







 该博客主要围绕wine和wine_quality数据集展开实训。实训1使用sklearn处理数据集,包括读取、拆分数据与标签、划分训练集和测试集、标准化及PCA降维。实训2基于处理后的wine数据集构建K-Means聚类模型,通过多种方法确定最优聚类数目。
该博客主要围绕wine和wine_quality数据集展开实训。实训1使用sklearn处理数据集,包括读取、拆分数据与标签、划分训练集和测试集、标准化及PCA降维。实训2基于处理后的wine数据集构建K-Means聚类模型,通过多种方法确定最优聚类数目。
实训1 使用sklearn处理wine 和wine_quality数据集
1. 训练要点
-
掌握sklearn转换器的用法。
-
掌握训练集、测试集划分的方法。
-
掌握使用sklearn进行PCA降维的方法。
2.需求说明
wine数据集和wine_quality数据集是两份和酒有关的数据集。wine数据集包含3种不同起源的葡萄酒的记录,共178条。其中,每个特征对应葡萄酒的每种化学成分,并且都属于连续型数据。通过化学分析可以推断葡萄酒的起源。 wine_quality数据集共有4898个观察值, 11个输入特征和一个标签。其中,不同类的观察值数量不等,所有特征为连续型数据。通过酒的各类化学成分,预测该葡萄酒的评分。
3.实现思路及步骤
(1)使用pandas库分别读取wine数据集和win_quality数据集。
(2)将wine数据集和wine_quality数据集的数据和标签拆分开。
(3)将wine_quality数据集划分为训练集和测试集。
(4)标准化wine数据集和wine_quality数据集。
(5)对wine数据集和wine_quality数据集进行PCA降维。
实验
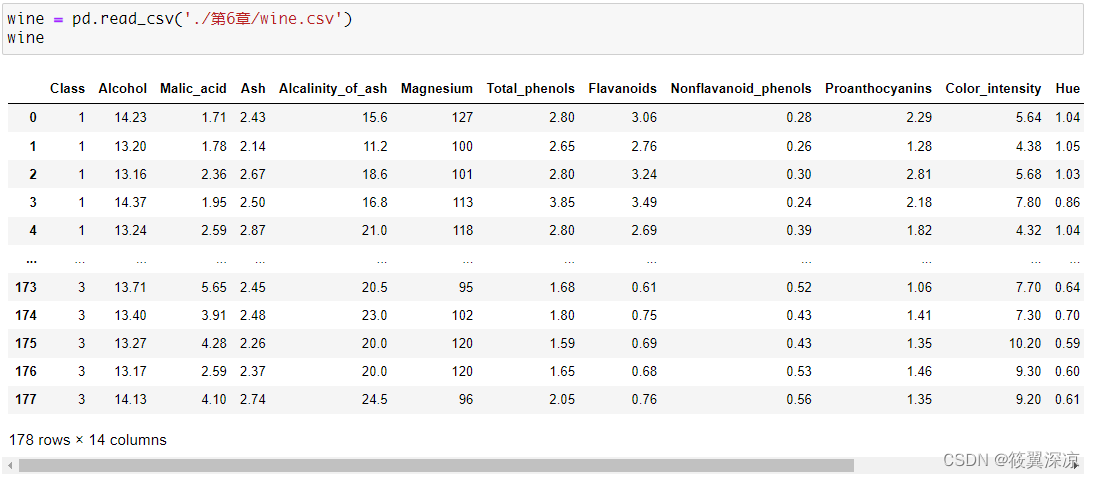
使用pandas库分别读取wine数据集和win_quality数据集。
wine = pd.read_csv('./第6章/wine.csv')
wine
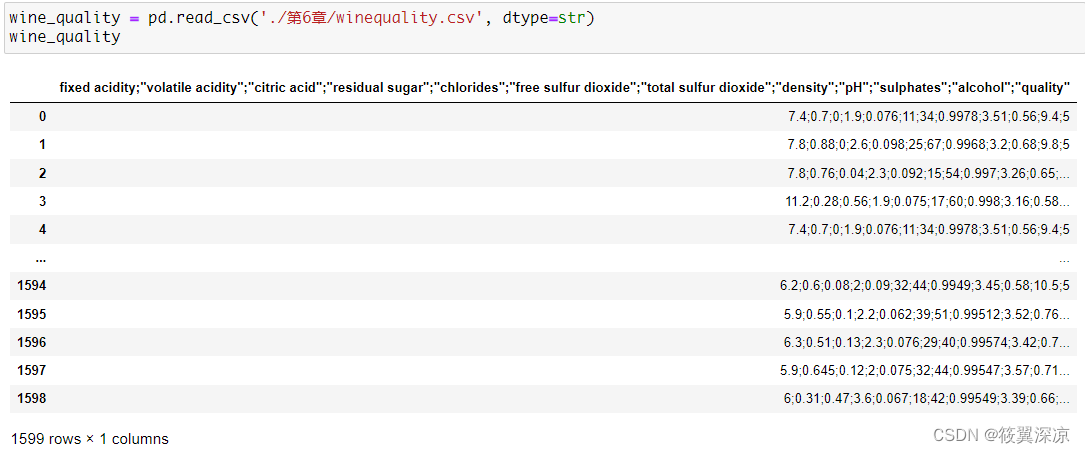
wine_quality = pd.read_csv('./第6章/winequality.csv', dtype=str)
wine_quality
将wine数据集和wine_quality数据集的数据和标签拆分开。
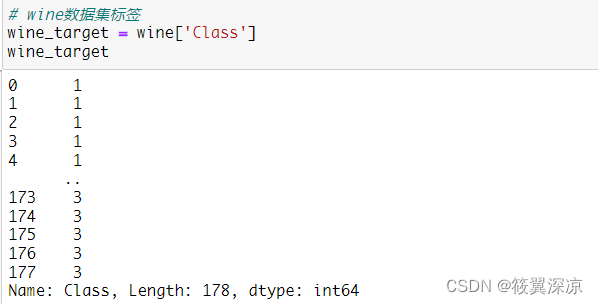
# wine数据集标签
wine_target = wine['Class']
wine_target
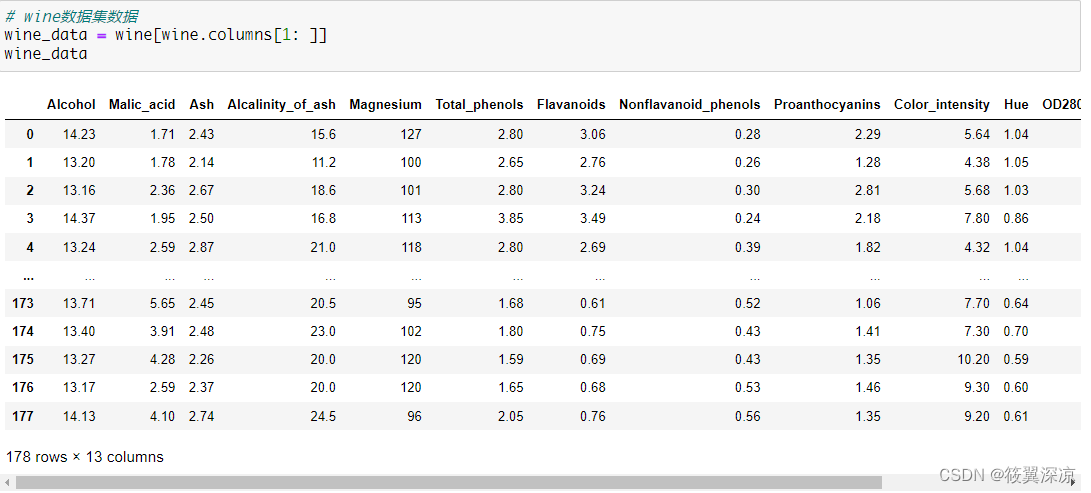
# wine数据集数据
wine_data = wine[wine.columns[1: ]]
wine_data
将winequality数据集格式化
# 将wine_quality数据集格式化
columnsName = list(wine_quality.columns.values)[0].split(';') # 将列名分割
columnsName = [name.replace('\"', '') for name in columnsName] # 把列名中的双引号去掉
wine_quality = wine_quality[wine_quality.columns[0]].str.split(';', expand=True) # 将winequalit数据集数据按分号分割并组成新的数据集
wine_quality.columns = columnsName
wine_quality
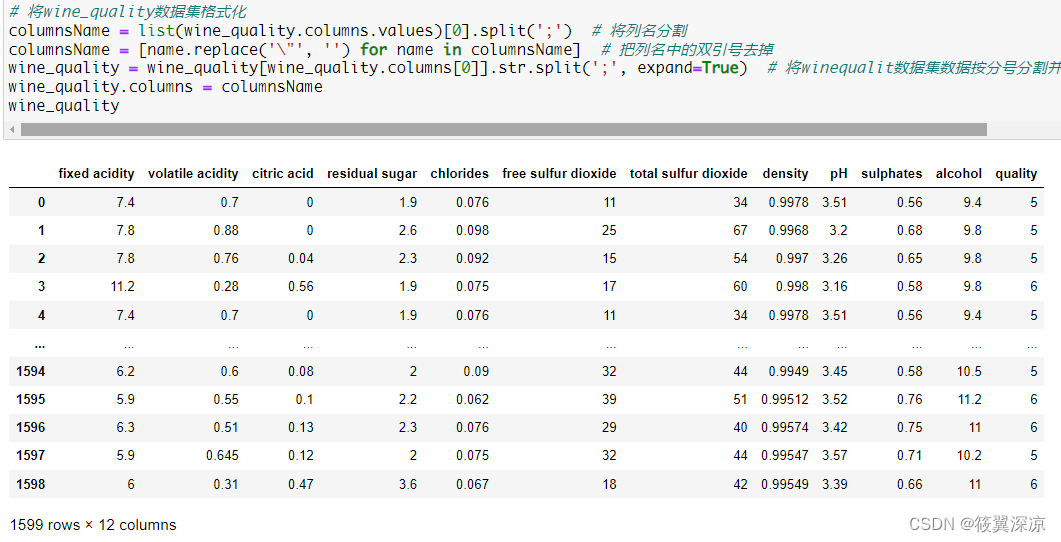
# wine_quality数据集的标签
wine_quality_target = wine_quality['quality']
wine_quality_target
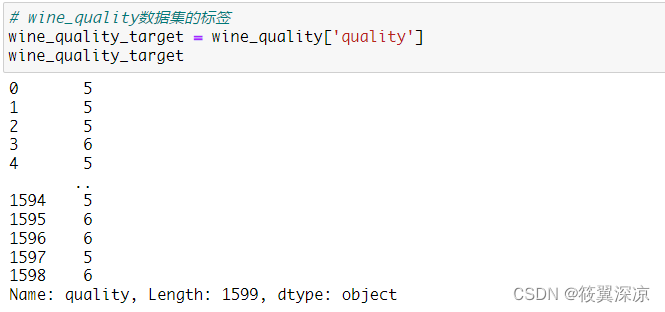
# wine_quality数据集的数据
wine_quality_data = wine_quality[wine_quality.columns[0: 11]]
wine_quality_data
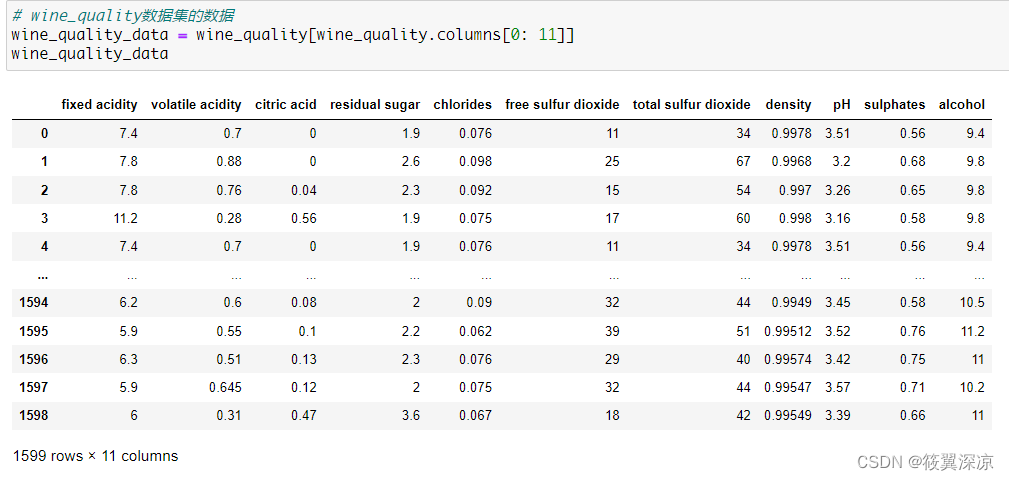
将wine_quality数据集划分为训练集和测试集。
# 将wine_qualit数据集划分成训练集和测试集,比例为7:3
wine_quality_data_train, wine_quality_data_test, wine_quality_target_train, wine_quality_target_test = train_test_split(wine_quality_data, wine_quality_target, test_size=0.3)
wine_quality_data_train
wine_quality_data_test
wine_quality_target_train
wine_quality_target_test
标准化wine数据集和wine_quality数据集。
Scaler = preprocessing.MinMaxScaler().fit(wine_data_train)
wine_trainScaler = Scaler.transform(wine_data_train)
wine_testScaler = Scaler.transform(wine_data_test)
wine_trainScaler
wine_testScaler
Scaler = preprocessing.MinMaxScaler().fit(wine_quality_data_train)
wine_quality_trainScaler = Scaler.transform(wine_quality_data_train)
wine_quality_testScaler = Scaler.transform(wine_quality_data_test)
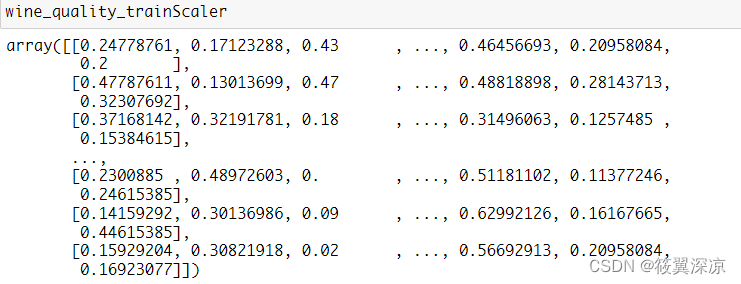
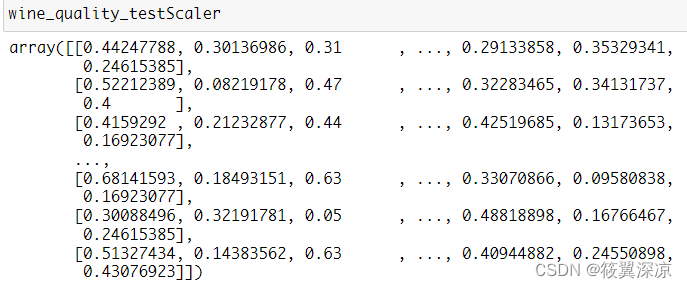
wine_quality_trainScaler
wine_quality_testScaler
对wine数据集和wine_quality数据集进行PCA降维。
# wine数据集进行PCA降维
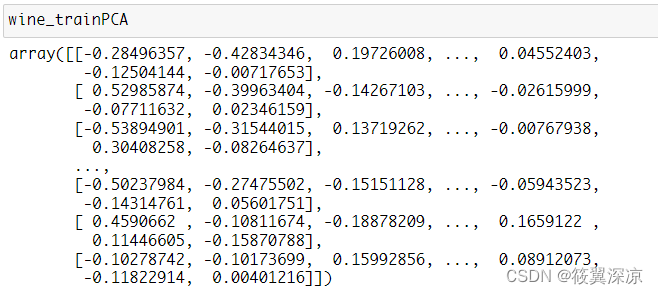
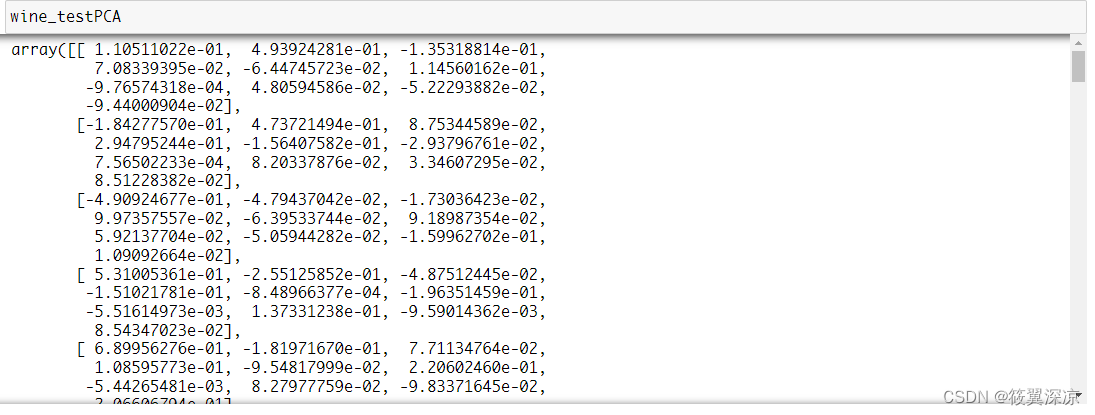
pca_model = PCA(n_components=10).fit(wine_trainScaler)
wine_trainPCA = pca_model.transform(wine_trainScaler)
wine_testPCA = pca_model.transform(wine_testScaler)
wine_trainPCA
wine_testPCA
# wine_quality数据集进行PCA降维
pca_model = PCA(n_components=10).fit(wine_quality_trainScaler)
wine_quality_trainPCA = pca_model.transform(wine_quality_trainScaler)
wine_quality_testPCA = pca_model.transform(wine_quality_testScaler)
实训2 构建基于wine数据集的K-Means聚类模型
1.训练要点
-
了解sklearn估计器的用法。
-
掌握聚类模型的构建方法。
-
掌握聚类模型的评价方法。
2.需求说明
wine数据集的葡萄酒总共分为3种,通过将wine数据集的数据进行聚类,聚集为3 个簇,能够实现葡萄酒的类别划分。
3.实现思路及步骤
(1)根据实训1的wine数据集处理的结果,构建聚类数目为3的K-Means模型。
(2)对比真实标签和聚类标签求取FMI。
(3)在聚类数目为2~10类时,确定最优聚类数目。
(4)求取模型的轮廓系数,绘制轮廓系数折线图,确定最优聚类数目。
(5)求取Calinski-Harabasz指数,确定最优聚类数目。
实验
根据实训1的wine数据集处理的结果,构建聚类数目为3的K-Means模型
kmeans = KMeans(n_clusters=3, random_state=123).fit(wine_trainScaler)
对比真实标签和聚类标签求取FMI
from sklearn.metrics import fowlkes_mallows_score
score = fowlkes_mallows_score(wine_target_train, kmeans.labels_)
score

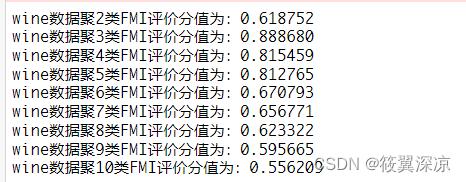
在聚类数目为2~10类时,确定最优聚类数目
for i in range(2, 11):
kmeans = KMeans(n_clusters=i, random_state=123).fit(wine_trainScaler)
score = fowlkes_mallows_score(wine_target_train, kmeans.labels_)
print('wine数据聚%d类FMI评价分值为:%f' %(i,score))
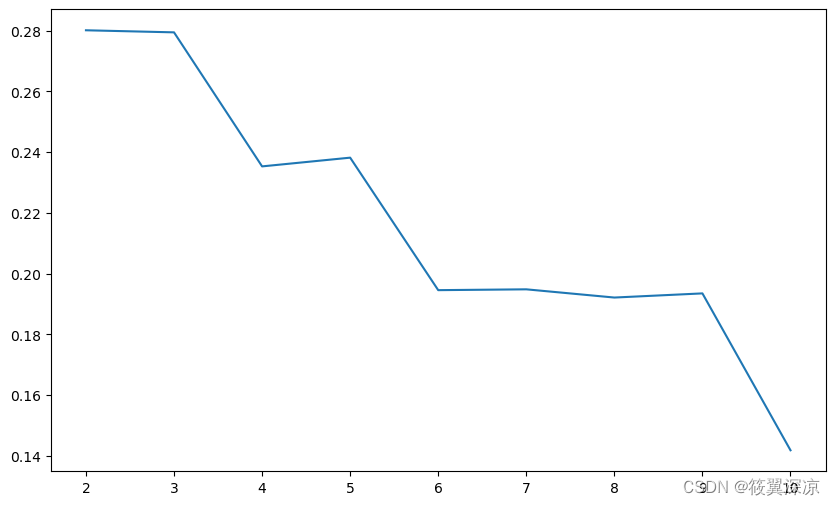
求取模型的轮廓系数,绘制轮廓系数折线图,确定最优聚类数目
silhouettteScore = []
for i in range(2, 11):
kmeans = KMeans(n_clusters=i, random_state=123).fit(wine_trainScaler)
score = silhouette_score(wine_trainScaler, kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10, 6))
plt.plot(range(2, 11), silhouettteScore, linewidth=1.5, linestyle='-')
plt.show()
求取Calinski-Harabasz指数,确定最优聚类数目
for i in range(2,10):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(wine_trainScaler)
score = calinski_harabasz_score(wine_trainScaler,kmeans.labels_)
print('iris数据聚%d类calinski_harabaz指数为:%f'%(i,score))


















 7192
7192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









