






python-中文文本词共现矩阵代码
(初学,仅做记录用)
参考链接https://www.cnblogs.com/jiangyiming/p/16102307.html
代码如下
import jieba
import numpy as np
import pandas as pd
text = ['有毛病吗?七月三号发五月份的事?制造恐慌?举报了', '制造恐慌,已举报']
# 处理text文本数据
data_array = [] # 每篇文章关键词的二维数组;[['词1',...],['词2',....]]
word_list = [] # 存储文本中的所有词,[词1,词2,....]
for sentence in text:
words = " ".join(jieba.cut(sentence)) # 返回 “词(空格) 词(空格)词”形式
words = words.split(' ') # 返回['词1','词2',..]形式
data_array.append(words)
word_list.extend(words)
word_to_id = {}
id_to_word = {}
for word in word_list:
if word not in word_to_id:
new_id = len(word_to_id) # 赋予每个词索引
word_to_id[word] = new_id
id_to_word[new_id]=word
corpus = np.array([word_to_id[w] for w in word_list]) # 所有词的词典
print(data_array)
print(word_list)
print(corpus)
print(word_to_id)
# 将data_array中的单词,用词id表示
for i in range(len(data_array)):
for j in range(len(data_array[i])):
if data_array[i][j] in word_to_id.keys():
data_array[i][j] = word_to_id[data_array[i][j]]
print(data_array)
# 构建词共现矩阵
vocab_size = len(word_to_id) # vocab_size 文本中有多少唯一的词
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
window_size = 1 # 共现的窗口
for p_corpus in data_array: # 逐个去计算每个句子中的词共现
for idx,word_id in enumerate(p_corpus):
for i in range(1,window_size+1):
left_idx = idx - i
right_idx = idx + i
if left_idx >=0:
left_word_id = p_corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < len(p_corpus):
right_word_id = p_corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
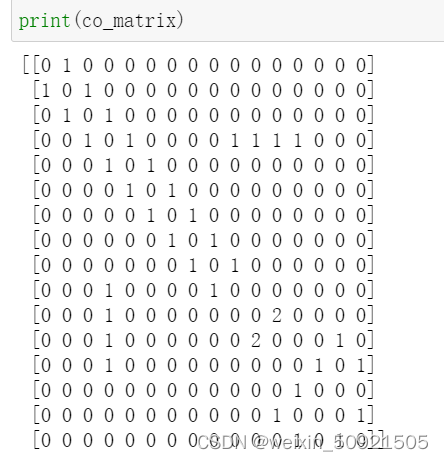
print(co_matrix)
结果:


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









