







简介
论文发现通过一些简单的修改,ddpm也可以在保持高样本质量的同时实现竞争对数可能性,反向扩散过程的学习方差允许以更少的正向传递数量级进行采样,而样本质量的差异可以忽略不计,这对于这些模型的实际部署非常重要。
扩散模型回顾
扩散模型分为加噪过程和去噪过程
加噪过程公式如下
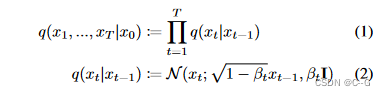
使用重参数技巧,加噪过程可以表示为
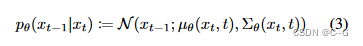
目标函数(VLB)
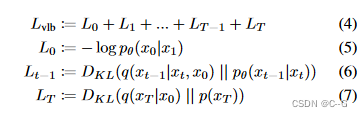
简化为
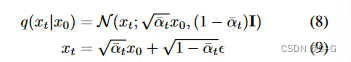
去噪过程公式如下
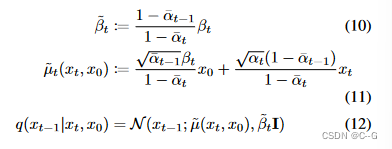
训练过程为通过模型预测不同时间步 t 的噪声,并且该噪声符合正态分布,其中均值表示为:
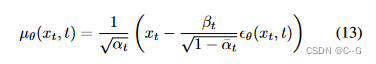
反差可以使用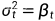 或者
或者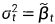
Improving the Log-likelihood
对数似然是生成建模中广泛使用的度量标准,通常认为优化对数似然会迫使生成模型捕获数据分布的所有模式,对数似然的微小改进可以对样本质量和学习到的特征表示产生巨大影响
扩散模型在设置 和t = 1000的同时优化  在ImageNet 64 × 64上经过200K训练迭代后实现了3.99 (bits/dim)的对数似然值。我们在早期的实验中发现,通过将T从1000增加到4000,对数似然提高到3.77。
在ImageNet 64 × 64上经过200K训练迭代后实现了3.99 (bits/dim)的对数似然值。我们在早期的实验中发现,通过将T从1000增加到4000,对数似然提高到3.77。
此外我们可以从不同角度优化DDPM:方差,加噪策略、减少梯度噪声和加速去噪采样过程
可学习的方差
原始DDPM中f方差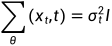 中的
中的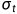 是固定数值
是固定数值 或者
或者 ,实验表明两者都获得了相似的样本质量,它们分别是
,实验表明两者都获得了相似的样本质量,它们分别是 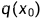 给出的方差的上界和下界,要么是各向同性高斯噪声,要么是delta函数。对于不同长度的扩散过程,每个扩散步骤的比值
给出的方差的上界和下界,要么是各向同性高斯噪声,要么是delta函数。对于不同长度的扩散过程,每个扩散步骤的比值 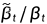
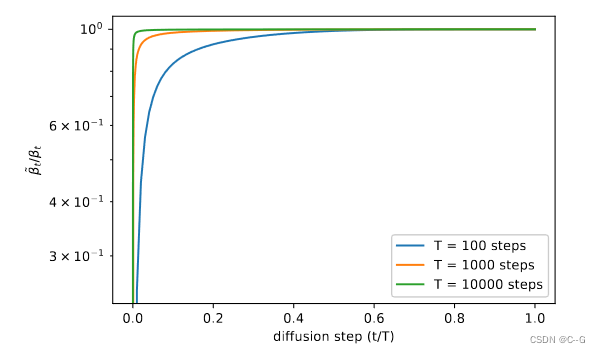
图 1对于不同长度的扩散过程,每个扩散步骤的比值。
和在几何相等,除了在 t = 0附近,即在模型处理细节的时候。随着扩散步骤数的增加,和在扩散过程中似乎保持更接近,这表明,在无限扩散步长的极限下, 的选择可能对样本质量没有影响。换句话说,当我们添加更多的扩散步骤时,模型均值
的选择可能对样本质量没有影响。换句话说,当我们添加更多的扩散步骤时,模型均值  比
比  更能决定分布。
更能决定分布。
虽然上面的论点表明,为了样本质量,固定是一个合理的选择,但它没有说对数似然。事实上,下图显示了扩散过程的前几个步骤对变分下界的贡献最大。因此,我们似乎可以通过使用更好的来提高对数可能性。
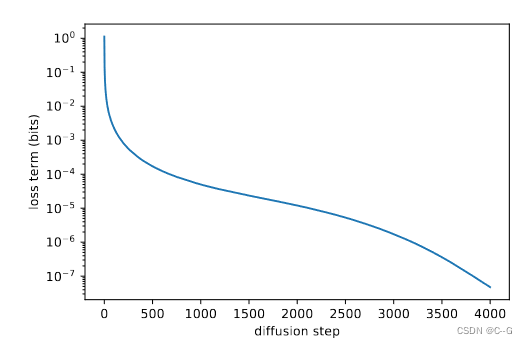
图2 时间步下loss term影响
如图1所示,的合理范围非常小,因此即使是在对数域,神经网络也很难直接预测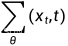 ,更好的方法是在对数域中将方差参数化为和之间的插值
,更好的方法是在对数域中将方差参数化为和之间的插值
模型输出一个向量v,每个维度包含一个分量
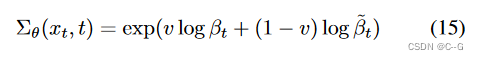
没有对v施加任何约束,理论上允许模型预测插值范围之外的方差。然而,并没有观察到网络在实践中这样做,这表明的边界确实具有足够的表现力。
由于 不依赖于 ,定义了一个新的混合目标
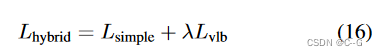
设定  防止
防止 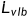 压倒 ,对 项的 输出应用了一个 stop-gradient。这样, 可以引导 ,而 仍然是影响 的主要来源。
压倒 ,对 项的 输出应用了一个 stop-gradient。这样, 可以引导 ,而 仍然是影响 的主要来源。
Improving the Noise Schedule
DDPM的噪声在高分辨率图像效果良好,但是在 64 x 64 和 32 x 32 的数据上效果不好。
同时,如下图,潜在样本分别来自线性(上)和余弦(下)表,线性间隔t值从0到t。线性的最后四分之一的潜在因素几乎是纯噪声,而余弦增加噪声的速度更慢 , 前向噪声处理的末端噪声太大,因此对样品质量的贡献不大

图 3 不同加噪策略结果
如下图,当我们跳过高达20%的反向扩散过程时,用线性时间表训练的模型并没有变得更差(由FID测量)。
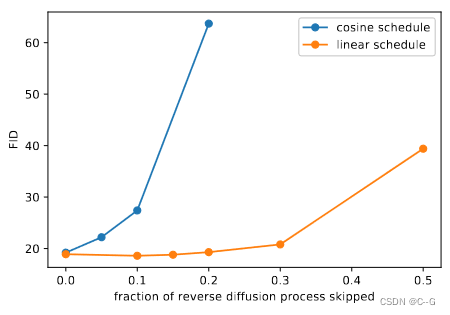
图4 在ImageNet 64 × 64上跳过反向扩散过程的一个前缀时的FID。
因此可以根据  构造了一个不同的噪声表
构造了一个不同的噪声表

在上述公式下,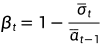 ,为了 防止扩散过程结束时在t =T 附近出现奇点,限制
,为了 防止扩散过程结束时在t =T 附近出现奇点,限制 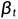 不大于0.999
不大于0.999
余弦设计为在过程中间有一个线性下降的 ,而在t = 0和t = T 的极端值附近变化很小,以防止噪声水平的突然变化。图5显示了两种时间表下的 进展情况。我们可以看到线性时间表更快地趋于零,太快地破坏信息。
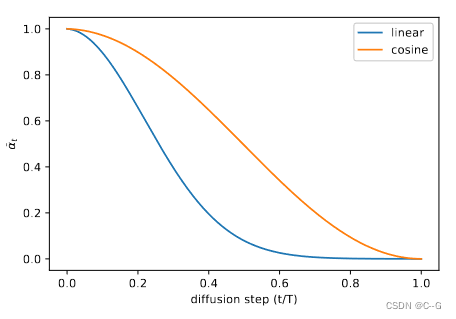
图 5 两种时间表的比较
公式使用一个小的偏移量s来防止 在t = 0附近太小
实验发现在过程开始时有少量的噪声使得网络很难足够准确地预测 ,因此,选择 s = 0.008 使得 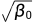 稍小于 像素库大小 1/127.5
稍小于 像素库大小 1/127.5
这里的余弦公式可以用 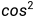
Reducing Gradient Noise
论文希望直接优化 ,而不是通过优化  ,来获得最佳的log-likelihood ,但 是 实际上很难在实践中优化
,来获得最佳的log-likelihood ,但 是 实际上很难在实践中优化
在训练时间相同的前提下,这两条曲线都有噪声,但混合目标显然在训练集上获得了更好的对数似然值
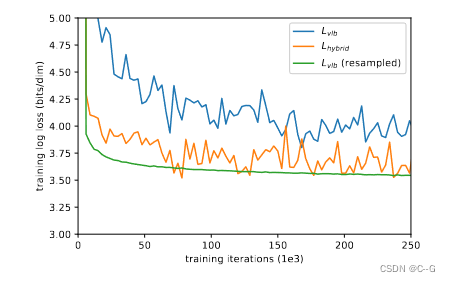
图6不同目标函数的效果
假设 的梯度比 的梯度噪声大得多 ,寻找了一种减少 方差的方法,以直接优化对数似然
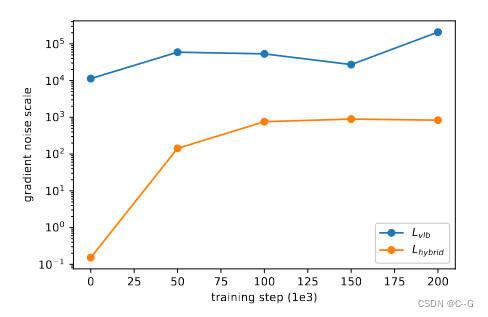
图 7 ImageNet 64 × 64上 vlb 和 hybrid 梯度噪声尺度。
注意到 的不同项有很大不同的幅度(图2),假设均匀采样t会导致 目标中不必要的噪声。为了解决这个问题,采用了重要性抽样:
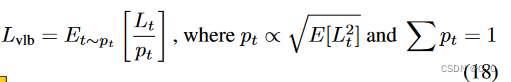
由于 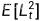 事先是未知的,并且可能在整个训练过程中发生变化,因此为每个损失项保留了前10个值的历史记录,并在训练过程中动态更新。在训练开始时,我们对t进行统一采样,直到为每个t∈[0,t−1]抽取10个样本。
事先是未知的,并且可能在整个训练过程中发生变化,因此为每个损失项保留了前10个值的历史记录,并在训练过程中动态更新。在训练开始时,我们对t进行统一采样,直到为每个t∈[0,t−1]抽取10个样本。
有了这个重要的抽样目标,能够通过优化 来实现最佳对数可能性。这可以在图6中看到 (重采样)曲线。该图还表明,重要采样目标的噪声比原始的均匀采样目标要小得多。我们发现,在直接优化低噪声的 目标时,重要性抽样技术没有帮助。
Results and Ablations
使用 和余弦提高了对数可能性,同时保持相似的FID。优化 以更高的FID为代价进一步提高了log-likelihood。通常更喜欢使用 而不是 ,因为它在不牺牲样本质量的情况下提高了可能性。
Improving Sampling Speed
预训练的 模型可以以比训练时(没有任何微调)少得多的扩散步骤产生高质量的样本
对于用T扩散步骤训练的模型,通常在训练中使用相同的T值序列(1,2,…, T)。但是,也可以使用任意子序列S (t)进行采样。给定训练噪声表 ,对于给定序列S,我们可以得到采样噪声表
,对于给定序列S,我们可以得到采样噪声表 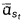 ,然后利用它可以得到相应的采样方差
,然后利用它可以得到相应的采样方差
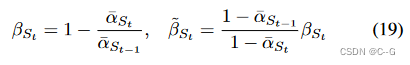
由于 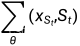 被参数化为
被参数化为 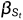 和
和 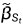 之间的范围,它将自动为更短的扩散过程重新缩放 ,从而通过
之间的范围,它将自动为更短的扩散过程重新缩放 ,从而通过 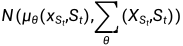 计算
计算 
为了减少从T到K的采样步骤数,使用K个在1到T(包括)之间均匀间隔的实数,然后将每个结果数四舍五入到最接近的整数
用25、50、100、200、400、1000和4000个采样步骤来评估一个模型和一个模型的FID。对一个完全训练的检查点和一个正在训练的检查点都这样做。对于CIFAR-10,使用了200K和500K训练迭代,对于ImageNet64,使用了500K和1500K训练迭代,结果如下图
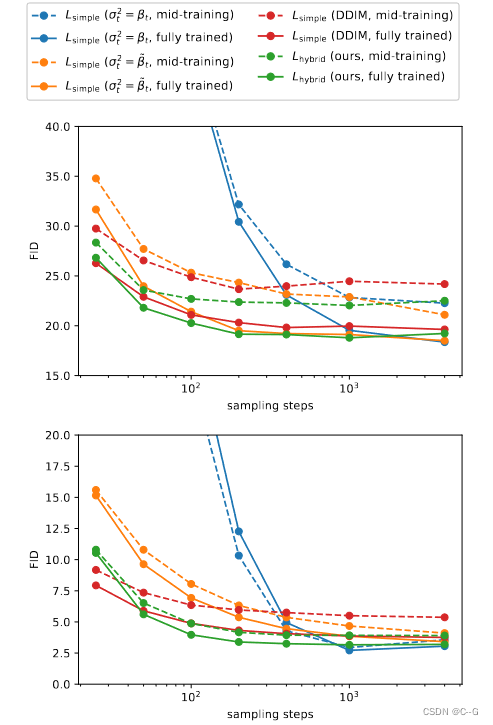
图8 对于在ImageNet 64 × 64(上)和CIFAR-10(下)上训练的模型,FID与采样步骤数的关系。所有模型都训练了4000个扩散步骤
具有固定sigma的模型( 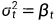 较大,
较大,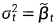 较小)在使用较少的采样步骤时,样本质量受到更大的影响,而具有学习sigma的 模型保持了较高的样本质量 ,对于这个模型,100个采样步骤足以为经过充分训练的模型实现接近最优的FID。
较小)在使用较少的采样步骤时,样本质量受到更大的影响,而具有学习sigma的 模型保持了较高的样本质量 ,对于这个模型,100个采样步骤足以为经过充分训练的模型实现接近最优的FID。
实验
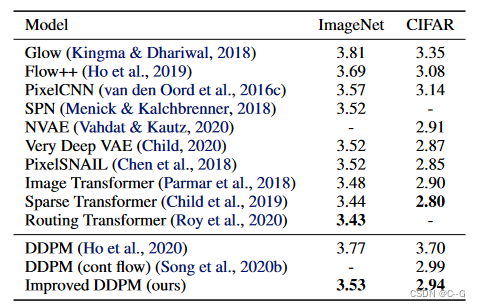
CIFAR-10和无条件ImageNet 64 × 64中ddpm与其他基于似然模型的比较。NLL以bit /dim为单位报告。在ImageNet 64 × 64上,论文模型可以与最好的卷积模型竞争,但不如完全基于变压器的架构。
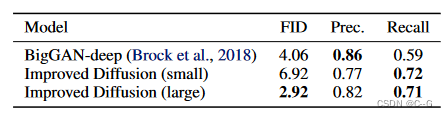
与GAN对比
总结
已经证明,通过一些修改,DDPM可以更快地采样,并获得更好的对数似然,而对样本质量影响很小。通过使用参数化和 学习 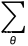 ,可能性得到了提高。这使得这些模型的可能性更接近于其他基于可能性的模型。这种变化还允许从这些模型中进行抽样,步骤要少得多。
,可能性得到了提高。这使得这些模型的可能性更接近于其他基于可能性的模型。这种变化还允许从这些模型中进行抽样,步骤要少得多。
DDPMs可以匹配GANs的样本质量,同时通过召回率获得更好的模式覆盖。此外,还研究了DDPM 是如何随着可用训练计算量的增加而扩展的,并发现更多的训练计算显然会导致更好的样本质量和对数似然。
这些结果的组合使得DDPM成为生成建模的一个有吸引力的选择,因为它们结合了良好的对数可能性、高质量的样本和合理的快速采样,以及一个良好的、稳定的训练目标,易于与训练计算进行扩展














 4346
4346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









