页变成了8次,LRU算法中,0和1频繁访问,所以01被保持在了内存中,减少了抖动。从数据上来说,LRU可以避免belady问题,这里给出理论证明:
从下图可以看出,似乎4块的时候,把最后一层切掉,和3块是一样的,只不过4块的时候容量更大,可以防止频繁使用的页被挤出。那么既然增加块就一定可以进一步保护频繁使用的页,这就证明增加块一定可以减少缺页次数,这就从理论上消灭了belady异常(增加块但缺页增加)
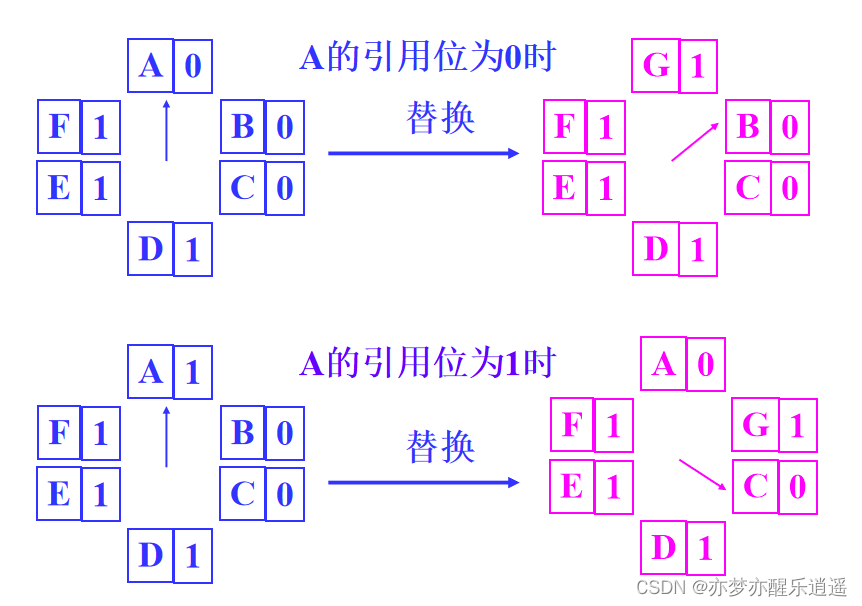
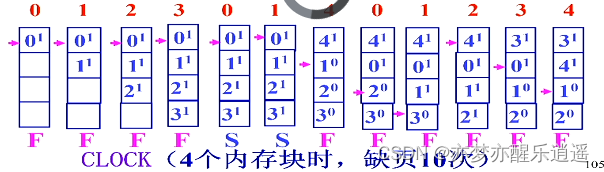
总的来说,时钟页面置换算法增加了引用位,0代表最近未被引用,1代表最近被引用。有点LRU的影子,因为如果淘汰的时候,为1的页面相当于有一次免死金牌,如果是0,那就去死吧。大体来说,就是把页面排成一圈(循环链表),然后用一个指针从最早访问页面开始,像时钟指针一样在链表里转,碰到1就置0跳过,0就淘汰替换成新页,置1。

下图给出例子,A是最早访问页面。
如果A是0,那就直接替换A为G。
如果A是1,跳过A置0,检查下一个B,是0,覆盖。
给一个更长的例子,可以发现,实际上是有两个指针的,一个指针指向最早访问,一个指针是临时指针,用于时钟遍历。
前4步,有空间,所以直接引入,最早访问是不变的。第5步的时候,需要进行遍历,从2开始,因为都是1,所以遍历指针走了一圈,全部置0后又回到了最早指针位置,去掉2,实现了一个FIFO。在去掉一个元素的时候,最早指针要移动一位。第6步,继续替换,最早指针移动。后面就都是这种逻辑了。
下面再给出块为4的例子(有点小bug),基本和这个类似,但是出现了belady异常。
这种异常是因为没有引入LRU机制,在LRU中,如果访问页已经存在,是会把这个页提到最前面的,但是在时钟算法中,如果一个页的引用位是0,访问一次后没有变化。如果在访问已有页的时候把引用位置1,就可以维持频繁访问页的优先级(见一次给一个免死金牌),这其实是在时钟算法中进一步增加LRU机制,相关研究很多,不再赘述。但是需要注意,这不是标准clock,考出来不能用。
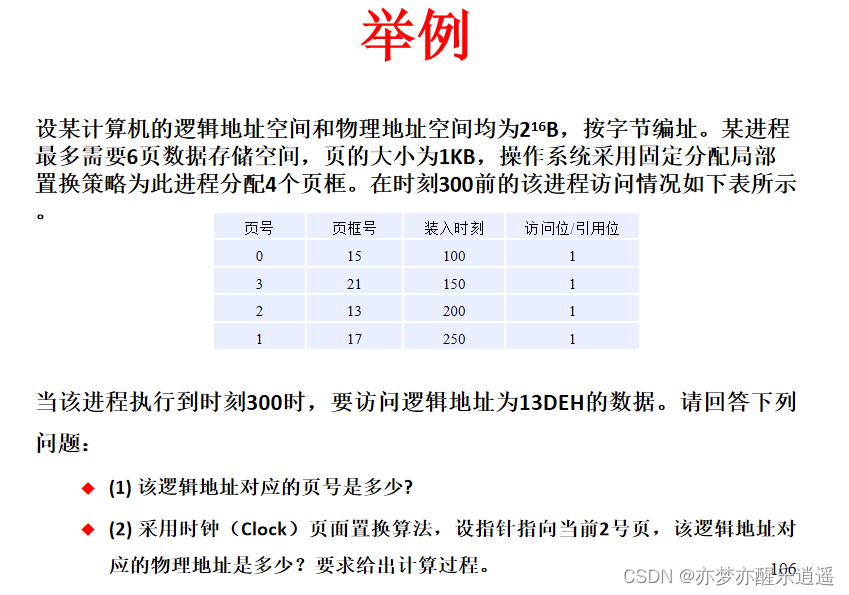
最后给出例子,13DEH,0001 0011 1101 1110,去掉后10位得到前面的数为00 0100 即4,发生缺页中断。
按照题意,最早指针指向2,所以经过缺页中断后,2号页变成了4号页,页框不变。
现在进行地址映射。将13页框,1101,前面补2个0得到001101,最后补上逻辑地址后半截,变成物理地址(其实这一步提前做也可以,反正缺页中断前后页框号是不变的)
页式管理设计的重点问题
- 交换区管理。linux中有swap分区,通过磁盘分区实现。windows不分区,通过一个页文件来实现。
- 页大小

- 页的共享。在段页式管理中,可以共享一段内存,即共享一个子页表。Windows下采用一个专用数据结构(原型页表)记录共享页,通过引用计数锁定共享页表。
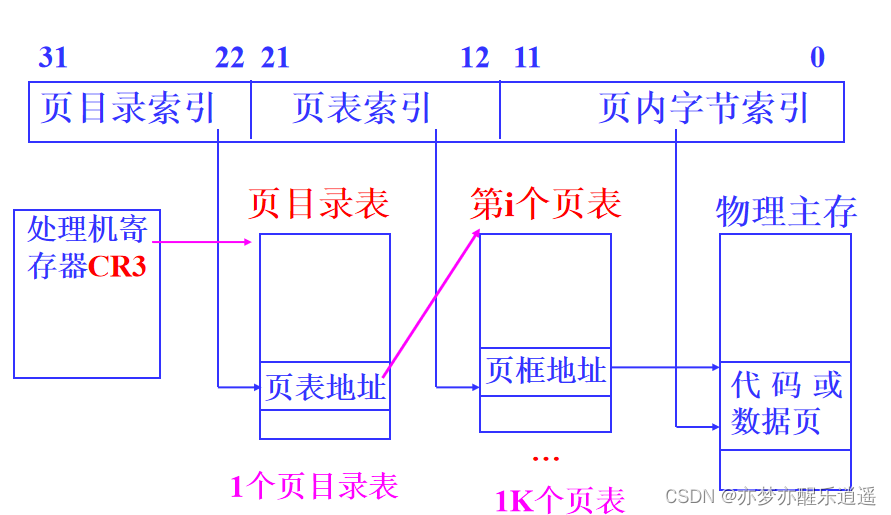
- 多级页表(计算要考,下面单独列出)。假如页很多,那一个页框肯定放不下一个大页表,所以要多级寻址。这个寻址结构详见汇编。
- 写时复制技术。不变就共享,要写(变)就独立。

最后,给出页框的计算(假设页框为4K大)。
当有1K个页的时候,就需要1K个页描述符,一个页描述符有32位4B的大小,所以这些页描述符构成一个4K的页表,正好塞满一个页框。也就是说,超过1K页的时候就要用二级索引了。
同理,一个页目录表最多放1K个页表描述符,所以一个页目录表最多对应1K×1K=1M个页,即1M×4K=4G的空间。
现在电脑不止4G了,但是对应的,地址总线也变成了64位,寄存器也会变,包括页大小之类的,但是总之,计算的思路就这么简单。
虚拟储存中的段式管理
段表与缺段中断
纯段式管理和纯页式管理类似,把所有段的副本都放在外存,把需要的段放入主存。
除了段基本信息以及辅助交换的三个位,段表还多了一个动态增长位:因为段理论上是可以变长的,所以如果这一位为1,如果发生越界中断,就会扩充段长。如果是0,那就不允许增长,发生越界中断。

缺段中断和缺页中断发生的时机一样,之后由操作系统完成缺段中断处理。但是因为段不定长,所以实际中段置换难度是比较大的。
动态链接
动态链接有两个方面:一是在生成二进制文件的时候可以节省空间,二是通过内存中共享一段来节省内存空间。

运行的时候,检查L位,L位为0,则只需要在内存中装入主程序段即可,当L=1,则触发链接中断,操作系统再从内存中寻找现成的段,没有就把动态链接段装入内存。

了解即可。
段的共享

虚拟储存中的段页式管理
现在的x86都是这种管理。
- 页式管理主存利用率高。
- 段式管理便于信息共享和存取保护。
- 段页式管理的基本思想:程序的逻辑结构按段划分,每段再按页划分。
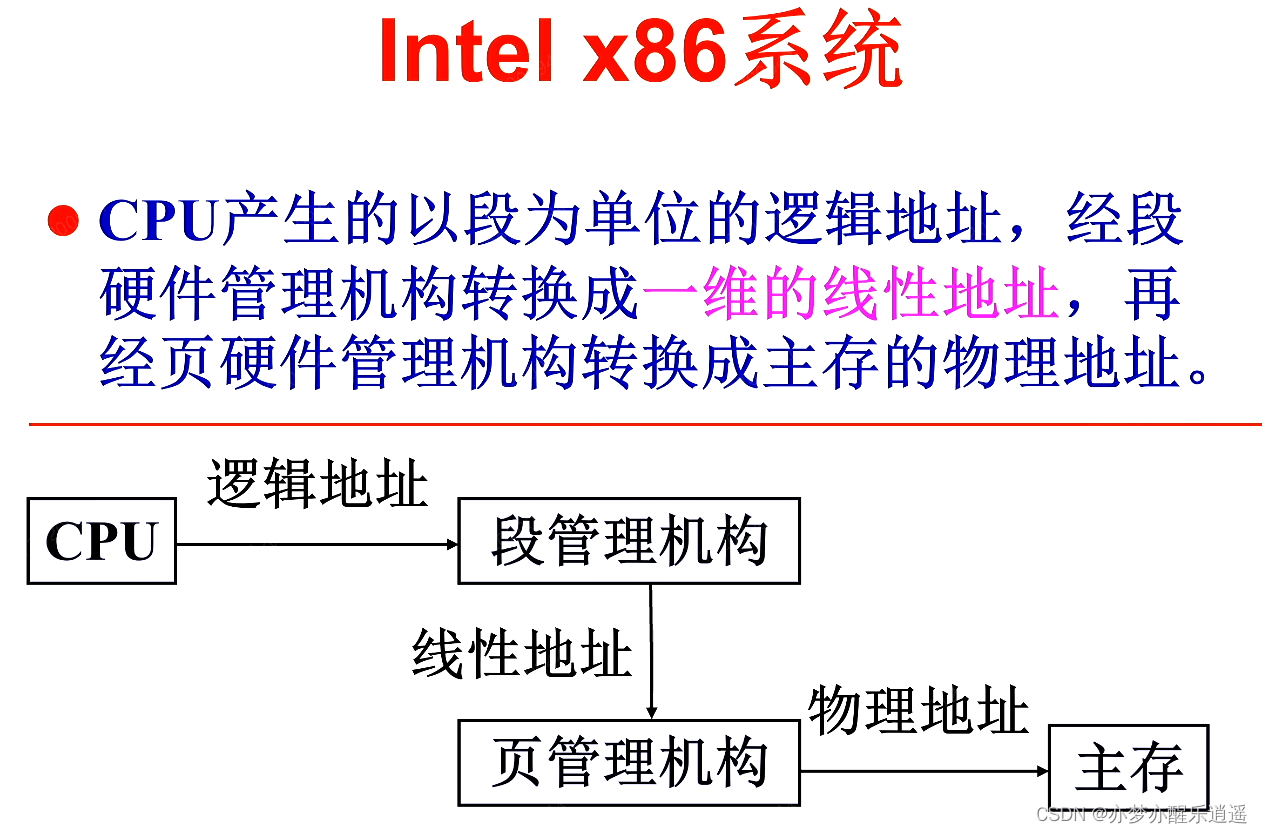
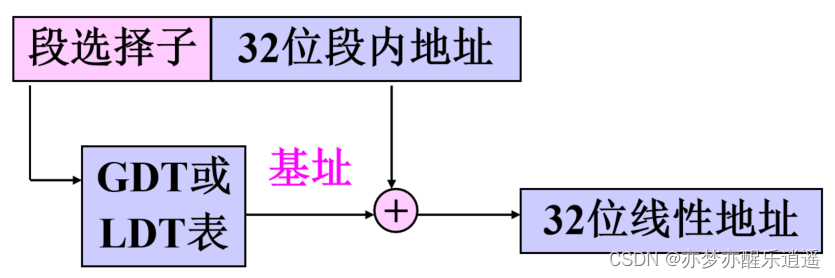
首先,段寄存器中有段选择子,同时另一个寄存器中有32位偏移量。把这两个丢给段管理机构进行段选,通过GDT,LDT之类的寻址,就可以得到64位的段描述符,其中,有32位的线性基址,加上32位偏移量,就可以得到32位线性地址。
把32位线性地址丢到分页部件里,进行两级页寻址,就可以得到最终的物理地址。
最后给出一个比较精细的流程图。
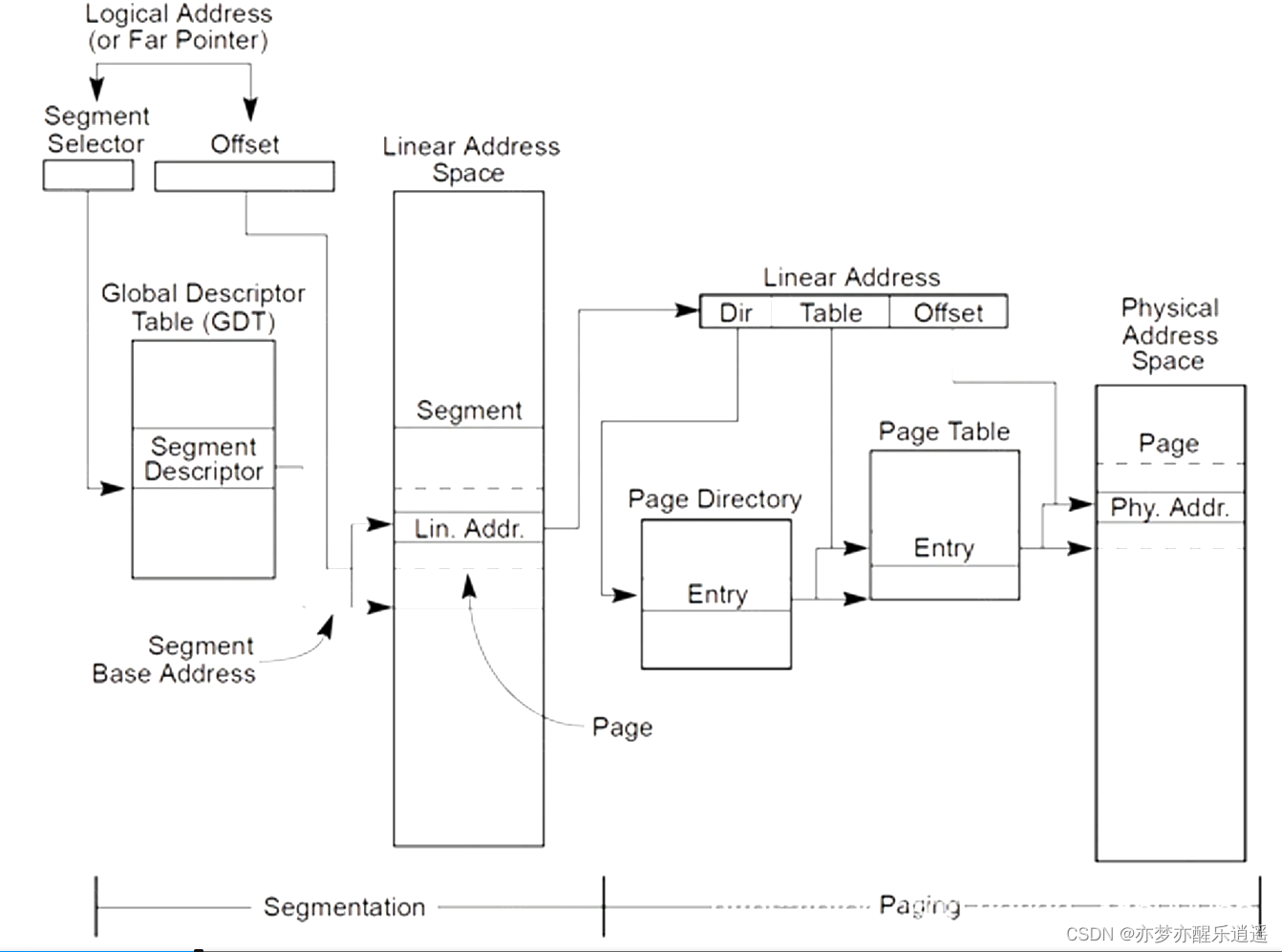
文件系统
文件和文件系统
文件管理块FCB
计算机就是信息的产物,文件是信息的载体,存在外存(磁盘)中,通过操作系统与用户交互。
狭义的文件是诸如一个源程序、目标程序、一批数据、各种语言的编译程序、各种编辑程序、银行的各种帐目、公司的各种记录之类的东西,广义的文件代表任何可以输出输入信息的个体,比如IO设备。
文件系统中,文件本身和文件的管理信息(元数据)是分离的,所以一个文件其实由两部分组成:文件体,文件控制块(FCB)。文件控制块包含了文件的说明信息和管理控制信息。如,文件名、文件标识、类型、存储位置、大小、保护方式、创建或修改日期等。
文件体由用户修改,而FCB记录文件的元数据,由操作系统管理。这些元数据都放在一个目录文件中,一个FCB相当于其中的一个描述符(32Byte,可以储存很多描述信息)

文件分类


从下面来看,目录本身就是文件,只不过比较特殊。而Unix特别文件其实就是广义的文件,而具体执行由操作系统进行转化。

文件系统
文件系统是os的部分,包括三部分:
- 操作系统软件
- 该软件用的数据结构
- 被该软件管理的文件
windows中最容易接触到的文件管理系统部件就是资源管理器,不过这只是文件系统的冰山一角罢了。从用户视角来说,文件系统的主要功能就是按照目录结构+名字的方式管理磁盘中的文件,从操作系统视角来说,功能很多:

文件目录结构
文件体在储存空间的摆放规则是比较散乱的,我们通过对其元数据的组织,实现逻辑上对文件体的组织。这就是文件目录结构,实际上个人感觉应该叫元数据组织结构。

一级目录结构
这是最简单的方式,所有描述符都丢在一张表里。缺点也很明显,你想找到这个文件,就得遍历一个大表,很慢。
二级目录结构
二级也好不到哪去,就是多了用户级。
多级目录结构
树状结构
现代操作系统都是用多级目录的,以树的结构管理。
- 完全路径名(绝对路径名):是由根到文件通路上所有目录与该文件的符号名拼接而成的。
- 当前目录(工作目录):用户根据自己的工作需要,在一定时间内,指定某个目录为当前目录。
- 相对路径:从当前目录出发的路径。
优点:便于管理,检索速度快,权限控制方便(比如根节点权限被子节点继承)
缺点:使用的时候需要逐层访问,会拖慢访问速度。不过明显利大于弊。
无环图结构与硬链接
纯树状结构不同分支之间不可共享,所以出现了有向无环图结构。
比如有两个节点,他们的名字不同,但是可以指向同一个文件。这种系统的构建,不允许出现环。具体的实现叫硬链接,可以看到,fileD和fileA是两个目录里的文件名,但是其都指向一个文件索引节点号(inode)。

软链接(符号链接)
windows不采用上面那种方法,而是用软链接:快捷方式。快捷方式指向一个源文件,而快捷方式本身只是存一个地址。
文件的逻辑结构和存取方法
逻辑结构是从用户角度出发的,与具体物理结构无关。相对的就是物理结构。文件系统就是在物理结构和逻辑结构之间建立映射。
文件存取方法有顺序和随机。结构也有两种:
- 无结构的,比如txt文件,可能就仅仅规定了个字符编码,甚至直接二进制文件。
- 有结构的,比如word,html,文件内部也是有组织结构的。

文件的物理结构和存储介质
文件的物理结构
- 物理块:物理结构以物理块为单位,真实的硬件是分扇区的,而这里所谓的物理结构,其实是还有一层抽象的。即:一个物理块里可能有多个扇区。
- 逻辑块。一个文件可以由多个物理块构成。

连续文件
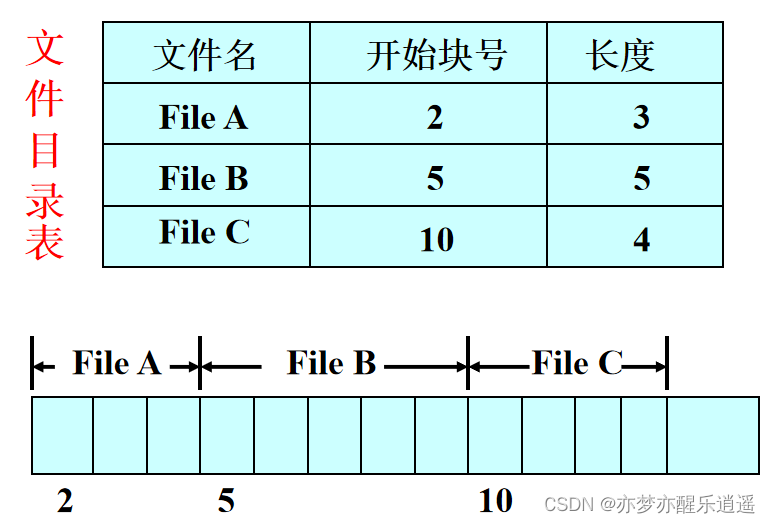
类似于内存中的连续存放,虽然很简单,访问页很方便,但是一来容易产生碎片,二来不便于动态扩展。
虽然用户用不了连续储存,但是系统文件是定长的,所以可以放系统文件(虽然后面都淘汰了)
链接文件
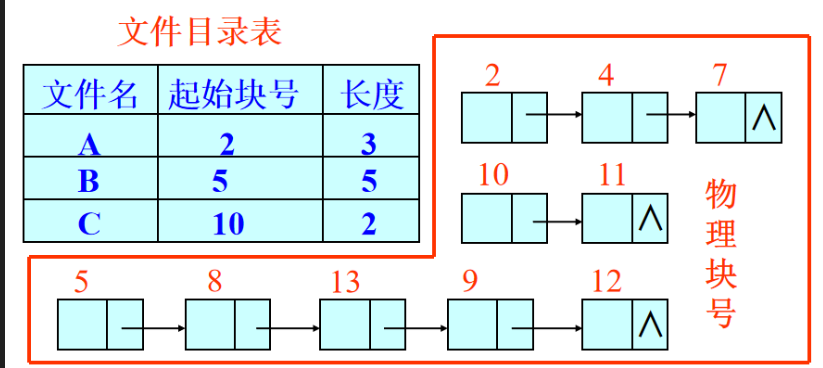
把一个文件的物理块用链表组织。目录表里,储存一个文件链表的起始块号,和链表长度。之后就去物理块中逐个读取即可。
之所以要逐个读取,是因为如果想要获取第二块的物理块号,就要先从磁盘中读取第一个块。同理,读取了第二块后才能知道第三块的块号。
也就是说,想读取第n块就要读取n次。
索引表——链接文件与索引文件的过渡
实际上,链接文件很明显是很慢的,要反复读取物理块,所以这些链表都是以数组(索引表)的方式存在内存中的的。
索引表中,下一个指针为0代表文件结束。一个索引表对应整个物理空间,即一个电脑只有一个索引表。

采用索引表后,将链表信息存在一张表,放在内存中,我可以在内存中一次性分析出要用哪些块,这就可以随机读取了。
很明显,一次性把一个电脑的表丢进去,对内存的负荷比较大,所以这种方法还要优化。一种思路就是,每次只加载一个文件的表进来,这就是后面的索引文件。


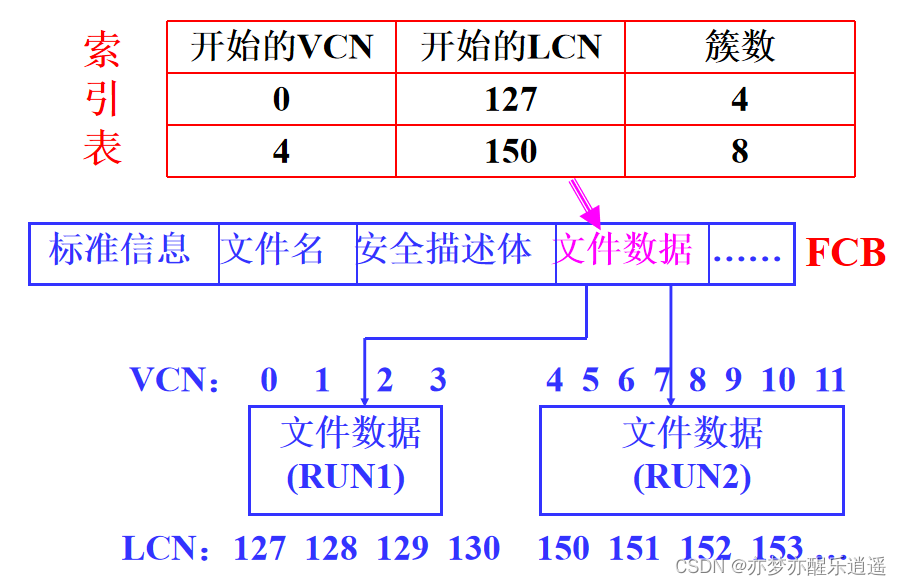
索引文件(重点复习)
这里就有点像内存管理了。为每一个文件建立一个索引表,一个索引表用一物理块储存。
访问的时候,先访问索引块,将文件对应的索引读入内存,然后再对文件的物理块进行随机存取。这种两次访问的速度慢一些,但是对内存的负担很小。
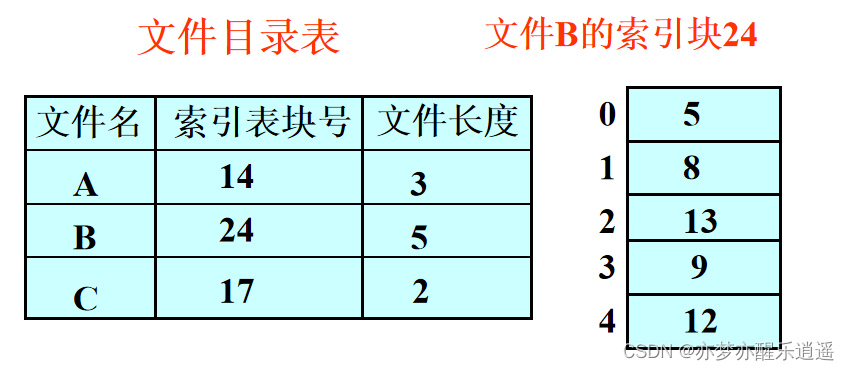
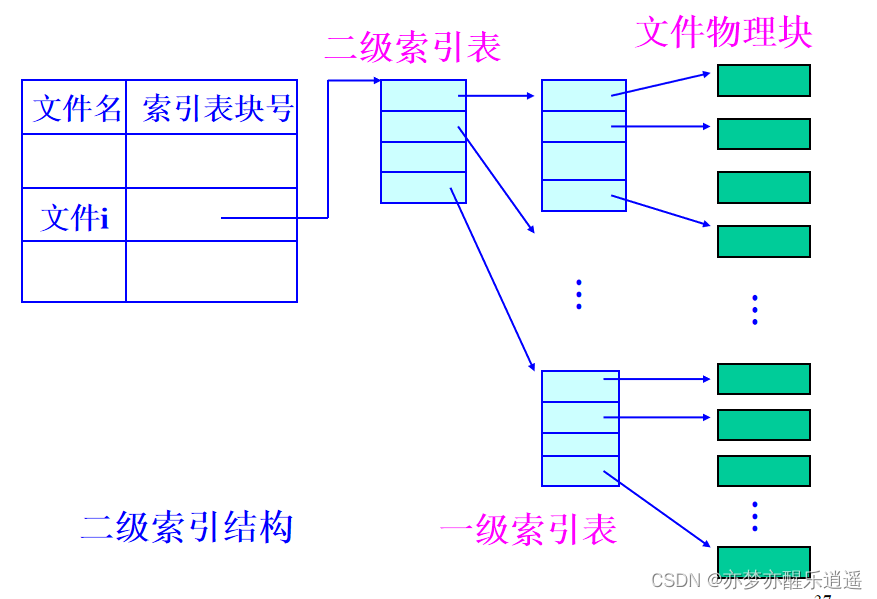
如果一个文件对应的块太多,那一个物理块是放不下其索引表的,所以出现了二级索引。而Linux多级索引(重点)

索引顺序文件
Windows的NTFS文件系统采用这个,这是个大杂烩。
因为有时候还是会出现物理块连续的情况的,所以索引文件可以压缩,这样,下面本来需要11行,现在只要2行:
文件的储存介质
磁盘的物理结构
磁带已经被淘汰,光盘可以随机存取,但是目前也不占主流,磁盘还是老大。
顺序结构为了防止碎片,干脆就用定长。链接和索引结构都是可变长的。但是链接结构不能随机读取,所以最常用的还是索引。

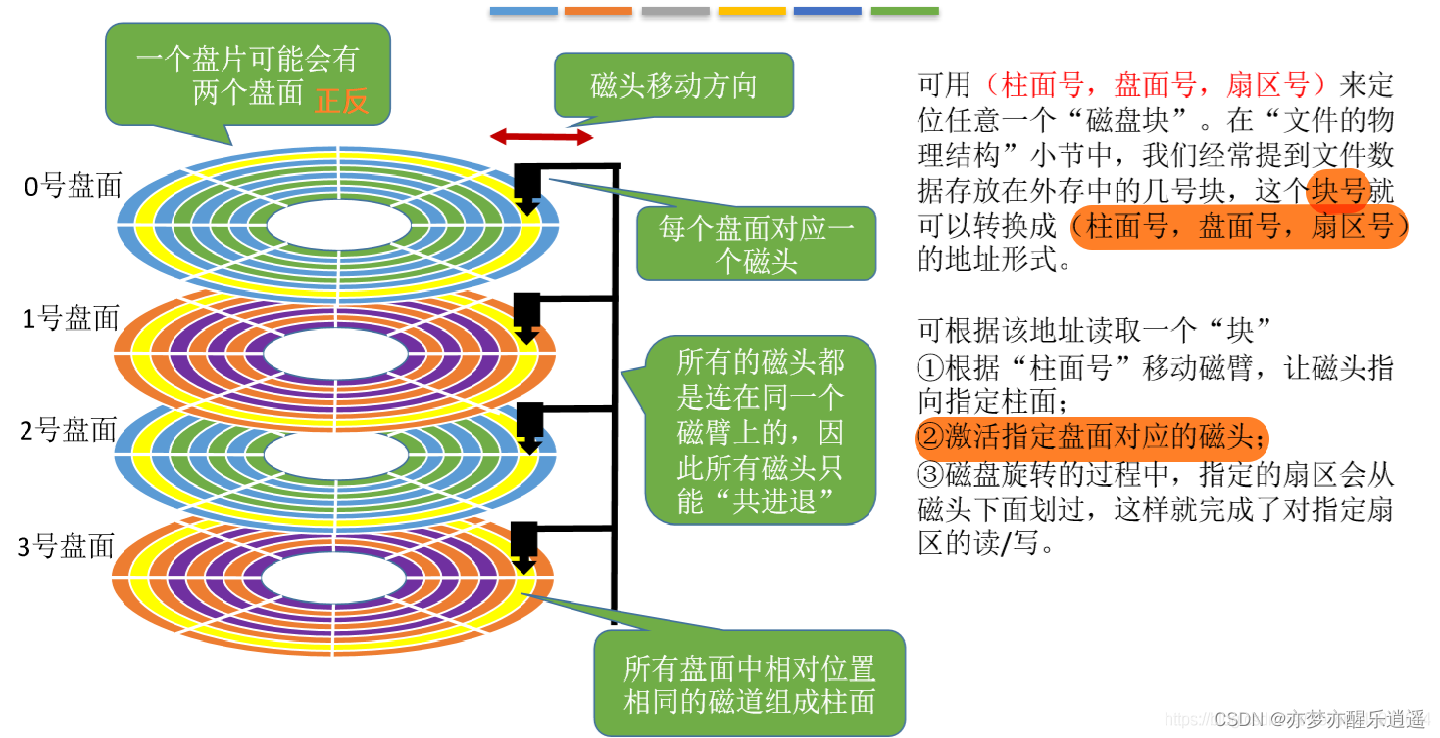
磁盘的基本储存单元是扇区。从最开始的n个磁盘盘面,到一个盘面上m条磁道,到一条磁道里的k个扇区,磁盘的定位有三级。
扇区有一点反常的特性:虽然外磁道的扇区比内磁道的扇区要大,但是两者的信息量是一样的,即可储存的空间是一样的,所以内磁道的信息密度要大。
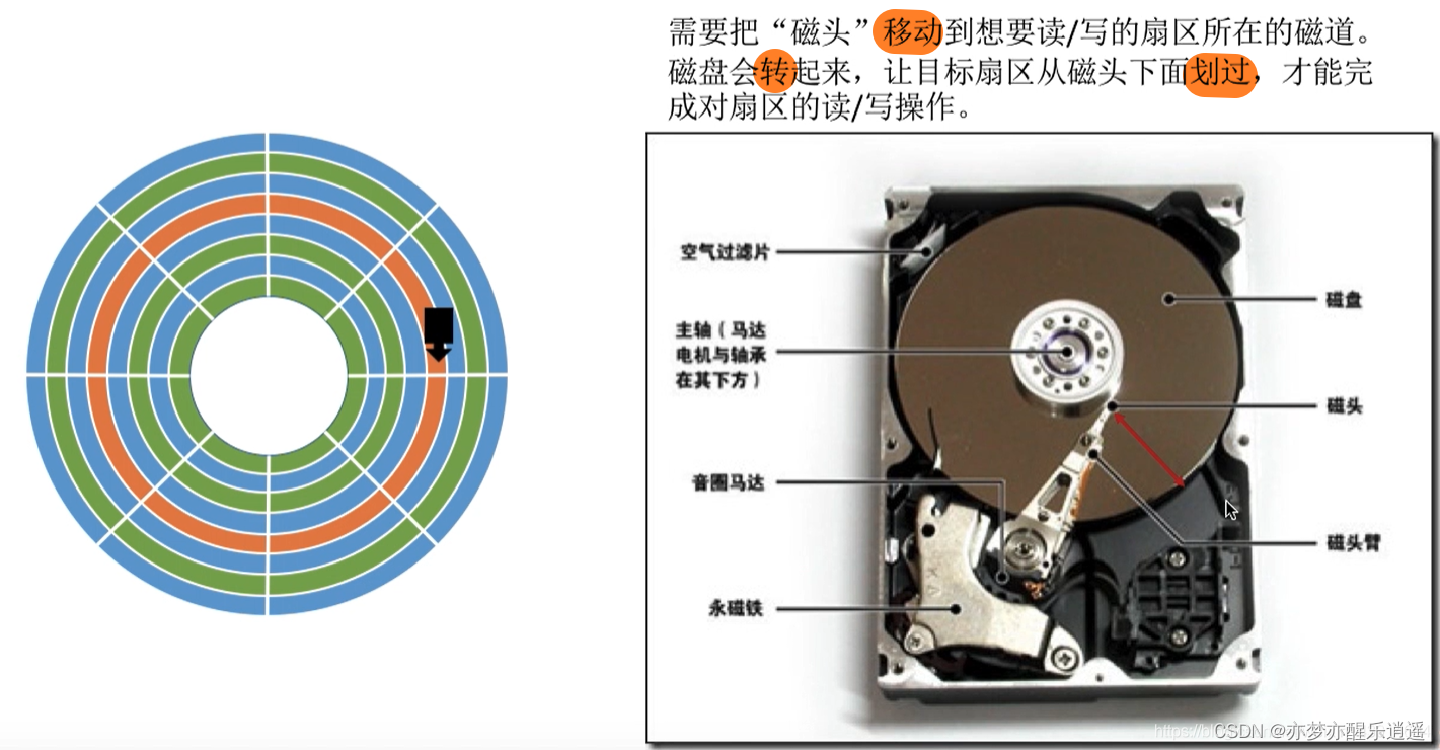
因为有多个盘面,所以会有多个磁头。这些磁头是垂直并列的,所以实际上当磁盘转起来,如果磁头不动,那同时可以读取的空间是一个柱面。很多时候都是用柱面区分的。
具体读写耗时:寻道时间,旋转延迟,读写。其实时间主要是花在寻道和旋转上了。
磁盘空间利用
从一块空盘到插到电脑里使用,中间要经过很多步骤:
首先要进行低级格式化,将物理空间划分为柱面,磁头,扇区。这是由厂家完成的,和我们平时说的格式化不是一个东西(我们那种格式化后就可以直接用了)
之后要进行分区。一个空盘,没有任何元数据组织空间,那是没法用的,所以需要在一个规定的区域储存磁盘元数据。这些元数据写在一个特殊的扇区:0柱面0磁头1扇区,占512B空间。这个扇区叫磁盘主引导扇区MBR(Main Boot Record)。分区的指令叫FDISK
确定分区后,使用FORMAT指
令对分区进行具体组织,制作文件系统。这一步是我们平常说的格式化,此时会指定是FAT还是NTFS。
MBR扇区
引导程序负责引出操作系统。硬盘分区表就是前面的分区数据。最后的有效表示作为验证。
- 硬盘主引导程序:位于该扇区的0-1BDH处。占446B。
- 硬盘分区表DPT:64B,位于1BEH-1FDH处,每个分区表项占用16B,共有4个分区表。16B意义如下:0为自举标志(80H为可引导分区,00H为不可引导分区);1-3是分区的起始地址(柱面号磁头号扇区号);4是分区类型(07H为NTFS分区);5-7是分区的结束地址;8-11是分区首扇区的绝对扇区号;12-15是分区占用的总扇区数。
- 主引导扇区的有效标志:位于1FEH-1FFH处,固定值为AA55H。
分区规范
- 主分区。可以放操作系统引导。
- 扩展分区。只能放数据。
- 逻辑分区。扩展分区可以区分为逻辑分区,就是我们所谓的D盘,C盘
总的来说,一个硬盘最多分4个区,可以是4个主分区,或者是3主1扩。一个扩展分区进一步分割,成为多个逻辑分区。
所以一个计算机,通常最多安装3个系统。留一个分区放数据。
文件记录的组块与分解
一个物理块可以存放若干个逻辑记录,一个逻辑记录可以存放在若干个物理块中。
记录的组块
当多个文件存在一个块中,这个过程叫组块(组合成块)。一个块中,逻辑记录的个数就叫做块因子。
因为IO是以块为单位的,所以要现在内存缓存区组块,再把块写入磁盘。
记录的分解
如果要读取一个很小的文件,需要先把一个物理块(包含多个文件)读取出来,再从其中取出目标的文件。
这就叫记录分解。
文件存储器存储空间的管理
管理磁盘有点像管理内存。
常用的对磁盘存储空间的管理方法:
- 空白文件目录(空闲块表法 ,是一种最简单的方法)
- 空闲块链表(进阶为空闲块成组链表)
- 位映像表(bit map)或位示图
UNIX系统采用空闲块成组链表
Windows的NTFS用“位图”记录卷上各簇的使用情况。P320
Linux的Ext2文件系统把磁盘块分为组,即块组,每组用“位图”来管理组内的磁盘块。P190
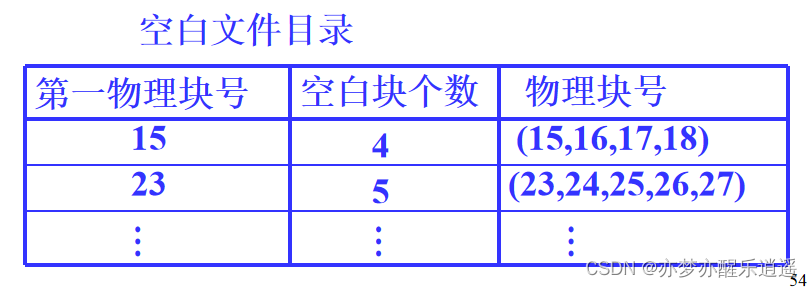
空白文件目录(顺序)
用表格储存空白文件。
从下图可以看出,这种管理适用于连续储存。
空闲块链表与成组链表
将空闲块用链表串起来(无序)。
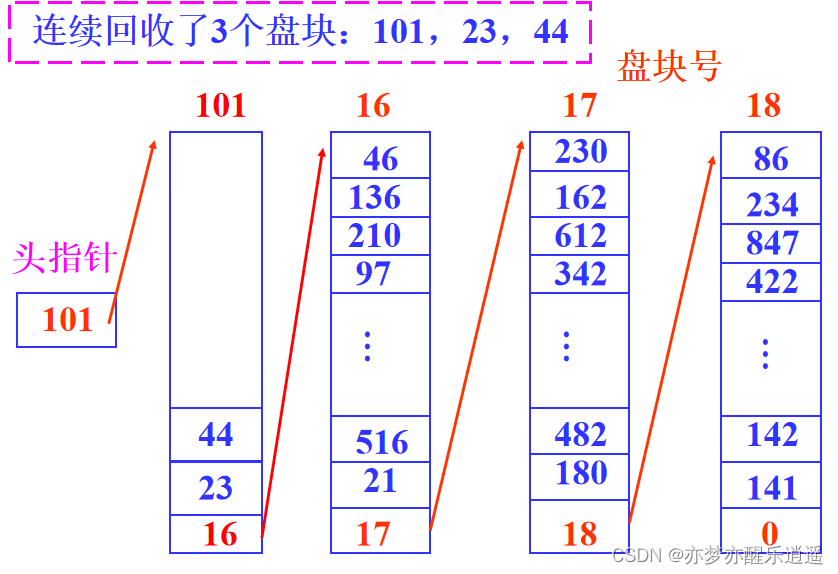
为了便于空闲块的分配与回收,将空闲块按组管理。一个组的标号都存在一个盘块中,利用盘空闲块来管理盘上的空闲块,每个磁盘块记录尽可能多的空闲块而成一组。各组之间用链指针链接在一起。
适合连续文件、链接文件和索引文件的存储分配。但是一般不存连续文件,因为链表本身是非连续存储的,所以比较麻烦。
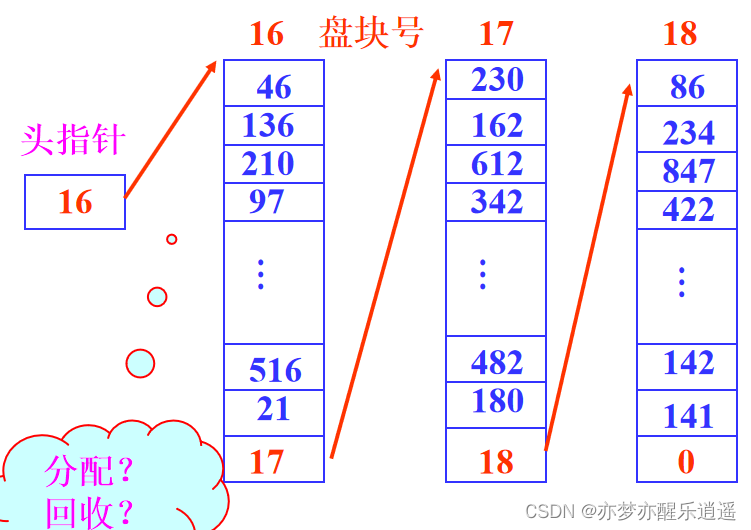
回收的时候,就通过头指针找一个有空间的盘块,将回收盘块标号丢进去。如果都满了,那么就用回收盘块中的一个盘块作为新的容器,放入空闲块成组链表中。
位映像表(位示图)
同内存的位示图。目前最好的方案。
[例] 一个10G的磁盘,每个盘块为4k字节时,它要求一个2.5M位的映像表,这个表需占用2.5M/8/4k = 80个盘块。
文件的共享与保护
共享

本质上来说,通过硬链接去寻找目标文件,是直接就找到了(机制不明 ),而通过软链接去找,需要从文件目录逐级寻找,所以软链接更慢。
保护
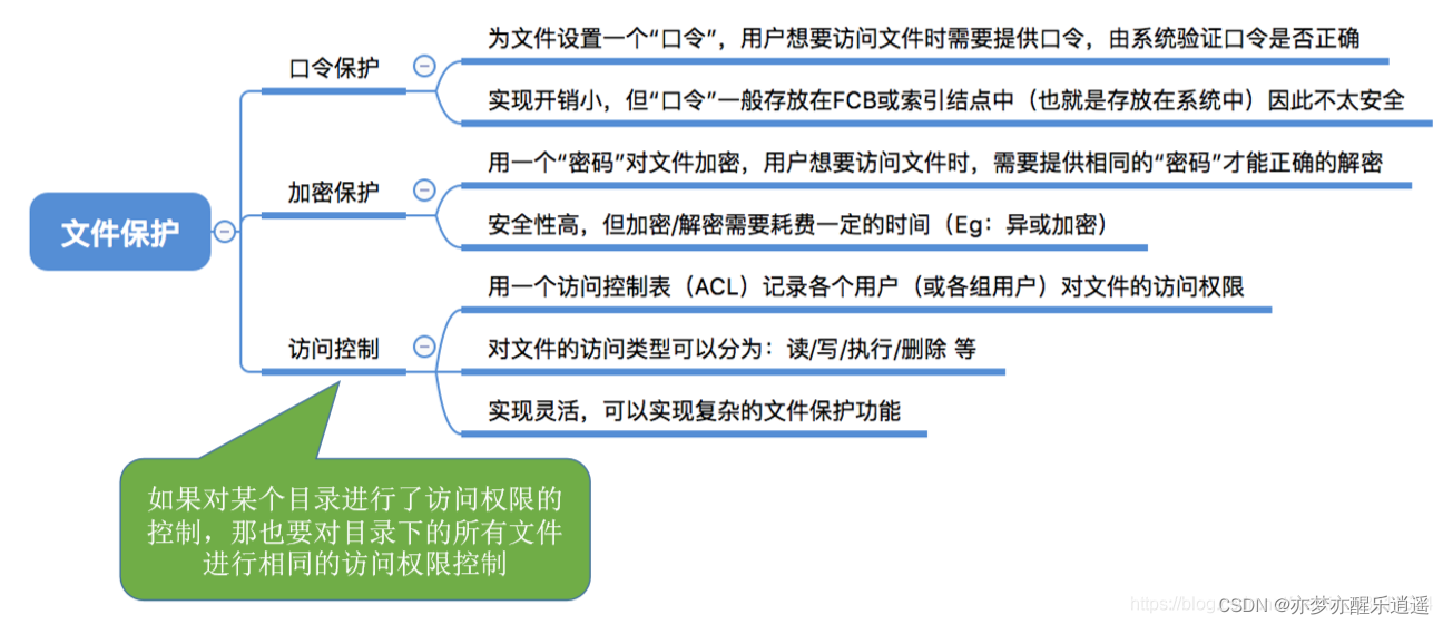
存取控制
存取控制是文件保护中常用的方式。
保护域
类似于数据库中的角色。
一个保护域包含了一系列权限。

可以为用户分配保护域,分配保护域后,用户就获取了保护域中的权限。上图中,第1域的权限比较少,第2域的权限很多。
存取控制表(ACL)
前文说到保护域,具体到储存结构,如何储存文件保护域呢?最简单的思路无非就是存取控制矩阵。但是那么稀疏,肯定不好用。
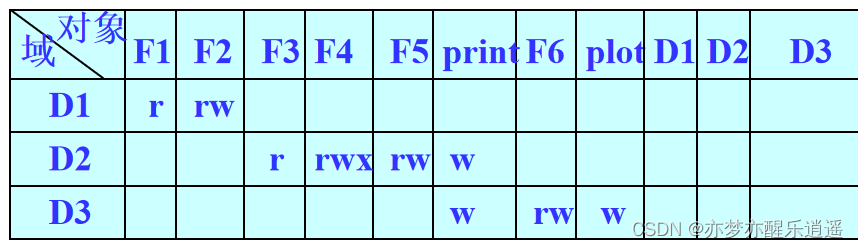
联想稀疏矩阵,实际上可以用另一种方式把这个稀疏矩阵存起来。即ACL表。稀疏矩阵应该是3维的<保护域,文件,权限>
我们将文件这一维度抽取出来,一个文件为其分配一个ACL表,表中储存了,哪些域可以对其进行哪些操作:

权限码
具体到现在的操作系统,一般的域就三个:拥有者,同组成员,其他成员。
正因为域往往是固定的,所以干脆就用定长方案制定ACL表,即采用3×3=9位数据储存一个文件的权限。
比如111 101 001,其权限就是751,而我们最常用的写法是777,即111 111 111,代表所有人都有最高权限(懒人写法)
文件的操作命令
略
文件系统的组织结构
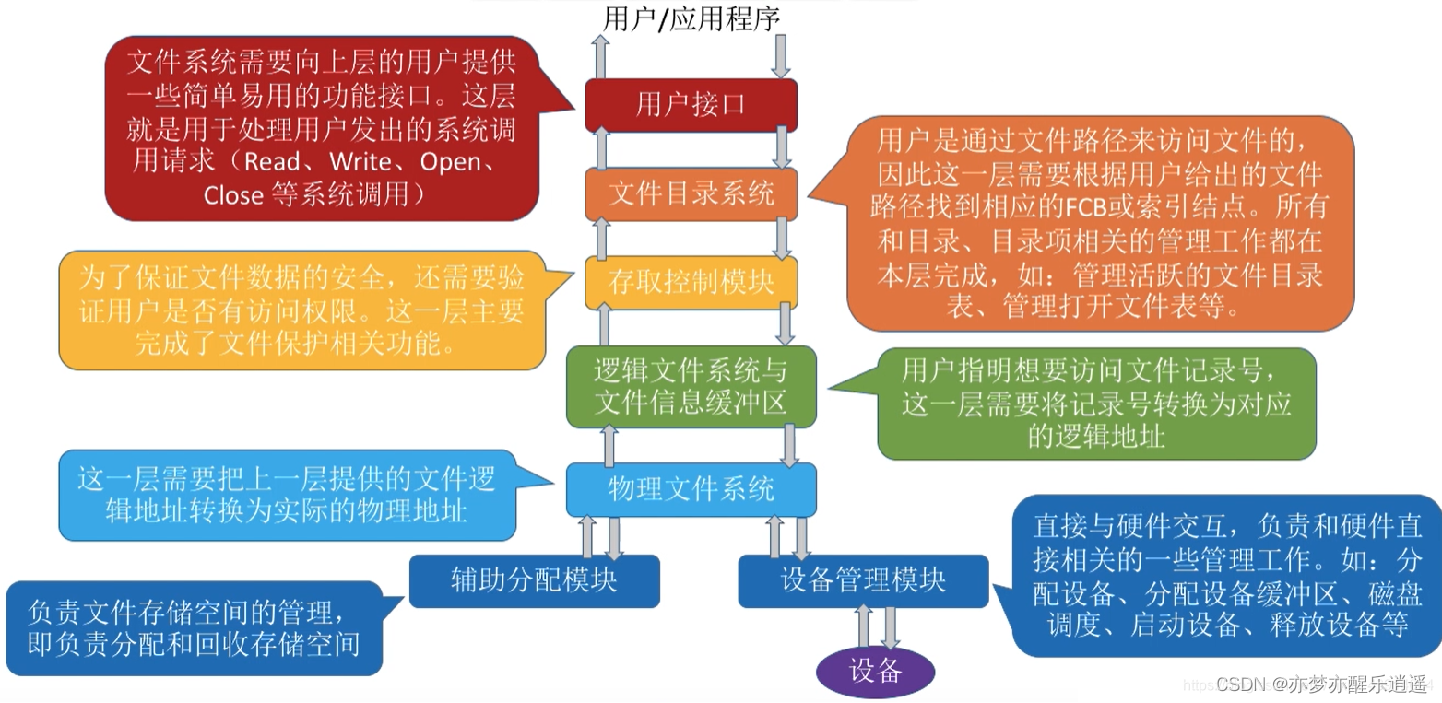
文件系统建立用户与硬件之间的桥梁,分层设计。
实际上的分层略有不同,大致类似:
- 用户进行宏观操作
- 通过目录系统查找目录,找到文件记录
- 权限检查
- 通过目录获得逻辑地址
- 将逻辑地址转换为物理地址
- 执行IO,同时辅助模块分配/回收空间

存储器映射文件
通过文件系统读写实际上比较慢,对于一些文件,可以通过储存器映射文件加快读写效率。
机制就是,跳过文件系统,结合交换技术,直接对虚拟内存进行操作,等同于通过内存直接操作文件。
其实进程之间也可以通过普通文件,比如txt文件来实现通信,但是相比于文件映射,慢很多,因为要走文件系统,而文件映射是直接操作的。
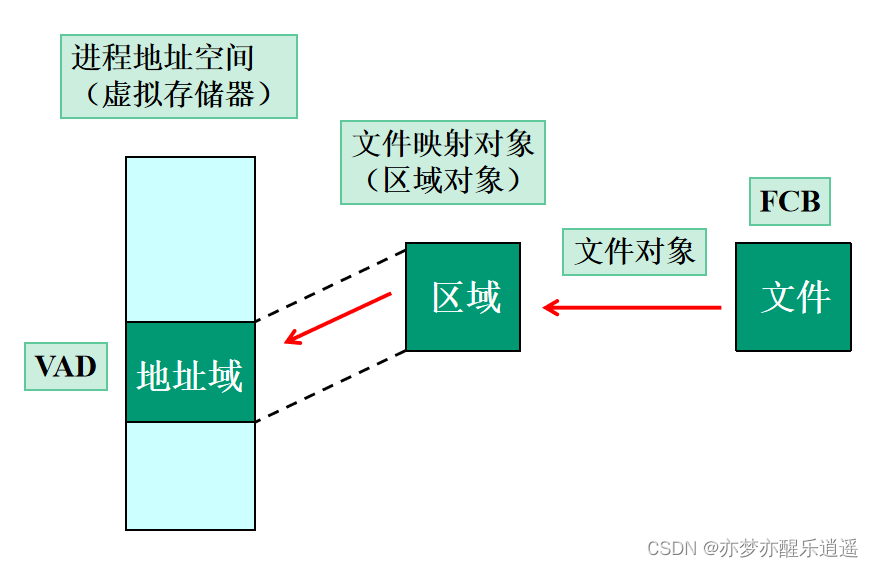
这个文件区域对象比较特殊,储存位置我不清楚,应该是介于内外存之间的动态对象(老师说的)
但是MapViewOfFile操作是真正地把映像放到了内存视图中。

例题
课后5-9:位示图/自由块链表空间计算

盘空间用D位表示,即用D位去描述盘块编号,也就是说储存一个盘块的位置要用D位。
一磁盘有B个盘块,用位图表示要使用B位。现有F个自由块,若表示一个盘块需用D位。则采用链表接连F个盘块,需要F个链指针,共占FD位。使用自由块链表比使用位示图占用更少的空间的条件是FD<B。
当D=16时,满足条件的自由空间占整个空间的百分比为:F/B<1/16=6.25%。
课后5-10:读盘块速度计算

这里注意,类似于快表,这里的缓冲机制和直接寻找也是并行的。
n×1+(1-n)×40=40-39n
课后5-13:链接方式的逻辑地址转物理地址

10个记录,放5个块,即一个块放两个记录。
访问1574字节数据,对应第7个记录,对应第4个块,从链接文件里看,对应物理块号4。应访问4号块内的第38个字节。
链接文件的指针在物理块内,所以是顺序读取,n个逻辑块要读取n次,所以要访问4次磁盘才能将该字节的内容读出。
课后5-14:多级目录读取与文件打开(坑)

共需要4次磁盘操作。
- 首先要用4次读取获取os的目录。根目录已经有缓冲,读取user的目录,读取lim的目录,读取course的目录,读取os的目录,这四次读取就可以确定result.txt文件的磁盘块位置。
- 进一步不需要读取了。这里有个坑,打开和读取是不一样的,打开仅仅是在进程中创建一个file对象,指定一个dentry对象,并不需要读取物理块。读取文件才需要进行磁盘读取。
课后5-15:多级索引占用空间计算

其实假定一个索引项占2B是可有可无的。因为空间是1G,所以可以分成 2 30 16 K B = 2 16 \dfrac{2^{30}}{16KB}=2^{16} 16KB230=216块,也就是说,物理块空间可以用16位(2B)的长度的索引去编码。
- 10KB<16KB, 所以,只占用1个磁盘块。
- 1089KB/16KB=69 需一个索引块和69个数据块,共70个盘块。
- 129MB/16KB=8256 , 16KB/2B=8K(个索引项)<8256。一级索引装不下。
- 所以首先需要一个二级索引表,占用1块。
- 然后需要两个一级索引表,占用2块。
- 最后需要8256个块储存数据。
总计:(1)+(1+69)+(1+2+8256)块。
IO设备管理
设备管理负责计算机对物理设备的操作,此前的文件系统,只是一个桥梁,设备管理才是负责真正的操作硬件(当然也不是直接操作,而是通过诸如驱动之类的东西,但是很底层就是了)。
IO设备多种多样,设备管理存在的意义就是统一IO接口,指定统一的操作方式。
IO硬件组成
IO设备分类
- 字符设备:人机交互设备,传递简单的信息。是以字符为单位发送和接收数据的,通信速度比较慢。键盘和传统显示器、鼠标、扫描仪、打印机、绘图仪等。
- 块设备:外部存储器,传递大量复杂信息。以块为单位传输数据。常见块尺寸:512B~32KB。如磁盘、磁带、光盘等。
- 网络通信设备:主要用于与远程设备的通信。传输速度比字符设备快,比块设备慢。如网卡、调制解调器,蓝牙,WLAN等。
- 机器内置设备。比如时钟,按预先规定好的时间间隔产生中断。
设备控制器
I/O设备一般由机械和电子两部分组成。机械部分是设备本身。电子部分叫做设备控制器。
设备控制器是电子器件,处于CPU和I/O设备之间,接收从CPU发来的命令,控制I/O设备工作。
每个控制器有几个寄存器,与CPU直连,用来与CPU通信。
- 控制寄存器:接收CPU发送的读写命令。
- 状态寄存器:包含设备的状态信息。
- 数据缓冲寄存器:通常为1B至4B。
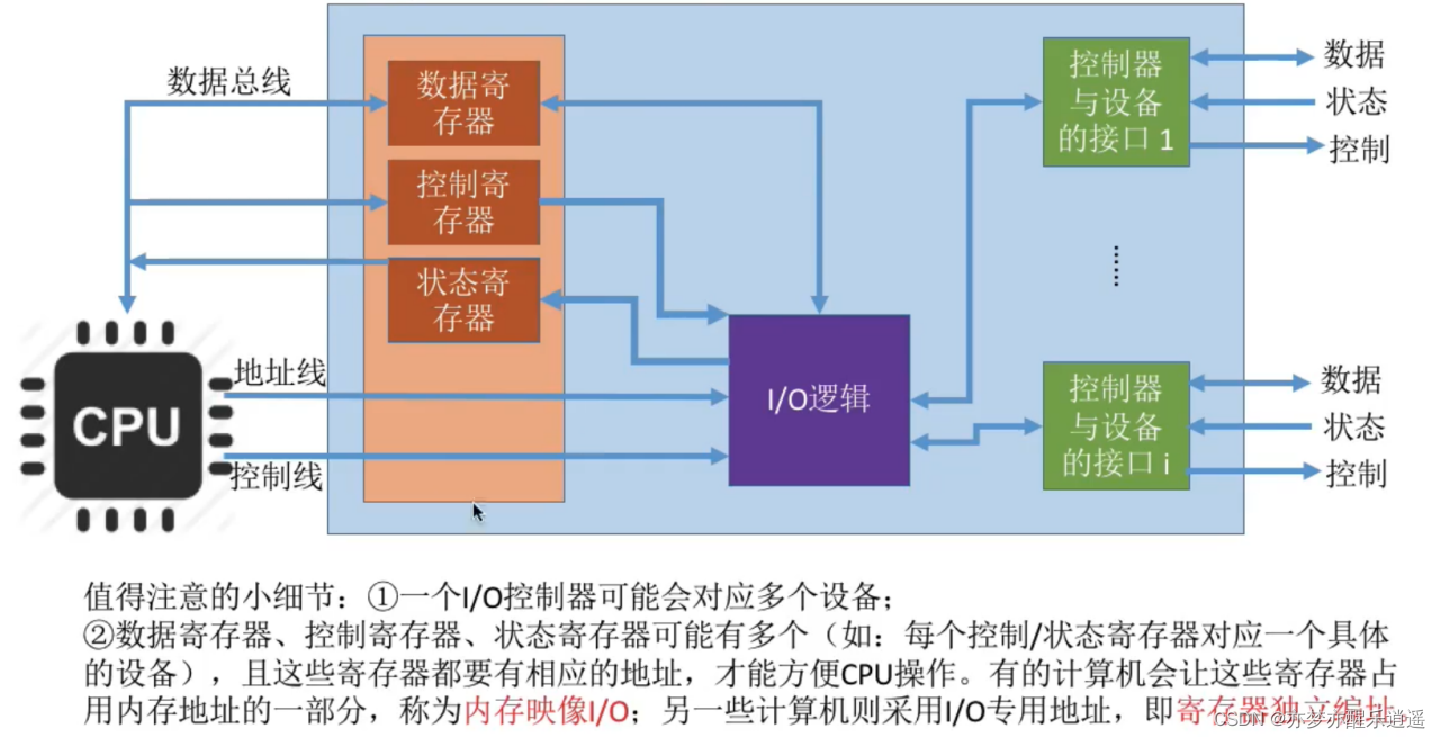
一种方式就是给寄存器独立编制,但是一般来说,内存映像IO更通用,比如汇编里面指定PORT端口后进行IO操作。
经典的设备控制器有两种:DMA(Direct)控制器和磁盘控制器
- DMA控制器是直接访问,速度快。
- 磁盘控制器通过数据缓冲区工作。从磁盘驱动器出来的是一连串的位流,控制器把串行的位流组装为字节,存入控制器内部的数据缓冲区中,形成以字节为单位的块。对块验证后,再一次一个字节地存入内存。
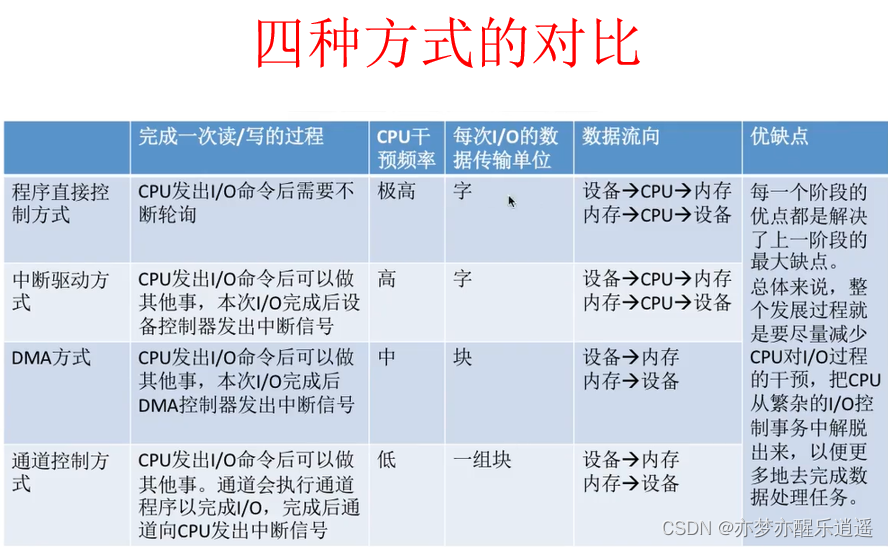
IO控制方式
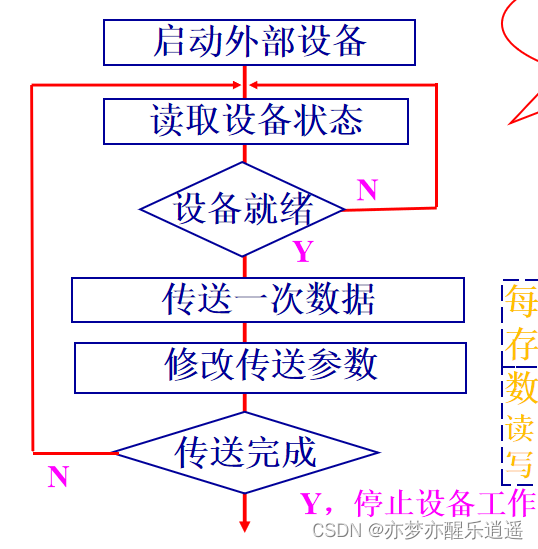
程序查询方式(polling)
这种是通过CPU完成IO。
数据的流向:
读:设备-》CPU-》内存
写:内存-》CPU-》设备
cpu用两个循环,一个不断查询设备状态如果设备就绪(数据寄存器满了)就往下走,另一个确认传送是否完成,完成了就停止设备。
很明显,这样效率比较低,如果能有信号机制就好了。
中断方式
CPU发出IO指令后就去干别的了,等设备准备好以后(比如数据寄存器满了),会发送一个数据产生中断,通知CPU可以执行了。
这样的缺点是,每次只能通过寄存器传,每次只能传一个寄存器那么大的空间,还是慢。

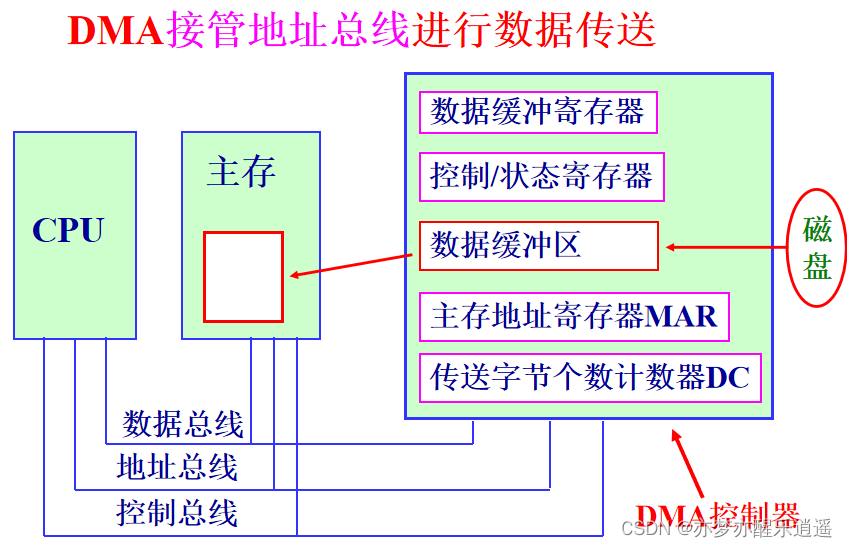
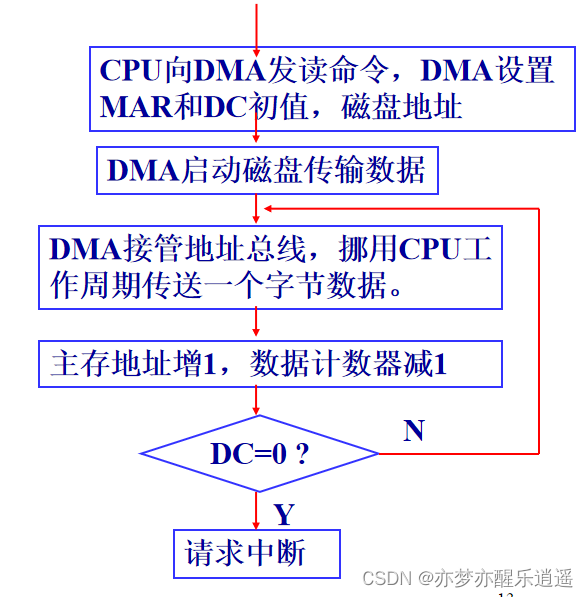
直接存储器访问(DMA)方式
- CPU规划好空间和磁盘地址后,通知DMA传输数据
- DMA接管地址总线,挪用CPU时钟(与CPU交错使用地址总线),开始工作,CPU干别的去。
- DMA传输完成,发送中断通知CPU
传输一个块的全过程只需要CPU参与两次,解放了CPU。一整个文件可能也用不了多少次CPU。
挪用CPU时钟虽然会拖慢CPU,但是比让CPU去进行操作与计算还是快很多。
通道控制方式
DMA同一时间只能控制一个IO。
通道是一种专用的IO处理器,有自己的指令系统,可以对多个IO进行操作。
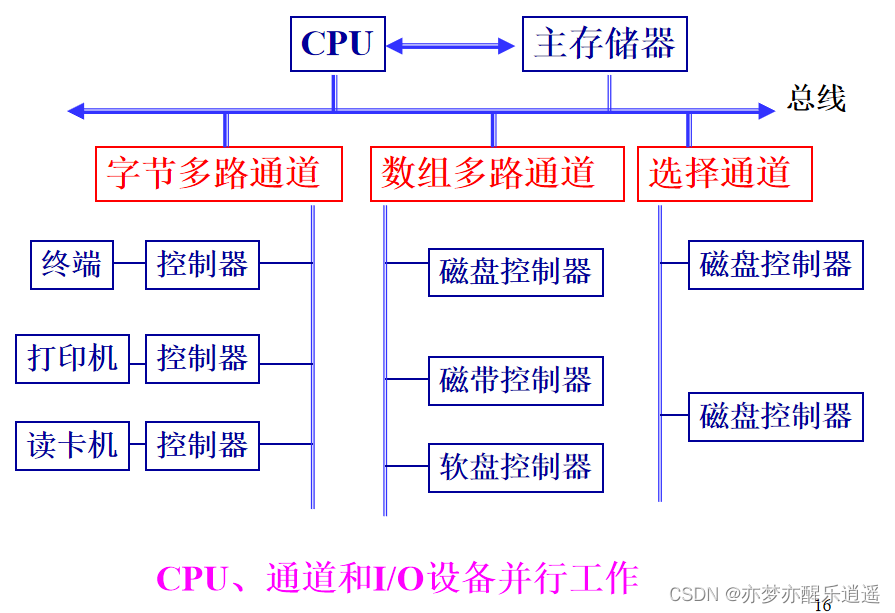
通道的类型(按照速度分类):
- 字节多路通道:以字节为单位传输信息,可以分时地执行多个通道程序,一个通道程序对应一台设备。主要用来连接大量慢速设备。
- 选择通道:每次传送一批数据,传送速度很快。在一段时间内只能执行一个通道程序,只允许一台设备传输数据。可用于固定头磁盘(每一个磁道上都有一个磁头,磁头不需要动,只需要进行选择)。
- 数组多路通道:结合了选择通道传送速度快和字节多路通道能够分时的优点。先为一台设备执行一条通道指令,再为另一台设备执行一条通道指令。可连接多台活动头磁盘机。
IO软件组成

用户层IO层
用户的IO接口不多,更多的IO软件是被包括在操作系统中的。
平时用的最多的IO接口就是c语言中的printf和scanf,用户的IO接口都是放在这种库函数里了。
库函数->系统调用。如“printf”将调用“write”系统调用。
设备独立层
这一层干的事情比较多。是对设备的操作系统级管理
设备命名
下面这张表是逻辑设备表,LUT(Logical Unit Table)。负责逻辑和物理的映射(逻辑——驱动——物理)
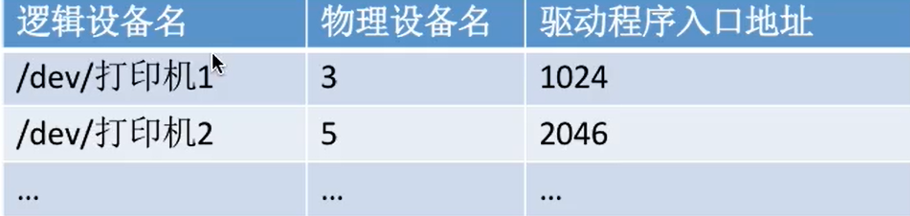
设备保护
统一块尺寸
将下层不同设备的不同尺寸输入转换为定长输入,对上层程序来说,逻辑块的是等长固定的。
输出同理。
缓冲技术
CPU频率太快,IO频率太慢,如果有一个缓冲区就可以解决这个矛盾。
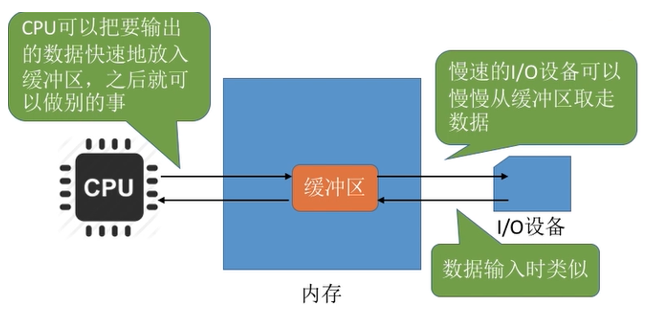
- 单缓冲:OS为I/O请求分配一个缓冲区。效率比较低,因为缓冲区必须空了才能写,满了才能读,进一步说,写的时候就不能读,读的时候不能写。
- 双缓冲in/out:建立两个缓冲区,可以平滑I/O设备和进程之间的数据流,改善系统效率。
- 多缓冲和缓冲池:多进程共享缓冲池。当内核收到I/O请求时,会首先检查缓冲池里是否有。
设备分配
配合操作系统,对进程进行设备(资源)分配。
- 静态分配:进程运行前分配设备。
- 动态分配:在进程运行过程中,分配设备。设备利用率高。
- 虚拟设备:是指设备本身是独占设备,经过虚拟技术处理,可以把它改造成共享设备。Spooling技术:实现虚拟设备的一种技术。它利用可共享的磁盘空间,来模拟独占的I/O设备。以空间换时间
Spooling技术,比如打印机,程序打印前先把打印内容发送到磁盘缓冲区,然后缓冲区再形成一个打印队列,将缓冲区内容打印出来。
出错处理
一般IO设备出错由驱动解决。
如果驱动解决不了,驱动就会通过设备独立层将错误上报。
硬件驱动层
一个驱动对应一个或者一个系列的产品。一般提供如下功能,虽然是不同的设备,但是功能接口类似:
①初始化设备与检测
②启动设备传输数据。
③中断处理。输入输出完毕后发送中断信号。
中断处理层
负责在CPU与IO设备之间处理中断。
检查设备状态:
- 若正常完成,就唤醒等待的进程。然后检查是否还有待处理的I/O请求,有就启动。
- 若传输出错,再发启动命令重新传输;或向上层报告“设备错误”信息。
磁盘管理
提高IO速度
- 选择性能好的磁盘。如 IDE、SATA、SCSI
- 采用好的调度算法。比如磁头如何调度,读写如何调度。
- 设置磁盘高速缓冲区
磁盘类型
- 硬盘和软盘;
- 固定头磁盘和活动头磁盘。
- 固定头磁盘:每条道上都有一个读/写磁头,用于大容量磁盘,并行读/写。(成本比较高)
- 移动头磁盘:每个盘面仅配有一个磁头。
- 现在还有SSD(固态硬盘),使用特殊的材料支持非机械的读写。而传统机械硬盘都要花很多时间在旋转和寻道上。
访问磁盘块的时间
寻道时间、旋转延迟时间、读/写传输时间。
- 寻道时间。最费时间的操作。
- 旋转延迟。从零扇区开始处到达目的地花费的时间,这里是平均值,为旋转一周的时间的一半。
- 数据传送。读取b个扇区,一个扇区要花费 1 N \dfrac{1}{N} N1份旋转时间

磁盘分配方法
连续分配;链接分配;索引分配
磁盘调度算法
调度算法用于优化寻道时间。
FIFO
简单公平。效率比较低,尤其是当调度请求多了以后,基本就是随机了。
但是如果是SSD,反而FIFO最快,反正SSD也不需要寻道。由此可见,软件的方法是建立在硬件上的,硬件的转变会改变软件方法的效率。

最短服务时间(SSTF)
在序列里,计算出距离当前位置最近的请求。
寻道效率比较高,但是也有不少计算负担。
而且效率也不见得特别高,当序列稀疏后逐渐呈现随机性。

扫描算法(SCAN)
朝着一个方向走,到头后折返。
缺点在于响应频率不均匀,比如在磁头走一个来回,中间位置的频率是稳定的,每隔一个周期来一次。但是边缘的,比如1位置,会在很短的时间内被来回扫两次,之后就要经历很长的时间去等待。

循环扫描与C-LOOK(C-SCAN与C-LOOK)
只朝着一个方向走,走到尽头后从头开始。
因为要返回初始,所以成本更大(返回过程啥都不干),但是不同位置的响应频率是稳定的,全部都是一个周期。

C-SCAN还可以优化为C-LOOK,折返位置和起始位置可以根据序列确定。

例题

(1)
2048(2K)×8=16384,刚好够位示图。
(2)
假定120为磁道上限
如果用纯C-SCAN,则需要(120-100)+(120-0)+(90-0)=230个单位
如果是C-LOOK,则需要(120-100)+(120-30)+(90-30)=170个单位(由此可见,没有明确说,默认都用C-LOOK)

0.01×0.5×4是4次读取的平均等待时间
0.0001×4是读取4个扇区的时间
同步IO与异步IO
- 同步IO:进程发出IO请求后阻塞,等待数据传送完成后唤醒。比如scanf。
- 异步IO:进程发出IO请求后继续运行,实现比较复杂。
没有绝对优劣,速度快不耗时的,同步效率比较高,速度慢耗时的,异步更好。


















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











