







其他章节笔记:
(一)操作系统的启动
(二)系统调用
(三)操作系统历史
(四)多进程管理图像
(五)进程,用户级线程与内核级线程
(六)进程同步与信号量
(七)内存管理
目录
线程切换与调度
并发是CPU高效工作的基础,而并发的基本含义就是多段程序交替执行。这种交替存在于两段“很远”的程序之间,也可以存在于两段“很近”的程序之间,比如同一个文件里的两个函数,前者就是进程,后者则诞生了线程的概念。
线程与进程
- 线程与进程的对比:
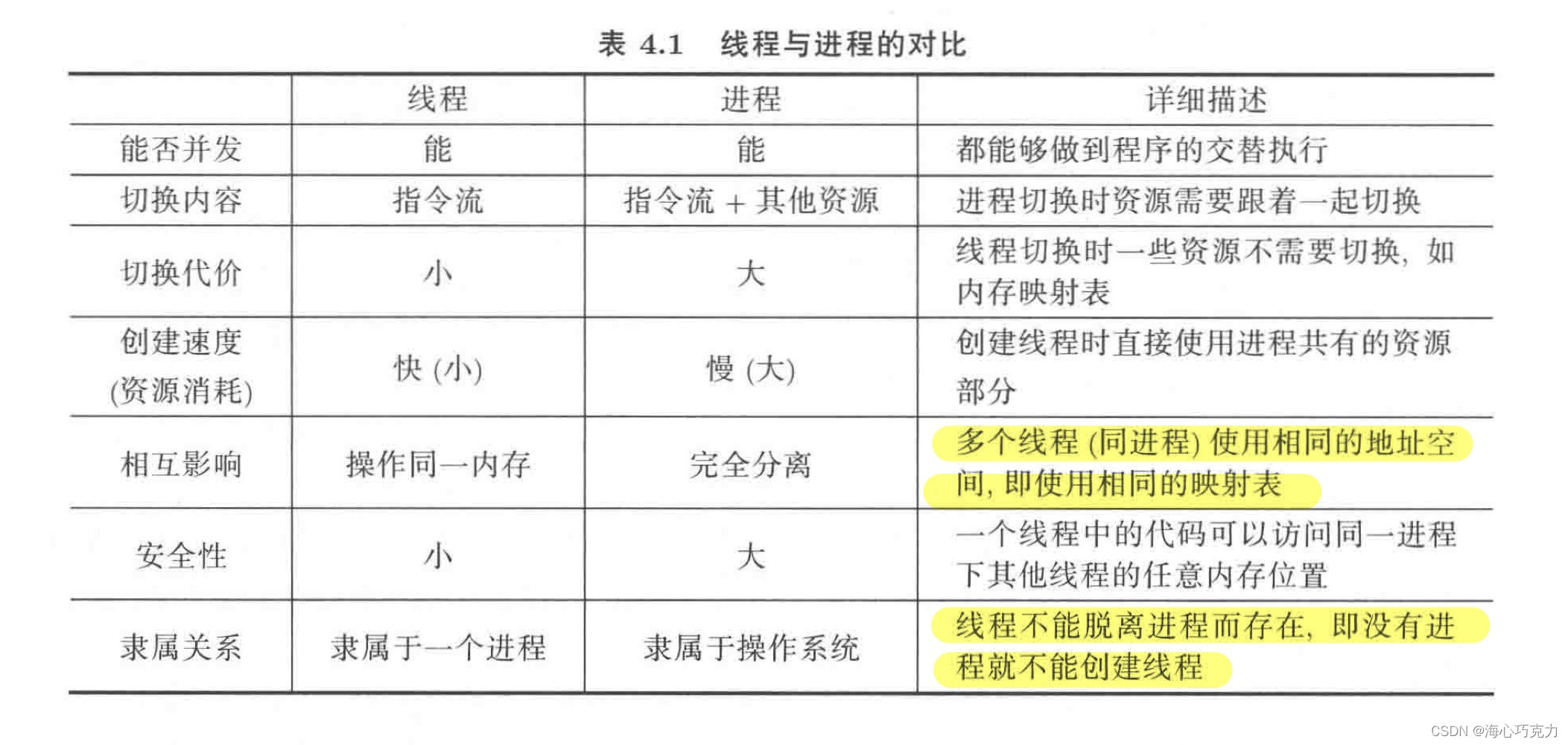
- 线程与进程的关系:线程是轻量级的进程,一个进程可以包含多个线程。
- 编写代码选择线程还是进程主要看资源是否需要共享
- 线程共享内存和同一个地址空间(映射表是一样的),不共享寄存器和栈。
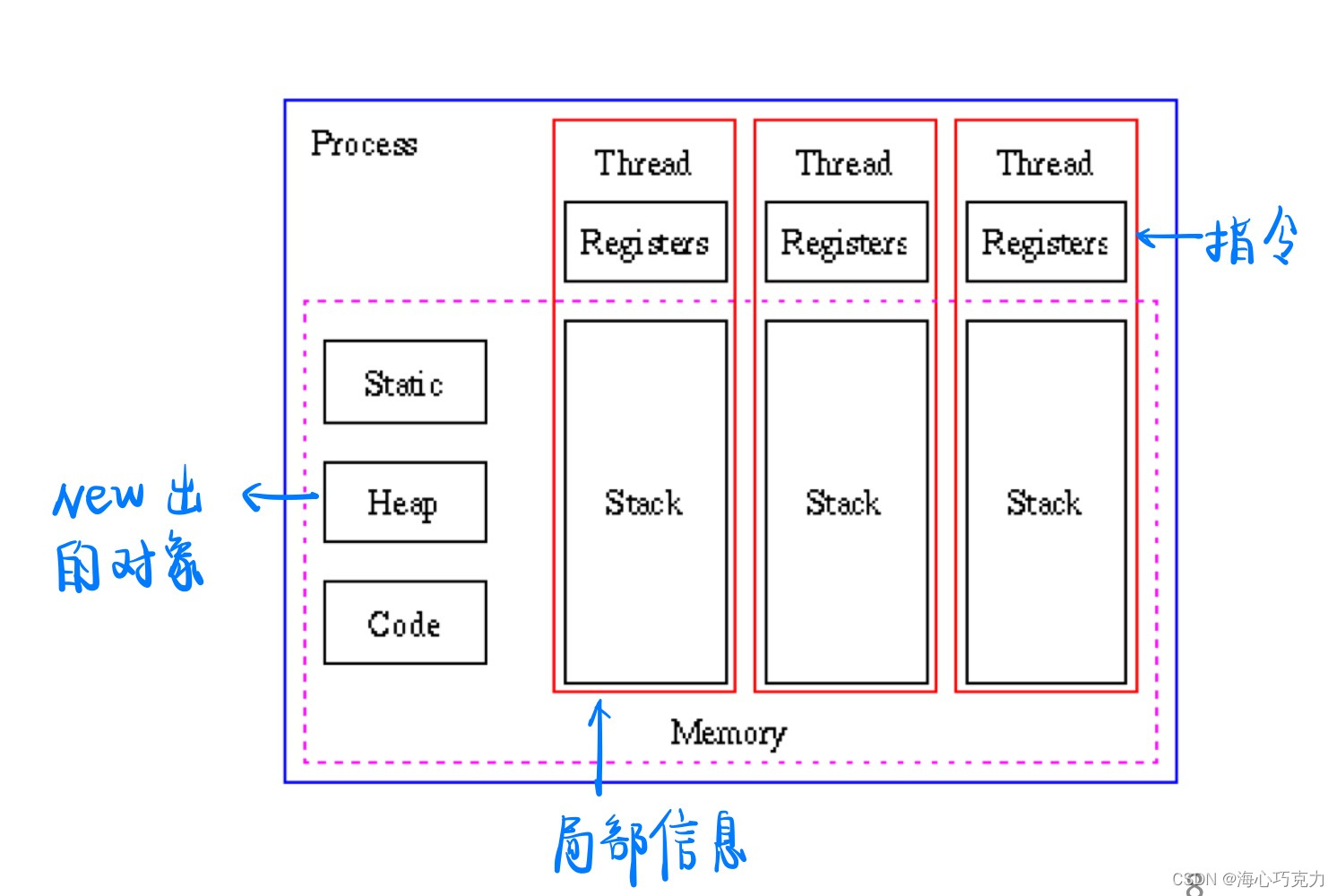
用户级线程
由用户程序自己管理的线程称为用户级线程。
用户级线程之间的切换:指令流+栈的切换
Yield()是完成切换的核心函数。如图,线程1运行函数A,调用函数B,压栈保存地址104;到函数B调用Yield(){jmp 300;},压栈保存地址204;切换到函数C,函数C调用函数D,压栈保存地址304;函数D调用Yield(){jmp 204;},切换回函数B,压栈保存地址404。
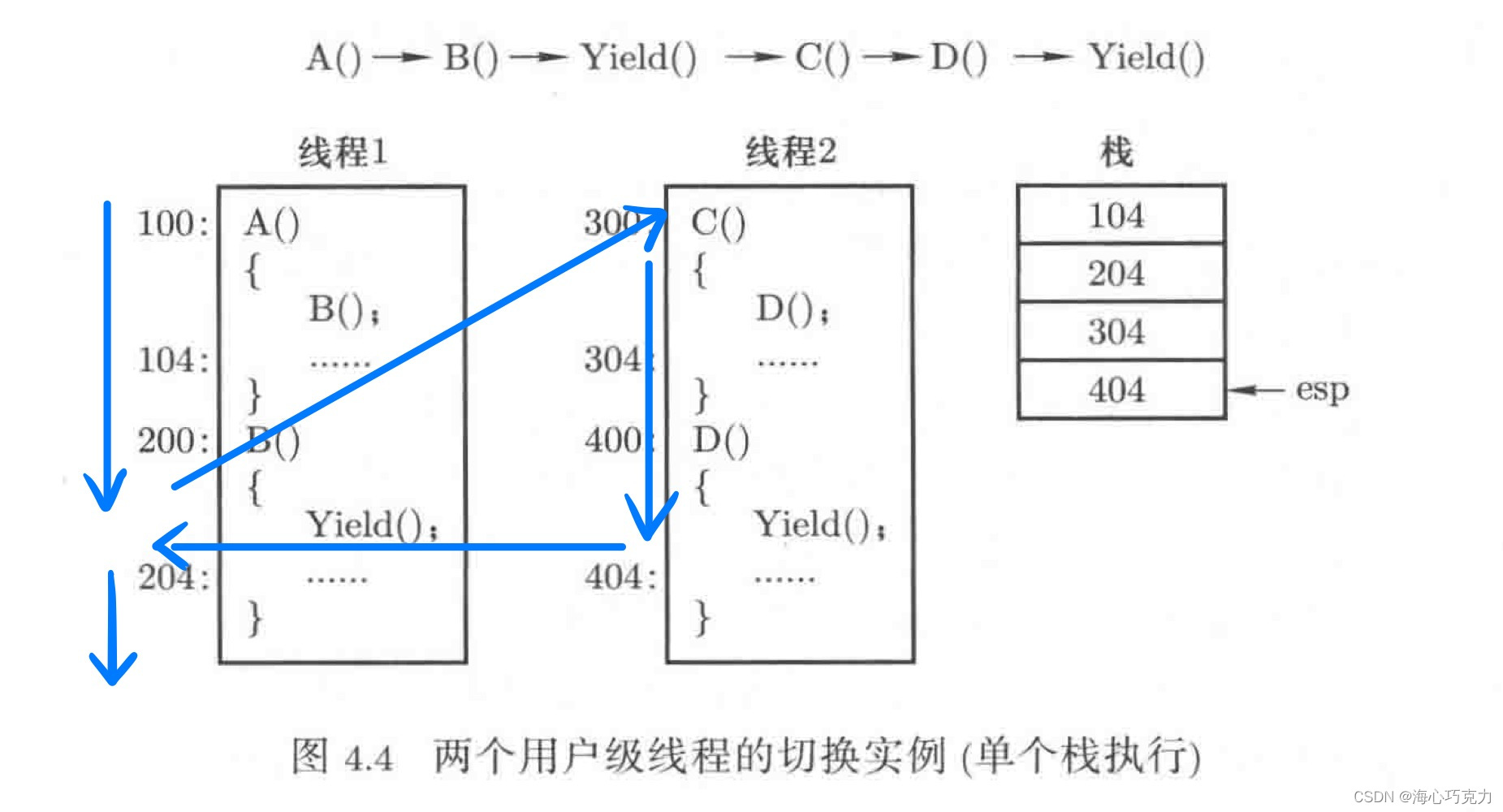
回到函数B时,应顺序执行函数B剩下的内容,再返回函数A执行代码。而此时栈顶是404,意味着运行指令会跳转到404往下执行,指令控制流显然发生错误,这种错误是两个线程之间的栈混乱管理带来的。
因为两个线程是两段具有不同功能的程序,所以它们的栈是不能一起管理的。
解决方法是每个线程申请一个栈。即每次线程切换,不仅要完成指令流的切换,还要完成栈的切换。此时Yiled函数改为:
Yield1(){ // 线程1 -> 线程2
TCB1.esp = 1004; // 把204压栈
esp = TCB2.esp; // 切换到线程2的栈
jmp 300;
}
Yield2(){ // 线程2 -> 线程1
TCB2.esp = 2004;
esp = TCB1.esp;
// jmp 204
}
其中esp为栈顶指针,TCB(thread control block)是存储线程信息的数据结构。栈的切换通过栈顶指针的切换完成。
注意当线程1切换到线程2时需要写“jmp 300”,而切换回来时不用写“jmp 204”,因为在线程1中调用Yield1跳转到线程2时已经完成了204的压栈,调用Yield2完成了栈的切换,此时运行到Yield2末尾遇到“}”时会执行弹栈返回,自然也能回到204.
如果写上“jmp 204”,则会导致线程1在运行B函数到末尾时再返回运行204一次,指令流也错误。
实际上多个线程来回切换的时候,应该也不太分哪个是切换去哪个是切换回了吧= =…
用户级线程的创建:用线程的切换完成创建
线程的创建也可以用线程的切换完成。创建一个用户级线程就是创建一个可以让CPU切换进去的初始样子。

申请栈空间,申请TCB空间,把程序的首地址存入栈中,TCB.esp 指向栈顶。当父线程调用Yield函数时,完成栈的切换,在运行到Yield函数末尾“}”时进行弹栈,完成线程的创建。
内核级线程
为什么需要内核级线程
- 内核级线程较用户级线程而言具有更好的并发性。
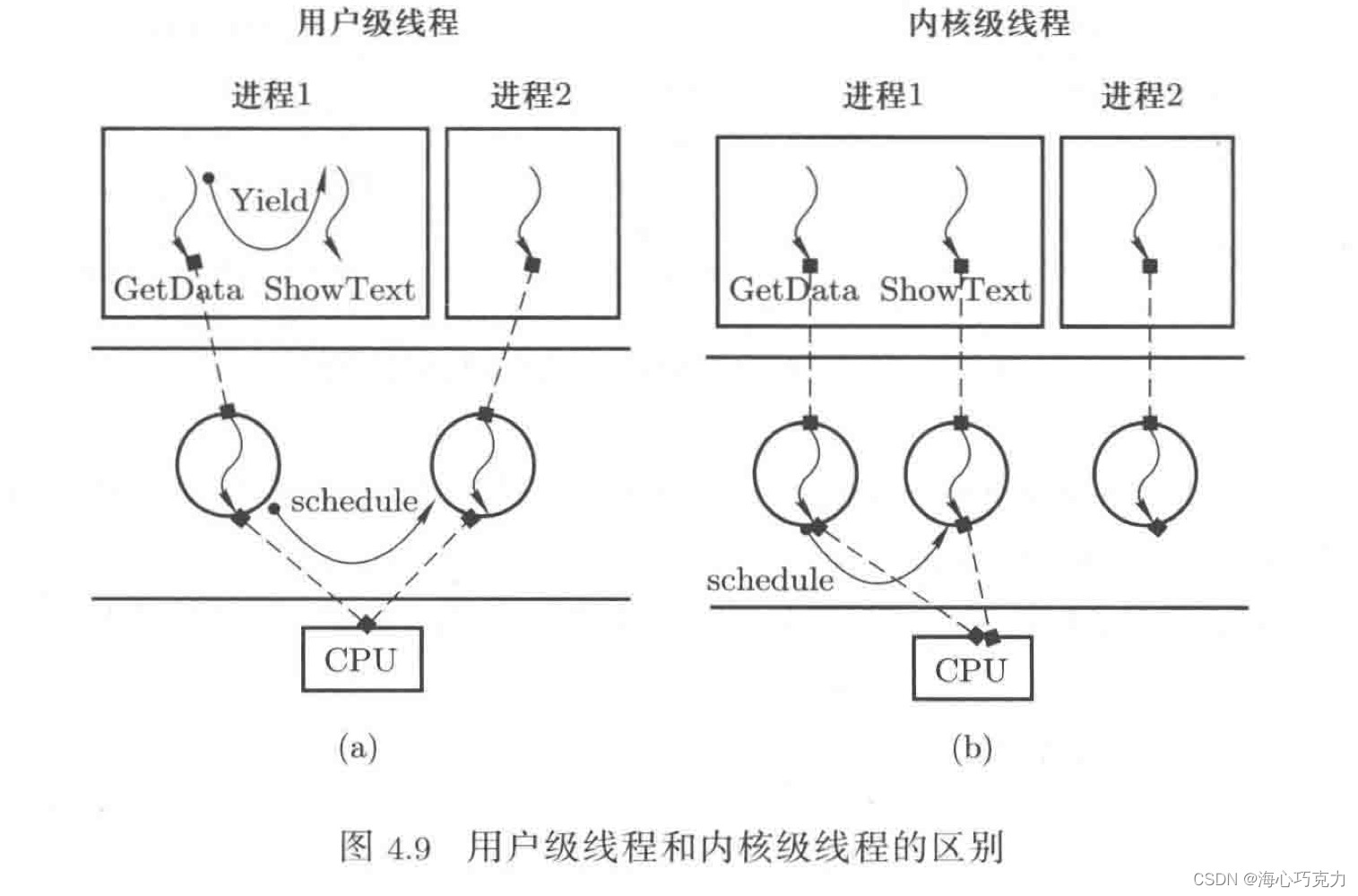
如图,进程1的GetData会通过网卡向网站发出数据下载请求,网卡是由操作系统负责驱动和管理的,所以GetData发出数据下载请求要借助系统调用进入操作系统内核才能完成。在等待网络连接时操作系统会控制CPU切换到进程2,而不会切换到进程1的ShowText。原因在于操作系统无法感知用户级线程ShowText的存在(用户级线程对应的TCB信息都处在用户态),只能调用schedule函数完成进程的切换。
因此,如果一个用户级线程在内核中阻塞,则这个进程的所有用户级线程将全部阻塞,限制了用户级线程的并发程度。
但是内核级线程就不一样了。内核级线程就是让内核态内存和用户态内存合作创建一个指令执行序列,内核级线程的TCB等信息是创建在操作系统内核中的,操作系统通过这些数据结构可以感知和操纵内核级线程,因此可以通过调用schedule函数来实现线程之间的并发。 - 内核级线程比进程更适应多核处理器。
这里有一台双核处理器:
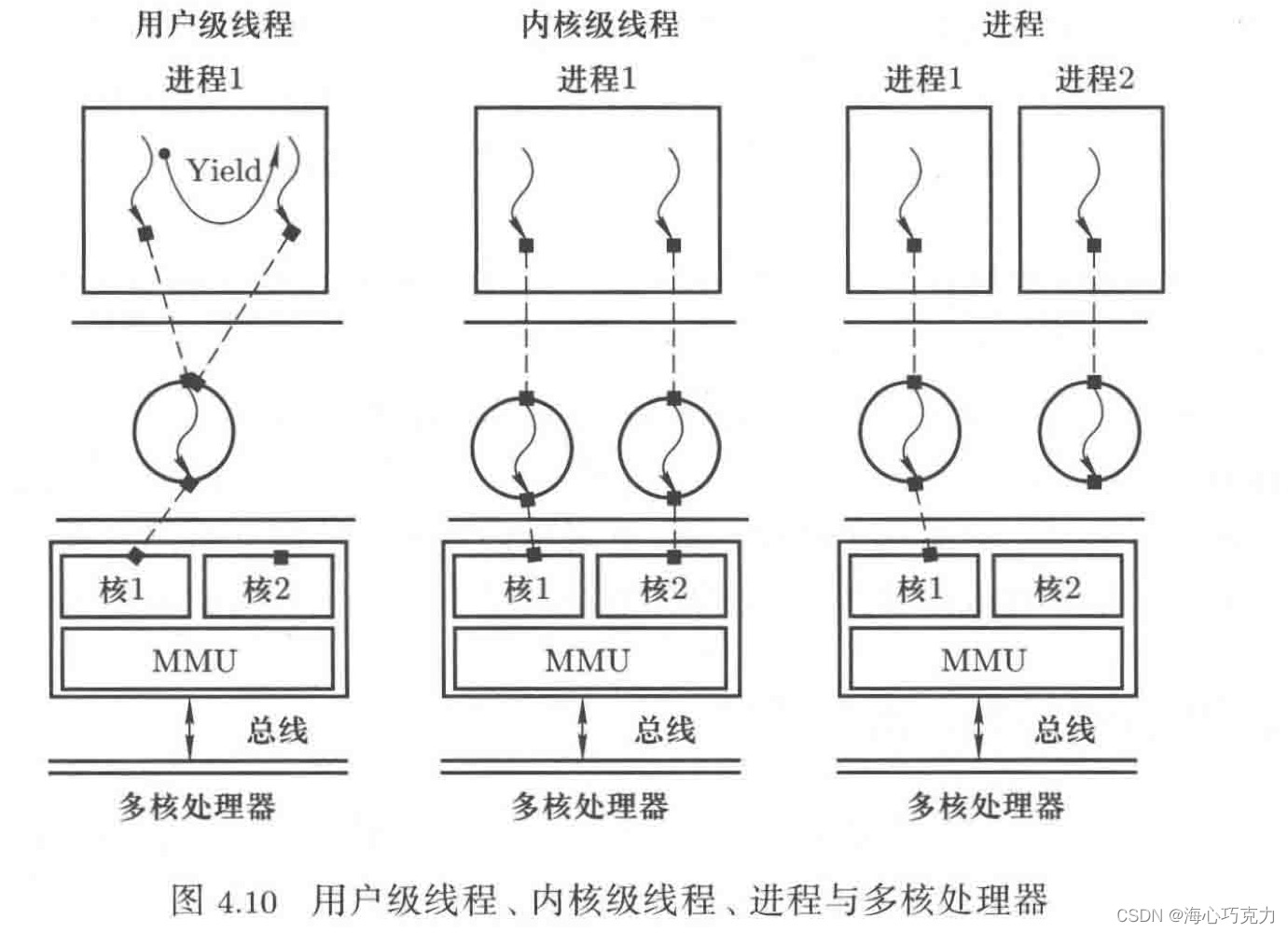
① 如果有两个用户级线程。因为操作系统不认识用户级线程,所以无法调度两个用户级线程,只能挤在一个核里工作,另一个核一直空闲。
② 如果有两个进程。操作系统可以调度,把两个进程分别放在两个核上运行,表面上看可以并行,但是多核处理器的内存资源共享,不可能同时去查两个映射表,所以实际上两个进程间不是并行的而是并发的。这样没有发挥出多核处理器的优势。
并行:三个人分别吃三个包子。
并发:一个人同时吃三个包子。
③ 如果有两个内核级线程 。因为创建于内核,所以操作系统可以调度;因为共享内存资源,所以没有进程的瓶颈,加快硬件处理速度,实现并行。
用户级线程,内核级线程,进程三者的区别与联系
- 联系:三者本质都是执行一个指令序列。
- 进程 = 分配栈+分配内存+切换指令流。
线程 = 分配栈+切换指令流。 - 进程,内核级线程:操作系统认识。
用户级线程:操作系统不认识。 - 事实上进程必须在内核中创建,因为进程涉及计算机资源的分配,而这些由操作系统掌管。因此进程中的执行序列其实是一个内核级线程。
上层应用程序也可以在进程的基础上开辟用户级线程,因为执行程序所需要的资源已经在创建进程的时候就分配好了。 - 三者都有各自的优点。用户级线程创建代价小,灵活性大;内核级线程可以提高并发性,有效支持多核处理器;进程之间互相分离,安全性高,可靠性好。三者协同可以提高CPU与硬件资源的利用率与灵活性。
内核级线程之间的切换
-
内核级线程拥有两个栈,用户栈与内核栈,在切换内核级线程时要同时切换这两个栈。内核级线程可以化简为“可以进入内核的用户级线程”,其中用户栈负责维护上层用户程序,内核栈负责在线程发生阻塞时,可以接受操作系统的调度,切换到另一个内核级线程去。
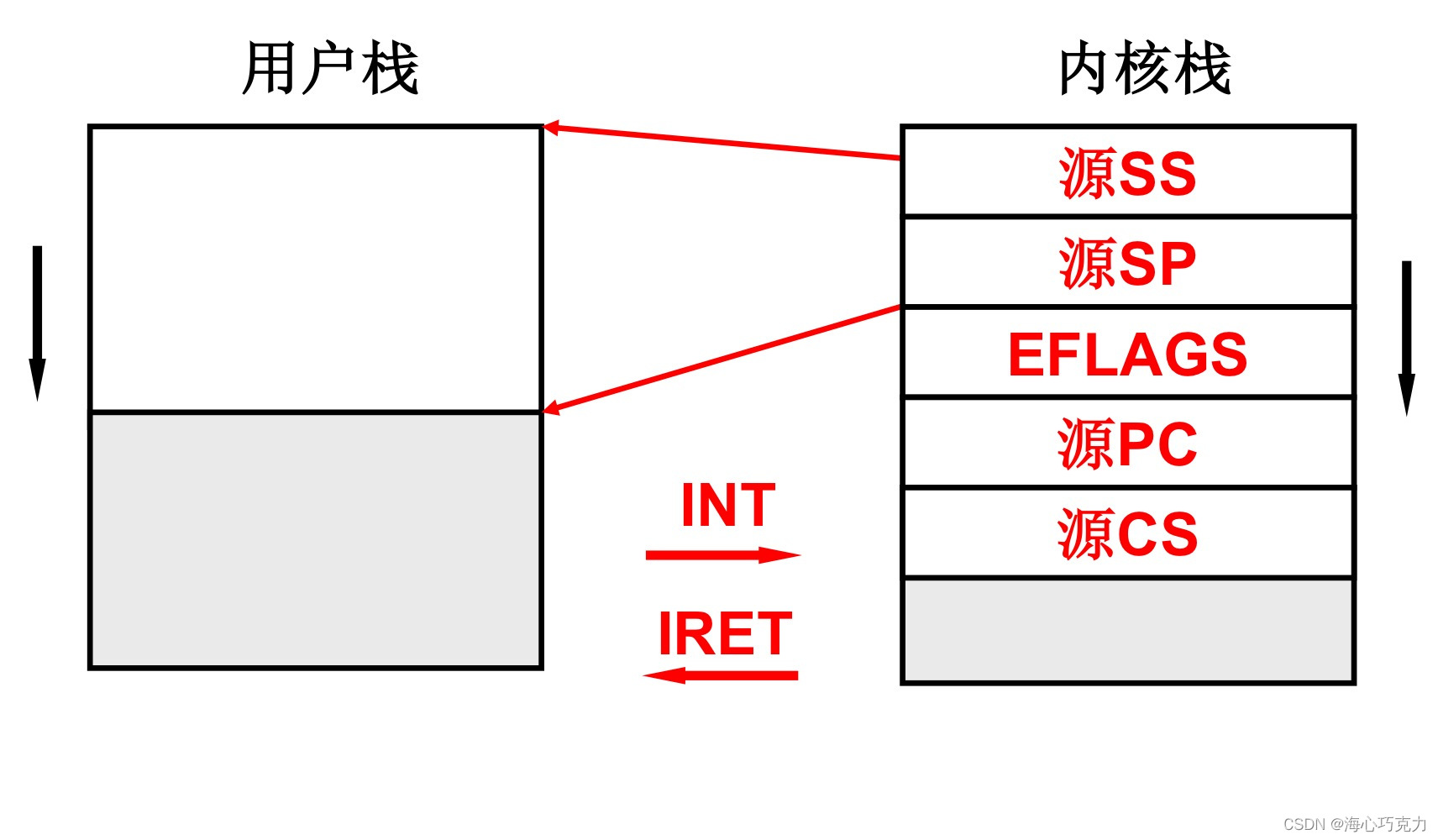
如图,内核栈中存有用户栈的地址(SS,SP),用户程序的返回地址(PC,CS),这样能将两个栈连起来,作为一套栈。其中INT是中断处理指令,用户态进入内核态,把用户态执行时的信息压入内核栈中;IRET是INT的逆过程,完成内核栈的切换后,通过这条指令完成用户栈的切换。 -
内核级线程之间的切换可以分为五个阶段:
- 中断入口:用户程序跑线程时发生要读写磁盘等需要中断处理的事件。
- 中断处理:要等待读写磁盘等结果,此时为了CPU运行效率引发切换。
- 调度:操作系统调用schedule函数进行调度。
- 内核栈切换:第一级切换,完成内核级线程切换。
- 中断出口:第二级切换,回到用户态处理代码。
-
具体代码实例
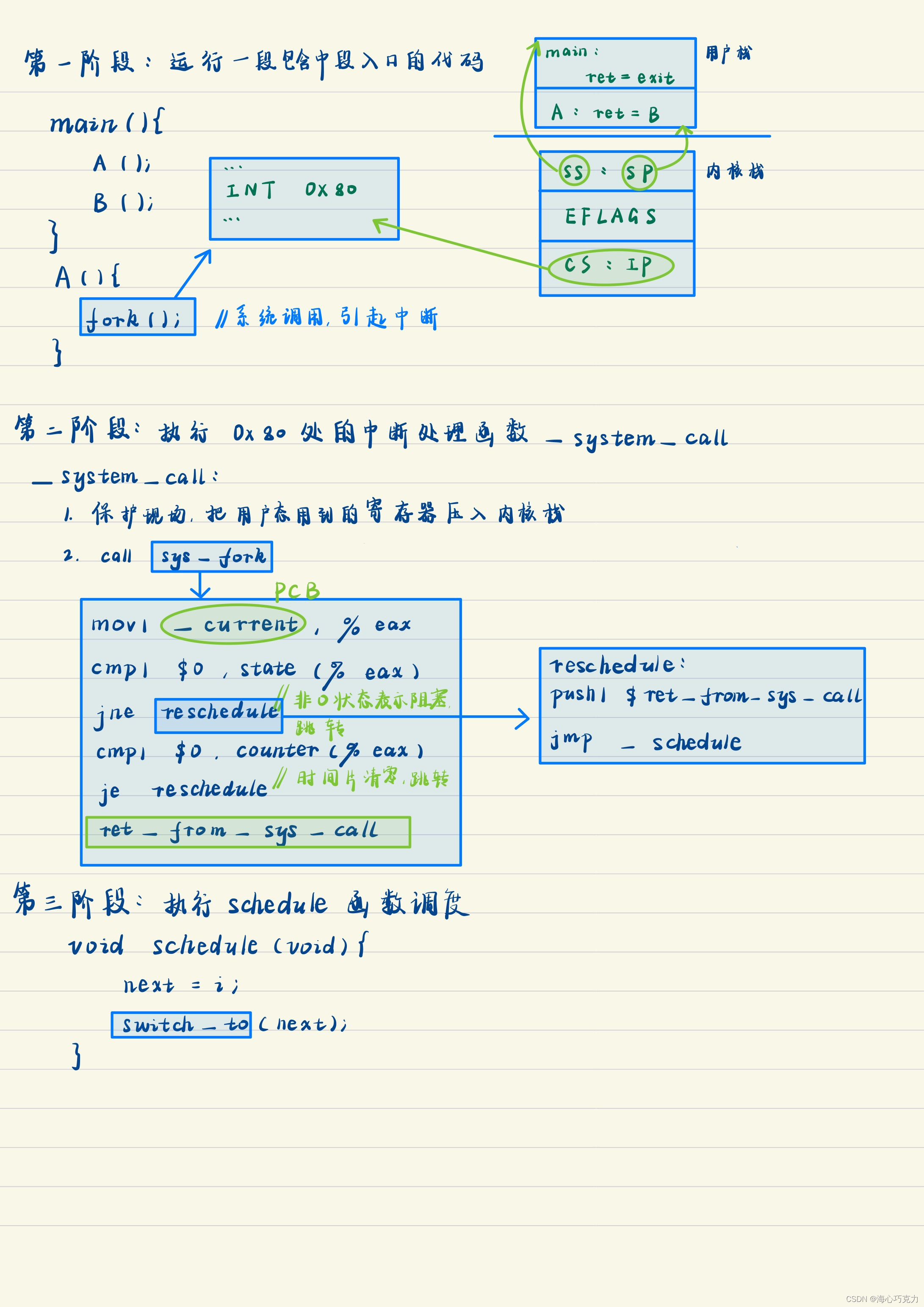
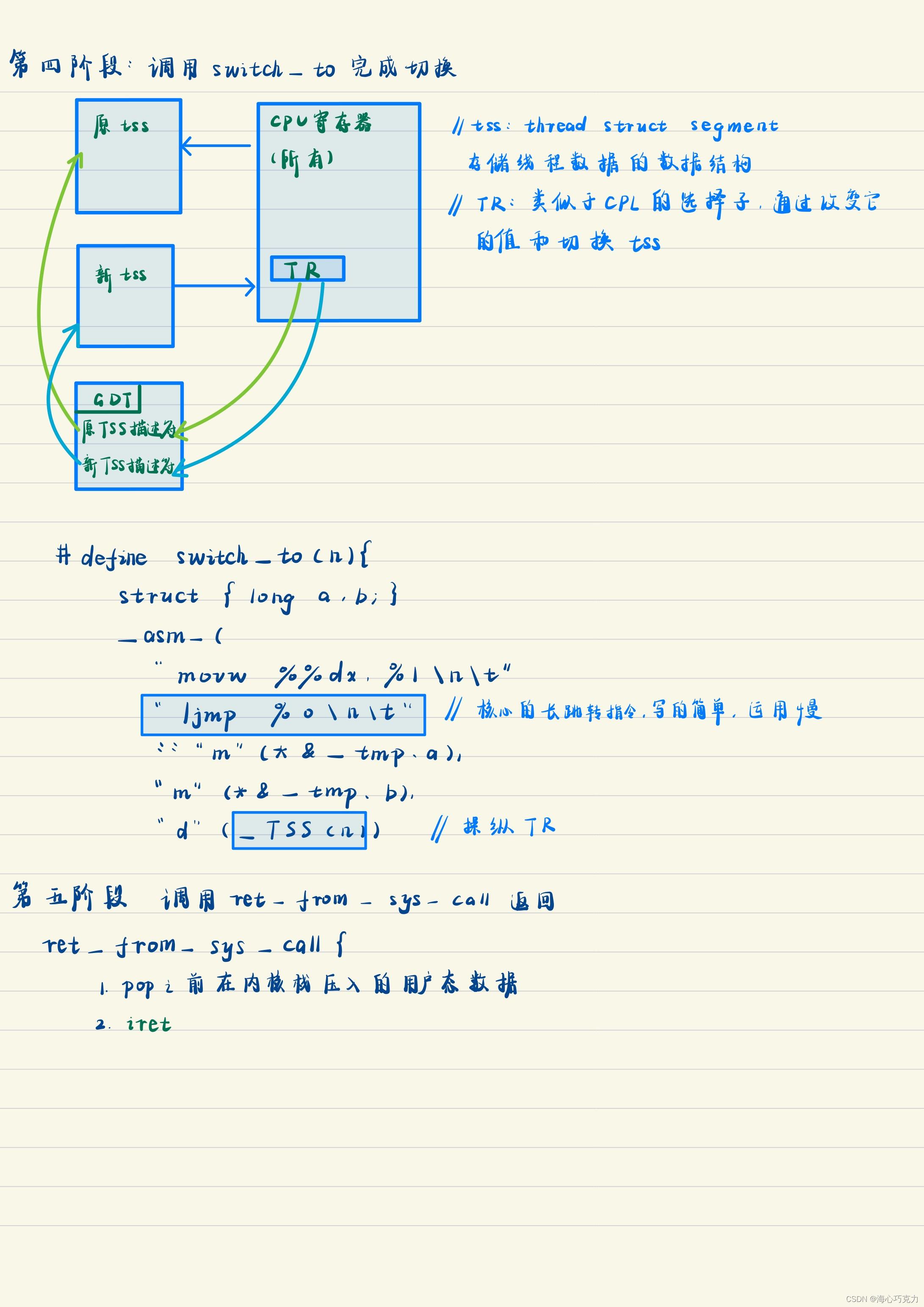
这里的切换用的是tss,tss切换简单,不用切换栈,但运行效率慢。配套实验是栈的切换。(不是很懂tss切换,写了实验应该会更清楚一点…)
内核级线程的创建
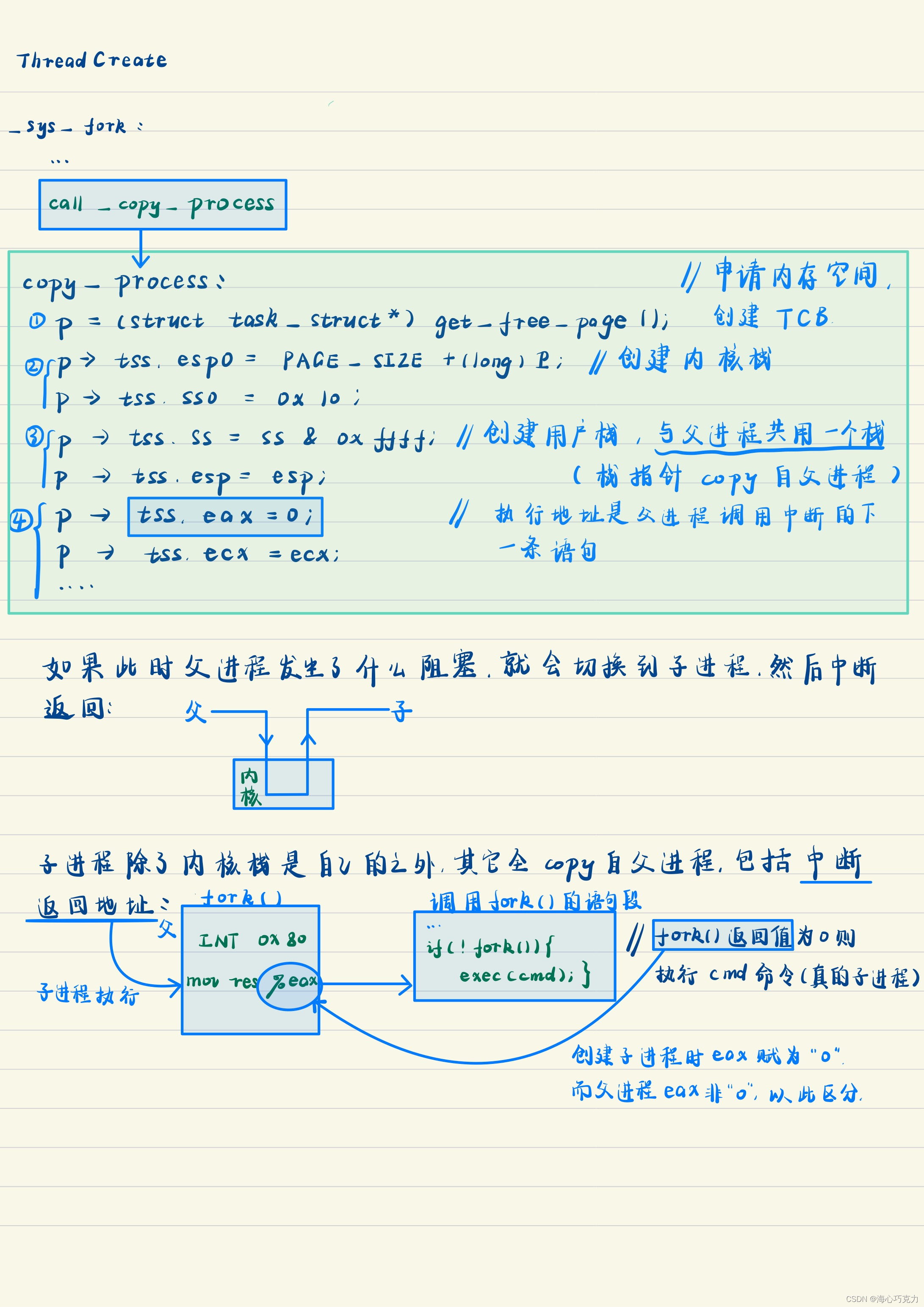
exec是系统调用函数,会根据传进来的cmd命令找到子进程要执行的真正代码段。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









