







 本文介绍了一种名为EfficientViT的新型视觉Transformer模型,通过采用记忆高效的sandwich布局和级联群注意力模块,减少了计算成本,提高内存效率,特别适合实时应用。作者还探讨了如何通过调整Q、K和V的维度以及使用分组卷积来优化计算。该模型旨在实现高吞吐量和轻量化,区别于传统的并行处理方式。
本文介绍了一种名为EfficientViT的新型视觉Transformer模型,通过采用记忆高效的sandwich布局和级联群注意力模块,减少了计算成本,提高内存效率,特别适合实时应用。作者还探讨了如何通过调整Q、K和V的维度以及使用分组卷积来优化计算。该模型旨在实现高吞吐量和轻量化,区别于传统的并行处理方式。
摘要
要解决的问题
Vision transformers have shown great success due to their high model capabilities. However, their remarkable performance is accompanied by heavy computation costs, which makes them unsuitable for real-time applications.
vit计算开销大,不适用于实时任务
为什么开销大
We find that the speed of existing transformer models is commonly bounded by memory inefficient operations, especially the tensor reshaping and element-wise functions in MHSA.
reshape 需要重新分配资源
element-wise functions q、k、v算内积的操作
多头注意力机制(MHSA)上面两个操作做得多
解决办法 a sandwich layout 的block
a new building block with a sandwich layout--减少self-attention的次数
we design a new building block with a sandwich layout, i.e., using a single memory-bound MHSA between efficient FFN layers
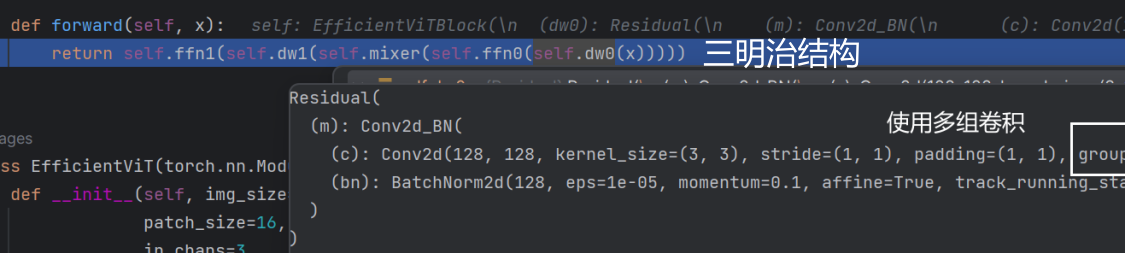
之前是一个block self-attention->fc->self-attention->fc->self-attention->fc->...xN次数
现在是一个block fc->self-attention->fc 像三明治一样
which improves memory efficiency while enhancing channel communication.
不仅能够提升内存效率而且能够增强通道间的计算
从多头注意力机制的不同头部有高相似度入手--减少每个头重复工作
Moreover, we discover that the attention maps share high similarities across heads, leading to computational redundancy. To address this, we present a cascaded group attention module feeding attention heads with different splits of the full feature, which not only saves computation cost but also improves attention diversity.
cascaded group attention:me:让多头串联学习特征:第一个头学习完特征后,第二个头利用第一个头学习到的特征的基础上再去学习(原来的transformer是第二个头跟第一个头同时独立地去学习),同理第三个头学习时也得利用上第二个头学习的结果
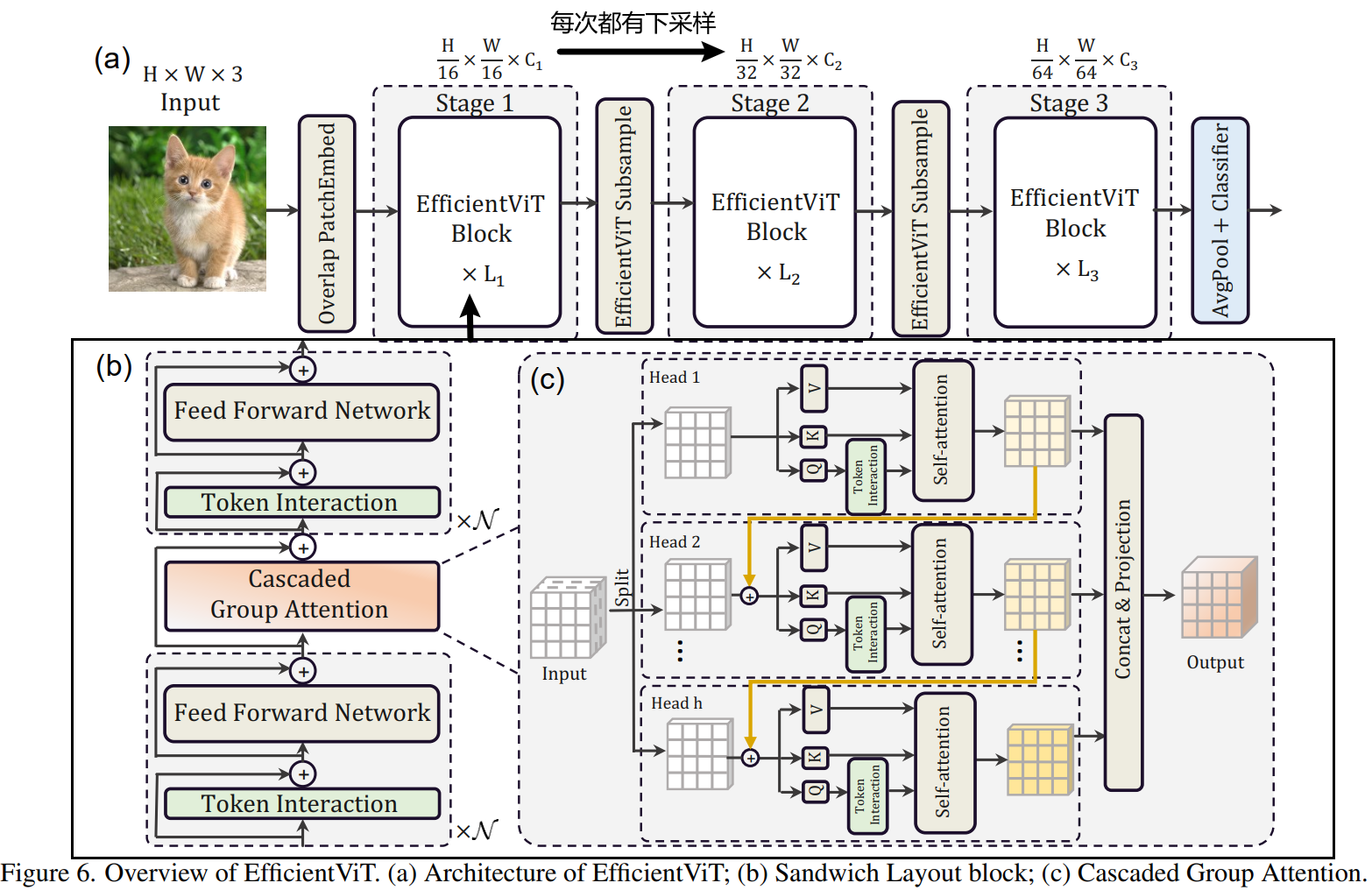
Efficient Vision Transformer
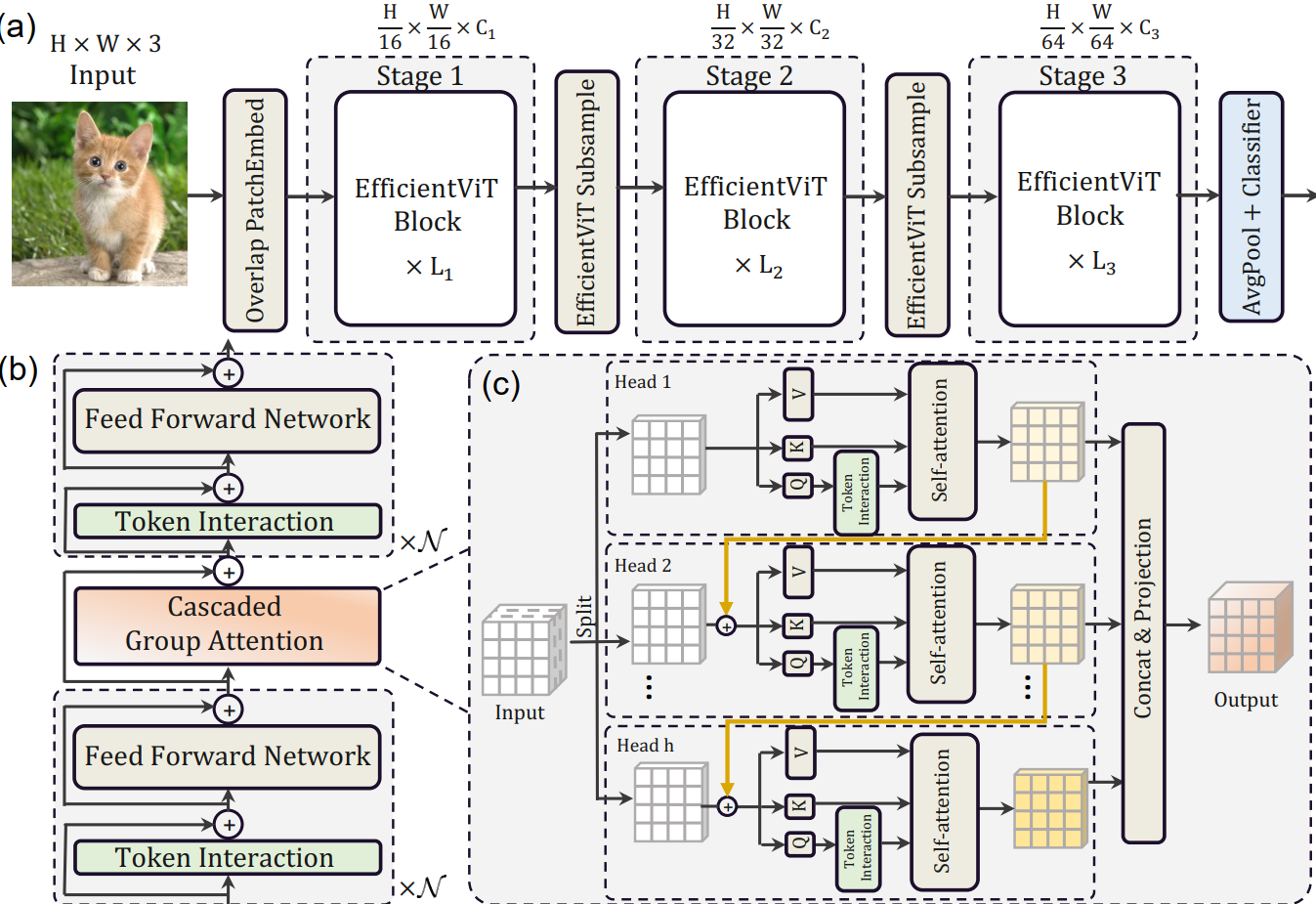
特征提取单元:EfficientViT Building Blocks 的组成
It is composed of a memory-efficient sandwich layout, a cascaded group attention module, and a parameter reallocation strategy
1:a memory-efficient sandwich layout 显存效率高的"三明治布局"
2:a cascaded group attention module 注意力机制中的级联结构
3:a parameter reallocation strategy 参数重新分配策略
a memory-efficient sandwich layout
sandwich layout 结构
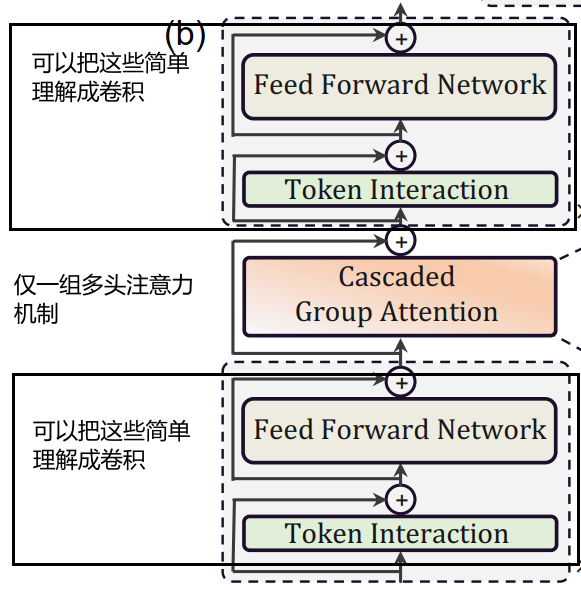
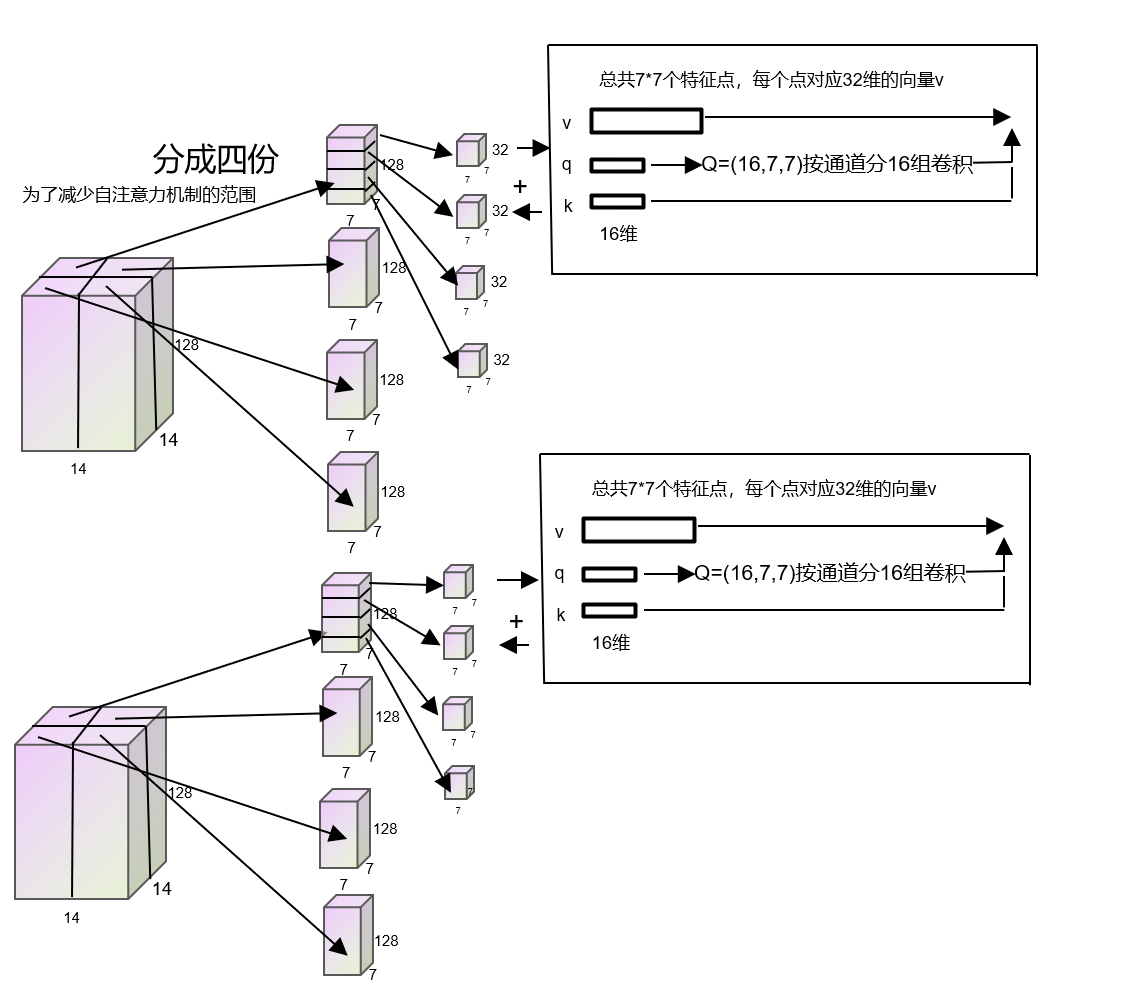
为什么显存利用率高:之前的FC现在都是卷积操作,运算量低;而且这里使用的是分组卷积
sandwich layout 公式
Specifically, it applies a single self-attention layer ΦAifor spatial mixing, which is sandwiched between FFN layers ΦFi.
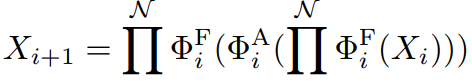
公式的解释

This design reduces the memory time consumption caused by self-attention layers in the model, and applies more FFN layers to allow communication between different feature channels efficiently.
通过多层FFN层(卷积层)来完成通道的特征映射
本文章卷积采用分组卷积:R、G、B通道分组卷积
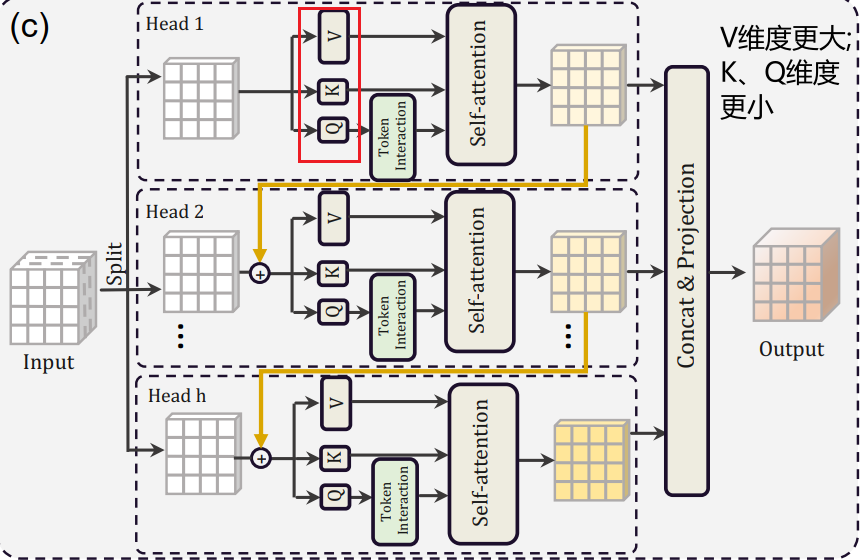
Cascaded(级联) Group Attention
论文内容
Inspired by group convolutions(分组卷积) in efficient CNNs, we propose a new attention module named cascaded group attention (CGA) for vision transformers.
It feeds each head with different splits of the full features, thus explicitly decomposing the attention computation across heads.
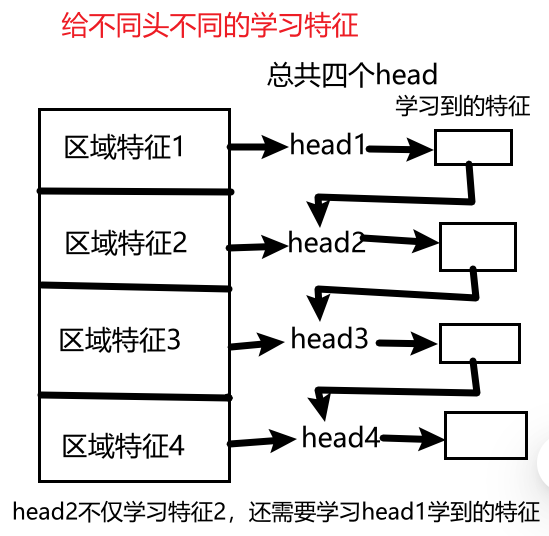
me:解决了原来模型中多头重复学习(学习到的特征很多都是相似的)的问题,这里每个头学到的特征都不同,而且越往下面的头学到的特征越丰富。
流程图
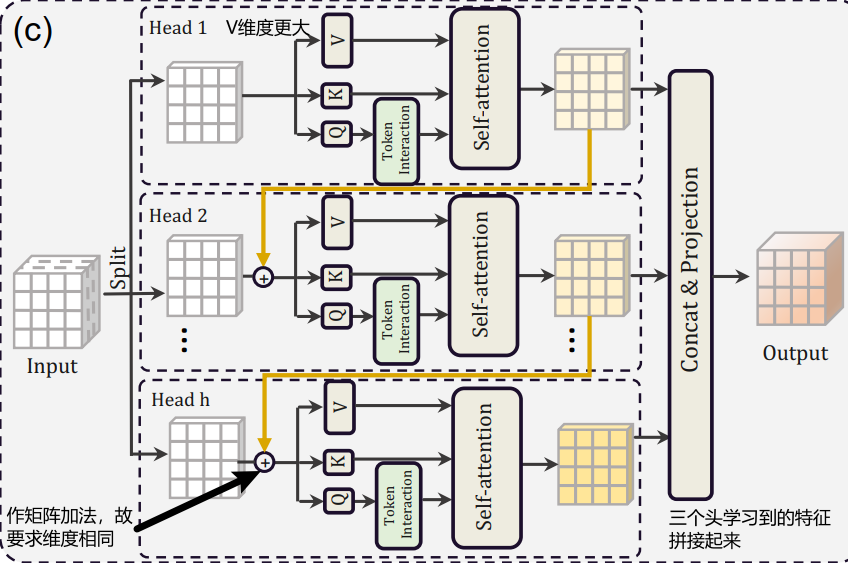
Q是主动查询的行为,特征比K更加丰富,所以额外做了个Token Interation
Q进行self-attention之前先通过多次分组卷积再一次学习
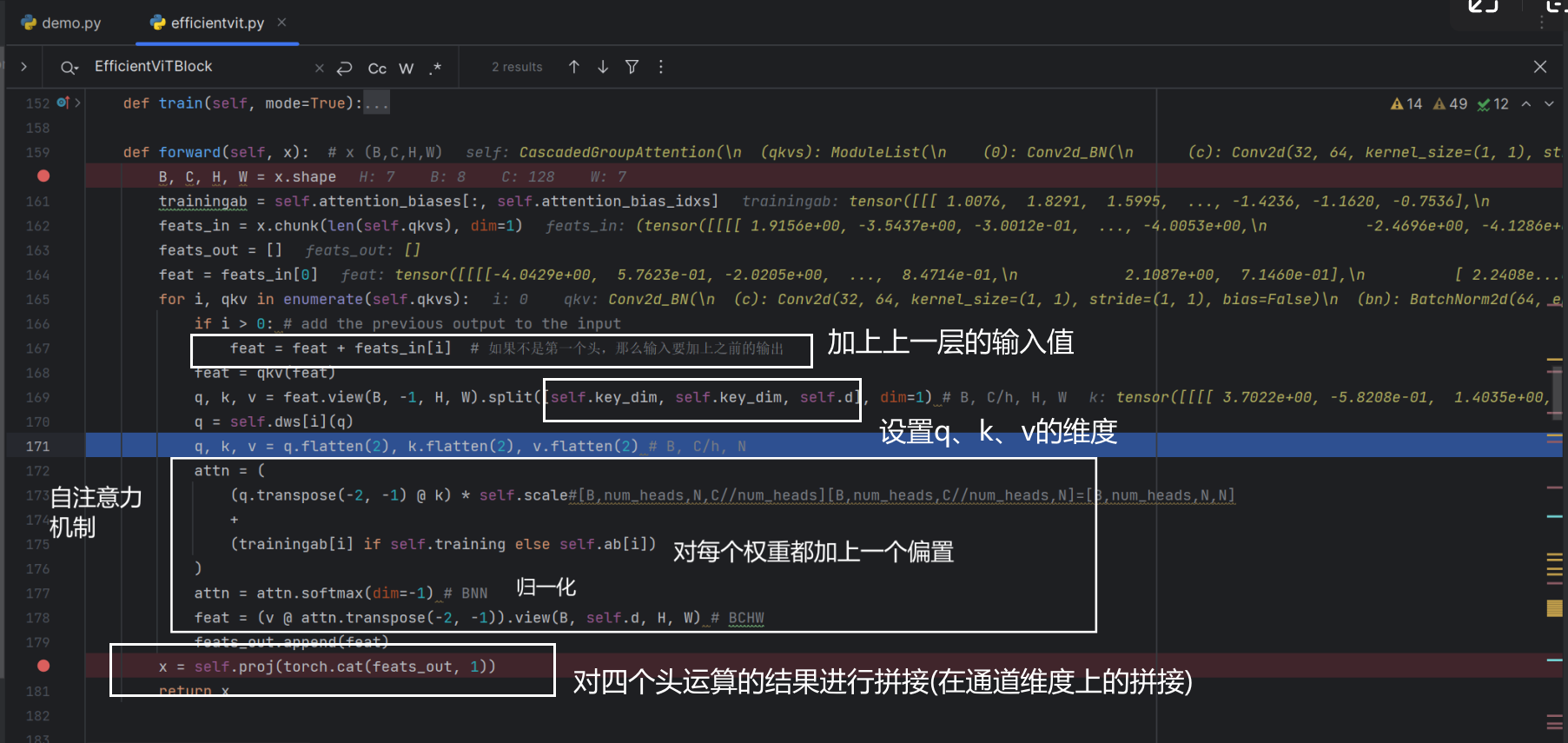
项目代码debug流程图显示
对应代码块
Parameter Reallocation
we set small channel dimensions for Q and K projections in each head for all stages.
For the V projection, we allow it to have the same dimension as the input embedding.
作用:
self-attention主要在进行Q*K,而且还需要对Q/K进行reshape,所以为了运算效率更快,Q与K的维度小一点
而V只在后面被Q*K得到的结果进行权重分配,没那么费劲,为了学习更多的特征,所以V维度更大一些
笔记区
追求的是比传统算法的吞吐量高(论文创新点,模型轻量化)
现在的往往都是并联并行,而他是级联
文章
📎EfficientViT Memory Efficient Vision Transformer with.pdf




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











