






本文着眼于对疫情期间教育领域新闻的分析,基于 python 语言,利用爬虫获取教育领域的最新新闻,并将其内容进行分词,抓取关键词。在此基础上,根据关键词进行共现分析,并利用 Gephi 软件绘制主题知识图谱,以分析在疫情之下教育行业的关注重点,并以此为鉴,分析未来教育行业的变化动向。
关键词:python 爬虫 Gephi 知识图谱
完整代码:https://download.csdn.net/download/qq_38735017/87382319
2.数据抓取与文本提取
2.1数据抓取
本文抓取的数据为光明网教育频道( )的新闻。主要有高校、中小学、留学、职教等方面的信息。
2.1.1 网页链接定位
采用 BeautifulSoup 进行正则判断,得到新闻标题链接的后缀。由于后缀有两种类型,所以用了 if/else 判断后缀类型,进而定位每一条新闻对应的真正链接。
myList=soup.find_all(name="span",attrs= {'class':'channel-newsTitle'})#得到新闻标题链接后缀
#myNews 存储新闻链接
myNews={}
j=0
foriinmyList:
j+=1
ifj>50:
break
#生成新闻链接
ifi.find('a').get('href')[0]=='2':
myNews[j]='[http://edu.gmw.cn/'+i.find('a').get('href')](http://edu.gmw.cn/'+i.find('a').get('href'))
else:
myNews[j]=i.find('a').get('href')2.1.2 获取新闻信息
在获取了链接之后,可以获取新闻的标题以及内容。此时依旧使用 beautifulsoup 获取文章,并通过分析网页源码可知,正文部分包含于 class 为 u-mainText 中。核心代码如下:
bsobj=bs(contents,'html5lib')
# 获取文章标题
title=bsobj.title.text+'\n'
# 获取文章内容
pList=bsobj.find(name='div',attrs= {'class':'u-mainText'}).find_all('p')
# 将标题和文章整合
content=''
forpinpList:
content+=p.text+'\n'2.1.3 文件写入
此处需要注意的是,首先由于文档需要后续进行关键字提取,所以保存为 txt 文件“D:/data.txt”,又为了便于之后共建矩阵的使用,也保存一份 CSV 文件。同时,因为数据量较大,不便于一次性爬取全部所需内容,此处均采用追加模式。
resp=getContent()
withopen('D:/data.txt','a',encoding='gb18030')asfp:
fortitleinresp:
fp.write(resp[title])
withopen('D:/data.csv','a',newline='',encoding='gb18030')asf:
write=csv.writer(f)
write.writerow(['title','text'])
a=1#记录数据量
fortitleinresp:
write.writerow([title,resp[title]])
print("已写入%d条信息"%a)
a+=12.1.4 爬取结果展示

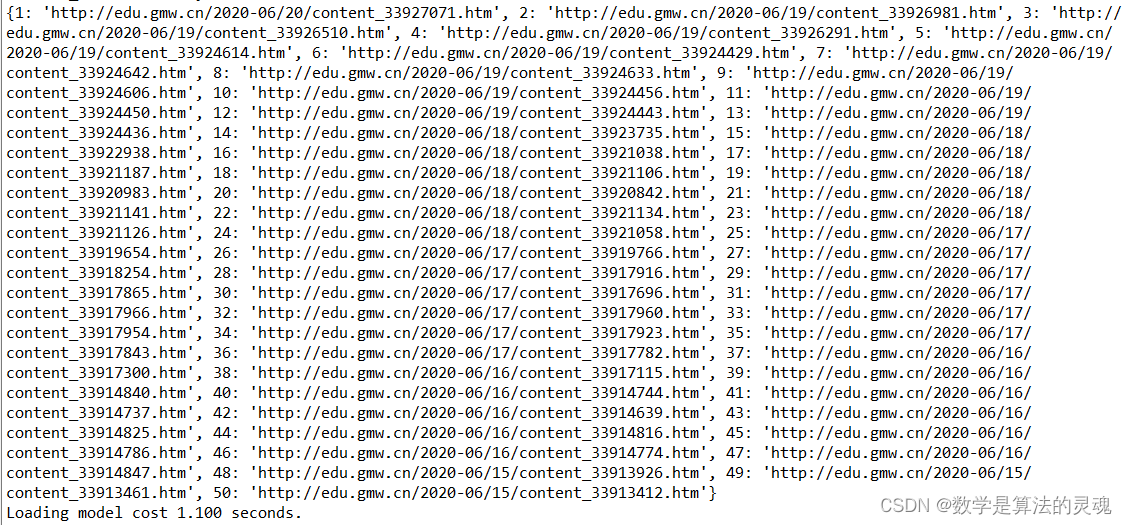
2.2 分词
该部分主要利用 jieba 包对已获取的文章进行中文分词,并提取每条新闻排名前 50 的关键词,将关键词写入"all-data-key.txt"文件中,为下一步实现共现矩阵做准备。
cut_words=""
f=open('D:/all-data-key.txt','a',encoding='utf-8')
forlineinopen('D:/data.txt',encoding='gb18030'):
line=line.strip('\n')
#停用词过滤
line=re.sub('[0-9’!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\\]^_`{|}~\s]+', "", line)
seg_list=jieba.cut(line,cut_all=False)
cut_words=(" ".join(seg_list))
#计算关键词
all_words=cut_words.split()
c=Counter()
forxinall_words:
iflen(x)>1andx!='\r\n':
c[x]+=1
#Top50
output=""
#print('\n词频统计结果:')
for(k,v)inc.most_common(50):
#print("%s:%d"%(k,v))
output+=k+" "
f.write(output+"\n")2.3 小结
第一部分主要完成了文字的获取与初步分词处理,并根据分词结果提取高频词,和课内的词云制作思路基本相同,所以在结果和代码方面也有共同之处。
3.共现矩阵与主题词分析
3.1 原理
共现分析常常应用于数据分析的领域,可以对关键词进行分析,比如文献中的关键词、作者、作者机构等等。在其他领域中,如电影电视剧也可以用来研究演员共现矩阵等等,网络上分析金庸笔下武侠世界人物关系时常用共现分析。
3.1.1 简例
对于如下的一组数据:
a | b | c | d |
b | d | m | e |
e | a | c | d |
m | n | a | b |
a 和 b 共现了 2 次,b 和 d 共现了 2 次。则称 a、b 共现的权重为 2,b、d 共现的权重为 2。而 c、m 没有同时出现,则认为 c、m 的权重为 0。
3.1.2 文本共现矩阵
在已获取的"all-data-key.txt"文件中,每一行存储了一则新闻的前 50 个关键词,可以将不同文章的关键词整合构造一个共现矩阵,通过关键词的配对次数来分析大数据下近日教育的热点词。将词组分别记为 Source 和 Target 便于之后 Gephi 绘图,同时 Weight 记录权重,可以使图像更为直观。下为文本共现矩阵的形式示例。

3.2 核心代码
i=0
j=0
whilei<len(nums):#ABCD共现 AB AC AD BC BD CD加1
j=i+1
w1=nums[i]#第一个单词
whilej<len(nums):
w2=nums[j]#第二个单词
#从word数组中找到单词对应的下标
k=0
n1=0
whilek<len(word):
ifw1==word[k]:
n1=k
break
k=k+1
#寻找第二个关键字位置
k=0
n2=0
whilek<len(word):
ifw2==word[k]:
n2=k
break
k=k+1
#重点: 词频矩阵赋值 只计算上三角
ifn1<=n2:
word_vector[n1][n2]=word_vector[n1][n2]+1
else:
word_vector[n2][n1]=word_vector[n2][n1]+13.3 主题词分析
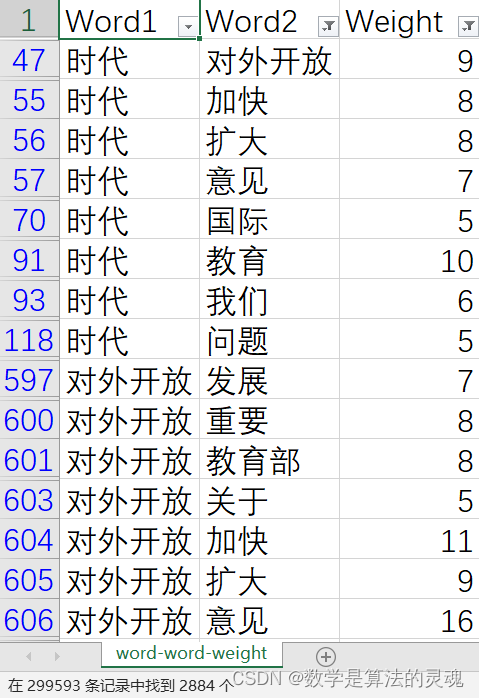
将文本共现矩阵存入"word-word-weight.csv"文档中,共有 299593 条数据,但其中有大量权重较低的词组对,因而还需要进一步筛选,此时将 Weight 低于 5 的数据都过滤掉,还剩 2884 条数据。
3.4 共现矩阵分析的优势与不足
在 python 课内学习中,我们学习了制作词云,可以说是数据处理的第一小步,虽然慈云可以快速感知最突出的文字并及时展现出来。但词云仅仅根据词频统计来显示词语使用频度的展现方式有些单薄,无法展现出关键词之间关联性,以及最近一段时间关键词的推演趋势,而共现矩阵可以通过关键词共现频度来逐次反映事件之间的内在联系,方便我们理解发展变化的内在逻辑,所以需要利用共现矩阵进一步处理数据。
但共现矩阵也明显存在不足,由于大量词语并没有同时出现,所以导致共现矩阵为稀疏矩阵,且在的"word-word-weight.csv"文档中,Weight 为 1 的词组对有 265840 组,高达 88.73%。所以大量的数据都是无效的,因此降低共现分析的时间空间复杂度很有必要。目前可以通过 SVD、PCA 方法进行降维,但计算量较大且时间紧张,不再赘述,将在之后的学习过程中进一步实现。
4.Gephi 绘制关键词图谱
4.1 数据初始化
4.1.1 构造顶点数组
新建 CSV 文件"entity.csv",将"word-word-weight.csv"文件中的 word1,word2 提取出来,去重,共得到 744 个顶点。
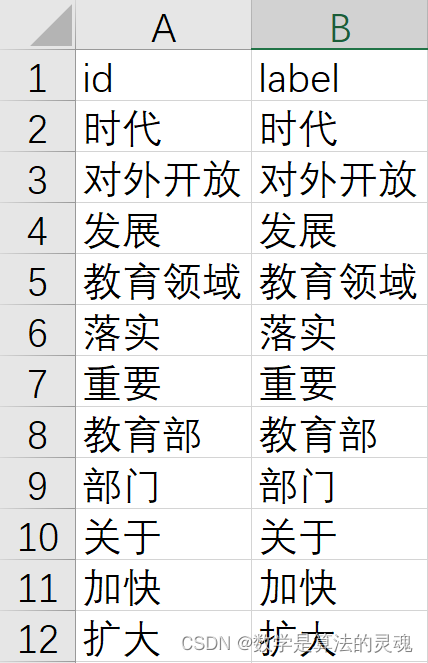
4.1.2 构造边集数组
新建 CSV 文件"relationship.csv",将"word-word-weight.csv"文件中的 word1,word2 以及 weight 提取出来,并添加属性"Type"为"Undirected",便于之后在 Gephi 中构建无向图。
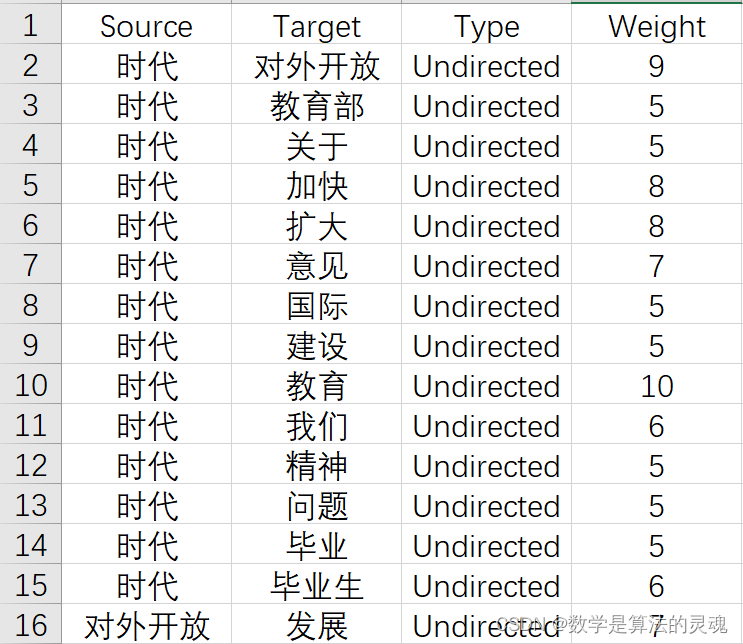
4.2 导入数据
4.2.1 导入顶点数组

4.2.2 导入边集数组

4.3 图谱绘制
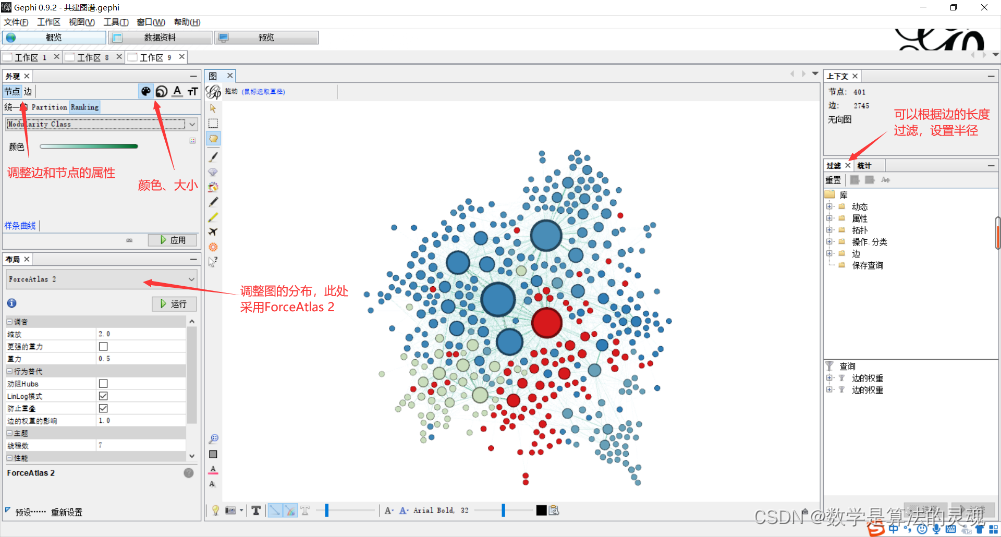
最后可以在预览处调整文字显示效果。
4.4 最终效果
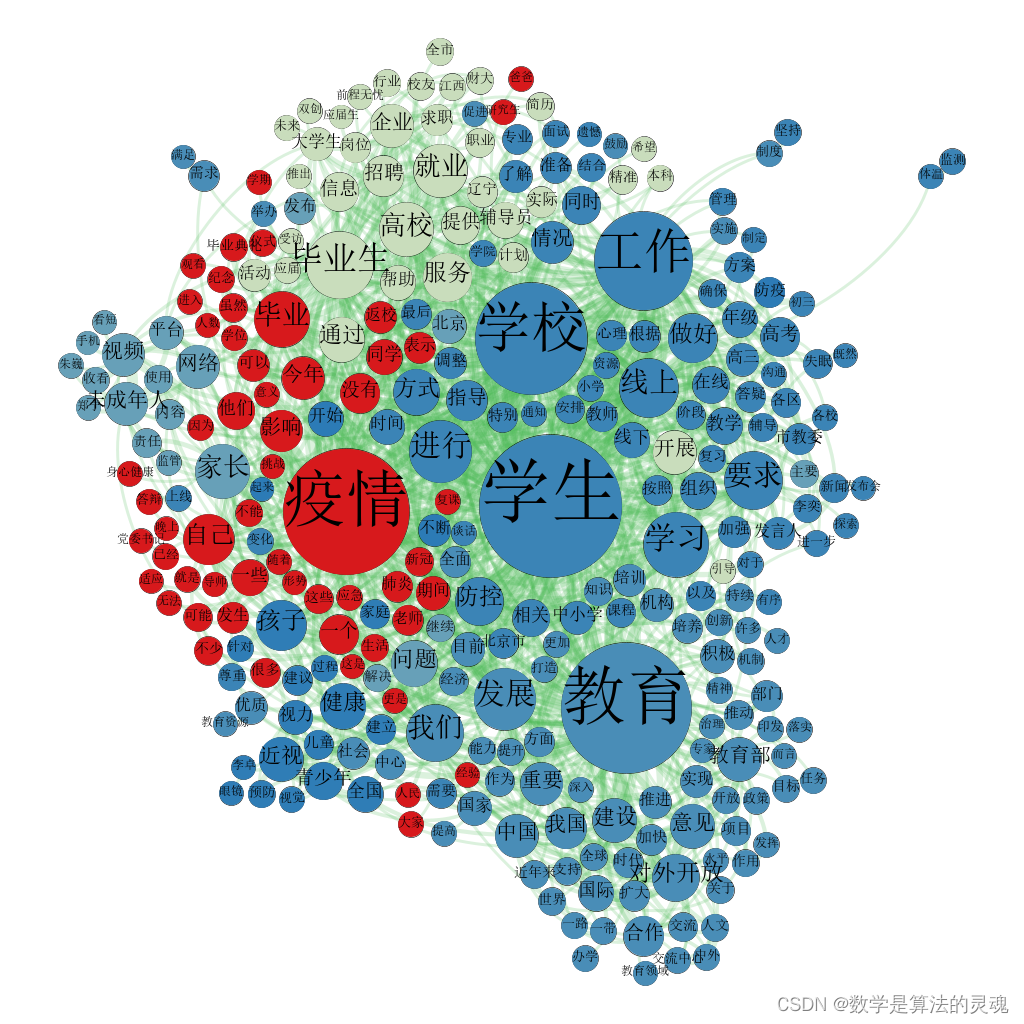
5.数据分析
从主题词图谱可以看出来,前十大关键词为学生、教育、疫情、学校、工作、毕业生、学习、发展、线上、要求。其中有八个词汇为蓝色,词汇“疫情”为红色,词汇“毕业生”为浅绿色。从中可以发现,深蓝色区域对应主要话题为学校教育、社会热点话题以及与国家宏观政策相关的关键词,浅绿色区域对应主要话题为毕业求职相关的关键词,红色区域对应主要话题为与疫情影响相关的关键词,蓝绿色区域对应主要话题为与青少年发展相关的关键词。
因此,对近期教育新闻的分析如下,毕业季到来,数以百万计的大学生和研究生将走上职场,招聘、求职相关的新闻自是不绝于耳。在面临疫情的冲击下,求职也愈发困难,国家对各单位提出的扩招等宏观调控政策也十分必要。同时,对于尚未毕业的大、中、小学生和职业学校的学生而言,由于疫情尚未完全控制,在家听网课、参加考试的状态仍需要保持一段时间。在宏观层面,国家也在积极建设,新闻发布会等多种形式进行及时的传播信息很重要。而对于广大青少年儿童而言,保护视力、身心健康、合理上网等老生常谈的话题依然不过时,尤其是当大家都只能待在家中的时候,家长更要注重孩子的健康发展。
6.总结
本次大作业采用课题报告的形式对于我而言是不小的挑战,既需要考虑期末考试的复习进度,还不能草草应付了事,所以其实是对 python 平时积累的考察,就像张老师刚带我们时候所言,第一个月学习基本语法,第二个月巩固、提升,第三个月就可以设计一下游戏,第四个月可以初步涉及机器学习、数据挖掘等领域,平时基础打扎实,不仅仅在处理大作业时能更加得心应手,更可以拓展眼界,开辟一片更辽阔的疆场。这次我选择使用共现分析 +Gephi 图谱也是希望自己可以综合之前学过的知识,再初步了解一下数据挖掘的知识,领略更加丰富的色彩。而我更期待在暑假到来的时候自己可以自由的驰骋在 python 的海洋中,挑战自我,寻找价值。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











