






本文为学习笔记,部分内容为老师所写,非纯原创
目录
要实现异步处理,得先要有挂起的操作(把需要等的操作先挂起来存档,存完档先去执行别的操作),当一个任务需要等待 IO 结果的时候,可以挂起当前任务,转而去执行其他任务,这样才能充分利用好资源,要实现异步,需要了解一下 await 的用法,使用 await 可以将耗时等待的操作挂起,让出控制权。当协程执行的时候遇到 await,时间循环就会将本协程挂起,转而去执行别的协程,直到其他的协程挂起或执行完毕。
await
await 后面的对象必须是如下格式之一:
- 一个原生 coroutine 对象。
- 一个由 types.coroutine 修饰的生成器,这个生成器可以返回 coroutine 对象。
- 一个包含 await 方法的对象返回的一个迭代器。
使用 aiohttp 实现异步请求时,需要使用返回值时需要等待,因此要加await;定义一个函数,函数里有发请求的方法,函数用了await时,调用函数需要加await。
aiohttp 的使用
aiohttp 是一个支持异步请求的库,利用它和
asyncio
配合我们可以实现异步请求操作。下面以访问博客里面的文章,并返回 reponse.text() 为例,实现异步爬虫。将请求库由 requests
改成了
aiohttp
,通过
aiohttp
的
ClientSession
类的
get
方法进行请求异步操作。
from lxml import etree
import requests
import logging
# 日志
import time
import aiohttp
# 异步
import asyncio
# 协程
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 日志模块基础设计,设置日志模块级别,level=logging.INFO(什么级别的会被记录,这里是INFO通知,有消息就记录)
# 后边format='%(asctime)s - %(levelname)s: %(message)s'是记录格式
url = 'https://blog.csdn.net/?spm=1001.2014.3001.4477'
start_time = time.time()
# 获取当前时间戳
def get_urls():
# 获取博客里的文章链接
headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64)AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
url_list = html.xpath("//div[@class='content']/a/@href")
return url_list
async def request_page(url):
logging.info('scraping %s', url)
async with aiohttp.ClientSession() as session:
response = await session.get(url)
# aiohttp发请求方法session.get()相当于request.get()
return await response.text()
def main():
url_list = get_urls()
tasks = [asyncio.ensure_future(request_page(url)) for url in url_list]
# 列表生成式,遍历url_list,调用request_page方法
loop = asyncio.get_event_loop()
tasks = asyncio.gather(*tasks)
# 上边列表里有一堆任务,需要用asyncio.gather(*tasks)整合成一个任务再执行
loop.run_until_complete(tasks)
if __name__ == '__main__':
main()
end_time = time.time()
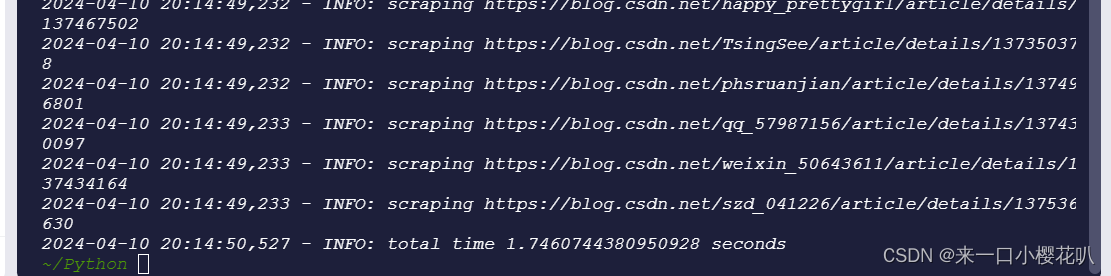
logging.info('total time %s seconds', end_time - start_time)
可以看到1.7s就执行完了,
当遇到阻塞式操作时,任务被挂起,程序接着去执行其他的任务,而不是傻傻地等待,这样可以充分利用 CPU 时间,而不必把时间浪费在等待
IO
上。
对比多线程 ,协程会比多线程速度快(注意线程不是越多越快,过多也会变慢)
异步mysql的使用
Python操作 MysQL数据库大部分驱动都是同步的,也就是必须等待他的返回才会往下执行,如果一个 SQL执行得比较久,那么会直接卡死这个线程。因此这里我们可以选择异步的Python驱动来操作 MysQL 数据库。
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分。其目的,是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。在这样的情况下,就不需考虑数据库创建时的名称重复问题。最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X 等等。另外我们也可以在e2fsprogs包中的UUID库找到实现。
import asyncio
import aiomysql
import shortuuid
import pymysql
# 异步
# aiomysql做数据库连接的时候,需要这个loop对象
async def async_basic(loop):
pool = await aiomysql.create_pool(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
db="ceshi",
loop=loop
)
async with pool.acquire() as conn:
async with conn.cursor() as cursor:
for x in range(10000):
content = shortuuid.uuid()
sql = "insert into mybrank(brank) values('{}')".format(content)
#执行SQL语句
await cursor.execute(sql)
await conn.commit()
#关闭连接池
pool.close()
await pool.wait_closed()
if __name__ == '__main__':
# 异步:数量大时用异步
loop = asyncio.get_event_loop()
loop.run_until_complete(async_basic(loop))
# 同步:sync_basic()用异步mysql把小说存数据库里
# 用异步mysql把小说存数据库里
import asyncio
import json
import time
import aiohttp
import logging
from aiohttp import ContentTypeError
# from motor.motor_asyncio import AsyncIOMotorClient
from lxml import etree
import aiomysql
from pymysql.converters import escape_string
CONCURRENCY = 4
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
class Spider(object):
def __init__(self):
# 设置协程的数量
self.semaphore = asyncio.Semaphore(CONCURRENCY)
async def scrape_api(self, url):
async with self.semaphore:
logging.info('scraping %s', url)
try:
logging.info('scraping %s', url)
# 发送请求
async with self.session.get(url) as response:
# await asyncio.sleep(1)
# 返回请求结果
return await response.text(encoding='gbk')
except ContentTypeError as e:
logging.error('error occurred while scraping %s', url,exc_info=True)
def save_file(self, tite,contents):
op = open('1.txt','a+',encoding='utf8')
op.write(tite[0]+'\n'+''.join(contents)+'\n')
op.close()
async def async_basic(self,title,contents):
pool = await aiomysql.create_pool(
host="localhost",
port=3306,
user="root",
password="123456",
db="ceshi",
loop=loop
)
async with pool.acquire() as conn:
async with conn.cursor() as cursor:
# for x in range(10000):
# content = shortuuid.uuid()
# sql = "insert into mybrank(brank)values('{}')".format(content)
sql = "INSERT INTO book(name,content) VALUES(%s, %s)"
await cursor.execute(sql, (title[0], ''.join(contents)))
# 执行SQL语句
await conn.commit()
# 关闭连接池
pool.close()
await pool.wait_closed()
def scrape_detail(self, source):
title = etree.HTML(source).xpath('//title/text()')
contents = etree.HTML(source).xpath('//dd[@id="contents"]/text()')
return title,contents
async def main(self):
# 设置header
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# aiohttp模块准备发送请求(主要加header头信息以及代理,cookie等头信息)
self.session = aiohttp.ClientSession(headers=headers)
# source = await self.scrape_api('https://www.23us.com/book/24/24664/')
# 异步请求获取页面源码
source = await self.scrape_api('https://www.72us.com/html/21/21578/')
# 获取所有章节的的链接(缺少一半)
chapter_href_list = etree.HTML(source).xpath('//td[@class="L"]/a/@href')
# 生成抓取本章前十章节
scrape_detail_tasks =[asyncio.ensure_future(self.scrape_api('https://www.72us.com/html/21/21578/'+href)) for href in chapter_href_list[:306]]
content_list = await asyncio.gather(*scrape_detail_tasks)
scrape_contents = [self.scrape_detail(contents) for contents in content_list]
# scrape_save = [self.save_file(title,contents) for title,contents in scrape_contents]
[await self.async_basic(title,contents) for title,contents in scrape_contents]
await self.session.close()
if __name__ == '__main__':
begin_time = time.time()
spider = Spider()
loop = asyncio.get_event_loop()
loop.run_until_complete(spider.main())
end_time = time.time()
print(end_time-begin_time)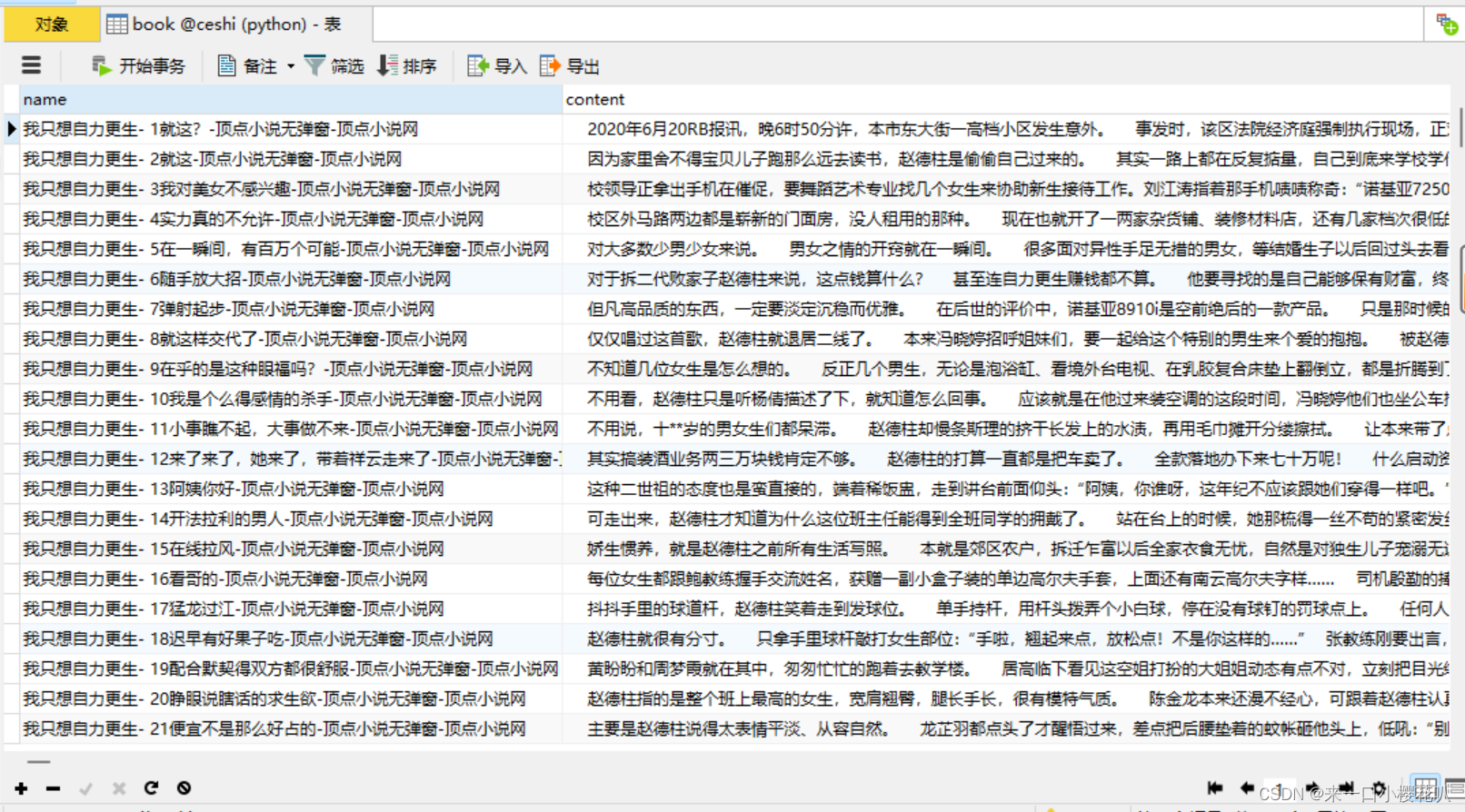















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









