







 本文详细介绍了如何安装和配置Doccano文本标注工具,包括安装步骤、参数设置和使用方法,同时提及了与NLP相关的命名实体识别和Transformer技术的应用。
本文详细介绍了如何安装和配置Doccano文本标注工具,包括安装步骤、参数设置和使用方法,同时提及了与NLP相关的命名实体识别和Transformer技术的应用。
目录
这篇文章是专门的安装教程,后续的项目创建,如何使用,以及代码部分可以参考这篇文章:
NER实战:(NLP实战/命名实体识别/文本标注/Doccano工具使用/关键信息抽取/Token分类/源码解读/代码逐行解读)_会害羞的杨卓越的博客-CSDN博客
1、安装说明
doccano是documment anotation的缩写,是一个开源的文本标注工具,我们可以用它为NLP任务的语料库进行打标。
Doccano是一个非常好用的开源工具,用起来很方便,安装也不麻烦。
首先不要着急去查百度,在github就有安装说明。
安装说明:
- pip (Python 3.8+)
- Docker
- Docker Compose
pip (Python 3.8+),要求Python环境是3.8以上,但是如果你深度学习环境一套都是3.8以下的,你新建一个python环境就行了,这个工具就只需要标注文本,标注的时候切换到Doccano环境就行了。
2、安装doccano
在prompt中cd到python环境的scripts文件夹(每个conda的python环境都有一个script文件夹)中,如果不知道自己的scripts文件夹在哪儿参考一下我的:
C:\Users\Alex\anaconda3\envs\NER\Scripts看我的是在这里,我自己新建了一个NER的python环境:
在prompt界面进行操作:
 安装指令:
安装指令:
pip install doccano如果安装太慢,就使用清华镜像:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple doccano3、相关参数设置
安装完成后,进行初始化操作:
# Initialize database.
doccano init设置用户名和密码:
# Create a super user.
doccano createuser --username admin --password pass设置用户名密码的时候,自己一定要记得,如果你没改的话,就是默认的账号名为admin,密码就是pass了,这个账号密码就是是存在云端的。
接着设置服务器端口:
# Start a web server.
doccano webserver --port 8000这是打开端口成功的界面:

这步做完后,一定要
再打开一个prompt命令窗口,再次cd到scripts文件夹
再打开一个prompt命令窗口,再次cd到scripts文件夹
再打开一个prompt命令窗口,再次cd到scripts文件夹
然后执行以下指令启动服务:
# Start the task queue to handle file upload/download.
doccano task启动成功的页面
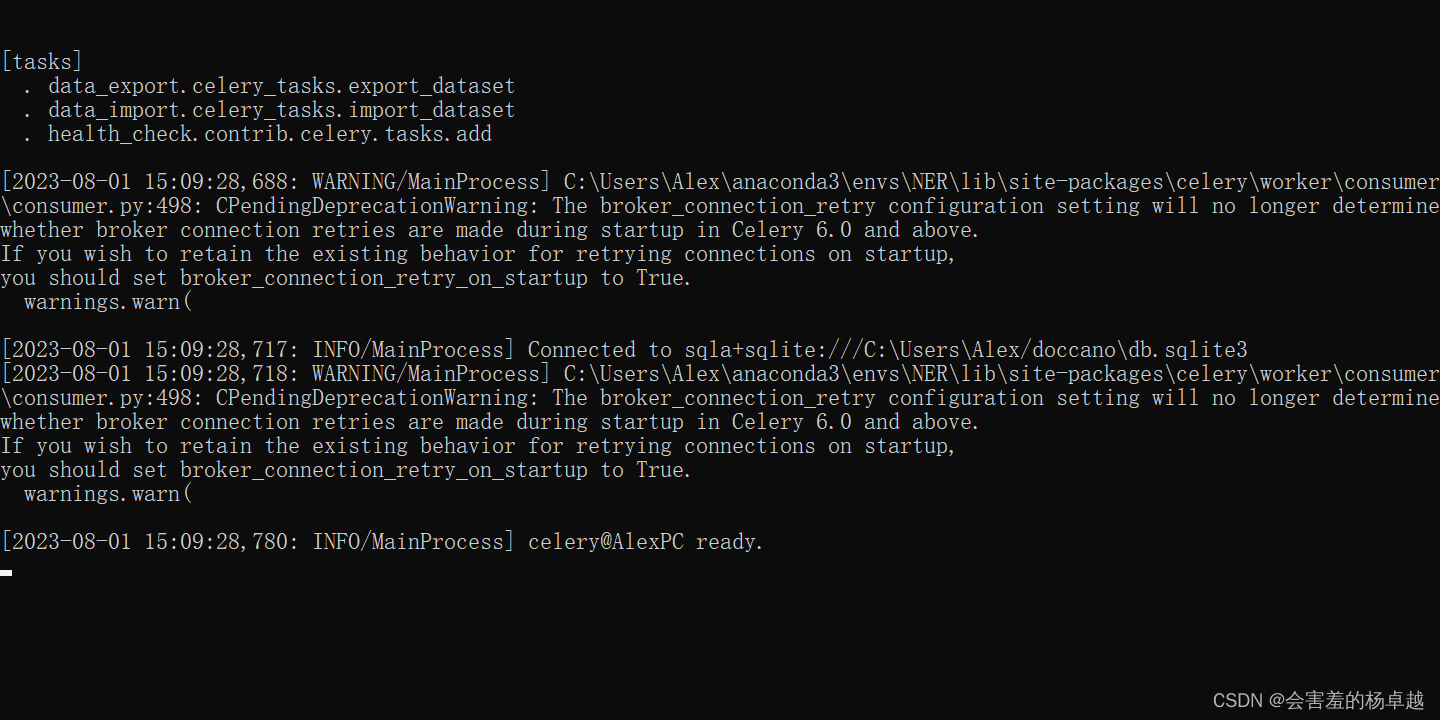
4、使用doccano
服务启动成功后,进入这个地址打开:
打开后的页面是这样:
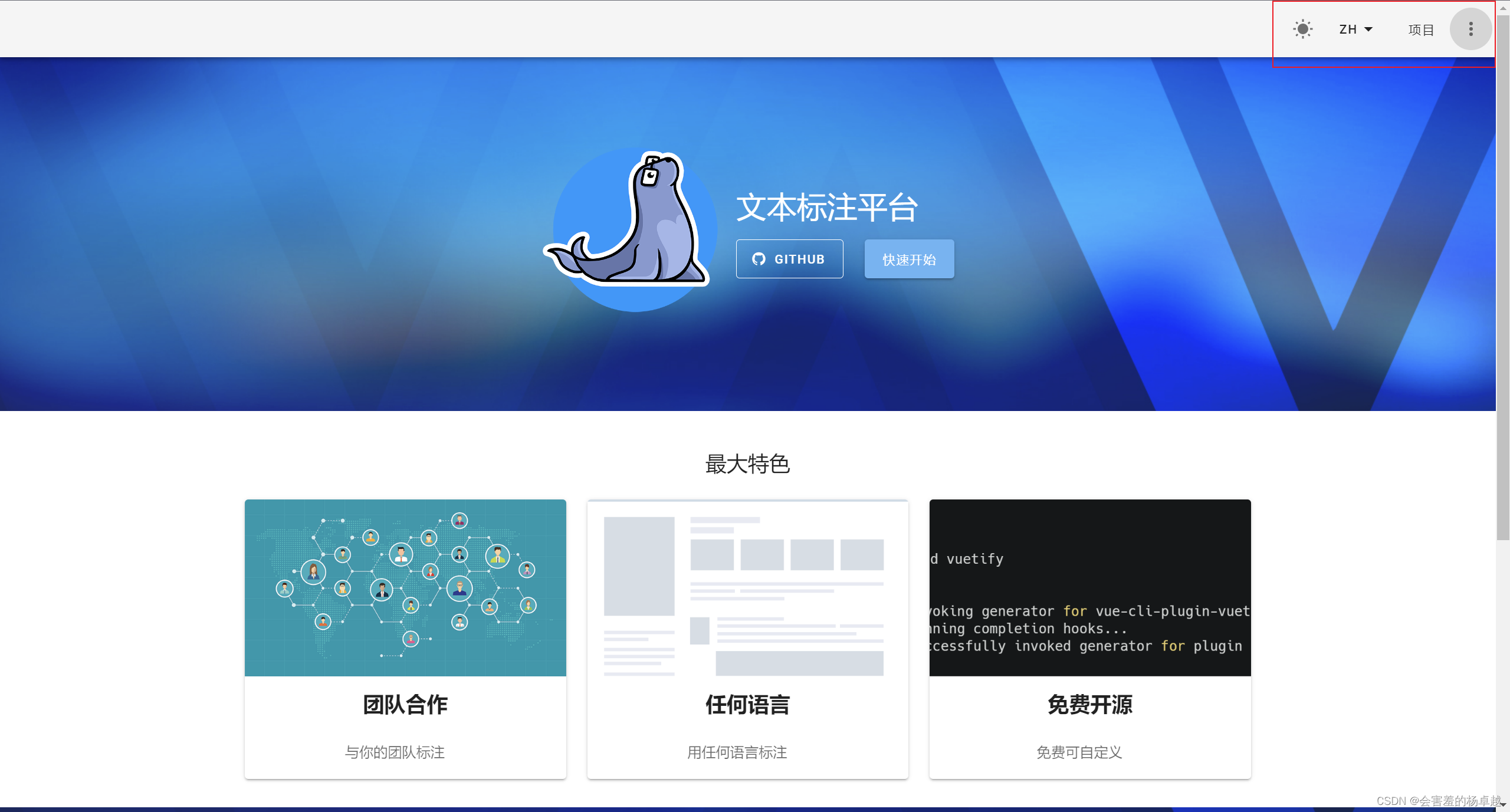
到这里doccano的安装与设置就结束了。
点击右上角进行登录,登录的账号和密码就是前面你自己设置的。
登录后点击开始进入这个页面
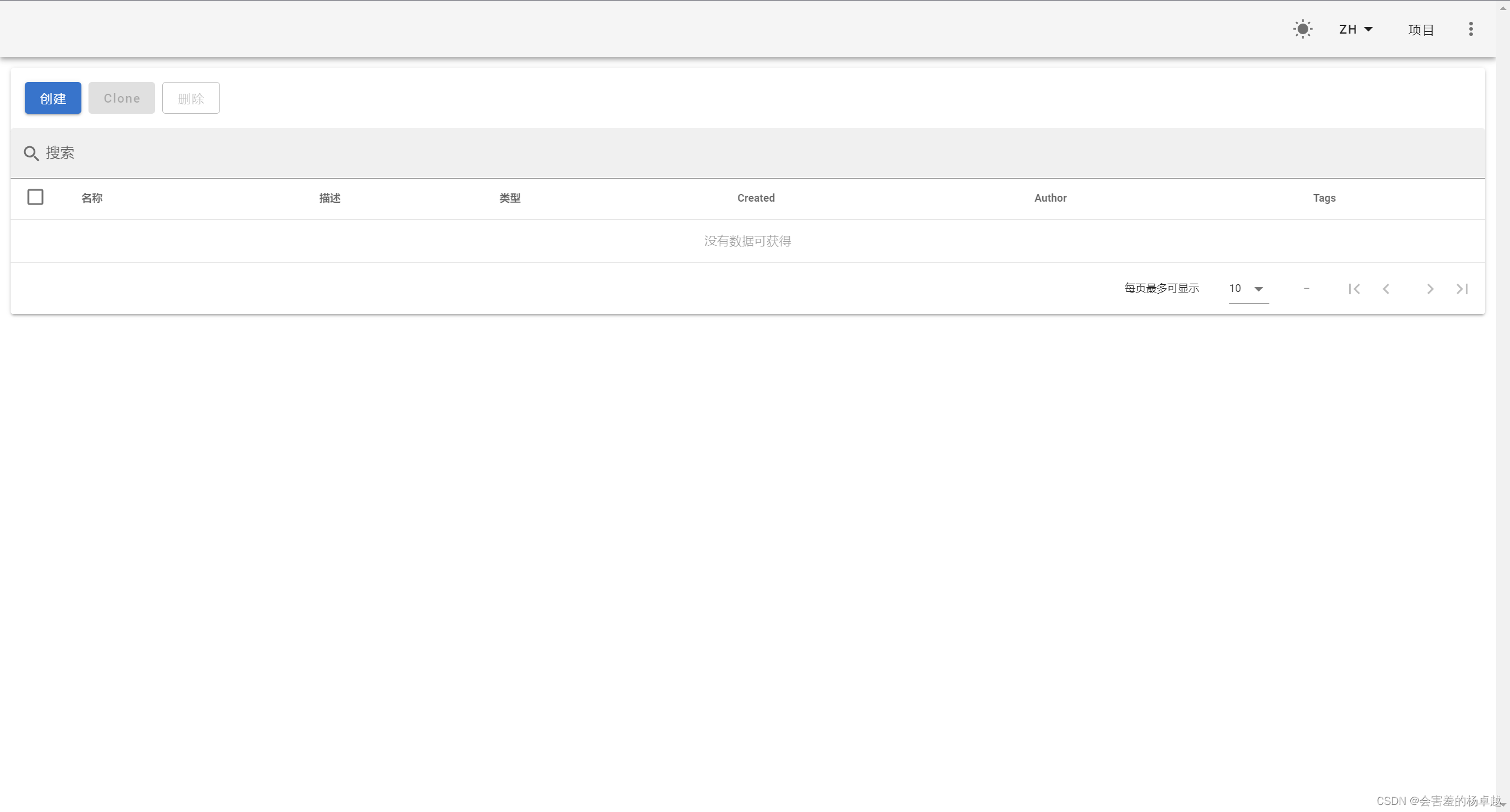
到了这里就可以开始创建自己的项目了,你已经完成了doccano文本标注工具的构建。
陆续更新中,有用的话拜托点赞收藏哦。
后续的项目创建,以及如何进行分词,中文分词,请参考这篇文章:
NER实战:(NLP实战/命名实体识别/文本标注/Doccano工具使用/关键信息抽取/Token分类/源码解读/代码逐行解读)_会害羞的杨卓越的博客-CSDN博客
5 优质文章
🧡💛💚💙💜Transformer提出文章论文精读
Transformer:《Attention is all you need》(论文精读/原理解析/模型架构解读/源码解析/相关知识点解析/相关资源提供)_会害羞的杨卓越的博客-CSDN博客
🧡💛💚💙💜Transformer解读:
Transformer算法解读(self-Attention/位置编码/多头注意力/掩码机制/QKV/Transformer堆叠/encoder/decoder)_会害羞的杨卓越的博客-CSDN博客
🧡💛💚💙💜Hugging Face实战
Hugging Face实战(NLP实战/Transformer实战/预训练模型/分词器/模型微调/模型自动选择/PyTorch版本/代码逐行解析)上篇之模型调用_会害羞的杨卓越的博客-CSDN博客
🧡💛💚💙💜bert系列算法
BERT系列算法解读:(RoBERTa/ALBERT/DistilBERT/Transformer/Hugging Face/NLP/预训练模型/模型蒸馏)_会害羞的杨卓越的博客-CSDN博客
🧡💛💚💙💜包括一些大方向的内容
人工智能的分类:机器学习/专家系统/推荐系统/知识图谱/强化学习/迁移学习/特征工程/模式识别_会害羞的杨卓越的博客-CSDN博客
🧡💛💚💙💜计算机视觉
陆续更新中,有用的话拜托点赞收藏哦。


















 6161
6161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











