







DFS双向搜索的经典例题。
对于DFS和BFS来说双向搜索都能有效降低时间复杂度,但缺点就是会多开销空间,也就是用空间换时间。
由于我们的搜索范围是逐步扩大的所以当我们的每个节点的子节点较多时就可以做到如下:
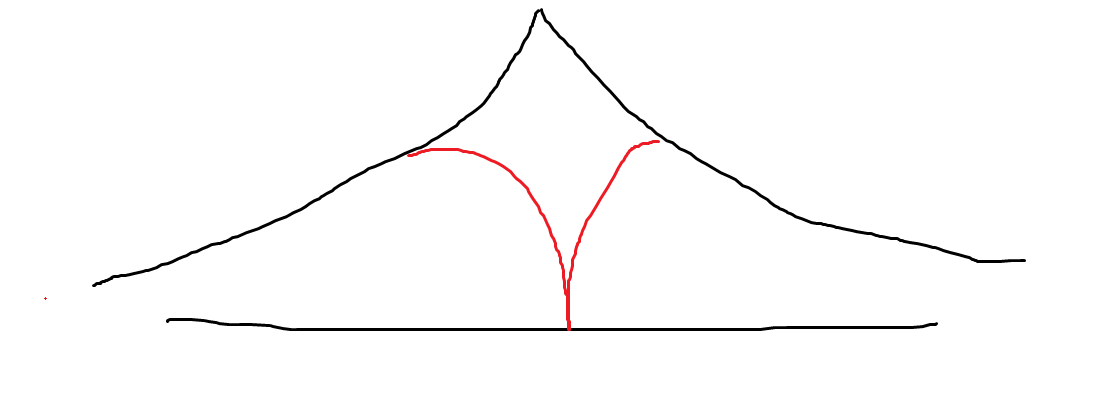
红色部分是从反向开始搜索,这样我们就可以明显看出我们有效的降低了时间的复杂度。
题目:

思路:
先通过对前部分进行搜索预处理出来能拿到的重量的所有情况,由于只搜索的一半的物品所以我们的时间复杂度有 2^N 降低到了2^N/2 ,显著降低了时间复杂度,并且进行打表,之后再对后半部分进行搜索时直接进对搜索出来的值在表中进行二分查找到最大的小于 m 的值并且更新一下答案即可。
剪枝:
①:优化搜索顺序
我们需要对后半部分进行二分查找所以时间复杂度为 2^N/2 * logN/2,那么我们可以适当的增加前面的搜索数据减小后面的搜索数据可以均匀一下,这样我们可以对前面的搜索N / 2 + 2 时时间复杂度最为低,而又由于我们增加了前面的搜索数据,这样我们可以将数据从大到小排序,那么我们搜索前面时会优先搜索到大的部分,会减掉更多的大于m的部分枝叶。
②:可行性剪枝
对于大于m的部分枝叶直接减掉不进行搜索。
代码:
1 #include <iostream>
2 #include <cstdio>
3 #include <algorithm>
4 #include <cstring>
5
6 using namespace std;
7
8 typedef long long LL;
9
10 const int N = 46;
11
12 int n, m, res;
13 int g[N];
14 int w[1 << 25];
15 int cnt;
16
17 void dfs1(int u, int sum)
18 {
19 if (u == n / 2 + 2)
20 {
21 w[cnt ++ ] = sum;
22 return;
23 }
24
25 dfs1(u + 1, sum);
26 if ((LL)sum + g[u] <= m) dfs1(u + 1, sum + g[u]);
27 }
28
29 void dfs2(int u, int sum)
30 {
31 if (u == n)
32 {
33 int l = 0, r = cnt - 1;
34 while (l < r)
35 {
36 int mid = l + r >> 1;
37 if (w[mid] + (LL)sum <= m) r = mid;
38 else l = mid + 1;
39 }
40 res = max(res, sum + w[l]);
41 return;
42 }
43
44 dfs2(u + 1, sum);
45 if ((LL)sum + g[u] <= m) dfs2(u + 1, sum + g[u]);
46 }
47
48 int main()
49 {
50 cin >> m >> n;
51 for (int i = 0; i < n; i ++ ) cin >> g[i];
52
53 sort(g, g + n);
54 reverse(g, g + n);
55
56 dfs1(0, 0);
57
58 sort(w, w + cnt);
59 cnt = unique(w, w + cnt) - w;
60 reverse(w, w + cnt);
61
62 dfs2(n / 2 + 2, 0);
63
64 cout << res << endl;
65
66 return 0;
67 }















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









