







 文章介绍了Transformer模型在自然语言处理中的重要性,强调了Attention机制和self-Attention的概念,以及多头注意力如何增强特征提取。Transformer通过堆叠多层和位置编码处理序列信息,解决了RNN在处理长序列时的挑战,推动了NLP领域的进步,特别是在BERT和GPT等预训练模型的发展中起到关键作用。
文章介绍了Transformer模型在自然语言处理中的重要性,强调了Attention机制和self-Attention的概念,以及多头注意力如何增强特征提取。Transformer通过堆叠多层和位置编码处理序列信息,解决了RNN在处理长序列时的挑战,推动了NLP领域的进步,特别是在BERT和GPT等预训练模型的发展中起到关键作用。
本文主要从工程应用角度解读Transformer,如果需要从学术或者更加具体的了解Transformer,请参考这篇文章。
目录
1 自然语言处理
1.1 RNN
RNN系列算法包括GUR、LSTM等变体,主体部分是一样的,内部结构不同。
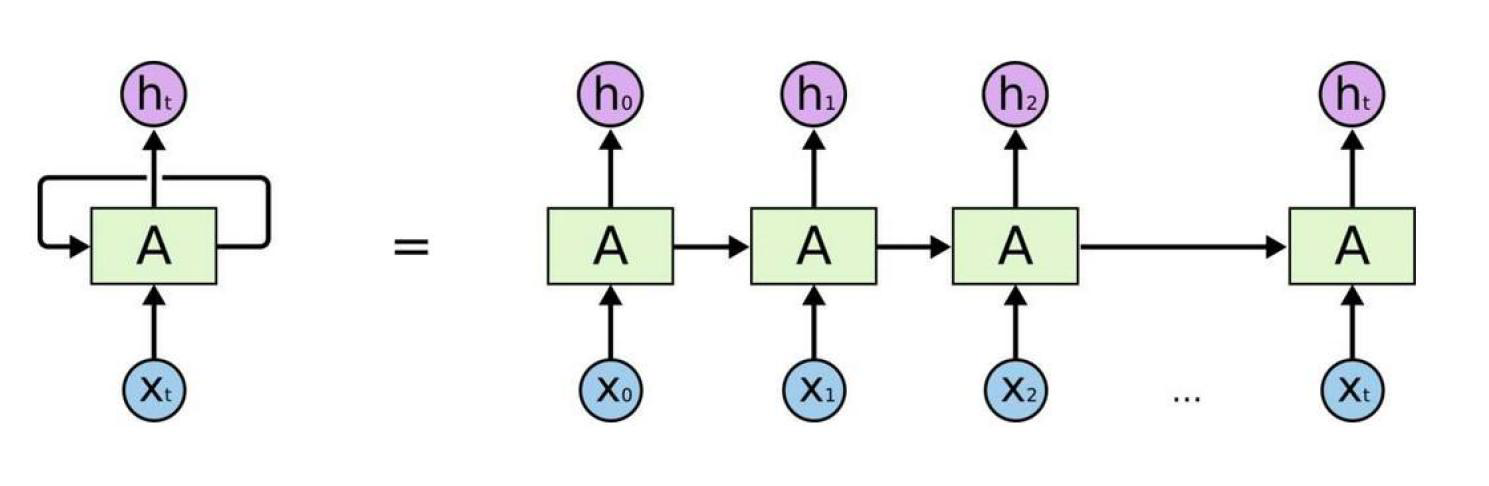
如图所示,是一组向量,它可以看成是一组时间序列,在NLP任务中可以将其看成是一个英文句子,
就是第一个单词。此时
本身也是一组向量,它包含多个特征,即
,d的大小取决如何进行embedding。
在RNN中,它的做法就是将上一个单词的处理结果和当前词一起进行处理,用这个方式进行提取前后或者时间的特征,而实际中只需要一个输出结果,前面的
都当成是中间结果。
如下图所示:
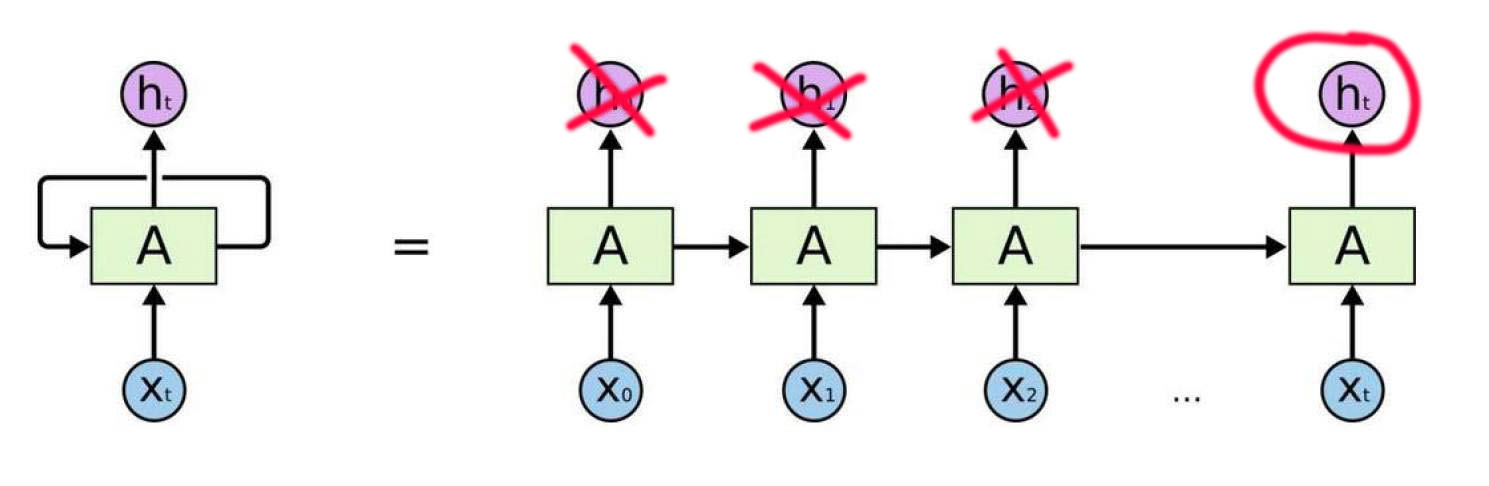
RNN不是我们今天的主角,它只是一个铺垫。就是这种处理方式导致了NLP一直发展的特别缓慢,2012年谷歌发布了word2vec,NLP才开始有一个缓慢的发展,但是实际上还是处于一个要死不活的状态,其实罪魁祸首就是这种RNN结构。一直到2017年Transformer的发布,NLP终于迎来了春天。
现在非常流行大模型,动不动就几百亿几千亿的参数,而RNN这种结构很难进行堆叠,卷积我们可以堆叠几十层,但是我们却从未见过RNN堆叠几十层,所以对于当今大模型时代,RNN就是会被淘汰。
2017年这篇足以封神的论文《Attention is all you need》被提出,彻底改变了NLP停滞不前的局面。
2017这篇论文一经发表,大家都知道了这种Attention机制,出现了群雄割据的情形,直到2018年中下旬google发布了BERT模型结束了这个局面,NLP被BERT所统治。BERT一经发布后,大量研究人员都在BERT基础上进行研究、开发NLP模型,几乎所有的NLP公开数据集都有大量的基于BERT的项目写出的论文,但是大家似乎忘记了Transformer,忘记了BERT也是基于Transformer设计出来的模型。
谷歌是NLP大哥大级别的人物,当年也有一个模型被大家所忽视了,在2018年其实它能和BERT并驾齐驱,它就是第一代gpt模型。gpt和BERT实际都是预训练模型,但是可以说BERT在当时占到了99%的市场。当年你对我(gpt)爱答不理,现在谷歌好像有点高攀不起的感觉了。
国内可能在NLP领域和国外有3年的发展差距。
1.2 Transformer
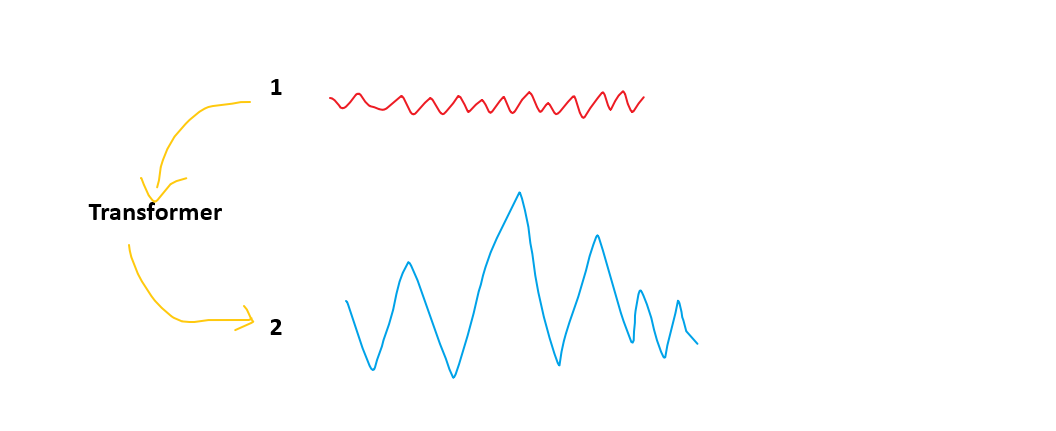
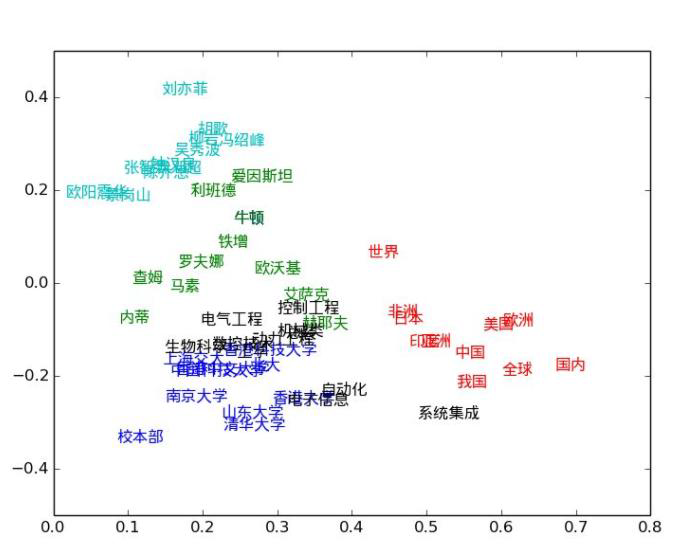
人工智能的本质是什么?实际上就是提取特征,如图所示1号特征和2号特征,很显然机器学习更加喜欢2号特征。因为1号特征之间差距太小,神经网络不那么好记住它,2号就相对来说很好记住。我们用1号特征作为输入,2号特征作为输出,这就是Transformer干的事情。所以Transformer实际上就是整合特征的,把平平无奇的特征整合成一个楞次分明的好特征。
1.3 传统的word2vec
之前是如何进行NLP任务的?最多的是google发布的词向量word2vec,这种表示向量的形式。
之前的NLP任务,比如说有一些词作为输入。比如“世界”作为一个词,它所产生的是一个向量,全球作为一个词也产生一个向量,每个词都是一个向量,每个词都是一个特征。当我们去训练这个模型的时候,每个词所对应的特征会进行更新吗?
我们要训练模型,更新的是什么?是参数,是权重,从未听说过把数据更新了!
但是我们思考一下,数据到底要不要更新呢?该不该更新呢?
对于每一个词,它可能不是独立存在的,它结合到语境中需要结合一下上下文信息。也就是说,同样一个词,在不同场景下表达的意思不同,所以最关键的事情是需要融合一下上下文的信息。
所以Transformer相当于站得高,看得远,能够看到的信息比较多,情商高!
2 Attention
2.1 Attention是什么意思
- 对于输入的数据,你的关注点是什么?
- 如何才能让计算机关注到这些有价值的信息?

比如说你去商场,你对啥感兴趣呢?你对啥感兴趣,你的注意力机制要放在哪儿。对于文本任务,一句话有300个字只有5个字是重点的,那我们就需要分析出来这哪5个字是重点的。
哪个是重点,不是我们自己决定的,是我们的算法我们的模型,在当前的语境计算出来的。
2.2 self-Attention是什么
如图所示的两个句子,第一个句子的it指代的是animal,第二个句子的it指代的是street,两个完全相同的词,在不同的语境中表达出了完全不同的意思。

所以一个词我们需要在上下文中学一学,它是什么意思。
今天晚上吃火锅,在这个句子中,拿今天这个词来说,它需要考虑它和晚上的关系,和吃的关系,和火锅的关系,当然还有自己和自己的关系,这个词它需要考虑全局。
在实际任务中,今天这个词它就需要跟所有的词都学习出一个权重,有了这个权重后,就需要去更新今天这个词的特征。同样的道理今天晚上吃火锅这句话,其他三个词晚上、吃、火锅也进行同样的操作去更新自己的特征。
2.3 self-attention如何计算?
2.3.1如何计算关系
在机器学习中,只有特征。如果要计算两个词之间的关系,首先肯定需要把两个词转化为向量:
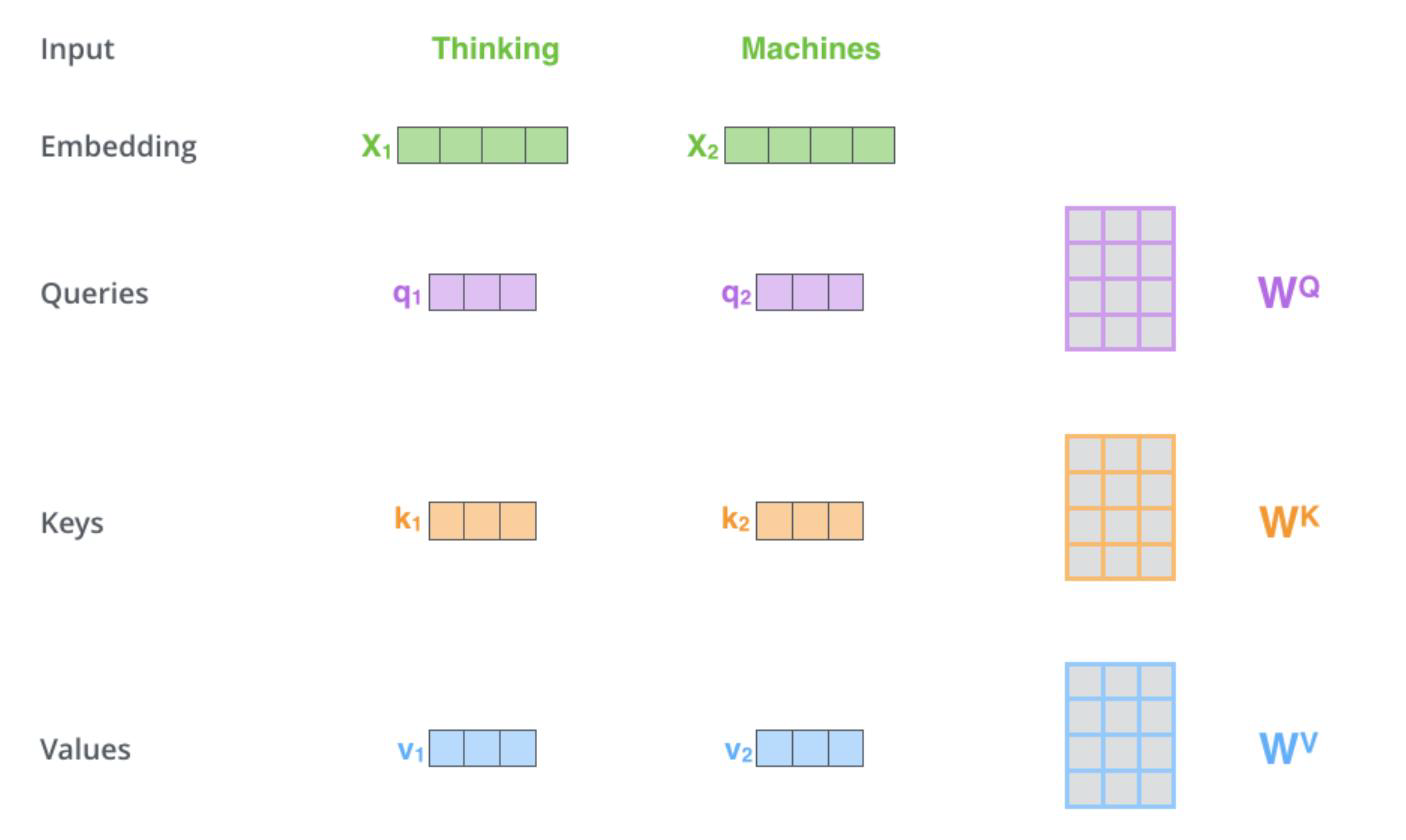
Thinking为x1向量,Machine为x2向量。表示两个向量之间的关系可以用内积的方式,两个向量内积的结果一定是一个值。如果他们正交的话,那就是完全没有关系,内积就为0,如果重合那就关系非常大,算出来的内积的结果的值也会很大。
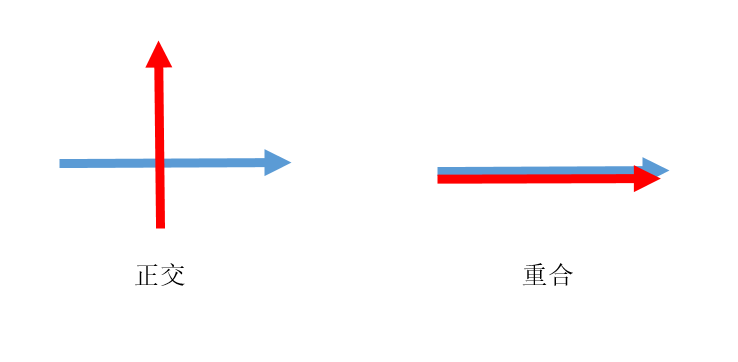
通过内积可以计算关系,那两个词之间的关系是否用内积直接计算呢?在Transformer中没有直接算,而是间接计算两个向量之间的关系。
2.3.2 QKV向量
在首次提出Transformer的论文《Attention is all you need》中的做法是构建出三个辅助向量。
具体为:
- 输入经过编码后得到向量
- 想得到当前词语上下文的关系,可以当作是是加权
- 构建三个矩阵分别来查询当前词跟其他词的关系,以及特征向量的表达
Thinkin和Machine看成是x1和x2两个向量,x1需要计算与x2的关系,还需要计算x1与自己的关系,x1和x2都会通过训练生成属于自己的Q,K,V。
计算x1与x2之间的关系是在x1与x2在生成各自的Q,K,V之后进行的。
- 三个需要训练的矩阵
- Q: query,要去查询的
- K: key,等着被查的
- V: value,实际的特征信息
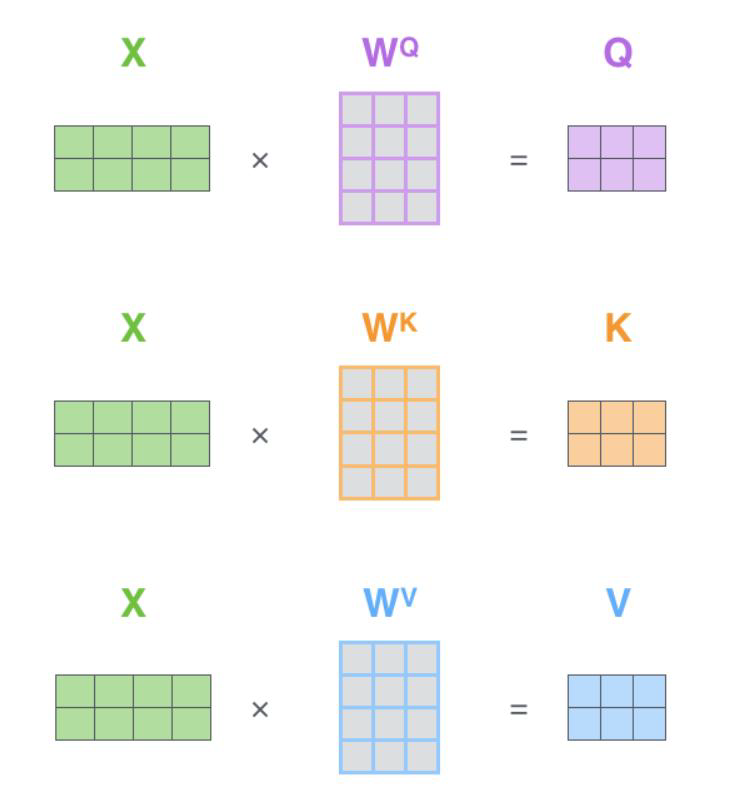
- q与k的内积表示有多匹配
- 输入两个向量得到一个分值
- K: key,等着被查的
- V: value,实际的特征信息
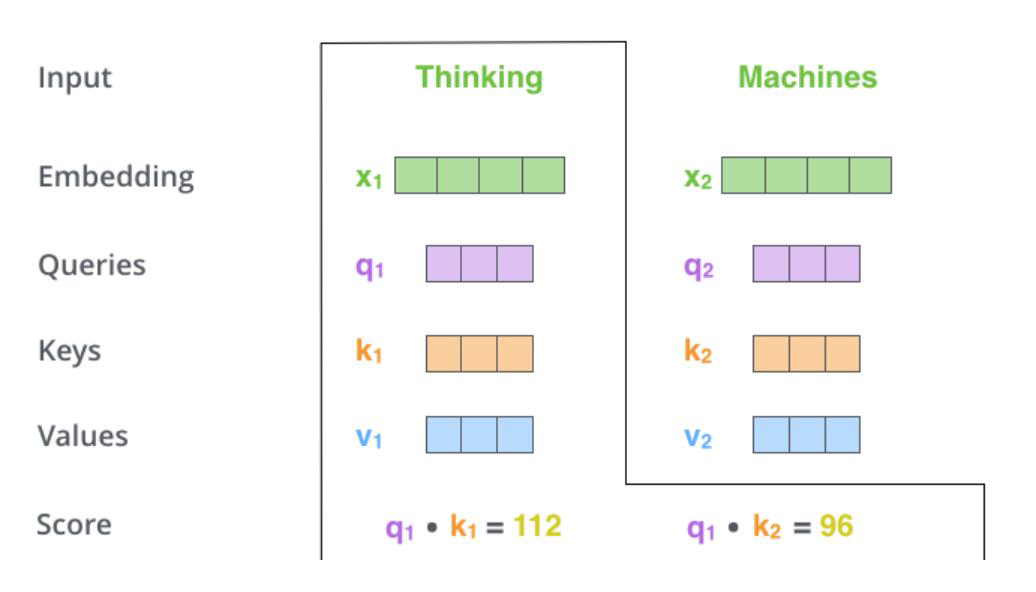
2.3.3计算
- 最终的得分值经过softmax就是最终上下文结果
- Scaled Dot-Product Attention
- 不能让分值随着向量维度的增大而增加(
)
公式中除以的目的:向量的维度越大,内积的结果显然越大,但是这个结果是要表示出两个向量的相似度的,所以除以
就会消除这个影响
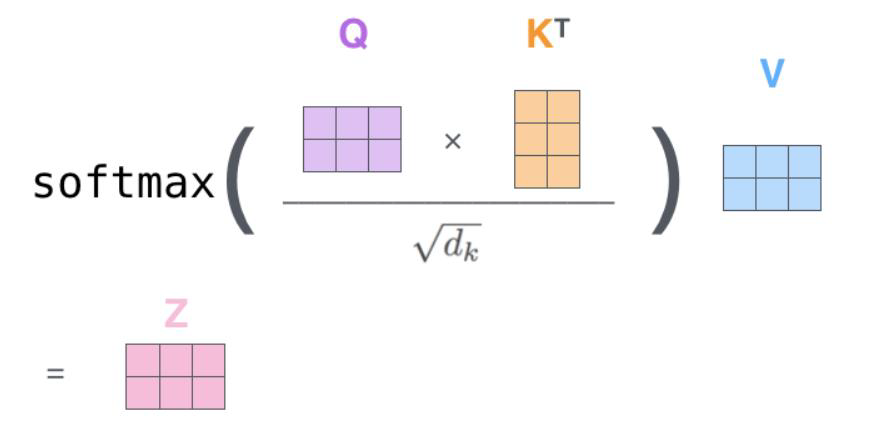
实际的计算流程:
- 假设一个句子有n个词,每一个词都有自己的QKV
- 每一个词都需要与其他所有词计算关系,当前的词需要计算关系时,就会拿出自己的Q向量与其他n-1个词的K向量计算内积再除以
- 当然自己的Q向量也会与自己的k向量计算内积,用来计算自己与自己的关系,同样也要除以
- 一个词计算最后得到n个结果,n个词就会计算出n*n个结果,这个结果被称为注意力分数
- 这n*n个结果,构成一个注意力分数矩阵A,对于A的每一行,都会经过softmax操作将注意力分数转换为注意力权重概率。softmax操作可以保证每行的注意力权重概率之和为1。
- 最终n*n的注意力分数矩阵A变成注意力权重矩阵A'
- 每一个词的v向量维度为
,注意力矩阵A'与n个V向量进行矩阵乘法操作,得到n个Z向量,每个Z向量的维度为
2.4多头注意力机制
- 一组q,k,v得到了一组当前词的特征表达
- 类似卷积神经网络中的filter
- 能不能提取多种特征呢?
- 卷积中的特征图:
也就是参考卷积神经网络的多通道策略,设计多个通道在这里即为多头注意力机制,一个词编码成一个向量,一个向量生成一组QKV,一个向量生成h组QKV可以得到更加丰富的特征,这就是多头注意力机制。可以理解为,一句话可以有多种解读方式。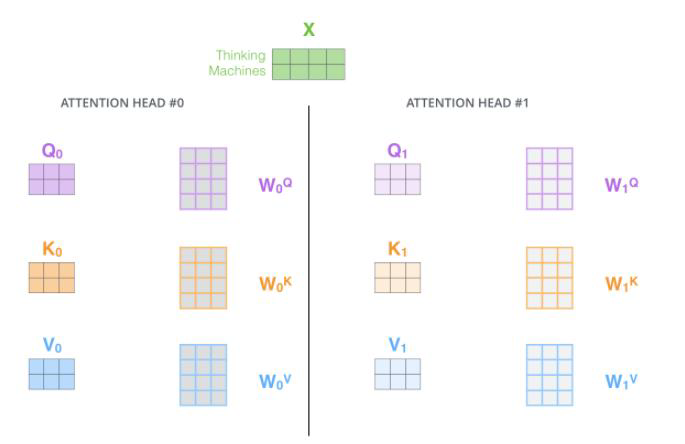
原来的做法是,一个词生成一组QKV,会与其他n个词生成的QKV进行内积计算。多头注意力机制,一个词汇生成h组QKV,那么又该与与其他n个词生成的QKV怎样做计算呢?
还是以一个词为例,假设一个词生成了一组Q,K,V后,然后Q与K与其他的Q与K计算了内积后生成了权重,权重将v向量重构成了Z向量,没有多头注意力机制,Z向量就是这个词的最后表达,如果是多头注意力机制,实际上就会生成h个Z向量。将h个z向量进行拼接,再经过一组可学习权重参数后得到新的Z向量。新的Z向量和原来的Z向量维度一致。
加入多头注意力机制的计算流程,假设为8头:
- 假设一个句子有n个词,每一个词都有自己的8组QKV向量(这8组是同时生成,同时计算的)
- 每一个词都需要与其他所有词计算关系,当前的词需要计算关系时,每一个词的每一个头的Q向量与其他n-1个词对应头的K向量计算内积再除以
- 并不会出现第一头的词与第二头的词进行计算,8组QKV向量同时生成,同时计算,最后得到8组结果
- 当然自己的Q向量也会与自己的k向量计算内积,用来计算自己与自己的关系,同样也要除以
- 一个词的每一头都会计算出n个分数,其中一个分数代表这一头中一个词与另一个词的关系远近。
- n个词就会最后计算出8*n*n个分数,也就是说会计算出8个注意力分数矩阵,每个矩阵为n*n
- 8个注意力分数矩阵,同时计算。每一个注意力分数矩阵A,对于A的每一行,都会经过softmax操作将注意力分数转换为注意力权重概率。softmax操作可以保证每行的注意力权重概率之和为1。
- 最终n*n的8个注意力分数矩阵A变成8个注意力权重矩阵A'
- 每一个词的v向量维度为
,最后每个词都会生成8个Z向量
- 对每个词生成的8个Z向量进行拼接,再乘上一组可学习权重参数,生成新的Z向量,这个新的Z向量的维度与原来的保持不变。
- 多头注意力参考CNN的多通道模式,从多个角度提取特征,如果将这个机制进行可视化,可以表示为:
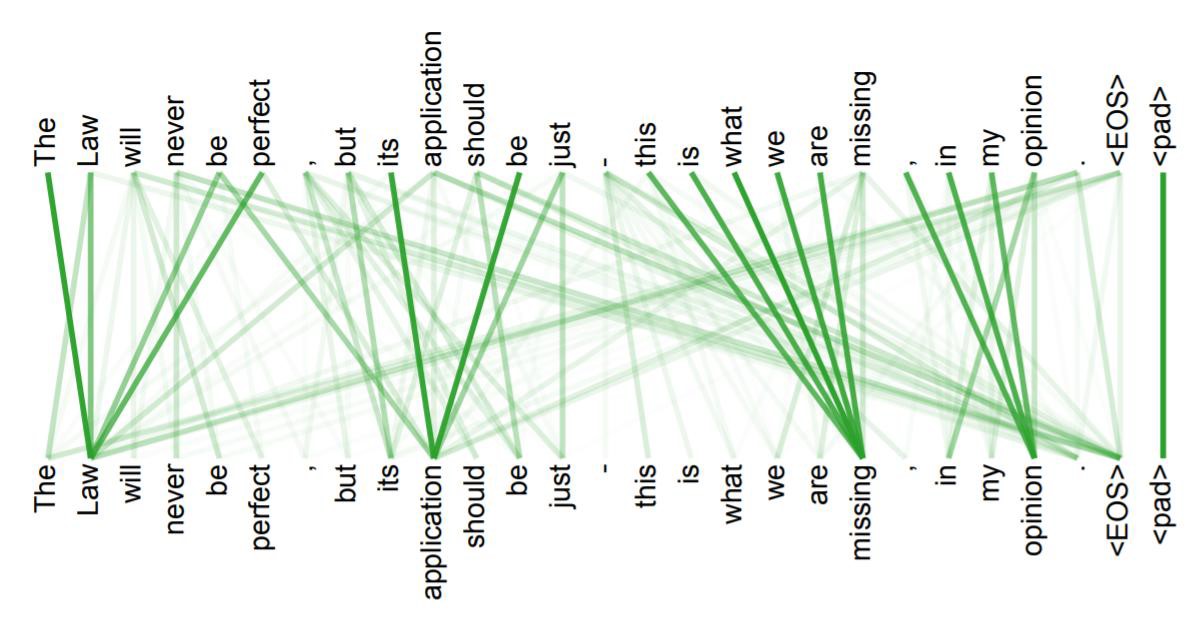
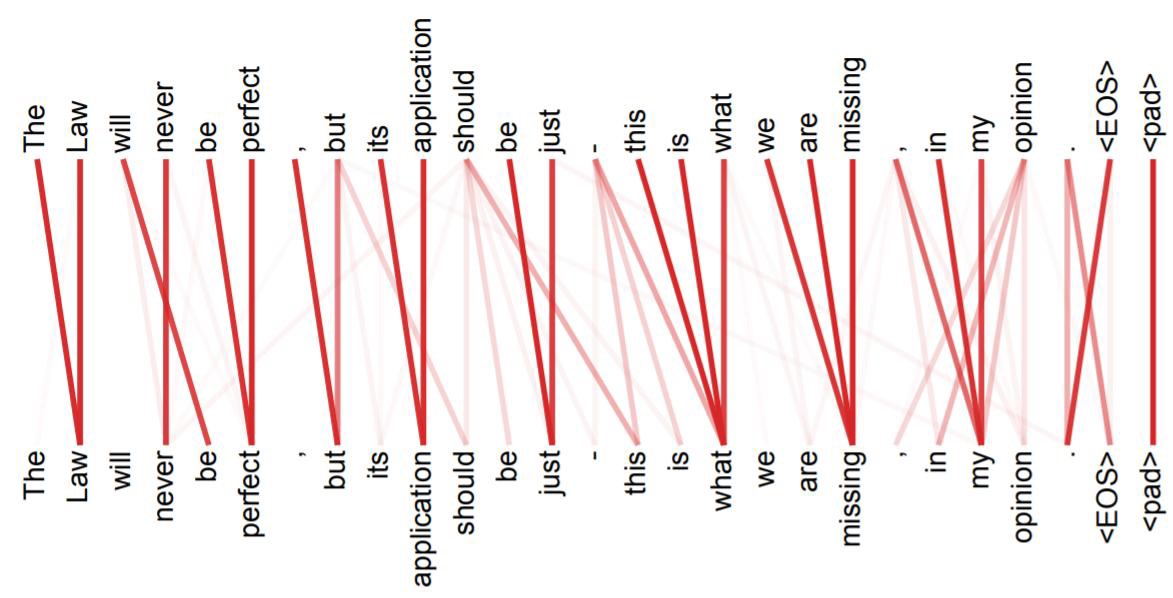
3 位置信息
纯注意力机制没有考虑序列之间的先后关系,那如果在序列中随意变换词与词之间的位置,得到的结果肯定是一样的。所以我们需要对每个词加入位置信息
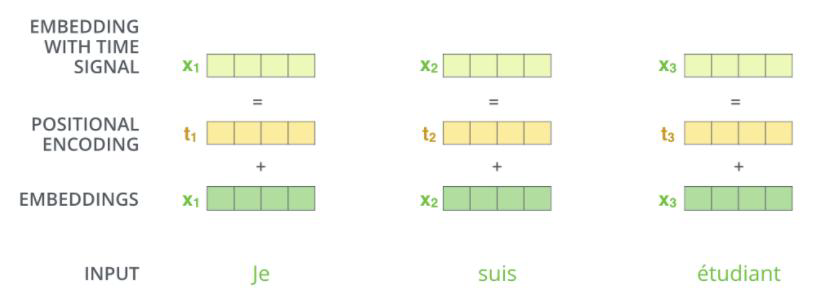
位置编码是需要在最开始输入的时候就进行处理的,最开始的词都被编码成向量如x1,x2,x3,同样要根据位置编码对应的位置向量t1,t2,t3,将x1与t1对应做一个向量加法后生成新的x1,其他编码以此类推,新的向量就包含了位置信息。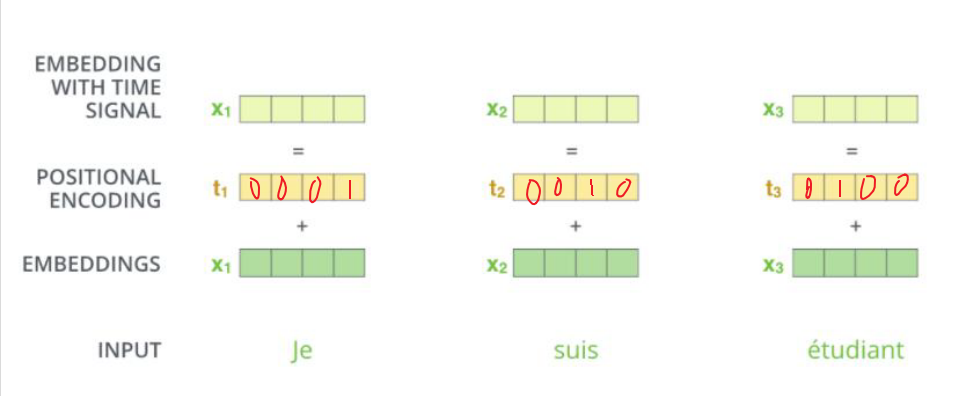
位置编码有多种形式,假如直接用的是一个简单的ont-hot01编码,假设有4个词,第一个词表示为一个4维向量: (0,0,0,1),第二个词为(0,0,1,0),依次类推,n个词即全部表示为n为的向量,如上图所示。
在Transformer中,位置编码是必须要的。
4 堆叠多层
前面所谈到的都是self-Attention,还不是完整意义上的Transformer,它只是Transformer的其中一部分。
在self-Attention中,输入是这个词的特征,输出也是这个词的特征。它就是将这个词融入了一下上下文的语境,相当于重构了一下,维度与特征个数都没有变,特征值变了。
那我们能不能再连一层self-Attention呢?能不能再连10层、20层self-Attention呢?是可以的,因为输入的格式与输出的格式完全一样,写个for循环直接堆叠就可以做到了。堆叠就一定能够把特征做的好吗?这个时候你应该想起一个人,15年的,说起他我真的想给他磕一个,没错!就是何凯明的Resnet,加入残差连接机制就可以完全避免堆叠特征反而变差的问题。就是这个y = f(x)+x策略,y的结果一定不会比f(x)的结果差。
我们自己设计模型的时候,可以任意堆叠4-12层,但是这是nlp啊,chatGPT多少层呢?这个就不知道了,chatGPT实际上就是在堆叠这些self-Attention
5 decoder
前面谈到的是self-Attention,输入是特征,输出也是特征,但是我们结果需要看到的是人类要看到的数据。
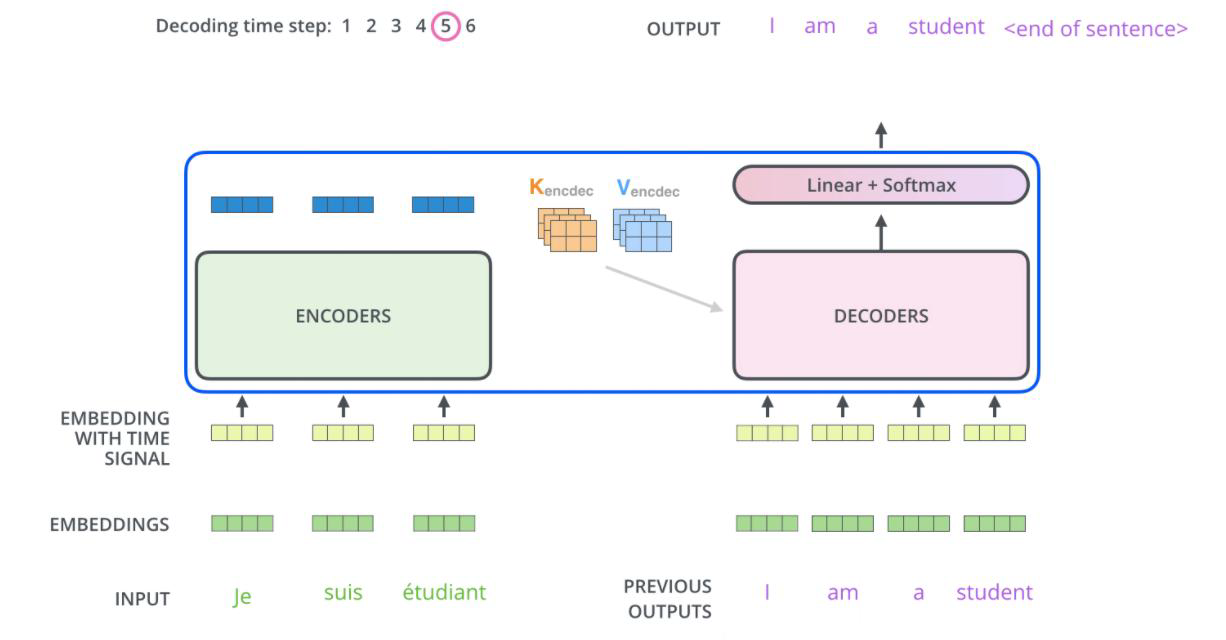
- Attention计算不同
- 加入了MASK机制
decoder的QKV的Q是自己提供的,k和v都是来自encoder的,encoder干了那么多事,就是为了提供这个h和v。
在decoder的输入中,k和v都是从encoder最后一个堆叠模块中输出得到的。
Decoder的Q向量是由Decoder自身的前一个时间步的隐藏状态计算得到的。在Decoder中,每个位置的Q向量会与Encoder的所有位置的K向量进行注意力计算,用来捕捉输入序列中不同位置之间的依赖关系。
那decoder的第一个Q向量是怎么来的呢?
第一个Q向量通常是一个特殊的起始符号(例如,句子开始符号)的嵌入向量。这个起始符号的嵌入向量通常是预训练的,它会作为Decoder的初始输入,用来表示生成序列的开始。当然也可以是通过训练模型学习得到的可学习参数。这取决于具体的实现和训练方法。
那上面图片中,encoder中输出的k和v包含了多个单词(法语),最后怎么生成了I单词呢?对于decoder而言,它的词生成式一个一个生成的,每一个词都要经过两万的分类得到,具体是多少分类取决于给定的词表。
新的QKV再去做QKV的self-Attention的计算。然而不同的是第一个词的q是不可以考虑后面所有词的q的影响的,单词第二个词的q需要考虑前面第一个词的影响,所有的词要考虑前面的词的影响,但是不可以考虑后面的词影响,这就是mask机制。(遮挡!)
从decoder的q来看,它的第一个q是预训练生成的,第二个q就是decoder的第一个q经过decoder的最后输出,decoder的最后输出内容是什么主要是根据任务的不同而不同。如果是时间序列的预测,很显然需要得到上一个时刻的数据才能预测当前时刻的数据,而当前时刻的数据也只能从之前的数据中预测,无法从未来的数据预测当前的数据,所以需要mask机制。机器翻译的任务因此只能一个词一个词的生成。
6 最终输出结果
- 得出最终预测结果
- 损失函数 cross-entropy即可
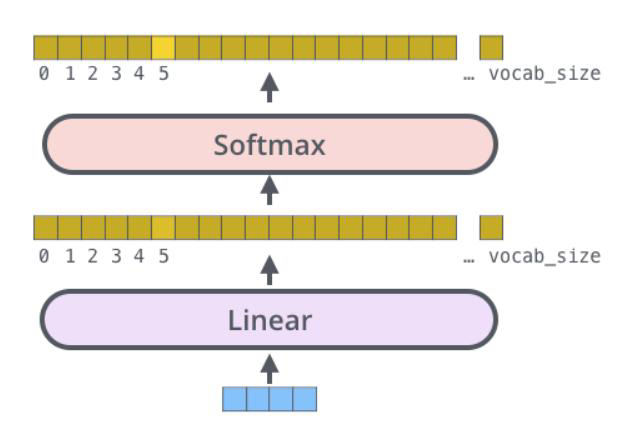
首先明确一点,文本任务基本就是分类任务。输入是一个特征(一个向量),最后的输出一定需要进入一个全连接层进行一个维度变换,将原来的维度变成是两万维度的,这个两万个值,再去softmax进行概率分布计算。
当然在视觉任务中,分类回归都有可能出现。
7 整体梳理
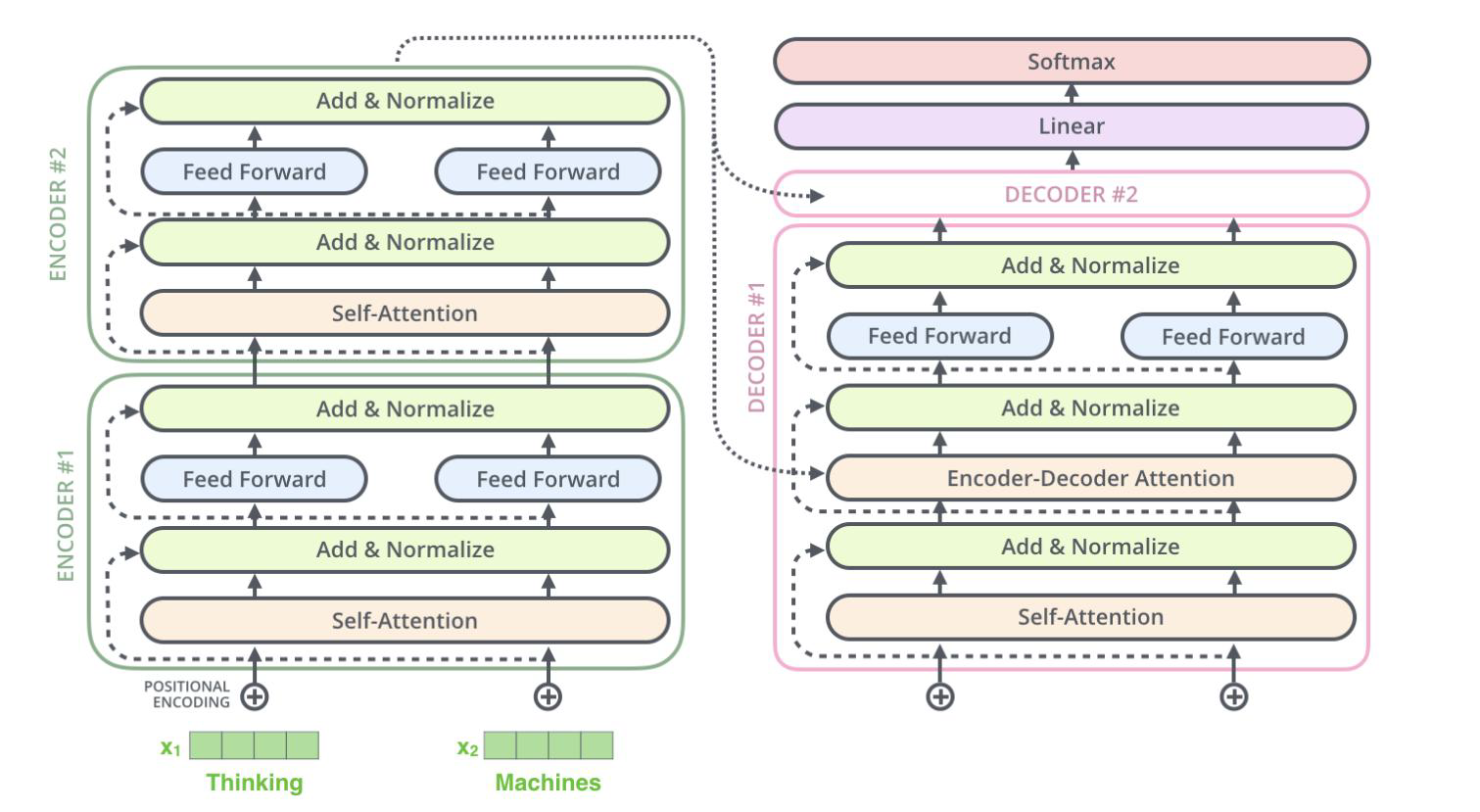
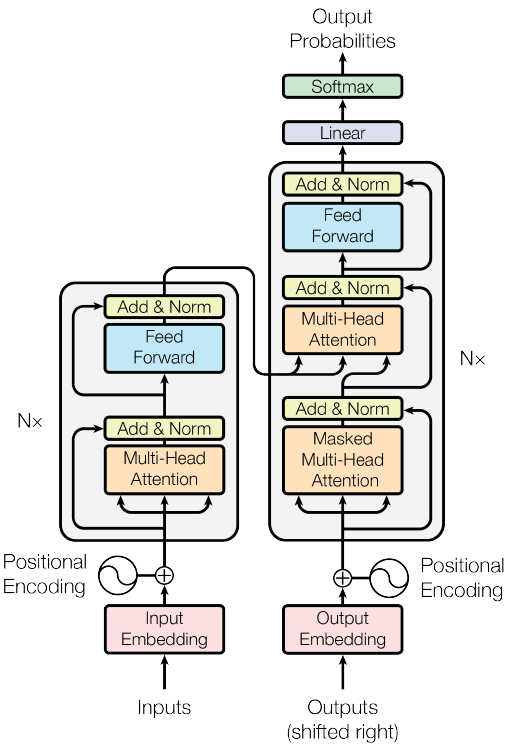
- Self-Attention
- Multi-Head
- 多层堆叠,位置编码
- 并行加速训练
- 编码器中首先一句英文做Inputs输入,经过Embedding(词嵌入)变成向量
- 加入位置编码向量与词向量融合
- 生成QKV经过多头注意力,进行残差连接和归一化
- 经过全连接再进行残差连接和归一化
- 3-4步多次进行,因为要堆叠N次,常用Transformer是6次
- 解码器首先得到所有已经生成的词,经过Embedding(词嵌入)变成向量
- 同样的加入位置编码向量与词向量融合
- 生成QKV经过掩码多头注意力,进行残差连接和归一化
- 8的输出作为Q,从编码器的最后输出取出K和V
- QKV经过多头注意力,进行残差连接和归一化
- 经过全连接再进行残差连接和归一化
- 同样的8-11重复进行6次
- 根据词库使用FC将维度变换为两万
- 使用softmax对两个单词进行概率分布的计算,概率最高的那个单词取出,即生成了一个单词
- 再去第6步,继续生成下一个单词



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











