







Autoregressive Models
Autoregressive Models vs GANs

PixelRNN

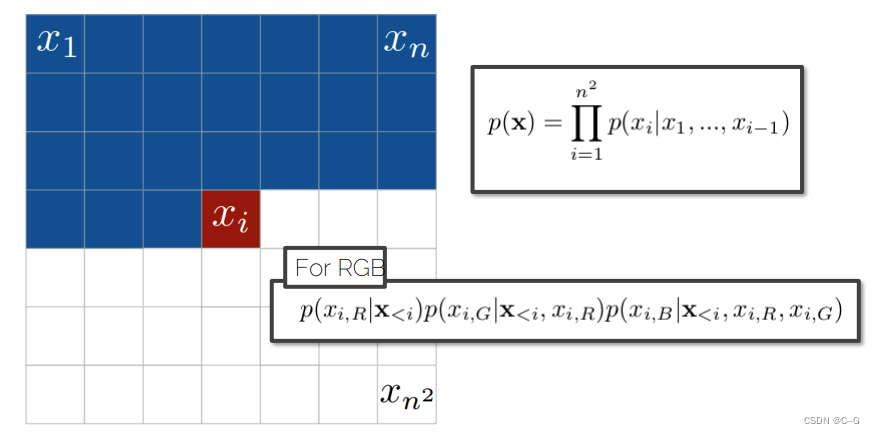

Row LSTM

Diagonal BiLSTM



网络架构

Gated PixelCNN

Blind Spot

** Eliminating Blind Spot**

Conditional PixelCNN

Autoregressive Models vs GANs

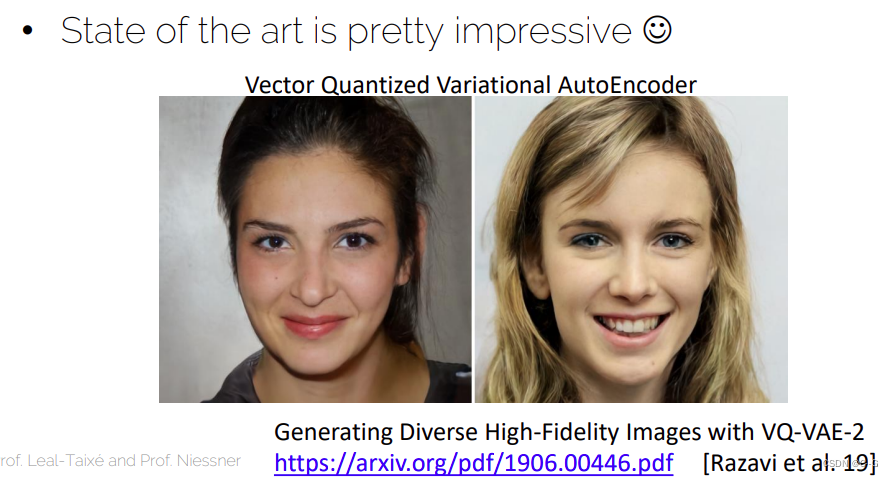
Generative Models on Videos
GANs on Videos

DVD-GAN(怪异视频生成器)
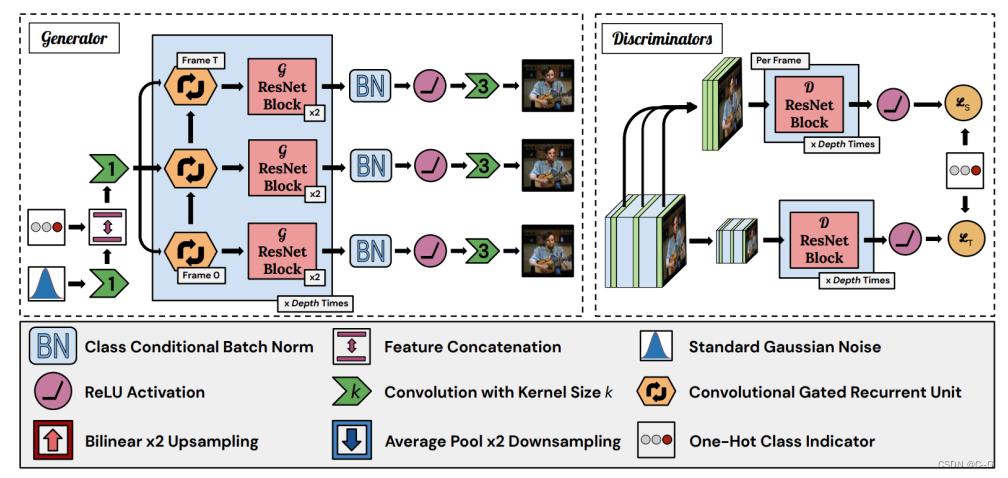
DVD-GAN 能够生成高分辨率和具备时间一致性的视频。它将大型图像生成模型 BigGAN 扩展到视频领域,同时使用多项技术加速训练。
与之前的研究不同,该模型的生成器不包含前景、背景或光流的显式先验信息,而是依赖于大容量的神经网络,以数据驱动的方式学习这些信息。DVD-GAN 包含自注意力和 RNN,但是它在时间或空间中并不具备自回归属性。RNN 按顺序为每个视频帧生成特征,然后 ResNet 并行地输出所有帧,联合生成每一帧中的所有像素。也就是说,每一帧中的像素并不直接依赖于视频中的其他像素,这与自回归模型并不相同。



- 双判别器
DVD-GAN 使用两个判别器:空间判别器(Spatial Discriminator:D_S)和时间判别器(Temporal Discriminator:D_T)。
D_S 对视频随机采样 k 个全分辨率帧,并对单个帧的内容和结构进行评价。研究人员使用了 k=8 的参数。和 TGANv2 一样,D_S 的最终分数是每个帧的分数之和。
D_T 则向模型提供生成动作的学习信号(动作是 D_S 无法评价的)。研究人员对整个视频使用了一种空间降采样函数 φ(·),并将函数的输出作为 D_T 的输入。这个降采样函数是一个 2 × 2 平均池化函数。
-
可分离自注意力
研究人员使用了一种名为可分离自注意力(Separable Attention)的机制。研究人员没有选择同时注意所有位置上的特征,而是将三个注意力层排为一行,一个接一个分别对视频的高、宽和时间轴进行注意力计算。这可以被视为是因式注意力(Factorized Attention)的一种特殊情况。 -
实验结果
DVD-GAN 建立在 BigGAN 架构之上。每个 DVD-GAN 都使用 TPU v3 进行训练,从 32 个 cores 到 512 个 cores 不等。研究者使用 Adam 优化器,最多训练 300000 步。研究人员使用了 TF-Replicator 进行数据并行训练。耗费的时间在 12 小时到 96 小时不等。
DVD-GAN 主要在Kinetics-600 数据集上进行实验,其中 Kinetics 是一个由10秒 YouTube 高清视频片段组成的大型数据集。研究人员使用了它的第二个迭代版本——Kinetics-600。该数据集包含 600 个类别,每一类至少有 600 个视频。数据集总共有大约 50 万个视频

Video-to-Video Synthesis
Nvidia在pix2pixHD的基础上,提出了高分辨率视频序列生成模型vid2vid。在前作能够生成高清图像的基础上,增加了帧序列generator,时间-空间Discriminator,帧间光流约束来辅助高清视频的生成。
- 视频序列生成
vid2vid解决的问题是以源视频(如semantic map序列或者从人脸视频中提取的边缘序列)作为条件输入
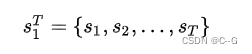
生成目标视频(真实街景图像或者人脸)
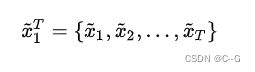
其中上标的T和下标的1代表从时间维度上的第1帧~第T帧
因此其目标是使生成视频的条件分布尽可能与真实视频的条件分布相近,即
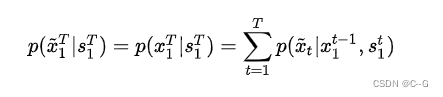
为了简化这个问题的求解难度,对这个过程做了马尔可夫假设,即当前帧生成的视频 [公式] 仅与前 [公式] 帧的信息相关,而不是与整个 [公式] 帧的视频序列的信息都相关,因此上式的约束条件就变成了
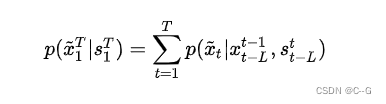
其实从直观上理解,就是在生成第 [公式] 帧视频时,只需要将下边三类信息送入网络即可:
-
当前第 [公式] 帧的条件输入 [公式]
-
前L帧的条件输入 [公式]
-
模型生成的前L帧图像 [公式]
对于输入2)和3),马尔可夫假设保证只需要提供前L帧的信息,而不是前边所有帧的信息,显然就会使网络更容易优化。文章通过实验发现L一般取2就可以,L太小会损失时序信息,L太大会造成巨大的GPU开销且提升的效果也有限。
- 光流约束
视频中一般存在的着大量的信息冗余,对于相邻的两帧图像,在空间上大部分区域像素都是相同的,而只有少部分存在运动的区域的像素有较大的变化,光流(optical flow)是可以用来表示这些区域的变化大小和方向。因此在生成第 [公式] 帧视频时,相比与仅使用条件输入 [公式] 信息(类似pix2pixHD那样)或者使用前L帧视频的完整信息,更好的方式是估算从第 [公式]帧到第 [公式] 帧的光流 [公式] ,然后作用于 [公式] 帧(此过程称为wrap),从而直接得到当前第 [公式] 帧的预测值,即加入光流约束。这种方法除了被遮挡或者移动到视频外部的区域,对于大部分区域的预测都是准确的。
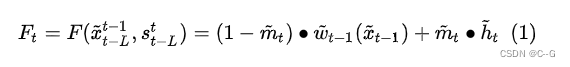
1)
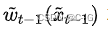
就是上文所说的,将估计的光流作用于前一帧图像,从而得到下一帧图像的预测值,其中估计的光流如图1和图2的右下角所示,是由Generator的一个单独分支生成的,其训练过程中的GroundTruth是由Flownet2生成的(所以对于vid2vid来说,其光流估计准确率的上限也就是Flownet2的准确率,但考虑光流约束只是一个辅助,这样的方法也是可行的);
2)
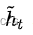
是仅使用条件输入和前几帧的信息得到当前帧的原始图像,没有加光流约束,简单说 [公式] 的生成过程与pix2pixHD是完全一致的,没加入新东西;
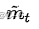
是权重map,即对通过1)中flow预测得到的当前帧图像和由2)中条件输入直接生成的当前帧原始图像进行融合时,两部分各占的比例大小。
这里解释一下,其实这个思路很好理解,既然直接生成的原始图像没有考虑光流约束可能造成时序不一致,而仅仅使用光流wrap得到下一帧图像在多帧图像之后容易造成累计误差,且当图像出现遮挡或者移出画面会造成预测不准确,那么直接将这两种方法生成的图像融合在一起就可以了,融合的方法也很简单,就是把这两部分的结果加权平均,而这个权重就是 [公式] ,是一个与生成图像一样大小的map(mask),这样图像的不同区域还可以使用不同的权重。这个 [公式] 也是网络自己学出来的,在图1和图2中也是生成flow map的那个分支负责生成的。最终这个加了flow约束的Generator就如式(1)所描述的这样。
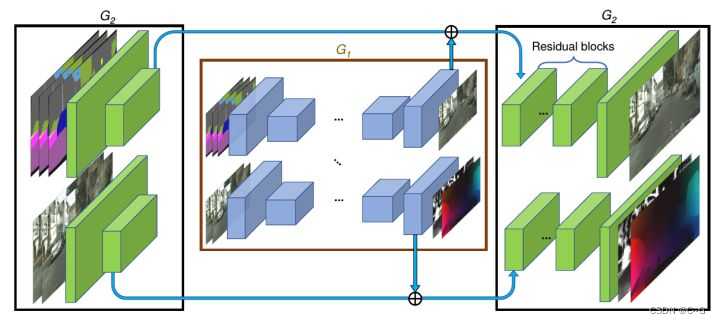
- Generator网络结构
G1低分辨率(Coarse) Generator
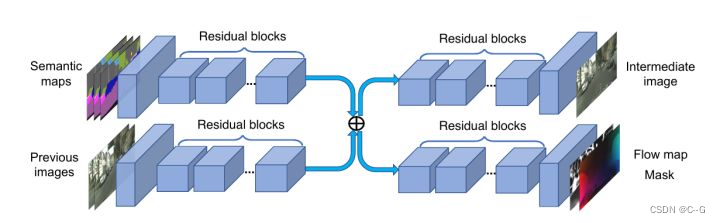
下面我们看一下Generator的网络架构。延续了pix2pixHD的设计,vid2vid还是使用了两阶段的Generator,第一阶段G1用来生成全局粗糙的低分辨率视频,第二阶段G2用来生成局部精细化的高分辨率视频。
其中,G1的输入是下采样2倍之后,前L帧+当前帧的Semantic map序列以及之前L帧生成图像的序列,在经过下采样和提特征之后,在网络的中间将两路输提取入的feature map相加,接着在网络后部又分出两个分支,来生成未加光流约束的原始图像以及光流和权重mask;
G2的输入是原始分辨率的Semantic map序列以及生成图像,在经过2倍下采样+提特征的卷积层之后,将两个分支提取的feature map分别与G1对应的两路输出相加,然后分别送入G2后半部分的两个分支,进行局部细节的refine。
G2高分辨率(Refine) Generator
- Discriminator和Loss
vid2vid与pix2pixHD使用的是相同的Discriminator,即PatchGAN的Discriminator,这里乏善可陈,其基本结构就是由多个卷积层构成的类似Encoder的结构,输入真实或者生成的图像,得到的是判断图像每个小区域是否真实的Score map,然后对这个Score map做Avg Pool最终得到一个Score,代表判别器对这张图像的判别结果
- 空间(Spatial) Discriminator及Loss
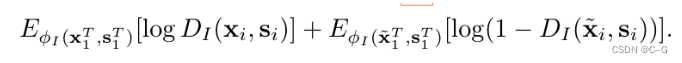

- 时域(Temporal) Discriminator及Loss

- Flow Estimation Loss

Deep Video Portraits
合成和编辑视频肖像(即构成人的头部和上半身的视频)是计算机图形学中的一个重要问题,在视频编辑和电影后期制作,虚拟现实和远程呈现等方面有许多的应用
人脸面部重现有许多工作,但是大部分工作只有面部表情可以修改的很真实,不能完整的修改3D头部姿势,包括上半身和背景。因此,在3D头部控制下,合成完整的肖像视频是更具有挑战性的工作。
将完整的3D头部位置、头部旋转、面部表情以及眼部细节从源参与者转移到目标参与者上,并且可以交互的自由重组源和目标参数实现高保真视觉配音

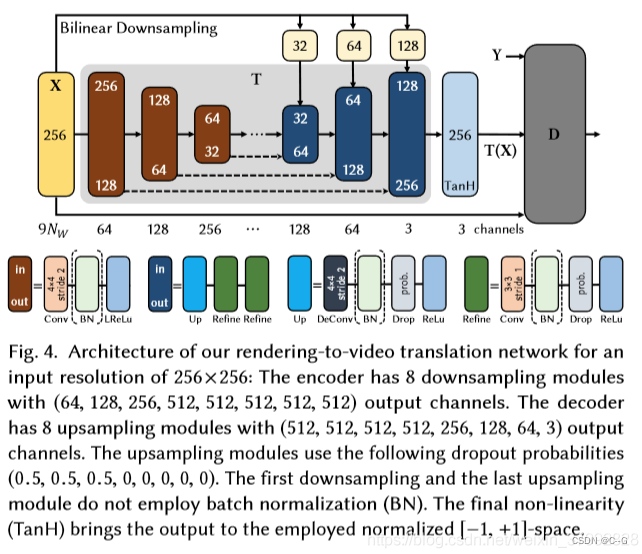
网络由一个一个space-time transformation network T和一个discriminator D组成,T输入一个W×H×9Nw的张量,输出一个目标人物的真实图像。T网络由两部分组成,一个编码器用于计算低维的潜在表示(latent representation),解码器用于生成图片。为了保证生成图片的质量,网络也用了一些常见的策略,包括跳跃链接(skip connection),和级联细化策略(cascaded refinement strategy)。
目标和损失函数
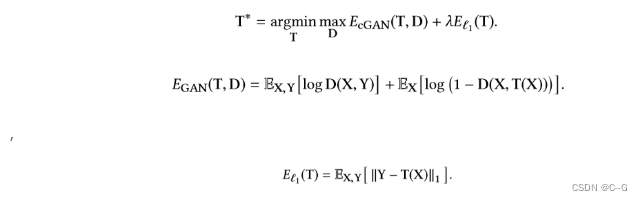
通过迁移源参与者的头部姿势,面部表情和眼睛动作来提供对目标参与者头部的完全控制,同时保留目标的身份和外观。首先,使用SOT的单目人脸重构方法(使用参数化人脸和照明模型)跟踪源和目标参与者,由此得到低的维参数向量序列,表示每个视频帧中参与者的身份,头部姿势,表情,视线和场景照明。接下来,根据修改后的参数生成目标参与者的新合成渲染。 除了正常的色彩渲染外,还渲染对应图(correspondence maps )和眼睛凝视图像( eye gaze images)。为了获得时间上连续的结果,网络输入时空量。 要处理完整的视频,以滑动窗口的方式输入时空量,然后通过从输出帧中组合初始视频来得到完整视频
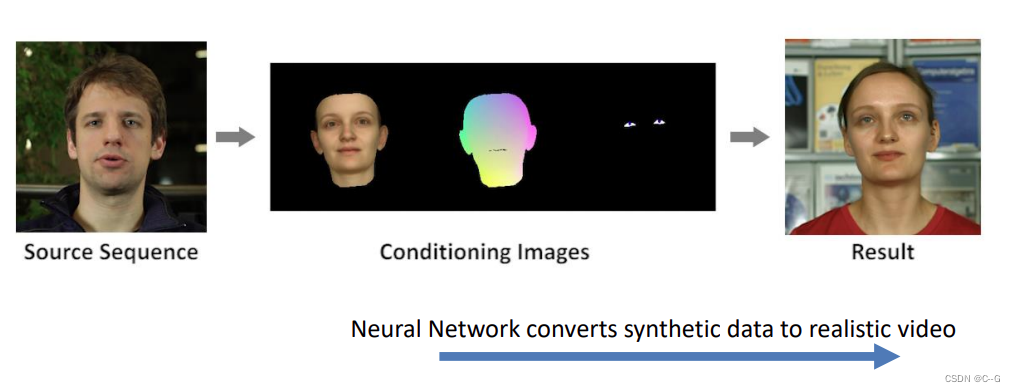

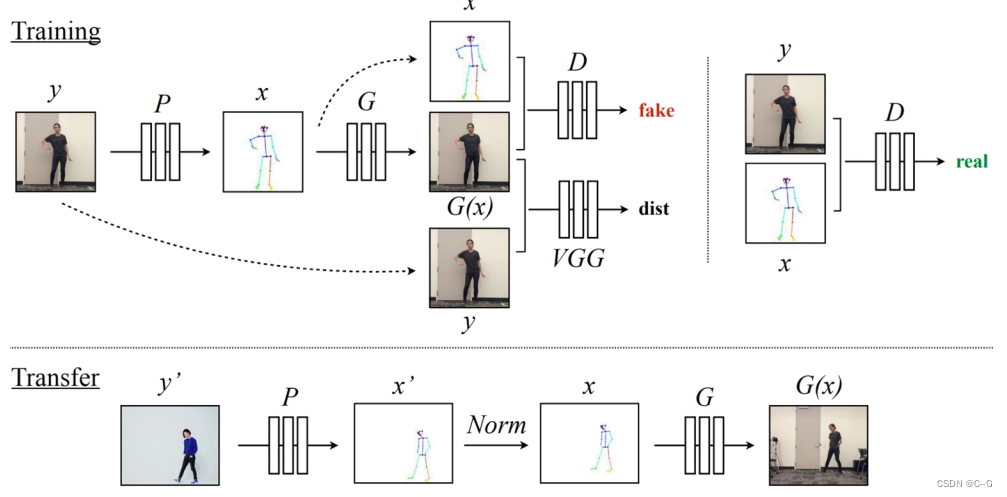
Everybody Dance Now
















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









