







文章目录
0. 前言
这篇分享笔者继续回归Golang的底层源码,尝试着从what-how-why三个维度探讨Golang中重要集合map的底层实现,着重讲解map的底层数据结构及其增删改查的执行流程,不关心map的具体使用。
1. 什么是map
在计算机科学中,map是一个由一组key-value键值对组成的集合,并且每个key只能出现一次,不能重复。
1.1 散列函数
散列技术是在value的存储位置和key之间建立一个对应关系f,使得每个关键字key对应一个存储位置f(key),value则存储在f(key)的位置上,这个位置称之为桶(bucket),这个对应关系f则称之为散列函数,也叫做哈希(Hash)函数。即哈希函数的作用是将key哈希到其对应的桶中。
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。Go语言中的map实现即采用散列表作为其底层数据结构。
在理想的情况下,不同的key通过散列函数计算出来的存储位置是不一样的,即,
f(key1) ≠ f(key2)
但实际上会出现不同的key通过散列函数计算出来的存储位置是一样的,即,
f(key1) = f(key2)
这种问题称作哈希冲突或者“碰撞”,即不同key被哈希到了同一个桶里。解决这种问题一般有两种方法:链表法和开放地址法。其中链表法是将发生碰撞的key穿成一个链表放在同一个桶里;开放地址法是指发生碰撞后,采取某种方法选择一个空桶将key放入其中。Go语言中的map实现采用链表法解决“冲突”。Go语言中一个桶里最多放8个key。如图1.1为链表法的示意图。
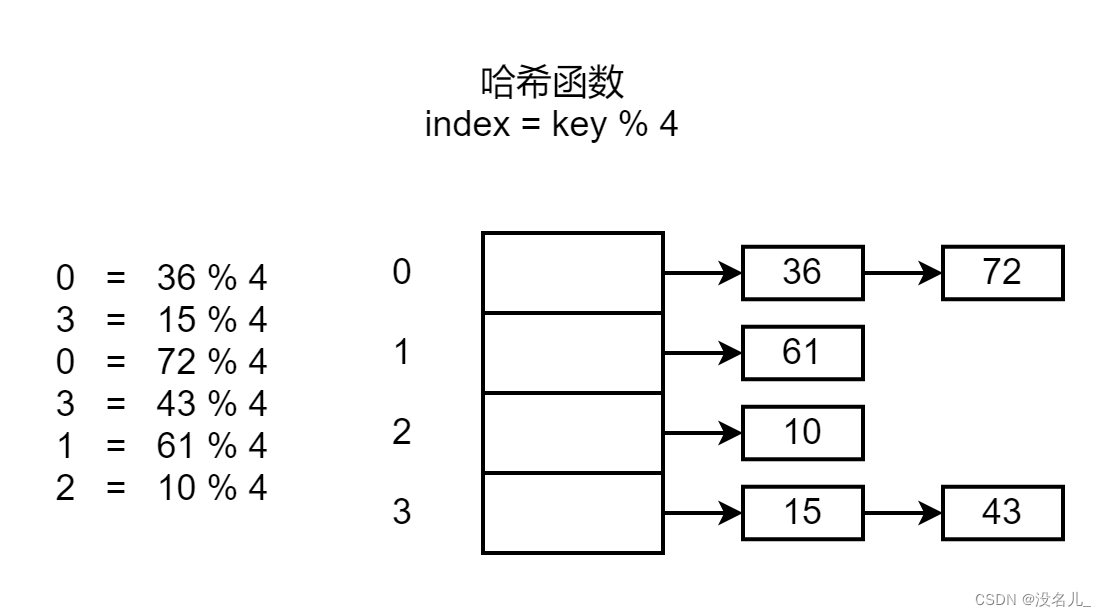
好的哈希函数应该尽量避免碰撞的发生,因为冲突的发生会降低map的查找性能。以上图链表法为例,查询72的时候,需要在编号为0的桶中比较两次,才能查询成功。如果碰撞导致编号为0的桶中存放N个元素,那么查询该桶中的元素最坏的时间复杂度为O(N)。扩容其实是一种提升哈希表查询效率的方法,扩容可以将原哈希表中的元素重新分配至新桶中,减少新哈希表中每个桶里的元素个数,从而进一步提升哈希表的查询效率。
1.2 为什么桶的个数是2的整数次幂
常用的哈希函数有两种,分别是取模法和与运算法。
取模法就是用key和数组长度length取模得到一个桶的编号(数组下标),即,
index = key % length
与运算法就是用key和数组长度length - 1进行与计算得到一个桶的编号(数组下标),即,
index = key & (length - 1)
在计算机内部,采用与运算的速度会非常快,所以哈希函数通常采用与运算法。但是采用与运算法时,桶数组长度必须是2的整数次幂,也即桶的个数必须是2的整数次幂,主要有以下两个原因。
-
原因1:不会出现空桶(主要原因)
举一个反例,假如桶的个数是7,那么length - 1为6,其二进制表示为110,即最低位是0。那么无论key为多少,当key & length - 1 = key & (110)时,计算结果最低位恒为0。因为最低位不可能是1,所以计算得到的桶编号不可能是1,3,5等奇数。这些桶即为空桶,key在桶里分配不均,易发生碰撞,不能作为哈希函数。
当桶的个数是2的B次幂时,length - 1的二进制表示为B个1。比如length = 8时,length - 1为7,7的二进制表示是111;比如length = 16时,length - 1为15,15的二进制表示为1111。因为每一位都是1,所以在做与运算时不会出现某个位置恒为0的情况,不可能出现空桶。且求与运算的到的结果中低B位表示桶的编号。

-
原因2:key % length = key & (length - 1)
也就是说,长度为2的n次幂时,模运算 % 可以变换为按位与运算。
长度取4,key取9;则9 % 4 = 1;9的二进制是 1001,4-1 = 3,3的二进制是 0011。 9 & 3 = 1001 & 0011 = 0001 = 1。计算结果相同。
长度取8,key取12;则12 % 8 = 4;12的二进制是 1100,8-1 = 7,7的二进制是 0111。12 & 7 = 1100 & 0111 = 0100 = 4。计算结果相同。
当长度不为2的整数次幂时,该结论不成立。
长度取5,key取9;则9 % 5 = 4,9的二进制是 1001,5-1 = 4,4的二进制是0100。9 & 4 = 1001 & 0100 = 0000 = 0。计算结果不同。
所以,当桶的个数是2的整数次幂时与运算法其实就是取模法。
2. 为什么用map
低时间复杂度是计算机科学中一个永恒的话题。理想情况下,map强大到其增删改查的时间复杂度均为O(1),因此在开发中map的使用非常频繁。
3. 桶的基本数据结构
笔者之所以从基本数据结构开始,是因为当我们明白了Go map底层用到的每个结构体以后,其实map的增、删、改、查流程大家可以猜到八九不离十。在阅读后续的具体执行流程源码时事半功倍。
本文代码版本均为go version go1.19.6 windows/amd64
bmap是桶对应的结构体。如下代码为bmap的源码,实现在src/runtime/chan.go中
// A bucket for a Go map.
type bmap struct {
// tophash是一个长度为unit8的数组,所以一个桶里最多有8个键值对
// tophash是hash值的高8位,发生碰撞时,多个key在同一个桶中,tophash可以用于快速定位桶内的键值对。
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
在编译期间,根据bmap的英文注释(上边),bmap的结构体会被动态创建为以下结构体:
type bmap struct {
tophash [bucketCnt]uint8 // 8个key的hash值的高8位,用于快速定位桶内的key
keys [bucketCnt]keytype // 8个key
elems [bucketCnt]valuetype // 8个value
padding uintptr // 对齐使用,按照源码的注释可以省略。
// 当发生碰撞时,一个桶里最多放8个键值对。
// 当有第9个key被hash到该桶时,由于没有多余的位置,需要放到溢出桶
// overflow即为指向溢出桶的指针,溢出桶和桶的内部结构是一样的。
overflow *bmap
}
如下图所示为桶的内存布局,桶内存放元素超过8,因此需要链接一个溢出桶。溢出桶与常规桶的布局是一样的,其设计目的是为了减少扩容的次数,毕竟扩容非常影响性能。
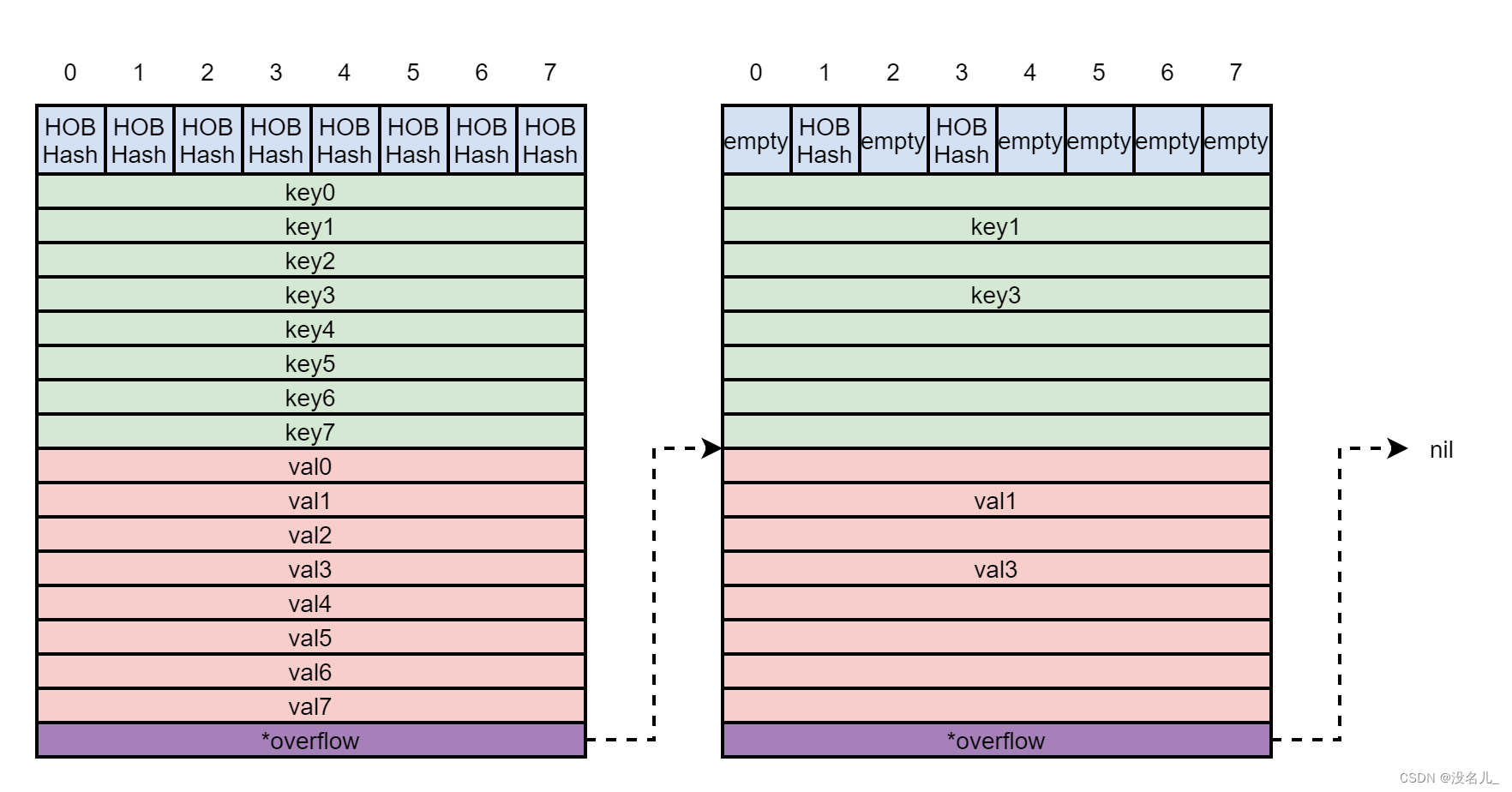
最上面蓝色区域的HOBHash即为每个对应key的hash值的高8位,也即tophash数组。
按照源码注释的解释,将所有key放在一起,然后将所有value放在一起可以省略padding,这个应该涉及操作系统,笔者不太清楚,留一个QA供大家讨论。
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
实际上,如果B大于4,那么哈希表需要分配的桶的个数其实大于24。因为当B>4时,系统会认为哈希表用到溢出桶的概率很大,系统会提前预分配2(B - 4)个溢出桶备用。这些溢出桶与常规的桶在内存上是连续的,只是常规桶当作常规桶使用,溢出桶在常规桶满时,链接在常规桶后边。
4. map的基本数据结构
hmap是map底层数据结构对应的结构体,实现在src/runtime/chan.go中。map类型的变量本质上就是一个指针,指向一个hmap结构体。所以不要再记map是引用类型了,也不用查go语言中引用和指针的区别了。
// A header for a Go map.
type hmap struct {
count int // map中键值对的数目,调用len(map)返回该值
flags uint8
B uint8 // 记录桶的数目,桶的数目为2^B,即桶数组长度为2^B
noverflow uint16 // 使用的溢出桶的数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 记录桶数组的位置,指向桶数组的指针
oldbuckets unsafe.Pointer // 记录扩容阶段原桶数组的位置,指向桶数组的指针
nevacuate uintptr // 记录渐进式扩容(后边讲)的进度,小于该编号的bmap已经被扩容至新桶中
extra *mapextra // 可选字段,用于记录溢出桶的信息
}
mapextra的结构体源码实现在src/runtime/chan.go中,如下所示,其中主要记录溢出桶的相关信息。
type mapextra struct {
overflow *[]*bmap // 指向已经使用的溢出桶数组
oldoverflow *[]*bmap // 指向扩容阶段旧桶使用的溢出桶数组
nextOverflow *bmap // 指向下个空闲溢出桶
}
继续往后看,在各个字段中笔者画了几张图帮助大家理解hmap结构体
4.1 B字段
B字段主要用于记录桶的数目,桶的数量是2B,也即桶数组的长度为2B,显然Go语言实现的map其散列函数采用与运算法,因此hash值的低B位表示桶的编号。一个map中最多容纳的键值对个数为loadFactor * 2^B个。**loadFactor为负载因子,它的含义是平均每个桶里的元素个数。**loadFactor为6.5,即平均每个桶里的元素个数为6.5个。如下述代码所示。
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
装载因子超过阈值6.5,即平均每个桶里的元素超过6.5就会触发扩容。
在64位的计算机中,一个key经过哈希以后会得到一个64位的hash值。该hash值的低B位即为key所在桶的编号,高8位(tophash)即为key在桶内的位置。
4.2 noverflow 字段与extra字段
- noverflow:表示使用的溢出桶数量
- overflow:指向已经使用的溢出桶数组
- oldoverflow:指向扩容阶段旧桶使用的溢出桶数组
- nextOverflow:指向下个空闲溢出桶
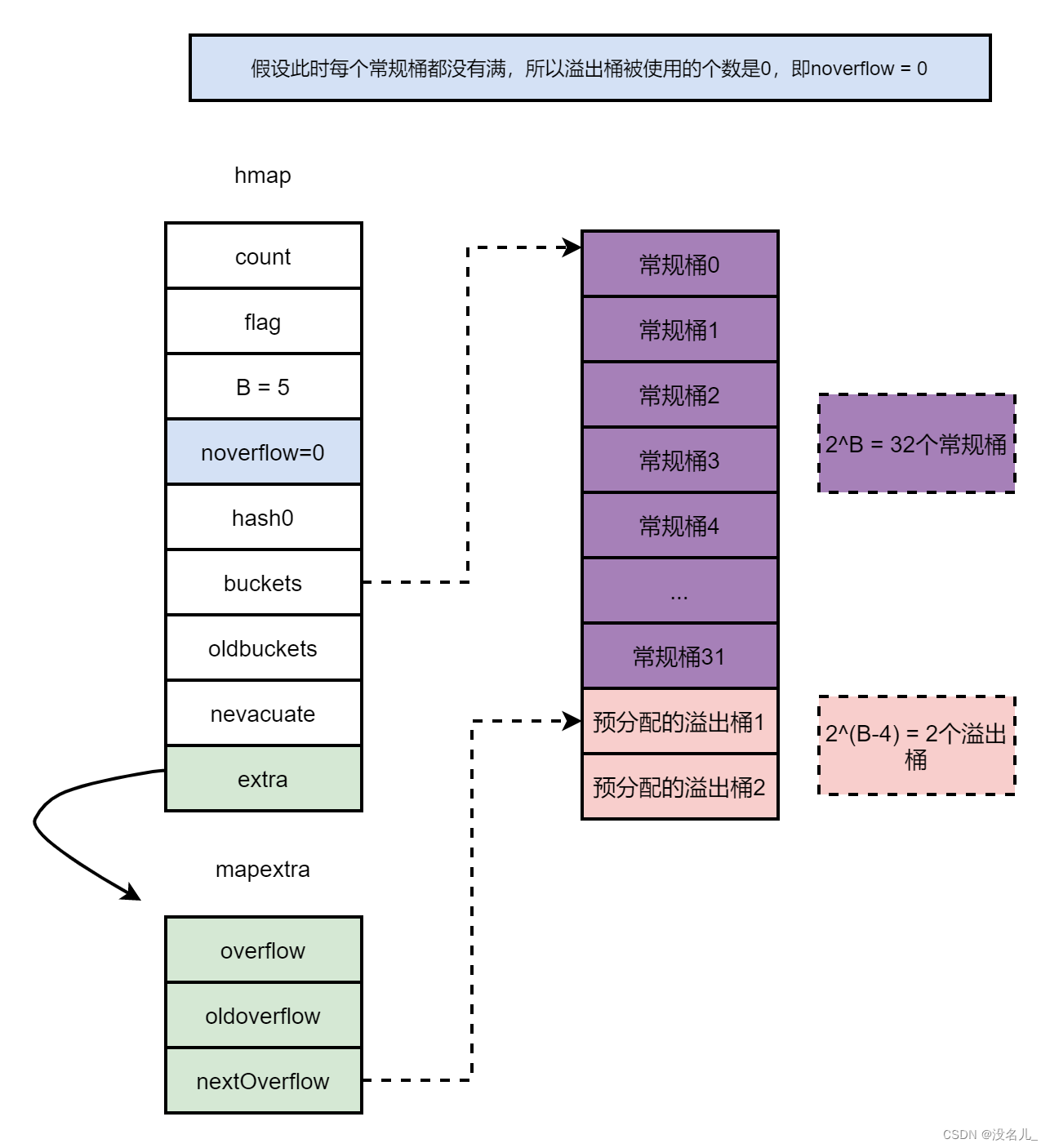
当B=5时,map有2的5次方=32个桶,但是B>4,系统会认为哈希表用到溢出桶的概率比较大,因此会提前分配2^(B - 4) = 2个溢出桶,且溢出桶和常规桶在内存上是连续的。假设此时每个常规桶都没有满,所以溢出桶被使用的个数为0,即noverflow = 0,extra字段中的nextOverflow指向下个空闲溢出桶。如下图所示。
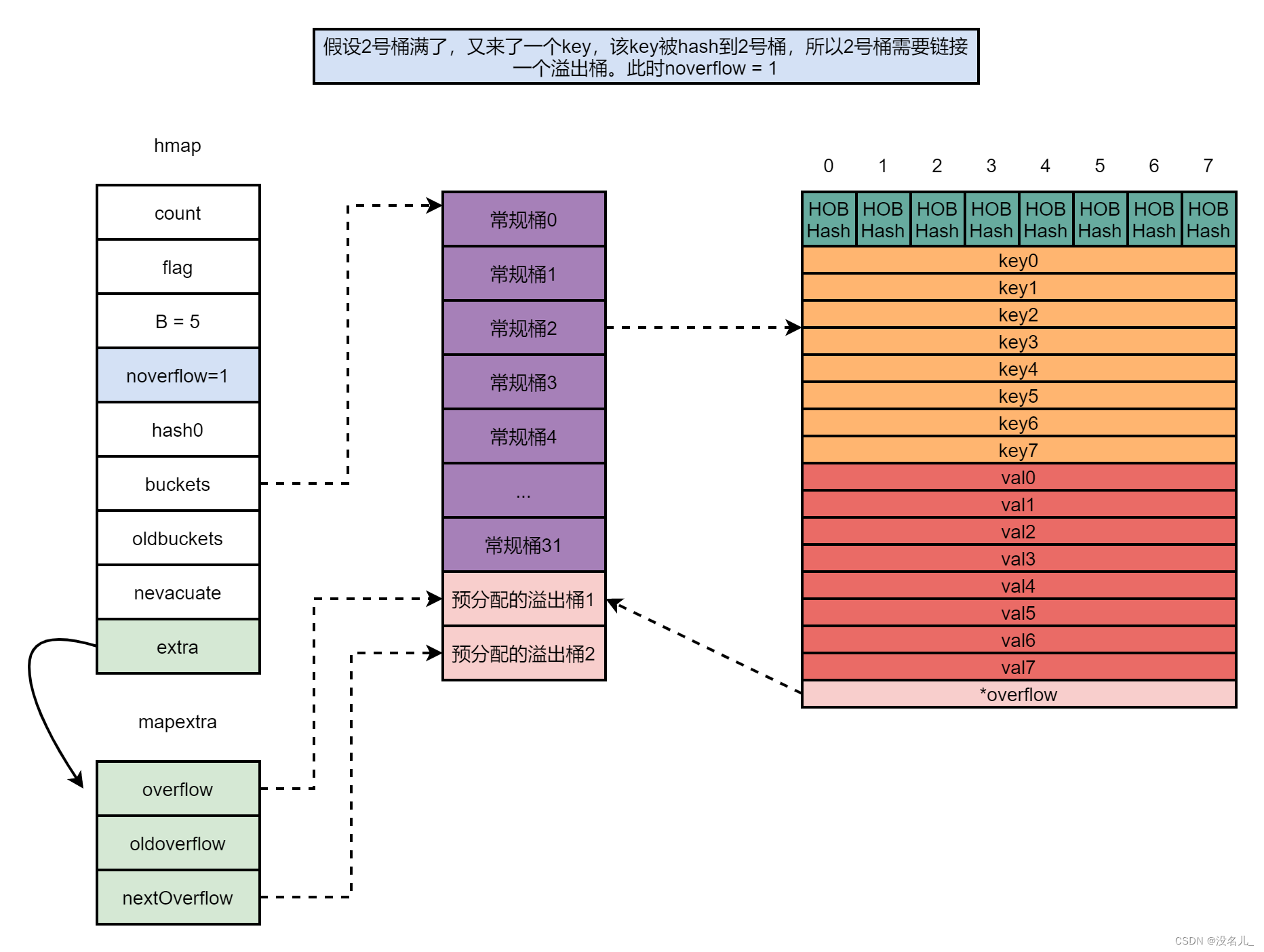
假设2号桶满了,又来了一个key,该key被hash到2号桶,因为2号桶满了,所以2号桶需要链接一个溢出桶。一个溢出桶被使用,所以noverflow = 1;预分配的溢出桶1被使用,所以extra的overflow字段指向预分配的溢出桶1;nextOverflow字段指向下一个空闲溢出桶,即预分配的溢出桶2,如下图所示。
4.3 oldbuckets字段和nevacuate字段
如果一个map中的键值对数量较多,在扩容时一次性迁移所有桶花费的时间是比较显著的。一种可行的办法是当需要扩容时,先分配足够多的新桶,在每次执行map的读写操作时,分批将旧桶中的所有元素迁徙到新桶中。所以需要oldbuckets来记录旧桶所在的位置,需要nevacuate来指示当前的扩容进度。当执行map读写操作时,如果监测到当前属于扩容阶段,会根据oldbuckets和nevacuate迁徙一部分旧桶中的元素至新桶,直到多次分批迁徙完毕。这种分批迁徙的方式称之为“渐进式扩容”,渐进式扩容可以避免一次性迁移花费过多时间所带来的性能抖动。
举个例子,帮助大家理解oldbuckets字段和nevacuate字段。
假设现在有一个map,该map只有1个桶,桶里的元素是7个,达到了翻倍扩容条件(平均每个桶里的元素个数超过负载因子loadFactor),那么在扩容前,内存布局如下。
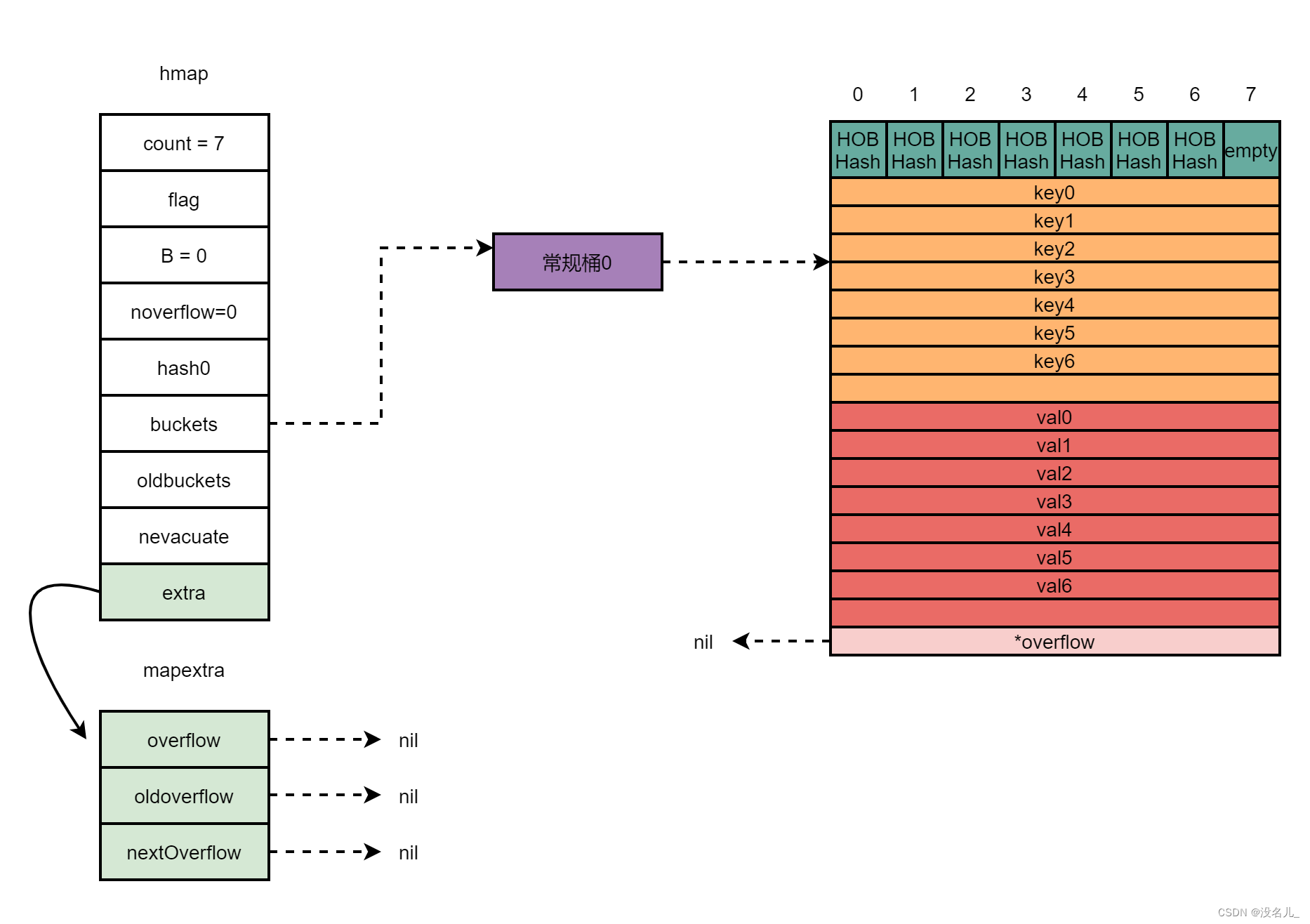
扩容后,系统新分配两个桶给该map,buckets则指向新被分配的两个桶,oldbuckets指向原先的桶。nevacuate的值为0,表示接下来迁移编号为0的旧桶。内存布局如下所示
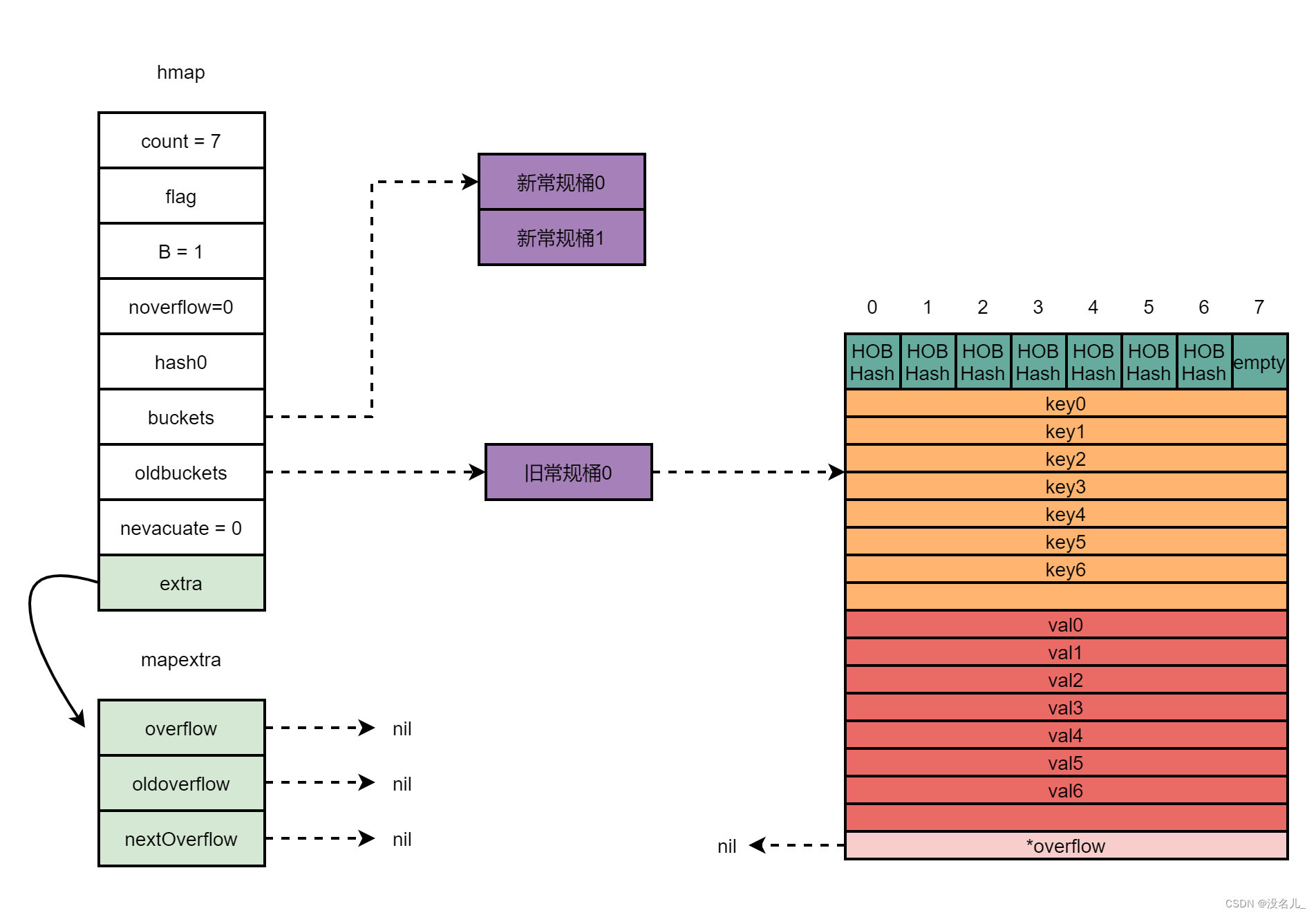
接下来的每次读写,会分批将旧桶中的7个元素迁移至两个新桶中,直到迁移完毕,oldbuckets指向nil。
5. QA
Q1:为什么桶的内存模型中,所有key放在一起,所有value放在一起?
Q2:桶的内存模型中多个key的前后关系是通过内存中的相邻关系指定的么,也即不需要next指针指向桶里的下一个key?
6. 参考
- 《大话数据结构》程杰著,p354-p355
- 【Golang源码系列】一:Map实现原理分析















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









