







目录
1、进程控制块PCB
为了描述控制进程的运行,系统中存放进程的管理和控制信息的数据结构称为进程控制块(PCB)。它是进程管理和控制的最重要的数据结构,每一个进程系统都会为其创建一个PCB。系统在创建进程时,建立PCB,伴随进程运行的全过程,直到进程撤消而撤消。
PCB的内容信息包括:
标示符(pid):描述本进程的唯一标示符,用来区别其他进程
状态:任务状态,退出代码,退出信号等。
优先级:相对于其他进程的优先级。
程序计数器:程序中即将被执行的下一条指令的地址。
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息。
在进程复制后,需要使用pid对父子进程进行区别。
2、fork()函数
需要引用的头文件为:<unistd.h>;其返回值为 pid_t 型,实质为整型。
使用 fork() 函数,就可以实现进程的复制。被复制的进程称为父进程;新复制生成的进程称为子进程。父进程的PCB和缓冲区都会被复制新的一份给子进程。
在 fork() 函数执行时,当前进程被复制,产生了两个进程。此时,可以根据fork()函数的返回值对父子进程进行区分。fork()函数一执行,父、子进程立刻产生,然后分别执行,fork()函数在父、子进程中分别进行返回值操作:在父进程中返回值 > 0,在子进程中返回值 == 0。
在执行完 fork() 函数后,两进程各自执行,但两进程源代码相同。要想两进程执行不同的操作,就需要在源代码中fork()函数之后,根据fork()返回值添加逻辑判断,让两进程在执行时进入不同的执行逻辑。
例如:


此时,可以看到在源代码中添加了逻辑判断后,结果却打印出了两句话,这就是父子进程分别执行的结果。
3、getpid()、getppid()
pid_t getpid(void); //获取当前进程的pid
pid_t getppid(void); //获取当前进程的父进程的pid
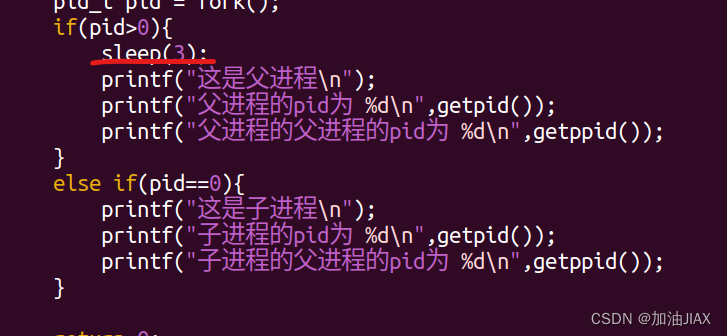
此时,修改a.c代码如上,让子进程先运行,父进程后执行,并且在执行时打印其各自pid与各自父进程的pid。

通过运行结果,可以看到子进程的父进程pid就是父进程的pid。并且通常,子进程的pid = 父进程的pid + 1。
4、写时拷贝
思考:复制后产生的父子进程的原来的变量是不是同一个(在同一个物理内存地址中)?

进程在物理内存中是以分页的形式存在的。系统根据程序内容,将其保存在不同分页,映射到物理内存中,逻辑上还是一个整体。
对于代码量较大、变量较多的程序,如果进行进程复制时,将所有东西都进行复制,那需要复制的东西太多了。如果有的变量值不会被父子进程修改(只访问),一个分页上的内容没有改变,那就没有多余复制一份的必要;如果变量值会被修改,那子进程就将其分页复制一份(对于子进程,逻辑上还是那个变量,但物理地址与父进程的变量不同)。这就是写时拷贝。
5、缓冲区被复制
Linux对于数据输入、输出设有缓冲区。
缓冲区被刷新的四种情况:
(1)缓冲区满。
(2)遇见 \n 。强制刷新。如:printf("A\n");
(3)程序结束前。
(4)碰见fflush()。强制刷新。
若缓冲区未被刷新,则其内容会被复制给子进程。如:
缓冲区被刷新:
int main(){
for(int i=0;i<2;++i){
fork();
printf("A\n");
}
}
第一次循环,产生父子两个进程,进行printf,并刷新缓冲区,打印出两个A;第二次循环,原父子进程分别进行复制,产生了4个进程,分别打印A。最终产生6个A。
缓冲区未刷新:

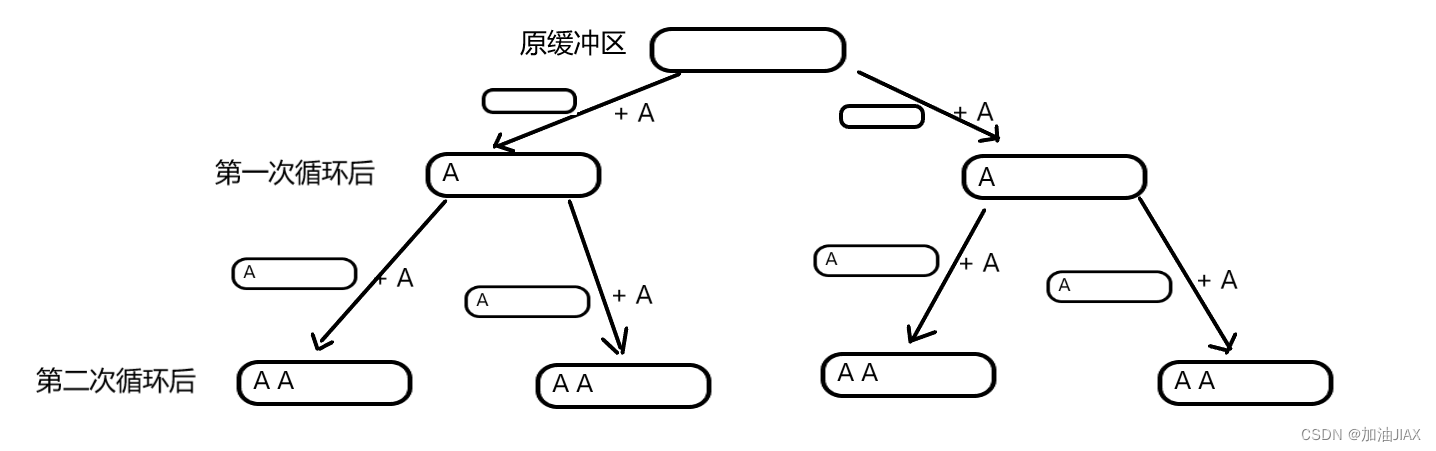
最终产生四个进程,四个缓冲区,每个缓冲区中两个A,所以最终8个A。
6、僵尸进程
6.1、产生原因
子进程先运行结束,而父进程未运行结束,父进程未获取子进程的退出码。子进程运行结束后,会产生一个退出码(一字节大小)。在父进程将退出码接收后,子进程的PCB才会被系统回收,子进程才算完全结束,否则,子进程会变成僵尸进程。
PCB是一个结构体型数据,若有大量僵尸进程产生,会导致大量PCB被占用,不及时释放,就会导致系统资源被浪费。
在3中演示父子进程的pid时,让子进程先运行,父进程后运行,这就导致了僵尸进程的产生。
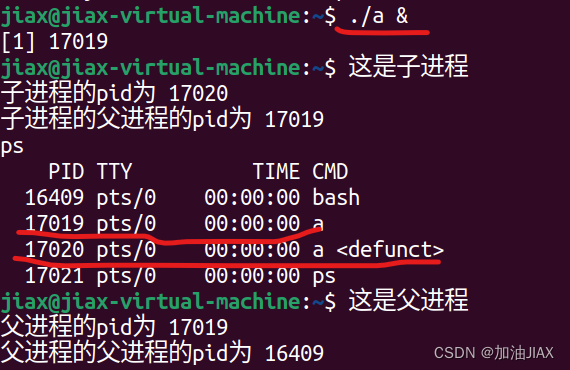
此时,让a程序进入后台运行(前台运行的同时不能运行其他命令),子进程立刻运行,将结果打印出来。使用 ps 命令,查看目前运行中的进程,会发现有两个 a 进程,并且子进程a 最右侧有一个 <defunct> 标志。这就表明:现在子进程是僵尸进程。
6.2、解决方法
在父进程运行结束时,会获取子进程的退出码,但这不够及时。若父进程运行时间很长,会导致资源被长时间占用。所以,需要让父进程主动获取子进程的退出码:使用 wait() 函数。
#include<sys/wait.h> //所需头文件
pid_t wait(int* wstaus); //用wstatus指针将子进程退出码带出
wait()函数会将父进程阻塞,等待子进程运行完成,获取子进程的退出码后,再让父进程运行。
当前,我们不知道子进程的退出码是多少,并且退出码是1字节大小,但用4字节的wstatus带出来,我们不知道它在哪一字节保存。可以配合WIFEXITED(int wstatus)函数进行验证子进程是否成功退出,使用WEXITSTATUS(int wstatus)函数将退出码进行截取并返回。
例如:
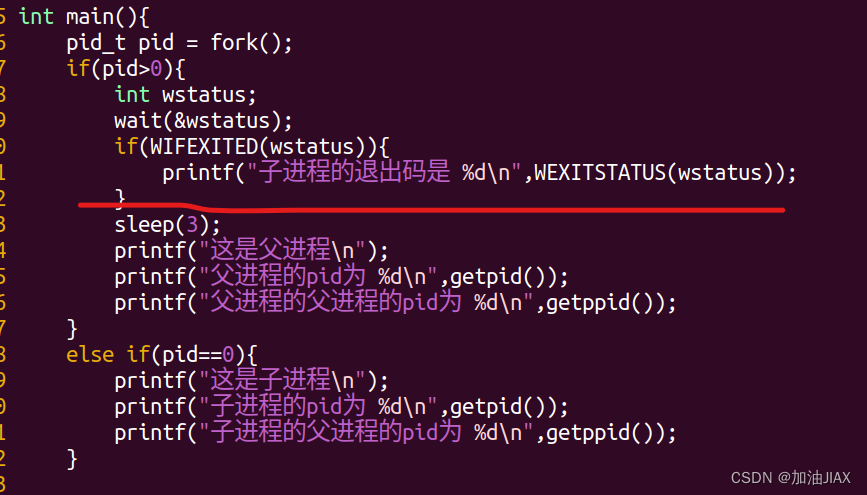
此时,让父进程阻塞,子进程先运行,然后回收其退出码,再让父进程运行。

在运行时就可以看到没有僵尸子进程出现。
7、孤儿进程
若我们将执行顺序调换,让子进程睡眠一会儿,让父进程先执行完,这就会导致一种新的情况产生:子进程变成孤儿进程。


通过上图,可以看到,子进程的父进程不再是原来的父进程;而父进程的父进程是bash进程。
bash是shell的一种,最通用。shell是用户与Linux内核交互的接口程序(命令解释器)。在终端输入命令,经shell解释命令后,传递给内核;内核解析命令,执行,输出结果。
所有进程都有父进程。原父进程可以看作由bush复制,替换后产生(进程替换)的子进程,所以其父进程为bash。
对于上图的子进程,由于其父进程运行结束,被回收,消亡了,所以系统用一个新进程Init收留这个孤儿进程。所以子进程的父进程不再是原父进程。















 5438
5438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









