







Ada-GTO(Adaptive Gorilla Troops Optimizer,自适应大猩猩部队优化器) 的详细介绍,包括其设计原理、关键改进、算法流程以及在癌症多组学数据整合中的具体应用。
1. 算法背景
GTO(Gorilla Troops Optimizer) 是一种受大猩猩群体社会行为启发的元启发式算法,模拟以下行为:
- 迁移(探索新领地)
- 竞争(争夺领导权)
- 协作(群体保护)
Ada-GTO 是GTO的改进版本,通过引入 自适应权重 和 Lévy Flight策略,增强其在复杂优化问题(如高维非凸的NMF初始化)中的性能。
2. 核心改进
(1)自适应权重策略
- 动态调整探索与开发的平衡:
在迭代过程中,根据当前进度自动调整搜索步长,早期侧重全局探索,后期侧重局部开发。% Lévy Flight步长公式(自适应衰减) step = u / (abs(v)^(1/beta)) * (1 - t/max_iter);beta:Lévy分布参数(通常取1.4)t:当前迭代次数,max_iter:总迭代次数- u 和 v 是两个独立的标准正态分布(高斯分布)随机变量: u ∼ N ( 0 , σ 2 ) , v ∼ N ( 0 , 1 ) u \sim \mathcal{N}(0, \sigma^2), \quad v \sim \mathcal{N}(0, 1) u∼N(0,σ2),v∼N(0,1)
(2)Lévy Flight移动
- 特点:结合长距离跳跃与短距离精细搜索,避免陷入局部最优。
- 数学形式:
Step ∼ u ∣ v ∣ 1 / β , u ∼ N ( 0 , σ 2 ) , v ∼ N ( 0 , 1 ) \text{Step} \sim \frac{u}{|v|^{1/\beta}}, \quad u \sim N(0,\sigma^2), v \sim N(0,1) Step∼∣v∣1/βu,u∼N(0,σ2),v∼N(0,1)- 其中 σ = ( Γ ( 1 + β ) sin ( π β / 2 ) β ⋅ Γ ( ( 1 + β ) / 2 ) ⋅ 2 ( β − 1 ) / 2 ) 1 / β \sigma = \left(\frac{\Gamma(1+\beta) \sin(\pi\beta/2)}{\beta \cdot \Gamma((1+\beta)/2) \cdot 2^{(\beta-1)/2}}\right)^{1/\beta} σ=(β⋅Γ((1+β)/2)⋅2(β−1)/2Γ(1+β)sin(πβ/2))1/β
(3)双阶段优化
- 探索阶段:广泛搜索解空间(类似大猩猩群体迁移)。
- 开发阶段:围绕当前最优解精细调整(类似争夺“银背大猩猩”领导权)。
3. 算法流程
伪代码步骤
1. 初始化种群(大猩猩位置随机分布)
2. While 未达到最大迭代次数:
a. 计算自适应Lévy步长
b. 探索阶段:
- 随机选择个体交互或全局搜索
- 更新候选解: X_new = X_old ± Lévy_step * (X_rand - X_old)
c. 开发阶段:
- 若当前解质量高(适应度优),则围绕其局部搜索
- 更新候选解: X_new = X_old + 权重 * (X_best - X_old)
d. 评估候选解,更新全局最优
3. 返回最优解
关键公式
-
位置更新(探索阶段):
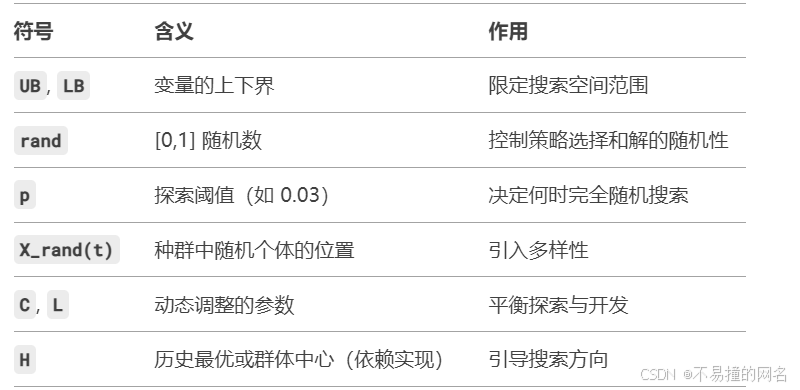
G X ( t + 1 ) = { ( U B − L B ) ⋅ rand + L B if rand < p ( rand − C ) ⋅ X rand ( t ) + L ⋅ H if rand ≥ 0.5 X ( t ) − L ⋅ ( L ⋅ ( X ( t ) − G X rand ( t ) ) + rand ⋅ ( X ( t ) − G X rand ( t ) ) ) otherwise GX(t+1) = \begin{cases} (UB - LB) \cdot \text{rand} + LB & \text{if rand} < p \\ (\text{rand} - C) \cdot X_{\text{rand}}(t) + L \cdot H & \text{if rand} \geq 0.5 \\ X(t) - L \cdot (L \cdot (X(t) - GX_{\text{rand}}(t)) + \text{rand} \cdot (X(t) - GX_{\text{rand}}(t))) & \text{otherwise} \end{cases} GX(t+1)=⎩ ⎨ ⎧(UB−LB)⋅rand+LB(rand−C)⋅Xrand(t)+L⋅HX(t)−L⋅(L⋅(X(t)−GXrand(t))+rand⋅(X(t)−GXrand(t)))if rand<pif rand≥0.5otherwise- 根据随机数 rand 的值选择三种不同的位置更新策略
C、L、H为控制参数,p为探索概率阈值。- UB 和 LB:变量的上界和下界(如 UB=[1,1], LB=[0,0])。
-
X
r
a
n
d
(
t
)
X_{rand}(t)
Xrand(t):当前种群中随机选择一个个体的位置。
- C 和 L:动态调整的参数
- H:历史最优位置或群体中心
- C:控制探索强度,随迭代衰减 : C = ( 1 − t max_iter ) ⋅ cos ( 2 ⋅ rand ) C = \left(1 - \frac{t}{\text{max\_iter}}\right) \cdot \cos(2 \cdot \text{rand}) C=(1−max_itert)⋅cos(2⋅rand)
- L:随机扰动因子:
L
=
C
⋅
l
,
l
∈
[
−
1
,
1
]
(随机数)
L = C \cdot l, \quad l \in [-1,1] \text{(随机数)}
L=C⋅l,l∈[−1,1](随机数)
-
自适应权重(开发阶段):
Weight = ( ϵ 1 − ϵ 1 ⋅ t MaxIter ) ( 1 − t / MaxIter ) \text{Weight} = \left(\epsilon_1 - \epsilon_1 \cdot \frac{t}{\text{MaxIter}}\right)^{(1-t/\text{MaxIter})} Weight=(ϵ1−ϵ1⋅MaxItert)(1−t/MaxIter)- ϵ 1 \epsilon_1 ϵ1 控制初始权重(通常 ϵ 1 = 1 \epsilon_1=1 ϵ1=1, ϵ 2 = 2 \epsilon_2=2 ϵ2=2)。
4. 在sparse-jNMF中的应用
优化目标
最小化多组学数据的联合重构误差,并施加稀疏约束:
min
W
,
H
i
∑
i
=
1
I
∥
A
i
−
W
H
i
∥
F
2
+
γ
∥
W
∥
1
\min_{W,H_i} \sum_{i=1}^{I} \|A_i - WH_i\|_F^2 + \gamma \|W\|_1
W,Himini=1∑I∥Ai−WHi∥F2+γ∥W∥1
W:共享基矩阵(样本-亚型关系)- H i H_i Hi:各数据特有的系数矩阵
Ada-GTO的作用
- 初始化优化:
- 用Ada-GTO生成高质量的初始
W和 H i H_i Hi,替代随机初始化。 - 避免NMF因非凸性陷入局部最优。
- 用Ada-GTO生成高质量的初始
- 提升收敛速度:
- 自适应步长减少无效搜索,加速收敛。
代码实现(MATLAB核心)
function W_init = ada_gto_for_nmf(data, k)
% 定义目标函数(NMF损失 + 稀疏项)
objective = @(W_flat) norm(data - reshape(W_flat, [m,k])*H, 'fro')^2 + gamma*norm(W_flat,1);
% Ada-GTO优化
W_flat = ada_gto(objective, m*k, 0, 1, 100); % 变量维度m×k,边界[0,1]
W_init = reshape(W_flat, [m, k]);
end
5. 与传统GTO的对比
| 特性 | 传统GTO | Ada-GTO |
|---|---|---|
| 搜索策略 | 固定随机步长 | Lévy Flight + 自适应权重 |
| 收敛性 | 易陷入局部最优 | 全局搜索能力更强 |
| 参数敏感性 | 依赖手动调参 | 动态调整参数,鲁棒性更高 |
| 适用场景 | 低维优化问题 | 高维非凸问题(如NMF初始化) |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











