






目录
1.Ollama server
1.下载
下载路径:Download Ollama on Windows
下载好后,直接打开安装包

2.环境配置
1.host

2.跨域
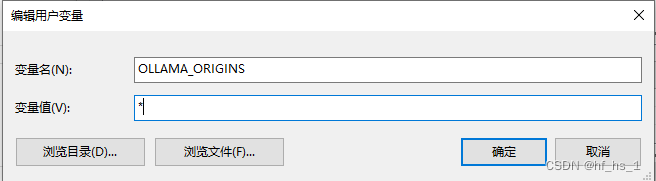
3.模型存储路径
解决存储空间不够的问题

如果修改后没有变化,记得修改用户变量(系统变量都可以试试,哈哈)。
3. 启动Ollama
直接搜索,可以找到ollama,点击打开,服务后台启动着。

点击后可以在任务管理器看到,服务已经打开了。

也可以在cmd中检查是否安装成功
ollama -v![]()
4.模型下载
执行该命令,下载并运行模型
ollama run [modelname]5.Ollama连接检测
直接在网页中输入http://ip+已经在环境变量中设置好的端口,证明可以连接。

2.Docker配置
1.本地环境配置
先打开控制面板,找到程序打开后,点击“启动或关闭Windows功能”

勾选这三个
![]()
![]()
![]()
2.下载Docker desktop
下载地址:Install Docker Desktop on Windows | Docker Docs

打开安装包
![]()
都选,直接点击OK

之后打开Docker desktop,点击accept。

如果打开后,出现WSL 2 installation is incomplete的问题,可以直接点击下方链接
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
原文:安装Docker Desktop报错WSL 2 installation is incomplete.-CSDN博客

3.Docker源配置
点击setting
环境源填写在"registry-mirrors"中
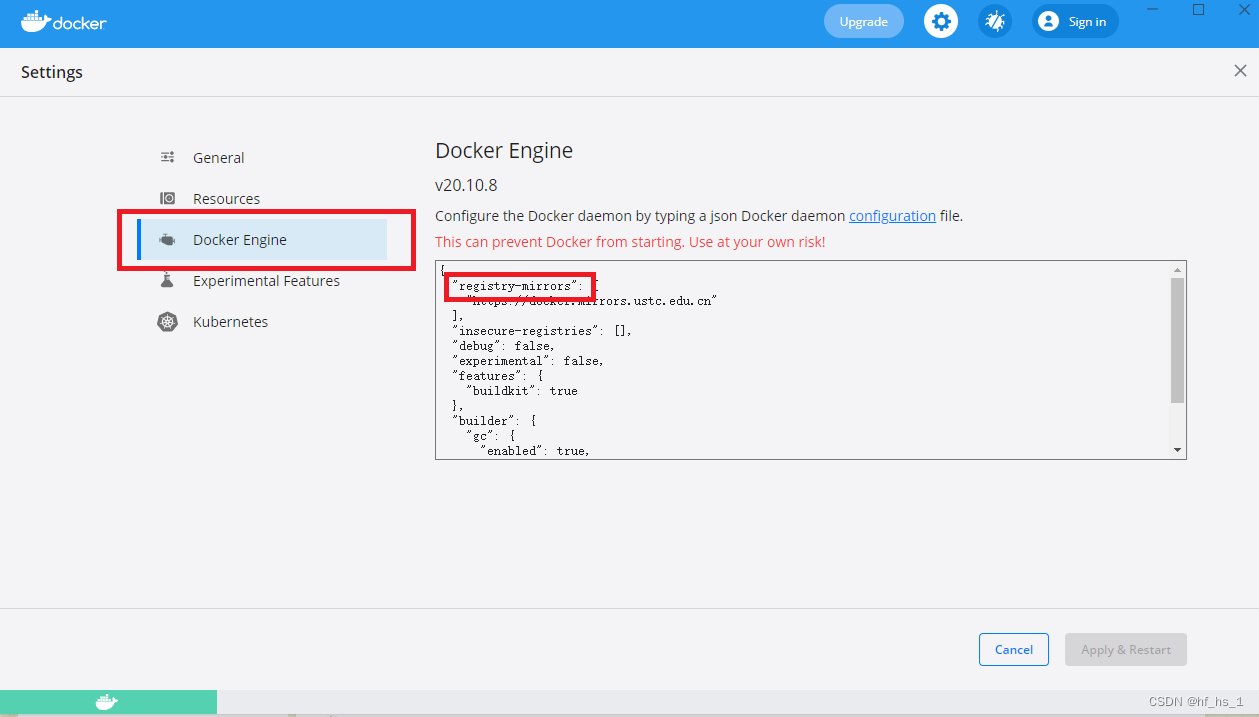
1.Docker中国官方
https://registry.docker-cn.com2.网易
http://hub-mirror.c.163.com3.中国科学技术大学
https://docker.mirrors.ustc.edu.cn4.环境检验
docker version
3.WebUI
详细可查看该地址🏡 首页 |打开 WebUI (openwebui.com)
1.本地Ollama
在终端中执行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main2.服务器Ollama:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main1.运行支持Nvidia GPU 的 Open WebUI
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda3.界面
安装好后,可以在docker中找到相应的容器,点击这个组件,就可以打开webui界面。

4.应用配置
点击右上角的setting

在这里输入Ollama的模型链接地址,即:http://ip+端口
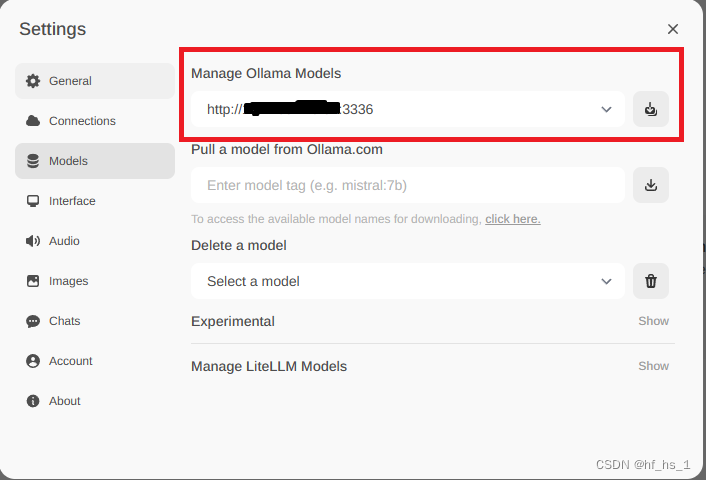
在这里选择本地下载好的模型

这样就可以开始聊天了

5.模型运行情况
Windows中是一张4090(24G显存)+内存(48G),运行不起来llama3:70b,预估需要内存64G以上。

6.本地环境
Windows10
Docker:20.10.8
Ollama:0.1.37















 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









