






一、路由器微体系结构
路由器执行传统的5级流水线(LT发生在路由器之间的连接上):
BW:把Head/Body/Tail Flit写到某个端口的VCx(端口W、VC1)
RC:根据Head Flit中的src、des计算输入端口(路由器1的E端口是路由0的输出E端口)
VA:为Head Flit分配下一个路由器的输入端口(根据RC计算得到的下一跳路由器1)的虚拟通道。例如:路由器0的VA以RC计算的结果为输入(分配路由器1端口1VC通道)
SA:仲裁两种情况:①多个虚拟通道争用交叉开关的同一个输入端口;② 多个输入端口争用交叉开关的同一个输出端口
ST:路由器读取VC通道中的Flit,穿过Crossbar
LT:Flit沿着路由器之间的链路传输到下一个路由
二、Garnet源代码学习(持续更新)
来自gem5官方文档Interconnection Network
1. 互连网络
首先可以根据默认网络配置,调用网络:
./build/NULL/gem5.debug configs/example/ruby_random_test.py \
--num-cpus=16 \
--num-dirs=16 \
--network=garnet2.0 \
--topology=Mesh_XY \
--mesh-rows=4
or
#注意,下面不是N*N拓扑,需要更改addr_range.hh Ruby.py源码之后,(re)build
./build/NULL/gem5.opt configs/example/garnet_synth_traffic.py \
--network=garnet \
--num-cpus=8 \
--num-dirs=8 \
--topology=Mesh_XY \
--mesh-rows=4 \
--sim-cycles=20000 \
--inj-vnet=0 \
--injectionrate=0.02 \
--synthetic=uniform_random
2. 拓扑结构
有Crossbar、CrossbarGarnet、Mesh_XY、Mesh_westfirst、MeshDirCorners_XY、Pt2Pt几种; --topology=XXX可调用该拓扑
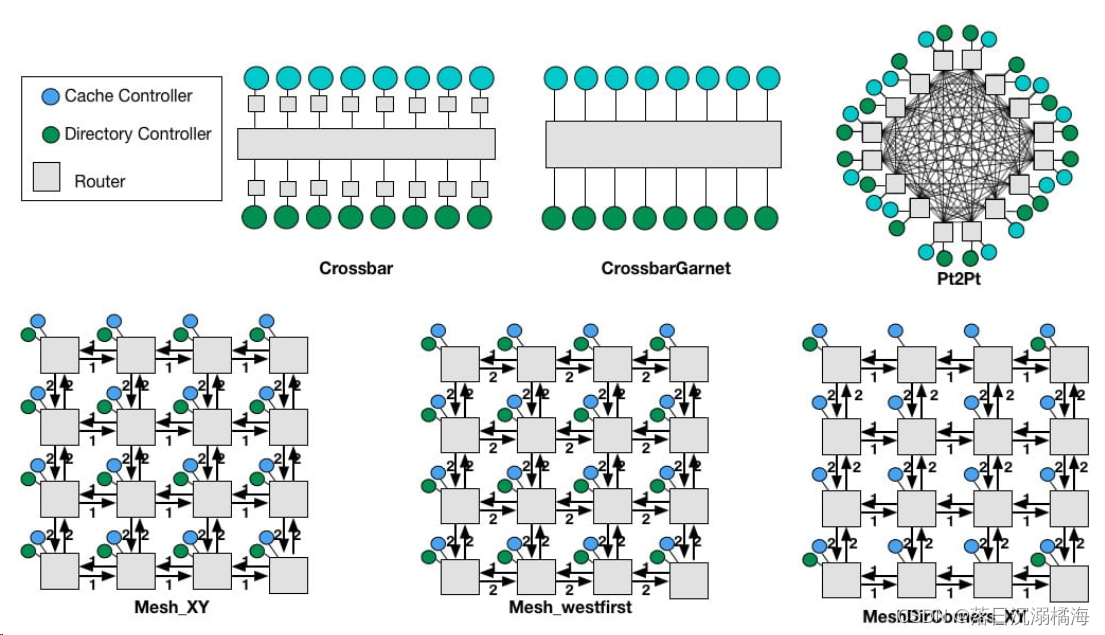
在每个拓扑中,BasicLink.py传递链接参数:(这里面的Param起到连接的作用,目前不明白)
定义BasicLink参数:link_id、latency、bandwidth_factor、weight、supported_vnets
定义BasicExtLink参数(外部链路--控制器和路由器间是双向的):ext_node、int_node、bandwidth_factor
定义BasicIntLink参数(内部链路--路由器之间是单向的):src_node、dst_node、src_outport and dst_inport(只用于Garnet)、bandwidth_factor(只用于simple network)
BasicRouter.py传递路由参数:router_id、latency
3. 路由
基于表的路由Weight-based Table(default):
src/mem/ruby/network/Topology.cc中默认路由算法,具有最少的链接遍历次数;
自定义路由算法(的调用):
在src/mem/ruby/network/garnet/GarnetNetwork.py定义:
--routing_algorithm=0,1,2(0:Weight-based Table,1:XY,2:自定义)
Garnet提供支持实现自定义路由算法模块——src/mem/ruby/network/garnet/RoutingUnit.cc::outportComputeXY()
4. 流量控制和路由器微架构
Ruby支持两种网络模型:Simple、Garnet,权衡建模详细程度和仿真速度
相关文件:
- src/mem/ruby/network/Network.py
- src/mem/ruby/network/simple
- src/mem/ruby/network/simple/SimpleNetwork.py
1)config
simple网络模型在 Network.py 中使用通用网络参数:
- number_of_virtual_networks:虚拟网络的数量
- control_msg_size:控制消息的大小(字节)。 默认值为 8,Network.cc 中的m_data_msg_size设置为块大小data_msg_size(字节)+ control_msg_size
其他参数在simple/SimpleNetwork.py 中指定:
- buffer_size:default internal buffer size for links and routers; 0 indicates infinite buffering
- endpoint_bandwidth:bandwidth adjustment factor
- adaptive_routing:enable adaptive routing
2)Flow control
设计中采用了虚通道流量控制。每个VC可以容纳一个数据包。在设计中,VCs分为两类——控制类和数据类。每个网络中的缓存深度都可以通过GarnetNetwork.py独立控制。默认值为1-flit deep control VCs和4-flit deep data VCs。控制报文大小默认为1flit,数据报文大小默认为5flit
5.网路遍历(重点,但还没理清)
涉及代码:src/mem/ruby/network/garnet/
CODE FLOW
NetworkInterface.cc::wakeup()
* 每个NI一端连接一个一致性协议控制器,另一端连接路由器
* 在vnet中从coherence protocol buffer接收消息,将其转换为网络数据包并发送到网络
* 此时Garnet添加了捕获网络跟踪的功能
* 从网络接收flits,提取协议消息并将其发送到适当的vnet中的一致性协议缓冲区
* 通过连接的路由器管理流量控制(即credits)
* NI消费flit/credit的输出被放在全局事件队列中,时间戳设置为下一个周期
* eventqueue调用consumer中的唤醒函数
NetworkLink.cc::wakeup()* 从NI/router接收flits,并在m_latency周期延迟后发送到NI/router
* 每个链路的默认延迟值可以在命令行中设置(见configs/network/network.py)
* 每个链路的延迟时间可以在拓扑文件中被覆盖
* 链接的消费者(NI/router)放在全局事件队列中,在m_latency周期之后设置一个时间戳。
* eventqueue调用consumer中的wakeup函数
Router.cc::wakeup()* 循环遍历所有的Inputunit并调用它们的wakeup()
* 循环遍历所有的Outputunit并调用它们的wakeup()
* 调用SwitchAllocator的wakeup()
* 调用CrossbarSwitch的wakeup()
* 路由器的唤醒函数在它的任何模块(InputUnit, OutputUnit, SwitchAllocator, CrossbarSwitch)有需要时(flit/credits)被调用
InputUnit.cc::wakeup()* 如果上游路由器准备好,就从上游路由器读取输入flit
* 对于HEAD/HEAD_TAIL flits,执行路由计算,并在VC中更新路由。
* 缓冲(m_latency - 1)周期的flits,并标记为有效,直到SwitchAllocation开始
* 每个路由器的默认延迟可以在命令行中设置(见configs/network/ network .py)
* 每个路由器的延迟(即,num个流水线阶段)可以在topology中设置
OutputUnit.cc::wakeup()* 如果下游路由器准备好,就从下游路由器读取输入credit
* 在适当的输出VC状态下增加credit值
* 如果credit携带is_free_signal为true,则将输出VC标记为空闲
SwitchAllocator.cc::wakeup()* 注意:SwitchAllocator在其内部执行VC仲裁和选择。
* SA-I(或SA-I):循环遍历每个输入端口上的所有输入VCs,并以轮询方式选择其中一个。
* 对于HEAD/HEAD_TAIL flits,只选择一个输出端口至少有一个空闲输出VC的输入VC。
* 对于BODY/TAIL flits,只选择一个在其输出VC中有积分的输入VC。
* 从这个VC中请求输出端口。
* SA-II(或SA-o):循环通过所有输出端口,并以轮询方式选择一个输入VC(在SA-I期间发出请求)作为该输出端口的获胜者。
* 对于HEAD/HEAD_TAIL微片,执行outvc分配(即从输出端口选择一个空闲的VC)。
* 对于BODY/TAIL flits,在输出vc中减少一个credit。
* 从输入VC中读取flit,并将其发送给CrossbarSwitch
* 为这个输入VC发送一个increment_credit信号到上游路由器。
* 对于HEAD_TAIL/TAIL flits,将is_free_signal标记为true。
* 输入单元通过credit链接将credit发送到上游路由器。
* 重新安排Router.cc::wakeup(),为下一个周期的flit进行SA做准备
CrossbarSwitch.cc::wakeup()* 循环所有输入端口,并将获胜的Flit从其output port发送到output link
* 路由器Output Link 消耗Flit被放入全局事件队列,时间戳设置为下一个周期* (The consuming flit output link of the router is put in the global event queue with a timestamp set to next cycle.)
* eventqueue调用consumer中的wakeup函数
NetworkLink.cc::wakeup()* 检查SerDes是否启用,并对其序列化或反序列化Flit适当的计算
* 检查CDC是否启用,并根据情况调度所有微片到消费者时钟域
6.garnet_synth_traffic*
scons build/NULL/gem5.opt PROTOCOL=Garnet_standalone
./build/NULL/gem5.opt configs/example/garnet_synth_traffic.py \
--network=garnet \ //--network:simple or garnet;
--num-cpus=8 \
--num-dirs=8 \
--topology=Mesh_XY \
--mesh-rows=4 \
--sim-cycles=20000 \
--inj-vnet=0 \
--injectionrate=0.02 \
--synthetic=uniform_randomNetwork configuration: configs/network/Network.py
| Network Config | Description |
|---|---|
| --router-latency | Default number of pipeline stages in the garnet router. Has to be >= 1. Can be over-ridden on a per router basis in the topology file. |
| --link-latency | Default latency of each link in the network. Has to be >= 1. Can be over-ridden on a per link basis in the topology file. |
| --vcs-per-vnet | Number of VCs per Virtual Network. |
| --link-width-bits | Width in bits for all links inside the garnet network. Default = 128. |
Traffic Injection: configs/example/garnet_synth_traffic.py
| Traffic Injection | Description |
|---|---|
| --sim-cycles | Total number of cycles for which the simulation should run. |
| --synthetic | The type of synthetic traffic to be injected. The following synthetic traffic patterns are currently supported: ‘uniform_random’, ‘tornado’, ‘bit_complement’, ‘bit_reverse’, ‘bit_rotation’, ‘neighbor’, ‘shuffle’, and ‘transpose’. |
| --injectionrate | Traffic Injection Rate in packets/node/cycle. It can take any decimal value between 0 and 1. The number of digits of precision after the decimal point can be controlled by ‘’–precision’’ which is set to 3 as default in ‘‘garnet_synth_traffic.py’’. |
| --single-sender-id | Only inject from this sender. To send from all nodes, set to -1. |
| --single-dest-id | Only send to this destination. To send to all destinations as specified by the synthetic traffic pattern, set to -1. |
| --num-packets-max | Maximum number of packets to be injected by each cpu node. Default value is -1 (keep injecting till sim-cycles). |
| --inj-vnet | Only inject in this vnet (0, 1 or 2). 0 and 1 are 1-flit, 2 is 5-flit. Set to -1 to inject randomly in all |
7.garnet_synth_traffic实现 GarnetSyntheticTraffic.cc
- 每周期每个 cpu 都会以 --injectionrate的概率执行 bernouli 试验,确定是否生成数据包
- 如果--num-packets-max为非负数,则每个 cpu 在生成--num-packets-max个数据包数后停止生成新数据包,在--sim-cycles个周期后终止注入
- 如果cpu生成新数据包,它会根据合成流量类型--synthetic计算新数据包的destination
- 目的地址destination嵌入到分组地址中块偏移量后
- 生成的数据包被随机标记为 ReadReq、INST_FETCH 或 WriteReq,并发送到 Ruby 端口 (src/mem/ruby/system/RubyPort*)
- Ruby端口会将数据包分别转换为RubyRequestType:LD、RubyRequestType:IFETCH和RubyRequestType:ST,然后发送给定序器,定序器再将数据包发送给Garnet_standalone缓存控制器
- 缓存控制器cache controller从数据包地址提取 destination directory
- 缓存控制器将 LD、IFETCH 和 ST 分别注入虚拟网络 0、1 和 2
- LD和IFETCH作为控制包(8字节)注入,而ST作为数据包(72字节)注入
- 数据包遍历网络并到目录directory
- 目录控制器directory controller只需将其删除即可















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









