







机器学习–KNN(scikit-learn,sklearn)
KNN(K- Nearest Neighbor)法即K最邻近法,最初由
Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别
。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种
Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率 。
KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。唐胡鑫,网站运营与数据分析 双色版,航空工业出版社,2016.12,第81页-第82页
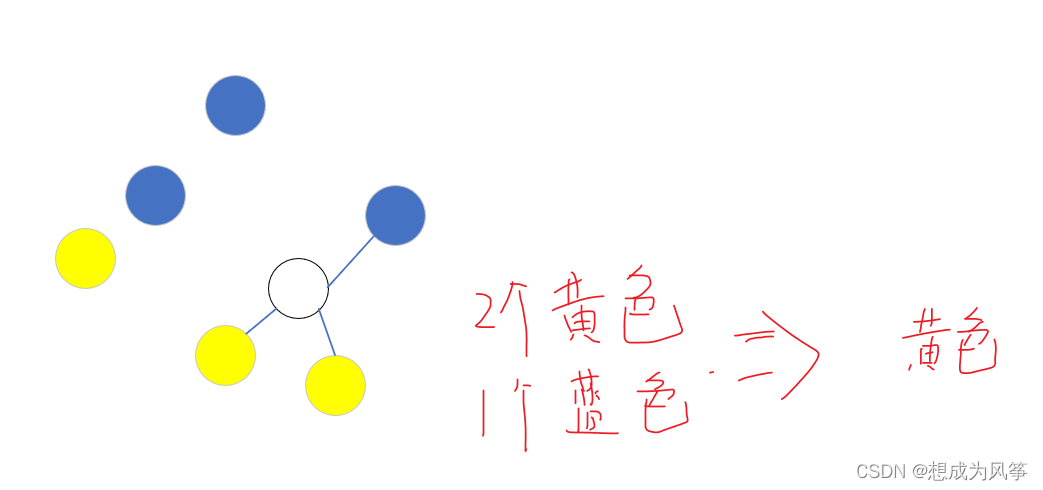
KNN的实现-sklearn库调用方式及参数解释
KNNf分类器
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)
参数:
- n_neighbors: 一个整数,指定k值。
- weights: 一字符串或者可调用对象,指定投票权重类型。
即这些邻居投票权可以为相同或者不同。
uniform: 本节点的所有邻居节点的投票权重都相等。
distance: 本节点的所有邻居节点的投票权重与距离成反比,即越近节点,其投票权重越大。
[callable]: 一个可调用对象,它传入距离的数组,返回同样形状的权重数组。 - algorithm: 一个字符串,指定最近邻的算法,可以为下:
ball_tree: 使用BallTree算法。
kd_tree: 使用KDTree算法。
brute: 使用暴力搜索算法。
auto: 自动决定最合适算法。 - leaf_size: 一个整数,指定BallTree或者KDTree叶节点的规模。它影响树的构建和查询速度。
- metric: 一个字符串,指定距离度量。默认为‘minkowski’(闵可夫斯基)距离。
- p: 整数值。p=1: 对应曼哈顿距离。p=2: 对应欧氏距离。
- n_jobs: 并行性。默认为-1表示派发任务到所有计算机的CPU上。
方法:
- fit(X,y): 训练模型。
- predict(X): 预测模型。
- score(X,y): 返回在(X,y)上预测的准确率(accuracy)。
- predict_proba(X): 返回样本为每种标记的概率。
- kneighbors([X,n_neighbors,return_distace]): 返回样本点的k邻近点。如果return_distance=True,同时还返回到这些近邻点的距离。
- kneighbors_graph([X,n_neighbors,mode]): 返回样本点的连接图。
from sklearn import neighbors,datasets,preprocessing
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
X,y = iris.data[:,:],iris.target
#数据划分 hold_out
X_train,X_test,y_trian,y_test = train_test_split(X,y,random_state=13)
#数据预处理
sclaer = preprocessing.StandardScaler().fit(X_train)
#训练集样本数量 大于 测试集样本数量
#标准一样
X_train = sclaer.transform(X_train)
X_test = sclaer.transform(X_test)
#定义模型
knn = neighbors.KNeighborsClassifier(n_neighbors=3)
#模型训练
knn.fit(X_train,y_trian)
y_pred = knn.predict(X_test)
print(accuracy_score(y_test,y_pred))
A = knn.kneighbors_graph(X_test[0:5],n_neighbors=3,mode='distance')
print(A.toarray())
KNN回归器
from sklearn.neighbors import KNeighborsRegressor
KNeighborsRegressor(n_neighbors=5, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)
参数:
- n_neighbors: 一个整数,指定k值。
- weights: 一字符串或者可调用对象,指定投票权重类型。
即这些邻居投票权可以为相同或者不同。uniform: 本节点的所有邻居节点的投票权重都相等。distance: 本节点的所有邻居节点的投票权重与距离成反比,即越近节点,其投票权重越大。[callable]: 一个可调用对象,它传入距离的数组,返回同样形状的权重数组。 - algorithm: 一个字符串,指定最近邻的算法,可以为下:
ball_tree: 使用BallTree算法。kd_tree: 使用KDTree算法。
brute: 使用暴力搜索算法。auto: 自动决定最合适算法。 - leaf_size: 一个整数,指定BallTree或者KDTree叶节点的规模。它影响树的构建和查询速度。
- metric: 一个字符串,指定距离度量。默认为‘minkowski’(闵可夫斯基)距离。
- p: 整数值。p=1: 对应曼哈顿距离。p=2: 对应欧氏距离。
- n_jobs: 并行性。默认为-1表示派发任务到所有计算机的CPU上。
方法:
- fit(X,y): 训练模型。
- predict(X): 预测模型。
- score(X,y): 返回在(X,y)上预测的准确率(accuracy)。
- predict_proba(X): 返回样本为每种标记的概率。
- kneighbors([X,n_neighbors,return_distace]): 返回样本点的k邻近点。如果return_distance=True,同时还返回到这些近邻点的距离。
- kneighbors_graph([X,n_neighbors,mode]): 返回样本点的连接图。
















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











