







简介
主页:http://geometrylearning.com/StylizedNeRF/

给定一组真实的照片(a)和一个风格图像(b),模型能够生成风格化的新视图©,通过学习风格化的NeRF在3D空间中是一致的。
复杂的三维真实场景的风格化问题,这对虚拟现实和增强现实等应用很有用
利用NeRF作为复杂3D场景的表示存在两个问题
- NeRF需要沿着光线查询数百个采样点来渲染单个像素,内存限制使得很难渲染整个图像,甚至一次渲染一个足够大的补丁,这对于计算内容和样式损失是很重要的,因此直接在小块训练补丁(单个RTX 2080Ti GPU为32×32)上训练一个具有感知风格和内容损失的程式化NeRF,会导致较差的程式化结果
- 直接采用最先进的图像风格化方法对NeRF渲染的图像进行风格化,会在不同的视角下产生不一致的结果,因为这些风格化方法缺乏3D信息。

只在小的训练补丁上训练一个风格和内容损失的风格化NeRF,将导致糟糕的内容维护和不令人满意的风格转移(NeRF w/ style)。在NeRF的结果上直接应用2D图像风式化方法(本例中使用了AdaIN)会导致从不同视图渲染时不一致(2D方法)。通过相互学习的方法,风格化的NeRF和2D风格化的方法产生了更好的风格和一致性质量的结果。
贡献点
- 提出了一种新颖的风格化NeRF方法,用给定的风格图像来风格化3D场景,在视觉质量和3D一致性方面优于现有的方法。
- 针对风格化的NeRF和2D风格化方法提出了一种相互学习的策略,利用了2D方法的风格化能力和NeRF的几何一致性
- 提出了一种可学习潜在码的条件概率建模方法,在实现条件风格化的同时处理二维风格化结果的二义性
实现流程
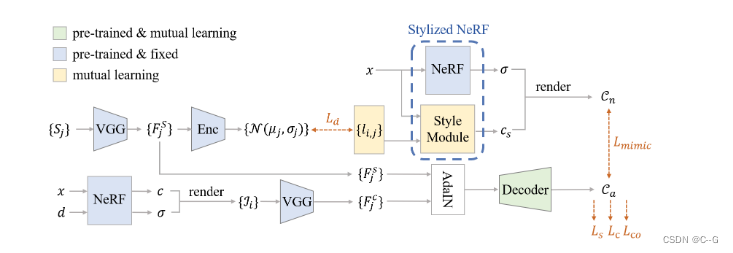
使用一个预先训练和固定的NeRF来渲染一些视图 {Ji} 作为相互学习的增强数据。通过预先训练的 VAE 编码器,将 VGG 从风格图像 {Sj} 提取的风格特征 {F^s j} 嵌入到潜在分布中。将提取的内容特征 {F^c j} 和风格特征 {F^s j} 送入 AdaIN 层和解码器,得到风格化颜色 Ca。另一方面,风格模块将可学习潜在码 {li,j} 和坐标 x 作为输入,预测风格化亮度颜色 Cs,形成风格化NeRF。通过将光线上的采样点与原始不透明度 σ 组合,可以得到渲染的程式化颜色 Cn。目标函数 Ld、Lmimic、Ls、Lc 和 Lco 用于相互学习优化
为了增强训练数据集,普通NeRF渲染了一系列视图 {Ii} 作为训练数据,样式图像表示为 {Sj} ,一个训练视图和一个给定的样式一起构成一个训练实例(li,j)
给定一个场景的图像集合与相应的相机参数,目标是生成风格化的图像遵循给定的风格从指定的新观点,同时保持几何一致性,为此,使用相互学习的方案,通过一致性和模拟损失来优化新引入的风格化NeRF和2D风格化网络
即使相互学习的风格化NeRF具有内在的一致性,但2D风格化网络不能保证结果的严格一致性,这仍然会导致风格化NeRF的结果模糊,因此将不一致的2D风格化结果视为服从样式条件分布的不同样本,并引入服从这些条件分布的潜在代码来处理不一致性,通过负对数似然损失用条件概率来建模可学习的潜在码
2D Stylization Network
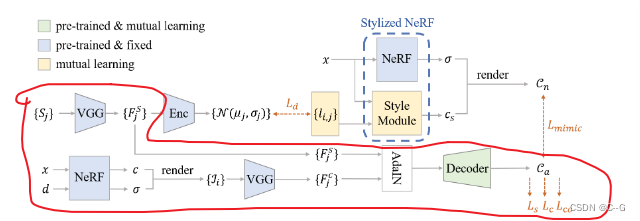
2D Stylization Network由VGG编码器、自适应实例归一化层(AdaIN,二维风格化方法)和基于cnn的解码器组成
注意:AdaIN是一种具有代表性的方法,但也可能被其他先进的图像风式化方法所替代
编码器首先从给定的输入样式 {Sj} 和内容图像 {Li} 中提取特征映射(F^s j)(F^c j),然后AdaIN将内容特征映射的均值和方差对齐到样式特征映射,解码器对对齐的特征映射进行解码,并生成目标样式的输出结果,在这个过程中只有AdaIN的解码器是可以学习的,其他都为预训练
除了风格损失(Ls)和 感知内容损失(Lc)外,还通过一致性损失(Lco)从NeRF中提取3D一致性知识对解码器进行预训练
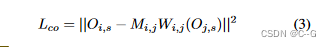
Oi,s 表示视图 i 和 样式 s 的风格化结果,Wi,j 表示根据NeRF估计的深度从视图 j 到视图 i 进行的弯曲操作,Mi,j 表示弯曲和遮挡的掩模。
Stylized NeRF
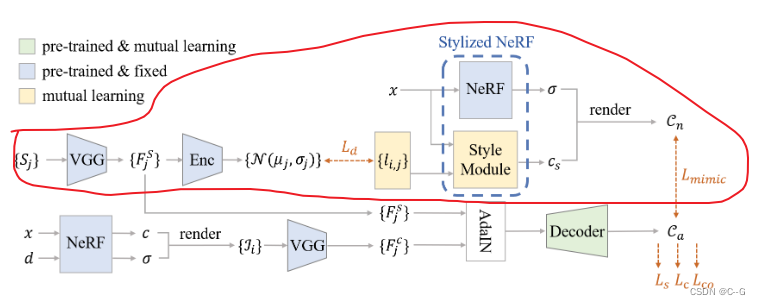
训练一个普通的NeRF来建模不透明度场σ(x)和原始亮度颜色场co(x, d),在接下来的相互学习过程中固定,为了实现NeRF的风格化能力,在NeRF中添加了一个MLP网络作为Style Module,而不是原始的颜色模块,对场景的风格化辐射颜色进行建模
Style Module在训练阶段查询场景的风格化亮度颜色时,除了位置坐标外,还接受可学习潜在码的输入。
NeRF- w中潜在代码用于模拟随机出现和场景瞬变,在Style Module,潜在代码学习了2D风格化结果的风格和模糊性,避免了风格化NeRF结果的模糊,并使其能够有条件地风格化场景。二维方法在指定样式的不同视图上的风格化结果可以看作是一个条件分布的样本
通过预先训练的VAE参数化2D程式化结果的条件分布,VAE将VGG提取的样式特征{F^s j}编码为高斯分布{N (μj, σj)},将二维风格化结果的条件分布参数化为嵌入高斯分布,该分布以样式特征为条件,对于第 i 个视图和第 j 个样式的二维风格化结果,赋给它一个在N (μj, σj)上采样初始化的潜在代码 li,j ,潜码在相互学习的过程中得到优化。为了约束潜在码 li,j 服从{N (μj, σj)} 的分布,使用负对数似然损失 Ld
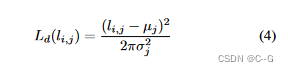
i 和 j 分别为训练视图和风格图像的索引,μj 和 σj 分别表示第 j 类图像嵌入分布的均值和方差,约束可学习潜码服从风格条件分布来参数化二维风格化结果的条件分布,训练时,以嵌入分布的μ均值作为输入对场景进行风格化,损失Ld约束潜在代码以获得更好的聚类和泛化,从而导致更好的结果

Ld聚集了相同风格的潜在代码,并避免了测试结果中的构件。
Mutual Learning
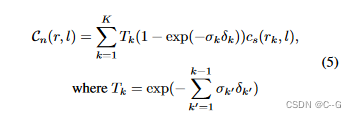
Cn(r, l) 为像素 r 的预测风格化颜色,δk 为第k个采样点与 (k + 1) 个采样点之间的欧拉距离,模拟损失定义为NeRF的程式化结果 Cn(ri, li,j) 与2D风格化方法的 Ca(Ii, Sj)ri 之间的L2距离
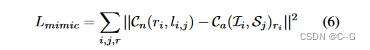
引入拟态(Lmimic)损失,以最好地交流NeRF和2D风格化方法之间不同强度的知识
感知内容损失Lc(Ca(Ii, Sj), Ii) 和风格损失 Ls(Ca(Ii, Sj),Sj) 是由解码器 Ca(Ii, Sj) 的结果决定的,这允许在有限的GPU内存中使用更大的补丁。
NeRF风格模块与潜在代码相互学习过程的目标函数是
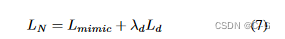
用于微调二维风格化解码器的目标函数可以写成
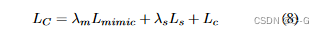
λd、λs和λm是控制项影响的超参数,分别设为1e-5、1和10
效果















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









