







(本文是对gem5官方教程gem5: HeteroGarnet (Garnet 3.0)的学习记录)
HeteroGarnet在Garnet 2.0网络模型的基础上进行了改进,能够精确模拟新兴互连系统。改进包括:
- 支持独立时钟域,支持多个频域的网络交叉,以及能够连接到多个物理链路的网络接口控制器
- 通过引入新的可配置的Serializer-Deserializer组件来支持可变带宽链路和路由器
目录
拓扑构造
HeteroGarnet允许用户使用python配置文件进行复杂的拓扑配置。整体拓扑配置可以包括系统的完整互连定义,包括任何异构组件。
定义拓扑的一般流程包括以下步骤:
1. 决定系统中的全部路由器数量,并实例化它们
(1)使用Router类来实例化单个路由器
(2)配置每一个路由器的属性,例如:时钟域、支持的flit宽度
routers = Router(id, latency, clock_domain, flit_width, supported_vnets, vcs_per_vnet)2. 使用外部物理互连连接路由器和端设备(例如:内核、cache、Directories)
(1)使用ExternalLink类来实例化连接端设备的链路
(2)配置每条外部链路的属性,例如:时钟域、链路宽度
(3)根据互连拓扑,选择启用时域交叉(clock-domain crossing, CDC)和串行器-解串器(Serializer-Deserializer, SerDes)单元
external_link = ExternalLink(id, latency, clock_domain, flit_width, supported_vnets, serdes_enable, cdc_enable)3. 根据拓扑连接网络内部的各个路由器
(1)所用InternalLink类来实例化网络内部的链路
(2)配置每条内部链路的属性,例如:时钟域、链路宽度
(3)根据互连拓扑,选择启用时域交叉(clock-domain crossing, CDC)和串行器-解串器(Serializer-Deserializer, SerDes)单元
internal_link = InternalLink(id, latency, clock_domain, flit_width, supported_vnets, serdes_enable, cdc_enable)p.s. 在./configs/Network/Network.py中提供了一些预置参数,会自动完成部分步骤,例如:实例化网络接口、CDC、SerDes单元。
物理链路
Garnet中的物理链路模型表示互连线本身。
一条链路是一个单独的实体,它有自己的延迟、宽度和它可以传输的flit类型。这种链路还支持一种基于信令的背压机制(a credit based back-pressuring mechanism)。每条Garnet 3.0链路都可以使用适当的参数配置工作频率和宽度,这允许以不同频率工作的链路之间相互连接。
网络接口
网络接口控制器(network interface controller, NIC)是位于网络端系统(如:cache、DMA节点)和互连系统之间的对象。
NIC接收来自控制器的消息,并将其转换为固定长度的flit(流量控制单元的简称)。这些flit的大小是根据传出的物理链路来适当调整的。网络接口还管理着流出和传入flits的流量控制和缓冲区管理。Garnet 3.0允许多个端口连接到单个端点。因此,NIC决定某个消息或flit必须调度到哪里。
时钟域交叉单元

为了支持多时钟域,Garnet 3.0引入时钟域交叉(Clock Domain Crossing, CDC)单元,由先进先出缓冲区组成,可以在网络模型的任何地方实例化。
CDC的延迟是可以配置的,也可以根据连接到它的时钟域动态计算。这使得DVFS技术的精确建模成为可能,因为CDC延迟通常是生产者和消费者的工作频率的函数。
DVFS:Dynamic voltage and frequency scaling,动态电压频率调整。根据芯片所运行的应用程序对计算能力的不同需要,动态调节芯片的运行频率和电压(对于同一芯片,频率越高,需要的电压也越高),从而达到节能的目的。
串行器-解串器单元

为了支持系统中的多种互连宽度,Garnet 3.0引入串行器-解串器(Serializer-Deserializer)单元,它在位宽边界上将flit转换为适当的宽度。与CDC类似,也可以在网络模型的任何地方实例化。
路由
路由算法决定flits如何在拓扑中移动。路由策略的目标是最小化争用,同时最大限度地利用互连所提供的带宽。Garnet 3.0提供了一些标准路由策略供用户选择。
路由策略
对于通过互连网络的flit的无死锁路由,已经提出了几种通用路由策略。
基于表的路由
Garnet还具有基于表的路由策略,用户可以选择使用基于权重的系统来设置自定义路由策略。权重较低的链路优先于配置为权重较高的链路。
流量控制和缓冲管理
流量控制机制决定了互连系统中的缓冲区分配。一个好的流量控制系统的目标是最小化缓冲区分配对系统中消息的整体延迟的影响。这些机制的实现通常涉及互连系统中物理数据包的微观管理。
缓存控制器生成的一致性信息通常被分解为固定长度的flit(流量控制单元)。携带消息的一组flit通常被称为包(packet)。数据包可以有头部、主体和尾部,以携带消息的内容以及数据包本身的任何附加元数据。在资源分配的不同粒度上,几种流量控制技术被提出并实现。
Garnet 3.0实现了一种基于信令的flit级别的流量控制机制,支持虚拟通道。
虚拟通道
虚拟通道(Virtual Channels, vc)在网络中充当独立的队列,可以在两个路由器或仲裁器之间共享物理线路(物理链路)。虚拟通道主要用于缓解头线阻塞(head-of-line blocking)。然而,它们也被用作避免死锁的一种手段。
缓冲背压(Buffer Backpressure)
互连网络的大多数实现不允许在遍历过程中丢弃包或flit。因此,有必要严格管理使用背压机制的flits。
基于信令的背压
基于信令(credit-based)的背压机制通常用于低延迟的flit拥塞(flit-stalling)实现。信令跟踪下一个中间目的地可用的缓冲区数量,方法是每次发送flit时减少总的缓冲区数量。当信令被清空时,目的地会将其退回。
互连系统中的路由器在网络中执行仲裁、缓冲区分配和流量控制。路由器微架构的目标是最小化路由器内的争用,同时为flit提供最小的每跳延迟。路由器微架构的复杂性也会影响互连系统的整体能量和面积消耗。
Garnt 3.0中消息传输过程
在本节中,我们描述一条消息在缓存控制器单元生成后在NoC中的生命周期。
下图展示了一个简单的示例场景,其中一个消息由缓存控制器生成,目的地是另一个缓存控制器,通过物理链路、串行器-解串器单元和时钟域交叉,由路由器连接。
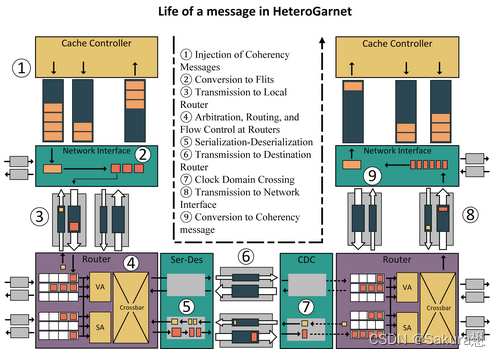
1. 消息注入
源cache控制器创建一条消息,并将一个或多个cache控制器分配为目标。然后将此消息注入到消息队列中。cache控制器通常有几个针对不同类型消息的传出和传入消息缓冲区。
2. 转化为flit
每个cache控制器上都有网络接口控制器(NIC),该NIC被唤醒并处理消息队列中的消息。每一条消息被转化为单播消息,然后根据传出物理链路支持的大小将其分解为固定长度的flit。然后,根据下一跳的缓冲区的可用性,通过其中一条输出链路对这些flit进行传输调度。传出链路的选择取决于目的地、路由策略和消息类型。
3. 传输到本地路由器
每个网络接口连接到一个或多个本地路由器,这些路由器可以通过外部链路连接。一旦flit被调度,它就通过这些外部链路传输,这些外部链路在一段定义的延迟后将flit交付给路由器。
4. 在路由器上进行仲裁、路由和流量控制
flit唤醒路由器,路由器是一个多级单元。路由器包含输入缓冲区、VC分配、交换机仲裁和交叉单元。到达时,flit首先被放置在输入缓冲队列中。路由器中有几个输入缓冲队列,它们争夺一个输出链路和一个VC作为下一跳。这是在使用VC分配和交换机仲裁阶段完成的。一旦一个flit被选择用于传输,交叉阶段将flit定向到输出链接。然后,为了为下一个flit的到达腾出输入缓冲区空间,信令(credit)被发送回NIC。
5. 序列化-反序列化
序列化-反序列化(SerDes)是一个可选单元,可以根据设计需求启用它。SerDes单元将flit转换为适当的输出flit大小。除了操作数据包之外,SerDes还通过序列化或反序列化信令单位来处理信令系统。
7. 时域交叉单元
时域交叉单元(CDC)也是一个可选单元,根据设计需求启用它。具体实现为通过设定的延迟将flit交付给本地路由器。
总结
HereoGarnet通过添加两个可选单元(SerDes、CDC)实现对跨时域和可变带宽链路系统的模拟。在其发表的论文中(Bharadwaj S, Yin J, Beckmann B, et al. Kite: A family of heterogeneous interposer topologies enabled via accurate interconnect modeling[C]//2020 57th ACM/IEEE Design Automation Conference (DAC). IEEE, 2020: 1-6.)提出该仿真架构能针对混合NoC/NoI的系统。
该模型仍然不够完备,不同设备之间消息传输的链路应该存在一定的差异性,可以添加更丰富的互连接口协议和路由算法,例如:在跨多个chiplet的通信需要考虑更多的外部链路和封装延迟。














 3593
3593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









