









 本文描述了作者在使用CBOW方法进行文本处理时,从基于矩阵的CBOW模型转向尝试负采样的过程。他们分享了模型的实现细节,包括词频分析、负样本抽取和反向传播,以及预测结果的初步评估。尽管遇到了挑战,如预测准确率低和参数调整,作者仍在持续优化过程中。
本文描述了作者在使用CBOW方法进行文本处理时,从基于矩阵的CBOW模型转向尝试负采样的过程。他们分享了模型的实现细节,包括词频分析、负样本抽取和反向传播,以及预测结果的初步评估。尽管遇到了挑战,如预测准确率低和参数调整,作者仍在持续优化过程中。
CBOW的Hierarchical softmax代码,虽然没有成功,但至今我仍然认为代码逻辑是没有问题
一定是有某些地方,是我理解有误,先暂时搁置Hierarchical Softmax的方式
来试试负采样的方式
负采样这个词,好像在哪看到过,忘了
今天开个坑吧,虽然这个坑,可能年后才能填完,这两天先试试
年前,把纯矩阵做的基础CBOW代码搞出来,开开心心回了家
寻思着,负采样基于纯矩阵基础去做的,稍微改改就好
唉。。。。收假后,头很疼
看这一大坨代码,头很疼
我已经忘记年前的思路了
。。。。。。。。。。。。。。。
唉,事情已经走到这一步,又能怎样呢?
再苦再累头再秃,不也还是要挣扎一番,纠结一下吗
人生,不就是这样破罐破摔吗
年前用基于矩阵的方式去做,基于矩阵的CBOW模型实操
预测准确率为22%左右

说实话。。。我已经很满意了,至少这个东西是可以去预测的,至于预测为什么不正确,我目前猜测主要还是跟词频有关。
在结果中,and和the、a的预测准确率较高,经过打印词频,确实词频高

但其中,预测准确的,也有一些低词频的词汇,所以这个方式目前是可用的。
至于预测效果是否好,主要还是看调参了,比如迭代次数、比如学习率等等。
但这不是我重点考虑的。
我只要模型流程是正确的,能跑的通。
所以,接下来,我就要根据基础的纯矩阵CBOW,改编成负采样方式。
跟基于矩阵的CBOW算法的差距在于,负采样,是需要指定负样本,以及统计所有上下文h值、或是,统计所有单词的μ值
比起自己的心血来潮,忽然觉得,上班其实是件快乐的事
我为什么要这么折磨自己呢
唉,人生在世不如意,明朝散发弄扁舟…我要发疯…唉

import math
import numpy as np
from docx import Document
import re
import pandas as pd
import random
random.seed(0)
pd.options.display.max_rows = None
"""
需要提前设置的参数:doc_path语料的word文档、η学习率、词向量的维度W_columns、iterate_times迭代次数、context_word_num单个上下文的词数量
+++++++ 【W词向量的所有初始值、θ霍夫曼树非叶子节点上的权重参数】:这两个关键参数在后续用正态分布随机树来进行初始化 ++++
"""
doc_path = r"simple_word.docx"
η = 0.01
W_columns = 10
iterate_times = 50
context_word_num = 4
# 获取语料库C+统计无重复单词的词典D
doc = Document(doc_path)
C_list = []
all_text = ''
for i in doc.paragraphs:
if len(i.text) != 0:
para = [x for x in re.split(' |!|\?|\.|。|,|,|\(|\)', i.text) if x]
C_list.append(para)
all_text = all_text + i.text
words_org = [x for x in re.split(' |!|\?|\.|。|,|,|\(|\)', all_text) if x]
"""统计每个单词的词频,word_count是series数据类型"""
word_count = pd.value_counts(words_org)
# 采用3/4幂律来获取每个词的采样概率
for word,count in word_count.items():
word_count[word] = count**(3/4)
print(word_count)
"""词典D转独热编码"""
D_list = set(words_org)
N = len(D_list)
D_onehot = {}
for index, value in enumerate(D_list):
temp = [0] * N
temp[index] = 1
D_onehot[value] = temp
del temp
# 最终词典D的独热编码为D_df
D_df = pd.DataFrame(D_onehot)
"""初始化词向量矩阵W:W_columns个维度特征"""
# 这意味着后续的中间向量h和关键词参数向量u,都是用3个值表示,如 h=[1,10,20]
W_dict = {}
for index, word in enumerate(D_list):
W_dict[word] = [random.random() for i in range(W_columns)]
# 最终词向量用W_df表示
W_df = pd.DataFrame(W_dict)
print(f"初始的词向量W为")
print(W_df)
"""初始化关键词的参数向量u:u的维度特征个数,跟w、h保持一致"""
u_dict = {}
for index, word in enumerate(D_list):
u_dict[word] = [1 for i in range(W_columns)]
# 最终关键词参数向量用u_df表示
u_df = pd.DataFrame(u_dict)
print(f"初始的关键词参数向量u为")
print(u_df)
# 每一个u的迭代,都需要所有上下文中间向量h的累加,每一个w的迭代,都需要所有u的累加
# 先迭代u,u迭代完变为一个新的u_new后,再用所有的u_new去依次迭代所有的w。
"""第3阶段反向传播:把所有上下文存进列表里"""
# 由于我们要迭代很多次,所以每次都重新选取上下文,会非常耗时
# 因此,不如一次性,把所有的上下文都选取后,放进一个列表里边
# 这样,以后无论迭代多少次,上下文都是一样的,不需要重复选取
c = context_word_num//2
y_and_context_list = []
y_h_dict = {}
for sentence in C_list:
for index, word in enumerate(sentence):
"""获取单个上下文"""
y = word
context = []
if index-2>=0:
context.append(sentence[index-1])
if index-2>=0:
context.append(sentence[index-2])
if index+1<len(sentence):
context.append(sentence[index+1])
if index+2<len(sentence):
context.append(sentence[index+2])
"""计算单个上下文的中间向量h"""
h = list(W_df[context].sum(axis=1))
y_and_context = (y, h,context)
y_h_dict[y]=list(h)
y_and_context_list.append(y_and_context)
"""y和h有个对应的dataframe表:每个关键词都有一个对应的中间向量h"""
y_h_df = pd.DataFrame(y_h_dict)
def sigmoid(x, y):
sig = np.matmul(x, y)
try:
result = 1 / (1.0 + math.exp(-sig))
except OverflowError:
result = 1 / (1.0 + math.exp(700))
return result
"""抽取负样本:根据词频的概率的3/4次幂来抽"""
def get_negative_words():
negative_num = 6
# 统计每个单词的词频,word_count是series数据类型
word_count = pd.value_counts(words_org)
word_count = ((word_count/word_count.sum())**(3/4)*100).cumsum()
negative_words = []
for i in range(0,negative_num):
rand = random.randint(0,int(word_count.max()))
for w,count_num in word_count.items():
if rand < count_num:
negative_words.append(w)
break
else:
negative_words.append(w)
return negative_words
"""反向传播:根据每个上下文和对应的待预测单词y,去迭代u和w"""
for i in range(iterate_times):
print(f"第{i + 1}次迭代")
h_temp = 0.0
"""负样本抽取时机1:每一轮迭代时,抽取一次负样本,这意味着所有待预测单词的参数迭代,都是用同样的负样本参与计算迭代"""
# 其实还有第二种抽取实际2,就是每个单词的预测,都重新抽一次负样本,但有个问题就是:我需要保存每个单词每次抽取的负样本,这样内存的消耗会非常大。
# 因为我不能每次只迭代一个待遇测单词的u和w,我需要将所有待预测单词的u都迭代完之后,才能去迭代所有待遇测单词的w
# 嗷。。。那还真不一定。。。。哇塞。。。。好像可以实现第二个负样本抽取时机。
# 但是实现之后。。。预测的效果也不咋样
negative_w = get_negative_words()
"""所有关键词的参数向量u的迭代"""
for y_and_context in y_and_context_list:
y, h,context = y_and_context
u_old = u_df[y]
u_temp = 0.0
words_u_temp = [w for w in negative_w]
words_u_temp.append(y)
y_h_df_temp = y_h_df[words_u_temp]
for y_index in y_h_df_temp:
if y_index == y:
l_word = 1
else:
l_word = 0
h_row = y_h_df[y_index]
"""u的迭代公式涉及所有h的累加计算"""
u_temp += η*(l_word-sigmoid(u_old,h_row))*h_row
u_new = u_old + u_temp
u_df[y] = u_new
words_u_temp.pop()
"""所有词向量w的迭代"""
for y_and_context in y_and_context_list:
y, h,context = y_and_context
w_temp = 0.0
words_h_temp = [w for w in negative_w]
words_h_temp.append(y)
u_df_temp = u_df[words_h_temp]
for y_index in u_df_temp:
if y_index == y:
l_word = 1
else:
l_word = 0
u_row = u_df[y_index]
"""w的迭代公式涉及所有u的累加计算"""
w_temp += η*(l_word-sigmoid(u_row,h))*u_row
for word in context:
W_df[word] = W_df[word] + w_temp
words_h_temp.pop()
print(f"迭代后的词向量W为")
print(W_df)
"""迭代后预测,预测的方式:每个h与所有的u分别进行乘积后,再softmax,看哪个值比较大,就预测为哪个关键词"""
def get_mom(a,b_df): # 计算softmax的分母部分
mom = 0
for b in b_df:
temp = np.matmul(a,b_df[b])
mom += math.exp(temp)
return mom
def softmax(a,b,b_df): # 计算最终的softmax值
mom = get_mom(a,b_df)
son = math.exp(np.matmul(a,b))
result = son/mom
return result
上边的代码,
"""反向传播:根据每个上下文和对应的待预测单词y,去迭代u和w"""
for i in range(iterate_times):
print(f"第{i + 1}次迭代")
h_temp = 0.0
"""所有关键词的参数向量u的迭代"""
for y_and_context in y_and_context_list:
y, h, context = y_and_context
u_old = u_df[y]
u_temp = 0.0
negative_w = get_negative_words()
words_u_temp = [w for w in negative_w]
words_u_temp.append(y)
y_h_df_temp = y_h_df[words_u_temp]
"""负样本抽取时机2:每个待预测单词,都抽取一次负样本,这意味着所有待预测单词的参数迭代,都是用不同的负样本参与计算迭代"""
for y_index in y_h_df_temp:
if y_index == y:
l_word = 1
else:
l_word = 0
h_row = y_h_df[y_index]
"""u的迭代公式涉及所有h的累加计算"""
u_temp += η * (l_word - sigmoid(u_old, h_row)) * h_row
u_new = u_old + u_temp
u_df[y] = u_new
"""w的迭代"""
w_temp = 0.0
u_df_temp = u_df[words_u_temp]
for y_index in u_df_temp:
if y_index == y:
l_word = 1
else:
l_word = 0
u_row = u_df[y_index]
"""w的迭代公式涉及所有u的累加计算"""
w_temp += η * (l_word - sigmoid(u_row, h)) * u_row
for word in context:
W_df[word] = W_df[word] + w_temp
words_u_temp.pop()
CBOW迭代出来的词向量应用
根据上下文,预测中间词汇
预测出的结果。。。em。。。比较惨烈,准确率非常低哦
预测准确的,都一些本来概率就很高的单词,很生气
准备要禁掉这些高概率单词作为负样本的抽取,看看它们还能不能这么作妖(试过,没用)

"""预测关键词:h和所有的u分别计算出softmax值,其中softmax值最大的为对应的预测关键词"""
def predict(a,b_df): # 预测关键词
y_predict = {'max_softmax':0,'y_index':None}
for y_index in b_df:
softmax_now = softmax(a, b_df[y_index], b_df)
if softmax_now>y_predict['max_softmax']:
y_predict['max_softmax'] = softmax_now
y_predict['y_index'] = y_index
if y_predict['y_index'] == None:
print("无法预测,报错")
else:
return y_predict['y_index']
pre_result = []
for y_and_context in y_and_context_list:
y, h, context = y_and_context
h = list(W_df[context].sum(axis=1))
y_pre = predict(h,u_df)
if y_pre == y:
print(f"{y}预测准确")
pre_result.append(1)
else:
print(f"{y}预测错误,预测值为{y_pre}")
pre_result.append(0)
print(f"预测准确率为:{sum(pre_result)/len(pre_result)*100}%")
根据输入的单词,预测相近词汇
主要是用词向量里的余弦相似度,去计算出相近的词汇。
我输入的是different,但。。。唉
一言难尽。。。。就先这样吧。。。。遗憾很大,但暂时解决不了,有可能是参数,有可能是运算逻辑,但这都不是我现在能解决的。
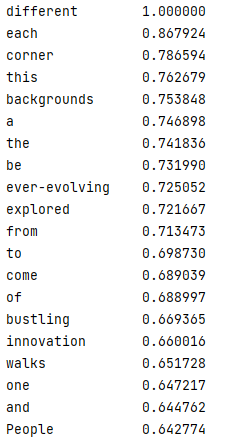
"""预测相近词汇 :计算某个单词和所有单词的词向量余弦相似度,并根据相似度值排序输出"""
def get_cos(vec1,vec2):
return np.sum(vec1 * vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
# similar_word = input("请输入待预测的单词:")
w_vec = W_df["different"]
cos_dict = {}
for w,vec in W_df.items():
cos = get_cos(w_vec,vec)
cos_dict[w] = cos
cos_Sries = pd.Series(cos_dict)
print(cos_Sries.sort_values())


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









