







本章通过实际案例,记录基础的数据预处理方法,以python的sklearn库的dataSets模块的案例为例进行测试和处理,同时对代码中的一些参数取值进行说明。
1、数据导入
参数return_X_y=True表示返回两个变量,分别是元素的目标矩阵X和目标变量y,并赋值给我们的自定义的参数wine_sets_X和wine_sets_y。
#导入数据集
wine_sets_X,wine_sets_y=datasets.load_wine(return_X_y=True)2、查看缺失值
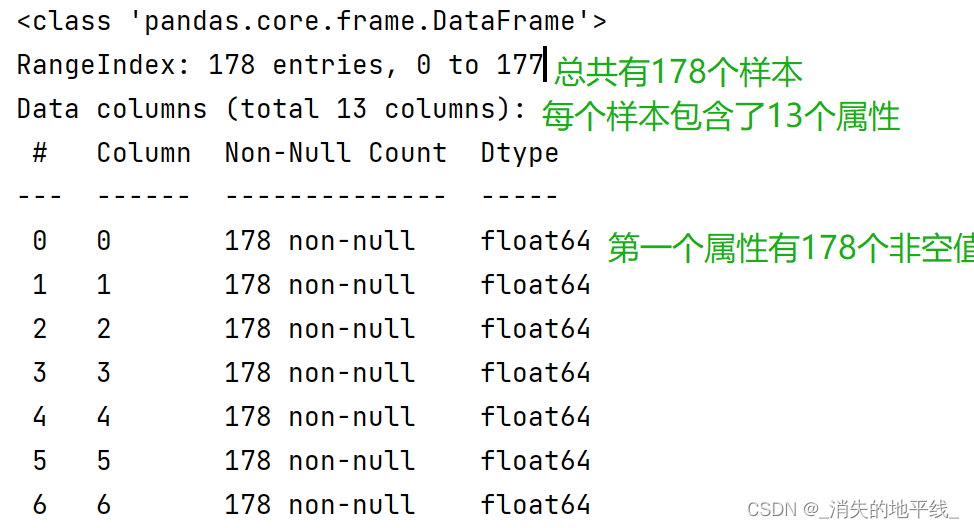
需要注意的是,在查看缺失值之前,需要先转化为DataFrame对象,才能使用DataFrame的特定内置函数进行分析。使用info()函数查看数据的基本描述信息,并通过print进行打印。
#查看是否有缺失值
dataFrame=pd.DataFrame(wine_sets_X)#先转化为DataFrame对象
datainfo=dataFrame.info()#查看基本信息
print(datainfo)结果和解释入下图所示:
3、缺失值的处理(如果有缺失值的情况下)
#缺失值处理方法
#1、直接删除
dataFrame=dataFrame.dropna()#删除包含缺失值所在的行
#dataFrame=dataFrame.dropna(axis=1)#删除包含缺失值所在的列
#2、用均值进行填充
dataFrame=dataFrame.fillna(dataFrame.mean())#用均值来填充缺失值
#3、使用插值的方式填充数据
dataFrame=dataFrame.interpolate(method="linear")#线性插值
dataFrame=dataFrame.interpolate(method="spline",order=3)#order表示插值多项式的阶数(这个例子是三次样条插值)4、判断样本是否平衡
也就是说,看一下归属于某个属性的样本数量是否严重过多或者过少,因为只需要看样本的类型,所以我们单独取出了wine_sets_y将其转化为Series对象来看。同时,将结果转化为饼图来进行直观化的描述,注意使用value_counts函数分析时,参数normalize=True表示只显示百分比,为False时只显示各个类型的个数。
#判断样本是否平衡
#使用value_counts()函数,适用于Series或者DataFrame对象
data_series=pd.Series(wine_sets_y)
print(data_series.value_counts())#显示个数
print(data_series.value_counts(normalize=True))#显示百分比
plt.pie(data_series.value_counts(normalize=True),labels=['第一类','第二类','第三类'],autopct='%0.01f%%')
plt.show()结果:


5、样本不平衡前提下的处理方法
#解决样本不平衡问题
from imblearn.over_sampling import RandomOverSampler
overSample=RandomOverSampler()#使用过采样的方法处理样本不平衡问题
X_train_res,y_train_res=overSample.fit_resample(wine_sets_X,wine_sets_y)
6、打乱数据集的顺序,避免划分训练测试集时出现样本不平衡情况
第一:注意设置随机数种子,确定随机数的生成路径,使得随机数生成过程可重复。
第二:注意permutation的参数是数据集的长度n而不是整个数据集。传入参数后,其返回值是一个长度为n,连续乱序的0~n-1组成的数组,之后可以利用该数组对数据集打乱顺序。
#随机打乱顺序,便于后续划分训练集和测试集
np.random.seed(0)
precess1=np.random.permutation(len(wine_sets_X))
new_wine_setsX=wine_sets_X[precess1]
print("打乱顺序后的属性集:")
print(new_wine_setsX)
new_wine_setsy=wine_sets_y[precess1]
print("打乱顺序后的标签是:")
print(new_wine_setsy)7、样本划分
#在样本量过大的情况下,引入sklearn库进行样本划分
from sklearn.model_selection import train_test_split
train_X,train_y,test_X,test_y=train_test_split(new_wine_setsX,new_wine_setsy,test_size=0.2)
print("测试集标签:")
print(test_y)
整个代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#设置默认使用中文字体
from sklearn import datasets
#导入数据集
wine_sets_X,wine_sets_y=datasets.load_wine(return_X_y=True)
#查看是否有缺失值
dataFrame=pd.DataFrame(wine_sets_X)#先转化为DataFrame对象
datainfo=dataFrame.info()#查看基本信息
print(datainfo)
#缺失值处理方法
#1、直接删除
dataFrame=dataFrame.dropna()#删除包含缺失值所在的行
#dataFrame=dataFrame.dropna(axis=1)#删除包含缺失值所在的列
#2、用均值进行填充
dataFrame=dataFrame.fillna(dataFrame.mean())#用均值来填充缺失值
#3、使用插值的方式填充数据
dataFrame=dataFrame.interpolate(method="linear")#线性插值
dataFrame=dataFrame.interpolate(method="spline",order=3)#order表示插值多项式的阶数(这个例子是三次样条插值)
#判断样本是否平衡
#使用value_counts()函数,适用于Series或者DataFrame对象
data_series=pd.Series(wine_sets_y)
print(data_series.value_counts())#显示个数
print(data_series.value_counts(normalize=True))#显示百分比
plt.pie(data_series.value_counts(normalize=True),labels=['第一类','第二类','第三类'],autopct='%0.01f%%')
plt.show()
#解决样本不平衡问题
from imblearn.over_sampling import RandomOverSampler
overSample=RandomOverSampler()#使用过采样的方法处理样本不平衡问题
X_train_res,y_train_res=overSample.fit_resample(wine_sets_X,wine_sets_y)
#随机打乱顺序,便于后续划分训练集和测试集
np.random.seed(0)
precess1=np.random.permutation(len(wine_sets_X))
new_wine_setsX=wine_sets_X[precess1]
print("打乱顺序后的属性集:")
print(new_wine_setsX)
new_wine_setsy=wine_sets_y[precess1]
print("打乱顺序后的标签是:")
print(new_wine_setsy)
#在样本量过大的情况下,引入sklearn库进行样本划分
from sklearn.model_selection import train_test_split
train_X,train_y,test_X,test_y=train_test_split(new_wine_setsX,new_wine_setsy,test_size=0.2)
print("测试集标签:")
print(test_y)














 3966
3966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









